
Chapter 6. Metadata
Elements of organization
If thorough and consistent metadata has been created, it is possible to conceive of its use in an almost infinite number of new ways …
If thorough and consistent metadata has been created, it is possible to conceive of its use in an almost infinite number of new ways …
Metadata, often described as
data about data, is critical to all forms of organized digital content. It is the means by which all organization in a digital library is achieved, and much of what you have read in this book so far implicitly assumes its existence. Whether in the creation of surrogates (Section 3.3), categories of video browsing (Section 5.4), or usage information (Section 2.2), it is metadata that yields collections that are
organized, rather than digital piles of unstructured and unconnected objects.
Specifically, metadata enables almost all the examples of digital library technology that we have seen in this book, including
• the item displays and surrogates in the Pergamos Digital Library in Figure 1.10;
• the browsing structures of
subjects,
titles a-z,
organization, and
how to of the
Village Brickmaking collection in Figure 3.1;
• the table of contents of the
Otago Witness newspaper in Figure 3.4d;
• the colored tabs marking the chapters in the realistic book
Farming Snails I in Figure 3.5b;
• the entire record display in Figure 3.9a;
• the structured form searching interface in Figure 3.15;
• the searching interface in Figure 3.17;
• the structured subject browsing of Figure 3.20;
• the user log graphs in Figure 2.4.
Metadata is generally taken to be structured information about a particular information resource. Information is “structured” if it can be meaningfully manipulated without understanding its content. For example, given a collection of source documents, bibliographic information about each document would be metadata for the collection—the structure is made plain, in terms of which pieces of text represent author names, which represent titles, and so on. But given a collection of bibliographic information, metadata might also comprise some information about each bibliographic item, such as who compiled it and when.
The role of metadata in your digital library can be clarified by considering such questions as:
• Where does your metadata come from? Is it automatically extracted from digital objects, manually assigned, or imported from an external source?
• How will the metadata affect document display, browsing, searching, and maintenance of the digital library?
• Does the metadata need any extra processing before use? For example, do different versions of people's names need to be harmonized?
• Is the metadata in your digital library affected by the activities of the end-users?
• Can you monitor the metadata in your library to continually assess its quality?
• Is the metadata private to your library or can it be shared with others?
• Can you migrate your metadata to another software application?
This chapter starts with a description of different perspectives on metadata and how these perspectives frame the answers to the questions above. Then we consider the evolution of metadata in library catalog systems, as this has had a lasting influence on digital library systems. Following this, we describe how metadata represents material like multimedia content (Section 6.3) and complex compound objects (Section 6.4). We then consider how to process and assess metadata within the workflow of a digital library. Finally, in Section 6.6 we examine how metadata can be extracted from source documents—a key process in automating the construction of large-scale collections.
6.1. Characteristics of Metadata
Imagine when electronic books are cheap and high-quality enough to begin displacing printed books. Every time a student highlights or annotates a page, that information will be used—with permission—to enhance the public metadata about the book. Even how long it takes people to get through pages or how often they go back to particular pages…. We’ll be able to ask our books to highlight the passages most often read by poets, A [grade] students, professors of literature, or Buddhist priests.
Some of the earliest organized external descriptions for physical objects are found in Sumerian collections of clay tablets used for recording commercial transactions. As the number of items in a collection increased, the need for efficient mechanisms to find particular items and to simply manage the collection grew accordingly. Gradually, physical descriptions grew very complex and very large, as illustrated by the card catalogs of the 20th century (Figure 6.1). As with many other data-intensive applications, computers evolved as the appropriate tool for managing these descriptions. Some argue that descriptions only formally became
metadata when they were moved to an electronic context, but we prefer the inclusive approach that emphasizes the continuity of resource description.

The objects of description have also evolved, to include varied media, and, in museums, a panoply of diverse physical objects. As the described objects become digital, we move from the library to the digital library—but the principles of description for access and management remain largely the same. The topic of metadata for
digital libraries inherits a vast amount of work performed by librarians in creating, sharing, applying, and managing metadata for library collections.
There are several approaches to classifying metadata, depending on its source, purpose, audience, and format. In building a digital library, a practical concern is the source of the metadata: Where do the metadata values come from? How do we know that the author of the Word file on our hard disc is
John Smith? Broadly speaking, there are two possibilities: either a human has declared that Smith is the author, or a computer program has determined the author's identity.
In the case of
human-assigned metadata, a human being examines the digital document (or its physical counterpart) and assigns a particular value (
John Smith) to a particular metadata element (
the author). This person (often a librarian) may consult other documents or other people in the process of determining the metadata value, but the ultimate source of the metadata assignment is the human brain.
In the case of
computationally assigned metadata, a computer program, after processing the digital document (by comparing it with other documents or using remote online resources), outputs a value for the metadata element. If the document was
born digital (such as a word-processed document or an image from a digital camera), metadata may have been embedded within the file at the moment of its creation. If the document was digitized from an analog source (using OCR, for example), the software applications used often will have embedded metadata within the file (e.g., TIFF tags, see Section 6.3). Such embedded metadata is usually easily extracted from digital objects, although it is often of less use than metadata derived from human judgments.
For a specific library system, metadata values may be imported from an external source, but if you follow the metadata creation process back far enough, eventually you will reach either a human being or a computer program.
Irrespective of its source, where does the metadata actually reside? Is it embedded within a digital document, as in HTML or XML files, for example, or is it stored separately in library catalog records or some remote metadata repository? Many file formats contain embedded metadata that needs to be
extracted from the file before it can used to organize items in a digital library. The central issue is whether the file format is clearly documented and available for inspection. Where formats are publicly specified (e.g., PNG, PDF, ODF), it is relatively straightforward to extract metadata. However, when file formats are proprietary, programmers often have to resort to reverse engineering the format, which is time consuming and less reliable.
An alternative perspective is to consider the function of different types of metadata, such as
•
administrative metadata for managing resources, such as rights information;
•
descriptive metadata for describing resources, such as the cards in Figure 6.1;
•
preservation metadata for describing resources, such as recording preservation actions;
•
technical metadata related to low-level system information, such as data formats and any data compression used;
•
usage metadata related to system use, such as tracking user behavior.
One important aspect of this categorization is that it highlights the fact that the end user's view of metadata (Figure 6.1) is only the tip of the iceberg. Much of the metadata is not intended for public display, and in the case of
usage metadata, the ALA Code of Ethics (Figure 2.2) reminds us that some parts may be confidential. The categorization further illustrates that metadata is not
static. Although we might expect that data like author and publisher might not change over the lifetime of the object, metadata related to preservation and use is likely to change, perhaps frequently. We would also expect metadata to be generated by user enhancements such as annotations (see Section 2.5).
6.2. Bibliographic Metadata
Anyone working with digital libraries needs to know about the different standard methods for representing document metadata. Much of the work on metadata in digital libraries is based on practices that have been adopted in library cataloging, particularly the MARC (
machine-readable cataloging) format that has been used by libraries internationally for decades. The spread of electronic resources in the 1990s led to the creation of a new scheme called Dublin Core, which is an intentionally minimalist standard intended to be applied to a wide range of digital library materials by people who are not trained in library cataloging. These two schemes are of interest not only for their practical value, but also for highlighting diametrically opposed underlying philosophies. We also include descriptions of two bibliographic metadata formats: BibTeX and EndNote. The former is common in scientific and technical fields (and a companion to the LaTeX format described in Section 4.6), while the latter is in widespread general use (and integrates with Microsoft Word, for example).
MARC
[The MARC standard] forever changed the relationship of a library to its users, and the relationship of geography to information.
Managing metadata with software tools has a long history in libraries, mostly deriving from the necessity to move from card catalogs to computer-based records. The core work was the development of the MARC standard in the late 1960s by Henriette Avram at the Library of Congress. Once metadata was expressed in computer-based MARC records, it could be copied, distributed, and shared among libraries. MARC is a comprehensive and detailed standard whose use is carefully controlled and transmitted to budding librarians in library science courses. Here we have space to present only an outline of all its richness.
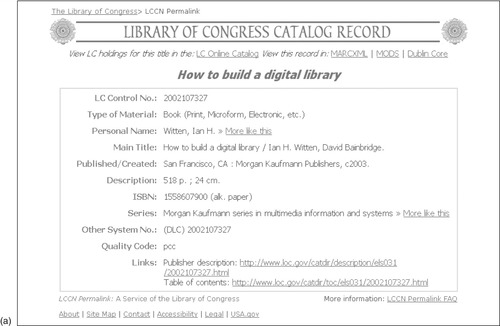
Figure 6.2a shows an entry that was obtained from the Library of Congress online catalog giving metadata for the first edition of this book,
How to Build a Digital Library. It includes information about authorship, topic coverage, details about the physical book itself, the publisher, various identification numbers, and links to more detailed information. This is an electronic record that describes a physical object, presented in a classic, familiar, library catalog style.
 |
 |
 |
 |
 |
 |
 |
| Figure 6.2: |
Producing a MARC record for a particular publication is an onerous undertaking that is governed by a detailed set of rules and guidelines called the
Anglo-American Cataloging Rules, familiarly referred to by librarians as
AACR2R (the
2 stands for second edition, the final
R for revised). These rules, inscribed in a formidable handbook, are divided into two parts: Part 1 applies mostly to the description of documents, Part 2 to the description of works. Part 2, for example, treats
Headings, Uniform titles, and References (i.e., entries starting with “See …” that capture relationships between works). Under
Headings there are sections on how to write people's names, geographic names, and corporate bodies. Appendices describe rules for capitalization, abbreviations, and numerals.
The rules in
AACR2R are highly detailed, almost persnickety. It is hard to convey their flavor in a few words. Here is one example: How should you name a local church? Rules under
corporate bodies give the answer. The first choice of name is that “of the person(s), object(s), place(s), or event(s) to which the local church … is dedicated or after which it is named.” The second is “a name beginning with a word or phrase descriptive of a type of local church.” The third is “a name beginning with the name of the place in which the local church … is situated.” Now you know. If rules like this interest you, there are thousands more in
AACR2R.
Internally, MARC records are stored as a collection of tagged fields in a fairly complex format. Figure 6.2b gives something close to the internal representation of the catalog record, while Table 6.1 lists some of the field codes and their meaning. Many of the fields contain identification codes. For example, field 008 contains fixed-length data elements, such as the source of the cataloging for the item and the language in which the book is written. Many of the variable-length fields contain subfields, which are labeled
a,
b,
c, and so on, each with their own distinct meaning (in the computer file they are separated by a special subfield delimiter character). For example, field 100 is the personal name of the author, with subfields indicating the standard form of the name, full forenames, and dates. Field 260 gives the imprint, with subfields indicating the place of publication, publisher, and date. The information in the more legible representation of Figure 6.2a is evident in the coded form of Figure 6.2b. Some fields can occur more than once, such as the subject headings stored in field 650.
The MARC format covers more than just bibliographic records. It is also used to represent authority records—that is, standardized forms that are part of the librarian's controlled vocabulary (see Section 6.5).
The rules and detailed formatting of the MARC standard are what allows these records to be exchanged between different library software systems. Rather than each library creating a new record for a book, it can be created once and then shared. The use of standardized records allows for great efficiencies in metadata creation and also facilitates the construction of so-called union catalogs that combine metadata from several libraries. The WorldCat union catalog at the Online Computer Library Center, a U.S. organization that helps libraries locate, acquire, catalog, and lend library materials, holds more than 125 million records from 112 countries. Cooperation on this scale is based on a consortium approach common in the library community and made practical through the widespread use of standards like MARC.
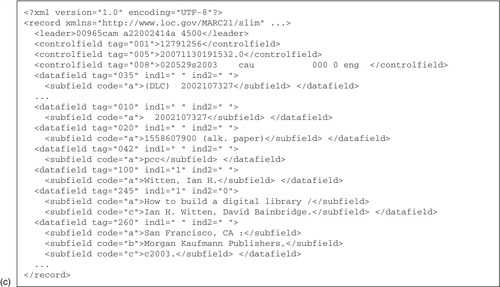
MARCXML
The Library of Congress guided the development of a standard way of representing MARC data in the XML language, called MARCXML. Figure 6.2c shows an example that contains an abbreviated version of the record in Figure 6.2b. Field codes are represented as the values of attributes within the opening tag of
datafield elements. Within these elements,
subfield elements represent the MARC subfields, with
code attributes to distinguish them. For example, the last few lines of Figure 6.2c give the publisher information in MARC field 260, including place of publication, publisher name, and publication date. The simplicity of this transformation emphasizes one of the design goals of MARCXML: lossless transformation between it and MARC in both directions. This round-trip compatibility is useful because there are many digital library applications where data is transformed or migrated between different systems.
