
Chapter 3. Presentation
User interfaces
Having reviewed the people in digital libraries and the roles they play, now we turn to presentation and what global users experience when interacting with digital libraries, which they invariably do through a Web browser.
From People to Presentation
Having reviewed the people in digital libraries and the roles they play, now we turn to presentation and what global users experience when interacting with digital libraries, which they invariably do through a Web browser.
Recall the definition of
digital library from Chapter 1. The definition begins by stating that a digital library is:
a focused collection of digital objects, including text, video, and audio …
and a good place to start is with the objects themselves (the documents) and how they appear on the user's screen. The next section illustrates different document displays in digital library systems. There are many possibilities, and we include a representative cross-section: structured text documents, unstructured text documents, page images, page images along with the accompanying text, audio, photographs, and videos. A digital library might include objects that manifest themselves in different forms. For example, music has many alternative representations—synthesized audio, music notation, page images, recorded audio performances—and digital libraries must cater to these optional views.
In addition to documents, digital libraries include metadata like that used conventionally for bibliographic organization. The role of metadata is considerably expanded in a digital library, and we examine some examples to convey how useful it is in helping to organize digital library collections. (Chapter 6 provides a more detailed account of metadata.)
The definition goes on to say:
… along with methods for access and retrieval …
and this chapter illustrates different methods for access and retrieval. Conventionally these are divided into
searching and
browsing, although in truth the distinction is not sharp. We first examine interfaces that allow you to locate words and phrases in the full text of a document collection. Searching is also useful for metadata—such as finding words in title and author fields—and we look at interfaces that allow these searches, and combinations of them, to be expressed. It is often useful to be able to recall and modify past searches:
search history interfaces allow you to review what you have done and reuse parts of it. Next we examine browsing interfaces for metadata—titles, authors, dates, and subject hierarchies—and show how to capitalize on the structure that is implicit within the metadata itself.
But searching and browsing aren't really different activities: they are opposite ends of a spectrum. In practice, people want to be able to interact with information collections in different ways, some involving searching for particular words, some involving convenient browsing—perhaps browsing the results of searching, or exploring various facets of the information being presented.
The final part of the definition is:
… and for selection, organization, and maintenance of the collection.
This chapter does not address this activity, except insofar as browsing structures reflect the organization of the collection. In truth, this entire book is about organizing and maintaining digital libraries, including organizing them in such a way that they are easy to maintain.
Most of the illustrations in this chapter show screen shots from a Web browser. However, the browser does not show a static Web page: the digital library software constructs pages dynamically at the time they are called up for display. The navigation bar at the top of Figure 3.1a, the cover picture at the top left, the table of contents on the right, and the book title near the bottom, are all composed together with the text at display time, every time the page is accessed. The information is typically stored in some form of managed datastore, or else reconstructed on the fly from compressed index files. If you look on the computer that is the Web server for this digital library, you will not find this page stored there.

This is why in Chapter 1 we distinguish a digital library from a Web site, even one that offers a focused collection of well-organized material. The fact that documents are treated as structured objects internally enhances the prospects for providing comprehensive searching and browsing facilities. Furthermore, because all pages are generated dynamically from an internal representation, it is easy to change the entire look and feel of all pages associated with a collection without regenerating or even touching the content of the collection.
3.1. Presenting Textual Documents
If you want to build a digital library, the first questions that need to be answered are: What form are the documents in? What structure do they have? How do you want them to look?
Documents, chapters, sections
The book shown in Figure 3.1,
Village-Level Brickmaking, is from the Humanity Development Library mentioned in Chapter 1. A picture of the front cover is displayed on the left, and the table of contents appears to its right. Below is the start of the main text, beginning with title, author, and publisher. The books in this collection are generously illustrated. On the screen these images appear in-line, just as they did in the paper books from which the collection was derived. Figures 3.1c and d show some of the images, obtained by scrolling down from Figure 3.1b.
Books in this collection have front-cover images, which appear at the top of any page where the book, or part of it, is displayed. This picture gives a feeling of physical presence, a reminder of the context in which you are reading. The user interface may be a poor substitute for the look and feel of a physical book—the heft, the texture of the cover, the crinkling sound of pages turning, the smell of the binding, highlighting and marginal notes on the pages, dog-eared leaves, coffee stains, the pressed wildflower that your lover always used as a bookmark—but it's a lot better than nothing.
The books in the Humanity Development Library are structured into chapters and sections. The small folder icons in Figure 3.1a indicate chapters—there are chapters on
Standardization,
Clay Preparation,
Moulding, and so on. The small text-page icons beside the
Preface,
Extraction, and
Acknowledgements headings indicate leaves of the hierarchy: sections that contain text but no further subsection structure.
Clicking on
Moulding in Figure 3.1a yields the page in Figure 3.1b, which shows the chapter's structure in the form of a table of contents. Here the user has opened the book to
Sand moulding by clicking its text-page icon; the section heading is shown in bold and its text appears below. Other headings lead the reader to such topics as
Slop moulding,
How to mould bricks, and
Drying. You can read the beginning of the
Sand moulding section in Figure 3.1b: the scroll bar to the right of the screen indicates that more text follows. Figures 3.1c and d show the effect of scrolling further down the page.
The Expand Contents button in Figure 3.1 expands the table of contents into a full hierarchical structure. Similarly, the Expand Text button expands the text of the section being displayed. In Figure 3.1a it would yield the text of the entire book, including all chapters and subsections; in Figure 3.1b it would yield the complete text of the
Moulding chapter, including all subsections. This is convenient for printing the whole book or sections of it. Finally, the Detach button duplicates this window on the screen, so that you can retain its text while continuing to browse the library in the other window. This is useful for comparing multiple documents.
As noted in Chapter 1, the Humanity Development Library is a large compendium of practical material. It covers diverse areas of human development, from agricultural practice to foreign policy, from water and sanitation to society and culture, from education to manufacturing, from disaster mitigation to microenterprises. This material was carefully selected and put together by a collection editor who acquired the books, arranged for permission to include each one, organized a massive optical character recognition (OCR) operation to convert them into electronic form, set and monitored quality-control standards for the conversion, decided what form the digital library should take and what searching and browsing options should be provided, entered the metadata necessary to build these structures, and checked the integrity of the information and the look and feel of the final product. The care and attention put into the collection is reflected by its high quality. Nevertheless, it is not perfect: there are small OCR errors, and some of the 30,000 in-text figures (of which examples can be seen in Figures 3.1c and d) are inappropriately sized. The amount of effort required to edit a high-quality collection of a thousand or more books is staggering—just ask a publisher what goes into the production of a single conventional book like the one you are reading.
Unstructured text documents
Figure 3.2 shows screen shots from a far plainer collection. The documents are not presented in a hierarchical way. There are no front-cover images. In place of Figure 3.1's picture and table of contents, what Figure 3.2 shows is more prosaic: the title of the book and a page selector that lets you turn from one page to another. Browsing is less convenient because there is less structure to work with. Even the “pages” do not correspond to physical pages, but are arbitrary breaks made by the computer every few hundred lines—that's why
Alice's Adventures in Wonderland has only 28 pages. The only reason for having pagination at all is to prevent the Web browser from downloading the entire book every time you look at it.

In fact, this book
does have chapters—in Figure 3.2 you can see the beginning of Chapter 1,
Down the rabbit-hole. However, this structure is not known to the digital library system: the book is treated as a long scroll of plain text. With some extra effort in setting up the collection, it would have been possible to identify the beginning of each chapter, and its title, and incorporate this information to permit browsing chapter by chapter, as has been done in the Humanity Development Library. The cost depends on how similar the books in the collection are to one another and how regular the structure is. For any given book, or any given structure, it is easy to do; but in real life large collections usually exhibit considerable variation in format. As we mentioned before, the task of proofreading thousands of books is not to be undertaken lightly.
The books in this collection are stored as raw text, with the end of each line hard-coded, rather than, say, in HTML, which is used for Figure 3.1. (Chapter 4 gives details of these formats.) That is why the lines of text in Figure 3.2 are quite short: they always remain exactly the same length and do not expand to fill the browser window. Compared with the Humanity Development Library, this is a low-quality, unattractive collection. Removing end-of-line codes would be trivial, but a simple removal algorithm would destroy the format of tables of contents and displayed bullet points. It is surprisingly difficult to do such things reliably on large quantities of real text—reliably enough to avoid the chore of manual proofreading.
Figure 3.2b shows page 26 of the book, where the words
begin and
beginning are highlighted in boldface. This is because the page was reached by a text search of the entire library contents (described in Section 3.4) to find a particular quotation. The system highlights search terms: there is a button at the top that turns highlighting off if it becomes annoying. In contrast, standard Web search engines do not highlight search terms in documents—of course, they do not serve up the target documents themselves but instead direct the user to the original source location.
