
Chapter 4. Textual documents
The raw material
Documents are the digital library's building blocks. It is time to step down from our high-level discussion of digital libraries—what they are, how they are organized, and what they look like—to nitty-gritty details of how to represent the documents they contain. To do a thorough job for international documents in non-Roman alphabets, we will have to descend even further and look at the representation of the characters that make up textual documents.
Documents are the digital library's building blocks. It is time to step down from our high-level discussion of digital libraries—what they are, how they are organized, and what they look like—to nitty-gritty details of how to represent the documents they contain. To do a thorough job for international documents in non-Roman alphabets, we will have to descend even further and look at the representation of the characters that make up textual documents.
A great practical problem anyone faces when writing about the innards of digital libraries is the high rate of change in the core technologies. Perhaps the most striking feature of the digital library field is the inherent tension between two extremes: the dizzying pace of technological change and the very long-term view that libraries must take. We must reconcile any aspirations to surf the leading edge of technology with the literally static ideal of archiving material “for ever and a day.”
Document formats are where the rubber meets the road. Over the last two decades a cornucopia of different representations have emerged. Some have become established as standards, either official or
de facto, and it is on these that we focus. There are plenty of them: the nice thing about standards, they say, is that there are so many different ones to choose from!
The standard ASCII (American Standard Code for Information Interchange) code used by computers has been extended in dozens of different and often incompatible ways to deal with other character sets. Some Web pages specify the character set explicitly. Internet Explorer recognizes over 100 different character sets, mostly extensions of ASCII and another early standard called EBCDIC, some of which have half a dozen different names. Without a unified coding scheme, search programs must know about all this to work correctly under every circumstance.
Fortunately, there is an international standard for representing characters: Unicode. It emerged over the last 20 years and is now stable and widely used—although it is still being extended and developed to cover languages and character sets of scholarly interest (e.g., archaic ones). It allows the content of digital libraries, and their user interfaces, to be internationalized. The basics of Unicode are introduced in the next section: a more comprehensive account is included in Chapter 8 on internationalization. Of course, Unicode only helps with character
representation. Language translation and cross-language searching are thorny matters of computational linguistics that lie completely outside its scope (and outside this book's scope, too).
Section 4.1 discusses the representation of plain text documents, and related issues. Even the most basic character representation, ASCII, can present ambiguities in interpretation. We also sketch how an index can be created for textual documents in order to facilitate rapid full-text searching. Before the index is created, the input must be split into words. This involves a few mundane practical decisions—and introduces deeper issues for languages that are not traditionally written with spaces between words.
Probably the single most important issue when contemplating a digital library project is whether you plan to digitize the material for the collection from ordinary books and other documents. This inevitably involves manually handling physical material, and perhaps also manual correction of computer-based text recognition. It generally represents the vast bulk of the work involved in building a digital library. Section 4.2 describes the process of digitizing textual documents, by far the most common source of digital library material. Most library builders end up outsourcing the operation to a specialist; this section alerts you to the issues you will need to consider when planning this part of the project.
The next section describes HTML, the Hypertext Markup Language, which was designed specifically to allow references, or
hyperlinks, to other files, including picture files, giving a natural way to embed illustrations in the body of an otherwise textual document
Electronic documents have two complementary aspects: structure and appearance. Structural markup makes certain aspects of the document structure explicit: section divisions, headings, subsection structure, enumerated and bulleted lists, emphasized and quoted text, footnotes, tabular material, and so on. Appearance is controlled by
presentation or
formatting markup that dictates how the document appears typographically: page size, page headers and footers, fonts, line spacing, how section headers look, where figures appear, and so on. Structure and appearance are related by the design of the document, that is, a catalog—often called a
style sheet—of how each structural item should be presented. While HTML supports this separation, it does not enforce it and, worse, given the format's chaotic beginnings it quickly became augmented with a host of other facilities that blurred this distinction.
Whatever its faults, HTML, being the foundation for the Web, is a phenomenally successful way of representing documents. However, when dealing with collections of documents, different ways of expressing formatting in HTML tend to generate inconsistencies—even though the documents may look the same. Although these inconsistencies matter little to human readers, they are a bane for automatic processing of document collections. Next we describe XML, a more modern development that is intended to solve some of the problems that arise with HTML. XML is an
extensible markup language that allows you to declare what syntactic rules govern a particular group of files. More precisely, it is referred to as a
metalanguage—a language used to define other languages. XML provides a flexible framework for describing document structure and metadata, making it ideally suited to digital libraries. It has achieved widespread use in a short period of time—reflecting a great demand for standard ways of incorporating metadata into documents—and underpins many other standards. Among these are ways of specifying style sheets that define how particular families of XML documents should appear on the screen or printed page. There is also XHTML, a recasting of this format using the stricter syntax of XML.
Style sheets have been mentioned several times. Associated with the markup languages HTML and XML are the stylesheet languages CSS (cascading style sheets) and XSL (extensible stylesheet language), and these are introduced in Section 4.4.
After thoroughly reviewing HTML and XML, we move on to more comprehensive ways of describing finished documents. Desktop publishing empowers ordinary people to create carefully designed and lavishly illustrated documents and to publish them electronically, often dispensing with print altogether. People have quickly become accustomed to reading publication-quality documents online. It is worth reflecting on the extraordinary change in our expectations of online document presentation since, say, 1990. This revolution has been fueled largely by the PostScript language and its successor, the Portable Document Format (PDF). These are both
page description languages: they combine text and graphics by treating the glyphs that comprise text as little pictures in their own right and allowing them to be described, denoted, and placed on an electronic page alongside conventional illustrations.
Page description languages portray finished documents, ones that are not intended to be edited. In contrast, word processors represent documents in ways that are expressly designed to support interactive creation and editing. Society's notion of
document has evolved from painstakingly engraved Chinese steles, literally “carved in stone,” to hand-copied medieval manuscripts; from the interminable revisions of loose-leaf computer manuals in the 1960s and 1970s to continually evolving Web sites whose pages are dynamically composed on demand from online databases, and it seems inevitable that more and more documents will be circulated in word-processor formats.
Section 4.6 describes examples of word-processor documents, starting with the ubiquitous Microsoft Word format and Rich Text Format (RTF). Word is intended to represent working documents inside a word processor. It is a proprietary format that depends on the exact version of Microsoft Word that was used and it is not always backward-compatible. RTF is more portable, being intended to transmit documents to other computers and other versions of the software. It is an open standard, defined by Microsoft, for exchanging word-processor documents between different applications.
Winds of change are sweeping through the world of document representation. XML and associated standards are beginning to be adopted for fully fledged word-processor documents. The Open Document Format (ODF) is an XML-based format that can describe word-processor documents and many more: from spreadsheets to charts, from presentations to mathematical formulae. ODF has been developed and promoted by a not-for-profit consortium called the Organization for the Advancement of Structured Information Standards, which is strongly associated with open source software, and whose mission is to drive the development and adoption of open standards for the global information society. Office Open XML (OOXML) is a similar (but, unfortunately, different) XML-based document format being developed by Microsoft to represent documents in its Office line of products. These two standards are vying to be the dominant format for describing word-processor documents, and we discuss the controversy and describe ODF in Section 4.6. We also describe the format used by the LaTeX document processing system, a system which has been around for over 20 years and is widely used to represent documents in the scientific and mathematical community.
Finally, Section 4.7 takes a brief look at other predominantly textual document formats: spreadsheets, presentation files, and e-mail.
This chapter gets down to details, the dirty details (where the devil is). You may find the level uncomfortably low. Why do you need to know all this? The answer is that when building digital libraries you will be presented with documents in many different formats, yet you will yearn for standardization. You have to understand how different formats work in order to appreciate their strengths and limitations. Examples? When converted from PDF to PostScript, documents lose interactive features like hyperlinks. Converting HTML to PostScript is easy (your browser does it every time you print a Web page), but converting an arbitrary PostScript file to HTML is next to impossible if you want a completely accurate visual replica.
Even if your project starts with paper documents, you still need to know about online formats. The optical character recognition process may produce Microsoft Word documents, retaining much of the formatting in the original and leaving illustrations and pictures
in situ. But how easy is it to extract the plain text for indexing purposes? To highlight search terms in the text? To display individual pages? Perhaps another format is preferable?
4.1. Representing Textual Documents
Way back in 1963, at the dawn of interactive computing, the American National Standards Institute (ANSI) began work on a character set that would standardize text representation across a range of computing equipment and printers. (At the time, a variety of codes were in use by different computer manufacturers, such as an extension of a
binary-coded decimal punched card code to deal with letters—EBCDIC, or Extended Binary Coded Decimal for Information Interchange—and the European Baudot code for teleprinters that accommodated mixed-case text by switching between upper- and lowercase modes.) In 1968, ANSI finally ratified the result, called ASCII: American Standard Code for Information Interchange. Until recently, ASCII dominated text representation in computing.
ASCII
Table 4.1 shows the ASCII character set, with code values in decimal, octal, and hexadecimal. Codes 65–90 (decimal) represent the uppercase letters of the Roman alphabet, while codes 97–122 are lowercase letters. Codes 48–57 give the digits zero through nine. Codes 0–32 and 127 are
control characters that have no printed form. Some of these govern physical aspects of the printer—for instance, BEL rings the bell (now downgraded to an electronic beep), BS backspaces the print head (now the cursor position). Others indicate parts of a communication protocol: SOH starts the header, STX starts the transmission. Interspersed between these blocks are sequences of punctuation and other nonletter symbols (codes 33–47, 58–64, 91–96, 123–126). Each code is represented in seven bits, which fits into a computer byte with one bit (the top one) free. In the original vision for ASCII, this was earmarked for a parity check.
ASCII was a great step forward. It helped computers evolve over the following decades from scientific number-crunchers and fixed-format card-image data processors to interactive information appliances that permeate all walks of life. However, it has proved a great source of frustration to speakers of other languages. Many different extensions have been made to the basic character set, using codes 128–255 to specify accented and non-Roman characters for particular languages. ISO 8859-1, from the International Organization for Standardization (the international counterpart of the American standards organization, ANSI), extends ASCII for Western European languages. For example, it represents
é as the single decimal value 233 rather than the ASCII sequence “
e followed by backspace followed by ´.” The latter is alien to the French way of thinking, for
é is really a single character, generated by a single keystroke on French keyboards. For non-European languages like Hebrew and Chinese, ASCII is irrelevant. For them, other schemes have arisen: for example, GB and Big-5 are competing standards for Chinese; the former is used in the People's Republic of China and the latter in Taiwan and Hong Kong.
As the Internet exploded into the World Wide Web and burst into all countries and all corners of our lives, the situation became untenable. The world needed a new way of representing text.
Unicode
In 1988, Apple and Xerox began work on Unicode, a successor to ASCII that aimed to represent all the characters used in all the world's languages. As word spread, the Unicode Consortium, a group of international and multinational companies, government organizations, and other interested parties, was formed in 1991. The result was a new standard, ISO-10646, ratified by the International Organization for Standardization in 1993. In fact, the standard melded the Unicode Consortium's specification with ISO's own work in this area.
Unicode continues to evolve. The main goal of representing the scripts of languages in use around the world has been achieved. Current work is addressing historic languages, such as Egyptian hieroglyphics and Indo-European languages, and notations like music. A steady stream of additions, clarifications, and amendments eventually lead to new published versions of the standard. Of course, backward compatibility with the existing standard is taken for granted.
A standard is sterile unless it is adopted by vendors and users. Programming languages like Java have built-in Unicode support. Earlier ones—C, Perl, Python, to name a few—have standard Unicode libraries. Today's operating systems all support Unicode, and application programs, including Web browsers, have passed on the benefits to the end user. Unicode is the default encoding for HTML and XML. People of the world, rejoice!
Unicode is universal: any document in an existing character set can be mapped into it. But it also satisfies a stronger requirement: the resulting Unicode file can be mapped back to the original character set without any loss of information. This requirement is called
round-trip compatibility with existing coding schemes, and it is central to Unicode's design. If a letter with an accent is represented as a single character in some existing character set, then an equivalent must also be placed in the Unicode set, even though there might be another way to achieve the same visual effect. Because the ISO 8859-1 character set mentioned above includes
é as a single character, it must be represented as a single Unicode character—even though an identical glyph can be generated using a sequence along the lines of “
e followed by backspace followed by ´.”
Round-trip compatibility is an attractive way to facilitate integration with existing software and was most likely motivated by the pressing need for a nascent standard to gain wide acceptance. You can safely convert any document to Unicode, knowing that it can always be converted back again if necessary to work with legacy software. This is indeed a useful property. However, multiple representations for the same character can cause complications. These issues are discussed further in Chapter 8 (Section 8.2), which gives a detailed account of the Unicode standard.
In the meantime, it is enough to know that the most popular method of representing Unicode is called UTF-8. UTF stands for “UCS Transformation Format,” which is a nested acronym: UCS is Unicode Character Set—so called because Unicode characters are “transformed” into this encoding format. UTF-8 is a variable-length encoding scheme where the basic entity is a byte. ASCII characters are automatically 1-byte UTF-8 codes; existing ASCII files are valid UTF-8.
Plain text
Unicode provides an all-encompassing form for representing characters, including manipulation, searching, storage, and transmission. Now we turn attention to document representation. The lowest common denominator for documents on computers has traditionally been plain, simple, raw ASCII text. Although there is no formal standard for this, certain conventions have grown up.
A text document comprises a sequence of character values interpreted in ordinary reading order: left to right, top to bottom. There is no header to denote the character set used. While 7-bit ASCII is the baseline, the 8-bit ISO ASCII extensions are often used, particularly for non-English text. This works well when text is processed by just one application program on a single computer, but when transferring between different applications—perhaps through e-mail, news, the Web, or file transfer—the various programs involved may make different assumptions. An alphabet mismatch often means that characters in the range 128–255 are displayed incorrectly.
Plain text documents are formatted in simple ways. Explicit line breaks are usually included. Paragraphs are separated by two consecutive line breaks, or else the first line is indented. Tabs are frequently used for indentation and alignment. A fixed-width font is assumed; tab stops usually occur at every eighth character position. Common typing conventions are adopted to represent characters like dashes (two hyphens in a row). Headings are underlined manually using rows of hyphens or equal signs. Emphasis is often indicated by surrounding text with a single underscore (_like this_), or flanking words with asterisks (*like* *this*).
Different operating systems have adopted conflicting conventions for specifying line breaks. Historically, teletypes were modeled after typewriters. The line-feed character (ASCII 10, LF in Table 4.1) moves the paper up one line but retains the position of the print head. The carriage-return character (ASCII 13, CR in Table 4.1) returns the print head to the left margin but does not move the paper. A new line is constructed by issuing
carriage return followed by
line feed (logically the reverse order could be used, but the
carriage return line feed sequence is conventional, and universally relied upon). Microsoft Windows uses this teletype-oriented interpretation. However, Unix and the Apple Macintosh adopt a different convention: the ASCII line-feed character moves to the next line
and returns the print head to the left margin. This difference in interpretation can produce a strange-looking control character at the end of every line:
∧M or “carriage return.” (Observe that
CR and
M are in the same row of Table 4.1. Control characters in the first column are often made visible by prefixing the corresponding character in the second column with
∧.) While the meaning of the message is not obscured, the effect is distracting.
People who use the standard Internet file transfer protocol (FTP) sometimes wonder why it has separate ASCII and binary modes. The difference is that in ASCII mode, new lines are correctly translated when copying files between different systems. It would be wrong to apply this transformation to binary files, however. Modern text-handling programs conceal the difference from users by automatically detecting which new-line convention is being used and behaving accordingly. Of course, this can lead to brittleness: if assumptions break down, all line breaks are messed up and users are mystified.
Plain text is a simple, straightforward, but impoverished representation of documents in a digital library. Metadata cannot be included explicitly (except, possibly, as part of the file name). However, automatic processing is sometimes used to extract title, author, date, and so on. Extraction methods rely on informal document structuring conventions. The more consistent the structure, the easier extraction becomes. Conversely, the simpler the extraction technique, the more seriously things break down when formatting quirks are encountered. Unfortunately you cannot normally expect complete consistency and accuracy in large plain text document collections.
Indexing
Rapid searching is a core function of digital libraries that distinguishes them from physical libraries. The ability to search full text adds great value when large document collections are used for study or reference. Search can be used for particular words, sets of words, or sequences of words. Obviously, it is less important in recreational reading, which normally takes place sequentially, in one pass.
Before computers, full-text searching was confined to highly valued—often sacred—works for which a concordance had already been prepared. For example, some 300,000 word appearances are indexed in Cruden's concordance of the Bible, printed on 774 pages. They are arranged alphabetically, from
Aaron to
Zuzims, and any particular word can be located quickly using binary search. Each probe into the index halves the number of potential locations for the target, and the correct page for an entry can be located by looking at no more than 10 pages—fewer if the searcher interpolates the position of an entry from the position of its initial letter in the alphabet. A term can usually be located in a few seconds, which is not bad considering that simple manual technology is being employed. Once an entry has been located, the concordance gives a list of references that the searcher can follow up. Figure 4.1 shows some of Cruden's concordance entries for the word
search.
 |
| Figure 4.1: Cruden's Complete Concordance to the Old and New Testaments by A. Cruden, C. J. Orwom, A. D. Adams, and S. A. Waters. 1941, Lutterworth Press |
In digital libraries searching is done by a computer, rather than by a person, but essentially the same techniques are used. The difference is that things happen faster. Usually it is possible to keep a list of terms in the computer's main memory, and the list can be searched in a matter of microseconds. When the computer's equivalent of the concordance entry becomes too large to store in main memory, secondary storage (usually a disk) is accessed to obtain the list of references, which typically takes a few milliseconds.
A full-text index to a document collection gives, for each word, the position of every occurrence of that word in the collection's text. A moment's reflection shows that the size of the index is commensurate with the size of the text, because an occurrence position is likely to occupy roughly the same number of bytes as a word in the text. (Four-byte integers, which are convenient in practice, are able to specify word positions in a 4-billion-word corpus. Conversely, an average English word has five or six characters and so also occupies a few bytes, the exact number depending on how it is stored and whether it is compressed.) We have implicitly assumed a word-level index, where occurrence positions give actual word locations in the collection. Space will be saved if locations are recorded within a unit, such as a paragraph, chapter, or document, yielding a coarser index—partly because pointers can be smaller, but chiefly because when a particular word occurs several times in the same unit, only one pointer is required for that unit.
A comprehensive index, capable of rapidly accessing all documents that satisfy a particular query, is a large data structure. Size, as well as being a drawback in its own right, also affects retrieval time, for the computer must read and interpret appropriate parts of the index to locate the desired information. Fortunately, there are interesting data structures and algorithms that can be applied to solve these problems. They are beyond the scope of this book, but references can be found in the “Notes and sources” section at the end of the chapter.
The basic function of a full-text index is to provide, for any particular query term, a list of all the units that contain it, along with (for reasons to be explained shortly) the number of times it occurs in each unit on the list. It's simplest to think of the “units” as being documents, although the granularity of the index may use paragraphs or chapters as the units instead—or even individual words, in which case what is returned is a list of the word numbers corresponding to the query term. And it's simplest to think of the query term as a word, although if stemming or case-folding is in effect, the term may correspond to several different words. For example, with stemming, the term
computer may correspond to the words
computer,
computers,
computation,
compute, and so on; and with case-folding it may correspond to
computer,
Computer,
COMPUTER, and even
CoMpUtEr (an unusual word, but not completely unknown—for example, it appears in this book!).
When one indexes a large text, it rapidly becomes clear that just a few common words—such as
of,
the, and
and—account for a large number of the entries in the index. People have argued that these words should be omitted, since they take up so much space and are not likely to be needed in queries, and for this reason they are often called
stop words. However, some index compilers and users have observed that it is better to leave stop words in. Although a few dozen stop words may account for around 30 percent of the references that an index contains, it is possible to represent them in a way that consumes relatively little space.
A query to a full-text retrieval system usually contains several words. How they are interpreted depends on the type of query. Two common types, both explained in Section 3.4, are
Boolean queries and
ranked queries. In either case, the process of responding to the query involves looking up, for each term, the list of documents it appears in, and performing logical operations on these lists. In the case of Boolean queries, the result is a list of documents that satisfy the query, and this list (or the first part of it) is displayed to the user.
