
Chapter 7. Interoperability
Protocols and services
Interoperability is the name of the game for libraries. An important part of traditional library culture is the ability to locate copies of information in other libraries and receive them on loan—interlibrary loan. Libraries work together to provide a truly universal international information service. The degree of cooperation is enormous and laudable. What other large organizations cooperate in this way?
Interoperability is the name of the game for libraries. An important part of traditional library culture is the ability to locate copies of information in other libraries and receive them on loan—interlibrary loan. Libraries work together to provide a truly universal international information service. The degree of cooperation is enormous and laudable. What other large organizations cooperate in this way?
Digital libraries, like library catalogs before them, are a product of a networked environment. Information can flow between different systems, between clients and servers, and between people and institutions. The examples we have seen so far have assumed the existence of a network and of cooperating systems. However, these interconnected systems did not come about by accident; they required the development of common understandings about the nature of data formats. It is these communication protocols that allow the reach of digital libraries to extend across our networked world and to interoperate.
This chapter begins by examining two key protocols in the digital library world: the relatively recent Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) and the long established Z39.50 standard. These protocols are separated historically by a decade and a half, culturally by the communities in which they arose, and ideologically by the approach taken. Z39.50 has been developed by standards committees whose members come from widely disparate backgrounds and who have very different agendas. Z39.50 supports a rich set of commands but it is large and complex to implement. OAI-PMH, on the other hand, is simpler and more focused on particular requirements. However, the protocols share the same aim, communicating with digital repositories, and common elements and themes recur between them.
As digital libraries pervade the workplace, the collective needs of users mushroom. The standard
modus operandi of Web usage is to reach a new document by clicking on a button or hyperlink—and this is the standard method for a digital library, too. How can we step outside this model in a flexible way that does not involve a heavy commitment to a particular alternative? The answer is to provide fine-grained interaction with the content of a digital library through a defined protocol that others can use. A Web Service is defined as a software system designed to support interoperable machine-to-machine interaction over a network, and Web Services are becoming a popular way for digital libraries to supply their content to other systems and interfaces that are designed to satisfy particular user needs. For example, Search/Retrieval via URL (SRU) is a more recent standard (derived from Z39.50) that recasts Z39.50-like requests in the form of Web Services.
Protocols for spreading content and metadata address some of the questions we posed in Chapter 1 (Table 1.1) concerning the sharing of resources—in particular, questions about exporting material from the library and interoperating with other libraries. When institutions hosting digital collections agree to share, it is these protocols that make it happen. Another enabling technology for sharing on the Web is the availability of standard methods that reliably identify digital resources. We have seen how stable URLs are central to the Web (Section 2.4)—imagine how inconvenient it would be if all the URLs you used were only valid for a few days! In this chapter we describe technological support for long-term stable URLs. Section 7.5 returns to some of the access issues discussed in Chapter 2 and outlines techniques for authenticating users. Finally, Section 7.6 presents two widely used open-source digital library systems, DSpace and Fedora, and discusses how they operate and interoperate.
7.1. Z39.50 Protocol
The Z39.50 standard defines a wide-ranging protocol for information retrieval between a client and a database server. It is administered by the Library of Congress, and progressive versions of the specification were ratified by standards committees in 1988, 1992, 1995, and 2003.
Z39.50 is an example of an application layer of the Open System Interconnection (OSI) Reference Model, a comprehensive standard for networked computer environments. Message formats are specified using Abstract Syntax Notation One (ASN.1) and serialized for transmission over the OSI transport layer using Basic Encoding Rules (BER). The Transmission Control Protocol (TCP) is typically used for the actual information communication.
Accessing and retrieving heterogeneous data through a protocol in a way that promotes interoperability is a challenging problem. To address the broad spectrum of different domains where it might be used—such as bibliographic data, museum collection information, and geospatial metadata—Z39.50 includes a set of classes, called
registries, that provide each domain with an agreed-upon structure and attributes. Registries cover query syntax, attribute fields, content retrieval formats, and diagnostic messages. For example, content retrieval formats include Simple Unstructured Text Record Syntax (SUTRS) and the various MARC formats.
The Z39.50 protocol is divided into eleven logical sections (called
facilities) that each provide a broad set of services. We cannot do justice to the myriad details here, but instead convey some idea of the functionality supported. Table 7.1 gives a high-level summary of each category.
The protocol is predominantly client-driven; that is to say, a client initiates a request and the server responds. Only in a few places does the server demand information from the client—for example, the Access Control Facility might require the client to authenticate itself before a particular operation can be performed. Any server that implements the protocol must retain information about the client's state and apportion resources so that it can respond sensibly to clients using the Initialization Facility, which sets resource limits. Mandatory search capabilities include fielded Boolean queries, which yield result sets that can be further processed by the Sort and Browse Facilities or canceled by the Result-set-delete Facility. Results themselves are returned through the Retrieval Facility. At any stage the response to a request might be an error diagnostic.
Establishing which of the many Z39.50 options, registries, and domain-specific attributes are supported by a particular server is accomplished through the Explain Facility. The Extended Services Facility is a mechanism for accessing server functionality that persists beyond the duration of a given client-server session—for example, periodic search schedules and updating the database. The client-server session can be canceled immediately by either side through the Termination Facility.
A particular Z39.50 system need not implement all parts of the protocol. Indeed, the protocol is so complex that full implementation is a daunting undertaking and may in any case be inappropriate for a particular digital library site. For this reason, the standard specifies a minimal implementation, which comprises the Initialize Facility, the Search Facility, the Present Service (part of the Retrieval Facility), and Type 1 Queries (part of the registry).
Using this baseline implementation, a typical client-server exchange works as follows. First the client uses the Initialization Facility to establish contact with the server and negotiate values for certain resource limits. This puts the client in a position to transmit a Type 1 query using the Search Facility. The number of matching documents is returned, and the client then interacts with the Present Service to access the contents of desired documents.
