
Chapter 11. Non-Functional Testing
Almost everyone has experienced or heard this story: Product development was going exceptionally well. The test team and development team worked together and made quick progress. Like clockwork, the development team released a new build of the software every day, and the test team updated their build, and then created and ran new tests every day. They found bugs in the functionality, but the development team fixed issues quickly. The release date approached, and there was little pressure. The software just worked. The tests just passed. The beta testers said the software did everything it was supposed to do. The software shipped, and the initial reaction was positive.
Two weeks later the first call came in, quickly followed by many more. The program that the team had just developed was designed to run constantly in the background. After a few weeks of continuous use, the software still “worked,” but performance had degraded so much that the application was nearly unusable. The team was so proud of the features and functionality of their application that they did not think to (or forgot to) run the application as a user would—for days, weeks, and months at a time. Daily builds meant that they reinstalled the application daily. The longest the application ever ran was over the weekend, from Friday to Monday, but that wasn’t enough time to expose the small resource leaks in the application that would show up in an obvious way only after nearly two weeks of constant use.
Over the next week, the development team fixed nearly a dozen memory leaks and performance issues, and the test team did their best to verify that the fixes didn’t break any functionality. Twenty-five days after releasing the software the team was so proud of, they released their first high-priority update, with several others following over the subsequent weeks and months.
Beyond Functionality
Non-functional testing is a somewhat confusing phrase, but one that is common throughout the testing industry. In a way, it makes sense. Functional testing involves positive and negative testing of the functionality in the application under test. Non-functional testing is merely everything else. Areas defined as non-functional include performance, load, security, reliability, and many others. Non-functional tests are sometimes referred to as behavioral tests or quality tests. A characteristic of non-functional attributes is that direct measurement is generally not possible. Instead, these attributes are gauged by indirect measures such as failure rates to measure reliability or cyclomatic complexity and design review metrics to assess testability.
The International Organization for Standardization (ISO) defines several non-functional attributes in ISO 9216 and in ISO 25000:2005. These attributes include the following:
Reliability. Software users expect their software to run without fault. Reliability is a measure of how well software maintains its functionality in mainstream or unexpected situations. It also sometimes includes the ability of the application to recover from a fault. The feature that enables an application to automatically save the active document periodically could be considered a reliability feature. Reliability is a serious topic at Microsoft and is one of the pillars of the Trustworthy Computing Initiative (http://www.microsoft.com/mscorp/twc).
Usability. Even a program with zero defects will be worthless if the user cannot figure out how to use it. Usability measures how easy it is for users of the software to learn and control the application to accomplish whatever they need to do. Usability studies, customer feedback, and examination of error messages and other dialogues all support usability.
Maintainability. Maintainability describes the effort needed to make changes in software without causing errors. Product code and test code alike must be highly maintainable. Knowledge of the code base by the team members, testability, and complexity all contribute to this attribute. (Testability is discussed in Chapter 4, and complexity is discussed in Chapter 7.)
Portability. Microsoft Windows NT 3.1 ran on four different processor families. At that time, portability of code was a major requirement in the Windows division. Even today, Windows code must run on both 32-bit and 64-bit processors. A number of Microsoft products also run on both Windows and Macintosh platforms. Portable code for both products and tests is crucial for many Microsoft organizations.
Testing the “ilities”
A list of attributes commonly called the ilities contains the preceding list plus dozens of other quality attributes such as dependability, reusability, testability, extensibility, and adaptability. All of these can be used to help evaluate and understand the quality of a product beyond its functional capabilities. Scalability (ability of the program to handle excessive usage) and security (ability of the system to handle unauthorized modification attempts) are two highly measured “ilities” among teams at Microsoft.
Microsoft test teams often have specialized teams to focus on many of these “ilities.” In the case of usability, we even have a whole separate engineering discipline dedicated to running the tests and innovating the tools and methods we use.
In regard to organizational structure, there are two primary approaches to testing nonfunctional areas. Larger teams can structure themselves as shown in Figure 11-1, with test leads or test managers managing feature team testers alongside non-functional test teams.

A more prevalent approach, shown in Figure 11-2, is the use of a virtual team to test a nonfunctional area. Virtual teams do not report through the same managers, but work together to address a specific aspect of testing in addition to their own feature work. Every virtual team has a designated virtual team lead who is responsible for strategy, goals, and success metrics of the team.