In the case of ranked queries, the final list of documents is sorted according to the ranking heuristic that is in place. As Section 3.4 explains, these heuristics gauge the similarity of each document to the set of terms that constitute the query. For each term, they weigh the frequency with which it appears in the document being considered (the more it is mentioned, the greater the similarity) against its frequency in the document collection as a whole (common terms are less significant). This is why the index stores the number of times each word appears in each document. A great many documents—perhaps all documents in the collection—may satisfy a particular ranked query (if the query contains the word
the, all English documents would probably qualify). Retrieval systems take great pains to work efficiently even on such queries; for example, they use techniques that avoid the need to sort the list fully in order to find the top few elements.
In effect, the indexing process treats each document (or whatever the unit of granularity is) as a “bag of words.” What matters is the words that appear in the document and (for ranked queries) the frequency with which they appear. The query is also treated as a bag of words. This representation provides the foundation for full-text indexing. Whenever documents are presented in forms other than word-delineated plain text, they must be reduced to this form so that the corresponding bag of words can be determined.
Word segmentation
Before an index is created, the text must first be divided into words. A word is a sequence of alphanumeric characters surrounded by white space or punctuation. Usually some large limit is placed on the length of words—perhaps 16 characters, or 256 characters. Another practical rule of thumb is to limit numbers that appear in the text to a far smaller size—perhaps four numeric characters, so that only numbers less than 9,999 are indexed. Without this restriction, the size of the vocabulary might be artificially inflated—for example, a long document with numbered paragraphs could contain hundreds of thousands of different integers—which negatively affects certain technical aspects of the indexing procedure. Years, however, which have four digits, should be preserved as single words.
In some languages, plain text presents special problems. Languages like Chinese and Japanese are written without any spaces or other word delimiters (except for punctuation marks). This causes obvious problems in full-text indexing: to get a bag of words, we must be able to identify the words. One possibility is to treat each character as an individual word. However, this produces poor retrieval results. An extreme analogy is an English-language retrieval system that, instead of finding all documents containing the words
digital library, found all documents containing the constituent letters
a b d g i l r t y. Of course the searcher will receive all sought-after documents, but they are diluted with countless others. And ranking would be based on letter frequencies, not word frequencies. The situation in Chinese is not so bad, for individual characters are far more numerous, and more meaningful, than individual letters in English. But they are less meaningful than words. Chapter 8 discusses the problem of segmenting such languages into words.
4.2. Textual Images
Plain text documents in digital libraries are often produced by digitizing paper documents. Digitization is the process of taking traditional library materials, typically in the form of books and papers, and converting them to electronic form, which can be stored and manipulated by a computer. Digitizing a large collection is a time-consuming and expensive process that should not be undertaken lightly.
Digitizing proceeds in two stages, illustrated in Figure 4.2. The first stage produces a digitized image of each page using a process known as
scanning. The second stage produces a digital representation of the textual content of the pages using optical character recognition (OCR). In many digital library systems, what is presented to library readers is the result of the scanning stage: page images, electronically delivered. The OCR stage is necessary if a full-text index is to be built that will allow searchers to locate any combination of words, or if any automatic metadata extraction technique is contemplated, such as identifying document titles by seeking them in the text. Sometimes the second stage is omitted, but full-text search is then impossible, which negates a prime advantage of digital libraries.
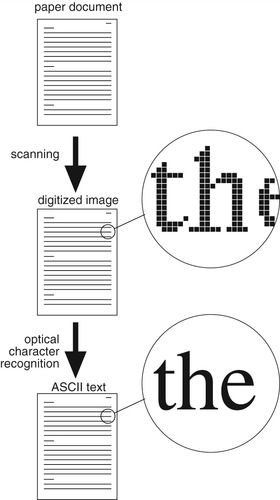
If, as is usually the case, OCR is undertaken, the result can be used as an alternative way of displaying the page contents. The display will be more attractive if the OCR system not only is able to interpret the text in the page image, but also can retain the page layout as well. Whether it is a good idea to display OCR output depends on how well the page content and format are captured by the OCR process, among other things.
Scanning
The result of the first stage, scanning, is a digitized image of each page. The image resembles a digital photograph, although its picture elements or
pixels may be either black or white—whereas photos have pixels that come in color, or at least in different shades of gray. Text is well represented in black and white, but if the image includes nontextual material, such as pictures, or exhibits artifacts like coffee stains or creases, grayscale or color images will resemble the original pages more closely. Image digitization is discussed more fully in the next chapter.
When scanning page images you need to decide whether to use black-and-white, grayscale, or color, and you also need to determine the resolution of the digitized images—that is, the number of pixels per linear unit. A familiar example of black-and-white image resolution is the ubiquitous laser printer, which generally prints 600–1200 dots per inch. Table 4.2 shows the resolution of several common imaging devices.
The number of bits used to represent each pixel also helps to determine image quality. Most printing devices are black and white: one bit is allocated to each pixel. When putting ink on paper, this representation is natural—a pixel is either inked or not. However, display technology is more flexible, and computer screens allow several bits per pixel. Color displays range up to 24 bits per pixel, encoded as 8 bits for each of the colors red, green, and blue, or even 32 bits per pixel, encoded in a way that separates the chromatic, or color, information from the achromatic, or brightness, information. Color scanners can be used to capture images having more than 1 bit per pixel.
More bits per pixel can compensate for a lack of linear resolution and vice versa. Research on human perception has shown that if a dot is small enough, its brightness and size are interchangeable—that is, a small bright dot cannot be distinguished from a larger, dimmer one. The critical size below which this phenomenon takes effect depends on the contrast between dots and their background, but corresponds roughly to a very low-resolution (640 × 480) display at normal viewing levels and distances.
When digitizing documents for a digital library, think about what you want the user to be able to see. How closely does it need to resemble the original document pages? Are you concerned about preserving artifacts? What about pictures in the text? Will users see one page on the screen at a time? Will they want to magnify the images?
You will need to obtain scanned versions of several sample pages, chosen to cover the kinds and quality of images in the collection, and digitized to a range of different qualities (e.g., different resolutions, different gray levels, and color versus monochrome). You should conduct trials with end users of the digital library to determine what qualities are necessary for actual use.
It is always tempting to say that quality should be as high as it possibly can be. But there is a cost: the downside of accurate representation is increased storage space on the computer and—probably more importantly—increased time required for page access by users, particularly remote users. Doubling the linear resolution quadruples the number of pixels, and although this increase is ameliorated by compression techniques, users still pay a toll in access time. Your trials should take place on typical computer configurations using typical communications facilities, so that you can assess the effect of download time as well as image quality. You might also consider generating thumbnail images, or images at several different resolutions, or using a “progressive refinement” form of image transmission (see Section 5.3), so that users who need high-quality pictures can be sure they’ve got the right one before embarking on a lengthy download.
Optical character recognition
The second stage of digitizing library material is to transform the scanned image into a digitized representation of the page
content—in other words, a character-by-character representation rather than a pixel-by-pixel one. This is known as
optical character recognition (OCR). Although the OCR process itself can be entirely automatic, subsequent manual cleanup is invariably necessary and is usually the most expensive and time-consuming operation involved in creating a digital library from printed material. OCR might be characterized as taking “dumb” page images that are nothing more than images and producing “smart” electronic text that can be searched and processed in many different ways.
As a rule of thumb, a resolution of 300 dpi is needed to support OCR of regular fonts (10-point or greater), and 400 to 600 dpi for smaller fonts (9-point or less). Many OCR programs can tune the brightness of grayscale images appropriately for the text being recognized, so grayscale scanning tends to yield better results than black-and-white scanning. However, black-and-white images generate much smaller files than grayscale ones.
Not surprisingly, the quality of the output of an OCR program depends critically on the quality of the input. With clear, well-printed English, on clean pages, in ordinary fonts, digitized to an adequate resolution, laid out on the page in the normal way, with no tables, images, or other nontextual material, a leading OCR engine is likely to be 99.9 percent accurate or above—say 1 to 4 errors per 2,000 characters, which is a little under a page of this book. Accuracy continues to increase, albeit slowly, as technology improves. Replicating the exact format of the original image is more difficult, although for simple pages an excellent approximation will be achieved.
Unfortunately, the OCR operation is rarely presented with favorable conditions. Problems occur with proper names, with foreign names and words, and with special terminology—like Latin names for biological species. Problems are incurred with strange fonts, and particularly with alphabets that have accents or diacritical marks, or non-Roman characters. Problems are generated by all kinds of mathematics, by small type or smudgy print, and by overly dark characters that have smeared or bled together or overly light ones whose characters have broken up. OCR has problems with tightly packed or loosely set text where, to justify the margins, character and word spacing diverge widely from the norm. Hand annotation interferes with print, as does water-staining, or extraneous marks like coffee stains or squashed insects. Multiple columns, particularly when set close together, are difficult. Other problems are caused by any kind of pictures or images—particularly ones that contain some text; by tables, footnotes, and other floating material; by unusual page layouts; and by text in the image that is skewed, or lines of text that are bowed from the attempt to place book pages flat on the scanner platen, or by the book's binding if it interferes with the scanned text. These problems may sound arcane, but almost all OCR projects encounter them.
The highest and most expensive level of accuracy attainable from commercial service bureaus is typically 99.995 percent, or 1 error in 20,000 characters of text (approximately six pages of this book). Such a level is often most easily achieved by having the text retyped manually rather than by having it processed automatically by OCR. Each page is processed twice, by different operators, and the results are compared automatically. Any discrepancies are resolved manually.
As a rule of thumb, OCR becomes less efficient than manual keying when its accuracy rate drops below 95 percent. Moreover, once the initial OCR pass is complete, costs tend to double with each halving of the accuracy rate. However, in a large digitization project, errors are usually non-uniformly distributed over pages: often 80 percent of errors come from 20 percent of the page images. It may be worthwhile to have the worst of the pages manually keyed and to perform OCR on the remainder.
Human intervention is often valuable for cleaning up both the image before OCR and, afterward, the text produced by OCR. The actual recognition part can be time-consuming—maybe one or two minutes per page—and it is useful to perform interactive preprocessing for a batch of pages, have them recognized offline, and return them to the batch for interactive cleanup. Careful attention to such practical details can make a great deal of difference in a large-scale project.
Interactive OCR involves six steps: image acquisition, cleanup, page analysis, recognition, checking, and saving.
Acquisition, cleanup, and page analysis
Images are acquired either by inputting them from a document scanner or by reading a file that contains predigitized images. In the former case, the document is placed on the scanner platen and the program produces a digitized image. Most digitization software can communicate with a wide variety of image acquisition devices. An OCR program may be able to scan a batch of several pages and let you work interactively on the other steps afterward. This is particularly useful if you have an automatic document feeder.
The cleanup stage applies image-processing operations to the image. For example, a despeckle filter cleans up isolated pixels or “pepper and salt” noise. It may be necessary to rotate the image by 90 or 180 degrees, or to automatically calculate a skew angle and deskew the image by rotating it back by that angle. Images may be converted from white-on-black to the standard black-on-white representation, and double-page spreads may be converted to single-image pages. These operations may be invoked manually or automatically. If you don't want to recognize certain parts of the image, or if it contains large artifacts—such as photocopied parts of the document's binding—you may need to remove them manually by selecting the unwanted area and clearing it.
The page analysis stage examines the layout of the page and determines which parts to process and in what order. Again, page analysis can be either manual or automatic. The result divides the page into blocks of different types, typically text blocks, which will be interpreted as ordinary running text, table blocks, which will be further processed to analyze the layout before reading each table cell, and picture blocks, which will be ignored in the character recognition stage. During page analysis, multicolumn text layouts are detected and are sorted into correct reading order.
Figure 4.3a shows an example of a scanned document with regions that contain different types of data: text, two graphics, and a photographic image. In Figure 4.3b, bounding boxes have been drawn (manually in this case) around these regions. This particular layout is interesting because it contains a region—the large text block halfway down the left-hand column—that is clearly nonrectangular, and another region—the halftone photograph—that is tilted. Because layouts like this present significant challenges to automatic page analysis algorithms, many interactive OCR systems show users the result of automatic page analysis and offer the option of manually overriding it.
 |
 |
| Figure 4.3: (a) Document image containing different types of data; (b) the document image segmented into different regions. Copyright © 1992 Canadian Artificial Intelligence Magazine |
It is also useful to be able to manually set up a template that applies to a whole batch of pages. For example, you might define header and footer regions, and specify that each page contains a double column of text—perhaps even give the bounding boxes of the columns. Perhaps the page analysis process can be circumvented by specifying in advance that all pages contain single-column running text, without headers, footers, pictures, or tables. Finally, although word spacing is usually ignored, in some cases spaces may be significant—as in formatted computer programs.
Tables are particularly difficult for page analysis. For each table, the user may be able to specify interactively such things as whether the table has one line per entry or contains multiline cells, and whether the number of columns is the same throughout or some rows contain merged cells. As a last resort, it may be necessary for the user to specify every row and column manually.
Recognition
The recognition stage reads the characters on the page. This is the actual “OCR” part. One parameter that may need to be specified is the typeface (e.g., regular typeset text, fixed-width typewriter print, or dot-matrix characters). Another is the alphabet or character set, which is determined by the language used. Most OCR packages deal with only the Roman alphabet, although some accept Cyrillic, Greek, and Czech as well. Recognition of Arabic text, the various Indian scripts, or ideographic languages like Chinese and Korean calls for specialist software.
Furthermore, character-set variations occur even within the Roman alphabet. While English speakers are accustomed to the 26-letter alphabet, many languages do not employ all the letters—Māori, for example, uses only 15. Documents in German include an additional character, ß or
scharfes s, which is unique because, unlike all other German letters, it exists only in lowercase. (A recent change in the official definition of the German language has replaced some, but not all, occurrences of ß by
ss.) European languages use accents: the German umlaut (
ü); the French acute (
é), grave (
à), circumflex (
ô), and cedilla (
ç); the Spanish tilde (
ñ). Documents may, of course, be multilingual.
For certain document types it may help to create a new “language” to restrict the characters that can be recognized. For example, a particular set of documents may be all in uppercase, or consist of nothing but numbers and associated punctuation.
In some OCR systems, the recognition engine can be trained to attune it to the peculiarities of the documents being read. Training may be helpful if the text includes decorative fonts or special characters like mathematical symbols. It may also be useful for recognition of large batches of text (100 pages or more) in which the print quality is low.
For example, the letters in some particular character sequences may have bled or smudged together on the page so that they cannot be separated by the OCR system's segmentation mechanism. In typographical parlance they form a
ligature: a combination of two or three characters set as a single glyph—such as
fi,
fl, and
ffl in the font in which this book is printed. Although OCR systems recognize standard ligatures as a matter of course, printing occasionally contains unusual ligatures, as when particular sequences of two or three characters are systematically joined together. In these cases it may be helpful to train the system to recognize each combination as a single unit.
Training is accomplished by making the system process a page or two of text in a special training mode. When unrecognized characters are encountered, the user can enter them as new patterns. It may first be necessary to adjust the bounding box to include the whole pattern and exclude extraneous fragments of other characters. Recognition accuracy will improve if several examples of each pattern are supplied. When naming the pattern, its font properties (italic, bold, small capitals, subscript, superscript) may need to be specified along with the actual characters that comprise the pattern.
There is a limit to the amount of extra accuracy that training can achieve. OCR still does not perform well with more stylized typefaces, such as Gothic, that are significantly different from modern ones—and training may not help much.
Obviously, better results can be obtained if a language dictionary is used. It is far easier to distinguish letters like
o,
0,
O, and
Q in the context of the words in which they occur. Most OCR systems include predefined dictionaries and are able to use domain-specific ones containing technical terms, common names, abbreviations, product codes, and the like. Particular words may be constrained to particular styles of capitalization. Regular words may appear with or without an initial capital letter and may also be written in all capitals. Proper names must begin with a capital letter (and may be written in all capitals too). Some acronyms are always capitalized, while others may be capitalized in fixed but arbitrary ways.
Just as the language determines the basic alphabet, it may also preclude many letter combinations. Such information can greatly constrain the recognition process, and some OCR systems let users provide it.
Checking and saving
The next stage of OCR is manual checking. The output is displayed on the screen, with problems highlighted in color. One color may be reserved for unrecognized and uncertainly recognized characters, another for words that do not appear in the dictionary. Different display options can suppress some of this information. The original image is displayed too, perhaps with an auxiliary magnification window that zooms in on the region in question. An interactive dialog, similar to the spell-check mode of word processors, focuses on each error and allows the user to ignore this instance, ignore all instances, correct the word, or add it to the dictionary. Other options allow users to ignore words with digits and other nonalphabetic characters, ignore capitalization mismatches, normalize spacing around punctuation marks, and so on.
You may also want to edit the format of the recognized document, including font type, font size, character properties like italics and bold, margins, indentation, table operations, and so on. Ideally, general word-processor options will be offered within the OCR package, to save having to alternate between the OCR program and a word processor.
The final stage is to save the OCR result, usually to a file (alternatives include copying it to the clipboard or sending it by e-mail). Supported formats might include plain text, HTML, RTF, Microsoft Word, and PDF. There are many possible options. You may want to remove all formatting information before saving, or include the “uncertain character” highlighting in the saved document, or include pictures in the document. Other options control page size, font inclusion, and picture resolution. In addition, it may be necessary to save the original page image as well as the OCR text. In PDF format (described in Section 4.5), you can save the text and pictures only, or save the text under (or over) the page image, where the entire image is saved as a picture and the recognized text is superimposed upon it, or hidden underneath it. This hybrid format has the advantage of faithfully replicating the look of the original document—which can have useful legal implications. It also reduces the requirement for super-accurate OCR. Alternatively, you might want to save the output in a way that is basically textual, but with the image form substituted for the text of uncertainly recognized words.
Page handling
Let us return to the process of scanning the page images and consider some practical issues. Physically handling the pages is easiest if you can “disbind” the documents by cutting off their bindings (obviously, this destroys the source material and is only possible when spare copies exist). At the other extreme, originals cans be unique and fragile, and specialist handling is essential to prevent their destruction. For example, most books produced between 1850 and 1950 were printed on acid paper (paper made from wood pulp generated by an acidic process), and their life span is measured in decades—far shorter than earlier or later books. Toward the end of their lifetime they decay and begin to fall apart (see Chapter 9).
Sometimes the source material has already been collected on microfiche or microfilm, and the expense of manual paper handling can be avoided. Although microfilm cameras are capable of very high resolution, quality is compromised because an additional generation of reproduction is interposed; furthermore, the original microfilming may not have been done carefully enough to permit digitized images of sufficiently high quality for OCR. Even if the source material is not already in this form, microfilming may be the most effective and least damaging means of preparing content for digitization. It capitalizes on substantial institutional and vendor expertise, and as a side benefit the microfilm masters provide a stable long-term preservation format.
Generally the two most expensive parts of the whole process are handling the source material on paper, and the manual interactive processes of OCR. A balance must be struck. Perhaps it is worth the extra generation of reproduction that microfilm involves to reduce paper handling, at the expense of more labor-intensive OCR; perhaps not.
Microfiche is more difficult to work with than microfilm, because it is harder to reposition automatically from one page to the next. Moreover, it is often produced from an initial microfilm, in which case one generation of reproduction can be eliminated by digitizing directly from the film.
Image digitization may involve other manual processes apart from paper handling. Best results may be obtained by manually adjusting settings like contrast and lighting individually for each page or group of pages. The images may have to be manually deskewed. In some cases, pictures and illustrations will need to be copied from the digitized images and pasted into other files.
Planning an image digitization project
Any significant image digitization project will normally be outsourced. The cost varies greatly with the size of the job and the desired quality. For a small simple job, with material in a form that can easily be handled (e.g., books whose bindings can be removed), text that is clear and problem-free, and with few images and tables that need to be handled manually, you could expect to pay
• 50¢/page for fully automated OCR processing
• $1.25/page for 99.9 percent quality (3 incorrect characters per page)
• $2/page for 99.95 percent quality (1.5 incorrect characters per page)
• $4/page for 99.995 percent quality (1 incorrect character every 6 pages)
for scanning and OCR, with a discount for large quantities. If difficulties arise, costs increase to many dollars per page. Using a third-party service bureau eliminates the need for you to become an expert in state-of-the-art image digitization and OCR. However, you will need to set standards for the project and to ensure that they are adhered to.