7.2. Open Archives Initiative
The Open Archives Initiative (OAI) was motivated by the electronic preprint community, which has a strong desire to increase the availability of scholarly repositories and to enhance access to them. Part of the initiative has been to devise a protocol for the efficient dissemination of content, the OAI Protocol for Metadata Harvesting, OAI-PMH, which is often abbreviated to just OAI. This protocol is intentionally broad and independent of content, making it useful to a wide range of areas, not just scholarly information. It is “open” in the sense that its definition is freely available and its use is encouraged. The term
archive should not be taken to imply only the compilation of digital material for historical purposes—although this is certainly one use.
OAI Protocol for Metadata Harvesting: OAI-PMH
OAI-PMH is intended as a standard way to move metadata from one point to another within the virtual information space of the World Wide Web. It supports interaction between a
data provider and a
service provider—a renaming of the client-server model that emphasizes that interaction is driven by the client (the service provider) and that the client alone has the onus of deciding what services are offered to users. Data providers, in contrast, are in the business of managing repositories. They export on-demand data records in a standardized form, unencumbered by any consideration of how the information will be used. If other operations, such as text searching, are to be supported, they must be performed by the service provider, not the data provider. Of course, a site may choose to be both a service provider and a data provider. It may also manage more than one repository.
A key technical goal of the protocol is that it be easily implemented using readily available software tools and support. The protocol provides a framework, using HTTP, in which requests are encoded in URLs and executed by programs on the server. Results are returned as XML records. Figure 7.1 shows the basic form of interaction using an example that requests a record pertaining to a particular document identifier and expressed using Dublin Core metadata. First the arguments are encoded into a URL (characters like : and / must be specially coded) and dispatched over HTTP. The response is an XML document that draws heavily on XML namespaces and schemas.

XML namespaces are a way of ensuring that markup tags intended for a particular purpose do not conflict with other tag sets, and XML Schema is a way of extending the idea of predefined tag sets and document structure with typed content. For example,
responseDate in OAI is defined to be the complete date, including hours, minutes, and seconds, using the schema type
xsd:timeInstant.
The top-level element in the example record is
GetRecord. Through its attributes this sets up a suitable namespace using a URL in the Open Archives Web site and specifies the defining XML Schema stored at the same site. Nested deeper in the
GetRecord structure is a
metadata element that uses the Dublin Core namespace and a schema specifically for this metadata standard that is also defined at the Open Archives site.
Within the
metadata element is the main content—expressed, as requested, using Dublin Core metadata—for the digital item that matches document identifier
oai:nzdl:hdl/018cf2f4256b4c8827e747b8. The book is titled
Farming Snails and was written for the Food and Agriculture Organization of the United Nations (and part of the Humanity Development Library featured in Chapters 1 and 3). Further information supplies a brief description of its content, gives the year of publication, declares that it is principally text, and states its format as HTML. This particular record is rich in metadata, but the protocol does not require this level of richness.
The protocol supports six services through the
verb argument, and Table 7.2 summarizes them.
Identify and
ListSets are services that are typically called early on in a client's interchange with a server to establish a broad picture of the repository. Figure 7.2 shows an example of a response to an
Identify request, which contains administrative information about the server: in this case, the OCLC's OAICat Repository Framework, whose repository name is
IDEALS @ UIUC. ListIdentifiers is a way of receiving all the document identifiers or a group that matches a stipulated set name.
ListMetadataFormats can be applied to the repository as a whole or to a particular document within it to establish which metadata formats are supported. Dublin Core is mandatory, but other formats, such as MARC, which has the capacity to export a greater volume of metadata per record, may also be supported. We have already seen
GetRecord in action in the example just given—
ListRecords is similar except that more than one record can be returned, and group selection is possible with the same set-naming technique used by
ListIdentifiers.

These are the general facilities supported by the protocol. Greater flexibility can be achieved using the input arguments and the set and resumption mechanisms. First, repository items can be categorized into sets—multiple hierarchies, where an item can be in more than one hierarchy or in none at all. Each node in the hierarchy has a set name, such as
beekeeping, and a descriptive name, such as
Beekeeping and honey extraction. Its hierarchical position is specified by concatenating set names separated by colons—like
husbandry:beekeeping.
ListSets returns this information for the complete repository, marked up as XML.
The set mechanism means that instead of retrieving all the document identifiers, a service provider can restrict the information returned by
ListIdentifiers to a particular set. (The same applies to
ListRecords.) Because records in the repository are date-stamped, the information returned can be restricted to a particular range of dates using
from and
until arguments. Even so, the list of data returned may still be excessively long. If so, a data provider might transmit part of the data and include a
resumption token in the record. This mechanism enables the service provider to contact the data provider again and request the next installment (which might include another resumption token).
The OAI protocol makes use of the HTTP status code mechanism to indicate the success or failure of a request. Status code 400, in this context, indicates a syntactic error in the request, such as an invalid input argument. Other forms of failure, such as a repository item being unavailable in the requested metadata format, produce null data in the XML record that is returned.
Serving
OAI-PMH imposes no requirements on how metadata is represented on the server of a data provider. The metadata can be stored in a database, as simple XML files, or even embedded within other documents. All that matters is that the data provider responds to protocol requests with appropriate responses; in the case of metadata embedded in documents, the metadata would first have to be extracted and then packaged up as an OAI-PMH response.
It is even possible to have a static metadata repository. A static repository is a single XML file that contains all the metadata a data provider wishes to share. This file needs to be registered with a Static Repository Gateway, which then performs the appropriate transformations to allow service providers to access the metadata. Static repositories are only really appropriate for small collections that do not change frequently. Most digital library systems come with OAI-PMH support built in, although they may only support basic Dublin Core metadata. Support for qualified Dublin Core (or MODS, METS, etc.) is rarer; as a result, although a digital collection may have detailed internal metadata, only a subset may be available via OAI-PMH. Naturally, such restrictions limit the applications that OAI service providers can create.
Harvesting
OAI-PMH was designed to allow structured retrieval of metadata on the Web. We can usefully contrast this with the unstructured approach of Web harvesting, or Web mirroring. When the remote resources are as varied as Web content, then most attempts to gather metadata will produce uneven results. There is no standard metadata scheme for Web content, and although metadata like Dublin Core is sometimes embedded within HTML, it is not present in sufficient quantity or with enough reliability to be of much use. OAI-PMH, on the other hand, provides structure through a defined protocol, which is a necessary condition for effective metadata sharing. However, a protocol by itself does not guarantee that the metadata available is of good quality.
