
2
Fundamentals of Experimental Design
Introduction
The experiments dealt within this book are comparative: the purpose of doing the experiments is to compare two or more ways of doing something. In this context, an experimental design defines a suite, or set, of experiments. In this suite of experiments, different experimental units are subjected to different treatments. Responses of the experimental units to the different treatments are measured and compared (statistically analyzed) to assess the extent to which different treatments lead to different responses and to characterize the relationship of responses to treatments. This process will be illustrated numerous ways throughout this book.
Agricultural experimentation, which gave rise to much of the early research on statistical experimental design (see, e.g., Fisher 1947), provides a simple conceptual example. An experimenter wants to compare the crop yield and environmental effects for two different fertilizers. The experimental units are separate plots of land. Some of these plots will be treated with Fertilizer A, and some with Fertilizer B. For example, Fertilizer A may be the currently used fertilizer; Fertilizer B is a newly developed alternative, perhaps one designed to have the same or better crop growth yields but with reduced environmental side effects. Better food production with reduced environmental impact is clearly something a research scientist and the public could be passionate, or at least enthusiastic, about.

In this conceptual experiment, the selection of the plots and the experimental protocol will assure that the fertilizer used on one plot does not bleed onto another. Schedules for the amount and timing of fertilizer application will be set up. Crops will be raised and harvested on each plot, and the crop production and residual soil chemicals will be measured and compared to see if the new fertilizer is performing as designed and is an improvement over the current fertilizer.
This example can be readily translated into other contexts:
- Medical experiments in which the experimental units are patients and the treatments evaluated might be a new medication, perhaps at different dosage levels, and a placebo
- Industrial experiments in which different product designs or manufacturing processes are to be compared
- Market research experiments in which the experimental units are consumers and the treatments are different advertising presentations
- Education experiments in which the experimental units are groups of children and the treatments are different teaching materials or methods
The possibilities are endless, which is why experimental design is so important to scientific and societal progress on all fronts.
Note the importance of running comparative experiments. If we applied Fertilizer B to all of our plants in this year’s test, we might get what appear to be very satisfactory yields, perhaps even better than Fertilizer A got in previous years. But we would not know whether Fertilizer A would have gotten comparable yields this year due, say, to especially favorable growing conditions or experimental care compared to previous years. To know whether B is better than A, you have to run experiments in which some experimental units get A, some get B, and all other conditions are as similar as possible.
Moreover, you have to assign A and B to experimental units in a way that does not bias the comparison. And you need to run the experiment with enough experimental units to have an adequate capability to detect a difference between fertilizers, relative to the natural variability of crop yields. For a wide variety of reasons, crop yields on identically sized, similar plots of land, all receiving the same fertilizer treatment, will vary; they won’t be identical. (As car commercials warn about gas mileage: actual results may vary.) The potential average crop-yield differences between plots with Fertilizer A and plots with Fertilizer B have to be evaluated relative to the inherent variability of plots that receive the same fertilizer. In experimental design terminology, to do a fair and effective comparison of Fertilizers A and B, you have to randomize and replicate. These are two principles of experimental design, discussed later in this chapter.
Experimental Structure
The common features of all the preceding examples, the building blocks of a comparative experiment, are:
- Experimental units (eus)—the entities that receive an independent application of one of the experiment’s treatments
- Treatments—the set of conditions under study
- Responses—the measured characteristics used to evaluate the effect of treatments on experimental units
Basically, in conducting an experiment, we apply treatments to experimental units and measure the responses. Then we compare and relate the responses to the treatments. The goal of experimental design is to do this informatively and efficiently. The following sections discuss the above aspects of experimental structures.
Experimental units
The choice of experimental units can be critical to the success of an experiment. In an example given by Box, Hunter, and Hunter (1978, 2005) (which will be abbreviated BHH throughout this book), the purpose of the experiment is to compare two shoe-sole materials for boys’ shoes. The experimental unit could be a boy, and each boy in the experiment would wear a pair of shoes of one material or the other. Or the experimental unit could be a foot, and each boy would wear one shoe of each material. As we shall see, the latter experiment dramatically improves the precision with which the wear quality of the two materials can be compared. Where one foot goes, the other goes also, so the wear conditions experienced (the experimental protocol is for the boys to wear the shoes in their everyday lives for a specific period of time) are very much the same (skateboarding and other one-foot dominant activities not allowed). Such is not the case for different boys with different activities. Some boys are just naturally harder on shoes than other boys. As will be seen in Chapter 3, the data from this experiment show much more variability of shoe wear among different boys than there is between the two feet of one boy. This difference translates into a much more precise, efficient, comparison of shoe materials when the experimental unit is a foot than when it is a boy.

