
″What a fool believes he sees
No wise man has the power to reason away
What seems to be
Is always better than nothing.″
— ″WHAT A FOOL BELIEVES,″ THE DOOBIE BROTHERS, MINUTE BY MINUTE
(WARNER BROTHERS RECORDS, 1978)
Sitting in a recording studio all day (and most of the night), engineers might easily begin to believe that their music, their art, is the squiggly waveforms drawn on the computer screen before them.
It is important to realize that those signals do not reach humans directly. Humans listen to audio, they don′t plug directly into the computer. Those waveforms on the screen represent signals that can be persuaded to make loudspeakers move, which creates sound waves in the air that travel through the room, around each person′s head, and into his or her ears. The ears ultimately convert that acoustic wave into some stream of neurological pulses that, at last, are realized within the brain as sound. The music is not in the equipment of the recording studio. Music ultimately lives within the mind and heart of the listener, having begun in the minds and hearts of the composers and performers.
The audio engineer has little control over the processing of sound by the human hearing system. Nevertheless, it is a major part of the production chain. This chapter summarizes the critical properties of the human perception of sound, allowing that engineer to make more informed use of the studio equipment that feeds it.
Listening as musicians and music fans, we constantly savor and analyze melody, harmony, rhythm, words, etc. Listening as audio engineers and producers, we critically evaluate the qualities of the audio signal, assessing its technical merit and enjoying the production techniques that likely led to the creation of that particular sound.
Remove these conscious aspects of sound perception and cognition, and we find our minds still do a terrific amount of analysis on incoming sounds.
As you read this, perhaps you hear a bird chirping, a hard disk spinning, some people chatting, or a phone squawking. Without trying, a healthy hearing system will determine the direction each of these sounds is coming from, estimate its distance, and identify the source of the sound itself (Was it animal or machine? Was it mother or sister? Is it my mobile phone or yours?). All of those simple observations are the result of a terrific amount of signal analysis executed by our hearing system without active work from us. It is work done at the preconscious level — when we are first aware of the sound, this additional information arrives with it.
Figure 3.1 summarizes the range of audible sounds for average, healthy human hearing. Audio engineers often quote this range of hearing along the frequency axis, rounded off to the convenient, and somewhat optimistic, limits from 20 Hz to 20,000 Hz.
The bottom curve, labeled ″threshold in quiet,″ identifies the sound pressure level needed at a given frequency to be just audible. Amplitudes below are too quiet to be heard. Amplitudes above this level are, in a quiet environment, reliably detected. This threshold in quiet does not remotely resemble a straight line. Human sensitivity to sound is strongly governed by the frequency content of that sound. The lowest reach on this curve (near about 3,500 Hz) identifies the range of frequencies to which the human hearing system is most sensitive. The sound pressure level at which a 3,500-Hz sine wave becomes audible is demonstrably lower than the sound pressure level needed to detect a low-frequency (e.g., 50 Hz) sine wave or a high-frequency (e.g., 15,000 Hz) sine wave.
As the threshold in quiet makes clear, the sensitivity of human hearing is a highly variable function of frequency. The equal loudness contours of Figure 3.2 refine this point. Each equal loudness curve traces the sound pressure level needed at a given frequency to match the perceived loudness of any other audible frequency on the curve.

![]() Figure 3.1 Hearing area, i.e. area between threshold in quiet and threshold of pain. Also indicated are the areas encompassed by music and speech, and the limit of damage risk. The ordinate scale is not only expressed in sound pressure level but also in sound intensity and sound pressure. The dotted part of threshold in quiet stems from subjects who frequently listen to very loud music.
Figure 3.1 Hearing area, i.e. area between threshold in quiet and threshold of pain. Also indicated are the areas encompassed by music and speech, and the limit of damage risk. The ordinate scale is not only expressed in sound pressure level but also in sound intensity and sound pressure. The dotted part of threshold in quiet stems from subjects who frequently listen to very loud music.
