
Boa
An Enabling Language and Infrastructure for Ultra-Large-Scale MSR Studies
Robert Dyer*; Hoan Nguyen†; Hridesh Rajan‡; Tien Nguyen† * Department of Computer Science, Bowling Green State University, Bowling Green, OH, USA
† Department of Electrical and Computer Engineering, Iowa State University, Ames, IA, USA
‡ Department of Computer Science, Iowa State University, Ames, IA, USA
Abstract
Mining software repositories (MSR) on a large scale is important for more generalizable research results. Large collections of software artifacts are openly available (e.g., SourceForge has more than 350,000 projects, GitHub has more than 10 million projects, and Google Code has more than 250,000 projects), but capitalizing on this data is extremely difficult. This chapter serves as a reference guide for Boa, a language and infrastructure designed to decrease the barrier to entry for ultra-large-scale MSR studies. Boa consists of a domain-specific language, its compiler, a dataset that contains almost 700,000 open source projects as of this writing, a back end based on MapReduce to effectively analyze this dataset, and a Web-based front end for writing MSR programs. This chapter describes how researchers and software practitioners can start using this resource.
20.1 Objectives
Mining software repositories (MSR) on a large scale is important for more generalizable research results. Therefore, a number of recent studies in the MSR area have been conducted using corpus sizes that are much larger than the corpus size used by studies in the previous decade [1–15]. Such a large collection of software artifacts is openly available for analysis—for example, SourceForge has more than 350,000 projects, GitHub has more than 10 million projects, and Google Code has more than 250,000 projects. This is an enormous collection of software and information about software.
It is extremely difficult to capitalize on this vast amount of information to conduct MSR studies. Specifically, setting up ultra-large-scale MSR studies is challenging because they simultaneously require expertise in programmatically accessing version control systems, data storage and retrieval, data mining, and parallelization. These four requirements significantly increase the cost of scientific research in this area. Last but not least, building analysis infrastructure to process such ultra-large-scale data efficiently can be very difficult. We believe that for beginning practitioners or for practitioners with insufficient resources these obstacles can be a deal breaker.
This chapter describes Boa [16], an infrastructure that is designed to decrease the barrier to entry for ultra-large-scale MSR studies. Boa consists of a domain-specific language, its compiler, a dataset that contains almost 700,000 open source projects as of this writing, a back end based on MapReduce to effectively analyze this dataset, and a Web-based front end for writing MSR programs. While previous work has focused on Boa as a research result [16], this chapter serves as a reference guide for Boa and focuses on how researchers and software practitioners could start using this resource.
20.2 Getting Started with Boa
Before attempting to solve real mining tasks with Boa, one must understand what is happening behind the scenes. In this section we describe Boa’s architecture.
20.2.1 Boa’s Architecture
Even though Boa provides a very large dataset with almost 700,000 projects in it and users write queries that look sequential, Boa’s architecture efficiently executes those queries transparently to the user. Figure 20.1 gives an overview of Boa’s architecture.

At the back end, Boa clones the data from the source code repository, such as SourceForge. It then translates the data into a custom format necessary for efficient querying. The translated data is then stored as a cache on Boa’s cluster of servers. This forms the data infrastructure for Boa and abstracts many of the details of how to find, store, update, and query such a large volume of data.
Users interact with Boa via its Web interface. Users submit a query written in Boa’s domain-specific query language to the website. The servers then compile that query and translate it into a Hadoop [17] MapReduce [18] program. This program is then deployed onto the cluster and executes in a highly parallel, distributed manner. All of this is transparent to the users. Once the query finishes executing, the output of the program is made available via the Web interface.
As an example, Figure 20.2 shows a simple Boa program that counts the number of projects that use Java. First we declare an output variable named count (line 2). This output uses the aggregation function sum, which produces the arithmetic sum of each integer value emitted to it. The program takes as input a single project (line 3). It then looks at the metadata for that project, examining the declared programming languages (line 4) to see if at least one of those is Java. If there exists a value matching that condition, it outputs a value 1 (line 2) to indicate one project was found that uses Java.

Figure 20.3 shows the semantic model of how this program executes. Our input dataset consists of all projects on SourceForge. The Boa program is instantiated once for each of these projects, which are given as input. If the dataset has 700,000 projects, then (logically) there are 700,000 instances of the program running on our cluster. Each instance of the program then analyzes a single project, in isolation. When an instance finds the project it is analyzing uses Java as a programming language, it sends the value 1 to the output variable.

Each output variable can be thought of as its own separate process. Sending values is similar to a message send between processes. After all the input processes finish, the output process has a list of values (in this case, a bunch of 1s). It then aggregates the data by summing the values and producing the final output. The final output is the name of the output variable and its result.
20.2.2 Submitting a Task
Boa queries are submitted via the Web interface [19] (see Figure 20.4). The interface provides standard integrated development environment features such as syntax highlighting and code completion. Additionally, there are many example queries across several domains provided which are easily accessible from a drop-down box above the query editor.