MARCXML uses XML in a different way from other XML-based metadata standards, where element names usually convey semantic information (e.g., <title>, <publisher>, etc.). This characteristic makes it hard to read for a human unfamiliar with MARC. For comparison, look at the MODS representation of the same data in Figure 6.2e, also expressed in XML, which you will probably find much easier to understand. However, MARCXML provides a useful mechanism for connecting the wealth of library data in MARC format with XML processing technologies, such as XSL (Section 4.4).
Dublin Core: DC
The Dublin Core is a set of metadata elements that are designed specifically for non-specialist use. It is intended for the description of electronic materials—such as a Web page or site—which will almost certainly not receive a full MARC catalog entry. The result of a collaborative effort by a large group of people, Dublin Core is named for Dublin, Ohio, where the first meeting was held in 1995. It received the approval of ANSI, the American National Standards Institute, in 2001.
Compared with the MARC format, Dublin Core has a refreshing simplicity. Table 6.2 summarizes the metadata elements it contains: just 15, rather than the several hundred used by MARC. As the name implies, the elements are intended to form a “core” set that may be augmented by additional elements for local purposes. In addition, the existing elements can be refined through the use of qualifiers. All elements can be repeated where it is appropriate. Dublin Core uses the general term
resource for what is being described—the term subsumes pictures, illustrations, movies, animations, simulations, and even virtual reality artifacts, as well as textual documents. Indeed,
resource has been defined in Dublin Core documents as “anything that has identity.”Figure 6.2d shows a Dublin Core metadata record (in an XML format) for the book in Figure 6.2a; naturally, it contains only a subset of the full information.
The
Creator might be a photographer, an illustrator, or an author. The
Subject is typically expressed as a keyword or phrase that describes the topic or the content of the resource. The
Description might be an abstract of a textual document, or a textual account of a non-textual resource, such as a picture or an animation. The
Publisher is generally a publishing house, a university department, or a corporation. A
Contributor could be an editor, a translator, or an illustrator. The
Date is the date of resource creation, not the date or dates covered by its contents. For example, a history book will have an associated
Coverage date range that defines the historical time period it covers, as well as a publication
Date. Alternatively (or in addition),
Coverage might be defined in terms of geographical locations that pertain to the content of the resource. The
Type might indicate a home page, research report, working paper, poem, or any of the media types listed above. The
Format is used to help identify software systems needed to access the resource.
Qualified Dublin Core
An extension of the basic 15-element Dublin Core described above was introduced to add greater expressivity and to extend the range of uses. Two forms of qualification were added:
element refinement and
encoding schemes.
Any element can be refined or qualified. For example, the
Date element can be refined as
date created,
date valid,
date available,
date issued, or
date modified. The key principle in element refinement is “dumbing down”; the qualifier can be safely removed and the element value interpreted as a simple element. So the
date created, for instance, can be safely interpreted as a
Date. This principle allows qualified and simple Dublin Core to co-exist easily inside digital libraries.
Encoding schemes address the permissible ranges of element values. For example, a controlled vocabulary for an element could be expressed as an encoding scheme—that is, the Library of Congress Subject Headings could be used for the Dublin Core element
Subject. Given such an encoding scheme, digital library software can expect that only valid subject headings will appear as values in the
Subject element. Alternatives to the Library of Congress Subject Headings include the Dewey Decimal Classification and the Medical Subject Headings (MeSH) designed by the U.S. National Library of Medicine. A different form of encoding scheme can specify that a value should follow a precise structural rule, such as a date format, URL, or language-encoding scheme. The restrictions imposed by encoding schemes are valuable, because it is easier to write software to deal with constrained values than it is to write software for free text.
Table 6.3 gives details of the qualifiers and encoding schemes that are specified in qualified Dublin Core, including some notes on encoding schemes suggested by the official Dublin Core Metadata Initiative Usage Board. Table 6.3a includes qualifiers for
Audience,
Coverage,
Date,
Description,
Format,
Identifier,
Relation, and
Rights metadata fields (among others), and encoding schemes for both spatial and temporal coverage, date, identifiers, languages, and subjects. Table 6.3b gives suggested standards for encoding such things as regions of space, periods of time, particular locations, subjects, and languages.
| Accrual Method, Accrual Periodicity, Accrual Policy, Contributor, Creator, Instructional Method, Provenance, Publisher, and Rights Holder do not have refinements or encoding schemes. | ||||||
| (a) Sample elements, qualifiers, and encoding schemes | ||||||
|---|---|---|---|---|---|---|
| Element | Qualifier | Encoding schemes | ||||
| Audience | Education Level, Mediator | |||||
| Coverage | Spatial, Temporal | DCMI Point, ISO 3166, DCMI Box, TGN | ||||
| Date | Created, Valid, Available, Issued, Modified, Date Accepted, Date Modified, Date Submitted | DCMI Period, W3CDTF | ||||
| Description | Table of Contents | |||||
| Abstract | ||||||
| Format | Extent, Medium | IMT | ||||
| Identifier | Bibliographic Citation | URI | ||||
| Language | ISO 639-2, RFC4646 | |||||
| Relation | 13 different relations are specified as qualifiers, including Is Part Of, Has Version, and Is Referenced By | |||||
| Rights | Access Rights, License | |||||
| Source | URI | |||||
| Subject | LCSH, MeSH, DDC, LCC, UDC | |||||
| Title | Alternative | |||||
| Type | DCMIType | |||||
| (b) Notes on encoding schemes | ||||||
| Scheme | Type | What it encodes | Example | |||
| DCMI Box | Syntax | Region of space | The Western Hemisphere: westlimit=180; eastlimit=0 | |||
| DCMI Period | Syntax | Period of time | World War II: name=World War II; start=1939; end=1945 | |||
| DCMI Point | Syntax | A particular location | Perth, Western Australia: name=Perth, W.A.; east=115.85717; north=−31.95301 | |||
| DCMIType | Vocabulary | Type of resource | Quicktime video file: MovingImage | |||
| DDC | Vocabulary | Dewey Decimal Classification | 599 Mammalia. Mammals | |||
| IMT | Vocabulary | Internet Media Type—also known as MIME types | Quicktime video file: video/quicktime | |||
| ISO 639-2 | Syntax | Three-letter codes for languages | Arabic: ara | |||
| LCC | Vocabulary | Library of Congress Classification | QL700-739.8 | |||
| LCSH | Vocabulary | Library of Congress Subject Headings | Animal Psychology | |||
| MeSH | Vocabulary | Medical Subject Headings | Animals, Wild | |||
| RFC4646 | Syntax | Languages | English as used in the U.S.: en-US | |||
| TGN | Vocabulary | Getty Thesaurus of Geographic Names | Perth in Western Australia: Perth (inhabited place) ID: 7001977 | |||
| UDC | Vocabulary | Universal Decimal Classification | 599 Mammalia. Mammals | |||
| URI | Syntax | Uniform Resource Identifiers | http://www.ietf.org/rfc/rfc3986.txt | |||
| W3CDTF | Syntax | Date and time | November 5, 1994, 8:15:30 a.m., U.S. Eastern Standard Time: 1994-11-05T08:15:30-05:00 | |||
Metadata Object Description Schema: MODS
The Metadata Object Description Schema (MODS) is a bibliographic XML-based metadata format that can be used to represent a subset of MARC (specifically, the MARC21 variant that is a combination of the United States and Canadian MARC formats). Because it uses a subset of a particular MARC variant, general MARC records cannot be converted losslessly to MODS, and so round-trip compatibility is sacrificed.
Figure 6.2e shows a MODS record that describes the first edition of this book. The MARC field 260 publisher information we looked at in the last few lines of Figure 6.2c can be found starting at the tenth line of Figure 6.2e, within the
originInfo element:
<originInfo>
<place>
<placeTerm type="code" authority="marccountry">cau</placeTerm>
</place>
<place>
<placeTerm type="text">San Francisco, CA</placeTerm>
</place>
<publisher>Morgan Kaufmann Publishers</publisher>
<dateIssued>c2003</dateIssued>
<dateIssued encoding="marc">2003</dateIssued>
<issuance>monographic</issuance>
</originInfo>
This extract illustrates a key quality of well-designed XML-based representations: it is easily readable by people as well as by computers. As you can see, MODS allows richer descriptions than Dublin Core and is a useful alternative when qualified Dublin Core is inadequate for describing your resources.
Along with Dublin Core, MODS can be used within the METS standard described in Section 6.4. It does not in itself address issues of authority control, but there is an analog to MARC authority data in the MADS format described in Section 6.5.
BibTeX
Scientific and technical authors, particularly those using mathematical notation, often favor a widely used generalized document-processing system called TeX (pronounced
tech), or a customized version called LaTeX (see Section 4.6). This freely available package contains a subsystem called BibTeX that manages bibliographic data and references within documents.
Figure 6.2f shows a record in BibTeX format. Records are grouped into files, and files can be brought together to form a database. Each field can flow freely over line boundaries—extra white space is ignored. Records begin with the @ symbol followed by a keyword naming the record type: article, book, and so forth. The content follows in braces and starts with an alphanumeric string that acts as a key for the record. Keys in a BibTeX database must be unique. Within a record, individual fields take the form
name=value, with a comma separating entries. Names specify bibliographic entities such as author, publisher, address, and year of publication. Each item type can be included only once, and values are typically enclosed in braces (or double quotation marks) to protect spaces. Certain standard abbreviations, such as abbreviated month names, can be used, and users can define their own abbreviations.
Two items deserve explanation. First, the
author field is used for multiple authors, and names are separated by the word
and, rather than by commas, with a final
and as in ordinary English prose. This is because the tools that process BibTeX files incorporate bibliographic standards for presenting names. The fact that the two names in Figure 6.2f use different conventions is of no consequence: both will be presented correctly in whatever style has been chosen for the bibliography. Second, titles are also presented in whatever style has been chosen for the bibliography—for example, only the first word may be capitalized, or all content words may be capitalized—regardless of how they appear in the BibTeX file. Braces override this and preserve the original capitalization, so that the proper names can appear correctly capitalized in the document.
Unlike in other bibliographic standards, in BibTeX the set of attribute names is determined by a style file named in the source document and is used to formulate citations in the text as well as to format the references as footnotes or in a list of references. The style file is couched in a full programming language and can support any vocabulary. However, there is general consensus in the TeX community about the keywords to use. Advantage can be taken of TeX's programmability to generate XML syntax instead; alternatively, there are many standalone applications that simply parse BibTeX source files.
Academic authors often create BibTeX bibliographic collections for publications in their area of expertise, accumulating references over the years into large and authoritative repositories of metadata. Aided by software heuristics to identify duplicate entries, the repositories constitute a useful resource for digital libraries in scientific and technical areas.
EndNote
A format promoted by the popular bibliographic tool EndNote is illustrated in Figure 6.2g, which shows the same basic bibliographic record. The syntax is based on an earlier format that, like BibTeX, was designed for use by scientific and technical researchers. Today, many systems for maintaining bibliographic databases can export databases in this format. It is formatted line by line, and records are separated by a blank line. Each line starts with a key character, introduced by a percent symbol, that signals the kind of information the line contains. The rest of the line gives the data itself.
The format has a fixed set of keywords, listed in Table 6.4. The keyword
%0, or percent zero, appears as the first line of a record to make the type explicit—Book, in our example. Unlike BibTeX, EndNote repeats the author field (
%A) for multiple authors; the ordering reflects the document's authorship.
6.3. Metadata for Multimedia
Metadata is by no means confined to textual documents. In fact, because it is much harder to search the content of image, audio, or multimedia data than to search full text, flexible ways of specifying metadata become even more important for locating these resources.
The image file formats described in Chapter 5 (Section 5.3) incorporate some limited ways of specifying image-related metadata. For example, GIF and PNG files include the height and width of the image (in pixels), and the number of bits per pixel (up to 8 for GIF, 48 for PNG). PNG specifies the color representation (palletized, grayscale, or true color) and includes the ability to store text strings representing metadata. JPEG also specifies the horizontal and vertical resolution. But these formats do not include provision for other kinds of structured metadata, and when they are used in a digital library, image metadata is usually put elsewhere.