The selection of the boys needs to be discussed. The experiment described by BHH included 10 boys. It is possible, but unlikely (and not stated), that these 10 boys were randomly selected from some well-defined “population,” such as all the fifth-grade boys enrolled in Madison, Wisconsin, schools on October 1, 1975. Random sampling from identified populations is key to the validity and reliability of opinion polls and industrial quality control and can be used to select experimental units (or pairs of eus in this case) for an experiment. However, as will be discussed in Chapter 3, it is the random assignment of treatments to experimental units that establishes the validity of the experiment, not the random selection of the experimental units, themselves.
It is more likely that the boys are a “judgment sample” (Deming 1975), selected perhaps for convenience (such as children of the shoe company’s employees or all the boys in one particular classroom in a nearby school). This nonrandom selection would be based on an informed judgment by shoe company scientists that the boys selected are likely to subject the shoes to wear conditions that are “representative” of what the general population of boys would inflict on the company’s shoes. In fact, the boys may have been selected deliberately to span the plausible range of wear conditions. For any such judgment sample selections, any extension of the results of this experiment to the general shoe-wearing population of boys will rest on such subject-matter knowledge. The conclusions drawn will be a subject-matter inference, not a statistical inference. The statistical inference (Chapter 3) will be whether or not observed differences in wear for the two shoe material are “real or random.”
Why 10 boys, not 5, 50, or 100? Statistical analyses addressed in later chapters can shed some light on this issue, but these analyses must be built on subject-matter knowledge about the cost of experimentation and the anticipated variability in shoe-sole wear and its measurement. For the sake of completing the story line of the BHH experiment, let’s suppose that this is a pilot experiment aimed at providing a preliminary evaluation of the “wearability” of the cheap substitute material B and of the variability of shoe wear among boys and between a boy’s two feet. Ten boys just happened to be available. (Available time and resources often drive experimental designs and other statistical studies. Afterward, we find out if we collected enough data or more than were needed. Also, textbook examples tend to be small for reasons of space and clarity.) If shoe-sole material B is promising, more extensive experimentation, sized based on what we learn in this pilot experiment and on the degree of precision required to support a final decision, will follow.
The experimental unit issues in this shoe experiment are indicative of issues that arise in other contexts. In the agricultural experiment discussed previously, the location, size, and layout of the plots of land can be key to an experiment’s success, both in its findings and in its credibility. In medical laboratory experiments, the choice of animal experimental units—mice, rats, gerbils, or something else—can be important.
In all of these situations, subject-matter expertise is the primary determinant of the experimental unit. The statistician can evaluate the ramifications of different choices, for example, a boy vs. a foot, an acre vs. a hectare, etc., but subject-matter knowledge and experimental objectives will define the choices.
Blocks and block structures
There are many ways that the experimental units selected for an experiment can be organized or structured. The simplest situation is to have one group of homogeneous experimental units (meaning similar, not identical), such as individual plots of land in a field or a garden in which the soil quality is presumed or known to be essentially the same throughout. In a medical experiment, the experimental units could be patients in a specified demographic or medical category.
Alternatively, an experiment can have multiple groups of experimental units. The groups might differ in some recognizable way, but within each group, the experimental units would be relatively homogeneous. An example is plots of land in different fields or gardens or regions. The different gardens or regions would be the blocks of eus. In the boys’ shoes experiment, the experimental units—the boys’ feet—were paired (grouped or “blocked”) by boy. There were two experimental units (feet) per boy, and each eu got a different “treatment.” Clearly, a boy’s two feet are more similar to each other, with respect to the wear conditions they experienced, than are the feet of two different boys, whose physiques and activity levels could differ substantially. Hence, there is more homogeneity of experimental units within a group than between groups. Conventional terminology is to refer to groups of experimental units as “blocks.”
An alternative, but strange, way to do the shoe-sole experiment would be to ignore the pairing of a boy’s feet and randomly assign 10 of the 20 ft in the experiment to material A and the others to B. This assignment would likely have some boys with two shoes of one material and other boys with one shoe of each material. This “experimental design” would clearly not be very efficient or effective for comparing the two materials.