A combination of these two approaches is also common. There might be a dedicated team for an area such as security or performance, while virtual teams take on areas like usability and accessibility.
Numerous resources describe various types of non-functional testing. In this chapter, I do not attempt to discuss every single type of non-functional testing used at Microsoft. Instead, I highlight a few of the areas of non-functional testing where Microsoft has solutions that represent something interesting in innovation, approach, or scale.
Performance Testing
Because of the scope and overlap between various non-functional attributes, the names of many attributes are used interchangeably. For example, performance testing is often associated with the concepts of stress, load, and scalability testing mentioned later in this chapter. In many test organizations at Microsoft, the same testers or test teams are in charge of all of these areas. The approaches and goals for these areas have many differences, but there are several similarities. For example, testing a server system to see how well it performs with thousands of connected users is a type of a performance test (many others would call this a load test or scalability test). Similarly, the ability of an application to perform after running for weeks or months without restarting is considered by many to be part of performance testing (most would call this test a reliability test or long-haul test).
The most common flavor of performance testing could be called stopwatch testing. Many years ago, some testers actually sat in front of the screen and used a stopwatch to measure the performance of various functional tests. This approach, although a reasonable first step in performance testing, is error prone and rarely is the best approach for timing application performance.
The concept behind this genre of performance testing is simply to measure the duration of various important actions. This type of performance test is a single test or a suite of tests designed to measure the application’s response times to various user actions or to measure product functionality in controlled environments. Because the stopwatch approach just doesn’t scale and isn’t really reproducible, most performance testing is accomplished with automated tests that execute the tests and record timing information.
The goal of performance testing is to identify the important and significant bottlenecks in the system. You can think of the system as a series of bottlenecks; identifying and improving one bottleneck most often reveals a new bottleneck somewhere else. For example, I worked on a device running Microsoft Windows CE once where the first big performance problem we found was with the way memory management worked on a specific hardware implementation. We isolated the problem and improved the speed of the memory allocations. We ran our tests again and found a new bottleneck, this time in network throughput. After we fixed that issue, we worked on improving the next bottleneck, and then the next bottleneck until the entire system met our performance goals. One thing to keep in mind is that establishing performance goals early is critical—otherwise, you might not know when to stop performance testing.
How Do You Measure Performance?
Perhaps the most difficult part of performance testing is determining what to measure. Performance testers use several different approaches to help target their testing. One thing every experienced performance tester will tell you is that a proactive approach that involves reviewing and analyzing performance objectives early in the design process is imperative. In fact, the best way to address most non-functional testing needs is to consider those needs during program design. Some tips to help identify potential performance issues during the design phase include the following:
Ask questions. Identify areas that have potential performance problems. Ask about network traffic, memory management, database design, or any other areas that are relevant. Even if you don’t have the performance design solution, testers can make a big impact by making other team members think about performance.
Think about the big picture. Think about full scenarios rather than individual optimizations. You will have time to dig into granular performance scenarios throughout development, but time during the design is better spent thinking about end-to-end scenarios.
Set clear, unambiguous goals. Goals such as “Response time should be quick” are impossible to measure. Apply SMART (specific, measurable, achievable, relevant, time-bound) criteria to the design goals. For example, “Execution of every user action must return application control to the user within 100 milliseconds, or within 10 percent of the previous version, whichever is longer.”
An additional tactic to consider is to anticipate where performance issues might occur or which actions are most important to the users and need measurement. Definition of these scenarios is most effective when addressed during the design phase. A scenario-based approach is effective as an alternative and is well suited for performance testing legacy code. Regardless of the situation, here are some helpful tips for performance testing.
Establish a baseline. An important aspect of defining and measuring early is establishing baselines. If performance testing starts late in the project, it is difficult to determine when any discovered performance bottlenecks were introduced.
Run tests often. Once you have a baseline, measure as often as possible. Measuring often is a tremendous aid in helping to diagnose exactly which code changes are contributing to performance degradation.
Measure responsiveness. Users don’t care how long an underlying function takes to execute. What they care about is how responsive the application is. Performance tests should focus on measuring responsiveness to the user, regardless of how long the operation takes.