We describe several metadata formats for images and multimedia. The Tagged Image File Format, or TIFF, is a practical scheme for associating metadata with image files that has been in widespread use for well over a decade. TIFF is often used storing for images—including document images—in today's digital libraries. EXIF, XMP/IPTC, and MIX are alternative approaches for image metadata: embedding metadata in the image file itself or separating the metadata from the image data. Temporal multimedia, such as audio and video, offer limited facilities for storing metadata within the files themselves. MPEG-7 is a far more sophisticated and ambitious scheme for defining and storing metadata associated with any multimedia information.
The following sections describe TIFF in specific detail, briefly cover metadata for temporal formats, and proceed to outline the facilities that MPEG-7 provides. Finally, we outline the usage-based framework of the MPEG-21 standard.
Image metadata: TIFF
The Tagged Image File Format, TIFF, described in Section 5.3, incorporates extensive facilities for descriptive metadata. It is used to describe image data that comes from scanners, frame-grabbers, paint programs, and photo-retouching programs. It is a rich format that can take advantage of many image requirements but is not tied to particular input or output devices. It provides numerous options—for example, several different compression schemes and comprehensive information for color calibration. It is designed so that private and special-purpose information can be included.
A single TIFF file can include several images, each of which is characterized by tags whose values define particular properties of the image. Most tags contain integers, but some contain ASCII text—and provision is made for tags containing floating-point and rational numbers. Baseline TIFF has a dozen or so mandatory tags that give physical characteristics and features of images: their dimensions, compression, various metrics associated with the color specification, and information about where they are stored in the file.
Table 6.5 shows some TIFF tags, all of which except the last group are mandatory. The first group specifies the image dimensions in pixels, along with enough information to allow conversion to physical units where possible. All images are rectangular. The second group gives color information. For bilevel images, the color group defines whether they are standard black-on-white or reversed; for grayscale it gives the number of bits per pixel; for palette images, it specifies the color palette. The third group specifies the compression method—baseline TIFF allows only extremely simple schemes. Finally, a TIFF image can be broken into strips for efficient input/output buffering, and the last group of mandatory tags specifies their location and size.
Additional features go far beyond the baseline illustrated in Table 6.5 and users can define new TIFF tags and compression. This makes the TIFF format even more flexible than the official list of extensions given in the standard, although naturally care needs to be taken to ensure that the software used to read and write image files is conversant with the tags they use. To avoid conflict, a registration process is provided for allocating private tags. There are over 70 such tag sets, including support for EXIF (see next subsection). More radical extensions include GeoTIFF, which permits the addition of geographic information associated with cartographic raster data and remote sensing applications, such as projections and datum reference points. Many digital cameras produce TIFF files, and Kodak has a PhotoCD file format based on TIFF with proprietary color space and compression methods.
Most digital library projects of images use the TIFF format to store and archive the original captured images, even though they may convert them to other formats for display. At the bottom of Table 6.5 are some optional fields that are widely used in digital library work. Some, such as the name of the program that generated the image and the date and time it was generated, are usually filled in automatically by scanner programs and other image-creation software. Digital library projects often establish conventions for the use of the other fields. For example, in a digitization project, the
Document name field might contain the catalog ID of the original document. These fields are coded in ASCII, but there is no reason why they should not contain data that is further structured. For example, the
Image description field might contain an XML specification that itself includes several subfields.
Image metadata: EXIF, XMP, IPTC, and MIX
The exchangeable image file format (EXIF) is a standard for embedding technical metadata in image files that many camera manufacturers use and many image-processing programs support. EXIF metadata can be embedded in TIFF and JPEG images. Table 6.6 shows a metadata record extracted from a JPEG image produced by a digital camera: it includes the exposure, resolution, focal length, and whether flash was used. The record shows that the GIMP image-editing program has been used to process the file, which illustrates that embedded metadata expressed in EXIF is only as accurate as the last application that saved the file and may have been altered by several programs before it is added to your digital library. EXIF metadata can include a thumbnail image—in this case the thumbnail is a 196 × 147 pixel JPEG that occupies 3.6 KB, compared with the original 2,048 × 1,536 (262 KB) image. Including the thumbnail, the metadata itself occupies 4.4 KB.
The DIG35 standard provides an extensible XML framework that can be used to embed metadata in the private tags of image formats like TIFF and JPEG. DIG35 groups elements into four main categories: image creation, content description, provenance, and intellectual property rights. Many elements are optional. The JPEG 2000 file format has an XML
Box container that can include any XML data, although DIG35 is suggested.
In 2001, Adobe introduced the
Extensible Metadata Platform (XMP) to provide a general solution for embedding metadata within files like images and PDF documents. XMP values are expressed in XML using a subset of RDF (see Section 6.4), allowing great flexibility in metadata expression. XMP's model is flexible enough to allow structural metadata to be expressed—so that, for example, different pages in a document can be described independently.
Within XMP, metadata can be expressed using different schemas and can be extended by adding new schemas. Schemas can be based on external standards (e.g., Dublin Core and EXIF) or internal schemas (e.g., XMP Rights Management) and can be associated with specific file types (e.g., PDF) or applications (e.g., Adobe Photoshop). Many applications now provide custom dialog windows to simplify the manual entry and editing of XMP metadata.
The XMP metadata itself is embedded in files in a serialized
Packet, optionally surrounded by a wrapper consisting of a Header, Padding, and Trailer sections. The suggested size for the Padding section is 2–4 KB, allowing space for editing and expanding the metadata without overwriting application data. The actual mechanism for embedding the XMP packet varies depending on the particular file format. In PDF, for example, the packet is embedded in a metadata stream stored within a PDF object (see Section 4.5). Using custom embedding techniques allows XMP to be applied to a wide range of file types, including GIF, PNG, JPEG, JPEG 2000, Photoshop, MP3, MPEG-4, HTML, and WAV. When XMP cannot reliably be embedded in the native file format, as with MPEG-2, the packet is placed in a small “sidecar” file with the same filename and the suffix
.xmp.
In 2008 the International Press Telecommunications Council (IPTC) released the
IPTC Photo Metadata 2008 standard, based on requirements gathered from device manufacturers and photographers, which is implemented as a core XMP schema. Many image-processing applications provide support for XMP metadata, and it is likely that support for IPTC embedded metadata will grow quickly.
Metadata for Images in XML (MIX) is a new standard for image metadata that, in contrast to the
de facto use of EXIF, is being coordinated and promoted by the Library of Congress. Like EXIF, it addresses technical rather than descriptive metadata. Its elements represent scanner resolutions, details of camera exposure, and processing software—and nothing about the image content or who took a particular photograph. Its flavor is illustrated by Figure 6.3, which shows a fragment of a MIX document for a photograph.

Both EXIF and MIX-style metadata address the technical and preservation aspects of the five-part metadata classification in Section 6.1. EXIF is almost universal in consumer electronics but is restricted to certain image types, whereas MIX, being relatively new, is not yet widely used. The IPTC Photo Metadata standard is very new but has strong growth potential: it is open, has an extensible metadata model, and is based on the well-known XMP approach.
Audio metadata
Although audio resources are often described using external metadata schemes, such as Dublin Core, several audio formats contain embedded metadata. The ubiquitous MP3 format is an interesting case. Initially it had virtually no internal metadata, apart from the technical audio information needed to play the file.
The first set of metadata tags for MP3 was developed in 1996 and is known as ID3 (for “IDentify an MP3”). ID3 tags were placed at the end of the audio data (in an attempt to minimize disruption to software). They were limited to 128 bytes: 3 for the starting string “TAG,” which identified the metadata block, 30 bytes for the title, 30 for the artist, 30 for the album, 4 for the year, 1 for track number, 1 for genre, and 30 for comments. The genre byte was an index into a list of 80 predefined genres. These limits were found to be too restrictive for describing music metadata and the ID3 format has been evolving ever since to provide more flexible metadata containers.
The current ID3v2 tag format allows many
frames of data of variable size (up to 16 MB each) that can contain text, images, and technical metadata about the audio data. They are normally located at the beginning of the file to assist media streaming software. There are 39 predefined text frames, including composer, length, copyright, publisher, and title. Other frames provide scope for URLs, images (such as CD cover art), synchronized lyrics, and, in a “commercial
” frame, for advertising. All frames are optional, and users can also define their own. MP3 ID3 is not a formal standard, so metadata extracted from MP3 collections is likely to be incomplete and inconsistent.
The Ogg container format that wraps Vorbis audio (Section 5.2, Post-MP3 formats) does not include a structured metadata component, although there is a comment facility for simple textual values. Vorbis comments take the form
fieldname=data, where the
fieldname is a case-insensitive ASCII string and
data is a UTF-8 encoded string. A proposed set of field names includes TITLE, COPYRIGHT, and GENRE, but, as with MP3, none is mandatory and usage is variable. FLAC files support Vorbis comments along with a PICTURE block for storing an image and a CUESHEET block that uses track and index points compatible with the CD audio standard.
WAV audio is a form of RIFF file consisting of
chunks (Section 5.2, Early formats). A LIST chunk with a type of INFO provides a limited facility for embedded metadata. A variety of text chunks are available, including genre, source, and copyright, and there is a display chunk that allows text or images to be associated with the audio data. AIFF files have optional chunks for name, author, copyright, annotation, and comments. Table 5.1 lists some of the chunk types for WAV and AIFF files. The AU format has a single unstructured text field.
The WAV
cue chunk (or the comparable AIFF
marker) allows points of interest and text to be associated with particular points in an audio track internally. These cue points can provide useful structural metadata, and the text can be used to supplement the listening experience for users. Alternatively, the Continuous Media Markup Language (CMML) is a generalized approach to linking metadata with a specific point in temporal media. CMML is an XML format for linking text to time periods through
clip elements, such as
<clip id="painting" start="npt:3.5" end="npt:5:5.9">
<img src="painting1.jpg"/>
<desc>A close up of the painting</desc>
<meta name="Subject" content="painting"/>
</clip>
which defines a description, subject metadata, and image—and associates it with a period of audio. CMML can be used to synchronize lyrics with music, to allow metadata values to be assigned with temporal precision, and to provide subtitling for video. CMML can be serialized into data that can be inserted into container formats such as Ogg.
Neither AAC nor MPEG-4 audio includes a standard metadata format. However, Apple's tagging format has become a
de facto standard for AAC because of its use in the popular iTunes music store. It exploits the generic user-data (“udta”)
atom (or
box), and metadata is stored as tag-value pairs. The values themselves are flexible, textual metadata (e.g., the
aART tag for album artist,
cprt for copyright, and ©
nam for title). They are stored as UTF-8 strings. iTunes also sets a
covr value for a cover art image (typically JPEG or PNG).
Video metadata
Much video data is delivered within container formats like AVI, MPEG-4, Flash, or Ogg, and these containers often provide embedded metadata support. Apple's QuickTime format became the basis for the MPEG-4 container format, so MPEG-4 handles metadata in a similar way to the iTunes AAC audio discussed above. AVI is a form of RIFF file, so it handles metadata in a similar way to WAV. Ogg Theora video uses the same container format as Ogg Vorbis audio, so the same comment structure is supported. However, software support for these video comments is currently limited.
MPEG-2 video has no textual metadata support. However, with some extensions and restrictions, it is used to add subtitles and menu information to DVD video. The added information is put on the DVD as images rather than text—thus avoiding the need for DVD players to include the entire set of Unicode characters as fonts. The lack of metadata support in MPEG-2 led to the MPEG-7 format described in the next section.
The basic idea of CMML—to associate external resources with time points—is used by several subtitling/captioning technologies, such as MPEG-4 Timed Text (supported in Apple's Quicktime tools). Most subtitles are simply plain text rather than structured metadata, although they could be used to enable limited text searching of video collections. The larger idea of coordinating temporal multimedia content is embodied in QuickTime, SMIL, and Flash (Sections 5.4 and 5.5).
The relative lack of structured metadata embedded in video files has been addressed in two ways: expanded container formats with explicit metadata support, and placing the metadata in external storage, such as linked XML files.
