
Chapter 8. Internationalization
The global challenge
Internationalization is a central component of the vision of digital libraries that motivates this book. It is all too easy from the native English speaker's perspective (which includes most of our readers and all three of this book's authors), to sweep under the carpet the many challenging problems of digitally representing and working with text in other languages.
Internationalization is a central component of the vision of digital libraries that motivates this book. It is all too easy from the native English speaker's perspective (which includes most of our readers and all three of this book's authors), to sweep under the carpet the many challenging problems of digitally representing and working with text in other languages.
Of course, we cannot possibly hope to cover all the issues raised by all the world's languages—and in a general text like this one, it would be inappropriate to attempt to do so. Instead, this chapter highlights some issues that are involved when making digital libraries available in languages other than English. We prefer to tackle a few specific issues in detail, rather than to give a general high-level sketch of what needs to be done for the world in general.
We have already introduced a foreign-language collection: the Pergamos system described in Section 1.3 has a user interface in Greek, English, and French; we set the stage for this chapter by showing some further interfaces and collections in other languages. Then we give a comprehensive account of Unicode. This standard aims to represent all the characters used in all the world's languages. We discuss it briefly in Section 4.1, but to work globally you need to know much more. As mentioned in Chapter 4, the same character can have multiple representations. To understand the complications this causes, imagine searching for an accented word like
détente in French text, where the non-ASCII character
é is sometimes represented as a single character in extended ASCII, sometimes in regular 7-bit ASCII as
e followed by a backspace followed by ′, and sometimes by the HTML incantation
é.
Prior to the establishment of Unicode, ASCII had been extended in many ad hoc ways, including a standard for Hindi and related languages called ISCII, where the initial
I stands for “Indian.” It turns out that Hindi and other Indic languages present many interesting problems for character coding that have not yet been entirely solved in Unicode-compliant applications. These languages raise subtle problems that are difficult for people of a European background to appreciate, and Section 8.3 gives a glimpse of the complexities involved. We also discuss the development of ISCII and practical problems with the adoption of Unicode for such languages.
Finally, we look at some issues with Chinese and other Asian languages: the so-called CJK (Chinese-Japanese-Korean) family of languages. As discussed in Chapter 4, languages like Chinese are written without using any spaces or other word delimiters (except for punctuation marks)—indeed, the Western notion of a
word boundary is literally alien. Nevertheless, the CJK languages do contain words. Most Chinese words comprise several characters: two, three, or four. Five-character words also exist, but they are rare. Many characters can stand alone as words in themselves, while on other occasions the same character is the first or second component of a two-character word, and on still others it participates as a component of a three- or four-character word.
Another issue is that CJK languages are not alphabetic, and—although it will seem surprising to Western readers—there is no single universally used way of ordering text strings analogous to alphabetic ordering in European languages. This makes the creation of browsing lists in digital libraries, for example, problematic. These are international problems, and they call for international solutions. Digital library systems must be globalized, not created by a single group of specialists.
8.1. Multilingual interfaces and documents
Figure 8.1 is from a collection of historical New Zealand Māori newspapers and shows the same page in image and text form. As you can see, the tabular information at the top of the page (just beneath the masthead and issue details), which represents sums of money (although it is difficult to make out), is missing from the text version. The text version is what supports searching, so this information is invisible to searches. On the other hand, the word
Rotorua, which was the search term for this page, is highlighted in the text but not in the page image. The collection provides both page images and text because of the advantage of being able to locate search terms in the text. Readers can choose which to view and can move quickly from one to the other. A magnified version of page images is also available.

The Māori newspapers record fascinating historical information that is useful from many points of view. The newspapers were published from 1842 to 1933, a formative period in the development of New Zealand, which, being so far from Europe, was colonized quite late. Far-reaching political developments took place during these years, and the collection is a significant resource for historians. It is also an interesting corpus for linguists, because changes in the Māori language were still taking place and can be tracked through the newspapers.
The collection contains 40 different newspaper titles that were published during the period. They are mostly written in Māori, although some are in English and a few have parallel translations. There are a total of 12,000 images, varying from A4 to double-page tabloid spreads—these images contain a total of around 20,000 newspaper pages. The images had previously been collected on microfiche. They are in a variety of conditions: some are crisp, others are yellowish, and still others are badly water-stained.
The enormous effort of constructing the microfiche was undertaken to make this national treasure available to scholars. However, the material was entirely unindexed. Although a research project is producing manual summaries of the articles, these will take many years to complete. The digital library collection completely transforms access to the material. First, the documents are available on the Web, which makes them readily and universally accessible. Second, they can be searched, which makes almost any kind of research immeasurably easier. Third, the collection does not require scholarly research skills to use, allowing a wider group of people to discover things that they would never otherwise know about their heritage, ancestry, or home town. This collection is the largest single online Māori resource in the country.
Figure 8.2 shows digital libraries with interfaces in French and Portuguese. The French illustration is from a UNESCO collection called Sahel Point Doc that contains information about the Sahel region of Sub-Saharan Africa. Everything in this collection is in French: all target documents, the entire user interface, and the help text. Figure 8.2b shows a Portuguese interface to an English-language collection—the same Gutenberg collection that we examined earlier. Again, the entire user interface (and help text) has been translated into Portuguese, but in this case the target documents are in English. In fact, the user interface language is a user-selectable option on a Preferences page: you can instantaneously switch to languages like German, Dutch, Spanish, and Māori, too.
 |
| Figure 8.2: |
Figure 8.3 shows documents from two different Chinese collections. The first comes from a collection of rubbings of Tang poetry—not unlike the stone steles described in Chapter 1, the world's oldest surviving library. These documents are images, not machine-readable text. There are machine-readable versions of each document—although in this case they were entered manually rather than by OCR—but the user never sees them: they are used only for searching.
 |
| Figure 8.3: |
The second Chinese example is from a small collection of classic literature. Here, books are represented in the same way as they are in the Humanity Development Library (see Section 3.1), with chapters shown by folders. The work illustrated here is
The Plum in the Golden Vase, an anonymous early 17th-century satirical novel that recounts the domestic life of a corrupt merchant with six wives and concubines who slowly destroys himself with conspicuous consumption, political imbroglios, and sexual escapades. One of the three most famous Ming Dynasty novels, it reflects the debaucheries of society at the time—and is still banned in China. The literature collection is textual, so matching search terms are highlighted in boldface. Boldface characters (and italics) are used in Chinese just as they are in Western languages.