Measure performance. It is tempting to mix functionality (or other types of testing) in a performance test suite. Concentrate performance tests on measuring performance.
Take advantage of performance tests. The alternate side of the previous bullet is that performance tests are often useful in other testing situations. Use automated performance tests in other automated test suites whenever possible (for instance, in the stress test suite).
Anticipate bottlenecks. Target performance tests on areas where latency can occur, such as file and print I/O, memory functions, network operations, or any other areas where unresponsive behavior can occur.
Use tools. In conjunction with the preceding bullet, use tools that simulate network or I/O latency to determine the performance characteristics of the application under test in adverse situations.
Remember that resource utilization is important. Response time and latency are both key indicators of performance, but don’t forget to monitor the load on CPU, disk or network I/O, and memory during your performance tests. For example, if you are testing a media player, in addition to responsiveness, you might want to monitor network I/O and CPU usage to ensure that the resource usage of the application does not cause adverse behaviors in other applications.
Use “clean machines” and don’t... Partition your performance testing between clean machines (new installations of the operating systems and application under test) and computer configurations based on customer profiles. Clean machines are useful to generate consistent numbers, but those numbers can be misleading if performance is adversely affected by other applications, add-ins, or other extensions. Running performance tests on the clean machine will generate your best numbers, but running tests on a machine full of software will generate numbers closer to what your customers will see.
Avoid change. Resist the urge to tweak (or overhaul) your performance tests. The less the tests change, the more accurate the data will be over the long term.
Performance counters are often useful in identifying performance bottlenecks in the system. Performance counters are granular measurements that reveal some performance aspect of the application or system, and they enable monitoring and analysis of these aspects. All versions of the Windows operating system include a tool (Perfmon.exe) for monitoring these performance counters, and Windows includes performance counters for many areas where bottlenecks exist, such as CPU, disk I/O, network I/O, memory statistics, and resource usage. A sample view of a Perfmon.exe counter is shown in Figure 11-3.
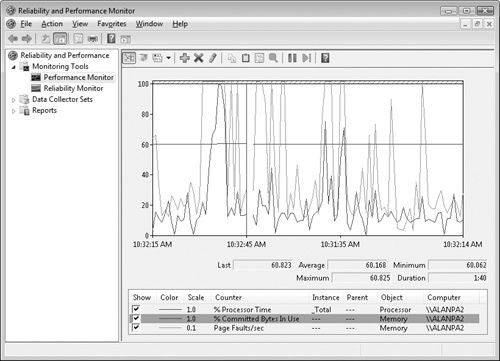
Applications can implement custom performance counters to track private object usage, execution timings, or most anything else interesting in regard to performance. A comprehensive set of performance counters planned in the design phase and implemented early will always benefit performance testing and analysis during the entire life of the product.
Many books and Web references contain extensive additional information in the area of performance testing. Both the patterns & practices Performance Testing Guidance Project at http://www.codeplex.com/PerfTesting/ and http://msdn.microsoft.com/en-us/library/bb924375.aspx are great places to find further information about this topic.
Stress Testing
The ability of an application to perform under expected and heavy load conditions, as well as the ability to handle increased capacity, is an area that often falls under the umbrella of performance testing. Stress testing is a generic term that often includes load testing, mean time between failure (MTBF) testing, low-resource testing, capacity testing, or repetition testing. The main differences between the approaches and goals of these different types of testing are described here:
Stress testing. Generally, the goal of stress testing is to simulate larger-than-expected workloads to expose bugs that occur only under peak load conditions. Stress testing attempts to find the weak points in an application. Memory leaks, race conditions, lock collision between threads or rows in a database, and other synchronization issues are some of the common bugs unearthed by stress testing.
Load testing. Load testing intends to find out what happens to the system or application under test when peak or even higher than normal levels of activity occur. For example, a load test for a Web service might attempt to simulate thousands of users connecting and using the service at one time. Performance testing typically includes measuring response time under peak expected loads.
Mean time between failure (MTBF) testing. MTBF testing measures the average amount of time a system or application runs before an error or crash occurs. There are several flavors of this type of test, including mean time to failure (MTTF) and mean time to crash (MTTC). There are technical differences between the terms, but in practice, these are often used interchangeably.