Alice's Adventures in Wonderland belongs to a collection called Project Gutenberg, whose goal is to encourage the creation and distribution of electronic text. Although the project was conceived in 1971, work on it did not begin in earnest until 1991, with the aim of producing 10,000 electronic texts within ten years. The first achievement was an electronic version of the U.S. Declaration of Independence, followed by the Bill of Rights and the Constitution. Then came the Bible and Shakespeare—unfortunately, however, the latter could not be released until much later because of copyright restrictions on the comments and notes in the particular edition that was entered. The collection was planned to double each year, with one book per month added in 1991, two in 1992, four in 1993, and so on, reaching the target of 10,000 by 2001. This schedule slipped slightly, but the target was passed in 2003.
A huge boost came from a development known as
distributed proofreading, which provides a perfect example of the role of user contributions mentioned in Section 2.5. Optical character recognition (OCR) software is used to digitize volumes
en masse. Then a global community of volunteers proofreads the result and corrects errors using a specially designed Web site. Upon logging in, registered volunteers are presented with a scanned page and the corresponding text in editable form, for correction. Once corrections have been made, a second volunteer verifies the work. Developed in 2000, this approach became an official part of Project Gutenberg two years later. The Project Gutenberg library now boasts over 26,000 digitized texts and continues to grow fast.
Project Gutenberg is a grassroots phenomenon. Text is input by volunteers, each of whom can enter a book a year or even just one book in a lifetime. The project does not direct the volunteers’ choice of material; instead, people are encouraged to choose books they like and to enter them in the manner in which they feel most comfortable. Central to the project's philosophy is to represent books as plain text, with no formatting and no metadata other than title and author. Professional librarians look askance at amateur efforts like this, and indeed quality control is a problem. However, dating back two decades before the advent of the World Wide Web, the Gutenberg vision is remarkably farsighted and gives an interesting perspective on the potential role of volunteer labor in placing society's literary treasures in the public domain.
The collection illustrated in Figure 3.2 represents the opposite end of the spectrum to the Humanity Development Library. It took just a few hours to download the Project Gutenberg files and to create the collection, and a few hours of computer time to build it. Despite this tiny investment of effort, it is fully searchable—which makes it indispensable for finding obscure quotations—and includes author and title lists. If you want to know the first sentence of
Moby Dick, or whether Hermann Melville wrote other popular works, or whether “Ishmael” appears as a central character in any other books, or the relative frequencies of the words
he and
her,
his and
hers in a large collection of popular English literature, this is where to come.
Page images
Figure 3.3 shows a historical collection of literature written for schoolchildren, the New Zealand School Journal, which is delivered to schools throughout New Zealand by the Ministry of Education. Dating from 1907—the first cover is the top left image in Figure 3.3—it is believed to be the longest-running serial publication for children in the world. Figure 3.3a shows the collection's home page: you click on an image to get to that issue of the journal. Figure 3.3b shows a page of the children's story “Never Shout at a Draft Horse,” represented not as text but as a facsimile of the original printed version—a decision made by the collection's designer. From a technical point of view, this decision makes a big difference: the textual content occupies only about 5 percent of the storage space required for a page image, greatly reducing the resources required to store the collection and the time needed to download each page. Of course, the picture of the horse would have to be represented as an image, just as the pictures in Figures 3.1c and d are, sacrificing some of the space gained.
 |
| Figure 3.3: |
A good reason for showing page images rather than extracted text is that the OCR process that identifies and recognizes the text content makes errors. When children are the target audience, it is important not to expose them to erroneous text. Of course, errors can be detected and corrected manually, as in the Humanity Development Library and the Gutenberg collection, but at a substantial cost well beyond the resources that could be mustered for this particular project.
Text is indeed extracted from the New Zealand School Journal pages using OCR, and that text is used for searching, but readers never see it. The consequence of OCR errors is that some searches may not return all the pages they should. If a word on a particular page is misrecognized, a search for it will not return that page. Or, if a particular word is misinterpreted as a different one, a search for
that word will return an extra page. However, neither of these errors was seen as a big problem—certainly not as serious as showing children corrupted text.
Figure 3.3b shows the journal cover at the top left and a page selector at the right that is more convenient to use for browsing around in the story than the numeric selector in Figure 3.2. The stories are short:
“Never Shout at a Draft Horse” has only four pages.
Images with text
Figure 3.4 demonstrates a far larger collection of page images that also allows searching on extracted, OCR'd text, but in this case users are able to see the text if they so desire. This is the National Library of New Zealand's Papers Past collection, which has 1.1 million pages of digitized national and regional newspaper and periodicals spanning the years 1839–1920.
 |
 |
| Figure 3.4: |
A user interested in the suffragette movement has entered the query
Kate Sheppard (Kate Sheppard was a prominent 19th-century campaigner who successfully campaigned to have New Zealand become the first country where women could vote). Figure 3.4a shows the beginning of one of the articles returned by the search, “To the Freewomen of New Zealand,” from p. 46 of the
Otago Witness (Issue 2066, 28 September 1893). Notice that (unlike in the School Journal collection) the search terms are highlighted in this image. During the OCR process, the precise location of each word in the source image is stored, along with coordinate information for each article. This allows search terms to be highlighted and individual articles to be clipped out of the newspaper pages.
A link at the top takes the reader to the text shown in Figure 3.4b. Some errors are apparent, most notably the word
names—the last word shown in Figure 3.4a—has been rendered as
niiniis. The decision to allow readers to see this text was a good one, for then they can see what they are searching. It is also a courageous decision because it exposes errors, and most digital libraries of newspapers conceal this information. In this case, the word
names in Figure 3.4a is badly broken up: no wonder it was misrecognized.
Below the main navigation bar is hierarchical information that pinpoints where the user is:
Papers Past > Otago Witness > 28 September 1893 > Page 46 > TO THE FREEWOMEN OF NEW ZEALAND. Clicking
Page 46 switches from article to page mode, shown in Figure 3.4c and the current article is highlighted. Moving the cursor around changes the highlighting from one article to another; clicking switches the highlighted item to article view.
From Figure 3.4c readers can view both a high-resolution image and a printable version. They can navigate page by page through the newspaper, and from one edition to the next. Figure 3.4d shows the contents of this edition of the
Otago Witness, providing a useful overview. At the top, the user can obtain a printable version of the full edition (in the PDF, Portable Document Format, that is described in Section 4.5). The first column provides navigable links to each page; the second provides links to each article.
This is just a glimpse of what the Papers Past digital library has to offer. Such magnificent functionality does not come cheap. For example, a huge amount of metadata is involved. Normally, storage requirements for the source documents vastly outstrip those needed for the accompanying metadata. Here, however, this is reversed: for every gigabyte of text extracted by the OCR process, three times as much space is consumed by the coordinate information—metadata. In fact, the 1 MB of metadata required for a page exceeds the 0.75 MB required even for the scanned page image, let alone for the text extracted from it.
Realistic books
Section 1.2 describes how it took centuries for the written word to progress from papyrus scrolls to the book form that we use today. The book was a revolutionary development that changed the way people read written information; it is arguably one of the most important inventions in the history of thought. Consequently, it is perplexing that the scroll bar, reminiscent of long-obsolete technology, has dominated our computer interfaces for the past three decades.
The book is coming back. Figure 3.5 shows an interface that much more closely resembles physical documents than the representations in earlier figures. Because it works in a standard Web browser, it can be widely deployed. Readers use a mouse to grasp the paper and sweep out the path of that point to turn the page. There is complete freedom to move the page within the constraints imposed by not moving it to a point that would tear physical paper, and the visual details follow instantly. Although the model does not look completely realistic in static pictures, it is effective in practice because it is dynamically reactive.

The book in Figure 3.5,
Farming Snails I, is from the same collection as the book in Figure 3.1. Readers grasp the page anywhere along the top, right, or bottom edge—usually, but not necessarily, at a corner—by pointing their mouse there and depressing and holding down the mouse button. As they move the mouse, the page follows. If they release the button, the page either floats back to its original position or floats down to the turned position. Readers who use a touch panel instead of a mouse gain an even better sense of control.
Realistic books typically have a cover (Figure 3.5a), title page, table of contents (Figure 3.5b), and the main text (Figures 3.5c and d). Sections begin on a new page and are split into pages. Contents entries are hyperlinked, so that clicking them opens the book to that chapter. Colored tabs protruding from the page edges mark chapters, sections, or pages containing illustrations (these things are switchable). The reader turns pages by using the mouse or simply by clicking to turn them automatically. When the book is open, the cover's inside border is visible, and the reader can click this to close the book in either direction.
The presentation in Figure 3.5a was generated by the same digital library system used for Figure 3.1. Any book in the Humanity Development Library can be displayed in this way; the software converts it on the fly from the HTML representation. This serves to underscore the fact that digital libraries can change the entire look and feel of all documents in a collection at the touch of a button—or, as in this case, a single menu selection on a Preferences page.
3.2. Presenting Multimedia Documents
Next we consider multimedia documents: audio recordings and photographic images; video, which includes both image and audio components; and musical objects that can be presented in several different forms.