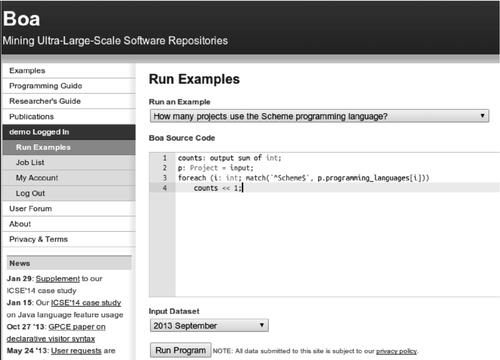
Once a user has written the query, the user selects the dataset to use as input. Boa provides snapshots of the input data, marked with the timestamp of when the snapshot was taken. Boa periodically produces these datasets (at least yearly, in the future perhaps even monthly). Once a dataset has been created, it will never change. This enables researchers to easily reproduce previous research results, by simply providing the same query and selecting the same input dataset.
When the query is submitted, Boa creates a job (see Figure 20.5). All jobs have a unique identifier and allow you to control them, such as stopping the job, resubmitting the job, and viewing the results of the job. The job page will show if compilation succeeded and any error messages. It will also show the status of executing the query. Once execution has finished, it provides information about how long execution took and links for viewing and downloading the output.

20.2.3 Obtaining the Results
Once a job has finished without error, the output of the Boa program is available from the job’s page. There are two options: users may view up to the first 64 kB of the output online (see Figure 20.6) or they may download the results as a text file.

20.3 Boa’s Syntax and Semantics
In this section we describe Boa’s syntax and semantics. Boa’s syntax is inspired by Sawzall [20], a procedural programming language designed by Google for processing large numbers of logs. Despite looking sequential, Boa programs are translated into MapReduce [18] programs, and thus run in a parallel, distributed manner. The language abstracts away many of the details of this framework. Most of a Boa program is actually the map phase, which takes a single project as input, processes it, and outputs the results. Users describe the output of a Boa program and select from a set of predefined aggregators, which acts like the reduce phase. In the remainder of this section we describe Boa’s language features in more detail.
20.3.1 Basic and Compound Types
Boa provides several built-in types. The first set of types are the basic types available in the language, and they are shown in Table 20.1. These include many standard types such as boolean values, strings, integers, and floats.
Table 20.1
Basic Types Provided by Boa
| Type | Description |
| bool | Boolean values (true, false) |
| string | Array of Unicode characters |
| int | 64-bit signed integer values |
| float | 64-bit IEEE floating point values |
| time | Unix-like timestamp, unsigned integer representing number |
| of microseconds since 00:00:00 UTC 1 January 1970 |
Boa also provides a type called time to represent Unix-like timestamps. All date/time values are represented using this type. There are many built-in functions for working with time values, including obtaining specific date-related parts (such as day of the month, month, year, etc.), adding to the time by day, month, year, etc., and truncating to specific granularities.
Strings in Boa are arrays of Unicode characters. Strings can be indexed to retrieve single characters. Strings can be concatenated together using the plus (+) operator. There are also many built-in functions for working with strings to uppercase/lowercase them, get substrings, match them against regular expressions, etc.
Boa also provides several compound types, which are shown in Table 20.2. These types include arrays, maps, stacks, and sets, and are composed of elements of basic type.
Table 20.2
Compound Types Provided by Boa
| Type | Example uses |
| array of basic_type | a: array of int = {0, 2}; # initialize |
| a = new(a, 10, 0); # initialize | |
| a[0] = 1; # assignment | |
| a = a + a; # concatenation | |
| i = len(a); # size of array | |
| map[basic_type] of basic_type | m: map[string] of int; # declare |
| m["k"] = 0; # assignment | |
| remove(m, "k"); # remove an entry | |
| b = haskey(m, k); # test for key | |
| ks = keys(m); # array of keys | |
| vs = values(m); # array of values | |
| clear(m); # clear map | |
| i = len(m); # number of entries | |
| stack of basic_type | st: stack of int; # declare |
| push(st, 1); # push value | |
| i = pop(st); # pop stack | |
| clear(st); # clear stack | |
| i = len(st); # number of values | |
| set of basic_type | s: set of int; # declare |
| add(s, 1); # add value to set | |
| remove(s, 1); # remove value | |
| b = contains(s, 1); # test for value | |
| clear(s); # clear set | |
| i = len(s); # number of values |
Arrays can be initialized to a set of comma-delimited values surrounded by curly braces. They can also be initialized to a fixed size using the new() function, which initializes all entries to a given value. Individual elements in the array can be indexed for both reading and assigning values. Array indexing is 0-based. Arrays can also be concatenated together using the plus (+) operator. The size of the array can be retrieved (using the function len(a)).
Maps provide simple map functionality, based on hashing functions. Maps are initially created empty, and can also be cleared (using the clear(m) function). Assigning values can be accomplished with an assignment operator (=) with an index into the map on the left-hand side and the value on the right-hand side. Entries can also be removed from a map (using the remove(m, k) function). The keys in the map can be retrieved as an array (using the keys(m) function). Similarly, the values in the map can be retrieved as an array (using the values(m) function). The number of entries in the map can also be retrieved (len(m)).