Low-resource testing. Low-resource testing determines what happens when the system is low or depleted of a critical resource such as physical memory, hard disk space, or other system-defined resources. It is important, for example, to understand what will happen when an application attempts to save a file to a location that does not have enough storage space available to store the file, or what happens when an attempt to allocate additional memory for an application fails.
Capacity testing. Closely related to load testing, capacity testing is typically used for server or services testing. The goal of capacity testing is to determine the maximum users a computer or set of computers can support. Capacity models are often built out of capacity testing data so that Operations can plan when to increase system capacity by either adding more resources such as RAM, CPU, and disk or just adding another computer.
Repetition testing. Repetition testing is a simple, brute force technique of determining the effect of repeating a function or scenario. The essence of this technique is to run a test in a loop until reaching a specified limit or threshold, or until an undesirable action occurs. For example, a particular action might leak 20 bytes of memory. This isn’t enough to cause any problems elsewhere in the application, but if the test runs 2,000 times in a row, the leak grows to 40,000 bytes. If the function provides core functionality that is called often, this test could catch a memory leak that might become noticeable only after the application has run for an extended period of time. There are usually better ways to find memory leaks, but on occasion, this brute force method can be effective.
Distributed Stress Testing
Stress testing is important at Microsoft. Most product lines run stress tests across hundreds of computers or more. Some portion of stress testing occurs over extended periods—often running 3 to 5 consecutive days or longer. On most teams, however, a more significant quantity of stress testing occurs over a 12- to 14-hour period between the time employees leave for the evening and return the next day. Everyone takes part in volunteering their computers to run the overnight stress tests. Test, Development, Program Management, and even Product Support run stress on their computers every night.
When running stress tests, failures and crashes are inevitable. On small teams, reporting stress failures and finding the owner of the code at fault can transpire by phone, e-mail, or a knock on a door. Unfortunately, if a crash occurs on a computer that nobody is paying attention to, or on Frank’s computer while he’s on vacation, investigation and debugging of the failure might never occur.
Large teams need a more efficient method for determining which computers have had stress failures and for determining who should investigate the failure. The most common solution is an ordinary client/server solution. Because stress tests usually run overnight, ideally, the client portion of stress runs in an idle state until reaching a specified time. Nightly stress testing is a valued part of the development life cycle, and this ensures that no one forgets to start stress before they leave for the evening. On Windows 95, for example, the client was a screen saver. The first time the screen saver ran after a specified time (19:00 by default), the stress tests would start. The Windows Vista team uses a background application that is configurable through an icon in the notification area.
Distributed Stress Architecture
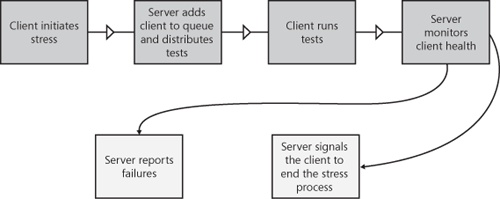
The architecture for a distributed stress system is somewhat less complex than is the automation infrastructure discussed in Chapter 10, but it does have some implementation challenges. Figure 11-4 shows the basic work flow for such a system.
The Stress Client
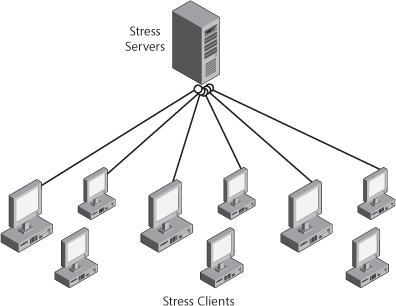
As mentioned earlier, an application on the computer targeted for stress (the stress client) initiates the stress test run. Manual initiation of the stress tests is possible, but in many cases, stress tests start automatically at a preconfigured time. The initiation phase is a simple announcement to the server that the host computer is ready to run stress tests. At this point, the server distributes a variety of stress tests to the host computer for execution. A mix of tests runs for various lengths of time until either reaching a specified time or the stress tests are manually terminated. (Manual termination is convenient if an employee arrives in the morning before the configured end time or needs to reclaim the computer for another reason.) Figure 11-5 shows stress clients connected to a stress server.