Sound and pictures
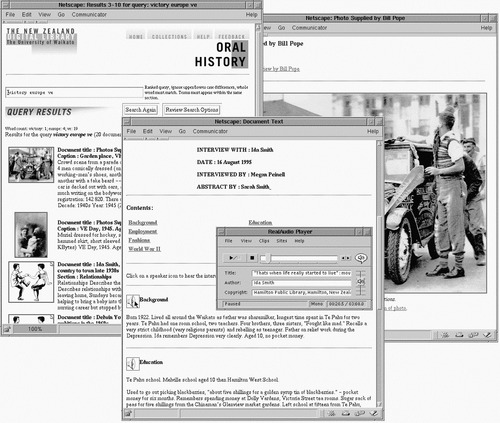
Some years ago, the public library in Hamilton, New Zealand, the small town where we live, began a project to collect local history. Concerned that knowledge of what it was like to grow up in Hamilton in the 1930s, 1940s, and 1950s would soon be permanently lost, the library decided to arrange to interview older people about their early lives. Armed with tape recorders, local volunteers conducted semistructured interviews with residents of the region and accumulated many cassette tapes of recorded reminiscences, accompanied by miscellaneous photographs from the interviewees’ family albums. From these tapes, the interviewers developed a brief typewritten summary of each interview, dividing it into sections representing themes or events covered in the interview. But then the collection sat in a cardboard box behind the library's circulation desk, largely unused.
In a subsequent round of development, all the tapes and photos, along with the summaries, were digitized and made into a digital library collection. Figure 3.6 shows it in use. The user is listening to a particular recording using a standard software audio-player that has regular tape-recorder functions (pause, fast forward, and so on) on the small control panel in the center. Users don't have to wait until the whole file is downloaded: the beginning starts playing while the rest is being transmitted. Behind the control panel is the interview summary. In the background on the right can be seen a photograph—in this case, of the town's celebrations on VE Day (Victory in Europe) near the end of the Second World War—and on the left is the query page that was used to locate this information.
 |
| Figure 3.6: |
The interview page is divided into sections, with a summary for each. Clicking on one of the speaker icons plays back the selected portion of the audio; interviews also can be played in full using buttons at the top of the page (not visible in Figure 3.6). When the tapes were digitized, timings were generated for the beginning and end of each section. Flipping through a recording in this way, scanning a brief textual synopsis and clicking on interesting parts to hear them, is far more engaging and productive than trying to scan an audiotape with a finger on the fast-forward button.
The contents of the interview pages are used for text searching. Although they do not contain full transcripts, many keywords that you might want to search on are included. In addition, brief descriptions of each photograph were entered, and they are also included in the text search. These value-adding activities were done by amateurs, not professionals. Standard techniques, such as deciding in advance on the vocabulary with which objects are described (i.e., using a
controlled vocabulary) were not used. Nevertheless, users can easily find material of interest.
Consider the difference between accessing a box of cassette tapes at the library's circulation desk and searching the fully indexed, Web-accessible digital library collection depicted in Figure 3.6. Text searching makes it easy to find out what it was like at the end of the war, to study the development of a particular neighborhood, or to see if certain people are mentioned (and you can actually hear senior residents reminisce about these things). Casual inquiries and browsing are simple and pleasurable—in striking contrast to searching through a paper file, then a box of tapes, and finally trying to find the right place on the tape using a cassette player. In fact, although this collection can be accessed from anywhere on the Web, the audio files are available only on terminals in the local public library, because the interviewees were not asked for consent to broadcast their voices worldwide. The message here for those engaged in local history projects is: think big.
Video
Videos combine time-based information with a spatial image component. As with audio, time-based documents can be made more conveniently browsable by segmenting them, and videos can be automatically converted into sequences of thumbnails that correspond to scene changes. Web browsers can play video in a variety of formats, provided a suitable plug-in is installed; the digital library server can even offer users a choice of formats. The Flash video format (reviewed along with several others in Chapter 5) adopted by YouTube has enormous penetration: some surveys estimate that it is installed on 99 percent of Internet-capable computers (compared with 80 to 85 percent for its closest rivals).
In planning a digital library, such statistics are useful in deciding on the best way to deliver documents to the intended audience. Decisions need to be coupled with knowledge about what the delivery format can do (for instance, Can the video be started at particular time offset? How easily and faithfully can the source format be converted?).
The feasibility of downloading video over the Internet depends on technical factors like the bandwidth of the connection. Of course, a great deal of storage space will be required for a large collection. Perhaps the digital library designer should consider providing an audio-only representation initially. This requires far less bandwidth and, particularly in the case of fixed-camera interviews, still communicates the essential information. For movies with an important visual component, a storyboard of images could convey important details at a fraction of the cost of video.
Searching video, like searching the oral history audio, requires appropriate descriptive text. And, as is discussed in Section 3.4, images can also be searched directly, using similarity based on analysis of the images themselves. This technique can be applied to key-frames chosen from the video either manually or automatically.
Music
As Chapter 1 describes, digital collections of music have the potential to capture popular imagination in ways that scholarly libraries never will. Two elements to creating such a resource that is interesting and entertaining to search and browse are (1) having different representations of the same music available, and (2) linking to external resources to locate additional, relevant information.
Figure 3.7 shows a prototype digital music library motivated by these observations. Starting with scanned images of sheet music, optical music recognition (OMR) software—which is similar to OCR software but works in the domain of printed music—was used to generate a symbolic version of each song. This was paired up with the original score and accompanying metadata for title, composer and lyricist. Searching and browsing capabilities were then developed based on this digital content.

In the figure we join a user partway through seeking for the tune
Auld Lang Syne in the digital library, having sung a few remembered notes (we return to this “query by humming” capability in Section 3.4). For now we are interested in what can be done given the result of the query, which is a ranked list of songs that match precisely or are at least similar to the query. The further down the list a song is, the less likely it is to be the one the user is looking for. Clicking on the speaker icon to the top matching item (which in this case happens to be
Auld Lang Syne) results in an audio rendition of the piece, based on the symbolic representation stored in the digital library. The player can be seen in the front window of Figure 3.7. The adjacent icon displays the musical notation for the tune (also featured in the figure), which was generated from the same internal representation, this time by a music-typesetting program.
For various reasons, this computer generated playback and typesetting can be of limited quality. Not shown in Figure 3.7, but just a click away for the user, is an image of the actual book page that contains the song. Also available are the lyrics. Furthermore, the song and artist metadata for a song are automatically hyperlinked to initiate text queries on the Web using a conventional general purpose Internet search engine: a convenient (but not necessarily precise) way to locate additional information about the song (or composer). It also enables other versions of the song to be found in, for instance, MIDI (Musical Instrument Digital Interface) format (see Section 5.6), or an actual recording (see Section 5.2) and one of those played instead.
3.3. Document Surrogates
Traditional libraries manage their holdings using catalogs that contain information about every object they own. Metadata, characterized in Chapter 1 as “data about data,” is a recently coined term for this information. Metadata is information in a structured format and its purpose is to provide a description of other data objects in order to facilitate access to them. The data objects themselves (e.g., the books) generally contain unstructured information. Sometimes, as in the Humanity Development Library in Figure 3.1, they do have some internal structure. Sometimes, as in the Project Gutenberg collection in Figure 3.2, their information has structure but that structure is not apparent to the system. However, the essential feature of metadata is that its elements are structured. Moreover, metadata elements are standardized so that the same type of information can be used in different systems and for different purposes. In the computer's full-text copy of a book, the title, the author, the publisher, the source of the original edition, etc., may not be obvious. However, when this information is represented in metadata, in a standard way using standard elements, the computer can identify these fields and operate on them.
When users initiate a search or browse in a digital library, they are often presented with lists or displays that summarize the digital objects themselves. These summaries are known as
document surrogates, which are concise displays that represent the actual object, typically using some of its metadata.
Metadata
Figure 3.8 is taken from a digital library collection of computer science bibliographies. It shows the result of searching for the author
Honkala, with matching publications presented as a standard bibliographic listing: the hyperlink at the end of each item links to the source bibliography. Many of the entries have abstracts, which are viewed by clicking the page icons to the left—although here they are grayed out, indicating that abstracts are unavailable. The metadata displayed includes title, author, date, the title of the publication in which the article appears, volume number, issue number, and page numbers. As noted above, it also includes the URL of the source bibliography and the abstract (although it is debatable whether this is structured enough to constitute metadata).

Metadata has many different aspects, corresponding to various kinds of information that might be available about an item. Historical features describe provenance, form, and preservation history. Functional ones describe usage, condition, and audience. Technical ones provide information that promotes interoperability between different systems. Relational metadata covers links and citations. And, most important of all, intellectual metadata describes the content or subject. Metadata provides assistance with search and retrieval; gives information about usage in terms of authorization, copyright, or licensing; addresses quality issues, such as authentication and rating; and promotes interoperability with other systems.