Most of the factors that affect digitization can be evaluated only by practical tests. You should arrange for samples to be scanned and OCR'd by competing companies and then compare the results. For practical reasons (because it is expensive or infeasible to ship valuable source materials around), the scanning and OCR stages may be contracted out separately. Once scanned, images can be transmitted electronically to potential OCR vendors for evaluation. You should probably obtain several different scanned samples—at different resolutions, different numbers of gray levels, from different sources, such as microfilm and paper—to give OCR vendors a range of different conditions. You should select sample images that span the range of challenges that your material presents.
Quality control is clearly a central concern in any image digitization project. An obvious quality-control approach is to load the images into your system as soon as they arrive from the vendor and to check them for acceptable clarity and skew. Images that are rejected are returned to the vendor for rescanning. However, this strategy is time-consuming and may not provide sufficiently timely feedback to allow the vendor to correct systematic problems. It may be more effective to decouple yourself from the vendor by batching the work. Quality can then be controlled on a batch-by-batch basis, where you review a statistically determined sample of the images and accept or reject whole batches.
Inside an OCR shop
Because it's labor-intensive, OCR work is often outsourced to developing countries like India, the Philippines, and Romania. Ten years ago, one of the authors visited an OCR shop in a small two-room unit on the ground floor of a high-rise building in a country town in Romania. It contained about a dozen terminals, and every day from 7:00 am through 10:30 pm the terminals were occupied by operators who were clearly working with intense concentration. There were two shifts a day, with about a dozen people in each shift and two supervisors—25 employees in all.
Most of the workers were university students who were delighted to have this kind of employment—it compared well with the alternatives available in their town. Pay was by results, not by the hour—and this was quite evident as soon as you walked into the shop and saw how hard people worked. They regarded their shift at the terminal as an opportunity to earn money, and they made the most of it.
This firm uses two different commercial OCR programs. One is better for processing good copy, has a nicer user interface, and makes it easy to create and modify custom dictionaries. The other is preferred for tables and forms; it has a larger character set with many unusual alphabets (e.g., Cyrillic). The firm does not necessarily use the latest version of these programs; sometimes earlier versions have special advantages.
The principal output formats are Microsoft Word and HTML. Again, the latest release of Word is not necessarily the one that is used. A standalone program is used for converting Word documents to HTML because it greatly outperforms Word's built-in facility. The people in the firm are expert at decompiling software and patching it. For example, they were able to fix some errors in the conversion program that affected how nonstandard character sets are handled. Most HTML is edited by hand, although they use a WYSIWYG (What You See Is What You Get) HTML editor for some of the work.
A large part of the work involves writing scripts or macros to perform tasks semiautomatically. Extensive use is made of Visual Basic for Applications (VBA). Although Photoshop is used for image work, they also employ a scriptable image processor for repetitive operations. MySQL, an open-source SQL implementation, is used for forms databases. Java is used for animation and for implementing Web-based questionnaires.
These people have a wealth of detailed knowledge about the operation of different versions of the software packages they use, and they constantly review and reassess the situation as new releases emerge. But perhaps their chief asset is their set of in-house procedures for dividing up work, monitoring its progress, and checking the quality of the result. They claim an accuracy of around 99.99 percent for characters, or 99.95 percent for words—an error rate of 1 word in 2,000. This is achieved by processing every document twice, with different operators, and comparing the result. In 1999, their throughput was around 50,000 pages/month, although the firm's capability is flexible and can be expanded rapidly on demand. Basic charges for ordinary work are around $1 per page (give or take a factor of two), but vary greatly depending on the difficulty of the job.
An example project
The New Zealand Digital Library undertook a project to put a collection of historical New Zealand Māori newspapers on the Web, in fully indexed and searchable form. There were about 20,000 original images, most of them double-page spreads. Figure 4.4 shows a sample image, an enlarged version of the beginning, and some of the text captured using OCR. The particular image shown was difficult to work with because some areas are smudged by water-staining. Fortunately, not all the images were so poor. As you can see by attempting to decipher it yourself, high accuracy requires a good knowledge of the language in which the document is written.


The first task was to scan the images into digital form. Gathering together paper copies of the newspapers would have been a massive undertaking, since the collection comprises 40 different newspaper titles that are held in a number of libraries and collections scattered throughout the country. Fortunately, New Zealand's national archive library had previously produced a microfiche containing all the newspapers for the purposes of historical research. The library provided us with access not just to the microfiche result, but also to the original 35-mm film master from which it had been produced. This simultaneously reduced the cost of scanning and eliminated one generation of reproduction. The photographic images were of excellent quality because they had been produced specifically to provide microfiche access to the newspapers.
Once the image source has been settled on, the quality of scanning depends on the scanning resolution and the number of gray levels or colors. These factors also determine how much storage is required for the information. After some testing, it was determined that a resolution of approximately 300 dpi on the original printed newspaper was adequate for the OCR process. Higher resolutions yielded no noticeable improvement in recognition accuracy. OCR results from a good black-and-white image were found to be as accurate as those from a grayscale one. Adapting the threshold to each image, or each batch of images, produced a black-and-white image of sufficient quality for the OCR work. However, grayscale images were often more satisfactory and pleasing for the human reader.
Following these tests, the entire collection was scanned by a commercial organization. Because the images were supplied on 35-mm film, the scanning could be automated and proceeded reasonably quickly. Both black-and-white and grayscale images were generated at the same time to save costs, although it was still not clear whether both forms would be used. The black-and-white images for the entire collection were returned on eight CD-ROMs; the grayscale images occupied 90 CD-ROMs.
Once the images had been scanned, the OCR process began. First attempts used Omnipage, a widely used proprietary OCR package. But a problem quickly arose: the Omnipage software is language-based and insists on utilizing one of its known languages to assist the recognition process. Because the source material was in the Māori language, additional errors were introduced when the text was automatically “corrected” to more closely resemble English. Although other language versions of the software were available, Māori was not among them, and it proved impossible to disable the language-dependent correction mechanism. In previous versions of Omnipage one can subvert the language-dependent correction by simply deleting the dictionary file (and the Romanian organization described above used an obsolete version for precisely this reason.) The result was that recognition accuracies of not much more than 95 percent were achieved at the character level. This meant a high incidence of word errors in a single newspaper page, and manual correction of the Māori text proved extremely time-consuming.
A number of alternative software packages and services were considered. For example, a U.S. firm offered an effective software package for around $10,000 and demonstrated its use on some sample pages with impressive results. The same firm offers a bureau service and was prepared to undertake the basic OCR for only $0.16 per page (plus a $500 setup fee). Unfortunately, this did not include verification, which had been identified as the most critical and time-consuming part of the process—partly because of the Māori language material.
Eventually, we located an inexpensive software package that had high accuracy and allowed for the provision of a tailor-made language dictionary. It was decided that the OCR process would be done in house, and this proved to be an excellent decision; however, it is heavily conditioned on the unusual language in which the collection is written and the local availability of fluent Māori speakers.
A parallel task to OCR was to segment the double-page spreads into single pages for the purposes of display, in some cases correcting for skew and page-border artifacts. Software was produced for segmentation and skew detection, and a semiautomated procedure was used to display segmented and deskewed pages for approval by a human operator. The result of these labors, turned in to a digital library, is described in Section 8.1.
4.3. Web Documents: HTML and XML
HTML, the Hypertext Markup Language, is the underlying document format of the World Wide Web, which makes it an important baseline for interactive viewing. Like all major, long-standing document formats, HTML has undergone growing pains, and its history reflects the anarchy that has characterized the Web's evolution. Since HTML's conception in 1989, its development has been largely driven by software vendors who compete for the Web browser market by inventing new features to make their product distinctive—the so called “browser wars.”
Many of the introduced features played on people's desires to exert more control over how their documents appear. Who gets to control font attributes like typeface and size—writer or reader? If you think this is a trivial issue, imagine what it means for the visually disabled. Allowing authors to dictate details of how their documents appear conflicts sharply with the original vision for HTML, which divorced document structure from presentation and left decisions about rendering documents to the browser itself. It makes the pages less predictable because viewing platforms differ in the support they provide. For example, HTML text can be marked up as “emphasized,” and while it is common practice to render such items in italics, there is no requirement to follow this convention: boldface would convey the same intention.
Out of the maelstrom, a series of HTML standards has emerged, although HTML's evolution continues—indeed, a major new revision, HTML 5, is under development although the warring parties (with vested interests) still clash: on this occasion a key controversy centers on whether or not native support for patent-free audio and video formats should be included in the standard.
The birth of HTML did not occur in a vacuum. Dipping further back in time, during the 1970s and 1980s, a generalized system for structural markup was developed called the Standard Generalized Markup Language (SGML); it was ratified as an ISO international standard in 1986. SGML is not a markup language but a metalanguage for describing markup formats. The original HTML format was expressed using SGML, and large organizations like government offices and the military also made significant use of it; however, SGML is rather intricate, and it has proven difficult to develop flexible software tools for the fully blown standard. This fact was the catalyst for the
extensible markup language, XML.
XML is a simplified version of SGML designed specifically for interoperability over the Web. Informally speaking, it is a dialect of SGML (whereas HTML is an example of a markup language that SGML can describe). XML provides a flexible way of characterizing document structure and metadata, making it well suited to digital libraries. It has achieved widespread use in a very short stretch of time.
XML has strict syntactic rules that prevent it from describing ancient forms of HTML exactly. The differences expose parts of the early specifications that were loosely formed—ones that cause difficulty when parsing and processing documents. However, with a little trickery—for example, judicious placement of white space—it is possible to generate an XML specification of an extremely close approximation to HTML. Put another way, you can take advantage of HTML's sloppy specification to produce files that are valid XML. Such files have twin virtues: they can be viewed in any Web browser, and they can be parsed and processed by XML tools. The idea is formalized in HTML 5, which includes parallel specifications: one for “classic” HTML and another, XHTML, which is XML-compliant.
We start this section by describing the development of markup languages and their relation to stylesheet languages. Then we describe the basics of HTML and explain how it can be used in a digital library. Following that, we describe the XML metalanguage and again discuss its role in digital libraries. Section 4.4 covers stylesheet languages for both HTML and XML.
Markup and stylesheet languages
Web culture has advanced at an extraordinary pace, creating a melee of incremental—and at times conflicting—additions and revisions to HTML, XML, and related standards. Figure 4.5 summarizes the main developments.

Although it has been retrospectively fitted with XML descriptions, HTML was created before XML was conceived and drew on the more general expressive capabilities of SGML. It was also forged in the heat of the browser wars, in which Web browsers sprouted a proliferation of innovative nonstandard features that vendors thought would make their products more appealing. As a result, browsers became forgiving: they process files that flagrantly violate SGML syntax. One example is tag scope overlap—writing <
i>
one <
b>
two </
i>
three </
b> to produce
one
twothree—despite SGML's requirement that tags be strictly nested. During subsequent attempts at standardization, more tags were added that control typeface and layout, features deliberately excluded from HTML's original design.
The notion of
style sheets was introduced to resolve the conflict between presentation and structure by moving formatting and layout specifications to a separate file. Style sheets purify the HTML markup to reflect, once again, nothing but document structure. Different documents can share a uniform appearance by adopting the same style sheet. Equally, different style sheets can be associated with the same document, for instance defining one for on-screen viewing and another for printing Style sheets can specify a sequence—a cascade—of inherited stylistic properties and are dubbed
cascading style sheets.
The first specification of cascading style sheets was in 1996, and this was quickly followed by an expanded backward-compatible version two years later. Style sheets can be adapted to different media by including formatting commands that are grouped together and associated with a given medium—screen, print, projector, handheld device, and so on. Guided by the user (or otherwise), applications that process the document use the relevant set of style commands. A Web browser might choose
screen for online display but switch to
print when rendering the document in PostScript.
Modern versions of HTML promote the use of style sheets. Moreover, they encourage them by officially deprecating formatting tags and other elements that affect presentation rather than structure. This is accomplished through three subcategories to the standard.
Strict HTML expresses layout exclusively through style sheets: frameset commands and all deprecated tags and elements listed in the standard are excluded. In
transitional HTML, style sheets are the principal way of specifying layout, but to provide compatibility with older browsers deprecated commands are permitted, although framesets are prohibited.
Frameset HTML permits frameset commands and deprecated elements. Modern HTML files declare their subcategory at the start of the document. The format also adds improved support for multidirectional text (not just left to right) and enhancements for improved access by people with disabilities.
An HTML subset called XHTML has been defined that obeys the stricter syntactic rules imposed by the XML metalanguage. For instance, tags in XML are case sensitive, so XHTML tags and attributes are defined to be lowercase. Attributes within a tag must be enclosed in quotes. Each opening tag must be balanced by a corresponding closing one (there are also single tags that combine opening and closing, with their own special syntax).
The power and flexibility of XML are further increased by related standards. Three are given in Figure 4.5 (there are many others). The
extensible stylesheet language XSL described in Section 4.4 represents a more sophisticated approach than cascading style sheets: it can also transform data. The
XML linking language XLink provides a more powerful method for connecting resources than HTML hyperlinks: it has bidirectional links, can link more than two entities, and associates metadata with links. Finally, XML Schema provides a rich mechanism for combining components and controlling the overall structure, attributes, and data types used in a document.
From a technical standpoint, it is easier to work with XML and its siblings than HTML because they conform to a strictly defined syntax and are therefore easier to parse. In reality, however, digital libraries have to handle legacy material gracefully. Today's browsers cope remarkably well with the wide range of HTML files: they take backward compatibility to truly impressive levels. To help promote standardization, an open source software utility called HTML Tidy has been developed that converts older formats. The process is largely automatic, but human intervention may be required if files deviate radically from recognized norms.
Basic HTML
Modern markup languages use words enclosed in angle brackets as tags to annotate text. For example, <
title>
A really exciting story</
title> defines the title element of an HTML document. In HTML, tag names are case insensitive—<
Title> is the same as <
title>. For each tag, the language defines a “closing” version, which gives the tag name preceded by a slash character (/). However, closing tags can be omitted in certain situations—a practice that some decry as impure while others endorse as legitimate shorthand. For example, <
p> is used to mark up paragraphs, and subsequent <
p>s are assumed to automatically end the previous paragraph—no intervening </
p> is necessary. The shortcut is possible because nesting a paragraph within a paragraph—the only other plausible interpretation on encountering the second <
p>—is invalid in HTML.
Opening tags can include a list of qualifiers known as
attributes. These have the form
name="value". For example, <
img src="gsdl.gif" width="537" height="17"> specifies an image with source file name
gsdl.gif and dimensions 537 × 17 pixels.
Because the language uses characters such as <, >, and " as special markers, a way is needed to display these characters literally. In HTML these characters are represented as special forms called
entities and given names like &
lt; for “less than” (<) and &
gt; for “greater than” (>). This convention makes ampersand (&) into a special character, which is displayed by &
amp; when it appears literally in documents. The semicolon needs no such treatment because its literal use and its use as a terminator are syntactically distinct. The same kind of special form can be used to specify Unicode characters beyond the ASCII range, such as &
egrave; for
è.
Figure 4.6 shows a sample page that illustrates several parts of HTML, along with a snapshot of how it is rendered by a Web browser. It contains “typical” code that you find on the Web, rather than exemplary HTML. Some attributes miss out double quotes (such as
align and
valign used in some of the table elements), and not all the elements stipulate all the attributes they should (e.g., two of the <
img> tags are missing their
alt attribute through which an alternative text description is given). The example would not even pass the test for transitional HTML, let alone strict HTML; however, as Figure 4.6b shows, the Web browser renders it just fine.
 |
 |
| Figure 4.6: |
HTML documents are divided into a header and a body. The header gives global information: the title of the document, the character encoding scheme, any metadata. The <
meta> tag is used in Figure 4.6a to acknowledge the New Zealand Digital Library Project as the document's creator.
Creator imitates the Dublin Core metadata element (see Section 6.2) that is used to represent the name of the entity responsible for generating a document, be it a person, organization, or software application; however, there is no requirement in HTML to conform to such standards. Following the header is a comment and a command that sets the background to a Polynesian motif.
This particular page is laid out as two tables. The first controls the main layout. The second, nested within it, lays out the poem and the image of a greenstone pendant. The tags <
tr> and <
td> are used to mark table rows and cells, respectively. The list item <
li> near the end illustrates various special characters. Most take the &
…; form, but the last two ( ; and #) do not need to be escaped because their normal meaning is syntactically unambiguous. To generate the letter
a with a line above (called a
macron and used in the Māori language) the appropriate Unicode value is given in decimal (#257), demonstrating one way of specifying non-ASCII characters. The example illustrates several other features, including images specified by the <
img> tag, paragraphs beginning with <
p>, italicized words given by <
i>, and a bulleted list introduced by <
ul> (for “unordered list”), along with a <
li> tag for each list item (just one in this case).
Hyperlinks are an important feature of HTML. In the example, the tag pair <
a> … </
a> near the end defines a link
anchor element. The document to link to—in this case, another page on the Web—is specified as an attribute. Hyperlinks can reference PDF documents, audio and video material, and many other formats—such as the Virtual Reality Modeling Language, VRML, which specifies a navigable virtual reality experience. Browsers display the anchor text—the text appearing between the start and end hyperlink tag—differently to emphasize the presence of a link. When the hyperlink is clicked, the browser loads the new document.
HTML was originally encoded in ASCII for transmission over byte-oriented protocols. Other encoding schemes are supported by setting the
charset attribute in the header element to the appropriate encoding name. In Figure 4.6a, line 5 sets it explicitly to UTF-8, which, as mentioned in Section 4.1, is a representation scheme for Unicode. In fact UTF-8 (which is backward-compatible with ASCII) is now the default, and the behavior would be the same if the attribute were omitted.
HTML has many more features. For example, locally defined link anchors permit navigation within a single document. Fonts, colors, and page backgrounds can be specified explicitly. Forms can be created that collect data from the user—such as text data, fielded data, and selections from lists of items.
A mechanism called
frames allows an HTML document to be tiled into smaller, independent segments, each an HTML page in its own right. A set of frames, called a
frameset, can be displayed simultaneously. This is often used to add a navigation bar to every page of a Web site, along the top or down the side of the browser pane. When a link in the navigation bar is clicked, a new page is loaded into the main display frame, and the bar remains in place. Clicking on a link in the main display frame also loads the new page into the main frame.
Frames were introduced by one vendor during the browser wars and were soon supported by other browsers too. However, they have serious drawbacks. For instance, now that a browser can display more than one HTML document at a time, what happens when you create a bookmark? People often click around a site to reach an interesting document, then bookmark it in the usual way—only to find that the bookmark returns not to the intended page but to the point where the site splits into frames instead. This can be very frustrating.
Many of the effects for which frames were invented—such as persistent navigation bars—can also be accomplished by the newer and more principled mechanism of style sheets, avoiding the problems of frames; hence the three demarcated forms of HTML in more recent specifications of the standard: frameset, transitional, and strict, increasing in conformity to XML. We describe style sheets in Section 4.4.
Using HTML in a digital library
As the
lingua franca for the Web, HTML underpins virtually all digital library interfaces. Moreover, digital library source documents are often presented in HTML. This eliminates most of the difficulties associated with the plain text representation introduced earlier. For example, the HTML header disambiguates the character set, while the <
br> and <
p> tags disambiguate line and paragraph breaks.
To extract text from HTML documents for indexing purposes, the obvious strategy of parsing them according to a well-defined grammar quickly runs into difficulty. The permissive nature of Web browsers encourages authors to depart from the defined standard. A better way to identify and remove tags is to write them in the form of “regular expressions” (a scheme described in the next section), which generally achieves greater success for less effort, in this particular circumstance. An alternative is to use the very application that caused the complication in the first place: Web browsers. A plain text browser called
lynx provides a fast and reliable method of extracting text from HTML documents—you give it a command-line argument (
dump) and a URL, and it dumps out the contents of that URL in the form of plain text.
As the example in Figure 4.6 illustrates, HTML allows metadata to be specified explicitly using <
meta> tags. However, this mechanism is rather limited. For one thing, you might hesitate before tampering with source documents by inserting new metadata (perhaps determined separately, perhaps mined from the document content) in this way. When developing a digital library you need to consider whether it is wise (or even ethical, as discussed in Section 1.5) to add new information that cannot be disentangled from that present in the source document. Users might legitimately object if you serve up an altered version in place of the original.