It's easy to display documents in any language within Web browsers. In the early days you had to download a special plug-in for the character set being used, but today's browsers incorporate support for many languages. Figure 8.4 shows pages from an Arabic collection of information on famous mosques, displayed using an ordinary browser.

As Figures 8.3a and 8.4b imply, the text of both the Chinese and Arabic collections (as well as text in all other languages) is fully searchable. Again, the browser does the hard part, facilitating character entry and ensuring that Arabic text is composed from right to left, not from left to right as in other languages. To enter ideographic languages like Chinese, which go beyond the normal keyboard, you need special software. All documents in this digital library system are represented internally in Unicode and the system converts between this and the representation supported by the browser (which can differ from one browser to another). The next section discusses the complexities of different character sets, and the approach Unicode uses to bring them together.
8.2. Unicode
The Unicode standard is massive. It has two parts (ISO 10646-1 and ISO 10646-2) and specifies a total of 94,000 characters. The first part focuses on commonly used living languages and is called (for reasons to be explained shortly) the
Basic Multilingual Plane. It weighs in at 1,000 pages and contains 49,000 characters.
Table 8.1 breaks down the ISO 10646-1 code space into different scripts, showing how many codes are allocated to each (unassigned codes are shown in parentheses). Unicode's scope is impressive: it covers Western and Middle Eastern languages, such as Latin, Greek, Cyrillic, Hebrew, and Arabic; Chinese, Japanese, and Korean Hangul ideographs; as well as other scripts, such as Bengali, Thai, and Ethiopic—to name just a few. Also included are Braille, mathematical symbols, and a host of other shapes.
Table 8.1 divides the Unicode code space into five zones: alphabetic scripts, ideographic scripts, other characters, surrogates, and reserved codes. Falling within the first zone are the broad areas of general scripts, symbols, and CJK (Chinese-Japanese-Korean) phonetics and symbols. The reserved blocks are intended to help Unicode's designers respond to unforeseen circumstances.
Unicode distinguishes characters by script, and those pertaining to a distinct script are blocked together in contiguous numeric sequences: Greek, Cyrillic, Hebrew, and so on. However, characters are not distinguished by language. For example, the excerpt from the Unicode standard in Figure 8.5 shows the Basic Latin (or standard ASCII) and Latin-1 Supplement (an ASCII extension) characters, which are used for most European languages. Capital
A in French is the same character as in English. Only the accented letters that are used in European languages are included in the Latin-1 Supplement; the basic character forms are not redefined.

Punctuation is also shared among different scripts. The ASCII period (i.e., full stop) in Figure 8.5 is used in Greek and Cyrillic text too. However, periods in languages like Armenian, Arabic, Ethiopic, Chinese, and Korean are shaped differently and have their own Unicode representations. The multifunction ASCII hyphen is retained for the purpose of round-trip compatibility (see Section 4.1), but new codes are defined under “general punctuation” (codes 2000 and up in Table 8.1) to distinguish among the hyphen (-), en-dash (–), and em-dash (—). The minus sign, which is not usually distinguished typographically from the en-dash, has its own symbol as a “mathematical operator” (codes 2200 and up in Table 8.1).
Unicode distinguishes letters from different scripts even though they may look identical. For example, the Greek capital alpha looks just like the Roman capital
A, but capital alpha receives its own code in the Greek block (codes 0370 and up in Table 8.1). This allows you to lower-case capital alpha to α, and capital
A to
a, without worrying about exceptions.
The characters at the core of Unicode are called the
universal character set, and the standard is fundamentally a suite of lookup tables that specify which character is displayed for a given numeric code. What are all these characters, and what do they look like? Every one tells a story: its historical origin, how it changed along the way, the languages it is used in, how it relates to other characters, and how it can be transliterated or transcribed. We cannot tell these stories here: you will have to refer to other sources.
As an example of diversity, Figure 8.6a shows some of the Extended Latin characters, while Figure 8.6b shows part of the Cyrillic section. As you can see, some Cyrillic letters duplicate identical-looking Latin equivalents.


Composite and combining characters
In ordinary usage, the word
character refers to various things: a letter of an alphabet, a particular mark on a page, a symbol in a certain language, and so on. In Unicode, the term refers to the abstract form of a letter, but in a broad sense, so that it can encompass the fabulous diversity of the world's writing systems. More precise terminology is employed to cover particular forms of use.
A
glyph refers to a particular rendition of a character (or composite character) on a page or screen. Different fonts create different glyphs. For example, the character “a” in 12-point Helvetica is one glyph; in 12-point Times it is another. Unicode does not distinguish between different glyphs. It treats characters as abstract members of linguistic scripts, not as graphic entities.
A
code point is a Unicode value, specified by prefixing
U+ to the numeric value given in hexadecimal. LATIN CAPITAL LETTER G (as the Unicode description goes) is U+0047. A
code range gives a range of values: for example, the characters corresponding to ASCII are located at U+0000–U+007F and are called Basic Latin.
