
Chapter 11. The Giant Global Graph
Hopefully, over the course of this book we have demonstrated the power of semantic programming and convinced you of how easy it is to incorporate semantic technologies into your own architectures. Our ability to concisely introduce semantic technologies has been facilitated by a lot of existing research on building the semantic web over the past decade. And that existing work rests on more than a quarter century of research on language understanding and knowledge representation.
Today’s semantic technologies are the result of threshing many lines of academic research that deal with a wide variety of thorny issues, and harvesting, milling, and packaging the most useful and practical solutions. This sifted and codified experience gives you a standard, flexible approach to data integration and information management whether you are writing a Ruby on Rails “mash-up” or an Enterprise Java industrial solution.
Research into semantic technology continues to this day. Many academic labs are actively pursuing various open questions of knowledge representation. However, this ongoing research doesn’t mean the existing methods aren’t ready for adoption. To the contrary, it means that your investment in semantic technology today is backed with continuing support. What you learn today will prepare you for the continuous and incremental deliveries emerging from this vibrant area of work. That said, it is important to sort out what is useful today from what may be useful in the future.
When you are considering a new semantic technology, look to see if it is embodied in multiple tools, whether a community of practice is emerging around it, and if the W3C has released any Recommendations about it. All of these are good indications that incorporating a prospective technology into your own architecture is a good idea.
Vision, Hype, and Reality
The semantic web was first widely introduced into technical vernacular with the publication of Tim Berners-Lee, James Hendler, and Ora Lassila’s article “The Semantic Web” in the May 2001 issue of Scientific American. The article outlined existing work on almost all of the foundational concepts covered in previous chapters, including triples, RDF, ontologies, and the role of URIs. The article also attempted to motivate the role of the semantic web by introducing an agent scheduling usecase, which used semantically annotated information to find health care providers that fulfilled a number of constraints.
In the years following the article, the promise of the semantic web has continued to grow both inside and outside the technical community. Mainstream publications such as Newsweek, Forbes, and the New York Times have covered various promises and prospects for semantically enabled data on the Web. But while many of the technologies necessary for building the semantic web were known in 2001, we have yet to see anything like the semantic web or the agents envisioned in the Scientific American article emerge.
The semantic web, however, is not a single thing, and as such it won’t come into existence on any given day. Rather, the semantic web is a collection of standards, a set of tools, and, most importantly, a community that shares data to power applications. Unfortunately, throughout this period the W3C has continued to present the semantic web as a monolithic “stack” of technologies (see Figure 11-1). Sometimes referred to as the “layer cake,” the stack illustrates how different technologies build upon one another, extending semantic capabilities. With all the technologies in place, user applications can be supported on top of the stack. Over the years, the layers of the cake have been refined to reflect the scope of evolving standards and to account for capabilities required by new usecases.
This view of semantic technologies reinforces the notion that the semantic web is a “thing” that does or does not exist. If this view of the semantic web were correct, then we are a long way off from being able to provide semantic web applications, as most of the top-level technologies identified by the stack are only fledgling research activities and have no standards in development.
But, as we have hopefully shown in this book, useful semantic applications using the nascent web of data can be built today. The view of the semantic web as a monolithic architecture misses the general point that semantic technologies are now sufficiently mature that the core methodologies have been codified in well-designed components that can be included in any application architecture. Many businesses are currently applying the practical semantic technologies that we have outlined in the book.