Basic XML
Figure 4.7 shows a formatted list of information about United Nations agencies encoded in XML. For each agency, the file records its full name, an optional abbreviation, and the URL of a picture of its headquarters. Included with the name is the address of the headquarters, stored as an attribute.

The file contains three broad sections, separated by comments in the form <!-- . . . -->. Line 1 is a header: it uses the special notation <? . . . ?> to denote an application-processing instruction. This syntax originates in SGML, which uses it to embed information for specific application programs that process the document. Here it is used to declare the version of XML, the character encoding (UTF-8), and whether or not external files are used. Lines 5 to 19 dictate the syntactic structure in which the remainder of the file is expressed, in the form of a Document Type Definition (DTD). Lines 21 to 44 provide the content of the document.
The style of the content section is reminiscent of HTML. The tag specifications have the same syntactic conventions, and many tags are identical—examples are <
Head>, <
Title>, and <
Body>. However, in lines 27 to 40 the markup creates structures that HTML cannot represent.
Because it is a metalanguage, XML gives document designers a great deal of freedom. In Figure 4.7 the main document structure resembles HTML, but this does not have to be the case. Different element names could be chosen, and different ways could be used to express the information. For example, Figure 4.7 gives the headquarters address as the
hq attribute of the <
Name> element. Alternatively, a new element could have been defined to contain this information. It could be constrained to appear immediately following the <
Name> element, or left optional, or sited anywhere within the <
Agency> element.
Structural decisions are recorded in the DTD (lines 5–19). DTD tags use the special syntax <! . . . > and express keywords in block capitals. For example,
ELEMENT and
ATTLIST are used to define elements and element attributes. Our document designer decided to capitalize the initial letter of all document elements and leave attributes in lowercase. This improves the legibility of Figure 4.7 considerably.
Line 5 starts the DTD, and the square bracket syntax [. . .] indicates that the DTD will appear in-line. (It must, for line 1 declares that the file stands alone.) Alternatively, the DTD could be placed in an external file, referred to by a URL—which is the usual practice.
New elements are introduced in lines 6 to 11 by the keyword
ELEMENT, followed by the new tag name and a description of what the element may contain. A
leaf is an element that comprises plain text, with no markup. This is accomplished through
parsed character data (
#PCDATA
), in which special characters may be included. For example, when the <
Title> tag defined on line 10 is used, markup characters may appear in the title's text, encoded in the familiar HTML way—&
lt; &
amp; and so on. (This convention originated in SGML.)
Lines 6 to 9 describe nonleaf structures. These are defined in a form known as a
regular expression. Here a comma signifies an ordered sequence: line 6 declares that the top-level element <
NGODoc> contains a <
Head> element followed by a <
Body> element. A vertical bar (|) represents a choice of one element from a sequence of named elements, and an asterisk (*) indicates zero or more occurrences. Thus <
Body> (line 8) is a mixture of parsed character data and <
Agency> elements where it is permissible for nothing at all to appear. A plus sign (+) means one or more occurrences, and a question mark (?) signifies either nothing or just one occurrence. Line 9 includes all four symbols |, *, +, and ?: it declares that <
Agency> must include a name element, but that <
Abbrev> is optional and there can be zero or more occurrences of <
Photo> (the example is contrived: there are more concise ways of expressing the same thing). The inner pair of brackets bind these last two tags together, adding the extra stipulation that there must be at least one occurrence of the <
Abbrev> and <
Photo> specifications.
Attributes also give a set of possible values, but here there is no nesting. Lines 12 and 13 show an example. The attribute is signaled by the keyword
ATTLIST, followed by the element to which it applies (
Name), the attribute's name (
hq), its type (
character data), and any appearance restrictions (this one is optional). Lines 16 to 18 show another example, which introduces two attributes of the element
Photo. Line 17 states that the
src attribute is required, while line 18 provides a default value (namely “A photo”) for the
desc attribute.
In addition to &
lt; and &
amp; XML incorporates definitions for &
gt; &
apos; and &
quot;. These are called
entities, and new ones can be added in the DTD using the syntax
ENTITY name "value". For instance, although XML does not have a definition for
à as HTML does, one can be defined by <!ENTITY agrave "à">, which relies on the Unicode standard for the numeric value. Entities are not restricted to single characters, but can be used for any excerpt of text (even if it is marked up). For example, <!ENTITY howto "How to Build a Digital Library"> is a shorthand way of encoding the title of this book.
If several elements shared exactly the same attributes, it would be tedious (and error-prone) to repeat the definitions in each element. This can be handled using a special type of entity known as a
parameter entity. To illustrate it, Figure 4.8 shows a modified and slightly restructured version of the DTD for the document in Figure 4.7 that defines attributes
ident and
style under the name
sharedattrib (lines 3–5), which is then used to bestow these attributes on the <
Title>, <
Abbrev>, and <
Name> elements (lines 11–14). Parameter entities are signaled using the percent symbol (%) and provide a form of shorthand for use within a DTD.

Declaring the shared attribute
style as NMTOKEN (line 4) restricts this attribute's characters to alphanumeric characters plus period (.), colon (:), hyphen (-), and underscore (_), where the first character must be a letter. Its twin
ident is defined as ID (line 5), which is the same as NMTOKEN with the additional constraint that no two such attributes in the document can have the same value. ID therefore provides a mechanism for uniquely identifying elements, which in fact HTML enforces for an attribute with the particular name
id. In XML, uniqueness can be bestowed on any attribute, whatever its name—such as
ident.
DTDs also support enumerated types, although none are present in the example. It can also include lists of tokens separated by white space (NMTOKENS) and attributes that are references to ID attributes (IDREF).
Parsing XML
A document that conforms to XML syntax but does not supply a DTD is said to be
well formed. One that conforms to XML syntax and does supply a DTD is said to be
valid—provided that the content does indeed abide by the syntactic constraints defined in the DTD. DTDs can be stored externally, replacing the bracketed section in Figure 4.7 lines 5–19 by a URL. This allows documents with the same structure to be shared within or between organizations.
XML allows you to define new languages, and makes it easy to develop parsers for them. Generic parsers are available that are capable of parsing
any XML file, and—if a DTD is present—also check that the file is valid. However, merely parsing a document is of limited utility. The result of a parser is just a yes/no indication of whether the document conforms to the general rules of XML (and to the more specific DTD). Far more useful would be a way of specifying what the parser should do with the data it is processing. This is arranged by having it build a parse tree and provide a programming interface—commonly called an API or
application program interface—that lets the user traverse the tree and retrieve the data it contains.
The result of parsing any XML file is a root node whose descendants reflect both textual content and nested tags. At each tag's node are stored the values of the tag's attributes. There is a cross-platform and cross-language API called the
document object model (DOM) that allows you to write programs that access and modify the document's content, structure, and style.
Using XML in a digital library
XML is a powerful tool. It allows file formats within an organization—or a digital library—to be rationalized and shared. Furthermore, organizations can provide an explanation of the structures used in the form of a published machine-readable document. By formulating appropriate DTDs, for instance, different organizations can develop comprehensive formats for sharing information.
A notable example is the Text Encoding Initiative (TEI), founded in 1987, which developed a set of DTDs for representing scholarly texts in the humanities and social sciences. SGML was the implementation backbone, but the work has since been reconciled with XML. These DTDs are widely used by universities, museums, and commercial organizations to represent museum and archival information, classical and medieval works, dictionaries and lexicographies, religious tracts, legal documents, and many other forms of writing.
Examples are legion. The Oxford Text Archive is a nonprofit group that has provided long-term storage and maintenance of electronic texts for scholars over the last quarter-century. Perseus is a pioneering digital library project, dating from 1985, which focuses upon the ancient Greek world. Der Junge Goethe in Seiner Zeit is a collection of early works—poems, essays, legal writings, and letters—by the great German writer Johann von Goethe (1749–1832). The Japanese Text Initiative is a collaborative project that makes available a steadily increasing set of Japanese literature, accompanied by English, French, and German translations.
Various related standards increase XML's power and expand its applicability. Used on its own, XML provides a way of expressing a document's structural information, and/or metadata. Indeed, whether information is metadata or not is really a matter of perspective. Combined with additional standards, XML goes much further: it supports document restructuring, querying, information extraction, and formatting. The next section expands on the formatting standards, which equip XML with display capabilities comparable with HTML. More details appear in the appendix, entitled
More on markup and XML, at the book's Web site: www.nzdl.org/howto.
4.4. Presenting Web Documents: CSS and XSL
Two kinds of style sheet can be used to control the presentation of marked-up documents.
Cascading style s
heets (CSS) produce presentable documents with minimal effort. They were developed principally in support of HTML, but also work with XML. A parallel development is the
extensible stylesheet language (XSL) for XML (and for versions of HTML that are XML compliant). XSL performs the same services as CSS but expresses the style sheet in XML form. It also adds further power by allowing the document structure to be altered dynamically. For example, a particular element type can be constrained to appear at the top of the page, regardless of where it is actually defined.
CSS and XSL share a common heritage and are based on the same formatting model. They share the notion of a rectangular block of content, padded by specified amounts of white space and encased within four borders, which are themselves enclosed by margins. In CSS this is called a
box, in XSL an
area. They also share the same framework for tables.
To illustrate their similarities and differences, we give parallel examples of each. The next subsection describes CSS: an introduction to its basic structure is given through a small example in Figure 4.10; for an example that illustrates tables and lists, and also the
cascading nature of CSS, see Figure 4.11; and for an example that shows context-sensitive formatting, see Figure 4.12. Each of these three figures has two parts, showing the CSS code and a screenshot of the result. An additional example illustrates media-dependent formatting in CSS (see Figure 4.13). The subsection following this provides a parallel description of XSL; Figures 4.14, 4.15 and 4.16 give XSL versions of the three examples (corresponding to Figures 4.10a, 4.11a and 4.12a for CSS). A final subsection illustrates how XSL can be used for the kind of processing that CSS cannot do.
CSS
Figure 4.9 shows what Figure 4.7 looks like when rendered by an XML-capable Web browser. The display is rudimentary; it shows the raw XML, typically color-coded to highlight different features of the language. Depending on the browser used, it might also be possible to open and close elements interactively.

Figure 4.10a gives a style sheet for the same example, and Figure 4.10b shows the result. Improved formatting makes the three individual agency records easier to read; a different font and type size are used to distinguish the title; and the background is set to white. The style sheet is included by adding the line
 |
| Figure 4.10: |
<?xml-stylesheet href="un_basic.css" type="text/css"?>
just after the XML header declaration in Figure 4.7 (the text of Figure 4.10a resides in a file called
un_basic.css).
Style sheets specify rules using
selector-declaration pairs, such as
NGODoc { background: white }
The selector, here NGODoc, names an element type in the document. Several rules can apply to a given element—Figure 4.10a includes two for NGODoc. The declaration in braces gives formatting commands for the element—in this case setting the background to white. Declarations consist of
property: value pairs, separated by semicolons if necessary.
There is an inheritance mechanism based upon the hierarchical document model that underpins XML. If the style sheet specifies formatting for an element, nested elements—ones beneath it in the document tree—inherit that specification. This makes style sheets concise and perspicuous. It is easy to override inherited behavior: just supply further rules at the appropriate level.
Although inheritance is the norm, some properties are noninheriting. What happens can be informally characterized as “intuitive inheritance” because exceptions to the rule make things behave more naturally. For example, if a background image is specified, it is tiled over the entire page. However, if nested elements inherit the background, they break up the pattern by restarting the image at every hierarchical block and subblock. Thus the
background-image property is noninheriting. (You can override the default inheritance behavior by explicitly specifying certain properties to be inheritable or noninheritable.)
Returning to Figure 4.10a, the first rule causes the entire document to be formatted in a block. The second rule augments this element's formatting to set the background to white and the block width to 7.5 inches. The third declares the Title font to be Times, 25 point, boldface. The fourth places the Agency record in a paragraph block with 8-point spacing above and 3-point spacing below, typeset as 16-point Helvetica. The inheritance mechanism ensures that nested elements share this typeface.
In rule five, the selector contains the two element names
Head and
Body, and both are assigned top, left, and right margins of 6 points, 0.2 inch, and 5 mm, respectively. Normally a style sheet would not mix units in such a haphazard way. It is done so here to illustrate that CSS supports different units of measurement. Referring to the DTD that begins Figure 4.7, the Head specification applies to the document's Title, and the Body applies to the Agency node. (Since the two specifications are the same, this effect could have been achieved more concisely by setting these properties in the NGODoc node.) Rule six adds italics to Abbrev, which already inherits 16-point Helvetica from Agency.
The last two rules use a construct known as
pseudo-elements. The :
before and :
after qualifications perform the operations before and after the Abbrev element is processed—in this case placing parentheses around the abbreviation. Other pseudo-elements give access to the first character and first line of a block. The related construct
pseudo-classes can distinguish whether a link has been visited or not, and supports interactive responses to events, such as the cursor hovering over a location.
In general, the ordering of rules in a style sheet is immaterial because every rule that matches any selector is applied. However, it is possible for rules to be contradictory—for example, the background color may be set to both red and blue. The CSS specification includes an algorithm that resolves ambiguity based upon ordering and precedence values.
Style sheets can be used in HTML documents by inserting a <
link> tag
<link ref="stylesheet" type="text/css" href="example_style.css">
into the document's head. CSS instructions can also be embedded directly into the HTML by enclosing them within <
style type="text/css"> … </
style> tags.
Cascading style sheets
Style sheets are
cascaded when several are applied to the same document. Figure 4.11 shows how the records in our running example can be embedded in a table and the title bulleted, along with the result viewed in a Web browser. The
@import command incorporates the
un_basic style in Figure 4.10a to provide a base layer of formatting rules, which will be augmented by the rules that follow. If conflicts occur, new properties take precedence. Figure 4.11a demonstrates some of CSS's table and list features.
 |
| Figure 4.11: |
The first rule augments the title formatting—Times font, 25 point, boldface, as defined in Figure 4.10a—with new specifications: the display type is set to
list item, a bullet point (
disk) is chosen to show list items, and the list is indented with a left-hand margin of 0.2 inch. These new rules create no conflict. CSS allows you to choose the symbol used for bullet points, use enumeration rather than bullets, and alter the style of enumeration (alphabetic, Roman, etc.). A counter mechanism allows such things as nested section numbering.
The other rules in Figure 4.11a present the document's information in tabular form. To do this, the style file maps element names to the display settings
table,
table-row, and
table-cell and supplies appropriate stylistic parameters for each. First the Body element is mapped to
table, along with values for background color and border style and size. The table layout mode is set to
auto, causing the cell dimensions to be calculated automatically to make best use of available space. (The alternative is to specify the layout to be
fixed and give cell width and height explicitly.) The value
separate for
border-collapse separates the borders of the individual cells.
The next rule maps the Agency node to
table-row, so that each agency's information is displayed in its own row. The following three rules define Name, Abbrev, and Photo to be table cells and specify some properties: a
white background;
inset,
dotted, and (by omission)
plain border styles; padded cells for Name and Abbrev (leaving space inside the border), and horizontally and vertically centered text in Abbrev.
Although the Photo elements in the XML document do not explicitly provide text information between tag pairs, they are defined as type
table-cell, and so the table will include empty cells of width 60 points. This illustrates a further point: the pseudo-element
before fills the empty cell with the text “photo available.”
The end result in Figure 4.11b exhibits a small glitch: the “photo available” message on the last line appears in the second column, not the third. This reflects the structure of the XML document in Figure 4.7, which lacks an abbreviation for the World Bank. CSS does not provide a general mechanism for altering document structure, although some manipulation is possible using pseudo-elements. In contrast, XSL is a more expressive language that allows the document structure to be modified.
There is far more to tables in CSS. Tables can have headers, footers, captions, or sections grouped by row or column, all of which can be structured hierarchically into the final table. CSS shares HTML's (and XSL's) table model, and concepts map naturally between the three.
Context- and media-dependent formatting
There's more to cascading style sheets. Using compound selectors, rules can detect when descendant or sibling tags match a particular pattern and produce different effects. Rules can trigger when attributes match particular patterns, and this facility can be combined with compound selectors. Figure 4.12 introduces some contrived formatting instructions into the running example to illustrate these points. Again it incorporates the formatting instructions of Figure 4.10a using the
@import command.
 |
| Figure 4.12: |
The first rule uses the pseudo-element
before to tailor the content of a Photo according to the value of the
desc attribute—but only when the Photo is a child of Agency. Omitting the > symbol would change the meaning to “descendant” rather than “child” and would trigger if the Photo node appeared anywhere beneath an Agency node.
The second rule suppresses the Photo text if its
desc attribute matches the string “A photo.” If the first rule appeared without the second, the text “A photo” would be shown for both the FAO and the World Bank records because the document's DTD supplies this text as the default value for
desc.
The third rule demonstrates the + syntax that is used to specify sibling context. When one Agency node follows another at the same level in the document tree, this rule alters its background and foreground colors. In the XML document of Figure 4.7, only the first Agency record in the document retains its default coloring. The rule also illustrates two different ways of specifying color: by name (red) and by specifying red, green, and blue components in hexadecimal.
The next rule prints the full name of the FAO in the same color as the background, because its
hq attribute in the Name tag matches “Rome, Italy.” (The example would be more realistic if different colors were used here, but in this book we are restricted to black and white.) It uses a third form of color specification:
rgb(), which gives color components in decimal—and these in fact specify the same color as in the previous hexadecimal assignment. This rule makes no sense in practice, but it explains why “(FAO)” is placed far to the right in Figure 4.12b, because it is preceded by the now-invisible name.
The last rule further illustrates inheritance by setting the font size for Agency to 20 points. This overrides the 16-point value set in the initial style sheet and is inherited by descendant nodes.
A key feature of cascading style sheets is the ability to handle different media, such as screen, print, handheld devices, computer projectors, text-only display, Braille, and audio. Figure 4.13 shows the idea. The
@media command names the media type and gives rules, scoped to that media, within braces. The example first sets the Agency node globally to be a block with specified margins. Then for screen and projection media the font is set to 16-point Helvetica, while for print it is 12-point Times.

An
@import command can be augmented to restrict the media type it applies to, for example:
@import url("un_audio.css") aural;
CSS continues to be developed. Like HTML and XHTML, the trend is to modularize the specification to make it easier for a software implementer to clarify what support is given. As with several Web technologies, the actual implementation of CSS in browsers lags behind the formal publication of the standard. Different browser versions support different subsets of the specification (often with idiosyncratic bugs). Web designers spend considerable time checking the appearance of their site in different browsers on different operating system platforms. For a digital library you should test your document display on common browsers and be aware of the browser population used to access your content. Typically, you will be able to find out about your users’ browsers via your library's usage data records (see Section 2.2).
Extensible stylesheet language
XSL, the extensible stylesheet language for XML, transcends CSS by allowing the stylesheet designer to transform documents radically. Parts can be duplicated, tables of contents can be created automatically, lists can be sorted. A price is paid for this expressive power—complexity.
The XSL specification is divided into three parts: formatting objects (FO), XSL transformations (XSLT), and XPath (a way of selecting parts of a document). Formatting objects map closely to CSS instructions and use the same property names wherever possible. XSL transformations manipulate the document tree, while XPath selects parts to transform. We expand on these later in this section.
CSS can be combined with facilities such as Web-page scripting and the document object model mentioned in Section 4.3 (under “Parsing XML”) to provide comparable functionality to XSL—this combination is sometimes dubbed
dynamic HTML. Experts fiercely debate which is the better approach. We think you should know about both, since the wider context in which you work often dictates the path you must tread. There is one key difference, however, between the two approaches. Because XSL is designed to work with XML, it cannot be used with all forms of HTML—because not all forms are XML compliant. CSS operates in either setting: HTML, for which it was designed, and XML, because there is no restriction in the tag names that CSS can provide rules for.
We introduce formatting in XSL by working through the examples used to illustrate CSS. However, XSL greatly extends CSS's functionality. For example, it includes a model for pagination and layout that extends the page-by-page structure of paper documents to provide an equivalent to the “frames” used in Web pages. Its terminology is internationalized. For example,
padding-left becomes
padding-start to make more sense when dealing with languages that are written right to left. Similar terms are used to control the space above, below, and at the end of text, although the old names are recognized for backward compatibility.