A code point does not necessarily represent an individual character. Some code points correspond to more than one character. For example, the code point U+FB01, which is called LATIN SMALL LIGATURE FI, represents the sequence
f followed by
i, which in most printing is joined together into a single symbol that is technically called a
ligature,
fi. Other code points specify part of a character. For example, U+0308 is called COMBINING DIAERESIS, and—at least in normal language—is always accompanied by another symbol to form a single unit, such as
ü,
ë, or
ï.
The diaeresis is an example of what Unicode calls a
combining character. To produce the single unit
ü, the Latin small letter
u (which is U+0075) is directly followed by the code for the diaeresis (which is U+0308) to form the sequence U+0075 U+0308. This is the handwriting sequence: first draw the base letter, then place the accent. Combining characters occupy no space of their own: they share the space of the character they combine with. They also may alter the base character's shape: when
i is followed by the same combining diaeresis, the result looks like
ï—omitting the original dot in the base letter. Drawing Unicode characters is not straightforward: it is necessary to be able to place accents over, under, and even through arbitrary characters—which may already be accented—and still produce acceptable spacing and appearance.
Because of the requirement to be round-trip compatible with existing character sets, Unicode can also have single code points that correspond to precisely the same units as character combinations—in fact, we have seen examples of these in the Latin-1 supplement shown in Figure 8.6a. This means that certain characters have more than one representation. For example, the middle letter of
naïve could be represented using the combining character approach by U+0069 U+0308, or as a single, precomposed unit using the already prepared character U+00EF. Around 500 precomposed Latin letters, for instance, in the Unicode standard are superfluous, in that they can be represented using combining character sequences.
Combining characters allow many character shapes to be represented within a limited code range. They also help compensate for omissions. For example, the Guaraní Latin small
g with tilde can be expressed without embarking upon a lengthy standardization process to add this previously overlooked character to Unicode. Combining characters are an important mechanism in intricate writing systems like Hangul, the Korean syllabic script. In Unicode, Hangul is covered by 11,172 precomposed symbols (codes AC00 and up in Table 8.1), each of which represents a syllable. Syllables are made up of
Jamo, which is the Korean name for a single element of the Hangul script. Each Unicode Hangul syllable has an alternative representation as a composition of Jamo, and these are also represented in Unicode (codes 1100 and up in Table 8.1). The rules for combining Jamo are complex, however—which is why the precomposed symbols are included. But to type medieval Hangul even more combinations are needed, and these are not available in precomposed form.
The existence of composite and combining characters complicates the processing of Unicode text. When searching for a particular word, alternate forms must be considered. String comparison with regular expressions presents a knottier challenge. Even sorting text into lexicographic order becomes nontrivial. Algorithmically, all these problems can be reduced to comparing two strings of text—which is far easier if the text is represented in some kind of normalized form.
Unicode defines four normalized forms using two orthogonal notions:
canonical and
compatibility equivalence. Canonical equivalence relates code points to sequences of code points that produce the same character—as in the case discussed earlier, where the combination U+0069 U+0308 and the single precomposed character U+00EF both represent
ï.
Canonical composition is the process of turning combining character sequences into their precomposed counterparts;
canonical decomposition is the inverse.
Compatibility equivalence relates ligatures to their constituents, such as the ligature
fi (U+FB01) and its components
f (U+0066) and
i (U+0069). Decomposing ligatures simplifies string comparison, but the new representation no longer maintains a one-to-one character-by-character mapping with the original encoding.
The four normalized forms defined by the Unicode standard are
• canonical decomposition
• canonical decomposition followed by canonical composition
• compatibility decomposition
• compatibility decomposition followed by canonical composition.
Certain Unicode characters are officially
deprecated, which means that although they are present in the standard, they are not supposed to be used. This is how mistakes are dealt with. Once a character has been defined, it cannot be removed from the standard (because that would sacrifice backward compatibility); the solution is to deprecate it. For example, there are two different Unicode characters that generate the symbol Å, LATIN CAPITAL LETTER A WITH RING ABOVE (U+00C5) and ANGSTROM SIGN (U+212B); the latter is officially deprecated. Deprecated characters are avoided in all normalized forms.
Further complications, which we only mention in passing, are caused by directionality of writing. Hebrew and Arabic are written right to left, but when numbers or foreign words appear, they flow in the opposite direction; thus bidirectional processing may be required within each horizontal line. The Mongolian script can only be written in vertical rows. Another issue is the fact that complex scripts, such as Arabic and Indic scripts, include a plethora of ligatures, and contextual analysis is needed to select the correct glyph.
Because of the complexity of Unicode, particularly with regard to composite characters, three implementation levels are defined:
• Level 1 forms the base implementation, excluding combining characters and the Korean Hangul Jamo characters.
• Level 2 permits a fixed list of combining characters, adding, for example, the capability to express Hebrew, Arabic, Bengali, Tamil, Thai, and Lao.
• Level 3 is the full implementation.
Unicode character encodings
With future expansion in mind, the ISO standard formally specifies that Unicode characters are represented by 32 bits each. However, all characters so far envisaged fit into the first 21 bits. In fact, the Unicode consortium differs from the ISO standard by limiting the range of values prescribed to the 21-bit range U+000000–10FFFF. The discrepancy is of minor importance; we follow the Unicode route.
So-called planes of 65,536 characters are defined; there are 32 of them in the 21-bit address space. All the examples discussed above lie in the Basic Multilingual Plane, which represents the range U+0000–U+FFFF and contains virtually all characters used in living languages. The Supplementary Multilingual Plane, which ranges from U+10000–U+1FFFF, contains historic scripts, special alphabets designed for use in mathematics, and musical symbols. Next is the Supplementary Ideographic Plane (U+20000–U+2FFFF), which contains 40,000-odd additional Chinese ideographs that were used in ancient times but have fallen out of current use. The Supplementary Special-Purpose Plane (U+E0000–U+EFFFF), or Plane 14, contains a set of tag characters for language identification, to be used with special protocols.