Blocks of experimental units can be defined by combinations of more than one variable. For example, patients in a medical experiment might be grouped by sex and age categories, particularly if it was known or suspected that different age groups and the two sexes might respond differently to the treatments in the study. With three age groups, for example, there would then be six groups defined by the combinations of age and sex categories. The different treatments would be applied to subsets of the patients in each group or block of experimental units.
Expressing this grouping in conventional experimental design terminology, we would say that there are two blocking factors, sex and age, and that these two factors are crossed—the same age categories are used for both men and women in the study.
Another experimental unit structure has nested factors. For example, in a manufacturing situation, the items produced, which, in a subsequent experiment, would be subjected to various treatments, could be grouped by the factory that produced them and then by assembly line within factories.
The blocking factors would be factory and assembly line, and the assembly line would be nested in factories. These factors are nested, not crossed, because assembly lines 1 and 2 in one factory are not the same as assembly lines 1 and 2 in another. The two assembly lines labeled line 1 are physically distinct. Figure 2.1 illustrates this structure: four (color-coded) groups of experimental units with the indicated structure. Subsequent experiments might be to evaluate properties of the tires, in this example, perhaps by testing them on a machine that simulates impacts and measures the blowout resistance of the tires as a function of impact velocity and inflation pressure. Comparisons of the test data between factories and among assembly lines could indicate manufacturing problems.
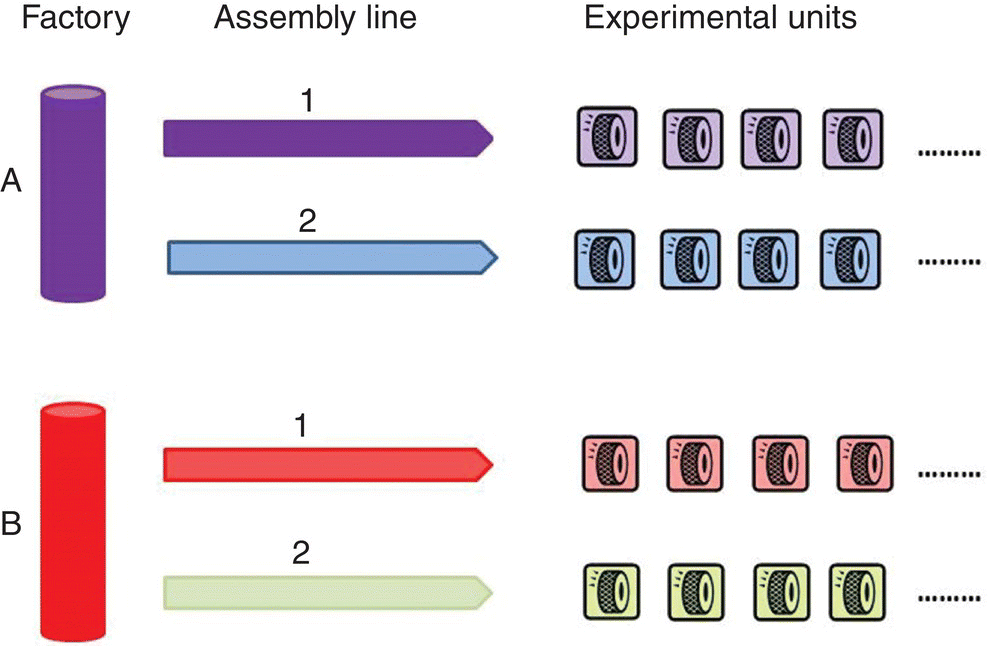
Figure 2.1 Nested Experimental Unit Structure.
Chapters 4–7 in this book generally start with an experimental unit structure that defines a class of experimental designs. Those structures and the data analyses they lead to will be discussed in detail in those chapters. Blocking, as one of the principles of experimental design, is discussed later in this chapter.
Experimental unit structure can become quite complex, especially when experimental units of one size are split into smaller units. Agricultural and industrial experiments offer the most intuitive examples of such situations. Suppose 20 plots of reasonably homogeneous land are available, and one of four varieties of wheat will be planted on five plots each. Then, after planting and germination, each plot is divided into four quadrants so that different fertilizers (randomly assigned) can be applied to each quadrant. Then, after the plants have grown for a predetermined period, each quadrant is divided into two halves (now octants) for the application of two different insecticides. Thus, there are three levels, or sizes, of experimental units in this experiment, linked to the treatments that are applied: for wheat varieties, the pertinent experimental unit is a plot; for fertilizer, the experimental unit is a quadrant; and for insecticides, the experimental unit is an octant. The statistical analysis of the resulting data (to be seen in Chapter 7) will have to account for these different experimental units in the same experiment.