Creating and sharing quality metadata is not a straightforward task. It requires appropriate tools, trained staff, and a long-term commitment to resource availability. Although the technologies may be relatively simple, this is only a
necessary condition for success, and without the associated human support it will not be sufficient. One example of a large-scale effort to harvest OAI metadata has been the U.S. National Science Digital Library (NSDL), which began in 2003 to implement a digital library based on metadata aggregation using Dublin Core and OAI-PMH. However, a retrospective analysis in 2006 found that these standards, which are supposed to be easy to adopt with a low human cost, were harder to deploy than expected.
Our expectation was that Dublin Core and OAI-PMH were relatively simple and that surely every collection provider would be able to implement them and be integrated into the National Science Digital Library. In fact, reality fell far short of our expectations. We discovered that the WorldCat paradigm, which works so well in the shared professional culture of the library, is less effective in a context of widely varied commitment and expertise. Few collections were willing or able to allocate sufficient human resources to provide quality metadata.
The comparison here is with WorldCat, the world's largest bibliographic database. WorldCat combines the collections of more than 10,000 libraries from over 100 countries that participate in the Online Computer Library Center global cooperative. It comprises 125 million different records pointing to physical and digital assets in more than 500 languages. (These statistics quickly become outdated, however, because a new record is added to the database on average every 10 seconds.)
Overall, OAI-PMH has been a successful method of sharing metadata. Its widespread adoption is due to the simplicity of the protocol and its building on top of other existing standards: HTTP, XML, and Dublin Core.
7.3. Object Identification
The Web scheme of Uniform Resource Locators (URLs) has been a great success. It has passed from the world of computer networking to common usage. URLs enable users to refer to resources, whether simple HTML documents or services, and be fairly confident that if they use those URLs again the URLs will still refer to the same things. Furthermore, computer programs can refer to external resources in the same way.
However, every Web user has clicked a link and received a message indicating that the target was not found (in raw form this message cryptically states “404 not found,” although Web servers often translate it into something more informative and helpful). Sometimes, the explanation is that the link was incorrectly written—there was a typo in the HTML file—but often the target resource has been moved. The one-way link structure that underlies the Web means that when a resource is moved to a different URL, a Web browser that finds the old link on some other HTML page cannot ascertain the new destination. Dead links are particularly frustrating when you think you have just found the document you were looking for only to be foiled at the last step. It is even worse for Web-based software services, which, being computer programs, may simply stop working altogether, leaving their users completely stymied. Consequently, it is very useful for URLs, or, more generally, digital object identifiers, to be robust.
Many schemes have been devised to make identifiers persist over time. The basic idea is to register names with ultra-reliable servers that keep track of their actual location (URL). Any reference to the resource goes through a server, which knows where the resource actually is. When a resource (such as a document in a digital library) is moved, this server must be notified. Without these long-life approaches,
link rot sets in—links to the content start to fail, and users become frustrated that (in this case) the digital library is unreliable and hard to use. Two generic approaches for naming Internet objects are the Uniform Resource Name (URN) and the Uniform Resource Identifier (URI). Both are specifications, not implementations, and both are the subject of considerable debate. We previously encountered these in Section 6.4 in connection with the Resource Description Framework (RDF).
Handles
An early technical solution to the problem of persistence was the Persistent URL (PURL), operated by the Online Computer Library Center (OCLC). Instead of describing the location of the resource to be retrieved, a PURL gives an intermediate, persistent, location which, when retrieved, is automatically redirected to the current location of the resource. A similar technical solution called Handle, from the Communications Network Research Institute (CNRI), is implemented as a Java-based program for assigning, managing, and resolving persistent identifiers for digital objects on the Internet.
The PURL and Handle systems (and the DOIs discussed below) are similar in that they maintain a database of the relationship between a name and an actual URL. When a user or a piece of software has the name, it uses a
resolution service to convert the name into an actual URL. If the actual URLs need to be changed, typically because the content has moved to a new server, only the database is updated.
Handles can be resolved by typing into any Web browser the string
http://hdl.handle.net/
followed by the Handle itself. For example, a paper called
Building digital library collections with Greenstone can be found in the University of Waikato Research Commons at http://hdl.handle.net/10289/1825. The resolution service (at http://hdl.handle.net) takes the object's Handle (10289/1825) and returns a URL (at the time of writing, http://waikato.researchgateway.ac.nz/handle/10289/1825). When used in a Web browser, the effect is to seamlessly navigate to the actual URL. However, Handles can be used just as easily by software applications outside of a browser, provided they use the HTTP protocol.
Digital object identifiers: DOIs
Achieving persistence is not really a technical problem, or even a naming problem. It's an organizational problem. To make URLs persistent, all you really need is a mechanism for assigning names, and an organization that administers them and records their locations—an organization that is expected to persist over time and is scalable enough to meet the world's needs. A scheme that is actually in use is the Digital Object Identifier (DOI), which is a
de facto practical implementation of the URN and URI specifications using the Handle system. In fact, DOIs are Handles with the prefix “10.” (The Handle system also incorporates other namespaces.)
The International DOI Foundation defines a Digital Object Identifier as a permanent identifier for any object of intellectual property and explains that it is used to identify a piece of intellectual property on a digital network and associate related data with it in an extensible way. A typical use is to give a scholarly article a unique identification number that anyone can use to obtain information about its location on a digital network. DOIs can easily be resolved: just type in the address bar of any Web browser the string
http://dx.doi.org/
followed by the DOI of the document. For example, the paper mentioned above has the DOI 10.1145/1065385.1065530, and you can see it at http://dx.doi.org/10.1145/1065385.1065530. The resolution service (at http://dx.doi.org/) takes the object's name (10.1145/1065385.1065530) and returns a URL (http://portal.acm.org/citation.cfm?doid=1065385.1065530). This identifies a copy of the document in the ACM Digital Library, rather than the one mentioned above at the University of Waikato.
