
A Mixed Methods Approach to Mining Code Review Data
Examples and a Study of Multicommit Reviews and Pull Requests
Peter C. Rigby*; Alberto Bacchelli†; Georgios Gousios‡; Murtuza Mukadam* * Department of Computer Science and Software Engineering, Concordia University, Montreal, QC, Canada
† Department of Software and Computer Technology, Delft University of Technology, Delft, The Netherlands
‡ Institute for Computing and Information Sciences, Radboud University Nijmegen, Nijmegen, The Netherlands
Abstract
Software code review has been considered an important quality assurance mechanism for the last 35 years. The techniques for conducting modern code reviews have evolved along with the software industry, and have become progressively incremental and lightweight. We have studied code review in a number of contemporary settings, including Apache, Linux, KDE, Microsoft, Android, and GitHub. Code review is an inherently social activity, so we have used both quantitative and qualitative methods to understand the underlying parameters (or measures) of the process, as well as the rich interactions and motivations for doing code review. In this chapter, we describe how we have used a mixed methods approach to triangulate our findings on code review. We also describe how we use quantitative data to help us sample the most interesting cases from our data to be analyzed qualitatively. To illustrate code review research, we provide new results that contrast single-commit and multicommit reviews. We find that while multicommit reviews take longer and have more lines churned than single-commit reviews, the same number of people are involved in both types of review. To enrich and triangulate our findings, we qualitatively analyze the characteristics of multicommit reviews, and find that there are two types: reviews of branches and revisions of single commits. We also examine the reasons why commits on GitHub pull requests are rejected.
9.1 Introduction
Fagan’s study [1] of software inspections (i.e., formal code review) in 1976 was one of the first attempts to provide an empirical basis for a software engineering process. He showed that inspection, in which an independent evaluator examines software artifacts for problems, effectively found defects early in the development cycle and reduced costs. He concluded that the increased upfront investment in inspection led to fewer costly customer-reported defects.
The techniques for conducting reviews have evolved along with the software industry, and have progressively moved from Fagan’s rigid and formal inspection process to an incremental and more lightweight modern code review process. We have studied modern code review in a number of settings: Apache, Linux, KDE [2–5], Microsoft [6, 7], Android [8], and GitHub [9]. Since code review is an inherently complex social activity, we have used both quantitative and qualitative methods to understand the underlying parameters (or measures) of the process [7] as well as the rich interactions and motivations for doing code review [6]. The goal of this chapter is to introduce the reader to code review data and to demonstrate how a mixed quantitative and qualitative approach can be used to triangulate empirical software engineering findings.
This chapter is structured as follows. In Section 9.2, we compare qualitative and quantitative methods and describe how and when they can be combined. In Section 9.3, we describe the available code review data sources and provide a metamodel of the fields one can extract. In Section 9.4, we conduct an illustrative quantitative investigation to study how multiple related commits (e.g., commits on a branch) are reviewed. This study replicates many of the measures that have been used in the past, such as number of reviewers and the time to perform a review. In Section 9.5, we describe how to collect and sample nonnumerical data—for example, with interviews and from review e-mails—and extract themes from the data. Data is analyzed using a research method based on grounded theory [10]. In Section 9.6, we triangulate our findings on multicommit reviews by quantitatively examining review discussions on multiple commits. We also suggest how one might continue this study by using card sorting or interviews. Section 9.7 concludes the chapter by summarizing our findings and the techniques we use.
9.2 Motivation for a Mixed Methods Approach
While it is useful to develop new processes, practices, and tools, researchers suggest that these should not be “invented” by a single theorizing individual, but should be derived from empirical findings that can lead to empirically supported theories and testable hypotheses. Grounded, empirical findings are necessary to advance software development as an engineering discipline. With empirical work, one tries not to tell developers how they should be working, but instead tries to understand, for example, how the most effective developers work, describing the essential attributes of their work practices. This knowledge can inform practitioners and researchers and influence the design of tools.
There are two complementary methods for conducting empirical work [11]: quantitative and qualitative. Quantitative analysis involves measuring the case. For example, we can measure how many people make a comment during a review meeting. Since there is little or no interpretation involved in extracting these measurements, quantitative findings are objective. One of the common risks when extracting measures is construct validity. Do the measures assess a real phenomenon or is there a systematic bias that reduces the meaningfulness of the measurements?
In contrast, qualitative findings allow the researcher to extract complex rich patterns of interactions. For example, knowing the number of people at a review meeting does not give information about how they interacted. Using a qualitative approach, one must code data to find the qualitative themes, such as how reviewers ask questions. While qualitative approaches such as grounded theory ensure that each theme is tied back to a particular piece of data, potential for researcher bias is present.
Triangulation involves combining one or more research methods and data sources. The goal is to limit the weaknesses and biases present in each research method and dataset by using complementary methods and datasets. For example, one can measure attributes of archival review discussion and then interview developers involved in the reviews to check the validity of these measurements.
Replication involves conducting the same study using the same method for new cases. Yin [12] identified two types of case study replications: literal and contrasting. The purpose of a literal replication is to ensure that similar projects produce similar results. For example, do two similar projects, such as Apache and Subversion, yield similar findings? Contrasting replications should produce contrasting results, but for reasons predicted by one’s understanding of the differences between projects. For example, one might compare how reviewers select contributions for review on the Linux project with Microsoft Office. We would expect to see differences between these two projects based on their drastically different organizational structures.
In subsequent sections, we will use quantitative methods to measure aspects of six case study replications, and we triangulate our findings by using qualitative coding of archival review discussion to understand how developers group commits for review.
9.3 Review Process and Data
To give the reader a sense of the different types of code review, we summarize how review is done traditionally, on open-source software (OSS) projects, at Microsoft, on Google-led OSS projects, and on GitHub. Subsequently, we provide a table of the different attributes of code review that we can measure in each environment.