Stacks of values can be maintained using a stack type. Stacks are initially empty. Values can be pushed onto the stack (push(st, v)) and popped off the stack (pop(st)). Stacks can also be cleared (clear(st)). The number of elements on the stack can also be retrieved (len(st)).
Finally, sets of unique values are created using a set type. Values can be added (add(s, v)) or removed from sets (remove(s, v)), and the set can be queried to check for their existence (contains(s, v)). Sets may also be cleared (clear(s)). The number of unique values in the set can also be retrieved (len(s)).
20.3.2 Output Aggregation
As previously mentioned, Boa provides a notion of output variables. Output variables declare an output aggregation function to use on the output. A list of available aggregation functions is given in Table 20.3.
Table 20.3
Output Aggregators Provided by Boa
| Aggregator | Description |
| collection [indices] of T | |
| A collection of data points. No aggregation is performed. | |
| Example: output collection[string] of string | |
| set (param) [indices] of T | |
| A set of the data, of type T. If param is specified, the set | |
| will contain at most the first param sorted elements. | |
| Example: output set(5) of int # limit to first 5 elements | |
| Example: output set of int | |
| sum [indices] of T | |
| An arithmetic sum of the data, of type T. | |
| Example: output sum[string][time] of int | |
| mean [indices] of T | |
| An arithmetic mean of the data, of type T. | |
| Example: output mean of int | |
| bottom (param) [indices] of T | |
| A statistical sampling that records the bottom param | |
| number of elements of type T. | |
| bottom (param) [indices] of T weight T2 | |
| Similar, but groups items of type T and uses their | |
| combined weight for selecting elements. | |
| Example: output bottom(10) of string weight int | |
| top (param) [indices] of T | |
| A statistical sampling that records the top param number | |
| of elements of type T. | |
| top (param) [indices] of T weight T2 | |
| Similar, but groups items of type T and uses their | |
| combined weight for selecting elements. | |
| Example: output top(10) of string weight int | |
| minimum (param) [indices] of T weight T2 | |
| A precise sample of the param lowest weighted elements, | |
| of type T. Unlike bottom, does not group items. | |
| Example: output minimum(10) of string weight int | |
| maximum (param) [indices] of T weight T2 | |
| A precise sample of the param highest weighted elements, | |
| of type T. Unlike top, does not group items. | |
| Example: output maximum(10) of string weight int | |

All aggregators can optionally take indices. Indices act as grouping operators. All output is sorted and grouped by the same index. Then the aggregation function is applied to each group. It is also possible to have multiple indices, in which case the grouping is performed from left to right.
The collection aggregator provides a way to simply collect some output without applying any aggregation to the values. Any value emitted to this aggregator will appear directly in the results.
The set aggregator is similar, but will output a value only once. Thus, if you emit the value “1” 50 times, it will appear only once in the output.
The sum aggregator takes values and computes their arithmetic sum. The param defines the maximum number of elements allowed in the set. If no param is given, the set can be of any size. The mean aggregator computes the statistical mean of the values.
The top/bottom aggregators produce at most param values in the output. The aggregators group all values together and for each value compute the total weight. Then the values are sorted on the basis of their weight and the aggregator outputs the top or bottom param values. If no weight values are given, a default weight of 1 is used.
So, for example, if the values and weights sent to the aggregator are
then the aggregator would see the following sorted list
and would select the top/bottom param values from that list.
The minimum/maximum seem similar to top/bottom; however, these aggregators do not compute the total weight. Instead they consider every value individually and pick the top/bottom values on the basis of their individual weights. So while a value can appear only once in the output of top/bottom, with minimum/maximum it can appear more than once. Consider the previous list. For these aggregators they would see the following sorted list
and would select the first/last param elements from this list. So while top(3) would have "foo" appearing only once, maximum(3) would contain "foo" twice.
20.3.3 Expressing Loops with Quantifiers
A lot of the data in Boa is represented in arrays. Being able to easily loop over this data is important for many mining tasks. To ease dealing with looping over data, Boa provides three quantifier statements: foreach, exists, and ifall. Quantifiers are simply a sugar, but are useful in many tasks. This sugared form makes programs much easier to write and comprehend.
All quantifiers expect a variable declaration (usually an integer type) with no initializer, a boolean condition, and a statement. The foreach quantifier executes the statement for each value of the quantifier variable where the condition holds. The quantifier variable is available and bound inside the statement. For example,
runs the body for each programming language the project declares whose name starts with the string ‘java’.
The exists quantifier is different, in that it will execute the statement at most once if and only if there exists (at least) one value of the quantifier variable where the condition holds. If the statement executes, the quantifier variable will be bound to the first occurrence where the condition held. For example,
runs the body once if at least one programming language the project declares has a name starting with the string ‘java’. In this case, the value of i will be bound to the first match.