DOIs are administered by the International DOI Foundation, a consortium that includes both commercial and non-commercial partners, and are currently being standardized through ISO. The structure of the DOI conveys these pieces of information:
• The prefix 10.1145 identifies the naming authority who assigned the DOI (10 is the directory code; 1145 is the publisher ID).
• The suffix 1065385.1065530 is the item ID or local name.
As noted earlier, DOIs build upon the Handle system, and DOIs are Handles with the directory code “10,” which refers to the International DOI Foundation. The publisher ID 1145 indicates the Association for Computing Machinery (ACM). Other examples include 1000, which is used by the International DOI Foundation itself, and 1007, which is used by the Springer publishing house.
The prefixes are guaranteed unique because they are registered with the global Handle Registry, and the Handle syntax ensures that suffixes are unique within the namespace defined by the prefix. The DOI directory code (10 above) is a prefix in the Handle system, and the DOI prefix 10.1145 is known as a
derived prefix. Because DOIs are themselves Handles, the same document that we discussed above can also be found in the ACM Digital Library by resolving the DOI through the central Handle server: http://hdl.handle.net/10.1145/1065385.1065530.
DOIs are administered by agencies recognized by the International DOI Foundation. They register identifiers, allocate prefixes, and allow registrants to declare and maintain metadata. The agencies are commercial: they levy a small charge to establish each new identifier. Practically, a publisher using this scheme uploads a file to a DOI Registration Agency, which links a DOI with the actual URL. If the URL changes, the publisher uploads the revised DOI-URL association.
OpenURLs
The purpose of persistent URLs is to create reliable identifiers that can be used to link to a document, no matter where it is stored. A different problem is to discover a link to a document when all you have is its metadata. This is accomplished by a scheme called OpenURL, which is often run as a service by libraries. An OpenURL is generated by a bibliographic citation or bibliographic record; its target is a resource that satisfies the user's information need.
An OpenURL consists of a base URL that usually addresses an institutional link server and a query string that specifies metadata in the form of key–value pairs. For example, http://www.oxfordjournals.org/content?genre=article&issn=0006-8950&volume=126&issue=2&spage=413 specifies a particular article at the base URL www.oxfordjournals.org by giving its serial number, volume, issue, and page number. In the case of this particular OpenURL resolver, the first four parameters—genre, ISSN (International Standard Serial Number), volume, and issue—are mandatory, but metadata like title and author can be given as an alternative to the page number.
The idea of OpenURLs is that a user can query an online bibliographic database and end up with a pointer to the full text of the article he wants to read. Whether the user is able to download the article depends on whether his institution has an appropriate subscription. To determine this, the link needs to be resolved by the user's institution to point to the appropriate institutional copy. An OpenURL can be made to resolve to a copy of a resource in a different library simply by changing the base URL. Thus, the same OpenURL can easily be adjusted by either library to provide access to its own copy of the resource.
OpenURLs work well for documents that have standard metadata associated with them. In order to refer to general documents on the Web, a scheme involving associative links has been proposed. Pages can be identified not just by a name or location, but also by their content—the words they contain. A few well-chosen words or phrases are sufficient to identify almost every Web page exactly, with high reliability. These snippets—called the page's
signature—could be added to the URL. Browsers would locate pages in the normal way, but if they encountered a broken-link error, they would pass the signature to a search engine to find the page's new location. The same technique identifies all copies of the same page on the Web—an important facility for search engines, so they need not bother to index duplicates. The scheme relies on the uniqueness of the signature: there is a trade-off between signature size and reliability.
Persistence
As noted above, persistence is really an organizational problem, and any solutions require the organizations involved to be perceived as stable and long-lasting. Some organizations, such as the Library of Congress or the International Organization for Standardization (ISO), have obvious longevity and national/international stature. Newer organizations, such as the Communications Network Research Institute that runs the Handle system and the International DOI Foundation that runs the DOI system, rely on technical competence and their wide user base.
7.4. Web Services
In order for an institutional repository to successfully meet the needs of its various user communities, it should provide not only preservation and access to digital objects but also a range of services that make these objects useful.
Many of the examples of digital collections we have seen so far allow users to access digital objects of various types. Z39.50 and OAI-PMH provide mechanisms for programmatic access to metadata, with indirect access to the actual objects. Eclipsing bespoke solutions such as these, the Semantic Web looks forward to a networked world with ubiquitous access to a wide variety of both resources
and services, a world of Web Services. For digital libraries, the Web Services paradigm addresses the issue of how your library holdings can be shared in a more general way with other users or programs.
Web Services are a broad and rapidly evolving topic, with many supporting technologies and countless applications; we give only a brief outline here. There is general agreement that Web Services are:
• modular
• self-describing
• self-advertising
• standards-based
• platform and programming-language independent
• XML-based.
In practice, a typical service receives an incoming request, processes it, and returns a response. Both the request and response are XML documents. The Web contains many services, each providing small chunks of functionality, and in processing a request, a service may call on several other services. The idea is that many organizations, including digital libraries, will open up their resources in a controlled manner to encourage new value-added services.
Technically, a server that processes Web Service requests resembles a Web server responding to ordinary requests from users who click links in their Web browsers. However, Web Service requests are more likely to originate with software and need to be used in more structured ways than clicking a link and returning a page. In order to inform other programs how it is to be used, a Web Service is self-describing: the Web Services Description Language (WSDL, also pronounced
wiz-del by some), which is based upon XML, is a common choice.
A WSDL file provides enough information for a program to be able to interact with a Web Service without any human intervention. Figure 7.3 shows a WSDL file that describes a service called
UsernameService (defined near the end) that processes usernames, possibly as part of a larger account management service. The WSDL specification describes where to find the service in the
wsdlsoap:address element (also near the end). It specifies that it expects a string
literal as input (in the
<wsdl:input name=getUsernameRequest> element) and produces another string
literal as output (in the
<wsdl:ouput name=getUsernameResponse> element).