The bottom curve of Figure 3.2 essentially repeats the data of the threshold in quiet shown in Figure 3.1. The third curve up from the bottom is labeled 20. At the middle frequency of 1 kHz, this curve has a sound pressure level of 20 dBSPL. Follow this curve lower and higher in frequency to see the sound pressure level needed at any other frequency to match the loudness of a 1-kHz sine wave at 20 dBSPL. All points on this curve will have the same perceived loudness as a 1-kHz sine wave at 20 dBSPL. Accordingly, sounds falling on this curve are all said to have a loudness of 20 phons, equivalent to the loudness of the 20-dBSPL pure sine wave at 1,000 Hz. Air pressure can be measured and expressed objectively in decibels (dBSPL). Perceived loudness, a trickier concept requiring the intellectual assessment of a sound by a human, is measured with subjective units of phons.
Figure 3.2 shows the results of equal loudness studies across sound pressure levels from the threshold of hearing in quiet up to those equivalent in loudness to a 1-kHz sine wave at 100 dBSPL, or 100 phons.
Even as the sound pressure is changed, some trends in human hearing remain consistently true. First, human hearing is never flat in frequency response. Sounds across frequency ranges that are perceived as having the same loudness (a subjective conclusion) are the result of a variety of sound pressure levels (an objective measurement). Uniform loudness comes from a range of sound pressure levels across the frequency axis. Similarly, uniform sound pressure level across the frequency axis would lead to a broad range of perceived loudnesses.
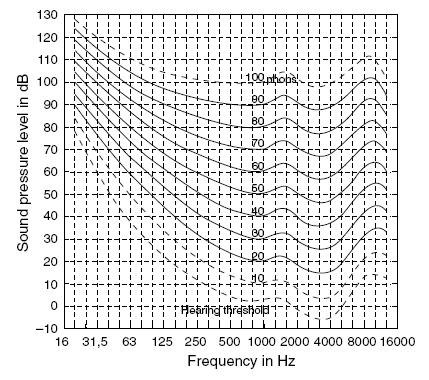
![]() Figure 3.2 Equal-loudness contours for loudness levels from 10 to 100 phons for sounds presented binaurally from the frontal direction. The absolute threshold curve (the MAF) is also shown. The curves for loudness levels of 10 and 100 phons are dashed, as they are based on interpolation and extrapolation, repectively.
Figure 3.2 Equal-loudness contours for loudness levels from 10 to 100 phons for sounds presented binaurally from the frontal direction. The absolute threshold curve (the MAF) is also shown. The curves for loudness levels of 10 and 100 phons are dashed, as they are based on interpolation and extrapolation, repectively.
Second, there is a consistent trend that human hearing is less sensitive to low and high frequencies and most sensitive to middle frequencies. This trend is shown to exist at a range of amplitudes.
Third, human hearing consistently remains most sensitive to that upper middle frequency range near about 3,500 Hz, across a range of amplitudes — from quiet, just-audible sound pressure levels (0 dBSPL) up to painfully loud, and possibly unhealthy sound pressure levels (100 dBSPL).
These consistent trends not withstanding, the equal loudness contours do reveal some amplitude-dependent changes in the perception of loudness across frequency. These more subtle properties of human hearing might be the more important points of the equal loudness curves. The sweep upward in amplitude of these equal loudness curves as one follows them from a middle frequency down to a low frequency shows the amount of additional sound pressure level needed at a low frequency to match the loudness of that middle frequency.
Compare the curve passing through 80 dBSPL at 1 kHz (the 80-phon curve) to the curve passing through 20 dBSPL at 1 kHz (the 20-phon curve). The 80-phon curve is flatter than the 20-phon curve. To be sure, the 80-phon curve is far from flat. But the 80-phon curve demonstrates that at higher sound pressure levels, the human hearing system gets better at hearing low frequencies than at lower sound pressure levels. As the overall amplitude of the audio is raised, one does not require as much compensation in sound pressure level to match the low frequency loudness to the middle frequency loudness. The sound pressure difference between a middle and a low frequency at the same perceived loudness decreases as amplitude increases.
Humans are always less sensitive to low frequencies than to middle frequencies. As amplitude increases, however, the sensitivity to low frequencies approaches the sensitivity to middle frequencies.
