
C H A P T E R 14
Implementing Query Hints
Placing hints in SQL is a common and simple approach to improve performance. Hints influence Oracle's optimizer to take a specific path to accomplish a given task, overriding the default path the optimizer may have chosen. Hints can also be viewed as a double-edged sword. If not implemented and maintained properly, they can hurt performance in the long run.
The most popular reason to use hints is simply to get data out of the database faster, and many of the available hints are geared for that purpose. The Oracle database supports more than 60 hints, so it is apparent that hints can be placed in SQL for a multitude of reasons. The purpose of this chapter is to categorize these hints into subsets, and then to show specific examples of some of the popular and most performance-impacting hints.
Some of the reasons to place hints in SQL are to change the access path to the database, change the join order or join type for queries that are doing joins, hints for DML, and hints for data warehouse–specific operations, to name a few. In addition, there are new Oracle 11g hints to take advantage of some of the new features of Oracle 11g.
14-1. Writing a Hint
Problem
You want to place a hint into a SQL statement.
Solution
Place your hint into the statement using the /*+ hint */ syntax—for example:
SELECT /*+ full(emp) */ * FROM emp;
Be sure to leave a space following the plus sign. The /*+ sequence is exactly three characters long, with no spaces. Generally, you want to place your hint immediately following the SQL verb beginning the statement. While it is not required to place this sequence of characters after the SQL verb, it is customary to do this.
How It Works
Hints are delimited by special characters placed within your SQL statement. Each hint starts with a forward slash, followed by the star and plus characters. They end with a star and forward slash:
SELECT /*+ full(emp) */ * FROM emp;
Table 14-1 breaks down many of the most popular hints into specific categories. This table is meant to make it easier to zero in on a hint based on your specific need, so keep in mind that some of these hints actually can fit into multiple categories. Another thing to remember about hints is that for many of them, you can enable a particular feature or aspect, and you can disable that same feature or aspect. For example, there is an INDEX hint to enable the use of an index. There is also a NO_INDEX hint, which disables the use of an index. This is true for many of the available hints within the Oracle database.
For a complete listing of hints, refer to the Oracle Database Performance Tuning Guide for your version of the database.


14-2. Changing the Access Path
Problem
You have a query that you have determined is not taking the access path you desire.
Solution
You can change the access path of your SQL statement by placing an access path hint in your query. The two most common access path hints to place in a query tell the Oracle optimizer to do a full table scan, or use an index. Often, the optimizer does a good job of choosing the best or at least a reasonable path to the data needed for a query. Sometimes, though, because of the specific makeup of data in a table, the statistics for the objects, or the specific configuration of a given database, the optimizer doesn't necessarily make the best choice. In these cases, you can influence the optimizer by placing a hint in your query.
By the time you decide to place a hint in a query, you should already know that the optimizer isn't making the choice you want. Let's say you want to place a hint in your query to tell the optimizer to modify the access path to either perform a full table scan, or change how the optimizer will access the data from table. Full table scans are appropriate if your query will be returning a large number of rows. For example, if you want to perform a full table scan on your table, your hint will appear as follows:
SELECT /*+ full(emp) */ empno, ename
FROM emp
WHERE DEPTNO = 20;
The foregoing hint instructs the optimizer to bypass the use of any possible indexes on the EMP table, and simply scan the entire table in order to retrieve the data for the query.
Conversely, let's say you are retrieving a much smaller subset of data from the EMP table, and you want to get the average salary for those employees in department 20. You can tell the optimizer to use an index on a given table in the query:
SELECT /*+ index(emp emp_i2) */ avg(sal)
FROM emp
WHERE deptno = 20;
![]() Tip Hints with incorrect or improper syntax are ignored by the optimizer.
Tip Hints with incorrect or improper syntax are ignored by the optimizer.
How It Works
Access path hints, like many hints, are placed in your query because you already know what access path the optimizer is going to take for your query, and you believe it will be more efficient using the method you specify with the hint. It is very important that before you use a hint, you validate that you are not getting the access path you desire or think you should be getting. You can also gauge the potential performance gain by analyzing the optimizer's cost of the query with and without the hint.
For example, you want to compare your salary to other jobs in your company, so you write the following query to get, by job title, the minimum, average, and maximum salary.