The Material Exchange Format (MXF) is a new container format that can hold many types of video data in a platform-independent manner. It is managed by the Society of Motion Picture and Television Engineers (SMPTE), who maintain central lists of metadata labels, metadata dictionaries, and the basic Descriptive Metadata Schema (known as DMS-1). MXF metadata is based on keys (e.g.,
Titles:MainTitle) and values and can be defined either globally or for specific time intervals.
MPEG-7 has an alternative but complementary approach, where external metadata is expanded to include a low-level description of content as well as the familiar Dublin Core-like high-level descriptions.
It is early days for video content, at least in terms of digital library usage, and few tools support metadata editing. Despite the availability of methods for splicing sophisticated metadata into video container file formats, in practice the video material that is actually supplied is often inadequate for the needs of digital libraries. As we have seen, collections like the Open Video project (Section 5.4) augment the video material with external metadata that meets their needs.
Multimedia metadata: MPEG-7
We learned about the MPEG family of standards in Section 5.4. MPEG-7, which is formally called the
multimedia content description interface, is intended to provide a set of tools for describing multimedia content. The aim is to allow the user to search for audiovisual material that has associated MPEG-7 metadata. The material can include still pictures, graphics, 3D models, audio, speech, video, and any combination of these elements in a multimedia presentation. It can be information that is stored or that is streamed from an online real-time source. The MPEG-7 standard was developed by broadcasters, electronics manufacturers, content creators and managers, publishers, and telecommunication service providers under the aegis of the International Organization for Standardization (ISO).
MPEG-7 has exceptionally wide scope. For example, it foresees that metadata may be used to answer queries like:
• The user plays a few notes on a keyboard and retrieves musical pieces with similar melodies, rhythms, or emotions.
• The user draws a few lines on a screen and retrieves images containing similar graphics, logos, or ideograms.
• The user defines objects, including color or texture patches, and retrieves similar examples.
• The user describes movements and relations between a set of given multimedia objects and retrieves animations that exhibit them.
• The user describes actions and retrieves scenarios containing them.
• Using an excerpt of Pavarotti's voice, the user obtains a list of his records and video clips and photographic material portraying him.
We encountered systems that embody the first and third of these examples in Chapter 3. However, it should be noted that the way in which MPEG-7 metadata is used to support such queries is beyond the scope of the standard.
MPEG-7 is based on four components
: Descriptors,
Description Schemes, Description Definition Language, and
Systems Tools. Descriptors represent low-level features, the fundamental qualities of audiovisual content. They range from statistical models of signal amplitude to the fundamental frequency of a signal, from emotional content to parameters of an explicit sound-effect model. Description Schemes specify the types of Descriptors that can be used and the relationships between them or between other Description Schemes. The Description Definition Language (DDL) allows users to extend the predefined description capabilities of Descriptors and Description Schemes. DDL uses XML syntax and is a form of XML Schema (more details appear in an appendix at the book's Web site). In this case, XML Schema alone is not flexible enough to handle low-level audiovisual forms, so DDL was formulated to address these needs. Finally, the Systems Tools are a suite of basic tools to synchronize metadata descriptions with content encoding and transmission.
A Description Scheme, together with instantiated values for a Descriptor, produces an actual Description, such as the one shown in Figure 6.4. The three AttributeValuePairs in the lower half (un-indented) give a trio of values of features (called
HSV_lin-4x4x4-G,
tamuraS-2-A, and
gabor-6-4) that were derived by analyzing the image whose URL is specified in the
MediaUri element. The actual values appear in the three lists of numbers (the
FloatMatrixValue elements). In fact, this example is from the system we described under Content-Based Image Search in Section 3.4 (illustrated in Figure 3.17), which, as we learned there, derives several mysteriously named features from the image content.

The MPEG-7 DDL is able to express spatial, temporal, structural, cardinal and data-type relationships between Descriptors and Description Schemas. For example, structural constraints specify the rules that a valid Description should obey: what child elements must be present for each node, or what attributes must be associated with elements. Cardinality constraints specify the number of times an element may occur. Data-type constraints specify the type and the possible values for data or Descriptors within the Description.
There are different Descriptors for audio, visual, and multimedia data. The audio description framework operates in both the temporal and spectral dimensions, the former for sequences of sounds or sound samples, and the latter for frequency spectra that comprise different components. At the lowest level, you can represent such things as instantaneous waveform and power values, various features of frequency spectra, fundamental frequency of quasi-periodic signals, a measure of spectral flatness, and so on. There is a way to construct a temporal
series of values from a set of individual samples, and a spectral
vector of values, such as a sampled frequency spectrum. At a higher level, description tools are employed for sound effects, instrumental timbre, spoken content, and melodic descriptors to facilitate query-by-humming.
In the visual domain, basic features include color, texture, region-based and contour-based shapes, and camera and object motion. Another basic feature is a notion of
localization in both time and space, and these dimensions can be combined in a space-time trajectory. These basic features can be built into structures like a grid of pixels or a time series of video frames.
Multimedia features include low-level audiovisual attributes like color, texture, motion, and audio energy; high-level features of objects, events, and abstract concepts; and information about compression and storage media. Browsing and retrieval of audiovisual content can be facilitated by defining summaries, partitions, and decompositions. Summaries, for example, allow an audiovisual object to be navigated either hierarchically or sequentially. For hierarchical navigation, material is organized into successive levels that describe it at different levels of detail, from coarse to fine. For sequential navigation, images or video frames can be arranged in sequences and possibly synchronized with audio and text so that they compose a slide show or audiovisual synopsis.
MPEG-7 descriptions can be entered by hand or extracted automatically from the signal (as in Figure 6.4). Some features (color, texture) can best be extracted automatically, while others (“this scene contains three shoes,” “that music was recorded in 1995”) cannot be extracted automatically.
The application areas envisaged for MPEG-7 are many and varied and stretch well beyond the ambit of what most people mean by digital libraries. They include education, journalism, tourist information, cultural services, entertainment, geographical information systems, remote sensing, surveillance, biomedical applications, shopping, architecture, real estate, interior design, film, video and radio archives, and even dating services.
Multimedia application metadata: MPEG-21
MPEG-7 provides a description framework for multimedia content that supports many digital library functions, such as structured browsing and surrogate creation. However, in reality, multimedia like music and video participate in complex international flows of content that are worth vast amounts of money. As we all know, some of this content is illegally distributed at various points in its lifecycle, due to the simplicity and fidelity of digital copying. MPEG-21 is a broad and ambitious standard that links multimedia producers and consumers to address issues of content control. According to the official overview,
MPEG-21 aims at defining a normative open framework for multimedia delivery and consumption for use by all the players in the delivery and consumption chain. This open framework will provide content creators, producers, distributors and service providers with equal opportunities in the MPEG-21 enabled open market. This will also be to the benefit of the content consumer, providing them access to a large variety of content in an interoperable manner.
MPEG-21 is founded upon two concepts: a
Digital Item (such as a video or music album) and the
User's Interaction with it. Because it is concerned with the access, consumption, and exchange of multimedia content, MPEG-21 emphasizes aspects of user interaction that are not considered by other metadata frameworks for digital content. Technically, Digital Items are compound objects that include multimedia content and metadata. Each Digital Item is defined by a Digital Item Declaration (DID) expressed in the Digital Item Declaration Language (DIDL) and written as an XML Schema. Another key part of the MPEG-21 framework is the Rights Expression Language, also written using XML Schema. The Rights Expression Language is based on licenses that grant principals (the users) the right to use a resource (such as a video) under certain conditions (such as a time limit). The intention is that MPEG-21 can link a multimedia resource with a machine-readable statement, such as
Alice permits Bob to play the video “Stupid Pet Tricks vol 26.mpg” during November 2011.
The development of MPEG-21 illustrates two important factors in the future of digital libraries: 1) the computational specification of rights management and 2) increasingly complex compound digital objects.
6.4. Metadata for Compound Objects
As we have seen, the descriptions of digital objects are becoming richer, and they are ever more interlinked with other objects or online resources—and the metadata needed to represent these connections is itself a source of complexity. In this section we provide examples of technologies that allow complex
compound objects to be rigorously defined.
Resource Description Framework: RDF
The Resource Description Framework (RDF) is designed to facilitate the interoperability of metadata, particularly in the realm of the World Wide Web. Because metadata covers too great a variety of information to specify exhaustively and categorically, RDF follows the lead of XML: rather than providing a set of possibilities, it supplies a means for describing a valid system. It is expected that communities of users will assemble to establish RDF systems suited to their collective needs. They will have to agree on a vocabulary, its meaning, and the structures that can be formed from it. This is done by specifying an RDF Schema, just as DTDs and XML Schemas are used to control XML vocabulary and structure.
RDF is a way of modeling as a resource anything that can be represented as a Universal Resource Identifier. What is a URI? Well, officially, according to the W3C standard (RFC 3986), a Universal Resource
Identifier is anything expressed in the appropriate format that serves to identify a Web resource, and thus a URI includes both locators—URLs—and names—URNs. Universal Resource
Locators are a subset of URIs that, in addition to identifying the resource, describe its location on the network. Universal Resource
Name refers to any URI that is guaranteed to remain globally unique and persistent even when the resource is deleted or becomes unavailable. A Web page, part of a document, an FTP site, or an e-mail address are all examples of the former, and the International Standard Book Number (ISBN) is an example of the latter.
RDF resources are described in a machine-readable fashion through a framework for specifying—in digital library terminology—metadata. The framework is compositional: new resources can be built from existing ones.
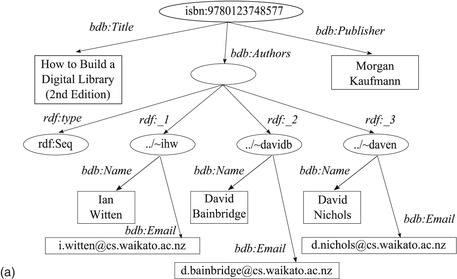
Figure 6.5 uses RDF to give a graphical description of the book you are holding in your hands. The book is represented by its ISBN (International Standard Book Number) in URI syntax. The top-level description comprises a title, three authors, and a publisher. The authors in turn are characterized by a name and an e-mail address.
Mapping the graphical description into a character stream is a process of serialization, and for RDF the language of choice is (again) XML. Figure 6.5b shows the description of the example graph. This representation obscures some of the abstract aspects of RDF and makes it seem like just another example of an XML language—especially since we have recently seen so many of them! When considering RDF, you should keep in mind that it is a sister format to XML, not a subsidiary. However, this medium bestows practical benefits: software support for parsing and editing, transparent handling of international characters, and so on.
The basic construction in RDF (indeed as it is in English) is to connect a subject to an object using a predicate. This is known as a statement. Subjects and objects are nodes in the graph. The directed arc that joins them shows the connection; a label on the arc identifies the predicate used. To take an example from Figure 6.5a,
How to Build a Digital Library (object) is the
Title (predicate) of the resource
ISBN: 9780123748577 (subject). The subject is a resource, represented in the diagram as an oval node. An object may be either a resource or a string literal. In our case it is a string, represented as a rectangular node.
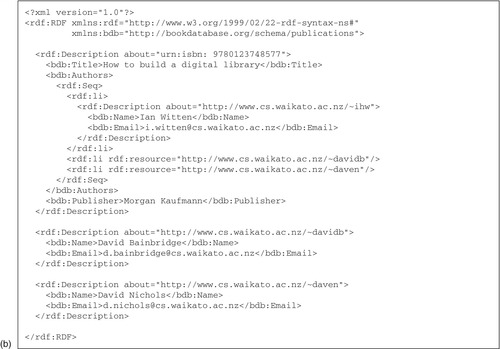
Now let's match up the graphical representation with the serialized form in Figure 6.5b. It begins with the familiar processing instruction, and a root node that declares some namespaces. In this case there are two: one for RDF and another for “Book Database,” denoted by the prefix
bdb. This represents a hypothetical organization that has developed an XML schema for representing metadata about books in terms of titles, authors, names, e-mail addresses, and publishers.
The first child of the root node is an
rdf:Description element that includes an
about attribute to specify the resource as a URI that gives the ISBN. The
bdb:Title tag that follows sets the predicate, and its content represents the string literal object that forms the title itself. Two other predicates connected to the ISBN resource are
Authors and
Publisher. The latter, like
Title, declares a string literal object (the string “Morgan Kaufmann”); the former, however, is more complex. Thus we see how the top level of the tree in Figure 6.5 is constructed.