Given the ISO 32-bit upper bound, the obvious encoding of Unicode uses 4-byte values for each character. This scheme is known as UTF-32. A complication arises from the different byte ordering that computers use to store integers:
big-endian (where the 4 bytes in each word are ordered from most significant to least significant) versus
little-endian (where they are stored in the reverse order), and the standard includes a mechanism to disambiguate the two.
The Basic Multilingual Plane is a 16-bit representation, so a restricted version of Unicode can use 2-byte characters. In fact, a special escape mechanism called
surrogate characters (explained below) is used to extend the basic 2-byte representation to accommodate the full 21 bits. This scheme is known as UTF-16. It too is complicated by the endian question, and resolved in the same way. For almost all text, the UTF-16 encoding requires half the space needed for UTF-32.
We mention UTF-8 in Chapter 4. It is a variant of Unicode that extends ASCII—which, as we have seen, is a 7-bit representation where each character occupies an individual byte—in a straightforward way. UTF-8 is a variable-length encoding scheme where the basic entity is a byte. Being byte-oriented, this scheme avoids the endian issue that complicates UTF-32 and UTF-16. We explain the UTF methods more fully in the following sections.
UTF-32
In Figure 8.7 the word
Welcome in five different languages has been converted to Unicode (Figure 8.7a) and encoded in the three different UTF methods (Figure 8.7b). UTF-32 maps the universal character set to 4-byte integers, and Unicode is turned into UTF-32 by dropping the U+ prefix.

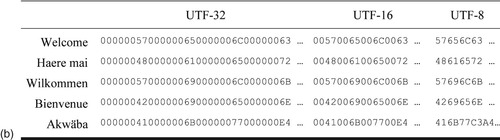
Byte order is irrelevant when data is generated and handled internally in memory; it only becomes an issue when serializing information for transfer to a disk or transmission over a byte-oriented protocol, such as the hypertext transfer protocol (http). In the Unicode standard, the big-endian format is preferred, bytes being ordered from most significant to least significant—just as they are when writing out the number in hexadecimal, left to right. This is what is shown in Figure 8.7b. However, two variants are defined: UTF-32BE and UTF-32LE for big-endian and little-endian, respectively.
A UTF-32 file can be either. Working within a single computer system, it does not matter which ordering is used—the system will be internally consistent. If necessary, however, UTF-32 encoding can include a
byte-order mark to differentiate the two cases. This character, from the Reserved zone in Table 8.1, is defined as “zero-width no-break space.” Its byte-for-byte transposition is intentionally defined to be an invalid character. This means that software that does not expect a byte-order mark will be fail-safe, since a correctly matched endian system displays the byte-order mark as a zero-width space, and a mismatched one immediately detects an incompatibility through the presence of the invalid character.
In practice it is rare to encounter UTF-32 data, because it makes inefficient use of storage. If text is constrained to the basic multilingual plane (and it usually is), the top two bytes of every character are zero.
UTF-16
In UTF-16, characters within the Basic Multilingual Plane are stored as 2-byte integers, as can easily be discerned in Figure 8.7b. The same byte-order mark as above is used to distinguish the UTF-16BE and UTF-16LE variants.
To represent code points outside the Basic Multilingual Plane, specially reserved values called
surrogate characters are used. Two 16-bit values, both from the Surrogates zone in Table 8.1, are used to specify a 21-bit value in the range U+10000–U+10FFFF (a subset of the full 21-bit range, which goes up to 1FFFFF). Here are the details: the 21-bit number is divided into 11 and 10 bits, respectively, and to each is added a predetermined offset to make them fall into the appropriate region of the surrogate zone. This is a kind of “escape” mechanism, where a special code is used to signify that the following value should be treated differently. However, the surrogate approach is more robust than regular escaping: it allows recovery from errors in a corrupted file, because it does not overload values from the nonescaped range, and thus the meaning cannot be confused even if the first surrogate character is corrupted. Inevitably, robustness comes at a cost—fewer values can be encoded than with conventional escaping.
UTF-8
UTF-8 is a byte-based, variable-length scheme that encodes the same 21-bit character range as UTF-16 and UTF-32. Code lengths vary from one byte for ASCII values through four bytes for values outside the Basic Multilingual Plane. If the top bit of a UTF-8 byte is 0, that byte stands alone as a Unicode character, making the encoding backward-compatible with 7-bit ASCII. Otherwise, when the byte begins with a 1 bit, the leading 1 bits in it are counted, and their number signals the number of bytes in the code—11 for two bytes, 111 for three, and 1111 for four. The four possibilities are illustrated in Table 8.2. Subsequent bytes in that character's code set their two top bits to 10—so that they can be recognized as continuation bytes even out of context—and use the remaining six bits to encode the value.
Figure 8.7b shows the
Welcome example in UTF-8. Of interest is the last line, which is one byte longer than the others. This is because the encoding for
ä falls outside the ASCII range: Unicode U+00E4 is represented as the two bytes C3 A4, in accordance with the second entry of Table 8.2.
To eliminate ambiguity, the Unicode standard states that UTF-8 must use the shortest possible encoding. For example, writing UTF-8 F0 80 80 C7 encodes U+0047 in a way that satisfies the rules, but it is invalid because 47 is a shorter representation.