Every successful audio engineer must be aware of this property of human hearing. Consider a mixdown session, simplified for discussion: a jazz duet consisting of acoustic bass and soprano saxophone. While questionable music might result, compelling audio logic will be revealed.
A fundamental action of the audio engineer is to carefully set the fader levels for every instrument in the mix, two instruments in this case (see Chapter 8). The engineer decides the relative level of the upright bass versus the soprano sax. While both instruments offer complex tone, it would be fair to oversimplify a bit and say that the majority of the acoustic bass signal lives in the lower-frequency range while the soprano saxophone exists predominantly in the middle and upper parts of the spectrum. The engineer finds a balance between bass and sax that is satisfying, musically. The foundation of the mix and the orientation of the harmony might be provided by the bass, while the saxophone offers melodic detail and harmonic complexity filling out the top of the spectrum. When the level of each is just right, the musicality of the mix is maximized; music listeners can easily enjoy the full intent of the composer and musicians.
Imagine the mix engineer listens at very low volume in the control room, at levels near the 20-phon curve. The fader controlling the acoustic bass and the fader controlling soprano sax are coaxed into a pleasing position.
Turn the control room level up about 60 dB, and the same mix is now playing closer to the 80-phon curve. A volume knob raises the level of the entire signal, across all frequencies, by the same amount. So the control room level adjustment from around 20 to around 80 phons has the perceptual result of turning up the bass performance more than the saxophone performance. As discussed above, at the higher level, one is more sensitive to the bass than when listening at a lower level.
Turning up the control room volume knob, the relative fader positions are unchanged. The overall level is increased globally. At the low listening level, maybe the bass fader was 30 dB above the sax fader to achieve a pleasing mix. At the higher listening level, this 30-dB difference has a different perceptual meaning. The 30 decibels of extra bass level now has the effect, perceptually, of making the bass much louder than the sax, shifting the musical balance toward the bass, and possibly ruining the mix.
The human hearing system has a variable sensitivity to bass. When the engineer turns up the level with a volume knob, they raise the level across all frequencies uniformly. Perceptually, however, turning up the level turns up the bass part of the spectrum more than the middle part of the spectrum, because the equal loudness curves flatten out at higher amplitudes.
Not only does this frustrate the mixdown process, it makes every step of music production challenging. Recording a piano, for example, an engineer selects and places microphones in and around the piano and employs any additional signal processing desired. A fundamental goal of this piano recording session might be to capture the marvelous harmonic complexity of the instrument. The low-frequency thunder, the mid-frequency texture, and the high-frequency shimmer all add up to a net piano tone that the artist, producer, and engineer might love. As any recording engineer knows, the sound as heard standing next to the piano is not easily recreated when played back through loudspeakers. The great engineers know how to capture and preserve that tone through microphone selection and placement so that they create a loudspeaker illusion very much reminiscent of the original, live piano.
The general flattening of the hearing frequency response with increasing level as demonstrated in the equal loudness contours portends a major problem. Simply raising or lowering the monitoring volume can change the careful spectral balance, low to high, of the piano tone. Turning it up makes the piano not just louder, but also fuller in the low end. Turning it down leads to a sound perceptually softer and thinner, lacking in low end. The control room level is an incredibly important factor whenever recordists make judgments about the spectral content of a signal. Perceptually, volume acts as an equalizer (see Equalization in Chapter 5).
The hearing system does not tolerate increases in sound pressure level without limit. Figure 3.1 shows that there is risk of permanent hearing damage when our exposure to sound pressure levels reaches about 90 dBSPL (see Decibel in Chapter 1) and above. Many factors influence the risk for hearing damage, including sound pressure level, frequency content, duration of exposure, stress level of the listener, etc. The equipment in even the most basic recording studio has the ability to damage one′s hearing, permanently. The reader is encouraged to use common sense, learn the real risks from resources dedicated to this topic, and try to create audio art in an environment that is healthy.
Typical speech and music, if there is such a thing, is shown in the crosshatched section within the audio window of Figure 3.1. Note that music seeks to use a wider frequency range and a more extreme amplitude range than speech. The history of audio shows steady progress in our equipment′s ability to produce wider and wider bandwidth, while also achieving higher and higher sound pressure levels. Musical styles react to this in earnest, with many forms of music focusing intensely on that last frontier of equipment capability: the low-frequency, high-amplitude portion of the audio window.