Not only is
bdb:Authors the first object encountered in our explanation that is itself a resource, but also it is an example of an
anonymous resource—an intermediary node that has no specific resource name but is itself the subject of further qualifying statements. The counterpart in the graphical version of the model in Figure 6.5a is the node at the end of the
Authors predicate, which is nameless.
The anonymous resource also demonstrates a new structure called a
container, which is used to group resources together. RDF has three types of container:
bag,
sequence, and
alternative. A
bag is an unordered list of resources or string literals; a
sequence is an ordered list; and an
alternative represents the selection of just one item from the list. Each item in a
container is denoted by an
rdf:li tag. The example uses
rdf:Seq to represent a sequence of authors because the order is significant. The container type is represented by the
rdf:type predicate, and its contents are numbered
rdf:_1, rdf:_2, rdf:_3. These are implicitly inferred from the XML description (Figure 6.5b) but are shown explicitly in the pictorial version (Figure 6.5a).
There are three list items in the example, one for each author, and they happen to be compound resources. They are introduced by the RDF list item tag
rdf:li, and for illustrative purposes they are specified in different ways. The first is embedded in-line by starting a new
rdf:Description tag. The second and third receive a more compact
rdf:li tag that defers the resource's definition through the
rdf:resource attribute. The missing detail is filled in when a resource description is encountered whose
rdf:about attribute matches the named list item. This occurs in the lower third of the example.
RDF is designed to be created and read by machines, rather than people, so its verbosity is less important than its descriptive power and flexibility as a format. Figure 6.6 shows an automatically generated RDF file that describes a Web resource, the home page of the World Wide Web Consortium. The page has been downloaded and analyzed to extract metadata values, which have been expressed as Dublin Core metadata and included in the RDF file by importing the Dublin Core namespace in the
rdf element (the value of attribute
xmlns:dc, near the beginning). This example shows how RDF can interoperate with other metadata schemas to contribute to the Semantic Web. An extension of URIs called Internationalized Resource Identifiers (IRIs) has been proposed to extend RDF to resources that use Chinese, Korean, and Cyrillic characters.
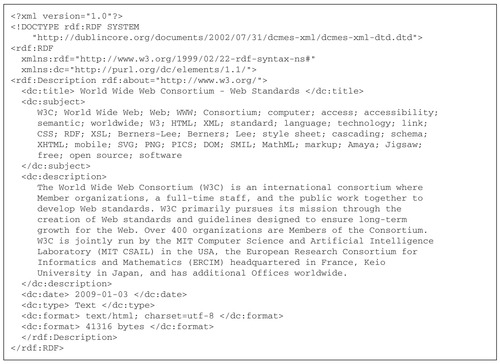
RDF is a rich framework whose design draws upon structured documents, entity relationships, object orientation, and knowledge representation. We cannot illustrate all aspects here, but the above examples convey the flavor of what it does.
Metadata Encoding and Transmission Standard: METS
The Metadata Encoding and Transmission Standard (METS) is designed to permit the representation, maintenance, and exchange of the increasingly complex digital objects that make up digital libraries. Library catalogs have for years used MARC records to fulfill these functions for their materials. The METS initiative aims to do the same for digital collections.
METS is an open standard implemented in XML that encodes three of the metadata types identified in Section 6.1: descriptive, structural, and administrative. It also contains an extension mechanism, through which it can encompass further areas. A METS document consists of six major sections:
Structural Map,
Structural Links, File,
Descriptive Metadata,
Administrative Metadata, and
Behaviors. The Structural Map provides the structure that links content and metadata together; it is the only compulsory element. Structural Links allow METS creators to record the existence of hyperlinks between nodes in the Structural Map. The File section lists the actual files that make up the digital object. Descriptive Metadata and Administrative Metadata come in two possible forms: external metadata, such as a MARC record in a library catalog, and internal metadata, such as a Dublin Core or MODS record for Descriptive Metadata or a MIX or PREMIS (see below) record for Administrative Metadata. Finally, the Behaviors section is used to associate executable behavior with content in a METS object.
METS is a complex format and can be used in different ways—for example, as the internal format of a digital library, or as an exchange format. Figure 6.7 shows an example document. The simplest part is the File section in the middle (
<mets:fileSec> element), which identifies the content files. The
Flocat elements all use a URL and an XLink pointer (see the appendix at the book's Web site) to locate a file, together with a MIME type and an identifier, so that other parts of the description can refer to it.

The Structural Map parts at the end (<
mets:structMap>) use
div elements to indicate divisions within the document (following a convention established in HTML), and
<mets:fptr> elements to indicate which content files contribute to each division (using the ID values from the
Flocat elements in the File section). There are two Structural Maps in Figure 6.7, each with one
div; the second consists of three content files. Structural Maps could reflect the physical structure of a scanned book in pages or its logical structure in chapters: the indirect way in which they are expressed allows multiple perspectives to be described for the same basic content.
The Descriptive Metadata section (<
mets:dmdSec>) continues the theme of flexibility. Figure 6.7 has embedded metadata near the top (indicated by the <
mdWrap> element) of type
Other—in this case, a specific Greenstone style of metadata. More standard metadata types, such as MODS or Dublin Core, could be included instead (or as well), either embedded within a <
mdWrap> element or linked externally through a <
mdRef> element.
Figure 6.7 does not show the Administrative Metadata section (<
mets:amdSec>), which encodes technical metadata (such as MIX), intellectual property rights, information about a physical source document, and preservation metadata. A typical component for the last is PREMIS, which describes information in terms of Intellectual Entities, Objects, Events, Rights, and Agents. Practically, such metadata will be split into groups to match METS sub-elements of <
mets:amdSec>. The use of PREMIS highlights the redundancy that often occurs when multiple metadata schemes are combined—file sizes and checksums can be part of an
objectCharacteristic element in PREMIS and an attribute of a
file element in METS. Redundancy is not necessarily a bad thing, and here it is reasonable to use both.
Finally, as noted above, the Structural Links section of a METS document includes hyperlinks between parts of the Structural Map, in order to model Web content, while the Behavior section associates executable behavior with METS objects.
One of the consequences of the complexity and richness of METS is that its use requires extensive support in the form of software tools. Even for simple objects, descriptions can easily be 50 lines of XML, and complex objects can produce documents 50 KB or more in size.
A useful component of the METS framework is the ability to express a profile. Profiles represent constraints and requirements that METS documents must fulfill to conform to the profile. Restrictions on the document values make it easier for software tools to process the documents and simplify exchange and aggregation. For example, a profile can require that there is no Behavior section, that the images referenced from the document must be in TIFF v6.0 format, or that subject headings in an embedded MODS section must use Library of Congress Subject Headings. Profile requirements are expressed in natural language, so conformance to a profile cannot be checked automatically.
Collection-level metadata
The examples of metadata seen so far have been for individual items. Typically, many items are grouped together in collections, and it becomes useful to consider metadata at the collection level. Such metadata could include the people who collated the collection, background on why it was created, and who to contact for maintenance requests. Collection-level metadata can also include information derived automatically from the items, such as their total number, the earliest item, or recent additions.
Collection-level metadata helps to contextualize item-level metadata that has been divorced from its collection. The need for this is exemplified by the so-called “on a horse” problem, where a collection of material about
Theodore Roosevelt (collection-level metadata) contains a photograph with the description
on a horse (item-level metadata). The description makes sense within the bounds of the collection, but the item-level metadata will be incomprehensible if it is separated from the collection (e.g., through harvesting via OAI-PMH, as described in Chapter 7).
This problem shows that collection-level metadata can be used to supplement item-level metadata to enhance user understanding, shareability, and searching and browsing. It also allows users to start their information-gathering process one step earlier by interrogating a set of collections to determine which best suits their need. For this idea to work across different digital library systems, standard terms and meanings are required—exactly what RDF, for example, was designed for.
The Research Support Libraries Programme (RSLP) Collection Description project is an example of collection-level metadata. The project uses a model that represents
Collections,
Locations, and
Agents as RDF resources. There are three types of agent—
Collector,
Owner, and
Administrator—reflecting the roles that people or organizations play in providing and maintaining a collection. The bulk of the detail is contained in the collection resource, which may in turn reference further resources, such as a location and a collector.
Figure 6.8 shows an abridged version of a description for the Morrison Collection of Chinese Books housed at the School of Oriental and African Studies Library in London, England. Four existing namespaces provide relevant elements and attributes: RDF (naturally), unqualified Dublin Core, qualified Dublin Core, and vCard, which is a namespace devised by the Internet Mail Consortium to represent fax numbers, phone numbers, and so on for electronic business cards. An additional namespace for RSLP covers attributes and elements not defined elsewhere (prefix
cld).

The example contains four top-level resource descriptions:
Collection,
Collector,
Owner, and
Location (marked with XML comments). There is no
Administrator resource in this example. Most of the information supplied in the collection resource description is through Dublin Core. In particular, the
<dc:subject> element shown uses the anonymous resource mechanism mentioned earlier to embed another resource, which is a Library of Congress Subject Heading, expressed using qualified Dublin Core.
About halfway down the collection resource description, the Dublin Core
<dc:type> element is used to give the collection's type. The RSLP collection description defines an enumerated list of possible types, starting with broad classifications, such as Catalog and Index, and then proceeding to more specific items, such as Library, Museum, and Archive, and finally defining even more specific items, such as Text, Image, and Sound. A collection can be given more than one of these types by separating the terms by a period (.), as can be seen in the figure.
Elements
<dq:hacsPart>,
<dcq:isPartOf>, and
<cld:hasDescription> are examples of external relationships. They identify or name other resources that have a bearing on the collection being described. There are seven external relationships in all. The ones appearing here are used to name subcollections (
hasPart), the larger library this collection fits into (
isPartOf), and where a description of the collection appears (
hasDescription).
The lower part of the collection resource description contains references to the collector, owner, and location resources through
dc:creator,
cld:owner, and
cld:hasLocation, respectively. The first two are examples of agents and make use of
vcard elements to supply the necessary information. A location can be electronic or physical, and most of its elements are defined by RSLP namespace elements.
Open Archives Initiative Object Reuse and Exchange: OAI-ORE
The Open Archives Initiative Object Reuse and Exchange (OAI-ORE) is a standard designed expressly for representing aggregations of digital objects. An extension of the OAI project (described in Chapter 7), it can be applied when separate (perhaps disparate) objects need to be treated as a group. Grouping objects is a natural human activity: photos are grouped into albums, music tracks are grouped into playlists, documents are grouped into collections.
OAI-ORE introduces a specific resource, called an
Aggregation, that refers to a set of objects. An aggregation is described by a
Resource Map that associates metadata with it. For example, Figure 6.9 shows an OAI-ORE document that describes this book. The aggregation contains four items: TIFF images of the front and back covers and PDF documents for the two parts of the book. The first <
rdfDescription> element is declared to be an OAI-ORE Aggregation by reference to the term http://www.openarchives.org/ore/terms/Aggregation. This element also contains Dublin Core metadata
dc:creator and
dc:title. The second <
rdfDescription> element is a resource map: it declares that the RDF file at http://www.cs.waikato.ac.nz/~ihw/rdf/htbadl2/ is a description (or resource map) of the aggregation. The remainder of the file attaches Dublin Core metadata to the individual items as item-level metadata.

OAI-ORE is a new framework with many potential uses in representing resources and metadata. It can link together different versions of the same document (e.g., PDF, PostScript, and Word). It can express parallel aggregations like a photograph collection containing themed groups (holiday in France, New Year party, graduation ceremony), all defined without affecting the base collection. The resources are URIs, so items can be defined across collections as well, from anywhere on the Internet that has a URI; thus, virtual collections can be built from remote resources. Because aggregations are themselves resources, they can themselves be aggregated into groups of collections, which can then be further aggregated.
The design of OAI-ORE is reminiscent of the METS Structural Map, which illustrates one of the virtues of the digital world: the ability to break apart, recombine, and restructure content in new and creative ways.