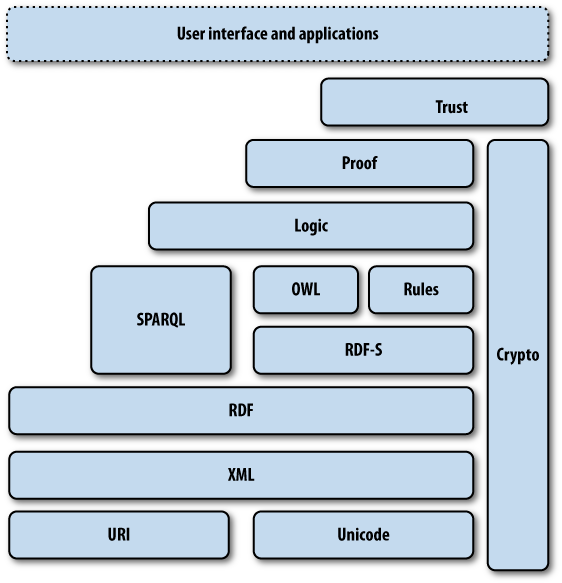
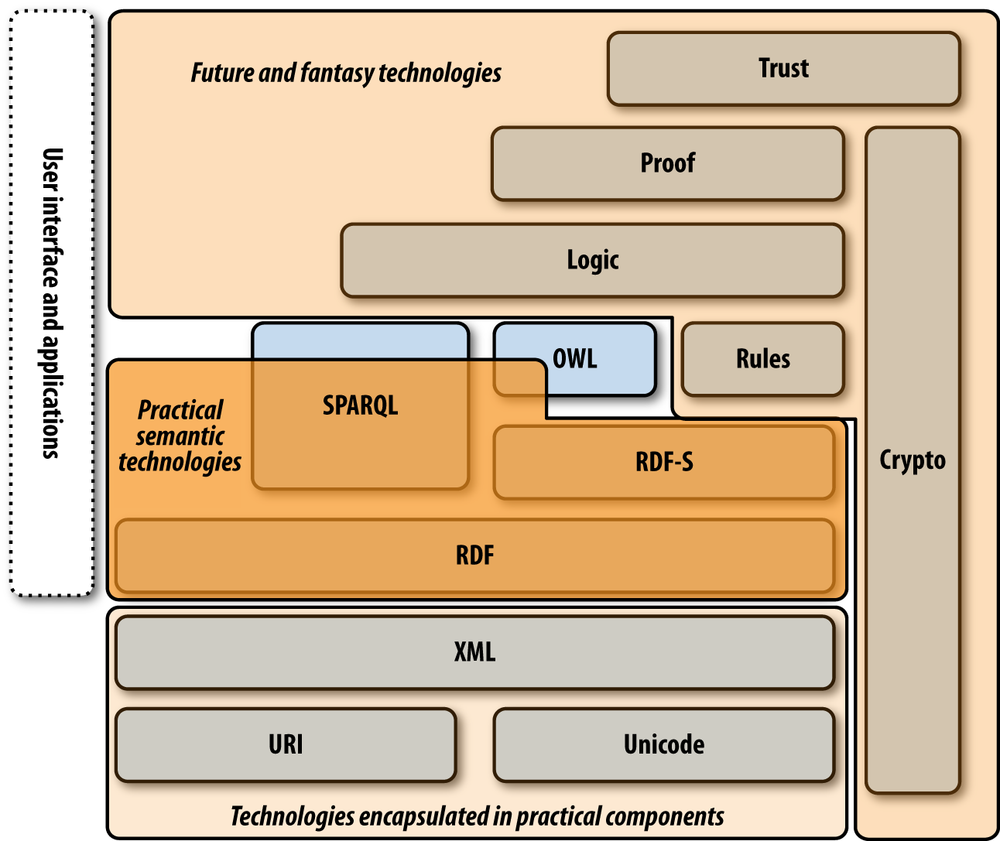
Figure 11-2 breaks the semantic stack into existing technologies that are already widespread (URIs, Unicode, XML); practical and proven semantic technologies that are being actively used by companies adopting semantic technologies (RDF, RDFS, SPARQL, and parts of OWL); and emerging research that exists mostly within the laboratory or in very proprietary business settings. There is an enormous amount of value that can be captured by bringing the middle layer of existing semantic technology into your software and your company today. At this point, the standards are settled, the software APIs are solid, and the community is growing. In the future, as the research questions around RDF-based rule systems and logic reasoners become settled and the standards emerge, you may be able to build the applications envisioned in Tim Berners-Lee’s original vision of the Web. But there is no reason not to reap the benefits from the existing work now.