SELECT job, min(sal), avg(sal), max(sal)
FROM emp
WHERE deptno=20
GROUP BY job;
-----------------------------------------------
| Id | Operation | Name |
-----------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH GROUP BY | |
| 2 | TABLE ACCESS BY INDEX ROWID| EMP |
| 3 | INDEX RANGE SCAN | EMP_I2 |
-----------------------------------------------
If you want to bypass the use of the index in the query, placing the FULL hint in the query will instruct the optimizer to bypass the use of the index:
SELECT /*+ full(emp) */ job, min(sal), avg(sal), max(sal)
FROM emp
WHERE deptno=20
GROUP BY job;
-----------------------------------
| Id | Operation | Name |
-----------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH GROUP BY | |
| 2 | TABLE ACCESS FULL| EMP |
-----------------------------------
Another way you can tell the optimizer to bypass the use of an index is by telling the optimizer to not use indexes to retrieve the data for a given query. In this particular case, it has the same effect as the FULL hint:
SELECT /*+ no_index(emp) */ job, min(sal), avg(sal), max(sal)
FROM emp
WHERE deptno=20
GROUP BY job;
You can also explicitly state the name of the index you wish to bypass:
SELECT /*+ no_index(emp emp_i2) */ job, min(sal), avg(sal), max(sal)
FROM emp
WHERE deptno=20
GROUP BY job;
In both of the foregoing cases, the result is a full table scan. In a different case, you may have a query that could possibly use different indexes. For instance, on our EMP table, we have an index on the DEPTNO column, and we also have an index on the HIREDATE column. If we wanted to execute a query to get the employees that started in the year 1980 for department 20, our query would look like this:
SELECT empno, ename
FROM emp
WHERE DEPTNO = 20
AND hiredate
BETWEEN to_date('1980-01-01','yyyy-mm-dd')
AND to_date('1980-12-31','yyyy-mm-dd'),
----------------------------------------------
| Id | Operation | Name |
----------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP |
| 2 | INDEX RANGE SCAN | EMP_I1 |
----------------------------------------------
In this case, the optimizer chose the EMP_I1 index, which is the index on the HIREDATE column. We can instruct the optimizer to bypass the use of that index:
SELECT /*+ no_index(emp emp_i1) */ job, min(sal), avg(sal), max(sal)
FROM emp
WHERE deptno=20
GROUP BY job;
In this case, we don't necessarily know what the optimizer is going to do next. It may decide to use our other index on the DEPTNO column, or it could choose to perform a full table scan. It is good practice in using hints to be as specific as possible when instructing the optimizer what to do. Therefore, if we place an index hint to tell the optimizer to use the index on the DEPTNO column, we can see that the optimizer now uses that index:
SELECT /*+ index(emp emp_i2) */ empno, ename
FROM emp
WHERE DEPTNO = 20
AND hiredate
BETWEEN to_date('1980-01-01','yyyy-mm-dd')
AND to_date('1980-12-31','yyyy-mm-dd'),
----------------------------------------------
| Id | Operation | Name |
----------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP |
| 2 | INDEX RANGE SCAN | EMP_I2 |
----------------------------------------------
Other examples of index hints are the INDEX_FFS for an index fast full scan, and the INDEX SS for an index skip scan. The INDEX_SS hint is appropriate if you have a table with composite, multi-column indexes. It is possible to have Oracle use the index, even if the query does not use the leading column of the index. At times, the INDEX_SS hint can be beneficial to retrieve data fast, even if the column noted in the WHERE clause isn't the leading column of an index. For example, if we want to get the names of all employees that received a commission, our query would look like this:
SELECT ename, comm FROM emp
WHERE comm > 0;
----------------------------------
| Id | Operation | Name |
----------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS FULL| EMP |
----------------------------------
As noted in the explain plan, no index is used. We happen to know there is a composite index on the SAL and COMM columns of our EMP table. We can add a hint to use this index to gain the benefit of having an index on the COMM column, even though it is not the leading column of the index:
SELECT /*+ index_ss(emp emp_i3) */ ename, comm FROM emp
WHERE comm > 0;
----------------------------------------------
| Id | Operation | Name |
----------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP |
| 2 | INDEX SKIP SCAN | EMP_I3 |
----------------------------------------------
![]() Note Hints influence the optimizer, but the optimizer may still choose to ignore any hints specified in the query.
Note Hints influence the optimizer, but the optimizer may still choose to ignore any hints specified in the query.
14-3. Changing the Join Order
Problem
You have a performance issue with a query where you are joining multiple tables, and the Oracle optimizer is not choosing the join order you desire.
Solution
There are two hints—the ORDERED hint, and the LEADING hint—that can be used to influence the join order used within a query.
Using the ORDERED Hint
You are running a query to join two tables, EMP and DEPT, as you want to get the department names for each employee. By placing an ORDERED hint into the query, you can see how the hint alters the execution access path—for example:
SELECT ename, deptno
FROM emp JOIN dept USING(deptno);
---------------------------------------
| Id | Operation | Name |
---------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | INDEX FULL SCAN | PK_DEPT |
| 3 | TABLE ACCESS FULL| EMP |
---------------------------------------
SELECT /*+ ordered */ ename, deptno
FROM emp JOIN dept USING(deptno);
---------------------------------------
| Id | Operation | Name |
---------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | TABLE ACCESS FULL| EMP |
| 3 | INDEX UNIQUE SCAN| PK_DEPT |
---------------------------------------
Using the LEADING Hint
As with the example using the ORDERED hint, you have the same control to specify the join order of the query. The difference with the LEADING hint is that you specify the join order from within the hint itself, while with the ORDERED hint, it is specified in the FROM clause of the query. Here's an example:
SELECT /*+ leading(dept, emp) */ ename, deptno
FROM emp JOIN dept USING(deptno);
---------------------------------------
| Id | Operation | Name |
---------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | TABLE ACCESS FULL| EMP |
| 3 | INDEX UNIQUE SCAN| PK_DEPT |
---------------------------------------
From the foregoing query, we can see that the table order specified in the FROM clause is irrelevant, as the order specified in the LEADING hint itself specifies the join order for the query.