9.3.1 Software Inspection
Software inspections are the most formal type of review. They are conducted after a software artifact meets predefined exit criteria (e.g., a particular requirement is implemented). The process, originally defined by Fagan [1], involves some variations of the following steps: planning, overview, preparation, inspection, reworking, and follow-up. In the first three steps, the author creates an inspection package (i.e., determines what is to be inspected), roles are assigned (e.g., moderator), meetings are scheduled, and the inspectors examine the inspection package. The inspection is conducted, and defects are recorded, but not fixed. In the final steps, the author fixes the defects, and the mediator ensures that the fixes are appropriate. Although there are many variations on formal inspections, “their similarities outweigh their differences” [13].
9.3.2 OSS Code Review
Asynchronous, electronic code review is a natural way for OSS developers, who meet in person only occasionally and to discuss higher-level concerns [14], to ensure that the community agrees on what constitutes a good code contribution. Most large, successful OSS projects see code review as one of their most important quality assurance practices [5, 15, 16]. In OSS projects, a review begins with a developer creating a patch. A patch is a development artifact, usually code, that the developer feels will add value to the project. Although the level of formality of the review processes differs among OSS projects, the general steps are consistent across most projects: (1) the author submits a contribution by e-mailing it to the developer mailing list or posting it to the bug/review tracking system, (2) one or more people review the contribution, (3) the contribution is modified until it reaches the standards of the community, and (4) the revised contribution is committed to the code base. Many contributions are ignored or rejected and never make it into the code base [17].
9.3.3 Code Review at Microsoft
Microsoft developed an internal tool, CodeFlow, to aid in the review process. In CodeFlow a review occurs when a developer has completed a change, but prior to checking it into the version control system. A developer will create a review by indicating which changed files should be included, providing a description of the change (similar to a commit message), and specifying who should be included in the review. Those included receive e-mail notifications and then open the review tool, which displays the changes to the files and allows the reviewers to annotate the changes with their own comments and questions. The author can respond to the comments within the review, and can also submit a new set of changes that addresses issues that the reviewers have brought up. Once a reviewer is satisfied with the changes, he or she can “sign off” on the review in CodeFlow. For more details on the code review process at Microsoft, we refer the reader to an empirical study [6] in which we investigated the purposes of code review (e.g., finding defects and sharing knowledge) along with the actual outcomes (e.g., creating awareness and gaining code understanding) at Microsoft.
9.3.4 Google-Based Gerrit Code Review
When the Android project was released as OSS, the Google engineers working on Android wanted to continue using the internal Mondrian code review tool and process used at Google [18]. Gerrit is an OSS, Git-specific implementation of the code review tool used internally at Google, created by Google Engineers [19]. Gerrit centralizes Git, acting as a barrier between a developer’s private repository and the shared centralized repository. Developers make local changes in their private Git repositories, and then submit these changes for review. Reviewers make comments via the Gerrit Web interface. For a change to be merged into the centralized source tree, it must be approved and verified by another developer. The review process has the following stages:
1. Verified. Before a review begins, someone must verify that the change merges with the current master branch and does not break the build. In many cases, this step is done automatically.
2. Approved. While anyone can comment on the change, someone with appropriate privileges and expertise must approve the change.
3. Submitted/merged. Once the change has been approved, it is merged into Google’s master branch so that other developers can get the latest version of the system.
9.3.5 GitHub Pull Requests
Pull requests is the mechanism that GitHub offers for doing code reviews on incoming source code changes.1 A GitHub pull request contains a branch (local or in another repository) from which a core team member should pull commits. GitHub automatically discovers the commits to be merged, and presents them in the pull request. By default, pull requests are submitted to the base (“upstream” in Git parlance) repository for review. There are two types of review comments:
1. Discussion. Comments on the overall contents of the pull request. Interested parties engage in technical discussion regarding the suitability of the pull request as a whole.
2. Code review. Comments on specific sections of the code. The reviewer makes notes on the commit diff, usually of a technical nature, to pinpoint potential improvements.
Any GitHub user can participate in both types of review. As a result of the review, pull requests can be updated with new commits, or the pull request can be rejected—as redundant, uninteresting, or duplicate. The exact reason a pull request is rejected is not recorded, but it can be inferred from the pull request discussion. If an update is required as a result of a code review, the contributor creates new commits in the forked repository and, after the changes have been pushed to the branch to be merged, GitHub will automatically update the commit list in the pull request. The code review can then be repeated on the refreshed commits.
When the inspection process ends and the pull request is deemed satisfactory, it can be merged by a core team member. The versatility of Git enables pull requests to be merged in various ways, with various levels of preservation of the original source code metadata (e.g., authorship information and commit dates).
Code reviews in pull requests are in many cases implicit and therefore not observable. For example, many pull requests receive no code comments and no discussion, while they are still merged. Unless it is project policy to accept any pull request without reviewing it, it is usually safe to assume that a developer reviewed the pull request before merging it.
9.3.6 Data Measures and Attributes
A code review is effective if the proposed changes are eventually accepted or bugs are prevented, and it is efficient if the time this takes is as short as possible. To study patch acceptance and rejection and the speed of the code review process, a framework for extracting meta-information about code reviews is required. Code reviewing processes are common in both OSS [5, 9] and commercial software [6, 7] development environments. Researchers have identified and studied code review in contexts such as patch submission and acceptance [17, 20–22] and bug triaging [23, 24]. Our metamodel of code review features is presented in Table 9.1. To develop this metamodel we included the features used in existing work on code review. This metamodel is not exhaustive, but it forms a basis that other researchers can extend. Our metamodel features can be split in three broad categories:
Table 9.1
Metamodel for Code Review Analysis
| Feature | Description |
| Code review features | |
| num_commits | Number of commits in the proposed change |
| src_churn | Number of lines changed (added and deleted) by the proposed change |
| test_churn | Number of test lines changed in the proposed change |
| files_changed | Number of files touched by the proposed change |
| num_comments | Discussion and code review comments |
| num_participants | Number of participants in the code review discussion |
| Project features | |
| sloc | Executable lines of code when the proposed change was created |
| team_size | Number of active core team members during the last 3 months prior to the proposed change creation |
| perc_ext_contribs | The ratio of commits from external members over core team members in the last n months |
| commits_files_touched | Number of total commits on files touched by the proposed change n months before the proposed change creation time |
| test_lines_per_kloc | A proxy for the project’s test coverage |
| Developer | |
| prev_changes | Number of changes submitted by a specific developer, prior to the examined proposed change |
| requester_succ_rate | Percentage of the developer’s changes that have been integrated up to the creation of the examined proposed change |
| reputation | Quantification of the developer’s reputation in the project’s community (e.g., followers on GitHub) |

1. Proposed change features. These characteristics attempt to quantify the impact of the proposed change on the affected code base. When external code contributions are examined, the size of the patch affects both acceptance and the acceptance time [21]. Various metrics have been used by researchers to determine the size of a patch: code churn [20, 25], changed files [20], and number of commits. In the particular case of GitHub pull requests, developers reported that the presence of tests in a pull request increases their confidence to merge it Pham et al. [26]. The number of participants has been shown to influence the amount of time taken to conduct a code review [7].