Using Unicode in a digital library
Unicode encoding may seem complex, but it is straightforward enough to use in digital library software. Internally, every string can be declared as an array of 16-bit integers and used to hold the UTF-16 encoding of the characters. In Java this is exactly what the built-in
String type does. In C and C++ the data type
short is a 16-bit integer, so UTF-16 can be supported by declaring all strings to be
unsigned short. Readability is improved by building a new type that encapsulates this. In C++ a new class can be built that provides appropriate functionality. Alternatively, a support library can be used, such as the type
wchar_t defined in the ANSI/ISO standard to represent “wide” characters.
Further work is necessary to treat surrogate characters properly. But usually operation can be restricted to the Basic Multilingual Plane, which covers all living languages—more than enough for most applications. A further practical restriction is to avoid combining characters and to work with Unicode level 1, which makes it far easier to implement string matching operations.
Take the problem of accent folding. Speakers of languages like French and Spanish generally type words in the properly accented form, because without accents words look as strange to them as misspellings do to us. But in some circumstances it may be helpful to arrange for queries to match terms in documents whether or not accents are used—either in the document or the query. For example, in a digital library based on the publications of famous 17th-century mathematicians, documents containing the word
Hôpital—a French mathematician, as well as the word for hospital—would be returned for the query
Hopital. Equally, documents containing the unaccented term (perhaps caused by erroneous optical character recognition) would be returned for the query
Hôpital, as well as ones containing the correct spelling.
If the input is Unicode level 1, the software need only check each character in turn, looking up its Unicode value in a table containing the fixed list of accented characters to see whether it should be elided. The situation is a little more complex when working with higher levels of Unicode representation—because combining characters must be checked too—but it is not overly complex.
Sorting Unicode strings into order is a more involved problem. English can be sorted simply and efficiently by numerically ordering a given list of strings by their ASCII values (ignoring, for now, complications like case difference), but things are more complex in an international setting. Although the code pages in Unicode present characters in logical groups that have a systematic ordering, extending the simple approach to sort strings according to each character's Unicode value quickly runs into difficulties. Corrections in later versions of the standard are necessarily out of order. In German, the letter
ö precedes
z in the alphabet, but the opposite convention is used in Swedish. In Slovak,
ch is treated as a single letter and positioned after
h. Even within a language, the rules for ordering can differ depending on the context. (In certain English-speaking countries, telephone directories treat names beginning with
Mc and
Mac as though they were the same, with
MacAdam and
McAdam appearing together and
Maguire later on.) The situation is more complex for non-European languages, and for ideographic scripts like Chinese characters, the notion of ordering is not well defined—we return to this at the end of Section 8.4.
The good news is that Unicode defines an approach that takes all these issues into account: the so-called
collation algorithm. This algorithm first transforms each string into the first of the four Unicode normal forms—the process of canonical decomposition. Then a lookup table is used to map the characters to a set of numeric values known as
levels. Different levels are used to achieve different types of ordering, such as ignoring case or accents. The standard defines a 4-level scheme as the default. At the first level is the base character: such as the difference between an
A and a
B. Accent differences are taken into account in the second level, case differences at the third, and punctuation differences at the fourth, as illustrated in Table 8.3. The default table is then combined with a mechanism known as
tailoring that allows for language-specific variations. The scheme is powerful enough to support the ordering described in Section 8.4, such as by the number of strokes in an ideograph.
| Level | Description | Examples |
|---|---|---|
| 1 | Base characters | role < roles < rule |
| 2 | Accents | role < r ôle < roles |
| 3 | Case | role < Role < r ôle |
| 4 | Punctuation | role < “role” < Role |
Most programming languages provide library support for the Unicode collation algorithm. Although efficiency is a primary objective, generality comes at a price, and ordering strings this way carries a significant computation cost—far greater than accent folding, for example. This will become less of a concern over time as technological advances improve computer performance.
When writing Unicode characters to disk in a digital library, the 16-bit character representation is usually converted to UTF-8; the process is reversed when the disk is read. This normally reduces file size greatly and increases portability, because the files do not depend on the order in which the bytes are written.
Care is necessary to display and print Unicode characters properly. Most Unicode-enabled applications incorporate an arsenal of fonts and use a lookup table to map each character to a displayable glyph in a known font. Complications include composite Unicode characters and the direction in which the character sequence is displayed. Digital library software benefits immensely from the Unicode support already present in modern Web browsers.
8.3. Hindi and indic scripts
Unicode is advertised as a uniform way of representing all the characters used in all the world's languages. Unicode fonts exist and are installed as standard with most commercial word processors and Web browsers. It is natural for people—particularly people from Western linguistic backgrounds—to assume that all problems associated with representing different languages on computers have been solved. Unfortunately, today's Unicode-compliant applications fall far short of providing a satisfactory solution for languages with intricate scripts.
We use Hindi and related Indic scripts as an example. As Table 8.1 shows, the Unicode space from 0900 to 0DFF is reserved for ten Indic scripts. Although many hundreds of different languages are spoken in India, the principal officially recognized ones are Hindi, Marathi, Sanskrit, Punjabi, Bengali, Gujarati, Oriya, Assamese, Tamil, Telugu, Kannada, Malayalam, Urdu, Sindhi, and Kashmiri. The first 12 of these are written in one of nine writing systems that have evolved from the ancient Brahmi script. The remaining three, Urdu, Sindhi, and Kashmiri, are primarily written in Persian Arabic scripts, but can be written in Devanagari, too (Sindhi is also written in the Gujarati script). The nine scripts are Devanagari, Bengali, Gujarati, Oriya, and Gurmukhi (northern or
Aryan scripts), and Tamil, Telugu, Kannada, and Malayalam (southern or
Dravidian ones). Figure 8.8 gives some characters in each of these scripts. As you can see, the characters are beautiful—and the scripts differ radically from each other. Unicode also includes a script for Sinhalese, the official language of Sri Lanka.