How It Works
The main purpose of specifying either of these hints is for multi-table joins where the most optimal join order is known. This is usually known from past experience with a given query, based on the makeup of the data and the tables. In these cases, specifying either of these hints will save the optimizer the time of having to process all of the possible join orders in determining the optimal join order. This can improve query performance, especially as the number of tables to join within a query increases.
When using either of these hints, you instruct the optimizer about the join order of the tables. Because of this, it is critically important that you know that the hint will improve the query's performance. Oracle recommends, where possible, to use the LEADING hint over the ORDERED hint, as the LEADING hint has more versatility built in. When specifying the ORDERED hint, you specify the join order from the list of tables in the FROM clause, while with the LEADING hint, you specify the join order within the hint itself.
14-4. Changing the Join Method
Problem
You have a query where the optimizer is choosing a non-optimal join type for your query, and you wish to override the join type by placing the appropriate hint in the query.
Solution
There are three possible types of joins: nested loops, hash, and sort merge. Depending on the size of your tables, certain join types perform better than others. You can use hints to specify the join order that you prefer.
Nested Loops Join Hint
To invoke a nested loops join, use the USE_NL hint, and place both tables needing the join within parentheses inside the USE_NL hint:
SELECT /*+ use_nl(emp, dept) */ ename, dname
FROM emp JOIN dept USING (deptno);
-----------------------------------------------
| Id | Operation | Name |
-----------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | TABLE ACCESS FULL | DEPT |
| 4 | INDEX RANGE SCAN | EMP_I2 |
| 5 | TABLE ACCESS BY INDEX ROWID| EMP |
-----------------------------------------------
The nested loops join is usually best when joining small tables together. In a nested loops join, one table is considered the “driving” table. This is the outer table in the join. For each row in the outer, driving table, each row in the inner table is searched for matching rows. In the execution plan for the foregoing statement, the EMP table is the driving, outer table, and it is seen in the execution plan as the outermost part of the plan. The DEPT table is the inner table, and is shown as the innermost part of the execution plan.
Hash Join Hint
To invoke a hash join, use the USE_HASH hint, and place both tables needing the join within parentheses inside the USE_HASH hint:
SELECT /*+ use_hash(emp_all, dept) */ ename, dname
FROM emp_all JOIN dept USING (deptno);
----------------------------------------------
| Id | Operation | Name | Rows |
----------------------------------------------
| 0 | SELECT STATEMENT | | 1037K|
| 1 | HASH JOIN | | 1037K|
| 2 | TABLE ACCESS FULL| DEPT | 4 |
| 3 | TABLE ACCESS FULL| EMP_ALL | 1037K|
----------------------------------------------
For the optimizer to use a hash join, it must be an equijoin condition. Hash joins are best used when joining large amounts of data or where a large percentage of rows from a table is needed. The smaller of the two tables is used by the optimizer to build a hash table on the join key between the two tables. In the foregoing example, the DEPT table is the smaller table, and will be used to build the hash table. For best performance, the hash table completely resides in memory.
Sort Merge Join Hint
To invoke a sort merge join, use the USE_MERGE hint, and place both tables needing the join within parentheses inside the USE_MERGE hint:
SELECT /*+ use_merge(emp, dept) */ ename, dname
FROM emp JOIN dept USING (deptno)
WHERE deptno != 20;
------------------------------------------------
| Id | Operation | Name |
------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | MERGE JOIN | |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPT |
| 3 | INDEX FULL SCAN | PK_DEPT |
| 4 | SORT JOIN | |
| 5 | TABLE ACCESS FULL | EMP |
------------------------------------------------
Sort merge joins, like hash joins, are used to join a large volume of data. Unlike the hash join, the sort merge join is used when the join condition between the tables is not an equijoin. The hash join will generally perform better than the sort merge join, unless the data is already sorted on the two tables. During this operation, the input data from both tables is sorted on the join key, and then merged together.
Join Hints When Querying Multiple Tables
If you are joining several tables, and wish to invoke a specific join method between all of the associated tables in the query, you must add a hint for each join condition—for example:
SELECT /*+ use_hash(employees, department) use_hash(departments, locations) */
last_name, first_name, department_name, city, state_province
FROM employees JOIN departments USING (department_id)
JOIN locations USING (location_id);
-----------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | HASH JOIN | |
| 3 | TABLE ACCESS FULL | LOCATIONS |
| 4 | TABLE ACCESS FULL | DEPARTMENTS |
| 5 | VIEW | index$_join$_001 |
| 6 | HASH JOIN | |
| 7 | INDEX FAST FULL SCAN| EMP_NAME_IX |
| 8 | INDEX FAST FULL SCAN| EMP_DEPARTMENT_IX |
-----------------------------------------------------
How It Works
Table 14-2 summarizes the hints available for each of the different join methods. Hints to instruct the optimizer to choose a join method are sometimes necessary because of several factors:
- Status of statistics on the table
- Size of the PGA
- If the data is sorted at join time
- An unexplained choice of the optimizer
Oracle advises against using hints as much as possible, as over time what was optimal at one moment under one circumstance and one version of the database software may not be optimal the next time. However, sometimes these hints can simply be helpful in fulfilling the short-term need or simply may be the only way to get the optimizer to do what you want it to do.