2. Project features. These features quantify the receptiveness of a project to an incoming code change. If the project’s process is open to external contributions, then we expect to see an increased ratio of external contributors over team members. The project’s size may be a detrimental factor to the speed of processing a proposed change, as its impact may be more difficult to assess. Also, incoming changes tend to cluster over time (the “yesterday’s weather” change pattern [27]), so it is natural to assume that proposed changes affecting a part of the system that is under active development will be more likely to merge. Testing plays a role in the speed of processing; according to [26], projects struggling with a constant flux of contributors use testing, manual or preferably automated, as a safety net to handle contributions from unknown developers.
3. Developer. Developer-based features attempt to quantify the influence that the person who created the proposed change has on the decision to merge it and the time to process it. In particular, the developer who created the patch has been shown to influence the patch acceptance decision [28] (recent work on different systems interestingly reported opposite results [29]). To abstract the results across projects with different developers, researchers devised features that quantify the developer’s track record [30]—namely, the number of previous proposed changes and their acceptance rate; the former has been identified as a strong indicator of proposed change quality [26]. Finally, Bird et al. [31], presented evidence that social reputation has an impact on whether a patch will be merged; consequently, features that quantify the developer’s social reputation (e.g., follower’s in GitHub’s case) can be used to track this.
9.4 Quantitative Replication Study: Code Review on Branches
Many studies have quantified the attributes of code review that we discussed in Table 9.1 (e.g., [2, 22, 32]). All review studies to date have ignored the number of commits (i.e., changes or patches) that are under discussion during review. Multicommit reviews usually involve a feature that is broken into multiple changes (i.e., a branch) or a review that requires additional corrective changes submitted to the original patch (i.e., revisions). In this section, we perform a replication study using some of the attributes described in the previous section to understand how multiple related commits affect the code review process. In Section 9.6, we triangulate our results by qualitatively examining how and why multiple commits are reviewed. We answer the following research questions:
1. How many commits are part of each review?
2. How many files and lines of code are changed per review?
3. How long does it take to perform a review?
4. How many reviewers make comments during a review?
We answer these questions in the context of Android and Chromium OS, which use Gerrit for review; the Linux Kernel, which performs email-based review; and the Rails, Katello, and WildFly projects, which use GitHub pull requests for review. These projects were selected because they are all successful, medium-sized to large, and represent different software domains.
Table 9.2 shows the dataset and the time period we examined in years. We use the data extracted from these projects and perform comparisons that help us draw conclusions.
Table 9.2
The Time Period we Examined
| Project | Period | Years |
| Linux Kernel | 2005-2008 | 3.5 |
| Android | 2008-2013 | 4.0 |
| Chrome | 2011-2013 | 2.1 |
| Rails | 2008-2011 | 3.2 |
| Katello | 2008-2011 | 3.2 |
| WildFly | 2008-2011 | 3.2 |
More details on the review process used by each project are provided in the discussion in Section 9.3. We present our results as boxplots, which show the distribution quartiles, or, when the range is large enough, a distribution density plot [33]. In both plots, the median is represented by a bold line.
9.4.1 Research Question 1—Commits per Review
How many commits are part of each review?
Table 9.3 shows the size of the dataset and proportion of reviews that involve more than one commit. Chrome has the largest percentage of multicommit reviews, at 63%, and Rails has the smallest, at 29%. Single-commit reviews dominate in most projects. In Figure 9.1 we consider only multicommit reviews, and find that Linux, WildFly, and Katello have a median of three commits. Android, Chrome, and Rails have a median of two commits.
Table 9.3
Number of Reviews in our Dataset and Number of Commits per Review
| Project | All | Single Commit (%) | Multicommit (%) |
| Linux Kernel | 20,200 | 70 | 30 |
| Android | 16,400 | 66 | 34 |
| Chrome | 38,700 | 37 | 63 |
| Rails | 7300 | 71 | 29 |
| Katello | 2600 | 62 | 38 |
| WildFly | 5000 | 60 | 40 |


9.4.2 Research Question 2—Size of Commits
How many files and lines of code are changed per review?
Figure 9.2 shows that WildFly makes the largest changes, with single changes having a median of 40 lines churned, while Katello makes the smallest changes (median eight lines). WildFly also makes the largest multicommit changes, with a median of 420 lines churned, and Rails makes the smallest, with a median of 43.
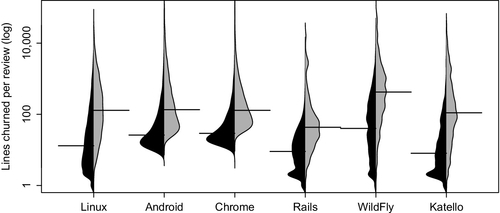
In terms of lines churned, multicommit reviews are 10, 5, 5, 5, 11, and 14 times larger than single-commit reviews for Linux, Android, Chrome, Rails, WildFly, and Katello, respectively. In comparison with Figure 9.1, we see that multicommit reviews have one to two more commits than single-commit reviews. Normalizing for the number of commits, we see that individual commits in multicommit reviews contain more lines churned than those in single-commit reviews. We conjecture that multicommit changes implement new features or involve complex changes.
9.4.3 Research Question 3—Review Interval
How long does it take to perform a review?