Treatments and treatment structures
Experimental objectives also are the starting point for defining treatments. For example, a researcher may want to find the optimum time and temperature settings in a process such as baking bread or in producing computer microchips. Previous work or theory—subject-matter knowledge—may suggest a starting point for the two “treatment factors,” time and temperature, as well as a range of these two factors to be considered. The experimental conditions to be evaluated and compared, that is, the “treatments,” or “treatment combinations,” will be a selected set of time and temperature combinations. Statistical considerations help select efficient, potentially informative combinations, subject to constraints dictated by the subject matter and built on the foreknowledge of the possible or, likely, the nature of the dependence of an experimental unit’s response on time and temperature. In both complex and deceptively simple situations, there may be a large number of factors that potentially influence the response of an experimental unit, and there is generally a trade-off to be determined between the size of the experiment and the number of treatment factors and treatment combinations to be included in the experiment. Subject-matter understanding is essential to making those trade-offs sensibly.

As just indicated, treatments can be structured according to multiple “factors.” Treatment factors can be either categorical, such as types of shoe-sole material, or quantitative, such as time, temperature, and other physical variables.
In an experiment, each factor has a selected “levels.” For example, for a categorical variable, such as type of fertilizer, the levels are the names or identifiers of the different fertilizers in the experiment. The levels of a quantitative factor, such the amount of fertilizer applied, would be selected amounts, expressed, for example, in pounds per acre. The treatments, or “treatment combinations,” then can consist of all combinations of factors and factor levels or just a subset of the possible combinations. For example, if time and temperature each have three levels, say, low, medium, and high, then the full set of treatments that can be constructed from these two factors are the nine possible combinations of time and temperature levels. We say treatments created this way have a “factorial treatment structure.” In some contexts, when the treatment combinations are tabulated or entered into a spreadsheet, the suite of experiments is called an experimental matrix. Experiments with this structure provide an efficient way to evaluate the separate and the combined effects of the factors on responses of interest.
The simplest treatment structure is that of a single factor, such as fertilizer type or shoe material in examples already discussed. The experiment will be done to compare the responses as a function of the different levels of this factor. Next, treatment structures (as was the case for block structures) can be based on two factors, three factors, etc. It can be the case that the resulting number of multifactor treatment combinations becomes too large to be practical. “Fractional factorial” treatment structure (to be discussed in Chapter 5) is the specification of a well-selected subset of the possible treatment combinations. The determination of a fractional factorial set of treatments has to be done with care in order to maximize the amount of information the experiment provides pertaining to the separate and combined effects of the treatments. Clearly, some potential information about treatment effects has to be sacrificed when using an experiment with a fractional factorial set of treatments, and, again, subject-matter understanding, combined with statistical analysis, is necessary for determining where that sacrifice is to be made.
Another aspect of treatment structure is that the treatment factors can either be crossed or nested, just as is the case for blocking factors. Two factors are crossed when the levels of one factor are the same when used in combination with each level of the other factor. For example, in a crossed-factor treatment structure, the temperature levels in the baking experiment would be the same for each level of the time factor.
The treatment combinations resulting from crossed factors, however, may include some combinations that the experimenter knows are not feasible—will not produce edible cookies. The knowledgeable experimenter knows that the higher the temperature, the shorter the baking time should be. Thus, the selected levels of baking time (say, low, medium, and high) considered in the experiment would be different at high temperature than at low temperature. When the levels of one factor are not the same at each level of the other factor, the factors are “nested.” Once again, subject-matter understanding is essential to recognizing this relationship and designing an experiment appropriate to it.
Figure 2.2 shows the treatment combinations for two crossed and nested factors, each with three levels.

Figure 2.2 Crossed and Nested Combinations of Treatment Factors. The three levels of B are different at the three levels of A; B is nested in A.
The plots in Figure 2.2 are appropriate for two quantitative factors. Factors can also be crossed or nested when one or both factors in a two-factor experiment are qualitative. For example, in a medical experiment, one factor might be medication source (a qualitative factor with levels that are different manufacturers of pain-relief medications), and a second factor might be dose (quantitative), with different levels for each manufacturer based on manufacturer recommendations.