![]() Tip The size of your PGA can affect which join method the optimizer uses for your query.
Tip The size of your PGA can affect which join method the optimizer uses for your query.
14-5. Changing the Optimizer Version
Problem
You have upgraded to a newer version of Oracle, and you are having query performance problems related to the newer version of Oracle. The problem is isolated to a small number of queries, so you want to place a hint in these queries to use the previous version of the optimizer's rules and features.
Solution
In order to specify a version of the optimizer for a given query, you specify the version of the optimizer you desire within the optimizer_features_enable hint. Within parentheses, place the desired version of the database within single quotes.
SELECT /*+ optimizer_features_enable('10.2') */ *
FROM EMP JOIN DEPT USING(DEPTNO);
This method is mostly used as an interim measure to improve performance immediately following an upgrade, until analysis can be done and a resolution found with the query and the upgraded version of the database.
How It Works
You can modify the version of the optimizer for a given query. This can be done via the optimizer_features_enable hint, and will be in effect only for a given query. The primary reason this hint is used is that a query that performed well under one specific version of Oracle has seen performance degrade immediately following an Oracle database version upgrade.
There is an Oracle initialization parameter, optimizer_features_enable, that can be changed for the entire database instance, and it is an option when widespread performance problems occur within queries immediately after you've upgraded your database. Often, however, changing this parameter at the database instance level is not feasible, nor even desired, as the primary reason for upgrading is to take advantage of new features. So, unless there are significant and widespread performance issues, it is not recommended to change the optimizer_features_enable parameter for an entire database instance.
If you have a given query or a small subset of critical queries that are performing at a substandard performance level after an upgrade, a quick method to return to the pre-upgrade performance is to use the optimizer_features_enable hint to point to a specific version of the optimizer for a given query.
14-6. Choosing Between a Fast Response and Overall Optimization
Problem
When you execute a query, you can choose between two goals:
- Fast, initial response: Get to the point of returning some rows as quickly as possible.
- Overall optimization: Minimize overall cost at the expense of upfront processing time.
Your instance will have a default goal configured for it. You can specify hints on a query-by-query basis to override the default goal and get the behavior that you want for a given query.
Solution
There are hints that can be used to override the optimization goal of your database instance. Before using any of the hints related to the optimizer_mode, you first want to validate what your database instance is currently set to. If you have the SELECT ANY DICTIONARY system privilege, you can see what value is set for the optimizer_mode parameter.
SQL> show parameter optimizer_mode
NAME TYPE VALUE
-------------------- -------------------- --------------------
optimizer_mode string ALL_ROWS
If we run an explain plan for an example query, we can see what the execution plan is by using the default optimizer_mode setting for our database instance.
SELECT *
FROM employees NATURAL JOIN departments;
------------------------------------------
| Id | Operation | Name |
------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | TABLE ACCESS FULL| DEPARTMENTS |
| 3 | TABLE ACCESS FULL| EMPLOYEES |
------------------------------------------
Since the foregoing query is doing full table scans against the tables, and we want to see some rows as soon as possible, but not necessarily the full result set, we can pass in a FIRST_ROWS hint to accomplish this task. It is apparent that this changes the optimizer's execution plan in order to provide results as soon as possible.
SELECT /*+ first_rows */ *
FROM employees NATURAL JOIN departments;
----------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | TABLE ACCESS FULL | EMPLOYEES |
| 4 | INDEX UNIQUE SCAN | DEPT_ID_PK |
| 5 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS |
----------------------------------------------------
If we needed the reverse situation, and the database's default optimizer_mode was set to FIRST_ROWS, we can supply an ALL_ROWS hint to tell the optimizer to use that mode when determining the execution plan:
SQL> alter system set optimizer_mode=first_rows scope=both;
System altered.
SQL> show parameter optimizer_mode
NAME TYPE VALUE
-------------------- -------------------- --------------------
optimizer_mode string FIRST_ROWS
SELECT /*+ all_rows */ *
FROM employees NATURAL JOIN departments;
------------------------------------------
| Id | Operation | Name |
------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | TABLE ACCESS FULL| DEPARTMENTS |
| 3 | TABLE ACCESS FULL| EMPLOYEES |
------------------------------------------
How It Works
The fast, initial response goal is often a good choice for queries when a user is awaiting results. It causes the database engine to make choices that allow rows to begin coming back from the query almost immediately. For example, optimizing for initial response often results in a nested loops join, because such a join can begin returning rows from the very beginning. The trade-off is possibly a longer overall execution time.