Figure 3.9a shows a record retrieved over the Internet from the Library of Congress and displayed within a simple interface (although only half of the fields in the record are visible). Common fields are named, while obscure ones are labeled with identification numbers (e.g., field 35). You can see that there is some redundancy: the principal author appears in both the
Personal Name field and in a subfield of the title; the other authors also appear further down the record in separate
Author Note–Name fields (not shown). This metadata was retrieved using an information interchange standard (called Z39.50) that is widely used throughout the library world (see Section 7.2) and is represented in a record format called MARC ( “machine-readable cataloging”) that is also used by libraries internationally (see Section 6.2).
 |
| Figure 3.9: |
Library metadata is standardized, but, as is often the case with standards, there are many different ones to choose from. (MARC itself comes in more than 20 variants, produced for different countries.) Non-bibliographic metadata has no widely accepted standards. Figure 3.9b shows a record from a BBC catalog of radio and television programs; the record gives such information as program title, item title, date, medium, format, several internal identifiers, a description, and a comments field.
Metadata descriptions often grow willy-nilly, in which case the relatively unstructured technique of text search is a better way to locate records than using a conventional metadata database. Because of increased interest in communicating information about radio and television programs internationally, people in the field are working on developing a new metadata standard for this purpose. Developing international standards requires a lot of hard work, negotiation, and compromise; it takes years.
Surrogates can also include elements from the document's actual content. A common method of displaying full-text search results is to highlight some matching text and to use it as part of the surrogate that is displayed to the user. For example, Figure 3.10 shows textual snippets from the documents in a page returned by the Google search engine. This allows users to see how their search terms interact with the document collection.

Multimedia surrogates
Textual surrogates rarely give users a good feeling for multimedia content, but some elements of multimedia can produce effective representations that help users make informed choices about which documents to investigate further. Even a predominantly textual document like a book can use its cover image as a surrogate.
It is natural to represent full-size images by miniature versions, and scaled or cropped thumbnails are effective surrogates. Temporal multimedia like audio and video are not so easily accommodated. Should an hour-long video be represented by a mini version of it? Which parts? All the way to the end? Users normally expect to be able to make selection decisions in just a few seconds, but if the surrogate appears among search results, they may face ten or twenty miniature videos.
For this reason, video surrogates are usually reduced to image key-frames or short clips (of a few seconds) that are under the user's control. Similarly, well-chosen musical excerpts can stand in for an entire symphony. Alternatively, images of CD covers or artists can be used as visual surrogates of audio. Here are some general approaches used when there are no obvious surrogates, as with complex digital objects like animations, computer programs, and data sets:
• textual metadata
• miniature version of the content (e.g., cropped or scaled images)
• extract in a different media format (e.g., image key-frames from video)
• short extract from temporal media (e.g., video, audio, animations)
• related multimedia in another format (e.g., CD cover image)
• generic icon like the symbol for a particular document format or an image representing music.
3.4. Searching
Electronic document delivery is the primary
raison d’être for most digital libraries. But searching comes a close second—in particular, searching the full text of documents. Conventional library catalog searches are restricted to metadata, but digital libraries have access to the full content of the objects they contain. This is a great advantage.
Figure 3.11 shows a request that seeks paragraphs in English containing both the word
begin and the word
beginning (in order to find the
Alice in Wonderland quotation “begin at the beginning”), and the computer's response: a list of documents that match. These pages provide a plain and simple search mechanism with rudimentary functionality. Digital libraries, particularly ones targeted to the general public, need simple facilities that fulfill what most people want most of the time, with options for more advanced users. To quote a famous saying, “Simple things should be simple, complex things should be possible.”

In Figure 3.11 readers can specify the unit to be searched, the language, and the type of search. The selection varies from collection to collection. Searchable units typically include
paragraphs,
sections, and
documents; as well as
section titles,
document titles, and
authors. The first group involves the full text; the second involves metadata.
Full documents, not just the relevant paragraphs, are returned in the list of titles in Figure 3.11b—even though the search was for
paragraphs. In this digital library system,
documents are defined as what the user finally sees on the screen as the result of a search. If you want paragraphs to be presented individually, you must define paragraphs to be the “documents”—and arrange for them to link to the paragraphs before and after so that users can read the text in sequence. This is not hard to do.
Types of queries
In Figure 3.11 the option
all of the words has been chosen; the alternative in this collection is
some of the words. Queries comprise a list of
terms—words to be sought. In a general Boolean query, terms are combined using the connectives AND, OR, and NOT. AND is the most common connective, and that is how the option
all of the words is interpreted in Figure 3.11. A query such as
digital AND
library
might be used to retrieve books on the same subject as this one. Both terms (or equivalent lexical variants) must occur somewhere in every answer. They need not be adjacent, nor in any particular order. Documents containing phrases like
library management in the digital age will be returned, as will documents containing the text
a software library for digital signal processing—perhaps not quite what is sought, but nonetheless a correct answer to the Boolean query. A document in which the word
library appeared in the first paragraph and
digital in the last also would be considered a correct result.
Retrieval systems inevitably return many irrelevant answers, which users must filter out manually. Users have to make a difficult choice between casting a broad query, to be sure of retrieving all relevant material (albeit diluted with many irrelevant answers), and a making a narrow query where most retrieved documents are of interest but others slip through the net because the query is too restrictive. A broad search that identifies nearly all the relevant documents is said to have
high recall, while one in which nearly all retrieved documents are relevant is said to have
high precision. Searchers must choose between high precision and high recall and formulate a query appropriately. In Web searches, for example, precision is generally preferred over recall. There is so much out there that you rarely want to find
every relevant document (you probably couldn't review them all anyway) and you certainly don't want to have to check through a host of irrelevant ones. However, if you are counsel for the defense looking for precedents for a legal case, you probably care a great deal about recall—you want to be sure that you have examined
every relevant precedent, because the last thing you want is for the prosecutor to spring a nasty surprise in court.
An enduring theme in information retrieval is the tension between recall and precision.
Another problem is that small variations can yield quite different results. You might think the query
electronic AND
document AND
collection is similar to
digital AND
library, but they are likely to produce very different answers. To catch all desired documents, professional librarians become adept at adding extra terms, learning to pose queries such as
(
digital OR
virtual OR
electronic) AND (
library OR (
document AND
collection))
where the parentheses indicate operation order.
Until around 1990, Boolean retrieval systems were the primary means of accessing information in commercial and scientific applications. However, Internet search engines have shown that they are not the only way a database can be queried.
Rather than seeking exact Boolean answers, it is often better simply to list words that are of interest and have the retrieval mechanism supply whatever documents seem most relevant. For example, to locate books on digital libraries, the list of terms
digital, virtual, electronic, library, document, collection, large-scale, information, retrieval
is, to a nonprofessional at least, probably a clearer encapsulation of the topic than the Boolean query cited earlier.
Yet, identifying relevant documents is not just a matter of converting a list of terms to a Boolean query. It would be fruitless to connect these particular terms with AND operators, since vanishingly few documents are likely to match. (We cannot say that no documents will match. This page certainly does.) It would be equally pointless to use OR connectives, since far too many documents will match and few are likely to be useful.
The solution is to use
ranking. In ranking, an artificial measure is used to gauge the similarity of each document to the query, and a fixed number of the closest matching documents are returned as answers. If the measure is good, high precision is guaranteed if few documents are returned, and high recall is guaranteed if many are returned. In practice, there is a trade-off: low precision invariably accompanies high recall, since many irrelevant documents come to light before the last of the relevant ones appears in the ranking. Conversely, low recall accompanies high precision, because precision will be high only near the beginning of the ranked list, at which point only a few of the total set of relevant documents will have been encountered.
A simple ranking technique is to count the number of query terms that appear somewhere in the document: this is called
coordinate matching. A document that contains five of the query terms will be ranked higher than one containing only three, and documents that match just one query term will be ranked lower still. Obviously, coordinate matching favors long documents over short ones, since by virtue of size alone long documents are more likely to contain a broader selection of the query terms. Furthermore, common terms in the query are treated just the same as highly specific ones—for example, the query
the digital library might rank a document containing
the digital age alongside or even ahead of one containing
a digital library. Words such as
the in the query should probably not be given the same importance as
library. For this reason, most ranking techniques assign a weight to each term based on its frequency in the document collection, giving common terms low weight. They also compensate for the length of the document, so that long ones are not automatically favored.
It is difficult to describe ranking mechanisms in a few words. The simple interface in Figure 3.11 mentions only that answers should match
some of the words, as the alternative to the
all of the words that is shown in the figure (but does not give any indication as to how this is done). Experience indicates that readers are rarely confused by the responses they receive—they don't even think about the ranking mechanism.
Professional information retrieval specialists like librarians want to understand exactly how their query will be interpreted and are prepared to issue complex queries provided that the semantics are clear. For most tasks they prefer precisely targeted Boolean queries, which are especially appropriate if metadata is being searched, and particularly if professional catalogers have entered it, because the terms that are used are relatively unambiguous and predictable. Casual users, on the other hand, may not be concerned about how queries are interpreted; they prefer to trust the system to do a good job and are prepared to scroll further down the ranked list if they want to expend more effort on their search. They like ranked queries, which are especially appropriate if full text is being searched, because term usage in full text is relatively unpredictable.