In the case of operating system stress, such as Windows or Windows CE, stress client computers are usually attached to a debugger to aid in investigating failures. Application-based stress suites can run with a debugger such as WinDbg or Microsoft Visual Studio attached during the entire stress run, or they might rely on starting the debugger as a just in time (JIT) debugger. The JIT approach is the most common on application and server teams, whereas an “always attached” debugger is used prevalently on teams developing operating systems.
The Stress Server
The role of the stress server is to distribute a set of stress tests (commonly called the stress mix) to all stress clients and track status on the state of the clients. After a client contacts the server, the server adds the client name to the list of known stress clients and begins distributing the tests. The clients periodically send a heartbeat pulse to the server. The heartbeat is critical for determining whether a computer is in a crashed or hung state. If a client heartbeat is not received in a reasonable amount of time, the computer name is added to the list of computers that will need additional investigation or debugging.
At the end of the stress run, the server signals all clients to end the stress testing session. The failures are examined, and then are distributed to the appropriate owners for additional debugging.
Attributes of Multiclient Stress Tests
Stress tests written for a large distributed stress system have many of the same quality goals as typical automated tests do, but also have some unique attributes:
Run infinitely. Stress tests ordinarily run forever, or until signaled to end. The standard implementation procedure for this is for the test to respond efficiently to a WM_CLOSE message so that the server can run tests for varying lengths of time.
Memory usage. Memory leaks by a test during stress typically manifest as failures in other tests resulting from a lack of resources. Ideally, stress tests do not leak memory. Because tests will run concurrently with several other tests, excessive use of processes, threads, or other system resources is also a practice to avoid.
No known failures. On many teams, it is a requirement that all tests are run anywhere from 24 hours to a week on a private computer with no failures before being added to the stress mix. The goal of the nightly stress run is to determine what the application or operating system will do when a variety of actions run in parallel and in varying sequences. If one test causes the same failure to occur on every single stress client computer, no new issues will be found, and an entire night of stress will have been wasted.
Compatibility Testing
Application compatibility testing typically focuses on interactions between the application or system under test and other applications. Other applications can include both internal and external applications. At Microsoft, the biggest efforts in application compatibility are undoubtedly the labors of the Windows team. Every new release of Windows adds new functionality, but must continue to support applications designed for previous versions of Windows. Application compatibility (aka app compat) affects most other Microsoft products as well. Microsoft Internet Explorer must continue to support relevant plug-ins or other addon functionality; applications with a rich developer community such as Visual Studio or Office must also support a variety of third-party-generated functionality. Even support for previous file formats in new versions of an application is critical.
The copy of Microsoft Office Word 2007 I am using to write this chapter supports previous Word document types, as well as templates and other add-ins created for previous versions of Word. Nearly every application I use supports opening files from previous versions of the application, opening files created by other applications, or a variety of add-in components that enhance program functionality. Application compatibility testing ensures that the interoperability between the application under test and all of these file formats and components continues to work correctly.
Application Libraries
Many teams at Microsoft maintain libraries of applications or components used entirely for application compatibility testing. The Windows Application Compatibility team has a library containing many hundreds of applications. There are similarly large libraries for teams such as Office, Windows CE, and the .NET Framework.
Application Verifier
One of the key tools used by engineers testing application compatibility is the Microsoft Application Verifier. Application Verifier is used to proactively examine native user-mode applications at run time to determine whether they have potential compatibility errors caused by common programming mistakes. Applications that incorrectly check for the Windows version, assume administrative rights, or have any of dozens of other subtle programming errors can all be detected with Application Verifier. Application Verifier also detects several other classes of programming errors such as memory leaks, memory corruption, or invalid handle usage. Application Verifier is extendable and is commonly used for numerous additional fault injection scenarios.
Plug-ins for Application Verifier, such as the Print Verifier, are used to test and verify subsystems, printer drivers and print applications, in this case. The Print Verifier detects errors such as invalid printer handle usage, incorrect usage of printing functions, and incorrect implementation of functions within a printer driver. Similar plug-ins for other driver subsystems are commonly available.