The review interval is the calendar time since the commit was posted until the end of discussion of the change. The review interval is an important measure of review efficiency [34, 35]. The speed of feedback provided to the author depends on the length of the review interval. Researchers also found that the review interval is related to the overall timeliness of a project [36].
Current practice is to review small changes to the code before they are committed, and to do this review quickly. Reviews on OSS systems, at Microsoft, and on Google-led projects last for around 24 h [7]. This interval is very short compared with the months or weeks required for formal inspections [1, 35].
Figure 9.3 shows that the GitHub projects perform reviews at least as quickly as the Linux and Android projects. Single-commit reviews happen in a median of 2.3 h (Chrome) and 22 h (Linux). Multicommit reviews are finished in a median of 22 h (Chrome) and 3.3 days (Linux).

Multicommit reviews take 4, 10, 10, 9, 2, and 7 times longer than single-commit reviews for Linux, Android, Chrome, Rails, WildFly, and Katello, respectively.
9.4.4 Research Question 4—Reviewer Participation
How many reviewers make comments during a review?
According to Sauer et al. [37], two reviewers tend to find an optimal number of defects. Despite different processes for reviewer selection (e.g., self-selection vs assignment to review), the number of reviewers per review is two in the median case across a large diverse set of projects [7]. With the exception of Rails, which has a median of three reviewers in multicommit reviews, reviews are conducted by two reviewers regardless of the number of commits (see Figure 9.4).

The number of comments made during a review varies with the number of commits. For Android, Chrome, and WildFly the number of comments increases from three to four, while for Rails and Katello the number increases from one to three. For Linux there is a much larger increase, from two to six comments.
9.4.5 Conclusion
In this section, we contrasted multicommit and single-commit reviews for the number of commits, churn, interval, and participation. We found that multicommit reviews increase the number of commits by one to two in the median case. The churn increases more dramatically, between 5 and 14 times the number of changed lines in the median case. The amount of time to perform a review varies quite substantially from 2.3 hours to 3.3 days in the median case. Multicommit reviews take 2-10 times longer than single-commit reviews. The number of reviewers is largely unaffected by review: we see two reviewers per review, with the exception of Rails. The number of comments per review increases in multicommit reviews. We purposefully did not perform statistical comparisons among projects. Statistical comparisons are not useful because we have the entire population of reviews for each project and not a sample of reviews. Furthermore, given the large number of reviews we have for each project, even small differences that have no practical importance to software engineers would be highlighted by statistical tests.
No clear patterns emerged when we compared the multicommit and single-commit review styles across projects and across review infrastructures (e.g., Gerrit vs GitHub). Our main concern is that multicommit reviews will serve two quite different purposes. The first purpose would be to review branches that contain multiple related commits. The second purpose will be to review a single commit after it has been revised to incorporate reviewer feedback. In Section 9.5, we randomly sample multicommit reviews and perform a qualitative analysis to determine the purpose of each review. These qualitative findings will enhance the measurements made in this section by uncovering the underlying practices used in each project.
9.5 Qualitative Approaches
Studies of formal software inspection [1, 34, 38] and code review [2, 7, 15, 22, 32, 39, 40] have largely been quantitative with the goal of showing that a new process or practice is effective, finds defects, and is efficient.
Unlike traditional inspection, which has a prescriptive process, modern code review has gradually emerged from industrial and open-source settings. Since the process is less well defined, it is important to conduct exploratory analyses that acknowledge the context and interactions that occur during code review. These studies are required to gain an in-depth understanding of code review, which is a complex phenomenon that encompasses nontrivial social aspects. Such understanding can be gained only by answering many how and why questions, for which numbers and statistics would give only a partial picture. For this reason, the studies were conducted using qualitative methods.
Qualitative methods involve the “systematic gathering and interpretation of nonnumerical data” [41]. Software engineering researchers collect the nonnumerical data by studying the people involved in a software project as they work, typically by conducting field research [42]. Field research consists of “a group of methods that can be used, individually or in combination, to understand different aspects of real world environments” [43]. Lethbridge et al. [43] surveyed how field research had been performed in software engineering, and accordingly proposed a taxonomy of data collection techniques by grouping them in three main sets: (1) direct, (2) indirect, and (3) independent. Direct data collection techniques (e.g., focus groups, interviews, questionnaires, or think-aloud sessions) require researchers to have direct involvement with the participant population; indirect techniques (e.g., instrumenting systems, or “fly on the wall”) require the researcher to have only indirect access to the participants via direct access to their work environment; independent techniques (e.g., analysis of tool use logs or documentation analysis) require researchers to access only work artifacts, such as issue reports or source code.
In this section, we analyze two exploitative studies on code reviews. We dive into the details of the qualitative research methods used in two of those studies, to understand them in more detail and to show how qualitative research could be employed to shine a light on aspects of modern code review practices.
The first study manually examines archives of review data to understand how OSS developers interact and manage to effectively conduct reviews on large mailing lists [3]. The second study investigates the motivations driving developers and managers to do and require code review among product teams at Microsoft [6]. The two studies considered use both direct and independent data collection techniques. The data gathered is then manually analyzed according to different qualitative methods.
9.5.1 Sampling Approaches
Qualitative research requires such labor-intensive data analysis that not all the available data can be processed, and it is necessary to extract samples. This regards not only indirect data (e.g., documents), but also direct data and its collection (e.g., people to interview), so that the data can be subsequently analyzed.
In quantitative research, where computing power can be put to good use, one of the commonest approaches for sampling is random sampling: picking a high number of cases, randomly, to perform analyses on. Such an approach requires a relatively high number of cases so that they will be statistically significant. For example, if we are interested in estimating a proportion (e.g., number of developers who do code reviews) in a population of 1,000,000, we have to randomly sample 16,317 cases to achieve a confidence level of 99% with an error of 1% [44]. Although very computationally expensive, such a number is simple to reach with quantitative analyses.
Given the difficulty of manually coding data points in qualitative research, random sampling can lead to nonoptimal samples. In the following, we explain how sampling was conducted on the two qualitative studies considered, first in doing direct data collection, then in doing independent data collection.