Case-folding and stemming
Two common operations in querying are
case-folding and
stemming. Figure 3.12 shows a Preferences page (which allows users to choose query options), and case-folding and stemming have been selected (near the bottom). The interface supplies three- or four-word descriptions of these operations so that their meaning can be grasped immediately by casual users.

Case-folding replaces all uppercase characters in the query with their lowercase equivalents, treating uppercase versions of words as equivalent to lowercase words (in our example queries, case-folding treats
Digital and
DIGITAL and
Library and
LIBRARY as equivalent to
digital and
library). Users seeking an exact match need to disable case-folding. For example, a user looking for documents containing
Digital AND
Equipment AND
Corporation (a now-defunct computer manufacturer) would disable case-folding in order to avoid being flooded with answers about
corporation policy on capital equipment for digital libraries. Thus, users must be able to specify whether case-folding applies.
Stemming reduces words by stripping off suffixes, converting them to neutral stems that are devoid of tense, number, and—in some languages—case and gender information. This relaxes the match between query terms and words in the documents so that, for example,
libraries is deemed equivalent to
library. Like case-folding, stemming is not appropriate for all queries, particularly those involving names and other very specific words.
The addition of suffixes is governed by linguistic rules. Converting the
y in
library to the
ies in
libraries is one example; another is the doubling of a final consonant, as when
stem is augmented to
stemming. Reducing a word to its root form, or
morphological reduction, requires language dictionaries that include information about which rules apply to which words. However, for the purposes of information retrieval, simpler solutions suffice. All that is necessary is for different variants of a word to be reduced to an unambiguous common form—the stem. The stem does not have to be the same as the morphological root form. The desired effect will be obtained so long as all variants reduce to the same stem, and no other words do. Also, only certain kinds of suffixes need be considered. Linguists use the word
inflectional to describe suffixes that mark a word for grammatical categories. In contrast,
derivational suffixes modify the major category of a word—for example, when
-less is appended to words like
hope or
cloud it converts a noun to an adjective. Derivational suffixes should not be stripped because they alter the meaning—radically, in this example.
Stemming is language-dependent: an algorithm for English will not work well on French and vice versa. Indeed, the concept of stemming differs widely from one language to another. Many languages use prefixes as well as suffixes to indicate derivational forms; others contain complex compound words that should be split into constituent parts before being entered into a query. Case-folding, too, is not relevant to certain languages, such as Chinese and Arabic.
Furthermore, stemming and case-folding complicate the highlighting of search terms in retrieved documents. Simply finding the stem and highlighting all words that contain it could highlight the wrong word. For example, a particular system might make
library and
libraries match when searching by stemming them both to
librar, but deliberately avoid stemming
librarian because its derivational suffix changes the meaning. However, a simple textual match with the stem will result in the word
librarian being incorrectly highlighted in the search results. And a simplistic method may fail to highlight correct terms—a different algorithm might stem
libraries to the root form
library when searching, but fail to highlight the retrieved search term.
The correct procedure is to stem each word in the retrieved document using the same algorithm and then to assess if the result matches the stemmed query word. However, this procedure can be prohibitively time-consuming. A more practical alternative is to record the stemmed form of each word and to expand the query by adding all unstemmed variants prior to the highlighting operation.
Phrase searching
Users often want to search for contiguous groups of words. Indeed, most of our examples—
digital library,
Digital Equipment Corporation—would be better posed as phrase searches. Phrases are generally indicated in a query by using quotation marks.
Although phrase searching is simple and natural for users, it is actually quite complex to implement. Users might think the computer looks through all the documents just as they would, but faster—a lot faster. Because the computer can find the individual words in all the documents, it seems natural to conclude that it can just as easily check to determine if they come together as a phrase. However, a computer search doesn't scan through the text: that would take too long. (Computers are not all
that fast, and for documents stored on disk, access is by no means instantaneous.)
Instead, computers first create an index that records, for each word, the documents that contain that word. Every word in the query is looked up in the index, and the computer compiles a list of retrieved document numbers for each word. Then the query is answered by manipulating the lists—in the case of a Boolean AND query, by checking which documents are in all the lists. (The process is described more in Section 4.1.)
Phrase searching changes everything. No longer can queries be answered simply by manipulating lists of document numbers. Instead, there are two options. Having treated the query as a set of individual words, one option is to look inside the documents themselves: checking through all documents that contain the query terms to see if they occur together as a phrase. This is a
postretrieval scan. The other option is to record word numbers as well as document numbers in the index—the position of each occurrence of the word in the document as well as the documents it occurs in. We refer to this as a
word-level index. Then, when each word in the query is looked up in the index, the computer can tell from the list of word positions if the words occur together in a phrase, because words in a phrase will be numbered consecutively.
How phrase queries are implemented greatly affects the resources required by the system. A postretrieval scan can take a great deal of time because—depending on how common the terms in the phrase query are—many documents might have to be examined. Phrases containing unusual words can be processed quickly: few documents will include them and therefore few will need to be scanned for the occurrence of the phrase. But phrases containing common words, such as
digital library, will require substantial computer time, and response will be slow.
With a word-level index, the exact position of each occurrence of every word is recorded, instead of just the documents in which it occurs. This makes the index significantly larger. Not only are word numbers larger than document numbers, and hence require more storage space, but any given word probably appears many times in each document, and every occurrence must be recorded.
Which mechanism is employed also affects how phrases can be used in queries. For example, people often want to specify proximity: the query terms must appear within so many words of each other, but not necessarily contiguously in a phrase. If word numbers are stored, responding to a proximity query is just a matter of checking that the positions do not differ by more than the specified amount. If phrase scanning is employed, proximity searching is far more difficult.
Users sometimes seek phrases that include punctuation and even white space. Most word-level indexes treat the documents as sequences of words, ignoring punctuation and spacing. Distinguishing between differently punctuated versions of a phrase requires a postretrieval scan even if a word-level index is available—unless the index also includes word separators.
Phrases complicate ranked searching. Here the frequency of a query term throughout the corpus is used to measure how influential that word should be in determining the ranking of each document—common words like
the are less influential than rare ones like
aspidistra. However, if the query contains a phrase, it should really be the frequency of the phrase, not the frequency of the individual words in it, that is used for ranking. For example, the English words
civil,
rights, and
movement are used in many contexts, but the phrase
civil rights movement has a specific meaning. The importance of this phrase relative to other words in a query should be judged according to the frequency of the phrase, not the constituent words.
Including phrases in queries complicates things technically. In practice, building digital libraries involves pragmatic decisions. Word-level indexes are recommended if phrase searching is likely to be common and if space is not a significant constraint. Simple systems use a postretrieval scan, which suffices when phrase searching is rare or if phrases contain punctuation. In either case, ranking is based on individual word frequencies, not phrase frequencies, for practical reasons.
How can we communicate these decisions to users? As we have seen, it is difficult to fully understand what is happening in phrase searching. An alternative is a more advanced search technique, like the one described in Section 3.6, which provides a natural interface whose workings are easy to grasp.
Query interfaces
The search pages we have seen have minuscule query boxes, implicitly encouraging users to type just one or two terms. In reality, most queries contain only a few words. In fact, studies have shown that the most common number of terms in queries to Web search engines is—zero! People just hit the search button, or the Enter key, without typing anything, presumably by accident. The second most common number of search terms is one. Note that for single-term queries there is no difference between AND and OR , although in some systems
all of the words returns the documents in some predetermined order—say by date—whereas
some of the words implies ranking. For single-term queries, ranking returns documents in order of how often they contain the query term (normalized by document length). The third most common query has two terms; after that, query frequency falls off rapidly with query length.
Modern search engines easily deal with large queries: indeed, large queries can often be processed more efficiently than smaller queries because they are more likely to contain rare words that restrict the scope of the search. Figure 3.13 shows a large query box into which users can paste paragraph-sized chunks of text—and it is scrollable to facilitate even larger queries.
People often repeat searches, which is easy if they have access to their search history. “Those who ignore history,” to adapt George Santayana's famous dictum, “will be forced to retype it.” New queries are often modifications of old ones—new terms are added if the query is too broad, to increase precision at the expense of recall, or terms are removed if the query is too restrictive, to increase recall. The interface in Figure 3.14 presents the last four queries issued by the user. The buttons on the left move the query into the search box, where it can be modified. For example, clicking on the button to the left of the first field will place
begin beginning in the search box. The Preferences page in Figure 3.12 is used to select how much history to display.

What if users change search options, or even collections, between queries? The history display should make this explicit. Maybe users are experimenting with these options to test their effect on a query—Does the number of results change with stemming? Does one collection contain more potential answers than another? This is why details are given alongside the history item when such changes occur, as Figure 3.14 shows. Normally, these details don't appear, because users rarely alter their query options. When the details do appear, they clarify the context within which the query history should be interpreted.