Application Verifier works by “hooking” several core Windows functions and adding additional checks before calling the “real” function. For example, when the application under test is loaded, the address of the Microsoft Win32 application programming interface (API) CreateFile method is replaced with an internal Application Verifier method that will trigger a series of tests, as shown in Figure 11-6. If any of the tests fail, the failure is logged, or if a debugger is installed, a debug breakpoint might be triggered. More information about Application Verifier is available on MSDN at http://msdn2.microsoft.com/en-us/library/ms807121.aspx.

Eating Our Dogfood
I mean, we talk at Microsoft about this notion we call “eating our own dog food.” You’re supposed to eat your own dog food before you serve it to anybody else.
Sometimes, the best way to determine how a user will use an application is to be a user. At Microsoft, “eating our own dogfood” (using the product we make every day during development) is a key part of every product team’s usability and compatibility strategy. Everyone on the Windows team uses daily or weekly builds of the in-development version of the operating system to develop the operating system. The Visual Studio team develops their product using Visual Studio. The Office team uses the latest builds of their own products to write specifications, deliver customer presentations, and even send and receive e-mail. When I worked on the Windows CE team, my office phone, my cell phone, and my home wireless router all ran dogfood versions of the operating system.
One disadvantage with dogfooding is that the intended audience of an application might use the product differently from how an employee working on the project uses it. For example, if engineers were the only users of early versions of Word, and they only wrote specifications and design documents, it is likely that other types of users would run into problems. Beta testers (external employees who test prerelease versions of products) are a partial solution for this problem and are enormously valuable in aiding product development at Microsoft. For Microsoft Office applications, the wide variety of nonengineering roles is also an immense advantage. Numerous Microsoft lawyers, accountants, and many other nonengineering employees use dogfood versions of the Office suite for many months preceding the product release.
Dogfood is so important to Microsoft that we are seeing this concept extend into our services. The Windows Live Mail team has a dogfood instance with a set of customers that understand that they will be getting a version of the service that is less stable than that of other users, but they are excited to go through that pain for the opportunity to provide us feedback on how to make the service better.
Accessibility Testing
Accessibility is about removing barriers and providing the benefits of technology for everyone.
Accessibility is the availability of equal access to the information and tools that anyone can use to accomplish everyday tasks. This includes everything from copying files to browsing the Web to creating new documents. A user’s capacity to create and maintain a mental model of the application, Web site, or document content, as well as the user’s ability to interact with it, is the root of software accessibility.
One of Microsoft’s largest customers, the United States federal government, requires that their information technologies take into account the needs of all users. In 1998, Section 508 (http://www.section508.gov) of the Rehabilitation Act was enacted to eliminate obstacles and create opportunities for people with disabilities. Microsoft is committed to supporting Section 508. An internal Accessibility Business Unit works with engineering teams, assistive-technology companies, and disability advocates to ensure that people with disabilities can use software developed by all software companies.
Several layers of specialty features—all of which play an important part in how accessible a program is—define accessibility. Some of the features that must be tested for any application include the following:
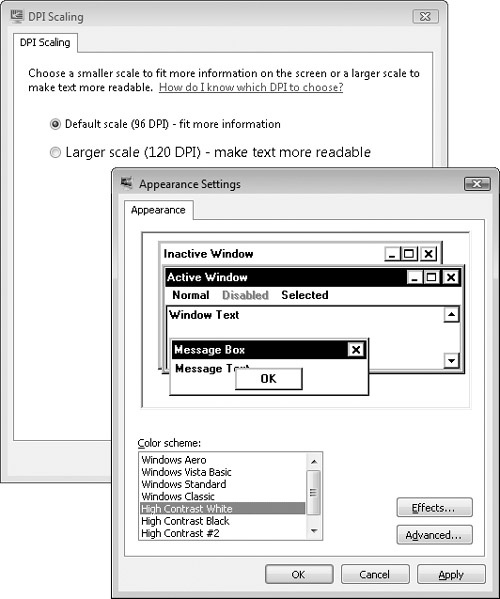
Operating system settings. Operating system settings include settings such as large fonts, high dots per inch (DPI), high-contrast themes, cursor blink rate, StickyKeys, FilterKeys, MouseKeys, SerialKeys, ToggleKeys, screen resolution, custom mouse settings, and input from on-screen keyboards, as shown in Figure 11-7.