Figure 4.14 shows an XSL file for the initial version of the United Nations example. The XML syntax is far more verbose than its CSS counterpart in Figure 4.10a. Beyond the initial NGODoc declaration, it includes many of the keywords we saw in the earlier version. For example, CSS's
font-size: 25pt specification for the Title node now appears between nested tags whose inner and outer elements include the attributes
font-size=25pt and
match=Title, respectively.

The style sheet is included in Figure 4.7 by adding the line
<?xml-stylesheet href="un_basic.xsl" type="text/xsl"?>
just after the XML header declaration (the text of Figure 4.14 resides in a file called
un_basic.xsl), which is exactly what we did before with CSS. The result is a replica of Figure 4.10b, although both standards are complex and it is not uncommon to encounter small discrepancies.
Figure 4.14 begins with the obligatory XML processing application statement, followed by an <
xsl:stylesheet> tag. As usual this is a top-level root element that encloses all the other tags. Its attributes declare two namespaces: one for XSL itself, called
xsl; the other for Formatting Objects, called
fo. Namespaces are an XML extension that keep sets of elements designed for particular purposes separate—otherwise confusion would occur if both XSL and FO happened to include a tag with the same name (such as
block). Once the namespaces have been set up in Figure 4.14, <
xsl:block> specifies the XSL block tag while <
fo:block> specifies the Formatting Objects tag.
Namespaces also incorporate semantic information. If an application encounters a namespace declaration whose value is http://www.w3c.org/1999/XSL/Format, it interprets subsequent tag names according to a published specification. In the following discussion we focus on a subset of Formatting Object tags typically used in document-related XML style sheets. The full specification is more comprehensive.
Returning to Figure 4.14, the next tag sets the document's output type. XSL style sheets perform
transformations: they are used to transform an XML source document into another document. Because our style sheet is designed to format the document using Formatting Object tags, the output is set to
xml. Other choices are
html—in which case all the
fo: scoped tags in the XSL file would need to be replaced with HTML tags—and
text.
To perform the transformation, the input document is matched against the style sheet and a new document tree built from the result. First the document's root node is compared with the XSL file's <
xsl:template> nodes until one is found whose
match attribute corresponds to the node's name. Then the body of the XSL
template element is used to construct the tags in the output tree. If
apply-templates is encountered, matching continues recursively on that document node's children (or as we shall see later, on some other selected part of the document), and further child nodes in the output tree are built as a result.
In the example, the document's root node matches <
xsl:template match="NGODoc">. This adds several
fo tags to the output tree—tags that initialize the page layout of the final document. Eventually <
xsl:apply-templates> is encountered, which causes the document's children <
Head> and <
Body> to be processed by the XSL file. When the matching operation has run its course, the document tree that it generates is rendered for viewing.
The fourth template rule specifies its
match attribute as
Head |
Body to catch Head or Body nodes. Although it achieves the same effect as commas in CSS, this new syntax is part of a more powerful and general standard called XPath. The last template rule also introduces brackets around the abbreviation. The
<xsl:value-of select="."/>
is again an XPath specification. The “.” is a way of selecting the current position, or “here”—in this context it selects the text of the current node (Abbrev). This usage is adapted from the use of a period (.) in a file name to specify the current directory.
Using Formatting Objects
Formatting Objects provide similar capabilities to CSS: margins, borders, padding, foreground and background color, blocks, in-line text, tables with rows and cells, and so on. Many CSS declarations are simply mapped into
fo tag names and attributes with the same name.
Figure 4.15 shows an XSL style sheet for the version of the United Nations Agencies example illustrated in Figure 4.11, with records embedded in a table and the title formatted with a bullet point. Like the CSS version, the file inherits from the basic XSL style sheet. This is done using the <
xsl:import> tag, whose
href attribute supplies the appropriate URL.

The first template rule processes the <
Title> node, which starts by wrapping a
list-block and
list-item around the core information. Using a Unicode character that lies beyond the normal ASCII range, it then inserts a
list-item-label whose content is a bullet point, before setting up the
list-item-body with the content of the
Title tag.
Next, instead of using <
apply-templates> to recursively process any nested elements as was done in the first XSL example, this rule specifies <
apply-imports>. This searches prior imported files (in the order that they were imported) for a rule that also matches the current tag (Title) and applies that rule as well. The result is to nest settings given in the Title rule of
un_basic.xsl inside the current formatting, and then fire the <
apply-templates> statement specified in the rule. The overall effect provides an inheritance facility similar to that of CSS.
The remaining template rules have
fo elements for table, table row, and table cell that correspond to the same entities in CSS and are bound to the same element names in the source document. Attributes within these tags provide similar table formatting: a silver-colored table with white cells using a mixture of border styles and padding.
Some complications stem from the stricter requirements of the Formatting Objects specification. First, tables must include a body, whereas the equivalent structure in CSS is optional. In the example, the body element appears in the rule for
Body, so this rule encodes both
table and
table-body elements. This is not possible in the CSS example because these two table structures are set by the
display property, and would therefore conflict in the file. To avoid the conflict the source document would need two tag names: one mapping to
table and the other to
table-body.
A second complication is that
fo:blocks cannot be placed immediately within
fo:table-body and
fo:table-row elements. That is why the two rules containing these elements must resort to <
xsl:apply-templates> in their recursive processing of the document (instead of <
apply-imports>) and duplicate the formatting attributes already present in the imported file.
Context- and media-dependent formatting
Figure 4.16 reworks the Figure 4.12 version of the United Nations example and illustrates context-based matching using contrived formatting instructions.

The key to context-based matching in XSL is the XPath mechanism. In many operating system interfaces, multiple files can be selected using wild card characters—for example,
project/*/file.html selects all files of this name within any subdirectory of
project. XPath generalizes this to select individual sections of a document. This is done by mapping nodes in the document tree into a string that defines their position in the hierarchy. These strings are expressed just as file names are in a directory hierarchy, with node names separated by slashes. For example, in our document
NGODoc/Body/* returns all the Agency nodes.
This idea is augmented to condition access on attributes stored at nodes. For example,
Name[@
desc] matches a Name node only if it has a
desc attribute defined. Built-in predicates are supplied to check the position of a node in the tree—for example, whether it is the first or last in a chain of siblings.
The first template rule in Figure 4.16 inserts the text that is stored as a Photo node's
desc attribute into the document, prefixed by “Available.” The second is more selective and only matches if the Photo node's
desc attribute contains the text “A photo”—which happens to coincide with its default given in the DTD. If it matches, no text is displayed, and recursive template matching down that part of the tree is abandoned.
The third rule, which works in conjunction with the fourth, demonstrates XSL modes. When an Agency node is first encountered, rule 3 fires and sets up the basic formatting for the block. When it comes to recursively applying the template match, it selects itself with
select=".", switches the mode to
Extra Color, and then rematches on Agency. This time only rule 4 can match (because of the mode), which enforces the additional requirement that Agency must be at least the second node in the file. If so, the rule uses <
xsl:attribute> tags to augment the closest enclosing tag (the
main block for Agency) with attributes for foreground and background colors.
Finally, the remaining rule sets the foreground color the same as the background color for any Name node whose
hq attribute matches “Rome, Italy.”
XSL supports different output media—screen, printer, and so on—using the media attribute of <
xsl:output>, which we have already seen used to set the output type to XML. For example, to restrict a style sheet setting to printers, add
<xsl:output output="xml" media="printer">.
Processing in XSL
Our examples have shown XSL's ability to transform the source document, but the changes have been slight (such as putting brackets around the content of an Abbrev tag) and could all have been achieved using CSS. Figure 4.17 shows a style sheet that sorts the United Nations agencies alphabetically for display, something CSS can't do. It imports
un_basic.xsl to provide some general formatting and then defines a rule for Body that performs the sorting, overriding the match that would have occurred against
Head |
Body in the imported file.

First a block is created that maintains the same margins and spacing provided by the basic style file. Then a recursive match is initiated on all Agency nodes that are descendants of the Body node. In earlier examples matching has been expressed by combining the opening and closing tags, as in <
xsl:apply-templates/>. This shorthand notation is convenient for straightforward matches. Here we separate the opening and closing parts, and supply the sort criterion through the nested tag
xsl:sort. To accomplish the desired result, the example sets the data type to
string and specifies a sort on child nodes of Agency called Name.
This example only scratches the surface. XSL can perform a vast array of transformations—even for sorting there are many more attributes that control the ordering. Other language constructs include variables,
if statements, and
for statements. XSL contains many elements of programming languages, making it impressively versatile, and it is finding use in places that even its designers did not envision.
4.5. Page Description Languages: PostScript and PDF
The purpose of page description languages is to express typeset documents in a way that is independent of the particular output device used. Early word-processing programs and drawing packages incorporated code for sending documents to particular printers and could not be used with other devices. With the advent of page description languages, programs can generate documents in a device-independent format that will print on any device equipped with a driver for that language.
Most of the time, digital libraries can treat documents in these description languages by processing them using standard “black boxes”: generate this report in a particular syntax, display it here, transfer it there, and print. However, to build coherent collections from the documents, you need internal knowledge of these formats to understand what can and cannot be accomplished: whether the text can be indexed, bookmarks inserted, images extracted, and so on. For this reason we describe two page description languages in detail.
PostScript, the first commercially developed page description language, was released in 1985, whereupon it was rapidly adopted by software companies and printer manufacturers as a platform-independent way of describing printed pages that could include both text and graphics. Soon it was being coupled with software applications (notably, in the early days, PageMaker on the Apple Macintosh) that ensure that “what you see” graphically on the computer's raster display is “what you get” on the printed page. PDF, Portable Document Format, is a page description language that arose out of PostScript and addresses many of its shortcomings.
PostScript fundamentals
PostScript files comprise a sequence of drawing instructions, including ones that draw particular letters from particular fonts. The instructions are like this: move to the point defined by these
x and
y coordinates and then draw a straight line to here; using the following
x and
y coordinates as control points, draw a smooth curve around them with such-and-such a thickness; display a character from this font at this position and in this point size; display the following image data, scaled and rotated by this amount. Instructions are included to specify such things as page size, clipping away all parts of a picture that lie outside a given region, and when to move to the next page.
But PostScript is more than just a file format. It is a high-level programming language that supports diverse data types and operations on them. Variables and predefined operators allow the usual kinds of data manipulation. New operations can be encapsulated as user-defined functions. Data can be stored in files and retrieved. A PostScript document is more accurately referred to as a PostScript
program. It is printed or displayed by passing it to a PostScript interpreter, a full programming language interpreter.
Being a programming language, PostScript allows print-quality documents that comprise text and graphical components to be expressed in an exceptionally versatile way. Ultimately, when interpreted, the abstract PostScript description is converted into a matrix of dots or pixels through a process known as
rasterization or
rendering. The dot structure is imperceptible to the eye—commonly available printers have a resolution of 600 dpi, and publishing houses use 1,200 dpi and above (see Table 4.2). This very book is an example of what can be described using the language.
Modern computers are powerful enough that a PostScript description can be quickly rasterized and displayed on the screen. This adds an important dimension to online document management: computers without the original software used to compose a document can still display the finished product exactly as it was intended to be displayed. Indeed, in the late 1980s one computer manufacturer took the idea to an extreme by developing an operating system (called NeXT) in which the display was controlled entirely from PostScript, and all applications generated their on-screen results in this form.
However, PostScript was not designed for screen displays. As is true for ASCII, limitations often arise when a standard is put to use in situations for which it was not designed. Just as ASCII is being superseded by Unicode, the Portable Document Format (PDF) has been devised as the successor to PostScript for online documents. Today the Apple Macintosh uses PDF throughout, just as the NeXT used PostScript.
The language
PostScript is page-based. Graphical marks are drawn one by one until an operator called
showpage is encountered, whereupon the page is presented. When one page is complete, the next is begun. Placement is like painting: if a new mark covers a previously painted area, it completely obliterates the old paint. Marks can be black and white, grayscale, or color. They are “clipped” to fit within a given area (not necessarily the page boundary) before being placed on the page. This process defines the
imaging model used by PostScript.
Table 4.3 summarizes PostScript's main graphical components. Various geometric primitives are supplied. Circles and ellipses can be produced using the
arc primitive; general curves are drawn using
splines, curved lines whose shapes are controlled precisely by a number of control points. A
path is a sequence of graphical primitives interspersed with geometric operations and stylistic attributes. Once a path has been defined, it is necessary to specify how it is to be painted: for example,
stroke for a line or
fill for a solid shape. The
moveto operator moves the pen without actually drawing, so that paths do not have to prescribe contiguous runs of paint. An operator called
closepath forms a closed shape by generating a line from the latest point back to the last location moved to. The origin of coordinates is located at the bottom left-hand corner of a page, and the unit of distance is set to be one
printer's point, a typographical measure whose size is 1/72 inch.
In PostScript, text characters are just another graphical primitive: they can be rotated, translated, scaled, and colored just like any other object. However, because of its importance, text receives special treatment. The PostScript interpreter stores information about the current font: font name, font type, point size, and so on, and operators like
findfont and
scalefont are provided to manipulate these components. There is also a special operator called
image for sampled images.
Files containing PostScript programs are represented in 7-bit ASCII, but this does not restrict the fonts and characters that can be displayed on a page. A percentage symbol (%) indicates that the remainder of the line contains a comment; however, comments marked with a double percent (%%) extend the language by giving structured information that can be utilized by a PostScript interpreter.
Figure 4.18b shows a simple PostScript program that, when executed, produces the result in Figure 4.18a, which contains the greeting
Welcome in five languages. The first line, which is technically a comment but must be present in all PostScript programs, defines the file to be of type PostScript. The next two lines set the font to be 14-point Helvetica, and then the current path is moved to a position (10,10) points from the lower left-hand corner of the page.
 |
 |
 |
 |
| Figure 4.18: |
The five
show lines display the
Welcome text (plus a space). PostScript, unlike most computer languages, uses a stack-based form of notation where commands
follow their arguments. The
show commands “show” the text that precedes them; parentheses are used to group characters together into text strings. In the fifth example, the text
Akw is “shown” or painted on the page; then there is a relative move (
rmoveto) of the current position forward two printer's points (the coordinate specification (2, 0)); then the character 310 is painted (octal 310, which is in fact an umlaut in the Latin-1 extension of ASCII); the current position is moved back six points; and the characters
aba are “shown.” The effect is to generate the composite character
ä in the middle of the word. Finally the
showpage operator is issued, causing the graphics that have been painted on the virtual page to be printed on a physical page.
The PostScript program in Figure 4.18b handles the composite character
ä inelegantly. It depends on the spacing embodied in the particular font chosen—on the fact that moving forward two points, printing an umlaut, and moving back six points will position the forthcoming
a directly underneath. There are better ways to accomplish this, using, for instance, ISOLatin1Encoding or composite fonts, but they are beyond the scope of this simple example.
Evolution
Standards and formats evolve. There is a tension between stability, an important feature for any language, and currency, the need to extend in response to the ever-changing face of computing technology. To help resolve the tension,
levels of PostScript are defined. The conformance level of a file is encoded in its first line, as can been seen in Figure 4.18b (
PS-Adobe-3.0 means Level 3 PostScript). Care is taken to ensure that levels are backward-compatible.
What we have described so far is basic Level 1 PostScript. Level 2 includes
• improved virtual memory management
• device-independent color
• composite fonts
• filters.
The virtual memory enhancements use whatever memory space is available more efficiently, which is advantageous because PostScript printers sometimes run out of memory when processing large documents. Composite fonts, which significantly help internationalization, are described below. Filters provide built-in support for compression, decompression, and other common ways of encoding information.
Level 2 was announced in 1991, six years after PostScript's original introduction. The additions were quite substantial, and it was a long time before it became widely adopted. Level 3 (sometimes called PostScript 3) was introduced in 1998. Its additions are minor by comparison, and include
• more fonts, and provision for describing them more concisely;
• improved color control and smoother shading;
• advanced processing methods that accelerate rendering.
While PostScript
per se does not impose an overall structure on a document, applications can take advantage of a prescribed set of rules known as the
document structuring conventions (DSC). These divide documents into three sections: a prolog, document pages, and a trailer. The divisions are expressed as PostScript “comments.” For example,
%%BeginProlog and
%%Trailer define section boundaries. Other conventions are embedded in the document—such as
%%BoundingBox, discussed below. There are around 40 document structuring commands in all.
Document structuring commands provide additional information about the document but do not affect how it is rendered. Since the commands are couched as comments, applications that do not use the conventions are unaffected. However, other applications can take advantage of the information.
Applications that generate PostScript, such as word processors, commonly use the prolog to define procedures that are helpful in generating document pages and use the trailer to tidy up any global operations associated with the document or to include information (such as a list of all fonts used) that is not known until the end of the file. This convention enables pages to be expressed more concisely and clearly.
Encapsulated PostScript
Encapsulated PostScript is a variant designed for expressing documents of a single page or less. It is widely used to incorporate artwork created using a software application like a drawing package into a larger document, such as a report being composed in a word processor. Encapsulated PostScript is built on top of the document-structuring conventions.
Figure 4.18c shows the
Welcome example expressed in Encapsulated PostScript. The first line is augmented to reflect this (the encapsulation convention has levels as well; this is EPSF-3.0). The
%%BoundingBox command that specifies the size of the drawing is mandatory in Encapsulated PostScript. Calculated in points from the origin (bottom left-hand corner), it defines the smallest rectangle that entirely encloses the marks constituting the rendered picture. The rectangle is specified by four numbers: the first pair give the coordinates of the lower left corner, and the second pair define the upper right corner. Figure 4.18c also shows document-structuring commands for the creator of the document (more commonly it gives the name and version number of the software application that generated the file), a suitable title for it, and a list of fonts used (in this case, just Helvetica).
An Encapsulated PostScript file contains raw PostScript along with a few special comments. It can be embedded verbatim, header and all, into a context that is also PostScript. For this to work properly, operators that affect the global state of the rendering process must be avoided. These restrictions are listed in the specification for Encapsulated PostScript and in practice are not unduly limiting.
Fonts
PostScript supports two broad categories of fonts: base and composite fonts. Base fonts accommodate alphabets up to 256 characters. Composite fonts extend the character set beyond this point and also permit several glyphs to be combined into a single character—making them suitable for languages with large alphabets, such as Chinese, and with frequent character combinations, such as Korean.
In Figure 4.18b the
findfont operator is used to set the font to Helvetica. This searches PostScript's font directory for the named font (
/Helvetica), returning a
font dictionary that contains all the information necessary to render characters in that font. Most PostScript products have a built-in font directory with descriptions of 13 standard fonts from the Times, Helvetica, Courier, and Symbol families. Helvetica is an example of a base font format.
The execution of a
show command such as
(Welcome) show takes place in two steps. For each character, its numeric value (0–255) is used to access an array known as the
encoding vector. This provides a name, such as
/W (or, for nonalphabetic characters, a name like
/hyphen). This name is then used to look up a glyph description in a subsidiary dictionary. A
name is one of the basic PostScript types: it is a label that binds itself to an object. The act of executing the glyph object renders the required mark. The font dictionary is a top-level object that binds these operations together.
In addition to the built-in font directory, PostScript lets you provide your own graphical descriptions for the glyphs, which are then embedded in the PostScript file. You can also change the encoding vector.
Font formats
The original specification for PostScript included a means of defining typographical fonts. At the time there were no standard formats for describing character forms digitally. PostScript fonts, which were built into the LaserWriter printer in 1985 and subsequently adopted in virtually all typesetting devices, sparked a revolution in printing technology. However, to protect its investment, Adobe, the company that introduced PostScript, kept the font specification secret. This spurred Apple to introduce a new font description format six years later (and this format was subsequently adopted by the Windows operating system). Adobe then published its format.
Level 3 PostScript incorporates both ways of defining fonts. The original method is called Type 1; the rival scheme is TrueType. For example, Times Roman, Helvetica, and Courier are Type 1 fonts, while Times New Roman, Arial, and Courier New are the TrueType equivalents.