The input and output described in the WSDL of Figure 7.3 are both
wsdlsoap elements, indicating that the request and response to the
UsernameService should be packaged in the XML Simple Object Access Protocol (SOAP). Figure 7.4 shows examples of the input and output SOAP messages to
UsernameService. As you can see, a SOAP message consists of an
envelope that surrounds the XML content or
payload. Typically this payload will be a structured XML document: in Figure 7.4a it is
<username>js</username>. The output comes in the same form. It could be a result list from a query, but might be as simple as a plain string (
John Smith in Figure 7.4b) or a URL to a further resource. SOAP is typically sent over HTTP, although it can be used with many different transport mechanisms.


Many Web Services will be deployed at specific known URLs. If you want a name processed by the
UsernameService, you can simply use its Web address. However, the Web Services environment contains a technology for self-advertising. The Universal Description, Discovery and Integration (UDDI) protocol provides a standard service for the discovery of Web Services, in effect acting as a registry of suppliers. UDDI is yet another XML format that allows various aspects of services to be expressed, such as
businessServices and
discoveryURL. UDDI allows programs to dynamically discover Web Services, although user interfaces for people to browse the services are usually available as well.
Web Service requests can be sent as SOAP messages, but they can also be encoded within a standard URL as HTTP GET requests. Just as an OAI request can be expressed as a URL (see Figures 7.1 and 7.2), many Web Service requests can be simplified from a SOAP message to a plain URL. For example, the request in Figure 7.4 to look up the user associated with the username
js might be expressed as http://www.example.com/username/js. If a Web Service can be expressed using URLs and simple stateless requests, then it is sometimes described as RESTful (Representational State Transfer). The Web itself is a RESTful system, and the HTTP methods GET and POST are examples of stateless requests, ones that are independent of previous requests. REST is not a standard itself—though it builds on familiar Web standards like HTTP, URL, and XML—but more a software architectural style that can simplify Web Service development.
All this technological infrastructure allows managers of digital collections to provide value-added services that build on the objects and metadata they already possess—or enable others to do so. Services for a repository that could be realized through the Web Services architecture include:
• annotation services
• automatic document alignment
• automatic map and timeline generation
• citation linking
• dynamic/ad hoc collection building
• gazetteer lookup
• named entity identification
• personal publication and aggregation
• social tagging and bookmarking
• text chunking and alignment
• vocabulary lookup.
Search/Retrieval via URL: SRU
As described in Section 7.1, Z39.50 is a complex protocol that was developed before the Web really took off. More recently, its basic ideas have been re-engineered for the Web environment, in the form of the Search/Retrieval via URL (SRU) protocol. SRU can operate in two flavors, with requests in HTTP (either GET or POST requests) or as a SOAP Web Service. The latter used to be called the Search/Retrieval Web Service (SRW).
Whereas OAI has six verbs, SRU has three main operations:
•
searchRetrieve sends queries and receives responses,
•
explain allows client programs to learn about the server's capabilities, and
•
scan retrieves lists of terms used in creating browsing structures.
Figure 7.5 shows an SRU response to a
searchRetrieve query. The response returns a metadata record, and in this case the metadata is couched as a MODS record (Section 6.2). The
recordData contains origin information (publisher, place and date issued), title information (
Five Songs), personal name and role (
Mary Lane Bayliff, creator), language, physical description, and information about local library holdings. The
explain operation mirrors Z39.50's Explain Facility mentioned in Section 7.1. The
scan operation allows the client to request a range of the available terms at a given point within a list of indexed terms. It enables clients to present users with an ordered list of values and to show how many hits there would be for each one. This operation is often used to select terms for subsequent searching or to verify a negative search result.

SRU services are more fine-grained than those of OAI-PMH. They allow clients to retrieve records with greater precision. It is perfectly reasonable for a digital library to provide access to its resources through both protocols and to allow clients to choose the one that best suits their needs.
7.5. Authentication and Security
As discussed in Section 2.2, it is sometimes necessary to restrict access to parts of a digital library. Threats to the integrity of a digital library arise from human hackers (or crackers) and from the destructive programs they create, such as viruses and worms. Library administrators will almost always need to restrict access to the administrative functions of the software (the only possible exceptions might be public-editing open-content systems like Wikipedia). In some cases they will also need to restrict access to the content. Some of these restrictions are inevitable once a collection is placed on a network. Collection maintenance relies on the security of the underlying library software and of the associated applications, such as Web servers.
The next general step is to ensure that the content that is placed on your network-facing server is content that you
really want to share. Many users place private documents on Web servers where they think they are concealed, but simple searches for terms like
confidential and
not for distribution show that Web servers and Web-indexing robots often conspire to reveal such documents. Once you have organized your content, arranged for regular and reliable backups, and changed any default passwords in your software, you are ready to consider how to configure access to your particular services.
Computer users are accustomed to providing usernames and passwords to log in to systems or gain access to resources. The username and password pair authenticates a person to the system, which then grants some privileges to the person. The password is an
authentication factor. Authentication factors can be classified into three groups:
•
something you know: a password or personal identification number (PIN);
•
something you have: a token, such as bank card;
•
something you are: biometrics, such as fingerprints and voice recognition.
Sometimes the factors are combined. Using a bank card in an ATM is two-factor authentication: the card and the PIN. The more authentication factors used, the harder it is to bypass the authentication. But greater security is accompanied by increasingly complex access. This complexity is often desirable: we
want it to be difficult to launch a nuclear missile, so we accept that launch systems should have complex multi-factor authentication. For users of Web-based systems, the one-factor pair of username and password is the
de facto norm, but the appropriate level of authentication depends on the nature of the content or service. For example, the administrative functions of a digital library could require that access be from a particular network (e.g., a university campus) as well as be password-protected.
For
something you know authentication factors to be effective, the
something has to remain private— if others know your password, they can pretend to be you. When private data is used to authenticate over a network, it must be transmitted using a protocol that hides that data. On the Web, URLs that begin with
https:// initiate a connection using the Hypertext Transfer Protocol Secure (HTTPS). HTTPS takes normal HTTP data and encrypts it to prevent third parties from observing the requests and responses using a cryptographic protocol such as Secure Sockets Layer (SSL) or its successor Transport Layer Security (TLS). Many Web browsers show a padlock icon when a HTTPS session is in progress, and most users are now generally aware that this indicates a secure connection.