It is a fundamental desire of audio production to create sounds that are within the amplitude and frequency ranges that are audible, without causing hearing damage. Figure 3.1 shows the sonic range of options available to the audio community. An additional dimension to audibility not shown in Figure 3.1 is the duration of the signal. It is measurably more difficult for us to hear very short sounds versus sounds of longer duration. Figures 3.1 and 3.2 are based on signals of relatively long duration. Figure 3.3 shows what happens when signals become quite short.
The dashed lines show the threshold in quiet for three test frequencies: 200 Hz, 1,000 Hz, and 4,000 Hz. The 4-kHz line is consistently lowest because humans are more sensitive to this upper-middle frequency than to the two lower frequencies tested. This is consistent with all of the equal loudness contours and the earlier plots of threshold in quiet, which all slope to a point of maximum sensitivity in this frequency range. Human hearing is less sensitive to low frequencies, and the 200-Hz plot of Figure 3.3 confirms this.
The effect of duration on the ability to hear a sound is shown along the horizontal axis of Figure 3.3. The shorter the signal, the higher the amplitude needed to detect it. As the signal lasts longer, it can be heard at a lower duration of test-tone burst level. This trend, that longer sounds are more easily detected than shorter sounds, continues up to a duration of about 200 ms. Beyond 200 ms, the extra duration does not seem to raise the audibility of the sound. At 200 ms or longer, our threshold of hearing remains consistently as reported in Figures 3.1 and 3.2. The solid lines of Figure 3.3 show the same effect for detecting a signal in the presence of a distracting other sound, discussed next.
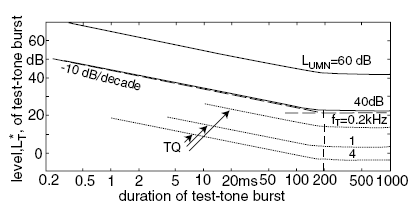
![]() Figure 3.3 Level of just-audible test-tone bursts, L*T, as a function of duration of the burst in quiet condition (TQ, dotted curves, for three frequencies of test tones) and masked by uniform masking noise of given level (solid curves). Note that level, L*T, is the level of a continuous tone out of which the test-tone burst is extracted. Broken thin lines mark asymptotes.
Figure 3.3 Level of just-audible test-tone bursts, L*T, as a function of duration of the burst in quiet condition (TQ, dotted curves, for three frequencies of test tones) and masked by uniform masking noise of given level (solid curves). Note that level, L*T, is the level of a continuous tone out of which the test-tone burst is extracted. Broken thin lines mark asymptotes.
Sounds that are audible in quiet may not be audible when other sounds are occurring. It is intuitive that, in the presence of other distracting signals, some desirable signals may become more difficult to hear. When one is listening to music in the car, the noise of the automotive environment interferes with one′s ability to hear all of the glorious detail in the music. Mixing electric guitars with vocals, the signals are found to compete, making the lyrics more difficult to understand, and the guitars less fun to enjoy. When one signal competes with another, reducing the hearing system′s ability to fully hear the desired signal, masking has occurred.
Spectral Masking
Fundamental to an understanding of masking is the phenomenon like that shown in Figure 3.4. Three similar situations are shown simultaneously; consider the left-most bump in the curve first.
The dashed curve along the bottom is the familiar threshold in quiet. A narrow band of distracting noise is played, centered at 250 Hz. The threshold of hearing, no longer a threshold in quiet, shifts upward in a spectral region around 250 Hz. The departure from the original curve shows the effect of masking. The typical ability to detect a signal is diminished by the presence of the masking signal. Signals at or near 250 Hz need to be a bit louder before they can be heard.