Technically, the two font description schemes have much in common. Both describe glyphs in terms of the straight lines and curves that make up the outline of the character. This means that standard geometric transformations—translation, scaling, rotation—can be applied to text as well as to graphic primitives. One difference between Type 1 and TrueType is the way in which curves are specified. Both use spline curves, but the former uses a kind of cubic spline called a
Bézier curve, whereas the latter uses a kind of quadratic spline called a
B-spline. From a user perspective these differences are minimal—but they do create incompatibilities.
Both representations are resolution independent. Characters may be resized by scaling the outlines up or down—although a particular implementation may impose practical upper and lower limits. It is difficult to scale down to very small sizes. When a glyph comprises only a few dots, inconsistencies arise in certain letter features depending on where they are placed on the page, because even though the glyphs are the same size and shape, they sit differently on the pixel grid. For example, the width of letter stems may vary from one instance of a letter to another; worse still, when scaled down, key features may disappear altogether.
Both Type 1 and TrueType deal with this by putting additional information called
hints into fonts to make it possible to render small glyphs consistently. However, the way that hints are specified is different in each case. Type 1 fonts give hints for vertical and horizontal features, overshoots, snapping stems to the pixel grid, and so on, and in many cases there is a threshold pixel size at which they are activated. TrueType hints define flexible instructions that can do much more. They give the font producer fine control over what happens when characters are rendered under different conditions, but to use them to full advantage, individual glyphs must be manually coded. This is such a daunting undertaking that, in practice, many fonts omit this level of detail. Of course this does not usually affect printed text, because even tiny fonts can be displayed accurately, without hinting, on a 600-dpi device. Hinting is only really important for screen displays.
Composite fonts
Composite fonts became standard in Level 3 PostScript. They are based on two key concepts. First, instead of using a single dictionary for mapping character values, as base fonts do, composite fonts use a hierarchy of dictionaries. At its root, a composite font dictionary directs character mappings to subsidiary dictionaries, which can contain either base fonts or further composite fonts (up to a depth limit of five). Second, the
show operator no longer decodes its argument one byte at a time. Instead, a
font number and
character selector pair are used. The font number locates a dictionary within the hierarchy, while the character selector uses the encoding vector stored with that dictionary to select a glyph description name to use when rendering the character. This latter step is analogous to the way base fonts are used.
The arguments of
show can be decoded in several ways. Options include 16 bits per font number and character selector pair, separated into one byte each (note that this differs from a Unicode representation), or using an escape character to change the current font dictionary. The method used is determined by a value in the root dictionary.
Compatibility with Unicode
Character-identifier keyed, or
CID-keyed, fonts provide a newer format designed for use with Unicode. They map multiple byte values to character codes in much the same way that the encoding vector works in base fonts—except that the mapping is not restricted to 256 entries. The CID-keyed font specification is independent of PostScript and can be used in other environments. The data is also external to the document file: font and encoding-vector resources are accessed by reading external files into dictionaries.
OpenType is a new font description that goes beyond the provisions of CID-keyed fonts. It encapsulates Type 1 and TrueType fonts into the same kind of wrapper, yielding a portable, scalable font platform that is backward-compatible. The basic approach of CID-keyed fonts is used to map numeric identifiers to character codes. OpenType includes multilingual character sets with full Unicode support, and extended character sets that support small caps, ligatures, and fractions—all within the same font. It includes a way of automatically substituting a single glyph for a given sequence (e.g., the ligature
fi can be substituted for the sequence
f followed by
i) and vice versa. Substitution can be context sensitive. For example, a
swash letter, which is an ornamental letter—often a decorated italic capital—used to open paragraphs, can be introduced automatically at the beginning of words or lines.
Text extraction
It is useful to be able to extract plain text from PostScript files. To build a full-text index for a digital library, the raw text needs to be available. An approximation to the formatting information may be useful too—perhaps to display HTML versions of documents in a Web browser. For this, structural features like paragraph boundaries and font characteristics must be identified from PostScript.
PostScript allows complete flexibility in how documents are described—for example, the characters do not have to be in any particular order. In practice, actual PostScript documents tend to be more constrained. However, the text they contain is often fragmented and inextricably muddled up with other character strings that do not appear in the output. Figure 4.19 shows an example, along with the text extracted from it. Characters to be placed on the page appear in the PostScript file as parenthesized strings. But font names, file names, and other internal information are represented in the same way—examples can be seen in the first few lines of the figure. Also the division of text into words is not immediately apparent. Spaces are implied by the character positions rather than being present explicitly. Text is written out in fragments, and each parenthetical string sometimes represents only part of a word. Deciding which fragments to concatenate is difficult. Although heuristics might be devised to cover common cases, they are unlikely to lead to a robust solution that can deal satisfactorily with the variety of files found in practice.

This is why text extraction based on scanning a PostScript document for strings of text meets with limited success. It also fails to extract any formatting information. Above all, it does not address the fundamental issue that PostScript is a programming language whose output, in principle, cannot be determined merely by scanning the file—for example, in a PostScript document the raw text could be (and often is) compressed, to be decompressed by the interpreter every time the document is displayed. As it happens, this deep-rooted issue leads to a solution that is far more robust than scanning for text, can account for formatting information, and decodes any programmed information.
If a PostScript code fragment is prepended to a document and the document is then run through a standard PostScript interpreter, the placement of text characters can be intercepted, producing text in a file, rather than pixels on a page. The central trick is to redefine PostScript's
show operator, which is responsible for placing text on the page. Regardless of how a program is constructed, all printed text passes through this operator (or a variant, as mentioned later). The new code fragment redefines it to write its argument, a text string, to a file instead of rendering it on the screen. Then, when the document is executed, a text file is produced instead of the usual physical pages.
A simple text extraction program
The idea can be illustrated by a simple program. Prepending the incantation
/show {
print }
def, shown in Figure 4.20a, to the document of Figure 4.19 redefines the
show operator. The effect is to define the name
show to be
print instead—and therefore print the characters to a file. The result appears at the right of Figure 4.20a. One problem has been solved: winnowing the text destined for a page from the remainder of the parenthesized text in the original file.
 |
 |
 |
 |
| Figure 4.20: |
The problem of identifying whole words from fragments must still be addressed, for the text in Figure 4.20a contains no spaces. Printing a space between each fragment yields the text in Figure 4.20b. Spaces do appear between each word, but they also appear within words, such as
m ultiple and
imp ortan t.
To put spaces in their proper places, it is necessary to consider where fragments are placed on the page. Between adjacent characters, the print position moves only a short distance from one fragment to the next; if a space intervenes, the distance is larger. An appropriate threshold will depend on the type size and should be chosen accordingly; however, we use a fixed value for illustration.
The program fragment in Figure 4.20c implements this modification. The symbol
X records the horizontal coordinate of the right-hand side of the previous fragment. The new
show procedure obtains the current
x coordinate using the
currentpoint operator (the
pop discards the
y coordinate) and subtracts the previous coordinate held in
X. If the difference exceeds a preset threshold—in this case, five points—a space is printed. Then the fragment itself is printed.
In order to record the new
x coordinate, the fragment must actually be rendered. Unfortunately, Figures 4.20a and b have suppressed rendering by redefining the
show operator. The line
systemdict /show get exec retrieves the original definition of
show from the system dictionary (
systemdict /show get) and executes it (
exec) with the original string as argument. This renders the text and updates the current point, which is recorded in
X on the next line. Executing the original
show operator provides a foolproof way of updating coordinates exactly as they are when the text is rendered. This new procedure produces the text in Figure 4.20c, in which all words are segmented correctly. Line breaks are detected by analyzing vertical coordinates in the same way and comparing the difference with another fixed threshold.
PostScript (to be precise, Level 1 PostScript) has four variants of the show command—
ashow,
widthshow,
awidthshow, and
kshow—and they should all be treated similarly. In Figure 4.20d, a procedure is defined to do the work. It is called with two arguments, the text string and the name of the appropriate
show variant. Just before it finishes, the code for the appropriate command is located in the system dictionary and executed.
Improving the output
Notwithstanding the use of fixed thresholds for word and line breaks, this scheme is quite effective for extracting text from many PostScript documents. However, several enhancements can be made to improve the quality of the output. First, fixed thresholds fail when the text is printed in an unusually large or small font. With large fonts, interfragment gaps are mistakenly identified as interword gaps, and words break up. With small ones, interword gaps are mistaken for interfragment gaps, and words run together. To solve this problem, the word-space threshold can be expressed as a fraction of the average character width. This is calculated for the fragments on each side of the break by dividing the rendered width of the fragment by the number of characters in it. As a rule of thumb, the interword threshold should be about 30 percent greater than the average character width.
Second, line breaks in PostScript documents are designed for typeset text with proportionally spaced fonts. The corresponding lines of plain text are rarely all of the same length. Moreover, the best line wrapping often depends on context—such as the width of the window that displays the text. Paragraph breaks, on the other hand, have significance in terms of document content and should be preserved. Line and paragraph breaks can be distinguished in two ways. Usually paragraphs are separated by more vertical space than lines are. In this case, any advance that exceeds the nominal line space can be treated as a paragraph break. The nominal spacing can be taken as the most common nontrivial change in
y coordinate throughout the document.
Sometimes paragraphs are distinguished by horizontal indentation rather than vertical spacing. Treating indented lines as paragraph breaks sometimes fails, however—quotations and bulleted text are often indented too. Additional heuristics are needed to detect these cases. For example, an indented line may open a new paragraph if it starts with a capital letter; if its right margin and the right margin of the following line are at about the same place; and if the following line is not also indented. Although not infallible, these rules work reasonably well in practice.
Third, more complex processing is needed to deal properly with different fonts. For instance, ligatures, bullets, and printer's quotes (“ ‘ ’ ” rather than ′ ″) are non-ASCII values that can be recognized and mapped appropriately. Mathematical formulas with complex sub-line spacing, Greek letters, and special mathematical symbols are difficult to deal with satisfactorily. A simple dodge is to flag unknown characters with a question mark, because there is no truly satisfactory plain-text representation for mathematics.
Fourth, when documents are justified to a fixed right margin, words are often hyphenated. Output will be improved if this process is reversed, but simply deleting hyphens from the end of lines inadvertently removes them from compound words that happen to straddle line breaks.
Finally, printed pages often appear in reverse order. This is for mechanical convenience: when pages are placed face up on the output tray, the first one produced is the last page of the document. PostScript's document-structuring conventions include a way of specifying page ordering, but it is often not followed in actual document files. Of several possible heuristics for detecting page order, a robust one is to extract numbers from the text adjacent to page breaks. These are usually page numbers, and you can tell that a document is reversed because they decrease rather than increase. Even if some numbers in the text are erroneously identified as page numbers, the method is quite reliable if the final decision is based on the overall majority.
Using PostScript in a digital library
Some early digital libraries were built from PostScript source documents, with contemporary versions shifting to PDF (discussed below) or a combination of the two. PostScript's ability to display print-quality documents using a variety of fonts and graphics on virtually any computer platform is a wonderful feature. Because the files are 7-bit ASCII, they can be distributed electronically using lowest-common-denominator e-mail protocols. And although PostScript predates Unicode, characters from different character sets can be freely mixed because documents can contain many different fonts. Embedding fonts in documents makes them faithfully reproducible even when sent to printers and computer systems that lack the necessary fonts.
The fact that PostScript is a programming language, however, introduces problems that are not normally associated with documents. A document is a program. And programs crash for a variety of obscure reasons, leaving the user with at best an incomplete document and no clear recovery options. Although PostScript is supposed to be portable, in practice people often experience difficulty printing PostScript files—particularly on different computer platforms. When a document crashes, it does not necessarily mean that the file is corrupt. Just as subtle differences occur among compilers for high-level languages like C++, the behavior of PostScript interpreters can differ in unpredictable ways. Life was simpler in the early days, when there was one level of Postscript and a small set of different interpreters. Now, with the proliferation of PostScript support, any laxity in the code an application generates may not surface locally, but instead cause unpredictable problems at a different time on a computer far away.
Trouble often surfaces as a
stack overflow or
stack underflow error. Overflow means that the available memory has been exceeded on the particular machine that is executing the document. Underflow occurs when an insufficient number of elements are left on the stack to satisfy the operator currently being executed. For example, if the stack contains a single value when the
add operator is issued, a stack underflow error occurs. Other complications can be triggered by conflicting definitions of what a “new-line” character means on a given operating system—something we have already encountered with plain text files. Although PostScript classes both the carriage-return and line-feed characters (
CR and
LF in Table 4.1) as white space (along with “tab” and “space,”
HT and
SPAC, respectively), not all interpreters honor this.
PostScript versions of word-processor files are invariably far larger than the native format, particularly when they include uncompressed images. Level 1 does not explicitly provide compressed data formats. However, PostScript is a programming language and so this ability can be programmed in. A document can incorporate compressed data so long as it also includes a decompression routine that is called whenever the compressed data is handled. This keeps image data compact, yet retains Level 1 compatibility. Drawbacks are that every document duplicates the decompression program, and decompression is slow because it is performed by an interpreted program rather than a precompiled one. These are not usually serious. When the document is displayed online, only the current page's images need be decompressed, and when it is printed, decompression is quick compared with the physical printing time. Note that PostScript based digital library repositories commonly include Level 1 legacy documents.
The ideas behind PostScript make it attractive for digital libraries. However, there are caveats. First, it was not designed for online display. Second, if advantage is taken of additions and upgrades, such as those embodied in comments, encapsulated PostScript, and higher levels of PostScript, digital library users must upgrade their viewing software accordingly (or, more likely, some users will encounter mysterious errors when viewing certain documents). Third, extracting text for indexing purposes is not trivial, and the problem is compounded by international character sets and creative typography.
Portable Document Format: PDF
PDF is a page description language that arose out of PostScript and addresses its shortcomings. It has precisely the same imaging model. Page-based, it paints sequences of graphical primitives, modified by transformations and clipping. It has the same graphical shapes—lines, curves, text, and sampled images. Again, text and images receive special attention, as befits their leading role in documents. The concept of current path, stroked or filled, also recurs. PDF is device independent and expressed in ASCII.
There are two major differences between PDF and PostScript. First, PDF is not a full-scale programming language. (In reality, as we have seen, this feature limits PostScript's portability.) Gone are procedures, variables, and control structures. Features like compression and encryption are built in—there is no opportunity to program them. Second, PDF includes new features for interactive display. The overall file structure is imposed, rather than being embodied in document-structuring conventions as with PostScript. This provides random access to pages, hierarchically structured content, and navigation within a document. Also, hyperlinks are supported.
There are many less significant differences. Operators are still postfix—that is, they come after their arguments—but their names are shorter and more cryptic, often only one letter, such as
S for stroke and
f for fill. To avoid confusion among the different conventions of different operating systems, the nature and use of white space are carefully specified. PDF files include byte offsets to other parts of the file and are always generated by software applications (rather than being written by hand as small PostScript programs occasionally are).
PDF has been through several versions since its introduction in 1993. In 1999, JavaScript support was added for greater interactivity (Version 1.3), and in 2000 (Version 1.5) support for JPEG 2000 was added (see Section 5.3). Adobe has released successive free versions of its Reader application (and associated browser plug-ins) to enable users to access the enhanced features. Although other readers are available, most users view PDF documents in Adobe applications. In 2008, PDF (Version 1.7) became an ISO international standard.
Different subsets of PDF have been defined to target specific user groups. Of particular relevance to digital librarians is the subset aimed at long-term archiving, known as PDF/A. PDF/A documents are intended to be self-contained and static. They require all fonts to be embedded, no use of external resources, no JavaScript actions, and device-independent color spaces. The first archival standard, PDF/A-1, is based on PDF version 1.4. The majority of applications that generate PDF provide options that allow users to save their document in whatever version they require. As with other evolving file formats, there is a trade-off between using the latest new features and ensuring that your documents can be widely read.
Inside a PDF file
Figure 4.18d is a PDF file that produces an exact replica of Figure 4.18a. The first line encodes the type and version as a comment, in the same way that PostScript does. Five lines near the end of the first column specify the text
Welcome in several languages. The glyph
ä is generated as the character
344 in the Windows extended 8-bit character set (selected by the line starting
/Encoding in the second column), and
Tj is equivalent to PostScript's
show. Beyond these similarities, the PDF syntax is far removed from its PostScript counterpart.
PDF files split into four sections: header, objects, cross-references, and trailer. The header is the first line of Figure 4.18d. The object section follows and accounts for most of the file. Here it comprises a sequence of six objects in the form <
num> <
num>
obj …
endobj; these define a graph structure (explained below). Then follows the cross-reference section, with numbers (eight lines of them) that give the position of each object in the file as a byte offset from the beginning. The first line says how many entries there are; subsequent ones provide the lookup information (we expand on this later). Finally comes the trailer, which specifies the root of the graph structure, followed by the byte offset of the beginning of the cross-reference section.
The object section in Figure 4.18d defines the graph structure in Figure 4.18e. The root points to a
Catalog object (number 1), which in turn points to a
Pages object, which points to (in this case) a single
Page object. The
Page object (number 3) contains a pointer back to its parent. Its definition in Figure 4.18d also includes pointers to
Contents, which in this case is a
Stream object that produces the actual text, and two
Resources, one of which (
Font, object 6) selects a particular font and size (14-point Helvetica), while the other (
ProcSet, object 5) is an array called the
procedure set array that is used when the document is printed.
A rendered document is the result of traversing this network of objects. Only one of the six objects in Figure 4.18d generates actual marks on the page (object 4,
stream). Every object has a unique numeric identifier within the file (the first of the <
num> fields). Statements such as
5 0 R (occurring in object 3) define references to other objects—object 5 in this case. The 0 that follows each object number is its
generation number. Applications that allow documents to be updated incrementally alter this number when defining new versions of objects.
Object networks are hierarchical graph structures that reflect the nature of documents. Of course they are generally far more complex than the simple example in Figure 4.18e. Most documents are composed of pages; many pages have a header, the main text, and a footer; documents often include nested sections. The physical page structure and the logical section structure usually represent parallel hierarchical structures, and the object network is specifically designed for describing such structures—indeed, any number of parallel structures can be built. These object networks are quite different from the linear interpretation sequence of PostScript programs. They save space by eliminating duplication (of headers and footers, for example). But most importantly they support the development of online reading aids that navigate around the structure and display appropriate parts of it, as described in the next subsection.
The network's root is specified in the trailer section. The cross-reference section provides random access to all objects. Objects are numbered from zero upward (some, such as object 0, may not be specified in the object section). The cross-reference section includes one line for each, giving the byte offset of its beginning, the generation number, and its status (
n means it is in use,
f means it is free). Object 0 is always free and has a generation number of 65,536. Each line in the cross-reference section is padded to exactly 20 bytes with leading zeros.
To render a PDF document, you start at the end. PDF files always end with
%%EOF—otherwise they are malformed and an error is issued. The preceding
startxref statement gives the byte offset of the cross-reference section, which shows where each object begins. The
trailer statement specifies the root node.
The example in Figure 4.18d contains various data types:
number (integer or real),
string (array of unsigned 8-bit values),
name,
array,
dictionary, and
stream. All but the last have their origin in PostScript. A dictionary is delimited by double angle brackets, ≪ . . . ≫—a notational convenience that was introduced in PostScript Level 2. The
stream type specifies a “raw” data section delimited by
stream … endstream. It includes a dictionary (delimited by angle brackets in object 4 of Figure 4.18d) that contains associated elements. The preceding
/Length gives the length of the raw data, 118 bytes. Optional elements that perform processing operations on the stream may also be included—
/Filter, for example, specifies how to decode it.
PDF has types for
Boolean,
date, and specialized composite types such as
rectangle—an array of four numbers. There is a
text type that contains 16-bit unsigned values that can be used for Unicode text (the UTF-16 variant described in Chapter 8), although non-Unicode extensions are also supported.
Features of PDF
The PDF object network supports a variety of different browsing features. Figure 4.21 shows a document—which is in fact the language reference manual—displayed using the Acrobat PDF reader. The navigation panel on the left presents a hierarchical structure of section headings known as
bookmarks, which the user can expand and contract at will and use to bring up particular sections of the document in the main panel. This simply corresponds to displaying different parts of the object network tree illustrated in Figure 4.18e, at different levels of detail. Bookmarks are implemented using the PDF object type
Outline.