Finally, the ifall quantifier also executes the statement at most once if and only if for all values of the quantifier variable the condition holds. In this case, the quantifier variable is not available inside the statement. For example,
runs the body once if there are no programming languages the project declares with a name starting with the string ‘java’. In this case, the value of i is not available in the body.
20.3.4 User-Defined Functions
The Boa language allows users to write their own functions directly in the query program. This gives users the ability to customize the built-in functions or expand the framework by writing their own mining functions. This is critical for the usability of the framework since different users might have different needs, want different values for the parameters of an algorithm, or even would like an algorithm or algorithms which have not yet been provided by the framework.
The basic syntax for defining a function is as follows:
which gives the name id to the function, defines zero or more named arguments, has an optional return type, and defines the body of the function. Note that the syntax is actually a variable declaration with an initialization—this means the semicolon after the closing brace is required!
Since functions are just variables with a function type, they may be passed into other functions as an argument or even assigned to multiple variables, assuming the function types are identical. For example, we could write a function to find the maximum int value in an array of integers:
which accepts an array and a comparator function. We could then call this function by passing in a custom comparator (in this case, it is an anonymous function):
which performs the standard comparison between two integers.
20.4 Mining Project and Repository Metadata
The dataset provided by Boa contains metadata on projects and source code repositories. This section presents our domain-specific types for the metadata and some examples demonstrating how to use them to query the projects and code repositories.
20.4.1 Types for Mining Software Repositories
The Boa language provides five domain-specific types for mining project and repository metadata. Table 20.4 shows these five types. Each type provides several attributes that can be thought of as read-only fields. The types form a tree, which is rooted at the Project type. This type serves as the input to a Boa program.
Table 20.4
Types Provided by Boa for Project and Repository Metadata
| Type | Attributes |
| Project | id: string |
| name: string | |
| created_date: time | |
| code_repositories: array of CodeRepository | |
| audiences: array of string | |
| databases: array of string | |
| description: string | |
| developers: array of Person | |
| donations: bool | |
| homepage_url: string | |
| interfaces: array of string | |
| licenses: array of string | |
| maintainers: array of Person | |
| operating_systems: array of string | |
| programming_languages: array of string | |
| project_url: string | |
| topics: array of string | |
| Person | username: string |
| real_name: string | |
| email: string | |
| CodeRepository | url: string |
| kind: RepositoryKind | |
| revisions: array of Revision | |
| Revision | id: int |
| log: string | |
| committer: Person | |
| commit_date: time | |
| files: array of ChangedFile | |
| ChangedFile | name: string |
| kind: FileKind | |
| change: ChangeKind |
The Project type contains metadata about a project in the code corpus. Its attributes include the project’s name, homepage url, a description of the project, information about its maintainers and developers, and a list of code_repositories. See Table 20.4 for all possible attributes. Depending on which repository the project came from, some of these attributes might be undefined.
The Person type represents a user on the repository. This includes project maintainers, developers, and committers. It contains their username in the repository, their real_name, and their email address.
The CodeRepository type provides metadata about a code repository of a project. It contains the url of the repository, the kind of version control system (e.g., Subversion (SVN), Git), and a list of all revisions which have been committed.
Each revision has the type Revision, which contains the unique revision id, the log message attached to the commit, the commit_date, information about the author of the commit as well as the actual committer (which are often the same person, and in SVN are always the same person), and the list of files changed in that revision.
All changed files are represented by the ChangedFile type, which contains the file’s name (the relative path to the file in the repository), the file’s kind (e.g., Java source file, C source file, binary file), and the kind of change performed on the file (e.g., added, deleted, or modified). The contents of source files that parse without error are available, while the contents of other files are not (for space reasons). In the future, Boa may contain file contents for other file types other than source code.
20.4.2 Example 1: Mining Top 10 Programming Languages
Some example questions which could be asked about programming languages are as follows: Which ones are the most popular? What has been the trend of using languages in the last few years? The answers would be useful for many people, from beginners who are choosing between dozens of programming languages to language designers who would like to improve their language(s). Figure 20.7 shows an example of a Boa program which could answer such a question.

This simple program contains only three lines of code. Similarly to the example in Figure 20.2, this program contains a declaration for the output (line 2). However, it uses a different aggregation function, top, to get the 10 languages which are used the most in our database. The output is a ranked list of 10 string elements based on their weights of type integer. The program runs on each input project (line 3). Note that this time we do not give a name to the input, and we just use it directly. For each programming language used in the project, it emits the language name and a weight of 1 to the output (lines 3-4). The aggregator collects those language names and increases their weights accordingly in the variable counts. The final outcome is a decreasingly ranked list of 10 language names having the highest weights.
From this simple starting Boa program, you could run the same program on different datasets for different years in the past to see the trend of language uses. You could also customize it to query a lot of different information about programming languages. For example, you could use different weight values for different criteria on usage popularity. You could use the amount of code written in a language to measure the popularity by replacing the weight value 1 by the number of lines of code written in that language. Or if you wish to study the relation between programming languages and the topic of the project, you could easily modify this program to compute the top k most popular pairs between topics and languages:
20.4.3 Intrinsic Functions
Besides the standard built-in functions as in Sawzall, Boa also provides several intrinsic functions for certain common tasks that involve processing the project and code repository metadata. This section will introduce two of those functions.