(Note—The focus in this discussion on experimental unit and treatment “structures” follows that of Scott and Triggs (2003). This approach, which I encountered when I taught for a semester at the University of Auckland, is somewhat unusual and, I think, a very useful way to present basic features of an experimental design).
The discussion thus far, illustrated by Figure 2.2, has defined factor levels generically, as low, medium, and high. Choosing the numerical levels of those factors, though, is critical to the meaningfulness and success of the experiment. You don’t want to run the experiment over such a tight range of the factors that only minor differences in the response result and inference outside of that tight experimental region cannot be supported. On the other hand, you don’t want to run the experiment over such a wide range of factor levels that, for example, at the selected low temperature the cookies don’t get cooked and at high temperature they’re burned to a crisp. You don’t want to starve your laboratory mice or incapacitate them by feeding them too little or too much of a dietary supplement. General guidance is to “be bold” in selecting factor ranges—give the factor a good opportunity to affect the response—but not foolhardy. Subject-matter knowledge is essential to knowing the physical or biological or business limits of the treatment factors in a practical experiment. Pilot experiments are useful in defining appropriate ranges for the experimental factors.
Response measurement
For an experiment to be effective, the effect of treatments on experimental units must be reflected in the measured responses of the experimental units. Sometimes, the choice of measurements that reflect the effect of treatments on experimental units is obvious; other times, it is not. Characteristics such as health, quality of life, mechanical fit, customer satisfaction, environmental impact, and learning can be difficult to capture quantitatively.
Once it has been decided what to measure, measurement devices and techniques can differ. For example, in the shoe example, one could measure “wear” as the percent decrease in sole thickness at one central point on the sole or as the average wear, or maximum wear, across several points at which the decrease in sole thickness is measured. Sole thickness might be measured with a foot ruler, a caliper, or a laser. The duration of the experiment and possible intermediate times at which measurements are made must also be decided as part of the measurement process. Obviously, the number and locations of the points at which to measure sole wear and the choice of measuring device could influence our ability to detect differences in wear of the two shoe-sole materials. In many fields, measurement protocols have been developed and improved over a long period of time. Ever more modern technology, though, can enhance response measurement.
Though we will focus in this book on single responses, it is generally appropriate to measure multiple characteristics—to record more than one response variable on each experimental unit. For the shoe experiment, we might try to measure comfort as well as wear. Consider an education experiment in which a class is the experimental unit. Tests could be given to the students at the end of the experiment that measure class “learning” in various subject areas. One could also measure class performance in these areas by average test score, the median test score, or some other variable such as the percentage of the class who exceed some threshold score, or all of these and more.
In addition to measuring responses that can reliably show treatment effects, other possibly influential variables (sometimes called “ancillary variables”) should also be measured. For example, in the boys’ shoes experiment, it might be pertinent to know certain characteristics of the boys, such as age, weight, and activity level (e.g., did a boy walk to school or not?).
Principles of Experimental Design
An experimental design consists of overlaying a treatment structure on an experimental unit structure and then measuring pertinent responses of the experimental units. The total measurement process includes experimental protocol—the care and feeding of the experimental units throughout the course of the experiment and the controls in place to assure the experiment are carried out as designed. The way in which this overlay is done will determine what questions can be answered by the experiment, and it will determine the precision with which relationships can be characterized. Three experimental design principles underlie this overlay:
- Replication (assignment of individual treatments to multiple experimental units)
- Randomization (assignment of treatments to experimental units by using a chance mechanism)
- Blocking (assignment of treatments within multiple groups of experimental units)
Application of these principles determines the validity and utility of the experiment.
Replication
Things vary. That’s a fundamental characteristic of the real world. No two plots of land, even side by side, and the crop-growing environments they experience will be the same. Patients taking the same medication will respond differently. Neither cookies nor integrated circuits, prepared by the same recipe, will be identical from cookie to cookie or from batch to batch. The raw input material and the processing will vary, perhaps in small ways, perhaps in large. This variability means that to compare three cookie recipes, for example, it is not enough to cook only one batch by each recipe. To determine whether an apparent difference is real or could just be “random” (meaning only due to the inherent variability of the phenomenon being studied), we need to know whether any apparent differences between recipes are greater than the inherent variability of multiple batches for cookies produced by following the same recipe. To measure that inherent variability, we need to “replicate”—the experiment needs to have multiple experimental units that receive independent applications of the same treatment. The variability of responses over these replications, which has the statistical term, experimental error, provides a yardstick against which we measure differences among treatments.