Thumbnail pictures of each page can also be included in this panel. These images can be embedded in the PDF file at the time it is created, by creating new objects and linking them into the network. Some PDF readers are capable of generating thumbnail images on the fly even if they are not explicitly included in the PDF file. Hyperlinks can be placed in the main text so that you can jump from one document to another. For each navigational feature, corresponding objects must appear in the PDF network, such as the
Outline objects mentioned earlier that represent bookmarks.
PDF has a
searchable image option that is particularly relevant to collections derived from paper documents. Using it, invisible characters can be overlaid on top of an image. Highlighting and searching operations utilize the hidden information, but the visual appearance is that of the image. Using this option, a PDF document can comprise the original scanned page, backed up by text generated by optical character recognition. Errors in the text do not mar the document's appearance at all. The overall result combines the accuracy of image display with the flexibility of textual operations such as searching and highlighting. In terms of implementation, PDF files containing searchable images are typically generated as an output option by OCR programs (see Section 4.2). They specify each entire page as a single image, linked into the object network in such a way that it is displayed as a background to the text of the page.
There are many other interactive features. PDF provides a means of annotation that includes video and audio as well as text. Actions can be specified that launch an application. Forms can be defined for gathering fielded information. PDF has moved a long way from its origins in document printing, and today its interactive capabilities rival those of HTML.
Compression is an integral part of the language and is more convenient to use than the piecemeal development found in PostScript. It can be applied to individual stream components and helps reduce overall storage requirements and minimize download times—important factors for a digital library.
Linearized PDF
The regular PDF file structure makes it impossible to display the opening pages of documents until the complete file has been received. Even with compression, large documents can take a long time to arrive.
Linearization is an extension that allows parts of the document to be shown before downloading finishes. Linearized PDF documents obey rules governing object order but include more than one cross-reference section.
The integrity of the PDF format is maintained: any PDF viewer can display linearized documents. However, applications can take advantage of the additional information to produce pages faster. The display order can be tailored to the document—the first pages displayed are not necessarily the document's opening pages, and images can be deferred to later.
Security and PDF documents
The PDF document format has four features related to information security:
• encryption
• digital rights management
• phoning home
• redaction.
PDF files can be encrypted so that a password is needed to edit or view the contents. Two separate encryption systems are defined within PDF; it also includes a way in which third-party security schemes can be used for documents.
A separate facility is provided for PDF files to embed
digital rights management (DRM) restrictions that can limit copying, editing, or printing. DRM restrictions provide only limited security, however, because they depend on the reader software to obey them. Alternatively, if you want to print a document that does not allow printing, you could use a screen-capture tool to capture the page images and print them. Of course, the resolution will suffer, but there are tools that convert PDF documents to high-resolution images, so this need not be a problem. If you need a fresh copy of the PDF document, just OCR the images.
Like HTML files, PDF files can submit information to a Web server. This facility could be used to make documents “phone home” when they are opened, and report the network (IP) address of the reader's computer. Many PDF readers will notify the user via a dialogue box that the document's supplier is auditing usage of the file and offer the option of withdrawing or continuing.
Redaction means removing information from documents. In the old days, secure redaction was achieved by physically cutting out parts of the text with scissors or knife and photocopying it against a black background. A similar effect can be achieved less securely using a black marker to strike through the text. However, as many people have discovered to their cost, covering up information in an electronic file is not the same as deleting it.
Whereas redacting paper documents is safe and easy, PDF files have created a trap for the unwary. The graphical tools available in Adobe Acrobat can be used to make it appear as though material has been redacted when in fact it has not, because the text remains in the PDF file and can still be extracted. For example, you might use a highlighter tool as a black marker, or use a rectangle tool to cover text. But these tools annotate; they do not redact. There have been several incidents where organizations have tried, and failed, to redact information in PDF files. For instance, in a 2008 legal case involving Facebook, some settlement details were kept confidential—the press were barred from the courtroom. However, when the improperly redacted PDF transcript was released, a simple copy-and-paste operation revealed the hidden text.
One sure way of redaction is to print out the document, redact the paper version, and scan it in again. Alternatively, you could visually cover the text using graphical tools, convert the PDF file to TIFF images (see Section 5.3), and convert these back to PDF. Finally, Adobe's Acrobat Professional program allows true redaction on the PDF form of the document.
PDF and PostScript
PDF is a sophisticated document description language that was developed by Adobe as a successor to PostScript. It addresses various serious deficiencies that had arisen with PostScript, principally lack of portability. While PostScript is a programming language, PDF is a format, and this bestows the advantage of increased robustness in rendering. Also, PostScript has a reputation for verbosity that PDF has avoided (PostScript now incorporates compression, but not all software uses it). Another feature of PDF is that metadata can be included in PDF files using the Extensible Metadata Platform, XMP (see Section 6.3).
PDF incorporates additional features that support online display. Its design draws on expertise that ranges from traditional printing to hypertext and structured document display. It is a complex format that presents challenging programming problems. However, a wide selection of software tools is readily available. There are utilities that convert between PostScript and PDF. Because they share the same imaging model, the documents’ printed forms are equivalent. But PDF is not a full programming language, so when converting PostScript to it, loops and other constructs must be explicitly unwound. In PostScript, PDF's interactive features are lost.
Today, PDF is the format of choice for presenting finished documents online. But PostScript is pervasive. Any application that can print a document can save it as a PostScript file, whereas standard desktop environments sometimes lack software to generate PDF. From a digital library perspective, collections (for example, CiteSeer for Scientific publications) frequently contain a mixture of PostScript and PDF documents. The problems of extracting text for indexing purposes are similar and can be solved in the same way. Some software viewers can display both formats.
4.6. Word-Processor Documents
When word processors store documents, they do so in ways that are specifically designed to support editing. Microsoft Word—currently a leading product—is a good example. Three different styles of document format are associated with Word: Rich Text Format (RTF), a widely published specification dating from 1987; a proprietary internal format that we call simply
native Word, which has evolved over many years; and an XML-based format called Microsoft Office Open XML, which is planned for 2010. We also describe the Open Document format, which is based on XML, XSL, and associated standards, and does not differ markedly from Microsoft's product. We end this discussion by describing an example of a completely different style of document description language, LaTeX, which is widely used in the scientific and mathematical community. LaTeX is very flexible and is capable of producing documents of excellent quality; however, it has the reputation of being difficult to learn and unsuitable for casual use.
RTF is designed to allow word-processor documents to be transferred between applications. Like PostScript and PDF, it uses ASCII text to describe page-based documents that contain a mixture of formatted text and graphics. Unlike them, it is specifically designed to support the editing features we have come to expect in word processors. For example, when Word reads an RTF document generated by WordPerfect or OpenOffice (or vice versa), the file must contain enough information to allow the program to edit the text, change the typesetting, and adjust the pictures and tables. This contrasts with PostScript, where the typography of the document might as well be engraved on a Chinese stone tablet. PDF, as we have seen, supports limited forms of editing—adding annotations or page numbers, for example—but is not designed to have anything approaching the flexibility of RTF.
Many online documents are in native Word format, a binary format that is more compact than RTF, and thus yields faster download and display times. Native Word also supports a wider range of features and is tightly coupled with Internet Explorer, Microsoft's Web browser, so that a Web-based digital library using Word documents can provide a seamless interface. But native Word has disadvantages. Non-Microsoft communities may be locked out of digital libraries unless other formats are offered. Although documents can be converted to forms like HTML using scriptable utilities, Word's proprietary nature makes this challenging—and it is hard to keep up to date. Even Microsoft products sometimes can't read Word documents properly; indeed, opening a file in a version of Word other than the one with which it was created can cause incorrect display of the document. Native Word is really a family of formats rather than a single one and it has nasty legacy problems.
Rendering documents in XML ensures—at least in theory—that they can be read even when the software that created them is not available, provided that details of the format have been published. Microsoft has been working on XML versions of its internal document formats since before 2000, and a new file format for Word was announced in 2002. In 2004, the European Union recommended that Microsoft standardize this, and the following year Microsoft announced it would do so. The result is Office Open XML (OOXML), which was approved as an ISO international standard in 2008. At the time of writing, Microsoft Office 14 (the working title of the next version) has been billed as the first version to support this standard. It also appeared that a service pack would be released to enable Word 2007 to read and write ISO standard OOXML files.
The Open Document Format for Office Applications (ODF) is another standard that represents word-processor documents in XML format. It was created under the auspices of the Organization for the Advancement of Structured Information Standards and is supported by several office productivity tools, most notably the open-source OpenOffice suite. Both ODF and OOXML are billed as a good solution for long-term document presentation, and in fact the differences between them are not large. However, the debate between their proponents is heated.
Rich Text Format: RTF
Figure 4.22a recasts the
Welcome example of Figure 4.18 in minimal RTF form. It renders the same text in the same font and size as the PostScript and PDF versions, although it relies on defaults for such things as margins, line spacing, and foreground and background colors.
 |
 |
| Figure 4.22: More ways of producing the document of Figure 4.18a: (a) RTF specification; (b) OpenDocument |
RTF uses the backslash () to denote the start of formatting commands. Commands contain letters only, so when a number (positive or negative) occurs, it is interpreted as a command parameter—thus
yr2001 invokes the
yr command with the value 2001. The command name can also be delimited by a single space, and any symbols that follow—even subsequent spaces—are part of the parameter. For example, {
title Welcome example} is a
title command with the parameter
Welcome example.
Braces {…} group together logical units, which can themselves contain further groups. This allows hierarchical structure and permits the effects of formatting instructions to be lexically scoped. An inheritance mechanism is used. For example, if an instruction is not explicitly specified at the current level of the hierarchy, a value that is specified at a higher level will be used instead.
Line 1 of Figure 4.22a gives an RTF header and specifies the character encoding (ANSI 7-bit ASCII), default font number (0), and a series of fonts that can be used in the document's body. The remaining lines represent the document's content, including some basic metadata. On line 3, in preparation for generating text,
pard sets the paragraph mode to its default, while
plain initializes the font character properties. Next,
f1 makes entry 1 in the font table—which was set to Helvetica in the header—the currently active font. This overrides the default, set up in our example to be font entry 0 (Times Roman). Following this, the command
fs28—whose units are measured in half points—sets the character size to 14 points.
Text that appears in the body of an RTF file but is not a command parameter is part of the document content and is rendered accordingly. Thus lines 4 through 8 produce the greeting in several languages. Characters outside the 7-bit ASCII range are accessed using backslash commands. Unicode is specified by u: here we see it used to specify the decimal value 228, which is LATIN SMALL LETTER A WITH DIAERESIS, the fourth letter of
Akwäba.
This is a small example. Real documents have headers with more controlling parameters, and the body is far larger. Even so, this example is enough to illustrate that RTF, unlike PostScript, is not intended to be laid out visually. Rather, it is designed to make it easy to write software tools that parse document files quickly and efficiently.
RTF has evolved through many revisions—over the years its specification has grown from 34 pages to over 240. Additions are backward-compatible to avoid disturbing existing files. In Figure 4.22a's opening line, the numeric parameter
rtf1 gives the version number, 1. The format has grown rapidly because, as well as keeping up with developments like Unicode in the print world, it must support an ever-expanding set of word-processor features, a trend that continues.
Basic types
Now we flesh out some of the details. While RTF's syntax has not changed since its inception, the command repertoire continues to grow. There are five basic types of command:
flag,
toggle,
value,
destination, and
symbol.
A
flag command has no argument. (If present, arguments are ignored.) One example is
box, which generates a border around the current paragraph; another is
pard, which—as we have seen—sets the paragraph mode to its default. A
toggle command has two states. No argument (or any nonzero value) turns it on; zero turns it off. For example,
b and
b0 switch boldface on and off, respectively. A
value command sets a variable to the value of the argument. The
deff0 in Figure 4.22a is a value command that sets the default font to entry zero in the font table.
A
destination command has a text parameter. That text may be used elsewhere, at a different destination (hence the command's name)—or not at all. For example, text given to the
footnote command appears at the bottom of the page; the argument supplied to
author defines metadata that does not actually appear in the document. Destination commands must be grouped in braces with their parameter—which might itself be a group. Both commands specified in {
info{
title Welcome example}} are destination commands.
A
symbol command represents a single character. For instance,
bullet generates the bullet symbol (•), and { and } produce braces, escaping their special grouping property in RTF.
Backward compatibility
An important symbol command that was built in from the beginning is *. Placed in front of any destination command, it signals that if the command is unrecognized it should be ignored. The aim is to maintain backward compatibility with old RTF applications.
For instance, there was no Unicode when RTF was born. An old application would choke on the
Welcome example of Figure 4.22a because the
u command is a recent addition. In fact it would ignore it, producing
Akwba—not a good approximation.
The * command provides a better solution. As well as
u, two further new commands are added for Unicode support. Rather than generating
Akwäba by writing
Akw
u228ba—which works correctly if Unicode support is present but produces
Akwba otherwise—one instead writes
{upr{Akwaba}{*ud{Akwu228ba}}}
The actions performed by the two new commands
upr and
ud are very simple, but before we reveal what they are, consider the effect of this command sequence on an older RTF reader that does not know about them. Unknown commands are ignored but their text arguments are printed, so when the reader works its way through the two destination commands, the first generates the text
Akwaba while the second is ignored because it starts with *. This text is a far more satisfactory approximation than
Akwba. Now consider the action of a reader that knows how to process these directives. The first directive,
upr, ignores its first argument and processes the second one. The second directive,
ud, just outputs its argument—it is really a null operator and is only present to satisfy the constraint that * is followed by a destination command.
File structure
Figure 4.23 shows the structure of an RTF file. Braces enclose the entire description, which is divided into two parts: header followed by body. We have already encountered some header components; there are many others. A commonly used construct is
table, which reserves space and initializes data—the font table, for example. The
table command takes a sequence of items—each a group in its own right, or separated using a delimiter, such as semicolon—and stores the information away so that other parts of the document can access it. A variety of techniques are deployed to retrieve the information. In a delimited list, an increasing sequence of numeric values is implied for storage, while other tables permit each item to designate its numeric label, and still others support textual labels.
The first command in the header must be
rtf, which encodes the version number followed by the character set used in the file. The default is ASCII, but other encoding schemes can be used. Next, font data is initialized. There are two parts: the default font number (optional) and the font table (mandatory). Both appear in the
Welcome example, although the font table has many more capabilities, including the ability to embed fonts.
The remaining tables are optional. The file table is a mechanism for naming related files and is only used when the document consists of subdocuments in separate files. The color table comprises
red,
green, and
blue value commands, which can then be used to select foreground and background colors through the commands
cf1 and
cb2, respectively. The style sheet is also a form of table. It corresponds to the notion of
styles in word processing. Each item specifies a collection of character, paragraph, and section formatting. Items can be labeled; they may define a new style or augment an existing one. When specified in the document body, the appropriate formatting instructions are brought to the fore. List tables provide a mechanism for bulleted and enumerated lists (which can be hierarchically nested). Revision tables provide a way of tracking revisions of a document by multiple authors.
The document body contains three parts, shown in Figure 4.23: top-level information, document formatting, and a sequence of sections (there must be at least one). It begins with an optional information group that specifies document-level metadata—in our example this was used to specify the title. There are over 20 fields, among them author, organization, keywords, subject, version number, creation time, revision time, last time printed, number of pages, and word count.
Next comes a sequence of formatting commands (also optional). Again there are dozens of possible commands: they govern such things as the direction of the text, how words are hyphenated, whether backups are made automatically, and the default tab size (measured in
twips, an interestingly named unit that corresponds to one-twentieth of a point).
Finally, the last part of the body specifies the document text. Even here the actual text is surrounded by multiple layers of structure. First the document can be split into a series of sections, each of which consists of paragraphs (at least one). Sections correspond to section breaks inserted by an author using, for instance, Microsoft Word. Sections and paragraphs can both begin with formatting instructions. For sections, formatting instructions control such things as the number and size of columns on a page, page layout, page numbering, borders, and text flow and are followed by commands that specify headers and footers. For paragraphs, formatting instructions include tab settings, revision marks, indenting, spacing, borders, shading, text wrapping, and so forth. Eventually you get down to the actual text. Further formatting instructions can be interspersed to change such things as the active font size.
Other features
So far we have seen how RTF specifies typographic text, based around the structure of sections and paragraphs. It has many other features. Different sampled image formats are supported, including open standards like JPEG and PNG (see Section 5.3) and proprietary formats like Microsoft's Windows Metafile and Macintosh's PICT. The raw image data can be specified in hexadecimal using plain text (the default) or as raw binary—in which case care must be taken when transferring the file between operating systems (recall the discussion of FTP's new-line handling in Section 4.1).
Built into many word processors are tools that draw lines, boxes, arcs, splines, filled-in shapes, text, and other vector graphic primitives. RTF contains over 100 commands to draw, color, fill, group, and transform such shapes. The resulting shapes resemble the graphical shapes that can be described in PostScript and PDF.
Authors use annotations to add comments to a document. RTF can embed within a paragraph a destination command with two parts: a comment and an identifying label (typically used to name the person responsible for the annotation).
Field entities introduce dynamically calculated values, interactive features, and other objects requiring interpretation. They are used to embed today's date, the current page number, mathematical equations, and hyperlinks into a paragraph. They bind a field instruction command together with its most recently calculated value—which provides backup should an application fail to recognize the field. Accompanying parameters influence what information is displayed, and how. Fields allow metadata such as title and author to be associated with a document, and this information is stored in the RTF file in the form of an
info command. RTF uses the field mechanism to support indexes and a table of contents.
In a word-processor document, bookmarks are a means of navigation. RTF includes
begin- and
end-bookmark commands that mark segments of the text along with text labels, accessible through the word-processing application. Microsoft has a scheme called
object linking and embedding (OLE) that places information created by one application within another. For example, an Excel document can be incorporated into a Word file and still function as a spreadsheet. RTF calls such entities
objects and provides commands that wrap the data with basic information, such as the object's width and height and whether it is linked or embedded.
Commands in the document format section control the overall formatting of footnotes (which in RTF terminology includes endnotes). The
footnote command is then used within paragraphs to provide a footnote mark and the accompanying text.
RTF tables are produced by commands that define cells, rows, and the table itself. Formatting commands control each component's dimensions and govern how text items are displayed—e.g., pad all cells by 20 twips, set this cell's width to 720 twips and center its text, and so on. However, there is a twist. While the other entities described earlier are embedded within a paragraph, an RTF table
is a paragraph and cannot be embedded in one—this definition reflects the practice visible in Word, where inserting a table always introduces a new paragraph.
Using RTF in a digital library
When building a digital library collection from RTF documents, the format's editable nature is of minor importance. Digital libraries generally deal with completed documents—information that is ready to be shared with others. What matters is how to index the text and display the document.
To extract rudimentary text from an RTF file, simply ignore the backslash commands. The quality of the output improves if other factors, such as the character set, are taken into account. Ultimately, full-text extraction involves parsing the file. RTF was designed to be easy to parse. Three golden rules are emphasized in the specification:
• Ignore control words that you don't understand.
• Always understand *.
• Remember that binary data can occur when skipping over information.
RTF files can usually be viewed on Macintosh and Windows computers. Different formats may be more appropriate for other platforms or for speedier access. For example, software is available to convert RTF documents to HTML.
Native Word formats
For much of its history the native Microsoft Word format has been proprietary and its details shrouded in mystery. Although Microsoft has published “as is” their internal technical manual for the Word 97 version, the format continued to evolve. Finally, in 2008, Microsoft made the specification publicly available. (Of course, this does not help people with legacy documents.) Native Word is primarily a binary format, and the abstract structures deployed reflect those of RTF. Documents include summary information, font information, style sheets, sections, paragraphs, headers, footers, bookmarks, annotations, footnotes, embedded pictures—the list goes on. The native Word representation provides more functionality than RTF and is therefore more intricate.
A serious complication is that documents can be written to disk in Fast Save mode, which no longer preserves the order of the text. Instead, new edits are appended, and whatever program reads the file must reconstruct its current state. If this feature has been used, the header marks the file type as “complex.”
Using native Word in a digital library
To extract text from Word documents for indexing, one solution is to first convert them to RTF, whose format is better described. The Save As option in Microsoft Word does this, and the process can be automated through scripting. (Visual Basic is well suited to this task.) It may be more expeditious to deliver native Word than RTF because it is more compact. However, non-Microsoft users will typically need a more widely supported option, although this trend is shifting with the advent of OpenOffice.