The first function is hasfiletype, which receives two arguments: a revision from some repository and a string containing a file extension. This function returns a boolean value which is true if the revision contains a changed file that has the given extension in its name and which is false otherwise. It uses pattern matching to check if there is a file name that ends with the given extension (line 2). This function could be useful for queries that are interested in the revisions which contain source code files written in certain programming languages, such as C, C++, Java, and C#, or in an certain format, such as comma-separated values, XML, or text.
The second intrinsic function is isfixingrevision, which also works on the metadata of the repository. This function receives a Revision or a string, which is the content of a commit log message, and determines if it is the log of a bug fixing revision or not. It figures that out by using pattern matching to check if the log message contains certain keywords indicating bug-fixing activities (lines 2-3). In this implementation, we consider the words fix, error, bug, and issue, and some of their variations as indicators of fixing bugs. Users who would like to use different sets of keywords or even different approaches could define custom functions in their query Boa code to achieve their goal, such as in the program shown in Figure 20.8 for the example in the next section.

20.4.4 Example 2: Mining Revisions that Fix Bugs
Developers evolve software projects by committing changes to their repositories. Among them are the changes that fix bugs in the source code. Researchers have been studying those bug-fixing changes to improve the quality of software and software development. For example, one would like to characterize the buggy code (before the fix) and train a classifier to predict buggy code in future commits. Other work might learn from the bug fixes in the past to automatically derive patches for similar bugs in the future. Others might model the trend of bug appearance in the previous development cycles to plan for the next cycles.
One core task of these works is identifying the bug-fixing revisions from the history. Figure 20.8 shows an example of a Boa program for doing this task. For an input project, the program accesses each repository (line 8) and checks each revision of that repository for if it could have fixed a bug or not by calling the function IsFixingRev to examine its commit log message (line 9). IsFixingRev is a user-defined function declared on lines 3-7. This function matches the given log message with certain patterns (lines 4-5). If there is a match, it considers the revision to be a bug-fixing revision. This program does not use the built-in function isfixingrevision, which has a similar purpose, because we wanted slightly different patterns for the matching.
20.4.5 Example 3: Computing Project Churn Rates
The final example of mining project and repository metadata is a query about the changed files in SVN repositories. It computes the churn rate, which we define as the average number of changed files per revision, in each project using SVN. The Boa program for this query is shown in Figure 20.9.

For each input project, the query accesses the SVN repository (if any) (line 3) and iterates all revisions (line 4). For each revision, the number of changed files is emitted to the output (line 5). The output is indexed by the project’s id, meaning that the values will be grouped by each project. The output variable uses the mean aggregator and computes the mean of all values for each project, giving us our final answer.
20.5 Mining Source Code with Visitors
Expressing source code mining tasks can be very challenging. Boa attempts to make this easier with custom syntax inspired by object-oriented visitor patterns.
20.5.1 Types for Mining Source Code
Previously we introduced the five types available for mining project and code repository metadata. In this section we introduce nine more types for mining source code data. These types are shown in Tables 20.5-20.7.
Table 20.5
Types Provided by Boa for Source Code Mining
| Type | Attributes |
| ASTRoot | imports: array of string |
| namespaces: array of Namespace | |
| Namespace | name: string |
| declarations: array of Declaration | |
| modifiers: array of Modifier | |
| Declaration | name: string |
| parents: array of Type | |
| kind: TypeKind | |
| modifiers: array of Modifier | |
| generic_parameters: array of Type | |
| fields: array of Variable | |
| methods: array of Method | |
| nested_declarations: array of Declaration | |
| Type | name: string |
| kind: TypeKind | |
| Modifier | kind: ModifierKind |
| visibility: Visibility | |
| other: string | |
| annotation_name: string | |
| annotation_members: array of string | |
| annotation_values: array of Expression |
Table 20.6
Method and Variable Types Provided by Boa for Source Code Mining
| Type | Attributes |
| Method | name: string |
| modifiers: array of Modifier | |
| arguments: array of Variable | |
| exception_types: array of Type | |
| return_type: Type | |
| generic_parameters: array of Type | |
| statements: array of Statement | |
| Variable | name: string |
| modifiers: array of Modifier | |
| variable_type: Type | |
| initializer: Expression |
Table 20.7
Statement and Expression Types Provided by Boa for Source Code Mining
| Type | Attributes |
| Statement | kind: StatementKind |
| condition: Expression | |
| expression: Expression | |
| initializations: array of Expression | |
| statements: array of Statement | |
| type_declaration: Declaration | |
| updates: array of Expression | |
| variable_declaration: Variable | |
| Expression | kind: ExpressionKind |
| annotation: Modifier | |
| anon_declaration: Declaration | |
| expressions: array of Expression | |
| generic_parameters: array of Type | |
| is_postfix: bool | |
| literal: string | |
| method: string | |
| method_args: array of Expression | |
| new_type: Expression | |
| variable: string | |
| variable_decls: array of Variable |
For any ChangedFile representing a source file, the parsed representation of that source code is provided as a custom abstract syntax tree (AST). As of August 2015, only Java source code is supported, although support for more languages is planned. The root of a source file’s AST is the type ASTRoot. This type contains information about any types or modules imported as well as any namespaces contained in the file. The ASTRoot of a file can be accessed by calling the intrinsic function getast(), described in detail later.