9.5.1.1 Sampling direct data
As previously mentioned, one of the main goals of qualitative research is to see a phenomenon from the perspective of another person, normally involved with it. For this reason, one of the commonest ways to collect qualitative data is to use direct data collection by means of observations and interviews. Through observations and interviews, we can gather accurate and finely nuanced information, thus exposing participants’ perspectives.
However, interviews favor depth over quantity. Interviewing and the consequent nonnumerical data analysis are time-consuming tasks, and not all the candidates are willing to participate in investigations and answer interview questions. In the two qualitative studies considered, the authors used different approaches to sample interview participants.
Rigby and Storey [3] selected interviewees among the developers of the Apache and Subversion projects. They ranked developers on the basis of the number of e-mail-based reviews they had performed, and they sent an interview request to each of the top five reviewers in each project. The researchers’ purpose was to interview the most prolific reviewers, in order to learn from their extensive experience and daily practice, thus understanding the way in which experts dealt with submitted patches on OSS systems. Overall, the respondents that they interviewed were nine core developers, either with committer rights or maintainers of a module.
Bacchelli and Bird [6] selected interviewees among different Microsoft product teams (e.g., Excel and SQL Server). They sampled developers on the basis of the number of reviews they had done since the introduction of CodeFlow (see Section 9.3.3): They contacted 100 randomly selected candidates who signed off between 50 and 250 code reviews. In this case, they did not select the top reviewers, but selected a sample of those with an average mid-to-high activity. In fact, their purpose was to understand the motivation of developers who do code reviews. The respondents that they interviewed comprised 17 people: five developers, four senior developers, six testers, one senior tester, and one software architect. Their time in the company ranged from 18 months to almost 10 years, with a median of 5 years.
9.5.1.2 Sampling indirect data
Although, as shown in the rest of this chapter, indirect code review data can be used entirely when employing quantitative methods, this is not the case for qualitative analyses. In fact, if researchers are willing to qualitatively analyze review comments recorded in e-mails or in archives generated by code review tools, they have to sample this data to make it manageable.
In the studies considered, Rigby and Storey [3] analyzed e-mail reviews for six OSS projects, and Bacchelli and Bird [6] analyzed code review comments recorded by CodeFlow during code reviews done in different Microsoft product groups. In both cases, since no human participants were involved, the researchers could analyze hundreds of documents.
9.5.1.3 Data saturation
Although a large part of the qualitative analysis is conducted after the data gathering, qualitative researchers also analyze their data throughout their data collection. For this reason, in qualitative research it is possible rely on data saturation to verify whether the size of a sample could be large enough for the chosen research purpose [10]. Data saturation happens in both direct data collection and indirect data collection, and occurs when the researcher is no longer seeing, hearing, or reading new information from the samples.
In both studies the number of data points—for example, reviews and possible interviewees—was much larger than any group of researchers could reasonably analyze. During analysis, when no new patterns were emerging from the data, saturation had been reached, and the researchers stopped introducing new data points and started the next stage of analysis.
9.5.2 Data Collection
In the following, we describe how the researchers in the two studies collected data by interviewing and observing the study participants selected in the sampling phase. In both studies, the aim of this data collection phase was to gain an understanding of code reviewing practices by adopting the perspective of the study participants (this is often the main target of qualitative research [41]). Moreover, we also briefly explain how they collected indirect data about code reviews.
9.5.2.1 Observations and interviews at Microsoft
In the study conducted at Microsoft, each meeting with participants comprised two parts: an observation, and a following semistructured interview [45].
In the e-mails sent to candidate participants in the study, Bacchelli and Bird invited developers to notify them when they received the next review task, so that the researchers could go to the participant’s office (this happened within 30 min from the notification) to observe how developers conducted the review. To minimize invasiveness and the Hawthorne effect [46], only one researcher went to the meeting and observed the review. To encourage the participants to narrate their work (thus collecting more nonnumerical data), the researcher asked the participants to consider him as a newcomer to the team. In this way, most developers thought aloud without the need for prompting.
With consent, assuring the participants of anonymity, the audio of the meeting was recorded. Recording is a practice on which not all the qualitative researcher methodologists agree [10]. In this study, researchers preferred to have recorded audio for two reasons: (1) having the data to analyze for the researcher who was not participating in the meetings; and (2) the researcher at the meeting could fully focus on the observation and interaction with participants during the interview. Since the researchers, as observers, have backgrounds in software development and practices at Microsoft, they could understand most of the work and where and how information was obtained without inquiry.
After the observations, the second part of the meeting took place—that is, the semistructured interview. This form of interview makes use of an interview guide that contains general groupings of topics and questions rather than a predetermined exact set and order of questions. Semistructured interviews are often used in an exploratory context to “find out what is happening [and] to seek new insights” [47].
The researchers devised the first version of the guideline by analyzing a previous internal Microsoft study on code review practices, and by referring to academic literature. Then, the guideline was iteratively refined after each interview, in particular when developers started providing answers very similar to the earlier ones, thus reaching saturation.
After the first five or six meetings, the observations reached the saturation point. For this reason, the researchers adjusted the meetings to have shorter observations, which they used only as a starting point for interacting with participants and as a hook to talk about topics in the interview guideline.
At the end of each interview, the audio was analyzed by the researchers, and then transcribed and broken up into smaller coherent units for subsequent analysis.
9.5.2.2 Indirect data collection: Review comments and e-mails
As we have seen in previous sections, code review tools archive a lot of valuable information for data analysis; similarly, mailing lists archive discussions about patches and their acceptance. Although part of the data is numerical, a great deal of information is nonnumerical data—for example, code review comments. This information is a good candidate for qualitative analysis, since it contains traces of opinions, interactions, and general behavior of developers involved in the code review process.
Bacchelli and Bird randomly selected 570 code review comments from CodeFlow data pertaining to more than 10 different product teams at Microsoft. They considered only comments within threads with at least two comments so that they were sure there was interaction between developers. Considering that they were interested in measuring the types of comments, this amount, from a quantitative perspective, would have a confidence level of 95% and an error of 8%.