Participating in the Global Graph Community
In late 2007, Tim Berners-Lee, father of the World Wide Web, suggested that the phrase “semantic web” doesn’t fully convey the granularity of the connections in his vision (http://dig.csail.mit.edu/breadcrumbs/node/215). “The Web” as we know it today is a network of interconnected documents, giving anyone the opportunity to publish their work and connect it to existing documents. The vision of “the semantic web” is a network of interconnected facts about real entities, published as graphs of data. Just as the existing Web is a graph of documents, the Giant Global Graph is envisioned to be a graph of graphs.
Anyone can publish their data into this massive joined graph, and anyone can connect their data to anyone else’s data. The grand vision is one of all human knowledge offered up in a decentralized network of interconnected datasets. This sounds like an idealistic goal, but the whole of the World Wide Web today proves that it is possible to build interconnected systems on this scale, given the right technology and community.
As we have seen, the use of strong identifiers and shared semantics makes the vision of a Giant Global Graph possible. But the vision also requires the development of a global data community. With the knowledge you now possess, you are well positioned to play an important role in the Global Graph Community.
Releasing Data into the Commons
Whether you run a website or a business, it is easy to think of all of your data as an asset—as something that produces business value and therefore should be guarded like any intellectual property. However, if you try to carefully differentiate your company’s value from your competitor’s, it often becomes apparent that there is only a small amount of data that is truly valuable and that provides your competitive advantage. The vast majority of data is often simply the glue that connects your valuable data to the rest of the world and makes it possible to use.
This distinction can be described as follows. The things that produce business value and allow a business to differentiate are what Geoffrey Moore, a technology business analyst, calls “core.” Everything else that goes on in a business that is not a part of value differentiation is deemed “context.” Moore points out that to optimize business value, organizations should focus on those things that are core and treat everything that is context as a commodity service, outsourcing to lower-cost providers whenever possible.
From this perspective, the data from which your company derives value—the information about your users, the data produced through your R&D, the data that your competitors don’t have access to—becomes core. All the other data that is used to make sense of the core data—geographic metadata used to organize your sales force, lists of industry standards that you need to comply with, databases of vendors that you keep on hand for convenience, product databases that everyone in your market must maintain—all of this is really context. Money and time spent maintaining and growing core data helps grow the company. On the other hand, resources spent on maintaining context data are overhead and operating costs—potentially a liability, and best if minimized.
By making data available to the Giant Global Graph, organizations have an opportunity to share the burden of maintaining context data by creating a commons of data. Shared data is a public good that lowers everyone’s overall cost of doing business. And unlike other types of public goods, there can be no tragedy of the commons with information because information it can never be used up. If one group takes more than they contribute, the overall community is not hurt. There is only upside as people contribute into the commons.
License Considerations
Public data is only useful if you understand how you are allowed use it. Copyright is a complicated area of law, and it is often unclear if there are limitations on the use of public data. Traditionally, the metadata about permitted uses of information has been provided in legal documents intended for humans—and even then, comprehensible by only a few of us. For a truly global graph to work, machines must not only be able to discover data and join it to existing information, but they must also be able to understand how the data can be used.
Creative Commons is a nonprofit organization that provides standardized ways to grant copyright permission to creative works. To convey the rights granted by information providers to data consumers in a machine-readable way, Creative Commons has developed the Rights Expression Language (ccREL), an RDF vocabulary for describing licenses. The vocabulary can be broken into two sets of predicates: Work Properties, which attach license statements to creative works, and License Properties, which describe the legal aspects of a license. See Figure 11-3.

Creative Commons provides an array of pre-constructed licenses, which make use of the License Properties to describe how data can be used. To use Creative Commons licenses, you utilize the Work Properties to specify which resources are associated with which license. For instance, to grant rights so that anyone can use the MovieRDF dataset as long as they give attribution to Freebase, the source of the data, we make use of the XHTML license predicate to connect the resource for the dataset to the Creative Commons Attribution license. We then use Work Properties to indicate the name and URL that should be used for making proper attribution to the data creator. In N3, these RDF statements would be:
@prefix cc: <http://creativecommons.org/ns#>
@prefix xhtml: <http://www.w3.org/1999/xhtml/vocab#>
<http://semprog.com/psw/chapter4/movierdf.xml>
xhtml:license <http://creativecommons.org/licenses/by/3.0/>
cc:attributionName "Freebase - The World's database" ;
cc:attributionURL <http://www.freebase.com/> ;You can find additional predicates for specifying other information about the licensed work and the full set of License Properties for constructing new licenses at http://wiki.creativecommons.org/CcREL.