The goal of reducing overall query cost is usually a good choice for batch processes. No live, human user is awaiting results, so it is acceptable to spend more time on upfront processing in order to reduce overall query cost. An example might be to execute a hash join, which can't begin returning rows until the join is done, but which might execute in less overall time than a nested loops join.
You can use either the FIRST_ROWS or the ALL_ROWS hint in your query in order to change the optimizer mode, which controls which of the preceding two goals applies to a given query.
To check what the current optimizer mode is for your database instance, check the value of the optimizer_mode initialization parameter. By specifying an optimizer goal hint, it overrides the optimizer mode set at the database instance level, as well as any settings at the session level.
The FIRST_ROWS hint is very popular, as it can quickly return the first possible rows back from a query. The FIRST_ROWS hint is also very common because ALL_ROWS is the default value for the optimizer_mode parameter. It's thus unusual to need to specify ALL_ROWS.
14-7. Performing a Direct-Path Insert
Problem
You are doing a DML INSERT statement, and it is performing slower than needed. You want to optimize the INSERT statement to use a direct-path insert technique.
Solution
By using the APPEND or APPEND_VALUES hint, you can significantly speed up the process of performing an insert operation on the database. Here is an example of the performance savings using the APPEND hint. First, we have a query that does a conventional insert between two tables:
INSERT INTO emp_dept
SELECT * FROM emp_ctas_new;
19753072 rows created.
Elapsed: 00:01:17.86
-------------------------------------------------
| Id | Operation | Name |
-------------------------------------------------
| 0 | INSERT STATEMENT | |
| 1 | LOAD TABLE CONVENTIONAL | EMP_DEPT |
| 2 | TABLE ACCESS FULL | EMP_CTAS_NEW |
-------------------------------------------------
If we place the APPEND hint inside of the same INSERT statement, we see a considerable gain in performance:
INSERT /*+ append */ INTO emp_dept
SELECT * FROM emp_ctas_new;
19753072 rows created.
Elapsed: 00:00:12.15
-------------------------------------------
| Id | Operation | Name |
-------------------------------------------
| 0 | INSERT STATEMENT | |
| 1 | LOAD AS SELECT | EMP_DEPT |
| 2 | TABLE ACCESS FULL| EMP_CTAS_NEW |
-------------------------------------------
The APPEND hint works with an INSERT statement only with a subquery; it does not work with an INSERT statement with a VALUES clause. For that, you need to use the APPEND_VALUES hint. Here are two examples of an INSERT statement with a VALUES clause, and we can see the effect the hint has on the execution plan:
INSERT INTO emp_dept
VALUES (15867234,'Smith, JR','Sales',1359,'2010-01-01',200,5,20);
---------------------------------------------
| Id | Operation | Name |
---------------------------------------------
| 0 | INSERT STATEMENT | |
| 1 | LOAD TABLE CONVENTIONAL | EMP_DEPT |
---------------------------------------------
INSERT /*+ append_values */ INTO emp_dept
VALUES (15867234,'Smith, JR','Sales',1359,'2010-01-01',200,5,20);
-------------------------------------
| Id | Operation | Name |
-------------------------------------
| 0 | INSERT STATEMENT | |
| 1 | LOAD AS SELECT | EMP_DEPT |
| 2 | BULK BINDS GET | |
-------------------------------------
How It Works
The APPEND hint works within statements performing DML insert operations from another table, that is, using a subquery from within an INSERT SQL statement. This is appropriate for when you need to copy a large volume of rows between tables. By bypassing the Oracle database buffer cache blocks and appending the data directly to the segment above the high water mark, it saves significant overhead. This is a very popular method for inserting rows into a table very quickly.
When you specify one of these hints, Oracle will perform a direct-path insert. In a direct-path insert, the data is appended at the end of a table, rather than using free space that is found within current allocated blocks for that table. The APPEND and APPEND_VALUES hints, when used, automatically convert a conventional insert operation into a direct-path insert operation. In addition, if you are using parallel operations during an insert, the default mode of operation is to use the direct-path mode. If you want to bypass performing direct-path operations, you can use the NOAPPEND hint.
Keep in mind that if you are running with either of these hints, there is a risk of contention if you have multiple application processes inserting rows into the same table. If two append operations are inserting rows at the same time, performance will suffer, as since the insert append operation appends the data above the high water mark for a segment, only one operation should be done at one time. However, if you have partitioned objects, you can still run several concurrent append operations, as long as each insert operates on separate partitions for a given table.
14-8. Placing Hints in Views
Problem
You are creating a view, and want to place a hint in the view's query in order to improve performance on any queries that access the view.