Hindi, the official language of India, is written in Devanagari (pronounced
Dayv’nagri, with the accent on the second
a), which is used for writing Marathi and Sanskrit as well. (It is also the official script of Nepal.) The Punjabi language is written in Gurmukhi. Assamese is written in a script that is very similar to Bengali, but it has one additional glyph and another glyph that is different. In Unicode, the two scripts are merged, with distinctive code points for the two Assamese glyphs. Thus the Unicode scripts cover all 12 of the official Indian languages that are not written in Persian Arabic. All these scripts derive from Brahmi, and all are phonetically based. In fact the printing press did not reach the Indian subcontinent until missionaries arrived from Europe. The languages had a long time to evolve before they were fixed in print, which contributes to their diversity.
ISCII: Indian Script Code for Information Interchange
During the 1970s the Indian Department of Official Languages began working on devising codes that catered to all official Indic scripts. A standard keyboard layout was developed that provides a uniform way of entering them all. Despite the very different scripts, the alphabets are phonetic and have a common Brahmi root that was used for ancient Sanskrit. The simultaneous availability of multiple Indic languages was intended to accelerate technological development and to facilitate national integration in India.
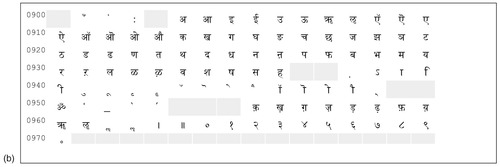
The result was ISCII, the Indian Script Code for Information Interchange. Announced in 1983 (and revised in 1988), it is an extension of ASCII that places new characters in the upper region of the code space. The code table supplies all the characters required in the Brahmi-based Indic scripts. Figure 8.9a shows the ISCII code table for the Devanagari script. Tables for the other scripts in Figure 8.8 are similar but contain differently shaped characters (and some entries are missing because there is no equivalent character in that script). The code table contains 56 characters, 10 digits (in the last line of Figure 8.9a), and 18 accents and combining characters. There are also three special escape codes, but we will not delve into their meaning here.


Unicode for Indic scripts
The Unicode developers adopted ISCII lock, stock, and barrel—they had to, because of their policy of round-trip compatibility with existing codes. They used different parts of the code space for the various scripts, which means that (in contrast to ISCII) documents containing multiple scripts can easily be represented. However, they also included some extra characters—about 10 of them—that in the original ISCII design were supposed to be formed from combinations of other keystrokes. Figure 8.9b shows the Unicode code table for the Devanagari script.
Most of the extra characters give a shorthand for frequently used characters, and they differ from one language to another. An example in Devanagari is the character Om, a Hindu religious symbol:
Although it is not part of the ISCII set, it can be created from the keyboard by typing the sequence of characters
The third character (ISCII E9) is a special diacritic sign called the
Nukta (which phonetically represents nasalization of the preceding vowel). ISCII defines Nukta as an operator used to derive some little-used Sanskrit characters that are not otherwise available from the keyboard, such as Om. However, Unicode includes these lesser-used characters as part of the character set (U+0950 and U+0958 through U+095F).
Although the Unicode solution is designed to adequately represent all the Indic scripts, it has not yet found widespread acceptance. A practical problem is that these scripts contain numerous clusters of two to four consonants without any intervening vowels, called
conjuncts. Conjuncts are similar to the ligatures discussed earlier, characters represented by a single glyph whose shape differs from the shapes of the constituents. Indic scripts contain far more of these, and there is a greater variation in shape. For example, the conjunct
is equivalent to the two-character combination
In this particular case, the conjunct happens to be defined as a separate code in Unicode (U+090C)—just as the ligature
fi has its own code (U+FB01). The problem is that this is not always the case. In the ISCII design,
all conjuncts are formed by placing a special character between the constituent consonants, in accordance with the design goal of a uniform representation for input of all Indic languages on a single keyboard. In Unicode, some conjuncts are given their own code—like the one above—but others are not.
Problems with the adoption of Unicode
Figure 8.9c shows the code table for a particular commercially available Devanagari font, Surekh (a member of the ISFOC family of fonts). Although there is much overlap, there is certainly not a one-to-one correspondence between the Unicode and Surekh characters, as can be seen in Figures 8.9b and c. Some conjuncts, represented by two to four Unicode codes, correspond to a single glyph that does not have a separate Unicode representation but does have a corresponding entry in the font. And in fact the converse is true: there are single glyphs in the Unicode table that are produced by generating pairs of characters. For example, the Unicode symbol
is drawn by specifying a sequence of three codes in the Surekh font.
We cannot give a more detailed explanation of why such choices have been made—it is a controversial subject, and a full discussion would require a book in itself. However, the fact is that the adoption of Unicode in India has been delayed because some people feel that it represents an uncomfortable compromise between the clear but spare design principles of ISCII and the practical requirements of actual fonts. They prefer to represent their texts in the original ISCII, because they regard it as conceptually cleaner.
The problem is compounded by the fact that today's word processors and Web browsers take a simplistic view of fonts. In reality, combination rules are required—and were foreseen by the designers of Unicode—that take a sequence of Unicode characters and produce the corresponding single glyph from Figure 8.9c. Such rules can be embodied in the “composite fonts” that were described in Section 4.5. But ligatures in English, such as
fi, have their own Unicode entry, which makes things much easier. For example, the “insert-symbol” function of word processors implements a one-to-one correspondence between Unicode codes and the glyphs on the page.
The upshot is that languages like Hindi are not properly supported by current Unicode-compliant applications. A table of glyphs, one for each Unicode value, is insufficient to depict text in Hindi script. To make matters worse, in practice some Hindi documents are represented using ISCII while others are represented using raw font codes like that of Figure 8.9c, which are specific to the particular font manufacturer. Different practices have grown up for different scripts. For example, the majority of documents in the Kannada language on the Web seem to be represented using ISCII codes, whereas in the Malayalam language, diverse font-specific codes are used. Often, to read a new Malayalam newspaper in your Web browser you have to download a new font!