A Namespace is similar to a package in Java. Namespaces have a name and optional Modifiers, and contain declarations. A Declaration represents the declaration for types, and can be a class, interface, enum, annotation, etc. A Type represents a type symbol in the source file. The type’s name is exactly as it appears in the source text at that location in the source, which means it may or may not be fully qualified.
Declarations have Method and Variabletypes (fields), which are shown in Table 20.6. These types are self-explanatory.
Finally, Boa provides Statement and Expression types as shown in Table 20.7. When we created these nine types, we had several goals in mind. First, we wanted to keep the total number of types as small as possible to make them easier for users to remember. Second, we wanted them to be flexible enough to support most object-oriented languages. Third, we wanted them to be extensible so we can add support for other languages over time.
Because of these goals, the Statement and Expression types are union types. This means that instead of having almost 50 different types, one for each kind of expression, we have a single unified type. The types have an attribute named kind to indicate what kind of statement or expression they are. Depending on the value of that attribute, other attributes will have values.
For example, a for statement in Java such as
would be represented as follows:
The variable_declaration, type_declaration, and condition attributes are undefined. A different language feature, such as Java’s enhanced-for loop, could still use this same type. For example, consider the Java code
which would be represented as follows:
The remaining attributes are undefined. A mining task can easily distinguish between the two statements by noticing if variable_declaration is defined.
20.5.2 Intrinsic Functions
Boa provides several domain-specific functions for dealing with source code. In this section we outline some of those.
The first function is getast():
This takes a ChangedFile and returns the ASTRoot for that revision of that file. If a file has no AST, then the function returns an empty ASTRoot.
The getsnapshot() function
returns a view in time of the code repository. These views, called snapshots, are all the files that existed at that point in time. The function also accepts an array of strings, which are used to filter files of a specific kind. The filtering is done on the basis of matching the string to the start of each file’s kind. For example, FileKind contains SOURce:JAVA_ERROR (for Java source files that do not parse), SOURce:JAVA_JLS2 (for Java 1.4), SOURce:JAVA_JLS3 (for Java 5), etc. If you pass in "SOURce:JAVA" it will retain all Java source files, even ones that do not parse. However if you pass in "SOURce:JAVA_JLS" it will retain only Java source files that parsed without any errors. The last two arguments are optional and if not provided will default to the current time and include all files.
isliteral() is a useful function while mining source code that needs to know if an expression is a specific literal (e.g., null)
that tests an expression to see if it is of kind literal and if it is, if the literal string matches the one provided. This is a commonly occurring pattern so we provide it as a reusable function.
20.5.3 Visitor Syntax
Boa also provides language features for easily mining source code. The syntax is inspired by object-oriented visitor patterns [21]. Since all data for a project is represented as a tree, visitors allow easy traversal of the structure of that tree and easily specifying actions while visiting nodes of specific types.
The general syntax for defining a visitor is
which declares a new visitor and gives it a name id. Visitors have one or more visit clauses, which can be either a before visit or an after visit. While traversing the tree, if a node has a type T, any matching before and after clauses will execute their statements. The before clause executes immediately on visiting the node and before visiting the node’s children. The after clause executes after visiting the node’s children. By default, visitors provide a depth-first traversal strategy. Visitors also automatically call getast() when visiting a ChangedFile, thus ensuring the source code nodes are visited.
To begin a visit, simply call the visit() function
and provide the starting node (which is typically just the input) and provide which visitor to use. Note that visitors can be anonymous as most of our examples will show.
There are three ways for a visit statement to match the type. The first form
matches exactly one type and (optionally) gives it a name. If a name is provided, then attributes in the type are accessible in the body. The second form
is a list of types. This clause will execute when the node being visited is of any type listed. This allows easily sharing functionality in visitors. The last form
is a wildcard. The wildcard acts as a default visit. When visiting a type, if there is no matching clause in the visitor and a wildcard is provided, the wildcard executes.
20.5.4 Example 4: Mining AST Count
Now consider a simple example to illustrate how this syntax works. Consider a mining task to find the number of AST nodes for every project in the corpus. A solution to this task is shown in Figure 20.10.

First we declare our output, which we name AstCount (line 2). The output expects values of type integer. It contains an index of type string, so we can group the values by project, and will sum the values together.
Next we declare a visitor (lines 3-8). We start the visit at the input (line 3) and use the anonymous visitor we declared. This visitor contains two clauses.
The first clause (line 5) provides our default behavior. By default we want to count nodes as we visit them. So as we visit each node, we send a value of 1 to the output variable, giving the current project’s id as the index.