Metadata for education: LOM and SCORM
Libraries have long supported a variety of educational activities, and digital libraries for education have driven both content creation and library technology. Educational technologists talk of
Learning Objects and have devised a metadata scheme called Learning Object Metadata (LOM) to describe them. According to the IEEE Learning Technology Standards Committee,
the LOM standard will specify the syntax and semantics of Learning Object Metadata, defined as the attributes required to fully/adequately describe a Learning Object. Learning Objects are defined here as any entity, digital or non-digital, which can be used, reused or referenced during technology supported learning.
As you can see, the scope of Learning Objects is very wide. Figure 6.10 shows a sample LOM record; it is expressed in XML, is quite readable, and resembles other XML metadata representations, such as MODS.

The resource that this metadata record describes is titled
A Teddy Bear Picnic, which is stated in the <
general> section as the <
title> tag. The previous section gives its subject classification as
Arts. The LOM standard allows information to be provided in more than one language if desired. In this case, the overall language of the resource is set to English through the <
language> tag. Individual <
langstring> tags could override this by including an attribute specification. Further down the <
general> section is a description of the resource:
This film is about a teddy bear trying to enjoy his picnic. Until his sandwich runs away … now he has to get it back!
The resource that this particular LOM record describes is a film, a fact that is prescribed in machine-readable form in the <
technical> section, which shows that it is a QuickTime video that is 1 minute 38 seconds long, requiring 2,053,707 bytes (2 MB) of file space. LOM allows a URL to be specified that points to an online version of the resource. The <
lifecycle>, <
educational>, and <
rights> sections of this example present details such as the name of the contributor, Dalvin Chung Trieu; the copyright owner, the Vancouver Film School; and the status of the work,
Finished.
The LOM standard is designed to cover a variety of situations. It is possible to use a subset of LOM and still remain compliant with the standard. Subsets are examples of
application profiles. Although LOM itself gives no directive about elements that are compulsory or optional for describing an educational resource, application profiles often stipulate such requirements.
LOM, which in isolation is a relatively straightforward metadata framework, is also an important component of the Sharable Content Object Reference Model (SCORM). This ambitious educational initiative aims to foster the creation of reusable learning content as “instructional objects” within a common technical framework for computer and Web-based learning. SCORM was created as a collaborative effort among government, industry, and academia to establish a new distributed learning environment that permits the interoperability of learning tools and course content on a global scale. In essence, SCORM acts as a wrapper for various components specified using existing standards—one of which is a particular profile of the LOM standard. A properly configured Sharable Content Object (SCO) can be shared and reused because it can be executed by any compliant learning management system (such as Moodle).
A SCORM package can contain many other resources. It contains a manifest file, an inventory of all the individual files that constitute it, along with how they are pulled together to form the learning object. Three key elements are
resources, which are the building blocks out of which the learning object is formed;
items, which draw upon the resources and stipulate their organizational structure; and
object metadata, expressed using the IEEE LOM standard.
Metadata for eResearch
Digital libraries can store any type of digital object and are now being used to record the process and results of research. The aim is not just to store the process of research, but to further the advancement of knowledge by ensuring that experiments are reproducible. Traditional academic research articles appear in physical journals in paper form. Many journals now have online versions, and some are entirely electronic. As storage costs fall and network speeds rise, online journals can store supplementary resources as well. These research products include data sets, intermediate results, high-definition images, and computer code. This raises interesting questions about metadata. What are appropriate metadata schemes for describing, say, an archive of tree-ring width measurements?
Along with the ability to publish more of the background context of research papers, researchers seek access to data sets and source code in order to independently replicate or reproduce results.
Reproducibility calls for data sets and software to be made available for 1) verifying published findings, 2) conducting alternative analyses of the same data, 3) eliminating uninformed criticisms that do not stand up to existing data, and 4) expediting the interchange of ideas among investigators. Ultimately, all scientific evidence should be held to the standard of full replication and the confirmation of important findings by independent investigators.
A statement like this implies that the scope of traditional research papers is insufficient, and a panoply of research artifacts need to be preserved as well—along with metadata for searching, browsing, and understanding diverse objects. It is also likely that access to some artifacts will be restricted, making rights metadata critically important.
Researchers who commit to reproducibility as a principle in their own laboratories see positive effects within their groups. Students quickly get up to speed with previous work, and since the process has been archived, it is less critical if researchers forget small details. An alternative perspective is to view the problem as one of the
provenance of research results. What do we know about the history of data points as they pass through various processing stages?
Tools for recording and reproducing work come together in the form of workflow environments for eScience. For example, Taverna is a software tool for defining and executing workflows. Workflows contain actual executable code, as well as references to external Web services and a sequence of input/output operations. When a workflow is executed on a Taverna platform, the operations and results are reproduced. Soon researchers will need to be able to search, browse, and reuse such workflows in a variety of disciplines and digital libraries will need to support preservation of both the workflows and their products.
6.5. Metadata Quality
Supporting the development of quality metadata is perhaps one of the most important roles for Library and Information Science professionals.
The applications of metadata outlined earlier rely on the accuracy of the information. The quality of the available metadata constrains its usefulness in any digital library. Metadata quality can be considered across these seven dimensions:
• completeness
• accuracy
• provenance
• conformance to expectations
• logical consistency and coherence
• timeliness
• accessibility.
Consider the accuracy of metadata for personal names. Table 6.7 shows variations in the name of the Libyan leader
Mummar Qaddafi that appear in official documents. Some derive from the transliteration from Arabic into English, but they all refer to the same person. How is the software supposed to know about these connections? Librarians faced this problem many years ago, and the answer they devised is known as
authority control.
Authority control: Names
Authority control can apply to any set of values, but in practice it is most commonly used for personal names. The Library of Congress maintains millions of authority records in a Name Authority File as part of the MARC standard. Each record contains three sections:
• an authorized version of the name
• a list of variant versions (including other names or aliases)
• documentation and notes to provide the rationale for the authorized version.
Figure 6.11 shows an excerpt from the name authority record for
Mummar Qaddafi. The structure follows the MARC format of numbered fields: field 100 contains the authorized version, and 400 fields, many of which have been omitted from the figure, show the numerous variants. The 670 fields contain notes that help explain the authorized/variant split. Libraries can subscribe to the Name Authority File and receive updates as names are added and revised.

Name authority data can be used in diverse ways. For example, in a browsing structure of author names, all variants may be collapsed into the authorized version. Or search terms can be expanded. For example, a search for
Mark Twain can be expanded to include his other pseudonyms
Quintus Curtius Snodgrass and
Louis de Conte, as well as his actual name,
Samuel Langhorne Clemens. Such alternatives are recorded in the authority record's 500 field, whereas variants of the authorized version are in the 400 field. A system could expand a user's search automatically, or present the user with interactive expansion options. Although authority files are designed for metadata values, they could be used for full-text search or other applications.
Earlier we described MODS, an XML-based format for metadata that performs an analogous role to MARC. Accompanying it is an XML-based authority format, the Metadata Authority Description Schema (MADS). Figure 6.12 shows a sample MADS record with one authorized name (
Smith, John) and two variant versions (
Smith, J and
Smith, John J).

Through the relationships expressed in authority records, digital libraries can ensure a one-to-one relationship between people and conceptual items in the interface. They can also inform users about relevant relationships to other authors (as with Mark Twain). The alternative makes for an unpleasant user experience: authors that seem different but are in fact the same person, and, as a result of poor navigational support, browsing by author yields a messy list of uncontrolled names, which confuses users and fails to inspire confidence in the service.
The naïve user of an institutional repository, for example, will swiftly find that the absence of name authority control inhibits retrieval of items by a single author. Should a user arrive at a specific item and desire to see more items by the same author, clicking on the author's name will lead only to results for that particular name spelling or variant.
In these respects, authority control contributes to one of the seven quality dimensions, conformance to users’ expectations. Most digital library systems do a poor job, resulting in considerable manual work:
The institutional repository manager hoping for proper name-authority control currently has little choice but to clean up records by hand after the fact.
Rectifying this deficiency should be a priority for digital library software developers, so that collection managers can manage and display their information appropriately.
Authority control: Subjects
A widely used form of authority control for subjects is the Library of Congress Subject Headings (LCSH), a comprehensive controlled vocabulary for assigning subject descriptors. The print versions occupy five large volumes, amounting to about 6,000 pages each, commonly referred to by librarians as “the big red books.” Users generally encounter the subject headings in online library catalogs, and librarians encounter them in the system they use to manage and maintain the catalog. Once headings have been assigned to items in the library, they can be used for subject-based searching and browsing and to help inform users of common terms used to classify items in the collection.
The aim of the LCSH is to provide a standardized vocabulary for all categories of knowledge, descending to quite a specific level, so that books—on any subject, in any language—can be described in a way that allows all books on a given subject to be easily retrieved. There are a total of around two million different Subject Headings. Perhaps 60 percent of them are full entries like the one for
Agricultural machinery in the first row of Table 6.8. This entry indicates that
Agricultural machinery is a preferred term, and should be used instead of the three terms
Agriculture—Equipment and supplies,
Crops—Machinery, and
Farm machinery.
UF stands for “use for.” Each of the three deprecated terms has its own one-line entry that indicates (with a
USE link) that
Agricultural machinery should be used instead; deprecated terms account for the remaining 40 percent of entries in the red books. The
UF/USE links, which are inverses, capture the relationship of
equivalence between terms. One of each group of equivalent terms is singled out as the preferred one, not because it is intrinsically special, but purely as a matter of convention.
Another relationship captured by the subject headings is the
hierarchical relationship of broader and narrower topics, which are expressed by
BT (broader topic) and
NT (narrower topic), respectively (also inverses). The
Agricultural machinery example of Table 6.8 stands between the broader topic
Machinery and narrower topics, such as
Agricultural implements and
Agricultural instruments—there are many more not shown in the table. Each of these narrower topics will have links back to the broader topic
Agricultural machinery; and
Agricultural machinery will appear in the (long) list of specializations under the term
Machinery.
The abbreviation
RT stands for “related topics” and gives an
associative relationship between a group of topics that are associated but neither equivalent nor hierarchically related. The fact that
Farm equipment is listed as a related topic under
Agricultural machinery indicates that the converse is also true:
Agricultural machinery will be listed as a related topic under
Farm equipment.
Finally, the
SA (“see also”) entry indicates a whole group of subject headings, often specified by example—such as
Corn—Machinery under
Agricultural machinery in Table 6.8. The dash in this example indicates that there is a subheading
Machinery under the main entry for
Corn. However, there is no back reference from this entry to
Agricultural machinery.
The Library of Congress maintains a Subject Authority File, which is similar to the Name Authority File. Other organizations also maintain parallel subject authorities, such as the National Library of Medicine's Medical Subject Headings (MeSH).
Unfortunately, the current state of authority control implementation in digital library software systems is well behind that of traditional library catalogs. When choosing digital library software, you should consider how you intend to address issues of consistency, because you may find that there is little system support available.
Controlling metadata values
Name authority control and subject authority control improve the user experience and simplify the task of maintaining complex information structures. Before we examine other ways of controlling metadata values, we first consider some of the errors that can creep into metadata.
We are all familiar with typographical errors in text we read and write; of course, similar errors also occur in any human-assigned metadata. Common errors include:
• omissions:
Managment instead of
Management
• insertions:
Econnomics instead of
Economics
• transpositions:
Phsyics instead of
Physics
• substitutions:
Sosiology instead of
Sociology
Typographical errors abound whenever text is created by humans, and they occur in document text as well as metadata. In the main text, they reduce the accuracy of full-text searching, while in metadata they affect all kinds of metadata-enabled facilities. Errors also arise when metadata is transferred between different schemes and when it is migrated between different software systems. They also arise from automatic metadata extraction processes, which are often relatively noisy.
The controlled vocabularies of authority control are one way to address these issues. For example, when Library of Congress Subject Headings are used for subject metadata, we can expect our software system to flag incorrect entries (such as
Phsyics). Even better, it should prevent the entry of incorrect terms in the first place. The best place to stop errors from propagating is at the time of creation. Library catalog systems that implement the MARC/AACR2 standard contain numerous validation checks on the tags and subfields that prevent many forms of entry errors. The encoding schemes of qualified Dublin Core function in the same way—if implemented in the software.
Other common forms of metadata control include requirements that certain elements be present (for example, every item must have a title) or that the values of elements are constrained in appropriate ways. Such constraints include:
• Adopting the ISO 8601 international standard for date and time representation, which specifies patterns of date expression (for example, 1997-07-16T19:20+01:00 and 1997-07-16 are legal values, but 97-07-16 is not, because years must be expressed in four digits).