Word has a Save As HTML option. While the result displays well in Microsoft's Internet Explorer browser, it is generally less pleasing in other browsers (although it can be improved by performing certain postprocessing operations). Public domain conversion software cannot fully implement the Fast Save format because of lack of documentation and may generate all the text in the file rather than just the text in the final version. The solution is simple: switch this option off and resave all documents (using scripting).
Office Open XML: OOXML
Office Open XML is a new standard designed by Microsoft to represent, in human-readable XML form, Word and other Microsoft Office documents (spreadsheets, presentations, etc.). It was designed specifically for the features in Microsoft Office and is constrained by the need to be backward-compatible with documents created in the binary format. There has been vigorous discussion of the relative merits of OOXML and the Open Document (ODF) format (described in the next section). ODF was designed as a general office document markup language, unconstrained by the features of existing word processors. It is helpful to keep in mind the fact that these two languages were designed for different purposes and will probably be used in different ways.
Although the next section contains a brief technical account of ODF, we omit a technical description of OOXML. One reason is that these are extremely complex standards—the OOXML specification is more than 6,000 pages long, and ODF's contains 722 pages. Instead, we give a flavor of the debate, which is often heated. Critics of OOXML complain that (for example)
• The standard is controlled by a single commercial company (Microsoft).
• It does not follow established standards for dates, graphics, formulas.
• Parts of it use non-XML formatting codes and are unreadable by XML parsers.
• Components of OOXML can be linked to Windows applications and can be understood only in a Windows context.
Proponents counter these criticisms by pointing out that naturally some OOXML elements are not supported by other software or other formats. Indeed, a project to translate documents from OOXML to ODF (funded in part by Microsoft) found that not all aspects of Office documents could be faithfully rendered. The problem basically stems from the fact that its design requirements force OOXML to capture all features of Microsoft Office, no matter how idiosyncratic or arcane they appear to others.
On the other side, critics of ODF complain that (for example)
• It lacks standard ways of rendering macros, tables, and mathematical symbols.
• It ignores the semantics of spreadsheet formulae.
• The documentation is insufficiently detailed for vendors who seek to build their own ODF software.
• It is not well enough defined to support fully interoperable applications.
In practice, its proponents say, ODF developers will naturally look to OpenOffice for canonical implementations that clarify features like spreadsheet formulae (which seem to have become a specific bone of contention). The code is there for anyone to view, and the XML output can be trivially inspected—providing a supplement to the standard in the form of an operational implementation. Of course, this is a very different philosophy from Microsoft's.
Although there are certainly differences between the two standards, advocates on both sides usually admit that the differences are not essential—certainly not when it comes to the interoperability and preservation of textual documents. Perhaps the real issue is the potential effect of each standard in the marketplace. ODF may be specified in less detail, but it offers the flexibility to create new products, which encourages competition. OOXML is aimed at reproducing Office documents and makes it easier for other products to work with Office—but does not encourage vendors to replace it.
At any rate, OOXML will be a great improvement over the native Word formats for designers of digital libraries.
Open Document format: ODF
The Open Document format can describe word-processor documents, spreadsheets, presentations, drawings, graphics, images, charts, mathematical formulas, and documents that combine elements of any of these. They are stored in files whose extensions contain “.od” followed by a single letter indicating the document type: .
odt for text documents, .
ods for spreadsheets, .
odp for presentation programs, .
odg for graphics.
A basic ODF document is an XML file with <
document> as its root element. (Open Document files can also take the format of a ZIP compressed archive containing a number of files and directories as described below.) Figure 4.22b shows the
Welcome example of Figure 4.18a in minimal ODF form. It renders the same text as the PostScript, PDF, and RTF versions, although it uses the default font and size. After the obligatory XML processing application statement, the document is defined by its root element, <
office:document>, in the
office namespace. This begins with four namespace definitions. In practice, ODF files usually define more namespaces—including ones for Formatting Objects (called
fo) used in Section 4.4—but these four are enough to make this rudimentary example work. The namespaces that begin with
urn are Uniform Resource Names (see Section 7.3).
Metadata can be stored along with documents, either with a set of metadata elements that are pre-defined in Open Document or using any user-defined metadata set. We have illustrated this by including two metadata elements specified in the Dublin Core standard (see Section 6.2). The namespace beginning with
http:// is for the Dublin Core standard, and is only necessary because the example uses it to specify some metadata.
Following the metadata is the text of the document, nested inside the appropriate
office tags. The <
text:p> tag specifies a paragraph. As you can see, Unicode characters can be included using the ordinary # notation of HTML and XML.
In order to make the text appear in Helvetica font as it does in Figure 4.18a, the <
text:p> statement near the end of Figure 4.22b needs to be augmented with a
style-name attribute to read
<text:p text:style-name="Normal">
Welcome Haere mai Wilkommen Bienvenue Akwäba
</text:p>
To make this work, the Normal text style must be explicitly defined using a statement like
<style:style style:name="Normal">
<style:text-properties style:font-name="Helvetica"/>
</style:style>
In reality the specifications are slightly more convoluted and verbose, which is why we have not included the details here. One cardinal advantage of XML-style document specifications over the others discussed previously is that it is very easy to create examples and study them to see what is going on.
Open Document files
Figure 4.22b shows a single file containing an entire document in the root XML tag <
office:document>. This represents the document content, metadata, and any styles defined in the document (there are none in Figure 4.22b). It also includes any document “settings,” which are properties that are not related to the document's content or layout, like the zoom factor or the cursor position (again, there are none here).
These four parts are usually separated by placing the components in separate XML files (
content.xml,
meta.xml,
settings.xml, and
styles.xml) instead. The single top-level <
office:document> would be replaced by four top-level roots, one for each file:
• <office:document-content>
• <office:document-meta>
• <office:document-styles>
• <office:document-settings>
The
content file is the most important, and carries the actual content of the document (except for binary data, like images). The
style file contains most of the stylistic information—Open Document makes heavy use of styles for formatting and layout.
Although Figure 4.22b shows a readable XML file, ODF files are compressed into ZIP archives to reduce their size. Furthermore, an additional file (called
mimetype) must be present in the archive, containing a single line specifying the document type—whether a textual document, spreadsheet, presentation file, or graphics. This makes the file extension (.
odt, .
ods, .
odp, or .
odg) immaterial to the format: it's only there for the user's benefit.
Formatting
Open Document has a comprehensive repertoire of formatting controls that dictate how information is displayed. Style types include:
• paragraph styles
• page styles
• character styles
• frame styles
• list styles.
There are many attributes that dictate the style of specific parts of the text, paragraphs, sections, tables, columns, lists, and fills. Characters can have their font, size, and other properties set. The vertical arrangement of paragraphs can be controlled through attributes that keep lines together and avoid widows and orphans; other attributes (such as “drop caps”) provide special formatting for parts of a paragraph.
The usual range of document structuring options is provided, including headings at different levels, numbered and unnumbered lists, numbered paragraphs, and change tracking. Section attributes can be used to control how the text is displayed. Documents can include hyperlinks, bookmarks, and references. Text fields can contain automatically generated content, and there are mechanisms for generating tables of contents, indexes, and bibliographies.
Page layout is controlled by attributes such as page size, number format, paper tray, print orientation, margins, borders, padding, shadow, background, columns, print page order, first page number, scale, table centering, maximum footnote height and separator, and many layout grid properties. Headers and footers can have defined fixed and minimum heights, margins, border line width, padding, background, shadow, and dynamic spacing.
Using ODF in a digital library
Like any well-defined XML-based standard, the Open Document format makes it easy to handle, process, and re-present documents in the way that digital libraries do. As the name implies, the standard is “open.” The natural verbosity of XML is curbed using a standard compression mechanism, ZIP, which renders the resulting files significantly smaller than other document files, such as Word's .
doc files. Yet the information is readable and processable. To see the contents of an
.odt file, you first decompress it, and then the data is exposed in simple text-based XML files whose content can be easily examined, modified, and processed.
The use of separate files for the content, metadata, style, and settings is designed to make it easy to process these components in different ways. Most digital libraries will simply ignore the settings. The fact that metadata resides in its own file eliminates the need to parse the entire document just to determine its metadata. The fact that style information is separate means that indexers can focus on the textual content of documents. Future digital libraries that deal only with such documents will be easier to construct and maintain, because they will not have to grapple with the complexity that is presently required to isolate such components as plain text and metadata in document formats like PostScript, PDF, and native Word. Legacy documents, unfortunately, will continue to pose problems.
Scientific documents: LaTeX
LaTeX—pronounced
la-tech or
lay-tech—takes a completely different approach to document representation. Word processors present users with a “what you see is what you get” interface that is specifically intended to hide the gory details of internal representation. In contrast, LaTeX documents are expressed in plain ASCII text and contain typed formatting commands: they explicitly and intentionally give the user direct access to all the internal representation details. Any text editor on any platform can be used to compose a LaTeX document. To view the formatted document, or to generate hard copy, the LaTeX program converts it to a page description language—generally PostScript, but PDF and HTML are possible too.
LaTeX is versatile, flexible, and powerful. It can generate documents of exceptionally high typographical quality. The downside, however, is an esoteric syntax that many people find unsettling and hard to learn. It is particularly good for mathematical typesetting and has been enthusiastically adopted by members of the academic, scientific, and technical communities. It is a nonproprietary system, and excellent implementations are freely available.
Figure 4.24 shows a simple example. Commands in the LaTeX source (Figure 4.24a) are prefixed by the backslash character, . All documents have the same overall structure. They open with
documentclass, which specifies the document's principal characteristics (article, report, book, etc.) and gives options, such as paper size, base font size, and whether to print single-sided or back-to-back. Then follows a preamble that gives an opportunity to set up global features before the document content begins. Here “packages” of code can be included. For example,
usepackage{
epsfig} allows Encapsulated PostScript files, generally containing the artwork for figures, to be included.


The document content lies between
begin{
document} and
end{
document} commands. This
begin …
end structure is used to encapsulate many structural items: tables, figures, lists, bibliography, abstract. The list is endless, because LaTeX allows users to define their own commands. Furthermore, you can wrap up useful features and publish them on Internet sites so that others can download them and access them through
usepackage.
As a document is written, most text is entered normally. Blank lines are used to separate paragraphs. A few characters carry special meaning and must therefore be “escaped” by a preceding backslash whenever they occur in the text; Figure 4.24 contains examples. Structural commands include
section, which generates an automatically numbered section heading (
section* omits the numbering, while
subsection,
subsubsection, … are used for nested headings). Formatting commands include
emph, which uses italics to emphasize text, and , which superimposes an umlaut on the character that follows. There are hundreds more.
The last part of Figure 4.24a specifies a mathematical expression. The
begin{
displaymath} and
end{
displaymath} commands switch to a mode that is tuned to represent formulas, which activates additional commands specially tailored to this purpose. LaTeX contains many shortcuts—for example, math mode can alternatively be entered by using dollar signs as delimiters.
Using LaTeX in a digital library
LaTeX is a popular source format for collections of mathematical and scientific documents. Of course these documents can be converted to PostScript or PDF and handled in this form instead—which allows them to be mixed with documents produced by other means. However, this lowest-common-denominator approach loses structural and metadata information. In the case of LaTeX, such information is signaled by commands for title, abstract, nested section headings, and so on.
If, on the other hand, the source documents are obtained in LaTeX form and parsed to extract structural and metadata information, the digital library collection will be richer and provide its users with more support. It is easy to parse LaTeX to identify plain text, commands and their arguments, and the document's block structure.
However, there are two problems. The first is that documents no longer occupy a single file—they use external files such as the “packages” mentioned earlier—and even the document content can be split over several files if desired. In practice it can be surprisingly difficult to obtain the exact set of supporting files that were intended to be used with a particular document. Experience with writing LaTeX documents is necessary to understand which files need copying and, in the case of extra packages, where they might be installed.
The second problem is that LaTeX is highly customizable, and different authors adapt standard commands and invent new ones as they see fit. This makes it difficult to know in advance which commands to seek to extract standard metadata. However, new commands in LaTeX are composites of existing ones, and one solution is to expand all commands to use only built-in basic features.
4.7. Other Documents
Many other document types might be included in a digital library. Prominent among them are multimedia documents, which are discussed in the next chapter, but some other kinds of predominantly textual documents are worth a brief mention.
Spreadsheets and presentation files
We have mentioned spreadsheets and presentation files (such as PowerPoint) when discussing Office Open XML and the Open Document format. Both spreadsheets and presentation files have traditionally been encoded in proprietary binary file formats, like native Word documents. They may be presented to the user either in their native form or as PDF image files (or both). Of course, this presentation loses much information, notably the dynamic functionality of a spreadsheet involving formulas and the dynamic aspects of a presentation.
In order to index such files, the text can be extracted using the same procedure as for native-format text documents: use a Save As option to generate a more text-friendly form, such as ASCII (using the CSV or comma-separated values format) or XML for spreadsheets, and HTML or PDF for presentations. In future, open XML-based formats, such as OOXML or ODF (which, as we discuss above, apply to these files as well as to textual documents), will make life much easier.
E-mail documents are also candidates for inclusion in digital libraries. Early in the history of international computer networks, there were multiple e-mail clients having various incompatible formats. Seeking interoperability, the U.S. Department of Defense funded efforts to create standards. The result is a set of international standards for e-mail and e-mail extensions called Multipurpose Internet Mail Extensions (MIME). This is the
de facto standard on the Internet.
However, corporate e-mail systems often use their own internal format and communicate with servers using a vendor-specific, proprietary protocol. The servers act as gateways for sending and receiving messages over the Internet, which involves undertaking any necessary reformatting. For mail sent and received within a single company, the entire transaction may take place within the corporate system.
Mail is not usually sent directly to a digital library but is imported from wherever it happens to be stored. This can be the user's e-mail client, or their server, or both places. There are two common standard formats for mailboxes (
Maildir and
mbox), but several prominent clients use their own proprietary format and conversion software is needed to transfer mail between them—or to ingest it into digital libraries.
Internet e-mail messages have a header and body, separated by a blank line. The former contains metadata and is structured into fields, such as sender, receiver, date, title, and other information. It also includes the clock time and time zone, which together define the actual time the message was sent. The body contains the message content in the form of unstructured text, and sometimes ends with a signature block.
E-mails often contain attachments, which are files that are sent along with the message, encoded as part of the message to which they are attached. In the Internet MIME format, messages and their attachments are sent as a single multipart message, using an encoding scheme (called “base64”) for non-text attachments that represents binary information as printable ASCII.
There are many problems with e-mail as it used today. For example, a standard way to quote text is to start each line with the “>” character, possibly followed by a space. Unfortunately e-mail readers usually wrap lines to fit the screen size, or to some predetermined maximum length. Quoting makes the lines overflow. Figure 4.25 shows a message that has been quoted several times. The mailer has tried to wrap the lines, but it has put only a single quote on the continuation lines, not realizing that the text being wrapped has four levels of quotes. Messages become unintelligible after a few cycles of such mutilation.

4.8. Notes and Sources
The ASCII code is central to many pieces of hardware and software, and the code table turns up everywhere in reference material, printed manuals, online help pages, Web sites, and even this book! At its inception, few could have predicted how widely it would spread. Of historical interest is the ANSI (American National Standards Institute, 1968) standard, a version of which was published (prior to final ratification) in
Communications of the ACM (Gorn et al., 1963).
The principal aim of ASCII was to unify the coding of numeric and textual information—the digits and the Roman alphabet—between different kinds of computer equipment. However, decisions about other symbols have had a subtle yet profound influence. In the 1960s few keyboards had a backslash key, yet so ingrained is its use today to convey special meanings—such as a directory separator and to protect the meaning of certain characters in certain contexts—that computing would be almost inconceivable without it. It is here that the concept of
escaping appeared for the first time.
The official title for Unicode is tongue-twisting and mind-boggling: The International Standard ISO/IEC 10646-1, Information Technology—Universal Multiple-Octet Coded Character Set (UCS). Chapter 8 gives more information about the Unicode standard, particularly with regard to its use for non-English languages.
Technical details of searching and indexing are presented in
Managing Gigabytes (Witten et al., 1999), which gives a comprehensive and detailed technical account of how to index documents and to make them rapidly accessible through full-text queries. This and other relevant books on information retrieval are included in the “Notes and sources” section of Chapter 3 (Section 3.7).
High-performance OCR products are invariably commercial: we know of no public-domain systems that attain a level of performance comparable to commonly used proprietary ones. One of the most accurate free software OCR engines currently available is Tesseract (http://code.google.com/p/tesseract-ocr/), which was originally developed at Hewlett-Packard from 1985 to 1995, and, after lying dormant for ten years, was taken over by Google and released under the Apache open source license. Another project is Ocrad, the Gnu OCR project (www.gnu.org/software/ocrad).
The interactive OCR facilities described in Section 4.2 are well exemplified by the Russian OCR program FineReader (ABBYY Software, 2000), an excellent example of a commercial OCR system. Lists of OCR vendors are easily found on the Web, as are survey articles that report the results of performance comparisons for different systems. The newsgroup for OCR questions and answers is comp.ai.doc-analysis.ocr. Price-Wilkin (2000) gives a nontechnical review of the process of creating and accessing digital image collections, including a sidebar on OCR by Kenn Dahl, the founder of a leading commercial OCR company. The OCR shop we visited in Romania is
Simple Words (now at www.itprovision.com), a well-organized and successful private company that specializes in high-volume work for international and nongovernment organizations.
The Māori language has fifteen sounds: the five vowels
a,
e,
i,
o, and
u, and ten consonant sounds written
h,
k,
m,
n,
p,
r,
t,
w,
ng, and
wh. Thus the language is written using fifteen different letters. The first eight consonant sounds are pronounced as they are in English; the last two are digraphs pronounced as the
ng in
singer and the
wh in
whale, or as
f. Each vowel has a short and long form, the latter being indicated by a macron, as in the word
Māori.
The ß or
scharfes s character in German has been the source of great controversy in recent years. In 1998 a change in the official definition of German replaced some, but not all, occurrences of ß by
ss. However, spelling reform has proven unpopular, and the traditional spelling system is still used by some newspapers and periodicals, including the widely read daily tabloid
Bild-Zeitung and two of Germany's most respected newspapers, the
Frankfurter Allgemeine Zeitung and
Die Welt.
All file formats described in this chapter are well documented, except where commercial interests prevail. There is a rich vein of online resources, as you might expect from the area and the working habits of those in it, which are easy to find using Internet classification directories and resources like the Wikipedia.
The definitive guides to PostScript and PDF are the reference manuals produced by Adobe (1999, 2000), the company responsible for these formats. They practice what they preach, putting their manuals online (in PDF format) on their Web site (www.adobe.com). A supplementary tutorial and cookbook (Adobe, 1985) gives worked examples in the PostScript language.
Ghostscript is a software PostScript interpreter that provides a useful means of experimentation. Released under the GNU Public License, it is available for all popular platforms (www.ghostscript.com). Our description of PostScript and PDF mentions several graphics techniques, such as transformations, clipping, and spline curves, that are explained in standard textbooks on computer graphics (e.g., Foley et al., 1990). The technique for extracting plain text from PostScript files is described by Nevill-Manning et al. (1998). The PDF redaction failure involving Facebook and another social networking site, ConnectU, is described in Benetton (2009). The problem is serious enough that the U.S. National Security Agency provides guidelines on how to redact properly (National Security Agency, 2006). Background information on the archival PDF/A format is at www.pdfa.org.
An initial description of Microsoft's RTF format appears in
Microsoft Systems Journal (Andrews, 1987), and its continued expansion is documented through the Microsoft Developers’ Network. Subscribers receive updates on CD-ROM, while the same information is provided for general consumption at http://msdn.microsoft.com. At one stage, an internal technical document describing the native Word format was published through this outlet, but it has since been discontinued. Information about OOXML can be found here. The ODF manual and other documentation are at the Organization for the Advancement of Structured Information Standards Web site, www.oasis-open.org.
LaTeX, which is based on the TeX system invented by Knuth (1986), is described in many books, such as Lamport (1994). A useful online source is Tobias Oetiker's
Not so short introduction to LaTeX2e at http://tobi.oetiker.ch/lshort. Bountiful collections of packages can be found on Internet sites like the Comprehensive TeX Archive Network (www.ctan.org).
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.