Particularly for academic study, searches on different fields often need to be combined. For example, a researcher might be seeking a book by a certain author with a particular word in the title or a particular phrase in the main text. Library catalog systems have a search form that supplies several fields into which specifications can be entered, like the one in Figure 3.15a. Users type each part of the query into a box and use the menu to the right of the box to select the field. Finally, they decide whether the documents should satisfy
some or
all of these conditions. If necessary, users can go to the Preferences page to request more boxes (Figure 3.12).
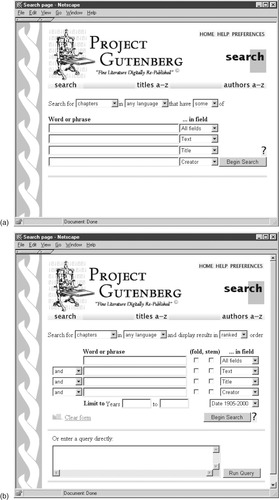
More complex fielded searches can be undertaken using the form in Figure 3.15b. Again, specifications are placed in the entry boxes and a field is selected for each one. Case-folding and stemming can be set for each individual field. The selection boxes that precede the fields allow the Boolean operators AND, OR, and AND NOT. This form cannot be used to specify completely general Boolean queries because users cannot control the order of operation—there is no place to insert parentheses. The specifications are executed sequentially: each one applies to all the fields beneath it.
The line near the top, just under the navigation bar, allows users to decide whether the results should be sorted into
ranked or
natural order (the latter is the order in which documents appear in the collection, usually by date). Users can also limit the search to certain date ranges. They can also select which date field to use, because in some collections more than one date may be associated with each document, with different dates corresponding to different kinds of metadata. For example, in a historical collection there can be a big difference between the period a document covers and the date it was written.
This advanced interface is intended for expert users. However, experts often find it frustrating to have to fill out forms: they prefer to type textual queries rather than to click between fields. Behind the form-based interface is an underlying query language, and users may prefer to use this for query entry.
Searching multimedia
The oral history collection in Figure 3.6 is a searchable multimedia collection based on textual metadata painstakingly entered by hand. An intriguing alternative is to base retrieval directly on the multimedia by analyzing the content itself. For example, optical character recognition (OCR) and automatic speech recognition (ASR) turn digitized textual images and spoken audio into text. In principle, these technologies allow source content to be fed directly into full-text indexing engines and to be retrieved in just the same way as text. However, there are some caveats, because such systems are error prone.
Media like photographs and music, which have no textual representation, present even greater challenges than textual images and spoken audio. Here are two examples.
Searching music
In a digital music library (Figure 3.7) multiple representations of music can be derived and presented. Search might be based on textual metadata, making each item retrievable by title, composer, the year it was written, who performed a particular version, etc.
But text-based search does not always map well to what users can express, particularly when the underlying form is non-textual. To locate Vivaldi's
The Four Seasons, should you search by overall title or for one of the individual parts—spring, summer, autumn and winter? In actual fact, one of the authors tried this as a student many years ago. Entering the title query
“four seasons” (with quotes) into the university library catalog returned nothing; removing the quotes produced a deluge of irrelevant matches—Vivaldi's work certainly did not appear in the first three pages. Much time was wasted varying the composition of the query (keyword, Boolean, adding the names of seasons, etc.), to no avail. Eventually, he resorted to searching for
Vivaldi and painstakingly working through several hundred matching items. When the sought-after work was finally located, it was revealed that it was cataloged under its Italian name (
Le quattro stagioni: La primavera, L’estate, L’autunno, L’inverno) and could never have been found by a title-based search formulated in English. If only it had been possible to sing a few bars of one of the themes and use that for searching!
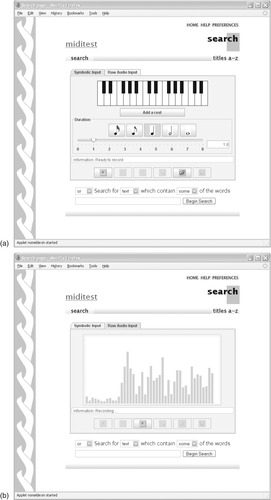
Figure 3.16 illustrates a digital library of popular MIDI tunes where searching is based upon what has been called “query by humming.” In Figure 3.16a a virtual piano keyboard is being used to tap out notes to form a symbolic query. An alternative is raw audio input, illustrated in Figure 3.16b, where the user presses a
record button and starts to sing or hum a query—in this case, the first ten notes of
Fields of Gold by Sting. Then the user presses
search, which after a short delay brings up the view shown in Figure 3.16c.
 |
 |
| Figure 3.16: |
During this time, the system analyzes the audio signal, segments it into individual notes and determines the pitch of each one. Then the collection is searched for matching songs. But musical themes recur in modified forms, and a user's recollection will not necessarily match the version in the collection, so the machine is programmed to seek approximate matches. The amount by which the notes in the query have to change to match one of the songs in the collection (technically known as the
edit distance) is used to order the results. Exact matches have an edit distance of zero and appear at the top of the list.
The result of converting the raw audio into symbolic notes is displayed in Figure 3.16c. Transcription errors may occur, depending on how clearly and accurately the user has sung, and the result is shown in music notation for the user to check. Alternatively, the query notes can be synthesized and played back. Below the query are the matching documents, with
Fields of Gold at the top. Clicking the adjacent icon launches a MIDI player to play the song (Figure 3.16d).
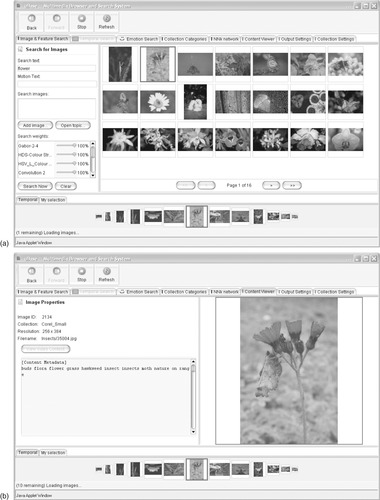
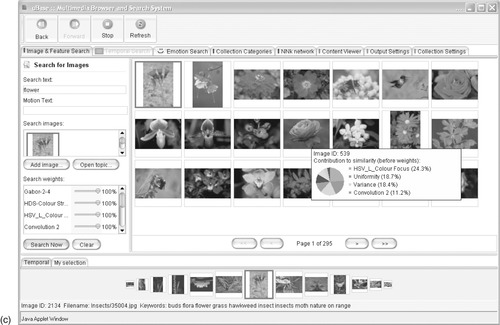
Searching images
Figure 3.17 shows a system that supports text and image content queries, both individually and jointly, and illustrates the state of the art in automatic image content analysis. The user enters the query
flower, which brings up a grid of matching thumbnails (there are 16 pages of thumbnails in all). The second thumbnail shows a carnation with a butterfly on its stem, against a defocused background of foliage. The user selects it and switches to the Content Viewer tab, which shows the larger version in Figure 3.17b, including some metadata—width and height, filename and textual keywords (in this case,
buds flora flower grass hawkweed insect insects moth nature on range). Part of the metadata (although not visible here) is a time-stamp for each image, and a temporal view appears along the bottom of the window. The current image is in the center, flanked by its neighbors in time order, shrinking into the distance in both directions.
 |
 |
| Figure 3.17: |
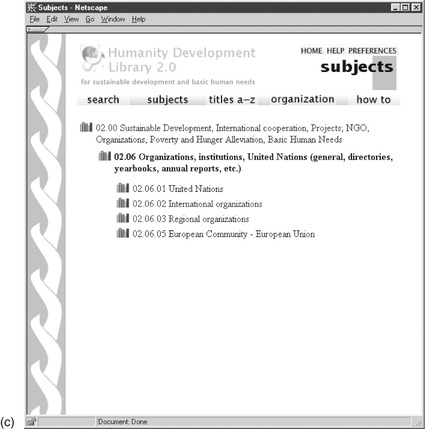
The user returns to the first view and right-clicks the image. This brings up a menu with options that include augmenting the search with the image itself. Selecting this and pressing the search button returns images whose textual metadata matches the word flower
and whose characteristics resemble the sample image; Figure 3.17c shows the result. But what does it mean to say that two images are similar? There are a host of possible dimensions: use of color, texture, uniformity, variation, and so forth.
The sliders to the left of the screen in Figures 3.17a and c each represent an aspect of similarity. There are nine in all, including one for text (the last five are obtained by scrolling). They are used to simultaneously control each aspect's influence on the decision. For example, setting the text slider to 0% and the others to 100% restricts the influence to features derived from the image content. (In this case, the same effect could be achieved by clearing the text query box.) The slider labels are cryptic—
Gabor 2-4,
Convolution 2, etc.—because the system is still an experimental research tool and these are technical names for the underlying algorithms. More conventional labels would have to be found for a general audience.