Replication—multiple experimental units receiving independent applications of a treatment—is different from subsampling within an experimental unit or repeated measurements on the same experimental unit. For example, suppose an experiment consisted of growing variety A tomato plants on one plot of land and variety B tomato plants on another plot of land. If we then measure tomato yield on each plant, the single plant yields are subsamples within a single experimental unit; they are not replicate experimental units.
Chemical processes are often characterized by taking measurements on a specimen drawn from a well-mixed vat of material produced by a single process run. Drawing and measuring multiple specimens from one run is a case of multiple measurements of one experimental unit. It does not constitute true replication of the process. True replication would be multiple vat loads, produced independently by the same protocol.
One more example: teaching single classes by each of four teaching methods, then testing the students, does not constitute true replication. A student is a subsample of the experimental unit, not an experimental unit. The class is the experimental unit—the entity to which a treatment is applied. Students within a class all experience the same teaching method, taught by a single teacher, over the same time period, and there are all sorts of within-class dynamics and personalities that introduce associations among the students and their performance. As mentioned earlier, a measurement on the experimental unit of a class could be the class average, the class median, or some other measure of class performance, such as the percentage exceeding a test score that defines the minimally satisfactory achievement. It does not matter whether there are 10 students per class or 50; there is still only one experimental unit per treatment. You would have to have multiple classes taught by each method to have true replication—to be able to make a valid comparison of methods. (The number of students per class is a measurement issue: the class average of a class of 50 students is a more precise measurement than the average of a class of 10 students, but the effectiveness of a teaching method could depend on class size; class size might a factor to be incorporated into the experimental design.)
Replication contributes to statistical analysis of the experimental data in two ways:
- It provides the data from which to estimate the inherent variability of experimental units.
- It influences the precision with which the treatments can be compared.
The larger the number of replications, the better one can estimate inherent variability and the more precisely one can estimate, for example, average differences in patients’ response for different treatments. Choosing the number of replications is a critical part of experimental design. The choice generally requires a trade-off between subject-matter considerations—primarily cost, time, and the availability of people, materials, and facilities—and the statistical considerations of estimation precision. Guidance and methodology for determining the extent of replication are given in later chapters.
Randomization
Suppose that we have a set of experimental units and have defined the treatments that will be applied. How should treatments be assigned to experimental units? The answer is randomly. This means literally drawing numbers from a hat or simulating that drawing via a computer or other means. For example, if one has 20 experimental units and four treatments to assign, one could number the experimental units from 1 to 20; then list the numbers, 1, 2, 3, …, 19, 20, in a computer-generated random order; and then assign treatment A to the experimental units corresponding to the first five numbers, treatment B to the next five, etc.
One might suppose an experimenter should make assignments in as fair and balanced manner as possible by considering the characteristics of each experimental unit and trying to make sure those characteristics are balanced across the groups of experimental units assigned to each treatment. But, in general, this is very hard to do. Not all pertinent characteristics of the experimental units are apparent—important characteristics may not be realized or measurable—and there may be too many characteristics to attempt to balance. And, no matter how fair the experimenter tries to be, it is hard to prevent subtle and unintentional biases from influencing the assignment of treatments. For example, if, in a medical experiment, individual doctors are permitted to assign treatments to patients by their own judgment, subjective considerations are bound to intrude. One then will not know whether apparent treatment differences are due to biases in the assignment of treatments to patients or are actually due to the treatments. By using a randomization device to make the treatment assignments, we remove the possibility of bias or the appearance of bias in the assignment, and we enhance the credibility of the experiment. Medical experiments are often done with a “double-blind” protocol for the assignment of treatments. Neither the doctor nor the patient knows what medication is assigned.

A major reason for random assignment of treatments to experimental units is that, as will be seen in the next chapter, statistical analysis involves a comparison of the “data we got” to a “probability distribution of data we might have gotten.” Randomization gives us a means of creating that distribution of data we might have gotten and in so doing assures us that valid comparisons of treatments are obtained (Fisher 1947; Box, Hunter, and Hunter 2005).