Solution
Hints can be placed in views, as a view is simply a stored query in the database. Depending on the type of hint used, as well as the type of view that is being queried, you can determine if your hint will be used. It is important to understand what type of view you have so you can determine what impacts hints will have on that view. To understand this, you first need to determine which of the following describes your view:
- Mergeable or non-mergeable view
- Simple or complex view
A simple view is a view that references only one table, and there are not any grouping functions or expressions:
CREATE view emp_high_sal
AS SELECT /*+ use_index(employees) */ employee_id, first_name, last_name, salary
FROM employees
WHERE salary > 10000;
A complex view can reference multiple tables, or it will have grouping clauses, or use functions and expressions:
CREATE or replace view dept_sal
AS SELECT /*+ full(employees) */ department_id, department_name,
departments.manager_id, SUM(salary) total_salary, AVG(salary) avg_salary
FROM employees JOIN departments USING(department_id)
GROUP BY department_id, department_name, departments.manager_id;
A mergeable view is simply one in which the optimizer can replace the query calling the view with the query within the view definition itself. For example, we simply want to query all the rows from our EMP_HIGH_SAL view. The optimizer simply has to go directly to the EMPLOYEES table:
SELECT * FROM emp_high_sal;
---------------------------------------
| Id | Operation | Name |
---------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS FULL| EMPLOYEES |
---------------------------------------
The optimizer has simply replaced the query with the query that defined the view:
SELECT /*+ full(employees) */ department_id, department_name,
departments.manager_id, SUM(salary) total_salary, AVG(salary) avg_salary
FROM employees JOIN departments USING(department_id)
GROUP BY department_id, department_name, departments.manager_id;
With a mergeable view, the hint inside the view is preserved because the essential structure of the view definition is intact based on the query calling the view. See Table 14-3 for the guidelines for hints regarding mergeable views.
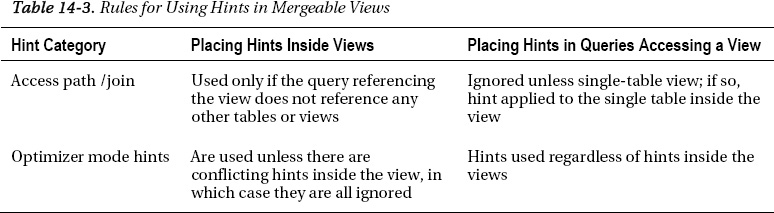
For a non-mergeable view, the optimizer must break the work up into two pieces. It first must execute the query that defines the view, and then must execute the top-level query. Because of this, the hints defined within the view itself are preserved. For instance, we are querying our DEPT_SAL view. We can see from the explain plan that the query is broken up into pieces:
SELECT manager_id, sum(total_salary)
FROM dept_sal
GROUP BY manager_id;
-------------------------------------------------------
| Id | Operation | Name |
-------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH GROUP BY | |
| 2 | VIEW | DEPT_SAL |
| 3 | HASH GROUP BY | |
| 4 | MERGE JOIN | |
| 5 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS |
| 6 | INDEX FULL SCAN | DEPT_ID_PK |
| 7 | SORT JOIN | |
| 8 | TABLE ACCESS FULL | EMPLOYEES |
-------------------------------------------------------
See Table 14-4 for the guidelines for hints regarding non-mergeable views.

It can be confusing to understand all the possible scenarios with hints and views, so they need to be used sparingly, and only when other means of tuning have not met the needed requirements.
How It Works
Since a view, as mentioned, is simply a stored query, hints can be placed easily inside the view as they would be inside any query. The type of hint placed in the view will determine how and if a hint can be used within the view. Much like performing DML on a view, there are limitations on when hints are used or ignored.
As a rule of thumb, the simpler a view is, the more likely hints can be effective. Because of the uniqueness of each application, each query, and each view, the only true way to know if a hint will be used is to simply try the hint and perform an explain plan to validate whether a given hint is used.
Oracle does not recommend placing hints in views, as since the underlying objects can change over time, you can expect unpredictable execution plans. Also, views can be created for one specific use, but could be used for other purposes later, and any hints in the views may not help every scenario. In addition, hints placed within views are managed differently than if you were simply executing the query itself. Before any hint placed inside a view is used, the optimizer needs to determine if the view can be merged with the query calling the view.
You can also consider placing hints within queries that access views. It is important to understand the rules of precedence when hints are placed within queries that access the views that have hints within themselves. This especially underlines the need for caution before placing a hint within a view.
![]() Tip Hints in queries that reference a complex view are ignored.
Tip Hints in queries that reference a complex view are ignored.
14-9. Caching Query Results
Problem
You want to improve the performance on a given set of often-used queries, and want to use Oracle's result cache to store the query results, so they can be retrieved quickly for future use when the same query has been executed.
Solution
The result cache is new to Oracle 11g, and was created in order to store results from often-used queries in memory for quick and easy retrieval. If you run an explain plan on a given query, you can see if the results will be stored in the result cache:
SELECT /*+ result_cache */
job_id, min_salary, avg(salary) avg_salary, max_salary
FROM employees JOIN jobs USING (job_id)
GROUP BY job_id, min_salary, max_salary;
---------------------------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | RESULT CACHE | 5t4cc5n1gdyfh46jdhfttnhx4g |
| 2 | HASH GROUP BY | |
| 3 | NESTED LOOPS | |
| 4 | NESTED LOOPS | |
| 5 | TABLE ACCESS FULL | EMPLOYEES |
| 6 | INDEX UNIQUE SCAN | JOB_ID_PK |
| 7 | TABLE ACCESS BY INDEX ROWID| JOBS |
---------------------------------------------------------------------
If you then query the V$RESULT_CACHE_OBJECTS view, you can validate whether the results of a query are stored in the result cache by looking at the cache ID value from the explain plan.