Rigby and Storey randomly sampled 200 e-mail reviews for Apache, 80 for Subversion, 70 for FreeBSD, 50 for the Linux kernel, and 40 e-mail reviews and 20 Bugzilla reviews for KDE. In each project, the main themes from the previous project reoccurred, indicating that that saturation had been reached and that it was unnecessary to code an equivalent number of reviews for each project.
9.5.3 Qualitative Analysis of Microsoft Data
To qualitatively analyze the data gathered from observations, interviews, and recorded code review comments, Bacchelli and Bird used two techniques: a card sort and an affinity diagram.
9.5.3.1 Card sorting
To group codes that emerged from interviews and observations into categories, Bacchelli and Bird conducted a card sort. Card sorting is a sorting technique that is widely used in information architecture to create mental models and derive taxonomies from input data [48]. In their case, it helped to organize the codes into hierarchies to deduce a higher level of abstraction and identify common themes. A card sort involves three phases: (1) in the preparation phase, participants of the card sort are selected and the cards are created; (2) in the execution phase, cards are sorted into meaningful groups with a descriptive title; and (3) in the analysis phase, abstract hierarchies are formed to deduce general categories.
Bacchelli and Bird applied an open card sort: there were no predefined groups. Instead, the groups emerged and evolved during the sorting process. In contrast, a closed card sort has predefined groups and is typically applied when themes are known in advance, which was not the case for our study.
Bacchelli created all of the cards, from the 1047 coherent units generated from the interview data. Throughout the further analysis, other researchers (Bird and external people) were involved in developing categories and assigning cards to categories, so as to strengthen the validity of the result. Bacchelli played a special role of ensuring that the context of each question was appropriately considered in the categorization, and creating the initial categories. To ensure the integrity of the categories, Bacchelli sorted the cards several times. To reduce bias from Bacchelli sorting the cards to form initial themes, all researchers reviewed and agreed on the final set of categories.
The same method was applied to group code review comments into categories: Bacchelli and Bird printed one card for each comment (along with the entire discussion thread to give the context), and conducted a card sort, as performed for the interviews, to identify common themes.
9.5.3.2 Affinity diagramming
Bacchelli and Bird used an affinity diagram to organize the categories that emerged from the card sort. This technique allows large numbers of ideas to be sorted into groups for review and analysis [49]. It was used to generate an overview of the topics that emerged from the card sort, in order to connect the related concepts and derive the main themes. To generate the affinity diagram, Bacchelli and Bird followed five canonical steps: they (1) recorded the categories on Post-it notes, (2) spread them onto a wall, (3) sorted the categories on the basis of discussions, until all had been sorted and all participants had agreed, (4) named each group, and (5) captured and discussed the themes.
9.5.4 Applying Grounded Theory to Archival Data to Understand OSS Review
The preceding example demonstrated how to analyze data collected from interviews and observation using a card sort and an affinity diagram. Qualitative analysis can also be applied to the analysis of archival data, such as records of code review (see Figure 9.5). To provide a second perspective on qualitative analysis, we describe the method used by Rigby and Storey [3] to code review discussion of six OSS projects. In the next section, we describe one of the themes that emerged from this analysis: patchsets. Patchsets are groups of related patches that implement a larger feature or fix and are reviewed together.

The analysis of the sample e-mail reviews followed Glaser’s approach [10] to grounded theory, where manual analysis uncovers emergent abstract themes. These themes are developed from descriptive codes used by the researchers to note their observations. The general steps used in grounded theory are as follows: note taking, coding, memoing, sorting, and writing.2 Below we present each of these steps in the context of the study of Rigby and Storey:
1. Note taking. Note taking involves creating summaries of the data without any interpretation of the events [10]. The comments in each review were analyzed chronologically. Since patches could often take up many screens with technical details, the researchers first summarized each review thread. The summary uncovered high-level occurrences, such as how reviewers interacted and responded.
2. Coding. Codes provide a way to group recurring events. The reviews were coded by printing and reading the summaries and writing the codes in the margin. The codes represented the techniques used to perform a review and the types and styles of interactions among stakeholders. The example shown in Figure 9.5 combines note taking and coding, with emergent codes being underlined.
3. Memos. Memoing is a critical aspect of grounded theory, and differentiates it from other qualitative approaches. The codes that were discovered on individual reviews were grouped together and abstracted into short memos that describe the emerging theme. Without this stage, researchers fail to abstract codes and present “stories” instead of a high-level description of the important aspects of a phenomenon.
4. Sorting. Usually there are too many codes and memos to be reported in a single paper. The researchers must identify the core memos and sort and group them into a set of related themes. These core themes become the grounded “theory.” A theme was the way reviewers asked authors questions about their code.
5. Writing. Writing the paper is simply a matter of describing the evidence collected for each theme. Each core theme is written up by tracing the theme back to the abstract memos, codes, and finally the data points that lead to the theme. One common mistake is to include too many low-level details and quotations [10]. In the work of Rigby and Storey, the themes are represented throughout the paper as paragraph and section headings.
9.6 Triangulation
Triangulation “involves the use of multiple and different methods, investigators, sources, and theories to obtain corroborating evidence” [50]. Since each method and dataset has different strengths and weakness that offset each other when they are combined, triangulation reduces the overall bias in a study. For example, survey and interview data suffer from the biases that participants self-report on events that have happened in the past. In contrast, archival data is a record of real communication and so does not suffer from self-reporting bias. However, since archival data was collected without a research agenda, it can often be missing information that a researcher needs to answer his or her questions. This missing information can be supplemented with interview questions.
In this section, we first describe how Bacchelli and Bird [6] triangulate their findings using follow-up surveys. We then triangulate our quantitative findings from Section 9.4 on multicommit reviews by first describing a qualitative study of branch reviews on Linux. We then manually code multicommit reviews as either branches or revisions in the Gerrit and GitHub projects that we examined in Section 9.4. We conclude this section with a qualitative and quantitative examination of why GitHub reviews are rejected.