There are situations in which randomized assignment of treatments to experimental units cannot be done, ethically or legally. For example, you cannot recruit a large group of teenagers for a study on tobacco effects and then randomly assign half of them to smoke 10 cigarettes a day and the other half not to smoke at all, say, for the next 10 years in both cases. In the social sciences, it is difficult to run a randomized experiment in which, for example, one group of randomly selected preschoolers is enrolled in Head Start and another randomly selected group is not allowed to enroll. (There are exceptions in which participants are selected by lottery from a pool of applicants, although eligible participants whose parents did not apply would be left out, so the assessment of the Head Start effect would pertain to families who signed up for the Head Start enrollment lottery. Thus, any inference about the effect of Head Start would apply among children whose families applied to participate in Head Start.) Researchers in such situations have proposed nonexperimental alternatives for evaluating social programs, such as by matching, to the extent possible, voluntary participants and nonparticipants. Characteristics such as age, race, sex, ethnicity, zip code, and family income are candidate matching variables. It is not clear that these approaches are successful (Peikes, Moreno, and Orzol 2008). Of course, though, well-designed experiments can occasionally be misleading, also. Randomization and replication, though, limit the risk to a known level. That cannot be said of nonexperimental studies.
Blocking
The previous subsection on “experimental unit structure” identified one structure as groups, or blocks, of experimental units. Such groups can be based on inherent characteristics of the experimental units, for example, male and female subjects in a medical experiment or groups of experimental plots of land in different locations and climates for an agricultural experiment.
Blocks can also be constructed or assembled by an experimenter as a means of enhancing the precision with which treatments can be compared. As an example, consider a chemical process in which it is planned to compare four treatments over a total of 20 runs (experimental units), scheduled as four per day for one 5-day work week. One way to run the experiment is to randomly assign the treatments to the 20 experimental units (five runs per treatment), without regard to which day any given treatment will be run. That is, the experimenter could regard the 20 available time periods as a homogeneous set of experimental units (a single block) and randomly assign the treatments to them. Thus, on any day, some treatments may be run more than once, some not at all. Figure 2.3a shows one random assignment of the four treatments to the 20 experimental units (periods).

Figure 2.3 (a) Completely Randomized Assignment of Treatments. (b) Random Assignment of Treatments within Each Block (Day).
Suppose that there are day-to-day differences in the process that are related, perhaps, to day-to-day environmental changes, personnel assignments, or equipment setup activities. These day-to-day differences will inflate the variability of the multiple experimental units that receive the same treatment, relative to a situation in which there is no extraneous day-to-day variation. Note that in Figure 2.3a T1 is applied on days 1–4, while T3 is applied on days 1, 2, and 5. Thus, day-to-day variability affects the responses in a systematic way, and the variability of eus that receive the same treatment would be inflated by day-to-day variability. The only “clean” comparisons of T1 and T3 are in the tests done on days 1 and 2: both treatments were done on these two days, so the day-to-day differences cancel out of the difference between treatments.
Alternatively, an experimenter can cancel out day-to-day variation by blocking the experimental units and assignment of treatments as follows: on each day, each of the four treatments would be run once, randomly assigned to the four time periods. Figure 2.3b illustrates one such block-by-block random assignment. With this design, the treatments can be compared within each block (day), and then the within-block treatment differences can be averaged across days. The inherent variability yardstick against which the treatment comparisons will be gauged (in certain situations to be discussed in the chapter on randomized block designs) is only within-day variation; among-days variation is eliminated from the comparison.
On the other hand, there is a convenient design, a simplification that a clever lab technician might decide would work just as well and save time: run treatment 1 five times on day 1, treatment 2 five times on day 2, etc. (some overtime might be required, but setup time between runs could be reduced, so maybe not), and then take Friday off. This bit of improvisation turns a day into the experimental unit, with five samples within each eu, but only one replication of each treatment, hence no valid comparison of treatments. You can’t separate treatment effects from day-to-day differences with this “design.” Variation within a day does not provide a yardstick against which to measure differences between different days. Shortcuts happen, often with noble motives. This is why successful experiments require well-defined experimental protocols and oversight—control of the experimental process.
Subject-matter knowledge is essential to an intelligent specification of blocks. Only someone who understands the process can identify potential sources of variation that can be controlled by blocking. A good statistical consultant, however, will ask probing questions about possible extraneous sources of variability that might be controlled by blocking.
The boys’ shoes experiment discussed previously is an example of a blocked set of experiments in which each block (boy) consisted of two experimental units (feet). However, the alternative to this design is not to randomly assign materials to feet, ignoring the boys they are attached to. This would not be a sensible design. The issue in the shoe experiment is not to block or not to block. Rather, the issue is choice of experimental unit—boy or foot.