“Built-in” accessibility features. Built-in features include features and functionality such as tab order, hotkeys, and shortcut keys.
Programmatic access. Programmatic access includes implementation of Microsoft Active Accessibility (MSAA) or any related object model that enables accessibility features.
Accessible technology tools. Testing of applications using accessibility tools such as screen readers, magnifiers, speech recognition, or other input programs is an important aspect of accessibility testing. Microsoft maintains an accessibility lab, open to all employees, filled with computers installed with accessibility software such as screen readers and Braille readers.
Accessibility Personas
Personas are descriptions of fictional people used to represent customer segments and the way these customers use our products. By using personas, teams can focus on designing and developing the right set of features to support these users. At Microsoft, most product teams identify and create user personas early in the product cycle and refer to these personas throughout the entire life of the product.
Product teams might create three to five (or more) personas for their product, but many personas span all Microsoft products. More than 10 personas were created for helping teams gain a better understanding of how customers with specific types of disabilities use computers and how they might interact with software. For example, the persona for a blind user includes information on the person’s usage of screen readers (screen readers cannot read text in bitmaps and in some custom controls) and expected navigation features. Similarly, the persona for users who are deaf or hard of hearing helps the engineering team remember that sounds should be customizable, volume should be adjustable, and that alternative options might need to be supplied for caller ID or voice mail features.
Testing for Accessibility
Using personas is an important approach and something that Microsoft capitalizes on for numerous facets of testing. Some approaches of accessibility testing are common to most applications and should be part of any testing approach. Some of these test lines of attack are as follows:
Respect system-wide accessibility settings. Verify that the application does not use any custom settings for window colors, text sizes, or other elements customizable by global accessibility settings.
Support high-contrast mode. Verify that the application can be used in high-contrast mode.
Realize size matters. Fixed font sizes or small mouse targets are both potential accessibility issues.
Note audio features. If an application uses audio to signal an event (for example, that a new e-mail message has arrived), the application should also allow a nonaudio notification such as a cursor change. If the application includes an audio tutorial or video presentation, also provide a text transcription.
Enable programmatic access to UI elements and text. Although this sounds like a testability feature (enable automation tools), programmatic access through Active Accessibility or the .NET UIAutomation class is the primary way that screen readers and similar accessibility features work.
Testing Tools for Microsoft Active Accessibility
The Active Accessibility software development kit (SDK) includes several worthwhile tools for testing accessibility in an application, particularly applications or controls that implement Microsoft Active Accessibility (MSAA).
With the Accessible Explorer program, you can examine the IAccessible properties of objects and observe relationships between different controls.
With the Accessible Event Watcher (AccEvent) tool, developers and testers can validate that the user interface (UI) elements of an application raise proper Active Accessibility events when the UI changes. Changes in the UI occur when a UI element is invoked, selected, has a state change, or when the focus changes.
With the Inspect Objects tool, developers and testers can examine the IAccessible property values of the UI items of an application and navigate to other objects.
The MsaaVerify tool verifies whether properties and methods of a control’s IAccessible interface meet the guidelines outlined in the specification for MSAA.[1] MsaaVerify is available in binary and source code forms at CodePlex (http://www.codeplex.com).
Whether you are satisfying government regulations or just trying to make your software appeal to more users, accessibility testing is crucial.
Usability Testing
Usability and accessibility are quite similar, but there is a significant difference between the two terms to consider. Accessibility is the ability of anyone to use the user interface, whereas usability refers to how easy it is for the user to understand and interact with the UI. Accessibility features can enable higher degrees of usability, but usability can mean a lot more. Helpful documentation, tooltips, easy-to-discover features, and numerous other criteria all contribute to highly usable software.
When testing the user interface of an application, usability testing includes verifying that the features of the application are discoverable and work as a user expects them to. Similarly, when testing an API or object model, usability testing includes verifying that programming tasks using the exposed functions are intuitive and that they perform the expected functionality. Usability testing also includes verifying that documentation is correct and relevant.