Once user name and password have been securely transmitted to the digital library software, they need to be checked against a register, or directory, of valid usernames and passwords. A digital library system could manage this process itself or use an external module that provides a
directory service. Many directory services support the widely used Lightweight Directory Access Protocol (LDAP) to manage user data; LDAP can be accessed by e-mail clients as well as other applications. Implementations of LDAP, including encryption, are available for many platforms and are often integrated into other applications, such as the Apache Web server.
The appropriate level of authentication for a digital library needs to balance the value of identifying users with the costs imposed by the authentication mechanisms. If restrictions are imposed on the content of passwords, they become burdensome for users to remember. If users are forced to choose a new password for every service they use, they are likely to simply re-use the same password. Some users react to password restrictions by writing them down on sticky notes attached to their displays, negating the security benefits. Because many services ask users to create usernames and passwords, an approach for reducing username/password overload has been devised, called
single sign-on.
True single sign-on allows one set of authentication details to be used by many different services; users enter their credentials just once. Single sign-on is often adopted within organizations to reduce password overload and to lower barriers to access. There is no widely used single sign-on technology on the Internet. A related idea, sometimes also referred to as single sign-on, allows users to have one username/password pair for many different services. Although users still have to log in many times, they can do so with a single identity.
The OpenID standard is a mechanism for using one digital identity on the Web. A user first registers with an OpenID
provider and generates an OpenID
identifier (which can be a URL). A Web site that adopts this authentication process asks users for their
identifier and redirects them to the provider to enter their password. The provider checks the password and sends a message back to the site to confirm the login. When many sites support OpenID, users can simply re-use their identifier without needing to remember many usernames and passwords. At the time of writing, OpenID claims tens of thousands of Web sites and hundreds of millions of users.
An alternative solution to password overload is the Shibboleth system, which is based on the Security Assertion Markup Language (SAML). SAML is a standard built on top of HTTP, XML Schema, and SOAP that uses XML to express statements about authentication and authorization. Shibboleth is broadly similar to OpenID but in practice it is usually institutionally oriented, because the server that authenticates your identity is managed by your organization. For example, a university might vouch for your online identity—a situation that is particularly useful for access to high-value resources where institutional weight enhances trust. Whereas your Shibboleth access may continue only so long as you remain with the same institution, OpenID is potentially a user-focused lifelong identity solution. However, given the speed with which the Web changes, reliable predictions are difficult to make.
Most digital library software comes with either a built-in authentication infrastructure or the ability to connect to existing external systems. Here are some practical suggestions for designing authentication for digital library collections:
• Ensure that the system uses HTTPS connections on the Web to reassure users who are familiar with this idea.
• Use organizational single sign-on systems wherever possible.
• Consider cross-domain systems, such as Shibboleth or OpenID, to reduce barriers to access for external users.
Once everything has been set up, do not forget the ongoing maintenance element, which requires:
• updating software with security patches and newer versions,
• maintaining the user database as people leave and arrive,
• checking that backups are really working, and
• regularly checking your system's log files (and those of any associated Web servers) to monitor usage.
The security and integrity of a digital library system and its content are an ongoing concern, not just a one-off task. Backups are particularly important: The very term “library” encourages users to think that, as in a physical library, every precaution is taken not to lose material, and backups are insurance policies—people usually need backups only in a time of crisis, which is not a good moment to discover that something has gone wrong.
7.6. DSpace and Fedora
This chapter concludes by looking at two open source digital library software systems: DSpace and Fedora. We met Fedora in Chapter 1, although its name was not mentioned: it powers the Pergamos digital library at the University of Athens (Section 1.3, Search for Sophocles). We met DSpace in Chapter 3 when looking at MIT's institutional repository (Section 3.6, Putting it all together). Here we describe these software systems in detail and discuss how they relate to the themes of this book, and in particular to the topics discussed in this chapter.
DSpace
In the year 2000, Hewlett-Packard teamed up with MIT's library to develop a system to meet the latter's need for an institutional repository. The result was called DSpace, for “Document space.” When the repository was launched in 2002, the software was simultaneously released as open source for others to use. Chapter 3 illustrated DSpace from the end-user's perspective for searching and browsing. We return to one of the documents viewed there, Kofi Annan's Master's thesis, and consider the steps required to enter it into the system.
Figure 7.6 shows snapshots from the document submission process. To have reached this point, the digital librarian (or end-user, since institutional repositories often allow registered users to submit documents) has first had to authenticate herself using a facility built into DSpace. Stages in the upload sequence are displayed along the top of each screenshot. The first three stages, labeled “describe,” gather metadata from the user. Figure 7.6a shows the second step, soliciting the title, author, and type of document (article, book, thesis, etc.).
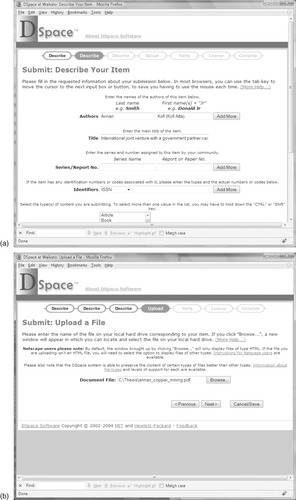 |
 |
| Figure 7.6: |
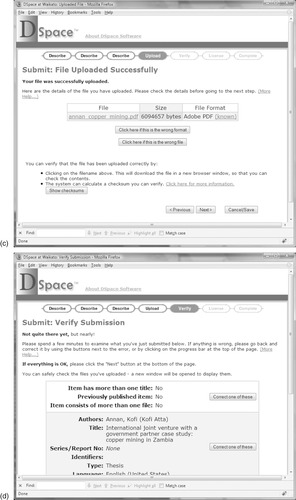
Next, the librarian selects the file to upload. In Figure 7.6b she has pressed the browse button and located the file—in this case a PDF document—in a pop-up window. Pressing Next produces Figure 7.6c (after an uploading delay), where she can check the uploaded data—for example, its file size (roughly 6 MB in this case) and type. Clicking on the hyperlinked filename shows the uploaded version; through this page the librarian can also rectify errors, such as uploading the wrong file or its type being incorrectly assigned. The
Show checksums button below computes the MD5 checksum of the uploaded file, which allows the librarian an opportunity to verify the integrity of the bytes that have been transferred. To do this, the librarian computes the checksum for the original file on her computer and then checks that the value she arrived at matches the value displayed in DSpace.