Returning to Figure 3.17c, combining the text query
flower with images similar to the chosen one replaces the matching documents with ones whose hue is more reddish (although this is not apparent in the printed version of Figure 3.17c). The user's mouse is hovering over the fourth image in the central row, and details pop up explaining which features were responsible for this item's appearance so early in the result set. A feature called
HSV-L-Colour Focus (HSV stands for hue, saturation and value) is dominant (at 24%); it is followed by features that gauge uniformity (19%), variance (18%), and convolution (11%).
3.5. Metadata Browsing
Browsing is often described as the other side of the coin from searching, but really the two are at opposite ends of a spectrum. One dictionary defines browsing as “inspecting in a leisurely and casual way,” whereas searching is “making a thorough examination in order to find something.” Other dictionaries have more verbose definitions. According to Webster's, browsing includes
• looking over casually (as a book), skimming;
• skimming through a book, reading at random passages that catch the eye;
• looking over books (as in a store or library), especially in order to decide what one wants to buy, borrow, or read;
• casually inspecting goods offered for sale, usually without prior or serious intention of buying;
• making an examination without real knowledge or purpose.
The word
browse originally referred to animals nibbling on grass or shoots, and its use in relation to reading, which is now far more widespread, appeared much later. Early in the 20th century, the library community adopted the notion of browsing as “a patron's random examination of library materials as arranged for use” when extolling the virtues of open book stacks over closed ones—the symbolic snapping of the links of the chained book mentioned in Section 1.2.
Searching is purposeful, whereas browsing tends to be casual. Terms such as
random,
informal,
unsystematic, and
without design are used to capture the unplanned nature of browsing and, often, the lack of a specific goal. Searching implies that you know what you're looking for, whereas browsing implies that you’ll know it when you see it. Often, browsers are far less directed than that—perhaps just casually passing time. But the distinction between searching and browsing is not clear—pedants are quick to point out that if, when searching, you
really know what you're looking for, then there's no need to find it. The truth is that we do not have a good vocabulary to describe various degrees of browsing.
The metadata provided with the documents in a collection can support different browsing activities. Information collections that are entirely devoid of metadata can be searched—that is one of the real strengths of full-text searching—but they cannot be browsed in any meaningful way unless some additional data is present. The structure that is implicit in metadata is the key to providing browsing facilities. And now it's time for some examples.
Lists
The simplest structure is the ordered list. Figure 3.18a shows a plain alphabetical list of document titles. Notice incidentally that the alphabetizing follows the common practice of ignoring articles like
The and
A at the beginning of titles. For some lists the ordering may use another practice: names are conventionally alphabetized by surname, even though they may be preceded by first name and initials.

Long lists can take a long time to download and are cumbersome to scroll through. They are usually presented in alphabetic ranges, as in Figure 3.18b. The user clicks a tag and a corresponding list of titles appears. In this example, the ranges have been automatically chosen so that each covers a reasonable number of documents—titles in the ranges
J–L,
Q–R, and
U–Y have been merged because there are only a few under each of the letters. In fact, Figure 3.18a was generated in exactly the same way, but there are so few documents that there was just one overall range and so the alphabetic range selector was suppressed.
This scheme does not scale up well. Tabs with multiletter labels such as
Fae–Fal are inconvenient. Although such labels are used in dictionaries and telephone directories, users generally take a stab at their desired location on the basis of the book's bulk, and then they might employ the tabs. Going through a sequence of decisions (
F,
Fa–Far,
Fae–Fal, … ) is a tedious and unnatural way of narrowing down the search.
The final tab,
0–9, presents another snag. Users can't always know what characters titles start with—titles sometimes start with punctuation characters, arithmetic operators, or mathematical symbols. Fortunately, this is not a big problem in English because such documents rarely occur and can be dealt with by a single Miscellaneous tab.
Dates
In Figure 3.19, newspapers are browsed by date. An automatically generated selector gives a choice of years; items within each range are laid out by month. Figures 3.18 and 3.19 were created automatically based on
Title and
Date metadata respectively; the year ranges are chosen to put a reasonable number of items on each page.

Hierarchies
The browsers introduced so far are restricted to linear classifications with a limited number of documents. In contrast, hierarchical structures are used in areas that have very large numbers of items. In the library world, the Library of Congress and Dewey Decimal classifications are used to categorize printed books (enabling placement of volumes treating similar subjects on neighboring shelves). These schemes are considered
hierarchical because the beginning parts of the code provide a rough categorization that is refined by the later characters.
Figure 3.20 shows a hierarchical display used in the Humanity Development Library. Nodes of the hierarchy are represented as bookshelves. Clicking one opens it up and displays all the nodes that lie beneath, as well as any documents at that level. For example, node 2.00 in Figure 3.20b contains one document and eight subsidiary nodes, of which one, node 2.06, is shown in Figure 3.20c. Just as bookshelf icons represent internal nodes of the hierarchy, so book icons represent documents, the leaves of the classification tree. Figure 3.20b shows a book icon for the
Earth Summit Report, which is the only document with classification 2.00.
 |
 |
| Figure 3.20: |
This hierarchical structure was generated automatically from metadata. Each document is accompanied by its associated position in the hierarchy. In fact, because documents can appear in several places, the metadata is multivalued. The hierarchical information includes names for the interior nodes, which are used to label the “bookshelves” in Figure 3.20. This particular classification scheme is nonstandard, chosen by the collection designer as being appropriate for the intended users. Some digital library systems impose uniformity; others provide flexibility for collection designers to organize things however they see fit. The latter option gives librarians freedom to exercise their professional judgment.
Facets
Given appropriate metadata, richer browsing options can be offered using the technique of
faceted classification, which provides alternative navigation options and conveys information that helps users understand the content of the collections. Figure 3.21 illustrates facets in a search from the Australian Newspapers project. In Figure 3.21a the user has entered the query term
Waikato (a region of New Zealand) and is viewing the result. There are over 1300 matching documents, the first ten being displayed in surrogate form, ranked, as usual, by relevance. The top item is a 1899 report in the
Northern Territory Times that the SS
Waikato was 42 days overdue on its trip from Vancouver to Auckland.
 |
| Figure 3.21: |
On the left are several categories—
facets—that provide an alternative route for exploring and refining the results. The first,
Title, is shown in its entirety, and the beginning of the second,
Category, is also visible (scrolling down would reveal the rest). The labels under each facet show the number of documents tagged with that metadata value (e.g., 178 of the 1346 results came from the
Argus newspaper), along with a visual representation as a bar graph. The user clicks on
Argus to reveal the corresponding reduced set of matching documents in Figure 3.21b. The first matching item is a 1927 report about the Melbourne Cricket Club's defeat of Waikato. Within this facet, the further facets displayed on the left can be explored by
Category,
Illustrated,
Decade, and
Word Count.
In general, facets use one of the forms of browsing described above. The Australian Newspapers project uses lists throughout, broken up into a series of pages that resemble search results. One could also imagine a
Subject facet structured as a hierarchy and an
On this day facet in calendar format. Facets are chosen by librarians based on the metadata available to guide users around collections. Not every piece of metadata makes a good facet. There are guidelines for effective facets; for example, facets should be mutually exclusive, permanent, and represent clear divisions of the items.
3.6. Putting It All Together
This section tours the Massachusetts Institute of Technology (MIT) institutional repository—a representative, publicly available digital library system—to illustrate the basic shape and form of many digital libraries today. The focus here is on the end-user's perspective. In Section 7.6 we revisit this example to explore it from a digital librarian's point of view.
An institutional repository
Figure 3.22a shows the home page of MIT's institutional repository, which is implemented in the DSpace system (see Notes and sources). It is a gateway to 30,000 digital items: technical reports, working papers, preprints, and theses. The repository is organized as a hierarchy: communities are the uppermost level, and they are hierarchically grouped into subcommunities and so forth, with individual collections at the bottom. Searching can be conducted at any level.
 |
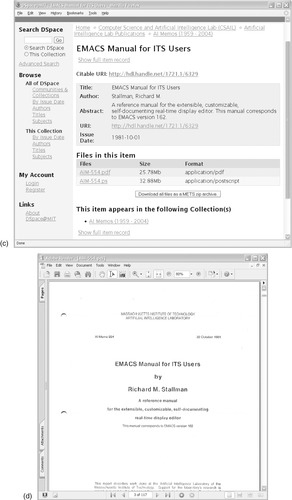 |
 |
 |
 |
| Figure 3.22: |
The left-hand margin of the screen provides access to all levels of the community hierarchy, plus browsing by date, author, and subject. Below this is where users register and log in. Searching and browsing are unrestricted, but an account is needed for services like requesting e-mail alerts. Registration is open to all, but MIT affiliates are distinguished from others and are granted access to restricted items as well as the ability to submit new items to the repository. The bottom two links in the margin connect users to RSS feeds, which provide information about new items that are added. Two variants are supported: RSS 1.0 and RSS 2.0 (depending on who you ask, the letters stand for
really simple syndication,
rich site summary or
RDF site summary). Both are XML based (see Section 4.3 for more information on XML and Section 6.4 for a description of RDF).