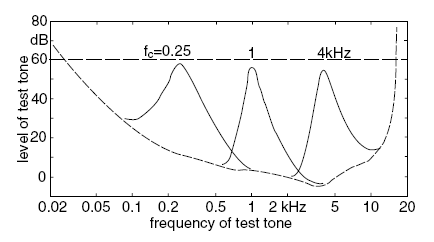
![]() Figure 3.4 Level of test tone just masked by critical-band wide noise with level of 60 dB, and center frequencies of 0.25, 1 and 4 kHz. The broken curve is again threshold in quiet.
Figure 3.4 Level of test tone just masked by critical-band wide noise with level of 60 dB, and center frequencies of 0.25, 1 and 4 kHz. The broken curve is again threshold in quiet.
This does not suggest there is any hearing damage, and is not a reflection of unhealthy or inferior hearing ability. Healthy human hearing exhibits the trends shown in Figure 3.4. A listener′s ability to detect a faint signal is reduced in the presence of a competing signal.
The upward shift in level needed in order to detect a signal in the presence of a distracting masking signal is at a maximum at the center frequency of the narrowband masking noise. Note also, however, that the masking noise affects our hearing at frequencies both below and above the masking frequency. The masker narrowly confined to 250 Hz casts a shadow that expands both higher and lower in frequency.
Figure 3.4 demonstrates masking in three different frequency regions, revealing similar effects not just at 250 Hz, but also at 1,000 Hz and 4,000 Hz. A distracting signal makes it more difficult to hear other signals at or near the frequency region of the masker.
As the masking signal gets louder, the effect grows a bit more complicated (Figure 3.5). The shape of the curve describing the localized decrease in the ability to hear a sound grows steadily biased toward higher frequencies as the amplitude of the masker increases. Termed ″the upward spread of masking,″ this phenomenon indicates that masking is not symmetric in the frequency domain. A distracting signal makes it more difficult to hear in the frequency region around the masking signal. Moreover, depending on the amplitude of the masking signal, the masking footprint can work its way upward in frequency, reducing the sensitivity above the masking frequency more than below it.
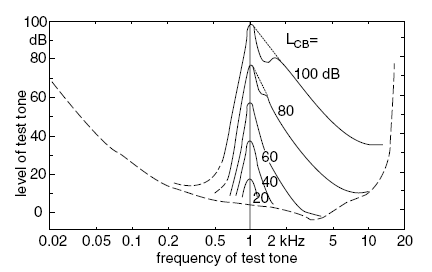
![]() Figure 3.5 Level of test tone just masked by critical-band wide noise with center frequencies of 1 kHz and different levels as a function of the frequency of the test tone.
Figure 3.5 Level of test tone just masked by critical-band wide noise with center frequencies of 1 kHz and different levels as a function of the frequency of the test tone.
Temporal Masking
Masking is not limited only to the moments when the masking signal is occurring. Masking can happen both before and after the masking signal. That is, the temporary reduction in hearing acuity due to the presence of a distracting sound occurs for some time after the masking signal is stopped. Perhaps more startling, the masking effect is observed even just before the onset of the masker (shown schematically in Figure 3.6). The downward sloping portion of the curve, labeled ″postmasking,″ on the right side of Figure 3.6 shows hearing sensitivity returning to the performance expected in quiet, but doing so over a short window in time after the masker has stopped. Postmasking (also called forward masking), when the signal of interest occurs after the masking distraction, can have a noticeable impact for some 100 to 200 ms after the masker has ceased. The upward sloping curve, labeled ″premasking,″ on the left side of Figure 3.6 demonstrates the reduction in sensitivity (versus our threshold in quiet) to a signal immediately before the masking signal begins. Premasking (also called backward masking), when the signal of interest happens before the distracting masker, operates at a smaller time scale, meaningful only for the 20 to 50 ms just before the masker begins. Figure 3.6 summarizes a significant property of human hearing: The masking effect is not limited to sounds occurring simultaneously with the masker. Not only is it more difficult to hear some signals during a masking event, but also it is more difficult to hear those signals immediately before or after the masking signal occurs.
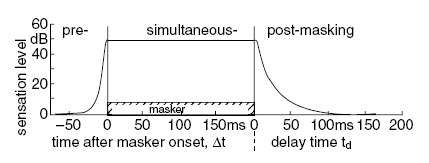
![]() Figure 3.6 Schematic drawing to illustrate and characterize the regions within which premasking, simultaneous masking, and postmasking occur. Note that postmasking uses a different time origin than premasking and simultaneous masking.