Usability Labs
Many product teams at Microsoft take advantage of usability labs. Testers are usually not directly involved in conducting the study, but they do use the data from the study to influence their approach to usability testing. For example, although the study might reveal design issues to be addressed by Program Management or Development engineers, testers often use the data on how the application is used to build scenarios or to weight testing in specific areas based on usage patterns. Of course, many other factors lead to determining the modeling of how customers use an application. (Some of those techniques and tools are covered in Chapter 13.)
The formal usability studies at Microsoft are conducted in a lab with a layout similar to the one shown in Figure 11-8. Participants spend approximately two hours using an application and are usually asked to accomplish a few targeted tasks.

The goals of these sessions vary, but common questions that these studies seek to answer include the following:
What are the users’ needs?
What design with solve the users’ problems?
What tasks will users need to perform, and how well are users able to solve them?
How do users learn, and then retain their skills with the software?
Is the software fun to use?
When we talk to teams about usability testing, we consistently share one bit of advice: Usability testing will always occur . . . eventually. It’s your choice whether you do it as part of your testing effort or leave it for the customer. Early usability testing makes the product more successful in the eyes of the user community and has a huge impact on reducing the number of support calls for your product.
Note
Microsoft has more than 50 usability labs worldwide, and more than 8,000 people a year participate in Microsoft usability studies.
Usability testing continues to grow and advance at Microsoft. New techniques used more often include eye tracking, remote usability testing over the Internet, and advances in playtest usability testing for games.
Security Testing
Security testing has become an integral part of Microsoft’s culture in recent years. Reactions to malicious software and spyware have given all engineers at Microsoft a security mindset. Security testing is such a major subject that it is more worthy of an entire book than a section of this single chapter. In fact, a quick browse on an online bookstore shows me no less than half a dozen books on security testing, including books written by Microsoft employees such as Hunting Security Bugs by Gallagher, Landauer, and Jeffries, as well two security books in the How to Break . . . series by James Whittaker (who is also a noted software security expert). Additionally, Writing Secure Code by Howard and LeBlanc is on many testers’ bookshelves at Microsoft. Any of these books or others on the subject will be beneficial if you desire depth or breadth in this area.
The tester’s role in security testing is not just to find the bugs, but to determine whether and how the bug can be exploited. A few of the key approaches and techniques for security testing are discussed in the following subsections.
Threat Modeling
Threat modeling is a structured activity that reviews application architecture to identify potential security threats and vulnerabilities. Threat modeling is in wide use at Microsoft, and testers are highly active participants in the threat model process. The familiarity testers typically have with input validation, data handling, and session management drives them toward being key contributors when examining applications for potential security issues.
Threat models—as do many other concepts discussed in this chapter—work best when carried out during program design. A threat model is a specification just like a functional specification or design document. The big difference is that the intention of a threat model is to identify all possible ways that an application can be attacked, and then to prioritize the attacks based on probability and potential harm. Good threat modeling requires skills in analysis and investigation—two skills that make Test a well-suited participant in the process. More information about threat modeling, including examples, can be found in Threat Modeling by Frank Swiderski and Window Snyder (Microsoft Press, 2004).
Fuzz Testing
Fuzz testing is a technique used to determine how a program reacts to invalid input data. A simple approach would be to use a hex editor to change the file format of a data file used by a program—for example, modifying the bits in a .doc file used by Microsoft Word. In practice, the process is nearly always much more methodical. Rather than randomly changing data, fuzz tests usually involve manipulating the data in a manner that exposes a potential security issue such as an exploitable buffer overrun. Fuzz testing is equally applicable to database testing, protocol testing, or any other situation where part of a system or application must read and interpret data.
Summary
Functional testing is extremely important—as are many of the techniques and methods used to carry out functional testing effectively. The point that teams sometimes forget is that customers don’t care about the number of bugs found or the number of tests that failed or code coverage rates. These are all important and valued ingredients of the testing recipe, but in the end, customers care about the non-functional aspects of the product. They want secure, reliable software that easily does what they want to do. They want software with easily discoverable features that responds to their actions quickly.
Non-functional testing is an integral complement to functional testing and is critical to establishing whether a product is of high quality and ready to ship. A dilemma with nonfunctional attributes is that most aspects require significant thought early in the development process; but measurement of many attributes cannot happen until the customers use the software. The key to solving this dilemma is to keep the customer voice—through personas or other similar mechanisms—at the forefront of all testing efforts.