SELECT ID, TYPE, to_char(CREATION_TIMESTAMP,'yyyy-mm-dd:hh24:mi:ss') cr_date,
BLOCK_COUNT blocks, COLUMN_COUNT columns, PIN_COUNT pins, ROW_COUNT "ROWS"
FROM V$RESULT_CACHE_OBJECTS
WHERE CACHE_ID = '5t4cc5n1gdyfh46jdhfttnhx4g';
ID TYPE CR_DATE BLOCKS COLUMNS PINS ROWS
---------- ------- ------------------- ------- -------- ----- ----------
4 Result 2011-03-19:15:20:43 1 4 0 19
If for some reason your database is set with a default mode of FORCE at the database or table level, you can use the NO_RESULT_CACHE hint to bypass the result cache. If we run our previous query with the result cache mode set to FORCE, it is evident that the result cache is used automatically.
SQL> show parameter result_cache_mode
NAME TYPE VALUE
-------------------- -------------------- --------------------
result_cache_mode string FORCE
select job_id, min_salary, avg(salary) avg_salary, max_salary
from employees join jobs using (job_id)
group by job_id, min_salary, max_salary;
---------------------------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | RESULT CACHE | 5t4cc5n1gdyfh46jdhfttnhx4g |
| 2 | HASH GROUP BY | |
| 3 | NESTED LOOPS | |
| 4 | NESTED LOOPS | |
| 5 | TABLE ACCESS FULL | EMPLOYEES |
| 6 | INDEX UNIQUE SCAN | JOB_ID_PK |
| 7 | TABLE ACCESS BY INDEX ROWID| JOBS |
---------------------------------------------------------------------
If we then rerun with the NO_RESULT_CACHE hint, the result cache is not used and the statement is executed:
SELECT /*+ no_result_cache */ job_id, min_salary, avg(salary) avg_salary, max_salary
FROM employees JOIN jobs USING (job_id)
GROUP BY job_id, min_salary, max_salary;
---------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH GROUP BY | |
| 2 | NESTED LOOPS | |
| 3 | NESTED LOOPS | |
| 4 | TABLE ACCESS FULL | EMPLOYEES |
| 5 | INDEX UNIQUE SCAN | JOB_ID_PK |
| 6 | TABLE ACCESS BY INDEX ROWID| JOBS |
---------------------------------------------------
The following query was run twice, first not using the result cache, and the second time using the result cache, and the performance difference is significant:
SELECT /*+ no_result_cache */
j.job_id, min_salary, avg(salary) avg_salary, max_salary, department_name
FROM employees_big e, jobs j, departments d
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND salary BETWEEN 5000 AND 9000
GROUP BY j.job_id, min_salary, max_salary, department_name;
JOB_ID MIN_SALARY AVG_SALARY MAX_SALARY DEPARTMENT_NAME
---------- ---------- ---------- ---------- ------------------------------
ST_MAN 5500 7280 8500 Shipping
SA_REP 6000 7494 12000 Sales
HR_REP 4000 6500 9000 Human Resources
AC_ACCOUNT 4200 8300 9000 Accounting
IT_PROG 4000 7500 10000 IT
FI_ACCOUNT 4200 7920 9000 Finance
MK_REP 4000 6000 9000 Marketing
7 rows selected.
Elapsed: 00:00:21.80
SELECT /*+ result_cache */
j.job_id, min_salary, avg(salary) avg_salary, max_salary, department_name
FROM employees_big e, jobs j, departments d
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND salary BETWEEN 5000 AND 9000
GROUP BY j.job_id, min_salary, max_salary, department_name;
Elapsed: 00:00:00.08
How It Works
The result cache hint, if placed in a query, will override any database-level, table-level, or session-level result cache settings. Before using hints in your queries, you need to determine the configuration of the result cache on your database. There are two separate result caches to look at: the server-side result cache and the client-side result cache. The server-side result cache is part of the shared pool of the SGA, and stores SQL query results and PL/SQL function results. Query time can be improved significantly, as query results are checked within the result cache first, and if the results exist, they are simply pulled from memory, and the query is not executed. The result cache is most appropriately used for often-run queries that produce the same results.