• Using similar pattern restrictions for URLs, MIME types (e.g.,
image/tiff,
video/quicktime), and digital object identifiers (see Section 7.3).
• Choosing values from restricted sets of externally defined possibilities, such as language codes (e.g.,
en-us,
fr,
es) and Library of Congress Subject Headings.
• Choosing values from a restricted set of locally defined possibilities (for example, ensuring that each item in an institutional repository is associated with a Department or Faculty identifier chosen from an approved list).
In practice, the ability to express constraints in your digital library metadata depends on the underlying software support. As with authority control, current digital libraries lag behind library catalog systems. This has several causes, including limited software functionality and inadequate resourcing—but fundamentally it reflects the fact that the digital library community has not yet evolved the same consortial approaches to metadata control.
Metadata tools
Managers of digital libraries should monitor the quality and characteristics of their metadata as their collections grow. However, their ability to assess the metadata is limited by the tools available: it is not feasible to hunt down metadata errors in large repositories manually. Although some of the quality dimensions listed earlier cannot be evaluated mechanically, others are easy to assess.
Completeness measures whether the value of a particular metadata element is defined across the entire collection. The requirement that all items should have a title is tantamount to saying that the completeness of the title element should be 100 percent. Analysis tools can report the completeness of each element to the collection manager and relate the results to any applicable constraints.
Figure 6.13 illustrates a tool that visualizes a collection's metadata for a subset of the Dublin Core elements by showing all the records in a scrolling table. Each column represents a metadata element and each row a document. The presence of a value is indicated by a filled rectangle; white areas indicate undefined items. The completeness percentage for each element appears at the bottom of the column.

Errors should be corrected as soon as they are detected. However, if they derive from automated processes, such as converting metadata from one scheme to another or extracting it from documents, they may occur on a large scale, and manual fixes are likely to be inordinately time-consuming. What is needed is the ability to change many values at once in a precise manner; in other words, batch editing of metadata—also known as
metadata cleaning. This can occur at any point in the workflow of a digital library. The edits or cleaning operations may be expressed in a pattern language (such as regular expressions) or a programming language. Again, most current digital library systems do not readily support such operations.
6.6. Extracting Metadata
We now turn to the business of extracting metadata automatically from a document's contents. Automatic extraction of information from text—
text mining, as it is often called—is a hot research topic. The ready availability of huge amounts of textual information on the Web has placed a high premium on automatic extraction techniques. In this area there is hardly any underlying theory, and existing methods use heuristics that are complex, detailed, and difficult to replicate and evaluate.
Plain text documents are designed for people. Readers extract information by
understanding their content. Indeed, text comprehension skills—reading documents and then being able to answer questions about them—have always been a central component of grade-school education. Over the past several decades, computer techniques for text analysis have been developed that can achieve impressive results in constrained domains. Nevertheless, fully automatic comprehension of arbitrary documents is well beyond their reach and will likely remain so for the foreseeable future.
Structured markup languages like XML help make key aspects of documents accessible to computers and people alike. They encode certain kinds of information explicitly in such a way that it can be extracted easily by parsing the document structure. Of course, except for the simplest of documents, this information falls far short of that conveyed by a complete and comprehensive understanding of the text.
Relatively few documents today contain explicitly encoded metadata. The balance will shift as authors recognize the added value of metadata, standards for its encoding become widespread, and improved interfaces reduce the mechanical effort required to supply it. However, although their role may diminish, schemes for extracting metadata from raw text will never be completely replaced by explicit provision of metadata.
Fortunately, it is often unnecessary to understand a document in order to extract useful metadata from it. In the following discussion we give several examples that indicate the breadth of what can be done, although we do not describe the techniques in full detail because they usually require considerable tuning to the problem at hand. The first three sections, extracting document metadata, generic entities, and bibliography entries, describe useful general techniques. The last four sections, language identification, extracting acronyms and key phrases, and generating phrase hierarchies, are facilities that are included in the Greenstone software described in Part II. This material pushes beyond the boundaries of what is conventionally meant by “metadata”—our focus is on extracting information that is generally of use in digital libraries rather than on any narrow interpretation of the term.
Extracting document metadata
Basic metadata about a document—its title, author, publisher, date of publication, keywords, and abstract—is often present on the first page for all to see. Moreover, it is frequently presented fairly uniformly: the title first, centered, followed by some white space; then the authors’ names and affiliations, also centered; followed by the publication date; keywords preceded by the word
Keywords; and an abstract, preceded by the word
Abstract or
Summary. Document families bear family resemblances. Different type sizes or typefaces may be used for different elements of the title page.
Such structure is easy to spot for a well-defined and tightly controlled family of documents. However, doing the same in a general way is not so easy. Furthermore, practical document collections often contain exceptions that human readers do not even notice as anomalies, but that confound automated extraction. Giving a full account of the techniques used for generic entity extraction is beyond the scope of this book. Instead we give some samplers. Some of the techniques described in the next subsection may be applicable in particular situations.
Generic entity extraction
Some information is easy to extract from plain text documents because it is expressed in a fixed syntax that is easy to recognize automatically. E-mail addresses and URLs are good examples, but, of course, they are both products of the Internet era: they are explicitly designed for automatic recognition and processing.
Other artificial entities are also readily recognized, although less reliably. Sums of money, times of day, and dates are good examples. But even these entities have variants. Dates can be expressed in several different ways that sometimes cause ambiguity, such as the date format 9/9/99, and time can be expressed in both the 12-hour (a.m. and p.m.) system and the 24-hour system (“1700 hours”). Some differences are cultural—for example, when sums of money are written in decimal currency, Americans and Europeans use the comma and period in opposite ways.
Names of people, places, and companies are an important kind of semistructured data, and it is often useful to identify them as metadata. Names can be recognized partly by intrinsic and partly by extrinsic properties. They almost always begin with capital letters. (But not always, as in the class of archaic English surnames, such as ffoulkes, the avant-garde poet e e cummings, and the contemporary singer k d lang. Also, capitalization as a name identifier loses much of its practical value in languages like German that capitalize all nouns.) However, in Western documents the statistical patterns in which letters appear differ between names and ordinary language in general, a trend that is accentuated by globalization, with the increasing incidence of foreign names. People's names are commonly preceded by forenames and may contain initials. There are numerous honorific prefixes, such as Mr., Ms., Dr., and Prof. Names may also include baronial prefixes, such as
von,
van, or
de, and other miscellaneous qualifiers, such as
Jr. or
Sr.
Extrinsic properties constrain the contexts in which names occur in text. People's names are often recognizable because they are introduced by phrases like “according to …” or “ … said.” Similar stock phrases characterize company names and place names. Indeed, sometimes entity names can be distinguished from people's names only by the surrounding words. When a string like
Norman occurs, context provides the only clue as to whether it is a place (Norman, Oklahoma), a person (such as Don Norman), or a race (the Normans). (Notice that this last sentence itself uses context to make the referents clear!)
Subsequent references to an already mentioned entity provide a further dimension of richness. Once a document has mentioned a person, place, or company, subsequent references may be abbreviated. Here, for example, it should be clear who cummings or lang is.
The task of identifying entities like times, dates, sums of money, and names in running text is called
generic entity extraction. Techniques can be broadly classed into three categories: those that use preprogrammed heuristics; those that can accommodate different textual conventions using manually tagged training data; and those that can self-adapt using untagged data.
When heuristics are preprogrammed, human intelligence is used to refine the extraction scheme manually to account for the vagaries of natural language usage. However, such heuristic entity extraction systems are never finished, and modifying such systems manually to account for newly discovered problems can be daunting—such systems quickly become practically unmanageable.
Some adaptive systems use training data in which the entities in question have been tagged manually. These systems embody a predefined generic structure that can adapt to the kinds of textual patterns that are actually encountered. Adaptation consists of adjusting parameters in accordance with pretagged training documents. This gives an easy way of catering to newly discovered variants: add some appropriate examples, manually tagged, to the training data.
Tagging training data is a boring, laborious, and error-prone task—particularly since large amounts of training data are often needed for such systems to work adequately. Therefore, some current research focuses on
self-adaptive techniques that, once primed, can work autonomously through large volumes of untagged documents to improve their performance. This approach promises good performance with a minimum of manual effort. However, its inherent limitations are not yet known.
Bibliographic references
Many documents contain bibliographic references, which constitute an important kind of metadata—although now we are beginning to stretch the conventional meaning of the term—that is extremely useful both for characterizing the topic of the article and for linking it to related articles. Traditional citation indexes identify the citations that a document makes and link them with the cited works. An advantage of citation indexes is the capacity for navigation forward, by listing articles that cite the current one, as well as backward, through the list of previously cited articles. Scholars find citation indexes useful for many purposes, including locating related literature, placing given articles in context, evaluating their scientific influence, and analyzing general research trends to identify emerging areas.
It is not hard to automatically locate lists of references in the plain text of a document with a reasonable degree of accuracy. Then each reference is parsed individually to extract its title, author, year of publication, page numbers, and so on, and the tag that is used to cite it in the body of the document (e.g., [1]). The special structure of references makes this easier than the general problem of generic entity extraction. Fields with relatively little variation in syntax and position should be identified first; then the relative position of not-yet-identified fields can be exploited to predict where they occur (if they are present at all). For example, author information often precedes the title, and publisher information often comes after it. Databases of author's names, journal names, and so on can be used to help identify the fields.
The power of a citation index depends on the ability to identify the article that is being referenced and to recognize different references to the same article. Thus, references must be normalized and heuristics must be used to identify when they refer to the same article.
Language identification
Two important pieces of metadata that can be readily and reliably derived from a document's content are the language in which it is written and the character encoding scheme used. Assigning such values is an example of text categorization, in which an incoming document is assigned to some preexisting category. Because category boundaries are almost never clear-cut, it is necessary to be able to recognize when a given document does not match any category, or when it falls between two categories. Also, to be useful, the process must be robust to spelling and grammatical errors in text, and to character recognition errors in OCR'd documents.
A standard technique for text categorization computes a profile that consists of the “
n-grams,” or sequences of
n consecutive letters, that appear in each document. From a training set containing several documents in each language or encoding scheme, a profile is obtained for each category. Then, given an unknown document, a distance measure between that document's profile and each category profile is calculated. The category whose profile is closest is selected—if none is close enough, no category is selected.
It is sufficient for successful language identification to consider just the individual words that make up the documents—the effects of word sequences can be neglected. Documents are preprocessed by splitting the text into separate word tokens consisting only of letters and apostrophes (the usage of digits and punctuation is not especially language-dependent). The tokens are padded with a sufficient number of spaces, and then all possible
n-grams of length 1 to 5 are generated for each word in the document. These
n-grams are counted and sorted into frequency order to yield the document profile.
In document profiles the most frequent 300 or so
n-grams are highly correlated with the language. The highest-ranking
n-grams are mostly unigrams consisting of one character only, and simply reflect the distribution of the letters of the alphabet in the document's language. Starting around rank 300 or so, the frequency profile begins to be more specific to the topic of the document.
A simple metric for comparing a document profile to a category profile is to calculate, for each document
n-gram, the difference between its positions in the two profiles—how far “out of place” it is. Document
n-grams that do not appear in the category profile are given some maximum value. The total of these “out of place” figures gives a measure of the overall difference. An unknown document is assigned to the category with the closest profile.
A small experiment demonstrates the accuracy of this method. About 3,500 articles in Internet newsgroups were used, written in eight different languages—Dutch, English, French, German, Italian, Polish, Portuguese, and Spanish. An independent training set contained a modest sample of each category, ranging from 20 to 120 KB in length. Only the most frequent 400
n-grams in each category profile were used. The system misclassified only seven articles, yielding an overall accuracy of 99.8 percent, an accurate way, therefore, of automatically assigning language metadata to documents.
Acronym extraction
Technical, commercial, and political documents make extensive use of acronyms. With a list of acronyms and their definitions, users can click acronyms to see their expansion and check whether acronyms are being used consistently in the collection. The dictionary definition of
acronym is
a word formed from the first (or first few) letters of a series of words, such as
SCUBA for Self-Contained Underwater Breathing Apparatus.