Figure 7.6d, the next page, shows a summary of the information entered (and derived). Each section has a button that allows the librarian to edit the information. An additional step (not shown) displays the license that is to be used and requires the librarian to confirm that permission is granted, whereupon the item is finally submitted to DSpace and (ultimately) can be viewed as illustrated in Chapter 3 (Figure 3.22h). The exact procedure depends on how DSpace is configured. Often there is a further round of checking and quality control before the item is published in the repository. If the librarian leaves the submission sequence partway through, the information she has entered so far is stored under her DSpace username and the next time she logs in she can pick up the process where she left off.
The metadata values entered in DSpace are matched to Dublin Core elements, and the software includes an OAI-PMH server. Because it's written in Java, it is Unicode compliant, and the interface has been translated into different languages. DSpace is servlet-based and makes extensive use of JavaServer Pages (JSP). Its developers recommend that it be used in conjunction with the Tomcat Web server, using PostgreSQL or Oracle as the database management system.
DSpace treats documents as black boxes to which metadata is attached. It is therefore important to identify each document's MIME type correctly, because this dictates which helper application a Web browser will use to view it when it is opened. However, DSpace does recognize Word, PDF, HTML, and plain text documents and can be configured to support full-text indexing using the open source indexing package Lucene. Documents can be submitted by librarians or registered users individually over the Web or may be ingested as a batch by command-line scripts that run on the DSpace server.
Fedora
Fedora (Flexible Extensible Digital Object Repository Architecture) began in 1997 at Cornell University as a conceptual design backed up by a reference implementation. In 1999, the University of Virginia library used this reference implementation as a foundation for developing a digital library tailored to their needs. The two groups (note, incidentally, another pairing of a technology research group with a large-scale library, as for DSpace) ended up working together to produce an open source digital library toolkit for others to use.
Fedora is based on a powerful digital object model, encapsulated as a repository that is extremely flexible and configurable. Moreover, a repository stores all kinds of objects, not just the documents placed in it for presentation to the end-user (we shall see examples shortly). In contrast to DSpace, Fedora is not ready to use out of the box, a deliberate design decision by its developers that means Fedora can be used to develop a wide variety of digital libraries with radically different functionality. However, there is a price to be paid: you cannot use Fedora without programming support by IT staff.
Figure 7.7 shows the default Web interface for a repository that contains a collection of historic maps. This interface is not intended for end-users, but rather to indicate the possibilities and to allow developers to explore the system's capabilities. In Figure 7.7a, the user has called up the search page and sought documents that include the word
Africa (searching across all indexed fields). The array of check-boxes determine which fields are displayed in the result list, in this case the document's identifier (persistent identifier, or pid) and title. In Figure 7.7b, the user has clicked on the third item,
Africae tabula nova, and is viewing its associated information.
 |
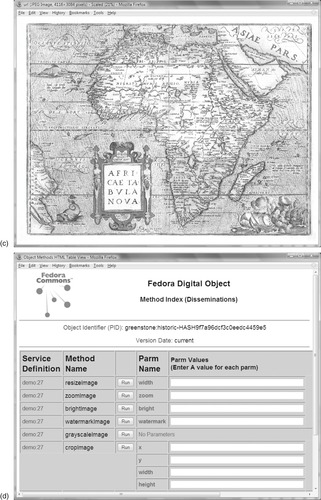 |
 |
| Figure 7.7: |
A
datastream in Fedora is MIME-encoded data associated with an object: for instance, a source file, such as an image or PDF file, or XML data.
Disseminators are methods that act upon an object, and they are linked to Web Services that provide dynamic capabilities that access the object's datastreams. Figure 7.7b, called the Item Index view, is the result of running the default disseminator, which lists the object's datastreams. Datastream names are hyperlinked, and clicking them serves up the underlying MIME-encoded data source. For instance, clicking DC yields an XML datastream representing the object's Dublin Core metadata. In this example we would see that <dc:Subject> is set to
Africa, which explains why the item was found despite the fact that its title (
Africae) is a Latin derivative of the stem (
Africa). Clicking on the
url datastream brings up Figure 7.7c, which displays a high-resolution version of the digitized image.
Figure 7.7d shows the disseminators associated with the object. This image is associated with the content model UVA_STD_IMAGE, which is why these disseminators appear. This content model, provided by Fedora, supports a wide range of image manipulation operations—resizing, zooming, brightening, watermarking, grayscale conversion, cropping, and so forth—through the RELS-EXT datastream (listed in Figure 7.7c). The default Web interface lists the disseminators along with input components (text boxes, radio buttons, and the like) that match the disseminators’ parameters. To crop the image, for example, the user enters the
x,
y,
width, and
height parameters and presses the
run button to generate a cropped excerpt.
Ingesting, modifying, and presenting information from this rich repository of objects is accomplished through a set of Web Services. The services fall into two core groups, one for access and the other for management, and both RESTful and full SOAP-based versions of the services (Section 7.4) are provided. A further protocol exists for expressing relationships between objects in terms of the Resource Description Framework (RDF, Section 6.4). These protocols have allowed a variety of digital libraries to been developed, including Pergamos (Section 1.3) and the U.S. National Science Digital Library mentioned in Section 7.2, which contains over 4 million items.