Some authors (e.g., Wikipedia 2014) regard blocks as “nuisance” factors: they are not of particular interest. An example is the blocking in Figure 2.3b, by day, in order to eliminate the day-to-day differences from the comparison of treatments. We’re not interested in these particular days; we’ll never see them again. Of course, in the general interest of quality, one should want to know about and take steps to reduce day-to-day variation, but in experiments of this type, the primary motivation for the experiment is to learn about the treatment effects. For that purpose, day-to-day variation is called a “nuisance,” to be dealt with by blocking. But even nuisance factors can be interesting. For example, car-nut lore says do not buy a car that is assembled on Monday or Friday. A well-designed experiment, following the pattern in Figure 2.3b, could substantiate or debunk that notion. As with the case study in Chapter 1, we could learn how to eliminate “nuisance” sources of variability.
In many situations, the factors that define blocks are of direct interest. If we want to compare the effects of different diets, or medical treatments, or TV commercials on people, we may block our subjects by sex because we want to know if such treatments have different effects on men and women. Sex is not a nuisance. Sex is of direct interest.
Blocking also defines the scope of the conclusions that can be drawn from an experiment. In agriculture, a developer of a new variety of corn wants to know whether that variety outproduces other varieties in a (reasonably) wide variety of soils and growing conditions. Thus, the experiment will be blocked by location, with the locations selected to span the desired range of conditions. A new variety that excels only in a very limited set of conditions is not as marketable as one that excels in a broad set of conditions. It takes blocked experiments to fully evaluate the new corn variety versus its competitors and convince farmers, many of whom have learned about experimental design at their university or from friendly local county agents, to buy it. The blocking factor—location—is not a nuisance; it’s key to the experiment.
Bottom Line: Don’t let anybody tell you that blocking is just for nuisance factors.
Control
In a textbook, it is easy to say, “Suppose an experiment was run according to such and such a design and resulted in the data in Table 1.” In real life, though, as already alluded to, there can be many a slip twixt design and data. People and machines are involved. One study participant can decide, “Why should I run the tests in that cockamamie order? It’s easier to do all of the low temperature tests first, then all the high temperature tests next. I can also test many more items simultaneously than they apparently think I can. Whoever planned those tests doesn’t really understand my lab’s capabilities. I’ll simplify this plan, knock these tests off quickly, and go home early.” There go your careful blocking, replication, and randomization plans. There goes your ability to separate real effects and random variation, signal and noise. Consequently, there goes your chance to learn something useful. But don’t blame the innovative team member. Blame the project leaders who didn’t assure that all involved knew the protocol and its importance (scientific and economic—flawed experiments cost money, too).
Experimental protocols need to be established and implemented that prevent such freelancing (and much more subtle modifications) and protect the integrity of the design and subsequent data analysis. Doing this may mean the friendly, local statistician, or research scientist will have to visit the lab, hospital, stores, or classrooms to see where the treatments meet the experimental units. That’s a good thing.
The basic experimental designs to be discussed in Chapters 4–7 will be defined by their blocking, replication, and randomization, and these design characteristics will be emphasized. Though it will be generally assumed that measurements and protocols will be properly handled, the reader should not lose sight of the importance of these aspects of experimental design. A great design on paper can fail if not diligently implemented.
The goal of an experiment is information-laden data, precipitating from a well-seeded cloud and captured for statistical analysis. Methods for distilling and communicating information from experimental data are the topic of the next chapter.
Assignment
Choose a topic of interest to you. Identify an issue that you would like to investigate with a designed experiment. Identify and discuss the experimental units, treatments, response measurement(s), and possible ancillary variables. Describe the experimental protocol for applying treatments and collecting data. Discuss your plans with a fellow student, a teaching assistant, or your instructor. Revise and repeat.
References
- Box, G. E. P., Hunter, W. G., and Hunter, J. S. (1978, 2005) Statistics for Experimenters, 1st and 2nd eds., John Wiley and Sons, New York.
- Deming, W. E. (1975) On Probability as a Basis for Action, The American Statistician, 29, 146–152.
- Fisher, R. (1947) The Design of Experiments, Oliver and Boyd, London and Edinburgh.
- Peikes, D., Moreno, L., and Orzol, S. (2008) Propensity Score Matching: A Note of Caution for Evaluators of Social Programs, The American Statistician, 76, 222–231.
- Scott, A., and Triggs, C. (2003) Lecture Notes for Paper STATS 340, Department of Statistics, University of Auckland, Auckland.
- Wikipedia (2014) Randomized Block Designs, http://en.wikipedia.org/wiki/Complete_block_designs.