The second clause (line 7) handles special cases. Since we are interested only in counting AST nodes, we list the non-AST node types and provide overriding behavior. In this case, we simply do nothing, as we wish to not count these node types.
This completes our mining task. The result of running this query will be a list of project ids and the total number of AST nodes for that project.
20.5.5 Custom Traversal Strategies
Visitors provide a default depth-first traversal strategy. This works well for many, but not all, source code mining tasks. For example, to collect all the fields of a class, a visitor would have to visit the Variable type; however, this type is also used for local variables. Thus, a custom traversal strategy is needed to ensure only the fields are visited. For such cases where the default traversal strategy will not work, Boa also provides syntax to easily allow you to specify your own traversals.
First, Boa has syntax for manually traversing a subtree rooted at any node:
which is similar to a normal visit call, but omits the second argument as the current visitor is implied. You may of course provide a different visitor as well as the second argument. This syntax allows you to manually visit any child nodes, in any order, as many times as you wish.
The second piece of syntax is the stop statement:
which says the current traversal should stop at that point. These statements act similarly to a return inside a function, so no code may appear after them. Stop statements are useful (and allowed) only for before visits, since an after visit has already traversed the children of that node.
A useful example of a custom traversal strategy is for traversing the current snapshot of the source code. This is useful for any mining task that does not need to analyze the history of the source and instead is interested only in the current state.
This pattern (shown in Figure 20.11) provides a before visit for all code repositories. Inside the body, we use the getsnapshot() intrinsic function to retrieve the latest snapshot of the code provided in the code repository (which we named n). Once we have the snapshot (which we store in a local variable named snapshot), we manually visit each of the ChangedFiles and then stop the default traversal.

20.5.6 Example 5: Mining for Added Null Checks
Now let us consider a more complex example. Consider a mining task that finds how many null checks were added to source code. A null check is an if statement containing either an equals or not-equals conditional check where one of the arguments is a null literal. A solution to this task is shown in Figure 20.12.

This solution needs one output variable, named AddedNullChecks, which will expect values of type integer and output their arithmetic sum. This will be the total count of all null checks added.
The first part of the solution is to write a visitor that looks for null checks (lines 3-11). This code creates a global variable nullChecks to keep track of how many null checks it found. The visitor (lines 6-11) looks for any expression that is an (in)equality conditional operator (== or !=) where either operand is a null literal. It makes use of the isliteral() function described previously.
The second part of the solution requires finding changed files, counting how many null checks are in the file ,and if the number of checks increased. A map is used (line 12) to track the last count for each file. The map is initialized at the start of each code repository (line 14) and is updated after each changed file has been visited (line 20). Since we update the map at the end of the visit clause, newly added files will not be in the map when we check for increased null checks (line 18).
The visitor looks for if statements (line 23) and on finding one, calls the null check visitor previously defined. Thus, we will look only for null checks that are in the condition of an if statement.
Finally, before visiting a changed file, we reset the null check counter (line 15). After visiting a changed file, we see if the number of null checks has increased (line 18), and if it has, we output this fact.
20.5.7 Example 6: Finding Unreachable Code
The final example we show is a standard static analysis technique to detect unreachable statements. Many compilers detect (and eliminate) unreachable code. Java’s compiler actually considers many unreachable statements to be a compilation error. This task answers the question: Are there existing files with unreachable statements? A solution to this task is shown in Figure 20.13.

This example needs one output variable, named DEAD, which will expect string values and simply show all of them in the output. The idea is to first find unreachable statements, and then output a path for the method containing such statements. So there is no need for aggregation here, we simply collect all results as is.
Next we need a variable and code to store the name of the current file being analyzed (lines 3 and 8). We also need a variable to track the name of the current method (lines 4 and 10). These variables are used when we find unreachable statements and need to output that fact (line 15).
The analysis needs a variable to track if we consider the current statement to be alive (line 5), which we initialize to true on entering a method (line 12). Since methods can actually be nested inside each other, we also need a stack (line 6), which we update by pushing and popping the alive variable when we enter and leave a method (lines 11 and 16).
Finally, we are ready to find statements that stop the flow of execution and require our setting the alive variable to false (lines 20-24). These are things such as return statements, throw statements, and break and continue (for loops).
Since we do not want our analysis to produce false positives (at the cost of possibly missing some unreachable statements, aka false negatives), we need to consider special cases for a few things. First, break and continue may have labels and thus might not actually create dead code after them. For these we just assume if there is a label the following statements are still alive (line 21).
Second, if blocks and labeled blocks can create problems with the analysis, we avoid analyzing their bodies (line 25).
Finally, for other statements with blocks we have to have special handling (lines 26-33). Since we do not know for certain these blocks will execute, in general we ignore the results of analyzing their bodies. However, we do want to visit the bodies in case there are nested methods inside them, which may themselves have unreachable statements.