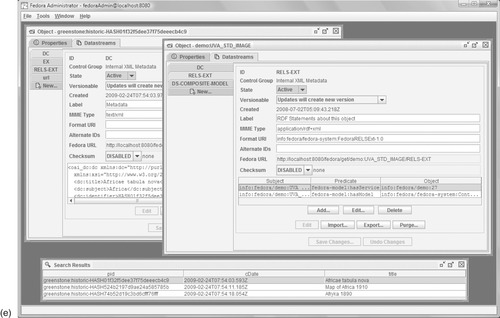
The capabilities provided by these protocols can be investigated using the Fedora Administration application illustrated in Figure 7.7e. The Administration application is another aspect of Fedora that is targeted toward IT developers rather than end-users or digital librarians. After they log in, users are presented with a blank virtual desktop upon which windows appear as they interact. For example, new objects can be created and existing ones can be edited or purged from the repository. The repository can be searched, and items can be selected and manipulated. Sets of files can be ingested or modified; they are streamed to the Fedora server using the protocol. Files must be in either FOXML, a native Fedora XML format; Fedora METS, a METS extension defined by the project; or the Atom Syndication Format, an XML extension used for Web feeds. Authentication is provided by the Extensible Access Control Markup Language. The Administration application also gives access to consoles that connect directly with Fedora's management and access facilities.
In Figure 7.7e the user has repeated the query for
Africa: the result list is displayed near the bottom. Double-clicking the first item produces the partially obscured window at the top left, through which datastreams and disseminators can be viewed and altered. Here the DC datastream is selected, which presents XML metadata that can be edited directly within the text box or using an external XML editor. Exploring the datastreams for this object, the user views the RELS-EXT datastream (not shown) and finds that the associated content model is UVA_STD_IMAGE, which means that disseminators for cropping, watermarking, and so on are available for this image as well.
Fedora's Content Model Architecture is a way of establishing properties that are shared by a set of digital objects. It is built upon Service Definitions and Service Deployments, which, like the content model itself, are merely additional objects stored in the repository. The former provide abstract methods; the latter, concrete implementations. For example, a Service Definition tailored for images might provide a method for generating thumbnails at runtime suitable for previewing in a Web browser. Further definitions would be provided to handle different image types: perhaps one for JPEG, GIF, and PNG formats (since Java provides standard support for these) and a separate one for JPEG 2000 files, which require additional library support and may not mesh well with the built-in ones. Since the mechanism is accessed through Web Services, it might be implemented in an entirely different programming language. Regardless of which mechanism is used, the fact that images can have associated thumbnails can be included in the content model and shared by a variety of source documents.
Seeking to understand more about the content model associated with the map, our user calls up the UVA_STD_IMAGE content model object, displayed on the right of Figure 7.7e. The RELS-EXT datastream in this object shows the RDF statements that are currently assigned, such as the
hasService predicate. Through the interface, additional statements can be added or existing ones can be edited or deleted. Alternatively, the displayed identifier information can be used as the source of new retrieval requests to continue the user's exploration of the repository.
Like DSpace, Fedora is written in Java and makes use of servlets. It ships with the McKoi relational database, a light-weight Java implementation, but can be configured to use other database management systems. Full-text indexing is achieved through a third-party package (GSearch) into which the Lucene, Solr (built on top of Lucene), or Zebra indexing packages can be plugged.
Because Fedora is not a turnkey software solution, additional development is necessary to shape it into a usable end product. However, following the open source philosophy, such modifications can be packaged up and made available to others in the form of ready-to-run software tools. Fez is a Web interface to Fedora that provides an institutional repository. It uses PHP and MySQL and includes notes for users migrating from DSpace or other repository systems. Muradora provides a Web front-end to a Fedora repository that re-factors authentication and authorization into pluggable middleware components. It provides a Shibboleth authentication module (Section 7.5) and also extends the above-mentioned Extensible Access Control Markup Language; in addition, it has rich user-oriented search and browse capabilities. For many of these systems, installation is quite complex. For example, in addition to a Fedora installation, Muradora requires software support for LDAP, DB XML, and XForms.
7.7. Notes and Sources
The home page for Z39.50 is located at the Library of Congress Web site, www.loc.gov/z3950/agency. An active group of online developers and implementers known as ZIG (for Z39.50 Implementers’ Group) maintain an e-mail discussion list and hold regular meetings.
Cole and Foulonneau (2007) give a very readable yet detailed treatment of the Open Archives Initiative Protocol for Metadata Handling (OAI-PMH). Further information on the Open Archives Initiative can be found in an article by Lagoze and Van de Sompel (2001) and on the Web site www.openarchives.org. The National Science Digital Library can be found at http://nsdl.org; the quote near the end of Section 7.2 about using OAI-PMH to harvest its metadata is from Lagoze et al. (2006).
The quotation at the beginning of Section 7.4 on the importance of services to institutional repositories is from Chavez et al. (2007) and applies to digital libraries in general. The list of potential Web Services in Section 7.4 is from the same source. Gurugé (2004) provides a good overview of the Web Services field. The Search/Retrieval via URL service is fully documented at http://www.loc.gov/standards/sru; Morgan (2004) provides a nice introduction. Sanderson et al. (2005) compare and contrast SRU and OAI and discuss how they can work together.
For more on authentication, see Smith's (2002)Authentication: From Passwords to Public Keys. Restricting access to a particular network is really a restriction on the networking configuration of your computer. Desktop computers are usually locked in rooms that require a key (something you have) for physical access, while laptops are often operated within a Virtual Private Network configured with another username and password. Stamp (2006) provides detailed coverage of both the theory and practice of information security, including cryptographic theory and real world protocols. OpenID is at http://openid.net and Shibboleth is at http://shibboleth.internet2.edu. Powell and Recordon (2007) provide an outline of OpenID and compare it to Shibboleth. SAML is described at http://saml.xml.org.
Further details about DSpace can be found in Smith et al. (2003). The original paper describing Fedora's architecture is by Payette and Lagoze (1998), with more recent developments summarized in Lagoze et al. (2006). Kortekaas (2007) gives details of Fez, while Muradora can be found at www.muradora.org. Going to press, a new open source repository initiative was announced, DuraSpace. This project sees the teams behind Fedora and DSpace join forces, with a coordinated strategy for growing the areas in which open repositories are used, while retaining their commitment to already established communities. More details can be found at www.duraspace.org. The historical map of Africa depicted in the Fedora example (Figure 7.7) was penned by the renowned Belgian cartographer Abraham Ortelius and was first published in 1570 as part of his
Theatrum Orbis Terrarum (Theatre of the World), considered by many to be the first modern atlas.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.