9.6.1 Using Surveys to Triangulate Qualitative Findings
The investigation of Bacchelli and Bird about expectations, outcomes, and challenges of code review employed a mixed quantitative and qualitative approach, which collects data from different sources for triangulation. Figure 9.6 shows the overall research method employed, and how the different sources are used to draw conclusions and test theories: (1) analysis of the previous study, (2) meetings with developers (observations and interviews), (3) card sort of meeting data, (4) card sort of code review comments, (5) affinity diagramming, and (6) survey of managers and programmers.
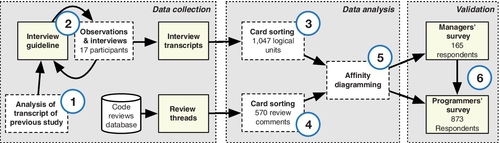
The path including points 1-5 is described in Section 9.5, because it involves collection and analysis of nonnumerical data; here we focus on the use of surveys for additional triangulation. In Figure 9.6 we can see that the method already includes two different sources of data: direct data collection based on observations and interviews, and indirect data collection based on the analysis of comments in code review archives. Although these two sources are complementary and can be used to learn distinct stories, to eventually uncover the truth behind a question, they both suffer from a limited number of data points. To overcome this issue, Bacchelli and Bird used surveys to validate—with a larger, statistically significant sample—the concepts that emerged from the analysis of the data gathered from other sources.
In practice, they created two surveys and sent them to a large number of participants and triangulated the conclusions of their qualitative analysis. The full surveys are available as a technical report [51]. For the design of the surveys, Bacchelli and Bird followed the guidelines of Kitchenham and Pfleeger [52] for personal opinion surveys. Although they could have sent the survey in principle to all the employees at Microsoft, they selected samples that were statistically significant, but at the same time would not inconveniently hit an unnecessarily large number of people. Both surveys were anonymous to increase response rates [53].
They sent the first survey to a cross section of managers. They considered managers for whom at least half of their team performed code reviews regularly (on average, one pr more per week) and sampled along two dimensions. The first dimension was whether or not the manager had participated in a code review himself or herself since the beginning of the year, and the second dimension was whether the manager managed a single team or multiple teams (a manager of managers). Thus, they had one sample of first-level managers who participated in a review, and another sample of second-level managers who participated in reviews, etc. The first survey was a short survey comprising six questions (all optional), which they sent to 600 managers who had at least 10 direct or indirect reporting developers who used CodeFlow. The central focus was the open question asking managers to enumerate the main motivations for doing code reviews in their team. They received 165 answers (28% response rate), which were analyzed before they devised the second survey.
The second survey comprised 18 questions, mostly closed questions with multiple choice answers, and was sent to 2000 randomly chosen developers who had signed off on average at least one code review per week since the beginning of the year. They used the time frame of January to June 2012 to minimize the amount of organizational churn during the time period and identify employees’ activity in their current role and team. The survey received 873 answers (44% response rate). Both response rates were high, as other online surveys in software engineering have reported response rates ranging from 14% to 20% [54].
Although the surveys also included open questions, they were mostly based on closed ones, and thus could be used as a basis for statistical analyses. Thanks to the high number of respondents, Bacchelli and Bird could triangulate their qualitative findings with a larger set of data, thus increasing the validity of their results.
9.6.2 How Multicommit Branches are Reviewed in Linux
In Section 9.4, we quantitatively compared single-commit and multicommit reviews. We found that there was no clear pattern of review on the basis of the size of the project and the type of review tool (i.e., Gerrit, GitHub, or e-mail-based review). To enhance our findings and to understand the practices that underlie them, we qualitatively examine how multiple commits are handled on Linux. We find that multicommit reviews contain patches related to a single feature or fix. In the next section, we use closed coding to determine if the other projects group commits by features or if multicommit reviews are indicative of revisions of the original commit.
Instead of conducting reviews in Gerrit or as GitHub pull requests, the Linux kernel uses mailing lists. Each review is conducted as an e-mail thread. The first message in the thread will contain the patch, and subsequent responses will be reviews and discussions of review feedback (Rigby and Storey [3] provide more details on this point). According to code review polices of OSS projects, individual patches are required to be in their smallest, functionally independent, and complete form [2]. Interviews of OSS developers also indicated a preference for small patches, with some stating that they refuse to review large patches until they are split into their component parts. For Iwai, a core developer on the Linux project, “if it [a large patch] can’t be split, then something is wrong [e.g., there are structural issues with the change].” However, by forcing developers to produce small patches, larger contributions are broken up and reviewed in many different threads. This division separates and reduces communication among experts, making it difficult to examine large contributions as a single unit. Testers and reviewers must manually combine these threads together. Interviewees complained about how difficult it is to combine a set of related patches to test a new feature.
Linux developers use patchsets, which allow developers to group related changes together, while still keeping each patch separate. A patchset is a single e-mail thread that contains multiple numbered and related contributions. The first e-mail contains a high-level description that ties the contributions together and explains their interrelationships. Each subsequent message contains the next patch that is necessary to complete the larger change. For example, message subjects in a patchset might look like this3 :
• Patch 0/3: fixing and combining foobar with bar [no code modified].
• Patch 1/3: fix of foobar.
• Patch 2/3: integrate existing bar with foobar.
• Patch 3/3: update documentation on bar.
Patchsets are effectively a branch of small patch commits that implements a larger change. The version control system Git contains a feature to send a branch as a number patchset to a mailing list for code review [55].
Notice how each subcontribution is small, independent, and complete. Also, the contributions are listed in the order they should be committed to the system (e.g., the fix to foobar must be committed before combining it with bar). Reviewers can respond to the overall patch (i.e., 0/N) or they can respond to any individual patch (i.e., n/N,n > 0). As reviewers respond, subthreads tackle subproblems. However, it remains simple for testers and less experienced reviewers to apply the patchset as a single unit for testing purposes. Patchsets represent a perfect example of creating a fine, but functional and efficient division between the whole and the parts of a larger problem.