A user interested in the work of Richard Stallman, founder of the GNU Project and the Free Software Foundation, enters the query
stallman in the main search box. Figure 3.22b shows the result: 97 matches. The first hit is a 1981 manual for the open source EMACS text editor developed by Stallman, and clicking this link brings up Figure 3.22c, a document surrogate displaying basic metadata: title, author, abstract, and issue date. The collection—
AI Memos—is displayed at the top, along with the associated community—
Computer Science and Artificial Intelligence Lab, Artificial Intelligence Lab Publications.
The user clicks a link to view the document. Once it has downloaded (26 MB) it appears in a new window, Figure 3.22d. Despite the fact that it was born digital—as the manual itself points out, it can be viewed online as part of the Emacs help system or purchased in print for $3.25—this item in the collection is derived from a scanned copy. This is not surprising: the document was authored a year before the inception of PostScript (described in Section 4.5).
The fact that the document is digitized accounts for its vast download size and the evident graininess of the pages. It has not undergone OCR and can only be located through metadata, not full text search. However, the result set does include later documents for which a searchable version had been generated directly from the computer file, and these are included because their full text also contains
stallman. In fact, all matching full-text items turn out to be other authors referencing Stallman's work. An “advanced” facility in the digital library can be used to restrict the search to the author's name, and the more carefully constructed query in Figure 3.22e returns only eight matching documents.
Next the user clicks the
Communities and Collections link on the left to examine the complete repository, listed alphabetically by top-level community and indented to convey the hierarchical structure. The ordering continues recursively within communities, so you can drill down and commence queries at any level. The list is very long, so our user elects to browse by author instead, clicking the appropriate link to bring up Figure 3.22g. Here the user can jump immediately to any letter of the alphabet using the navigation bar; then he can step through the authors using Next page and Previous page links. Twenty authors are displayed per page; this can be changed to 5, 10, 40, 60, 80, or 100 using a pull-down menu. The sort order can also be changed from ascending to descending. Pressing
Update reloads the page with the new setting.
As noted earlier, alphabetic browsing does not scale well. MIT's repository has 25,000 authors and most letters are tedious to click through even 100 items at a time. However, users can enter the first few letters on the browsing page to filter the information displayed. To get to Figure 3.22h our user typed
ann, and then selected the author
Annan, Kofi to yield Figure 3.22i, which shows a list of all the articles by the former UN Secretary-General. In this case there is just one: a 1972 Master's thesis at the Sloan School of Management entitled
International joint venture with a government partner case study: copper mining in Zambia. The document is viewed just as before, but only registered MIT users can print it because it belongs to the Thesis collection community. For other users, a link is provided to purchase a printable copy.
3.7. Notes and Sources
The Humanity Development Library in Figure 3.1 is mentioned in Chapter 1; it is available both on CD-ROM and interactively at www.nzdl.org. More information about Project Gutenberg, from which Figures 3.2 and Figure 3.11:, Figure 3.12:, Figure 3.13:, Figure 3.14: and Figure 3.15: come, can be found at www.gutenberg.org. When we wrote the first edition of this book in 2001, it took a few hours to download the 4,500 available e-texts, and a similar amount of time to create a digital library from it. By 2008 the collection had grown over threefold, to 17,000 e-texts, but increases in Internet connectivity and computer processing speeds meant that it took roughly the same time both to download and to build an updated version.
The New Zealand School Journal is produced by the Ministry of Education and published by Learning Media Ltd. in New Zealand. Its purpose is to provide quality writing that is relevant to the needs and interests of New Zealand children, and the ultimate aim is to foster a love of reading. Figure 3.3 is taken from a prototype collection containing a few sample journals across the entire range of years from 1907 onward; it was designed by Mankelow (1999). It gives a fascinating historical perspective on the development of attitudes toward children's education—and indeed the development of society in general—throughout the last century. For copyright reasons, the collection is not publicly available.
The National Library of New Zealand's Papers Past collection in Figure 3.4 is implemented in Greenstone, and Section 11.8 discusses its construction, size, and the resources it requires. It's on the web at http://paperspast.natlib.govt.nz.
The realistic book in Figure 3.5 was produced by an open source implementation that allows such books to be easily produced from HTML or PDF files (Liesaputra et al., 2009). It is available from www.nzdl.org/books. The Oral History collection in Figure 3.6 was originally produced on audiotapes by Hamilton Public Library; Bainbridge and Cunningham (1998) describe its conversion into digital form. Early research on music collections and music searching, some of which is illustrated in Figure 3.7, is described by McNab et al. (1996) and Bainbridge et al. (1999). The 99% figure for the uptake of Flash in Web browsers comes from a June 2008 Millward Brown survey that is conducted quarterly and spans ten countries (www.adobe.com/products/player_census/flashplayer).
Figure 3.8 is from a large collection of computer science bibliographies assembled and maintained by Alf-Christian Achilles at the University of Karlsruhe, Germany (http://liinwww.ira.uka.de/bibliography). Figure 3.9a was obtained from the Library of Congress using Greenstone's Z39.50 client. Figure 3.9b is from a million-entry collection of metadata for the BBC radio and television archives. It was produced in the form of a coordinated set of five CD-ROMs that can be loaded onto disk and searched either individually or together in a seamlessly coordinated fashion, making any laptop into a full catalog server.
Much of the material on searching is taken from the book
Managing Gigabytes (Witten et al., 1999), which gives a comprehensive and detailed technical account of how to compress documents and indexes, yet make them rapidly accessible through full-text queries. There are many standard reference works covering the area of information retrieval; the best-known are Salton (1989), Salton and McGill (1983), van Rijsbergen (1979), Frakes and Baeza-Yates (1992), Korfhage (1997) and Baeza-Yates and Ribeiro-Neto (1999). Lovins (1968) and Porter (1980) are two of many authors who have produced particular algorithms for stemming. Frakes surveys this area in a chapter of a book that he coedited (Frakes, 1992); Lennon et al. (1981) have also examined the problem. We return briefly to the topic of text searching in Section 4.1.
The “famous quote” about simple and complex things near the beginning of Section 3.3 is from Alan Kay, a guru in the interactive computing world; an interesting article about him appeared in
New Scientist (Davidson, 1993). George Santayana, who feared that those who ignored history would have to relive (not retype) it, was a philosopher, poet, critic, and best-selling novelist (Santayana, 1932). Oscar Wilde, on the other hand, said that “The one duty we owe to history is to rewrite it.” Perhaps it doesn't do to take these
bon mots too seriously.
The origins of automatic speech recognition can be traced back to 1936 at AT&T's Bell Labs (www.dragon-medical-transcription.com/historyspeechrecognition.html). Open source speech recognition software is available from Carnegie Mellon University's Sphinx project, and the University of Cambridge's HTK project.
Figure 3.16 is from the Meldex collection at www.nzdl.org/meldex. Although the illustrated example focuses exclusively on musical queries, they can be combined with textual metadata queries—the text field and pull-down menu for this can be seen in the lower portion of Figure 3.16a. Studies have shown that most users can recall at least one fragment of bibliographic information when performing a music-seeking task (Bainbridge et al., 2003). The advanced image retrieval system in Figure 3.17 is the U.K. Open University's uBase, at http://kmi.open.ac.uk/technologies/ubase. The system has many advanced capabilities; what we have shown is just a taster.
Chang and Rice (1993) examine the activity of browsing from a broad interdisciplinary point of view. Hyman (1972) discusses how the notion of browsing in traditional libraries was linked to the rise of the open-stack organization; the quotation near the beginning of Section 3.5 about the “patron's random examination of library materials” is his. The brief characterization of browsing is from the
Houghton Mifflin Canadian Dictionary of the English Language; the longer one is from
Webster's Third New International Dictionary.
The list of titles in Figure 3.18a shows the Demo collection, which is supplied with every Greenstone installation and contains a small subset of the Humanity Development Library; Figure 3.18b is from the full Humanity Development Library, as is Figure 3.20. The date list in Figure 3.19 was generated within the Māori-language Niupepa collection described in Chapter 8. Spiteri (1998) provides guidelines for choosing facets, and Yee et al. (2003) report on the effectiveness of facets for searching and browsing in image collections.
The example used to illustrate facets, the Australian Newspapers project, is part of Australia's Newspapers Digitization Program at http://ndpbeta.nla.gov.au. In early 2009 it was still under development, and the functionality and URL may both change.
MIT's institutional repository can be accessed at http://dspace.mit.edu/. It was the catalyst for the open source project DSpace, a joint venture between Hewlett Packard (www.dspace.org) and MIT. The size quoted for this repository is an estimate; we could find no definitive way to ascertain the total size.
The document viewed, Richard Stallman's 1981 Emacs Manual, is actually a scanned version of every second page: pages 1, 3, 5; a handwritten note alerts the reader to this problem. This suggests that at some point a double-sided version was copied single-sided and the original was lost; an interesting lesson in document preservation.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.