To accommodate Indic documents in a digital library that represents documents internally in Unicode, it is necessary to implement several mappings:
• from ISCII to Unicode, so that ISCII documents can be incorporated;
• from various different font representations (such as ISFOC, used for the Surekh font) to Unicode, so that documents in other formats can be accommodated;
• from Unicode to various different font representations (such as ISFOC), so that the documents can be displayed on computer systems with different fonts.
The first is a simple transliteration, because Unicode was designed for round-trip compatibility. However, both of the other mappings involve translating sequences of codes in one space into corresponding sequences in the other space (although all sequences involved are very short). Figure 8.10 shows a page produced by such a scheme.

8.4. Word segmentation and sorting
Spaces are a relatively recent invention in Western languages. Although ancient Hebrew and Arabic used spaces to separate words, partly to compensate for the lack of vowels, they were not used in Latin until 600 to 800 A.D. When the Latin alphabet was adopted for English, it was written
scripta continua, without any word separators. Later
, centered dots were added to make reading easier, and subsequently the dots were replaced with spaces. Today, languages in the CJK (Chinese-Japanese-Korean) family are written without using any spaces or other word delimiters; so are the Thai, Khmer (Cambodian), and Lao languages. This introduces the need for segmentation algorithms to separate words for indexing.
Segmenting words
Finding word boundaries in the absence of spaces is a non-trivial problem, and ambiguities often arise. To help you appreciate the problem, Figure 8.11a shows two interpretations of the same Chinese characters. The text is a play on the ambiguity of phrasing. Once upon a time, the story goes, a man embarked on a long journey. Before he could return home the rainy season began, and he took shelter at a friend's house. As the rains continued he overstayed his welcome, and his friend wrote him a note: the first line in Figure 8.11a. As shown in the second line, it reads “It is raining, the god would like the guest to stay. Although the god wants you to stay, I do not!” But before taking the hint and leaving, the visitor added the punctuation shown in the third line, making three sentences whose meaning is totally different—“The rainy day, the staying day. Would you like me to stay? Sure!”
 |
 |
| Figure 8.11: |
This is an example of ambiguity related to phrasing, but ambiguity also can arise with word segmentation. Figure 8.11b shows a more prosaic example. For the ordinary sentence on the first line, there are two different interpretations, depending on the context: “I like New Zealand flowers” and “I like fresh broccoli.”
Written Chinese documents are unsegmented, and readers are accustomed to inferring the corresponding sequence of words almost unconsciously. Accordingly, machine-readable text is usually unsegmented. To render them suitable for full-text retrieval, a segmentation scheme should be used to insert word boundaries at appropriate positions prior to indexing.
One segmentation method is to use a language dictionary. Boundaries are inserted to maximize the number of the words in the text that are also present in the dictionary. Of course, there may be multiple valid segmentations, and heuristics are needed to resolve ambiguities.
Another method is based on the fact that text divided into words is more compressible than text that lacks word boundaries. You can demonstrate this with a simple experiment. Take a text file, compress it with any standard compression utility (such as gzip), and measure the compression ratio. Then remove all the spaces from the file, making it considerably smaller (about 17 percent smaller, because in English approximately one letter in six is a space). When you compress this smaller file, the compression ratio is noticeably worse than for the original file. Inserting word boundaries improves compressibility.
This fact can be used to divide text into words, based on a large corpus of hand-segmented training data. Between every two characters lies a potential space. A text compression model can be trained on presegmented text, and coupled with a search algorithm to interpolate spaces to maximize the overall compression. Section 8.5 (“Notes and sources”) at the end of this chapter points to a fuller explanation of the technique.
For non-Chinese readers, the success of the space-insertion technique can be illustrated by applying it to English. Table 8.4 shows original text at the top, complete with spaces. Below is the input to the segmentation procedure. Underneath that is the output of two segmentation schemes: one dictionary-based and the other compression-based. The training text was a substantial sample of English, although far smaller than the corpus used to produce the word dictionary.
Word-based segmentation fails badly when the words are not in the dictionary. In this case both
crocidolite and
Micronite are segmented incorrectly. In addition,
inits is treated as a single word because it occurred that way in the text from which the dictionary was created, and in cases of ambiguity the algorithm prefers longer words. The strength of the compression-based method is that it performs well on unknown words. Although
Micronite does not occur in the training corpus, it is correctly segmented. The compression-based method makes two errors, however. First, a space was not inserted into
LoewsCorp because it happens to require fewer bits to encode than
Loews Corp. Second, an extra space was added to
crocidolite because that also reduced the number of bits required.
Segmenting words in Thai/Khmer/Lao
Thai, Khmer, and Lao are other languages that do not use spaces between the words in a sentence, although they do include spaces between phrases and sentences. Unlike the CJK family, which uses ideographs, they are alphabetic languages. However, they are easier to read than English would be if spaces were omitted, because English provides fewer clues about word breaks.
In Thai, for example, there are many rules that govern where words can begin and end. Thai includes a “silence marker” called
gaaran—the little symbol that appears above the last letter in the word
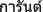 —which indicates that the letter or letters underneath are not pronounced in the usual Thai pronunciation. Here are some of the rules:
—which indicates that the letter or letters underneath are not pronounced in the usual Thai pronunciation. Here are some of the rules:
•
gaaran ends a word (except for some European loan words, such as
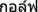 for
golf);
for
golf);
•
 ends a word (except in the rare cases when it is followed by a consonant with the
gaaran symbol, as in
ends a word (except in the rare cases when it is followed by a consonant with the
gaaran symbol, as in
 );
);
•
 ends a word;
ends a word;
• the vowels
 start a word (these are called “preposed” vowels, and are written before their accompanying consonant).
start a word (these are called “preposed” vowels, and are written before their accompanying consonant).