When you choose a license, think carefully about the restrictions that you place on your data. While selecting a license that disallows commercial usage or derivative work may seem like a conservative and prudent business decision, this often results in a lack of adoption of the data that you are trying to share. It can even lead to competing efforts to open up the same data with fewer restrictions, and can result in a community backlash against your good intentions.
If you’re trying to engage with a community of users and businesses, the Creative Commons Attribution license (CC-BY) is a liberal license that allows users and businesses to use your data as long as they credit you when and where it is used. It allows your users and partners to freely build on your data, while ensuring that nobody claims that your data is their sole property.
The Data Cycle
When thinking about semantic data ecosystems, it is tempting to partition the world into data providers and data consumers. At first glance, it seems like these types of distinctions could help identify the technologies used by participants in different parts of the data ecosystem. Consumers of web pages use web browsers, while producers of web content use content management systems, application servers, and web servers. Hopefully we have demonstrated a symmetry in the consumption and production of semantic data. A consuming application will typically have a local triplestore in which to join semantic data from multiple sources, and will use graph queries to extract the information used by the application. A producing application will use a local triplestore on which to run graph queries, which are serialized out for specific requests. Both types of participants in the system use the same machinery, and both can consume and produce data equally easily.
For this reason, networks of semantic data are more than point-to-point exchanges of information. Semantic applications are about integrating multiple sources of data through easy, standardized patterns. A good consuming application can reveal things that no singular source of its data “knew.” The application can then republish that information in a machine-readable form for consumption by other applications.
This approach, where consumers are also producers, forms a data cycle. Information is transformed, augmented, and refined by a loose coupling of services that can be joined end-to-end by other applications. Each service transmits data in a standardized way, packaging metadata with data for use by other downstream services. Through the use of well-known vocabularies and license attribution, services further down the chain may have no contact with services earlier in the chain, but will know precisely how the data can be used. This vision of machines helping one another to help humans has long been a vision in science fiction, but with growth in the Linked Open Data community and applications that implement the trivial “serving” functions we have demonstrated, we are on the cusp of making this a reality.
Bracing for Continuous Change
RDF and semantic technologies are generative meta-models. They are frameworks that allow you to create languages for data interchange and integration. Their advantage is their extensibility. Rather than hardcoding data formats from multiple sources in your application and building custom integration code, semantic technologies provide a standardized toolkit and templates for specifying these operations. Making use of these techniques, even when the data sources are not semantically enabled, will allow you to adapt to new data and extend functionality without duplicating effort or working around fragile code.
Semantic technologies are not static, either—they continue to expand in capability. But because they are based on meta-models, extensions don’t disrupt existing uses of the technology. When standardized rule expressions emerge, they will be expressed using the existing modeling language, and the systems that consume them will operate on the same model as well. In this way, an investment in semantic technologies is a hedge on future change—not only will your investment continue to yield, but you will have taken an option on using future technologies as they emerge.
The revolution of semantic technology is far from complete—we still have a long way to go. More semantic programming patterns will emerge, the tools will improve, and more people will learn the economies of semantic data. But hopefully we have convinced you that useful and powerful applications can be built today. There is a community of data providers who are motivated to share and curate large bodies of knowledge in a wide selection of domains, and you are welcome to join in that effort. Semantic technologies have arrived. They have been well incubated, and are now mature enough for serious application development.
We are truly interested in hearing what you are doing with semantic technologies, and we encourage you to join the semantic data community. Our FOAF information can be found throughout this book, and we have established http://www.semprog.com as a community resource for demonstrating practical approaches to semantic technology. We hope you will join the community and contribute new patterns, useful vocabularies, lessons learned, and best practices.
Though we are at the very early stages of the revolution, the tools
for change are upon us. And as a meta-programming model, you are empowered
to extend the framework for your expressive needs. After all, you don’t
have to wait for someone to invent the <blink>
tag—you can do it yourself.