9.6.3 Closed Coding: Branch or Revision on GitHub and Gerrit
A multicommit review may be a related set of commits (a branch or patchset) or a revision of a commit. We conduct a preliminary analysis of 15 randomly sampled multicommit reviews from each project to understand what type of review is occurring. Of the 15 reviews coded for each of the GitHub-based projects, 73%, 86%, and 60% of them were branches for Rails, WildFly, and Katello, respectively. These projects conducted branch review in a manner similar to Linux, but without the formality of describing the changes at a high level. Each change had a one-line commit description that clearly indicated its connection to the next commit in the branch. For example, the commits in the following pull request implement two small parts of the same change4 :
• Commit 1: “Modified CollectionAssociation to refer to the new class name.”
• Commit 2: “Modified NamedScopeTest to use CollectionAssociation.”
WildFly had the highest percentage of branch reviews, which may explain why it had the largest number of lines changed and the longest review interval of all the projects we examined (see Section 9.4).
For GitHub, we also noted that some of the multicommit reviews were of massive merges instead of individual feature changes.5 It would be interesting to examine “massive” merge reviews.
For Android and Chrome, we were surprised to find that none of the randomly selected reviews were of branches. Each multicommit review involved revisions of a single commit. While work is necessary to determine whether this is a defacto practice or enforced by policy, there is a preference at Google to commit onto a single branch [56]. Furthermore, the notion of “patchset” in the Gerrit review system usually applies to an updated version of a patch rather than a branch, as it does in Linux [19].
9.6.4 Understanding Why Pull Requests are Rejected
As a final example of mixed qualitative-quantitative research involving triangulation, we present new findings on why pull request reviews are rejected in GitHub projects. Previous work found relatively low rates of patch acceptance in large successful OSS projects. Bird et al. [17] found that the acceptance rate in three OSS projects was between 25% and 50%. In the six projects examined by Asundi and Jayant [16], they found that 28% to 46% of non-core developers had their patches ignored. Estimates of Bugzilla patch rejection rates for Firefox and Mozilla range from 61% [28] to 76% [15]. In contrast, while most proposed changes in GitHub pull requests are accepted [9], it is interesting to explore why some are not. Even though textual analysis tools (e.g., natural language processing and topic modeling) are evolving, it is still difficult for them to accurately capture and classify the rationale behind such complex actions as rejecting code under review. For this reason, a researcher needs to resort to qualitative methods.
In the context of GitHub code reviews, we manually coded 350 pull requests and classified the reasons for rejection. Three independent coders did the coding. Initially, 100 pull requests were used by the first coder to identify discrete reasons for closing pull requests (bootstrapping sample), while a different set of 100 pull requests was used by all three coders to validate the categories identified (cross-validation sample). After validation, the two datasets were merged, and a further 150 randomly selected pull requests were added to the bootstrapping sample to construct the finally analyzed dataset, for a total of 350 pull requests. The cross-validation of the categories on a different set of pull requests revealed that the categories identified are enough to classify all reasons for closing a pull request. The results are presented in Table 9.4.
Table 9.4
Reasons for Rejecting Code Under Review
| Reason | Description | Percentage |
| obsolete | The pull request is no longer relevant, as the project has progressed | 4 |
| conflict | The feature is currently being implemented by other pull requests or in another branch | 5 |
| superseded | A new pull request solves the problem better | 18 |
| duplicate | The functionality was in the project prior to the submission of the pull request | 2 |
| superfluous | The pull request does not solve an existing problem or add a feature needed by the project | 6 |
| deferred | The proposed change is delayed for further investigation in the future | 8 |
| process | The pull request does not follow the correct project conventions for sending and handling pull requests | 9 |
| tests | Tests failed to run. | 1 |
| incorrect implementation | The implementation of the feature is incorrect, is missing, or does not follow project standards. | 13 |
| merged | The pull request was identified as merged by the human examiner | 19 |
| unknown | The pull request could not be classified owing to lacking information | 15 |
The results show that there is no clearly outstanding reason for rejecting code under review. However, if we group together close reasons that have a timing dimension (obsolete, conflict, superseded), we see that 27% of unmerged pull requests are closed because of concurrent modifications of the code in project branches. Another 16% (superfluous, duplicate, deferred) are closed as a result of the contributor not having identified the direction of the project correctly and therefore submitting uninteresting changes. Ten percent of the contributions are rejected for reasons that have to do with project process and quality requirements (process, tests); this may be an indicator of processes not being communicated well enough or a rigorous code reviewing process. Finally, 13% of the contributions are rejected because the code review revealed an error in the implementation.
Only 13% of the contributions are rejected for technical issues, which are the primary reason for code reviewing, while 53% are rejected for reasons having to do with the distributed nature of modern code reviews or the way projects handle communication of project goals and practices. Moreover, for 15% of the pull requests, the human examiners could not identify the cause of not integrating them. The latter is indicative of the fact that even in-depth, manual analysis can yield less than optimal results.
9.7 Conclusion
We have used our previous work to illustrate how qualitative and quantitative methods can be combined to understand code review [3, 5, 6, 9]. We have summarized the types of code review and presented a metamodel of the different measures that can be extracted. We illustrated qualitative methods in Section 9.5 by describing how Rigby and Storey [3] used grounded theory to understand how OSS developers interact and manage to effectively conduct reviews on large mailing lists. We then contrasted this method with the card sorting and affinity diagramming used by Bacchelli and Bird [6] to investigate the motivations and requirements of interviewed managers and developers with regard to the code review tool and processes used at Microsoft.
To provide an illustration of a mixed methods study, we presented new findings that contrast multicommit reviews with single-commits reviews. In Section 9.4 we presented quantitative results. While no clear quantitative pattern emerges when we make comparisons across projects or types of review (i.e., Gerrit, GitHub, and e-mail-based review), we find that even though multicommit reviews take longer and involve more code than single-commit reviews, multicommit reviews have the same number of reviewers per review. We triangulated our quantitative findings by manually examining how multicommit reviews are conducted (see Sections 9.6.2 and 9.6.3). For Linux, we found that multicommit reviews involve patchsets, which are reviews of branches. For Android and Chrome, multicommit reviews are reviews of revisions of single commits. For the GitHub projects, Rails, WildFly, and Katello, there is a mix of branch reviews and revisions of commits during review. As a final contribution, we presented new qualitative and quantitative results on why reviews on GitHub pull requests are rejected (Section 9.6.4).