These rules help to determine some word boundaries, but not all. Sometimes ambiguities arise. For example, depending on how it is segmented,
means (roughly)
breath of fresh air (
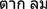 ) or
round eyes (
) or
round eyes (
 ). As with Chinese, there are several possible approaches to determining word boundaries for searching.
). As with Chinese, there are several possible approaches to determining word boundaries for searching.
Sorting Chinese text
Several different schemes underlie printed Chinese dictionaries and telephone directories. Characters can be ordered according to the number of strokes they contain; or they can be ordered according to their
radical, which is a core symbol on which they are built; or they can be ordered according to a standard alphabetical representation called Pinyin, where each ideograph is given a one- to six-letter equivalent. Stroke ordering is probably the most natural way of ordering character strings for Chinese users, although many educated people prefer Pinyin (not all Chinese people know Pinyin). This presents a problem when creating lists of Chinese text that are intended for browsing.
To help you appreciate the issues involved, Figure 8.12 shows title browsers for a large collection of Chinese documents. The rightmost button on the green access bar near the top invokes Figure 8.12a. Here, titles are ordered by the number of strokes in their first character, which is given across the top: the user has selected six. In all the titles that follow, the first character has six strokes. This is probably not obvious from the display, because you can only count the strokes in a character if you know how to write it. To illustrate this, the initial characters for the first and seventh titles are singled out and their writing sequence is superimposed on the screen shot: the first stroke, the first two strokes, the first three strokes, and so on, ending with the complete character, which is circled. All people who read Chinese know immediately how many strokes are needed to write any particular character.

There are generally more than 200 characters corresponding to a given number of strokes, almost any of which could occur as the first character of a title. Hence the titles in each group are displayed in a particular conventional order, again determined by their first character. This ordering is more complex. Each character has an associated
radical, the basic structure that underlies it. For example, the radical in the upper example singled out in Figure 8.12a (the first title) is the pattern corresponding to the initial two strokes, which in this case form the left-hand part of the character. Radicals have a conventional ordering that is well known to educated Chinese; this particular one is number 9 in the Unicode sequence. Because this character requires four more strokes than its radical, it is designated by the two-part code 9.4. In the lower example singled out in Figure 8.12a (the seventh title), the radical corresponds to the initial three strokes, which form the top part of the character, and is number 40; thus this character receives the designation 40.3. These codes are shown to the right of Figure 8.12a but would not form part of the final display.
The codes form the key on which titles are sorted. Characters are grouped first by radical number, then by how many strokes are added to the radical to make the character. Ambiguity occasionally arises: the code 86.2, for example, appears twice. In such situations, the tie is broken randomly.
Stroke-based ordering is quite complex, and Chinese readers have to work harder than we do to identify an item in an ordered list. It is easy to decide on the number of strokes, but once a page like Figure 8.12a is reached, most people simply scan it linearly. A strength of computer displays is that they can at least offer a choice of access methods.
The central navigation button of Figure 8.12a invokes the Pinyin browser in Figure 8.12b, which orders characters alphabetically by their Pinyin equivalent. The Pinyin codes for the titles are shown to the right of the figure, but again would not form part of the final display. Obviously, this arrangement is much easier for Westerners to comprehend.
8.5. Notes and sources
The design and construction of the “Niupepa” (the Māori word for “newspaper”) collection of historical New Zealand newspapers is described by Apperley et al. (2002); Apperley et al. (2001) give a synopsis. The scanning and OCR operations involved in creating this collection are discussed at the end of Section 4.2. The project was undertaken in conjunction with the Alexander Turnbull Library, a branch of the New Zealand National Library, whose staff gathered the material together and created the microfiche that was the source for the digital library collection. This work is being promoted as a valuable social and educational resource and is partially funded by the New Zealand Ministry of Education.
The collection of Tang Dynasty rubbings in Figure 8.3a was produced in conjunction with the Chinese Department of Peking University. The Chinese literature in Figure 8.3b and the Arabic collection in Figure 8.4 are small demonstrations built out of material gathered from the Web. The Chinese title browsers in Figure 8.12 are mock-ups and have not yet been implemented, although the Greenstone structure makes it easy to add new browsers like this by adding a new “classifier” module (see Part II).
The official description of Unicode is given in International Standard ISO/IEC 10646-1, Information Technology—Universal Multiple-Octet Coded Character Set (UCS)—Part 1: Architecture and Basic Multilingual Plane. Part 1 covers the values U+000000–U+10FFFF; the other values are covered by Part 2. We mentioned that the ISO standard and the Unicode Consortium differ inconsequentially over the size of the character space. Another difference is that Unicode augments its definition with functional descriptions to help programmers develop compatible software. For example, it defines an algorithm for displaying bidirectional text (Unicode Consortium, 2006). The consortium uses the Web site www.unicode.org to expedite the release of versions, revisions, and amendments to the standard.
The fact that certain characters have more than one Unicode representation, which is a consequence of demanding round-trip compatibility, has been exploited to deceive computer users about what remote system they are communicating with on the Internet in what is called the “international domain name homograph attack” (see www.opera.com/support/search/view/788).
Different scholars transcribe the Fante word for
welcome in different ways. We have chosen the version with an umlaut above the second
a to illustrate interesting text representation issues. Other common renderings are
akwāba and
akwaaba.
The material on segmenting Chinese text is from Teahan et al. (2000), while Table 8.4, giving English segmentation results, is due to Teahan (1997). Information about the word segmentation problem in Thai is from www.thai-language.com.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.