Figure 3.6 Schematic drawing to illustrate and characterize the regions within which premasking, simultaneous masking, and postmasking occur. Note that postmasking uses a different time origin than premasking and simultaneous masking.
The multitrack recordings produced in the studio throw listeners right into a masking conundrum. A simple rock tune consisting of drums, bass, guitar, and vocals presents severe masking challenges. Kick drum, snare drum, three tom toms, hi hat, crash cymbal, ride cymbal, bass guitar, rhythm guitar, lead guitar, and lead vocal — a simple rock arrangement presents an audio engineer with 12 individual elements fighting to be heard. Guitars mask snare drums. Cymbals mask vocals. Bass guitar masks kick drum. An engineer must cleverly minimize unwanted masking.
In multitrack production, the portion of the frequency axis and the range of amplitude used are determined first by the source signal (Is it a piano or a penny whistle, a guitar or glockenspiel?). It is further influenced by the type and quality of musical performance, microphone selection and placement, room acoustics, and signal processing applied.
Among recording studio effects that work the frequency axis directly, the most apt might be equalization (see Chapter 5). Note, however, that all processes can have some influence — directly or indirectly — on the spectral content of the signal.
On the amplitude axis, engineers reach for mute buttons, faders, compressors, expanders, gates, tremolo, and distortion devices for a direct effect.
Identifying the key drivers of audibility is fundamental to creating successful recordings. Audio engineers must balance the duration, amplitude, and spectral content of each and every element of the multitrack production to ensure that the work can be fully enjoyed later on loudspeakers in cars, laptops, headphones, living rooms, department stores, and elevators all over the world.
There is no universal cure for masking, but there are a few levers an engineer can pull.
Spectral Management
One signal can mask another when they occupy similar frequency ranges. Great arrangers, orchestrators, composers, and producers know this well. The very instrumentation chosen, and the playable range of each instrument, are driven, in part, by the spectral competition each chosen instrument presents to others.
When the pianist and guitarist play the same part, in the same range, using the same chord voicings, the instruments might blur into one vague texture. Done well, this creates a single, hybrid sound — a piano/guitar meta-instrument. This can be exactly the intent. The way the two spectrally competing instruments mask each other helps them fuse into a greater whole. Here masking is deliberate and desirable.
More frequently, such masking is unwanted. Each musician would like to hear their own part. Fans of the music want to enjoy each musical element individually. Separation is achieved by shifting the spectral content of the piano and the guitar to more distinct areas, reducing masking. Get the guitar out of the way of the piano by shifting it up an octave. Or ask the piano player to move the left-hand part down an octave, the right-hand part up an octave, or both. Have them play different parts using different chord voicings. This quickly becomes an issue for the band — an issue of arranging and songwriting. Counterpoint is required study for formally-trained musicians, and it applies to pop music as much as it does to classical music. Good counterpoint is good spectral management. Multiple parts are all heard, and they all make their own contribution to the music, in part because they do not mask each other. Choosing which instruments to play, and deciding what part each plays, are the most important drivers of masking. It is important to make those decisions during rehearsal and preproduction sessions.
Of course, the recording engineer influences the extent of the remaining spectral masking. Using equalization (see Chapter 5), engineers carve into the harmonic content of each signal so that competing signals shift toward different frequency ranges.
Level Control
The upward spread of masking serves as a reminder to all engineers: Do not allow the amplitude of any single signal to be greater than it absolutely needs to be. The louder a signal is in the mix, the bigger the masking trouble spot will be. As signals get louder still, they start to compete with all other signals more and more, masking especially those frequencies equal to and greater than themselves.
Worst case: a really loud electric bass guitar. Broad in spectral content, when it is loud, it masks much of the available spectral range. Audio engineers only have that finite frequency space between 20 and 20,000 Hz to work with. Low-frequency dominant, the masking of the bass guitar can spread upward to compete with signals living in a much higher range, including guitars and vocals! The bass must be kept under control.