20.6 Guidelines for Replicable Research
One of the main principles of the scientific method is being able to confirm or replicate prior research results. However, exactly replicating previous research results is often difficult or impossible. There are many reasons why: the raw dataset is not clearly defined in the paper, the processed dataset is not available, the tools and infrastructure used are not available, the mining task itself is ambiguous in the paper, etc. One of the main goals of Boa is to solve this problem. In this section, we give researchers using Boa guidance so that their work may be replicable by others.
The first step in this process is handled by Boa’s administrators. Boa provides timestamp-marked datasets for querying. These datasets, once published on the Boa website, will not change over time and will continue to be made available for researchers. This means other researchers will have access to the actual data used in your studies.
The second step is up to each individual researcher. For their research to be replicated, the program(s) used to query these fixed datasets must also be made available to other researchers. This can be accomplished in one of two ways:
(1) Researchers can publish the Boa program(s) and the dataset used for their research in a research publication. They can then make the results of the program(s) available on a website.
(2) Researchers can use the Boa website to publish the program(s), the dataset used, and the results of the program(s). They can then provide a link to this archive in their research publication(s).
The second method is preferred, as the public Boa archival page will contain all information, including the original source code, the execution date/time, the input dataset used, and the output of the program. In the rest of this section, we describe how to generate a Boa archival link for a job.
The first step is to view each Boa job used in the research project. Toward the top of the job page, there is text indicating if the job is PRIVATE or PUBLIC. To share the job, it must be marked PUBLIC. If it lists the job as PRIVATE, a link is provided to make it PUBLIC.
Now the job should be marked as a PUBLIC job. There is also a new link to view the public page. This is the URL for the archival page for this job. Click that link and verify the information matches what was used in your study.
The page you are now viewing is the public archival page for the job. This is the archival page for which you should provide a link in your research publication(s). This page contains all necessary information for replicating your research results, including the original source code, the input dataset used, and the original output of the program.
It is important to note that the necessary information for replicating this result (the program and the input dataset) can never be changed for this job! If you attempt to modify the job, Boa will create a new job and keep the original information intact. This helps avoid accidentally changing previously published results and ensures future researchers have the original information!
20.7 Conclusions
MSR on a large scale is important for more generalizable research results. Large collections of software artifacts are openly available (e.g., SourceForge has more than 350,000 projects, GitHub has more than 10 million projects, Google Code has more than 250,000 projects) but capitalizing on this data is extremely difficult. This chapter is a reference guide to using Boa, a language and infrastructure designed to decrease the barrier to entry for ultra-large-scale MSR studies.
Boa consists of a domain-specific language, its compiler, a dataset that contains almost 700,000 open source projects as of this writing, a back end based on MapReduce to effectively analyze this dataset, and a Web-based front end for writing MSR programs. The Boa language provides many useful features for easily looping over data, writing custom mining functions, and easily mining source code. Boa also aids reproducibility of research results by providing an archive of the data queried, the query itself, and the output of the query.
Currently Boa contains project metadata and source code data for Java source files. It also contains only data from SourceForge. Soon, Boa should support additional data such as issues/bug reports as well as additional sources of data such as GitHub. The goal of Boa is to provide the ability to easily query as many different data sources as possible, by simply using one infrastructure and query language. While this is an ambitious goal, we feel it is obtainable and look forward to the future of mining ultra-large-scale software repositories!
20.8 Practice Problems
In this section we pose several software repository mining tasks. Your job is to write a query in Boa to solve the task. The tasks start easy and get substantially more difficult. Solutions to some of these tasks appear on Boa’s website [19].
Project and Repository Metadata Problems
1. Write a Boa query to find in which year the most projects were created.
2. Write a Boa query to compute the average commit speed of each project.
3. Write a Boa query to find which developer has committed the most changes to each repository.
4. Write a Boa query to find, for each project, who commits changes to only a single file and who commits changes to the largest number of files.
5. Write a Boa query to find who has committed the most changes bug-fixing revisions for each project.
6. Write a Boa query to correlate the projects’ topics and the programming language used.
Source Code Problems
7. Write a Boa query to compute the average number of methods per file in the latest snapshot of each project.
8. Write a Boa query to find, for each project, the top 100 methods that have the most AST nodes.
9. Write a Boa query to find top 10 most imported libraries.
10. Write a Boa query to find top five most used application programming interface methods.
11. Write a Boa query to compute the average number of changed methods/classes per revision for each project.
12. Write a Boa query to find the average number of changes to a class/file, or the average number of changes to a method.
13. Write a Boa query to find the distribution of the number of libraries over projects.
14. Write a Boa query to find the year that JUnit was added to projects the most.
15. Write a Boa query to find the adoption trend of using graphic libraries (AWT, Swing, and SWT) in Java projects.
16. Write a Boa query to find all sets of projects that use the same set of libraries.
17. Write a Boa query to compute how often classes/files are in a bug-fixing revision.
18. Write a Boa query to find which pairs of methods/classes/files are always co-changed in all bug-fixing revisions of a project.
19. Write a Boa query to find all methods that contain an uninitialized variable.
20. Write a Boa query to correlate the developers and the technical terms in the source code that they have touched. The terms are tokens extracted from the classes’ name after tokenization.