Acronyms are often defined at their first use by a preceding or following textual explanation, as in this example. Finding them, along with their definitions, in technical documents is a problem that can be tackled using heuristics. The information desired—acronyms and their definitions—is relational, which distinguishes their extraction from many other information extraction problems.
One way of identifying acronyms is to encode potential acronyms with respect to the initial letters of neighboring words. With a well-chosen coding scheme, this should achieve a more efficient representation that can be detected by measuring the compression achieved. The criterion is whether a candidate acronym can be coded more efficiently using a special model than it is using a regular text compression scheme. A phrase is declared to be an acronym definition if the discrepancy between the number of bits required to code it using a general-purpose compressor and to code it using the acronym model exceeds a certain threshold.
The first step is to identify candidates for acronyms—for example, all words that are expressed in uppercase only. The definition may precede or follow the acronym itself and invariably occurs within a window of a fixed number of preceding or following words—say 16 words.
Candidate acronyms are expressed in terms of the leading letters of the words on either side; we omit the technical details. Then all legal encodings for each acronym are compared and the one that compresses best is selected, and this is then compared with the version compressed using a generic text model. Incidentally, it is a curious fact that, using a standard text model, longer acronyms tend to compress into fewer bits than do shorter ones. The reason is that, whereas short acronyms are often spelled out, long ones tend to be pronounced as words. This affects the choice of letters: longer acronyms more closely resemble “natural” words.
Needless to say, acronym extraction is not entirely perfect. However, experiments on a sizable sample of technical reports show that the scheme we describe here performs well and provides a viable basis for extracting acronyms and their definitions from plain text.
Key-phrase metadata
In the scientific and technical literature, keywords and phrases are often attached to documents to provide a brief synopsis of what they are about. (Henceforth we use the term
key phrase and regard keywords as one-word key phrases.) They condense documents into a few pithy phrases that can be interpreted individually and in isolation. Their brevity and precision make them useful in a variety of information-retrieval tasks: as document surrogates, for search indexes, as a means of browsing an information collection, and as a document clustering technique. Key phrases can be used to help users get a feel for the content of an information collection, to provide sensible entry points into it, to show how queries can sensibly be extended, to support novel browsing techniques with appropriate linkage structures, and to facilitate document skimming by emphasizing important phrases visually. They also provide a way of measuring similarity among documents.
The key phrases that accompany articles are chosen manually. In academia, authors assign key phrases to documents they have written. Also, librarians often select phrases from a controlled vocabulary that is predefined for the domain at hand (e.g., the Library of Congress Subject Headings; see Section 6.5). However, the great majority of documents, particularly those on the Web, don't have key phrases, and assigning them manually is a laborious process that requires careful study of the document and a thorough knowledge of the subject matter.
Surprisingly, perhaps, key-phrase metadata can be obtained automatically from documents with a considerable degree of success. There are two fundamentally different approaches: key-phrase
indexing, where a controlled vocabulary is used, and key-phrase
extraction, where key phrases are identified without a controlled vocabulary. Both approaches perform best when a training algorithm is defined that uses a set of documents to which key phrases have already been attached manually.
Key-phrase extraction
Extracting key phrases involves first identifying candidate phrases that occur in the document and then using heuristics to select those that characterize it best. Most key phrases are noun phrases, and syntactic parsing can identify the candidates. The features used for selection range from simple ones, such as the position of the phrase's first occurrence in the document, to more complex ones, such as its occurrence frequency in the document versus its occurrence frequency in a corpus of other documents in the subject area. The training set is used to tune the parameters that balance these different factors. This process uses methods of machine learning, and it would take us too far off track to describe them here.
How accurate are such methods? Suppose a well-tuned extraction algorithm is used to select half a dozen key phrases for a particular document, and these key phrases are compared with phrases selected manually by the document's author. Generally speaking, one might expect one or two of the key phrases to match exactly or almost exactly, one or two others to be plausible phrases that the document author happened not to choose, and the remaining two or three to be less satisfactory key phrases.
As an example, Table 6.9 shows sample output for three research papers in computer science. For each paper the title is shown, along with two sets of key phrases: one set assigned by its author, the other assigned by an automatic procedure. The phrases are aligned to make them easier to compare. It is not hard to guess that the ones on the left are the author's. Although many of the automatically extracted key phrases on the right are plausible, some are strange. Examples are
gauge and
smooth for the second paper;
smooth is not even a noun phrase. The key phrase
garbage for the third paper is a complete giveaway—while that word may be used repeatedly in a computer science paper, and even displayed prominently in the title, no author is likely to choose it as a keyword for a paper! Although automatically extracted key-phrase metadata may not reflect exactly what the author might have chosen, it is useful for many purposes.
Key-phrase indexing
Key-phrase indexing depends on a controlled vocabulary or thesaurus that contains legitimate index terms. Thesauri include relations between terms, such as those in the Library of Congress Subject Headings:
USE and
UF (use for) for synonyms;
BT and
NT for broader and narrower terms; and
RT for related terms. These relational links can provide valuable assistance to the algorithm in choosing the most appropriate index terms for documents.
The indexing procedure begins by identifying candidate phrases in the document, just like key-phrase extraction. However, in indexing, the identified phrases are then sought in the controlled vocabulary, and ones that cannot be found are discarded. First, though, they are normalized by removing stop-words such as
the and
a, stemming all words to their grammatical roots, and disregarding the order of words in the comparison with phrases in the controlled vocabulary. (Word order is rarely significant in actual key phrases.) Thus, phrases like
an efficient algorithm and even
these algorithms are very efficient would be matched to the index phrase
algorithm efficiency. So, of course, would
these algorithms are not very efficient—but, when you think about what index terms are used for, that is perfectly appropriate.
Terms are also conflated by replacing synonymous alternatives (as indicated by USE/UF links) with the preferred form. This greatly extends the approach of conflation based on word-stem matching and also (unlike key-phrase extraction) allows terms that do not actually appear in a document to be assigned to it. The result is a much more reliable set of candidate terms than for key-phrase extraction.
As before, the next step is to use heuristics to select the candidates that characterize the documents best. The same features mentioned above—such as position of first occurrence, and relative frequency—can be used. Moreover, the thesaurus permits the addition of new features, such as the frequency of individual terms and their degree of connectedness to other candidate terms for the document. Again, a training set is used to tune the parameters that balance the different factors using methods of machine learning.
Results of key-phrase indexing depend on the documents and the thesaurus, but they are often surprisingly good. In Table 6.9, for example, rogue words like
smooth would be eliminated because they are absent from the controlled vocabulary; more specific terms like
gauge fields would be preferred to general ones like
gauge because of their greater connectivity with other terms in the document. The only key phrases that can be assigned are ones that occur in the thesaurus, ensuring that all key phrases are well formed, but at the same time barring novel topics from consideration. In contrast, key-phrase extraction is open-ended: it selects phrases from the document text itself.
Experiments have shown that key-phrase indexing techniques rival the work of professional indexers in terms of consistency if a focused domain-specific thesaurus is employed. Wikipedia article names can serve as a large and extremely general thesaurus for index terms and inter-relationships among the terms can be inferred from hyperlinks and other information in Wikipedia itself. The size of the resultant “Wikipedia thesaurus” has several million terms and exceeds that of the Library of Congress Subject Headings. While admittedly Wikipedia terminology is nowhere near so carefully controlled, proponents point out that it reflects contemporary usage of living language, which real users are likely to employ when searching and browsing. Again, experiments have shown that automatic techniques can outperform subject specialists, in terms of consistency, when assigning relevant Wikipedia articles to documents.
6.7. Notes and Sources
The quotation at the beginning of this chapter is from Gilliland-Swetland (1998), from which the five-part categorization of different functions of metadata in Section 6.1 is also taken. The quotation at the beginning of Section 6.1 is from Weinberger (2007, p. 222).
Chapter 1 of Intner et al. (2006) provides a good overview of different metadata categorizations. Lagoze and Payette (2000) give an interesting and enlightening discussion of metadata. They point out that the term is meaningful only in a context that makes clear what the data itself is, and they discuss the different kinds of metadata identified at the start of this chapter.
The quotation about MARC near the beginning of Section 6.2 is from Avram's obituary (Australian Library and Information Association, 2006). Details of the MARC record structure are presented in books on library automation—for example, Cooper (1996). The
AACR2R cataloging rules are published by the American Library Association (Gorman and Winkler, 1988). Svenonius (2000) gives a readable account of them, and she quoted the extract about naming a local church. The information about the size of the WorldCat union catalog is from the Online Computer Library Center Web site. Information about MARCXML can be found at www.loc.gov/standards/marcxml.
The Dublin Core metadata initiative is described by Weibel (1999). Thiele (1998) gives a review of related topics. More recent information, including qualified Dublin Core and current developments, is available on the official Dublin Core Web site, http://dublincore.org (also http://purl.org/dc).
BibTeX, part of the TeX system invented by Knuth (1986), is covered by Lamport (1994). The EndNote bibliographic system, a commercial reference database and bibliographic software program, can be obtained from www.endnote.com. A description of Refer, on which the EndNote format is based, is included in the Unix manual pages.
The TIFF specification is provided online by Adobe and can be found at http://partners.adobe.com/asn/developer/technotes/prepress.html. The EXIF format is published by the Japan Electronics and Information Technology Industries Association (JEITA); a useful unofficial site is http://exif.org. The XMP home page is at www.adobe.com/products/xmp; IPTC is at www.iptc.org. The MIX fragment in Figure 6.3 is from the Library of Congress, who maintain the standard at www.loc.gov/standards/mix.
MP3 ID3 tags are described at www.id3.org. Vorbis comments are described at www.xiph.org/vorbis/doc/. The FLAC format is covered at http://flac.sourceforge.net. Apple's
iTunes metadata appears not to be publicly documented but various Web sites present the results of reverse engineering the files—with all the accompanying caveats about accuracy. Wells et al
. (2006) cover MXF in depth.
Comprehensive information about MPEG-7 and MPEG-21 is available from the MPEG home page, www.chiariglione.org/mpeg. A readable early account of the MPEG-7 standard is given by Nack and Lindsay (1999a, 1999b). Wang (2004) gives a brief overview of the MPEG-21 rights expression language, while Bekaert et al. (2003) give an example of using it in a digital library context.
Cundiff (2004) gives an overview of METS, while Dappert and Enders (2008) provide a good example of using several metadata schemes within it. PREMIS, like MPEG, is the name of a working group, PREservation Metadata—Implementation Strategies, and is located at www.loc.gov/standards/premis. The “on a horse” problem is from Wendler (2004). Freire et al. (2008) give a useful survey of provenance.
The quotation about reproducibility and eResearch is from Peng et al. (2006). Calls for replication are not confined to the hard sciences: see King (1995) in the area of politics. Schwab et al. (2000) discuss the positive experiences that stem from using reproducibility as a principle when running a laboratory. The Taverna workflow system can be found at http://taverna.sourceforge.net.
The quotation about metadata quality at the beginning of Section 6.5 is from Robertson (2005); Beall (2006) gives an overview of metadata quality problems. The 30th edition of the LCSH was published in 2007 (Library of Congress, 2007). The Library of Congress authority file can be searched online at authorities.loc.gov. The MADS example is from the Library of Congress, who maintain the standard at www.loc.gov/standards/mads. The quotation bemoaning the lack of name-authority control in institutional repositories is from Salo (2009). The National Library of Medicine's Medical Subject Headings (MeSH) can be found at their Web site, www.nlm.nih.gov/mesh. The visualization tool in Figure 6.13 that shows the completeness of metadata elements in an institutional repository is described by Nichols et al. (2008).
An account of an excellent and widely used automatic citation indexing system that embodies the techniques mentioned for extracting bibliographic references is given by Giles et al. (1998). The method described for language identification was developed and investigated by Cavnar and Trenkle (1994) and implemented in a system called TextCat. The acronym extraction algorithm was developed and evaluated by Yeates et al. (2000). Different systems for browsing using key phrases are described by Gutwin et al. (1999) and Jones and Paynter (1999). Dumais et al. (1998) describe state-of-the-art text classification techniques for key-phrase assignment, while Frank et al. (1999) and Turney (2000) describe key-phrase extraction. Medelyan and Witten (2008) describe the process of key-phrase indexing and report experiments that show that automatic techniques can rival the work of professional indexers.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.