Panning
All of the masking discussed above diminishes when the competing signals come from different locations. Use pan pots and/or short delays to separate competing instruments left to right and front to back. The reduction in masking that this achieves is immediately noticeable, and can reveal great layers of complexity in a multitrack production. Colocated signals fight each other for the listener′s attention. Signals panned to perceptually different locations can be independently enjoyed more easily.
Stretching
Signals that are shorter than 200 ms can be particularly difficult to hear. Most percussion falls into this category. Individual consonants of a vocal may be difficult to hear. Using some combination of compression (see Chapter 6), delay (see Chapter 9), and reverb (see Chapter 11), for example, engineers frequently try to stretch short sounds out so that they last a little longer. So treated, the sounds rise up out of the cloud of masking, becoming easier to hear at a lower level.
When a complex sound occupying a range of frequencies is treated with a distinct effect across all frequencies, it may become easier to hear. Tremolo or vibrato (see Chapter 7), for example, helps connect spectrally disparate elements of that instrument′s sound into a single whole. The hearing system then gets the benefit of listening to the broadband signal by perceptually grabbing hold of those spectral parts that are not masked. Frequency ranges treated with the same global effect can be perceptually fused to those parts that can be heard. As a result, the overall sound, that entire instrument, will become easier to hear.
When an electric guitar and an electric piano fight to be heard, treat them to different effects: distortion on the guitar (see Chapter 4) and tremolo on the keyboard (see Chapter 7). The spectrally similar signals that had masked each other and made the mix murky perceptually separate into two different, independently enjoyable tracks. Many effects, from reverb to an auto-panning, flanging, wah-wah multieffect can help unmask a signal in this way.
Interaction
When an engineer interacts with the device that affects that signal — when they move the slider, turn the knob, or push the button — it is easier to hear the result. If someone else is making those adjustments, and a listener does not know what that person is changing or when, then the exact same signals can return to a masked state where listeners just can not hear the effect.
There is a difference between what is audible on an absolute basis, and what is audible when one makes small signal processing changes to the signal. There is good news and bad news here.
The good news is that recording engineers can actually listen with high resolution while making the fine adjustments to signal processing settings that are so often necessary in music production. This helps engineers get their jobs done, as that is so much a part of the recording engineer′s daily life. Cueing in on the changes made, audio engineers are able to detect subtleties that would otherwise be inaudible.
The bad news is that this has no usefulness for consumers of recorded music. People listening to carefully-crafted recordings do not have the same benefit of interacting with the studio equipment that the engineer had when creating the recording. Because they are not interacting with the devices that change the sound, they are less likely to hear subtle changes in the sound. A sound engineer′s hard work might go completely unnoticed. Sound for picture (with visual cues) and sound for games (with interactivity), on the other hand, do offer some opportunity to leverage this property and push past some of the masking.
This discussion of what is audible and what is inaudible would not be complete without mentioning what is imaginable. That is, just because good hard scientific research into the physiology and psychology of hearing says humans likely can not hear something does not mean they do not think they heard something. A sort of wishful listening can influence the work in the recording studio.
Engineers might be making adjustments to the settings on an effects device, trying to improve, for example, a snare drum sound. They turn a knob. They think it sounds better. The assistant engineer nods with approval. They turn the same knob a bit further. Ooops! Too far. Too much. The producer agrees. They back off a bit to the prior setting and, yes, the snare drum is perfect.
This experience can then be followed by the (hopefully discreet) discovery that the device they were adjusting was not even hooked up. Or, worse yet, the device they were adjusting was affecting the vocal, not the snare!
The desire to make things sound better is so strong that one does not actually need it to sound better in order for it to sound better.
A frustrating part of creating multitrack recordings is that, though science documents when and where certain signals in certain situations will not be audible, there is no clear sign for the hard working engineer that any specific sound or effect is not audible. The hearing system searches earnestly, without fear, for all levels of detail in the recordings being worked on. Human hearing rarely states definitively, ″I don′t know. I don′t hear it.″ It almost always makes a guess. Subtle moving targets are hard to hear. When one listens for small changes, it can be difficult indeed to tell actual changes from imagined changes.