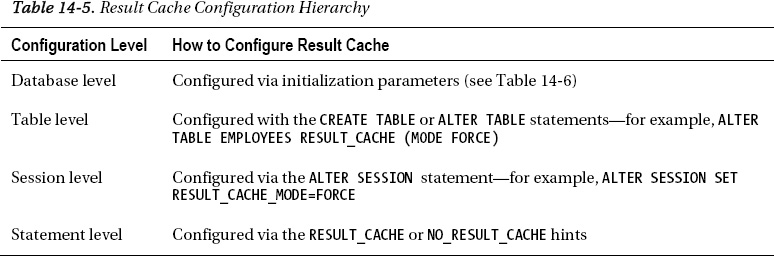
The result cache can be configured at several levels. As Table 14-5 indicates, it can be configured at the database level, the session level, the table level, or the statement level. The statement level is where hints are specified. If you decide to configure the result cache in your database, there are several initialization parameters that need to be configured. Table 14-6 reviews these parameters. Some are specific parameters for the result cache, while the remaining memory-related parameters need to be analyzed to see if they need to be changed to accommodate the result cache.

14-10. Directing a Distributed Query to a Specific Database
Problem
You are joining two or more tables together that exist on different databases, and want to direct the work to take place on a particular database, as the remote database is where most of the data resides.
Solution
By default, when you are joining tables that exist on different databases, the database where the query originated is where the majority of the work takes place. You can change this behavior and tell the optimizer which database will do the work:
SELECT /*+ driving_site(employees) */ first_name, last_name, department_name
FROM employees@to_emp_link JOIN departments USING(department_id);
Specifying the remote site as the driver is most appropriate if the volume on the remote site is large, or if you are querying many tables on the remote site. In order to process a distributed query, the optimizer first has to bring rows from remote tables over to the local site, before processing the overall query. This can be very resource-intensive on the temporary tablespace(s) on the local database. Therefore, by instructing the optimizer to perform the work at the site where the biggest percentage of the data resides, you can drastically improve your query performance.
When specifying the hint, you simply need to specify the remote table or table alias within your hint to direct the optimizer to the site that will do the work. There is no need to specify any hint if you wish the optimizer to do the work on the local database; the hint needs to be specified when you want to direct the work to a remote database.
How It Works
Distributed queries can be a blessing and a curse. By being able to join tables from remote databases, it gives users the impression of data transparency, that is, that the data they need to retrieve appears to be in one place, as they can assemble a single query to retrieve data, when in fact the data may reside on two or more databases. This simplicity in assembling queries is a key advantage of being able to perform distributed queries. The key disadvantage is that optimization of distributed queries is difficult. Essentially, the originating or local database where the query is initiated becomes the “driver” database by default. The optimizer at the local site has no knowledge of the makeup or volume of data at the remote site, and therefore the work is split up into pieces, and the query is not, by default, optimized as a single unit. Therefore, it is important to understand the makeup of the data on each database, in order to attempt to best optimize the query. The key decision you need to make with a distributed query is which database you want to be the “driving” site. The biggest factors in determining which site should be the driving site are as follows:
- How many tables are in the distributed query?
- How many databases are involved in the distributed query?
- Which database contains the most tables involved in the query?
- Which database contains the greatest volume of data?
In essence, if a majority of tables or a large volume of data resides remotely, it may be beneficial to use a remote database as the driving site. Let's say we are joining three tables together, and we want to get employee information along with the department they work in, and their work address. In this scenario, the employee table, being the largest, resides on one database, while two smaller tables, the department and location tables, reside on our local database:
SELECT first_name, last_name, department_name, street_address, city
FROM employees@to_emp_link JOIN departments USING(department_id)
JOIN locations USING (location_id);
-------------------------------------------
| Id | Operation | Name |
-------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH JOIN | |
| 2 | HASH JOIN | |
| 3 | TABLE ACCESS FULL| LOCATIONS |
| 4 | TABLE ACCESS FULL| DEPARTMENTS |
| 5 | REMOTE | EMPLOYEES |
-------------------------------------------
From the execution plan, we can see that the EMPLOYEES table is the remote table. What this means is before the join to the employee data can occur, all of that employee data must be brought over to the local database before the query can be completed. In this case, the employee data is by far the largest table of the three. There are far more employees than there are departments or locations, and therefore a large volume of data will be brought over to the local database before the remainder of the query can be processed. So, in this case, performance many improve by having the work done on the database where the employee data resides:
SELECT /*+ driving_site(employees) */
first_name, last_name, department_name, street_address, city
FROM employees@to_emp_link JOIN departments USING(department_id)
JOIN locations USING (location_id);
---------------------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------------------
| 0 | SELECT STATEMENT REMOTE | |
| 1 | HASH JOIN | |
| 2 | VIEW | index$_join$_001 |
| 3 | HASH JOIN | |
| 4 | INDEX FAST FULL SCAN| EMP_DEPARTMENT_IX |
| 5 | INDEX FAST FULL SCAN| EMP_NAME_IX |
| 6 | HASH JOIN | |
| 7 | REMOTE | DEPARTMENTS |
| 8 | REMOTE | LOCATIONS |
---------------------------------------------------------------
Now the explain plan shows the two smaller tables as remote tables, since the database where the EMPLOYEES table resides is now the driving site for the query. Sometimes you may simply need to determine this by trial and error, when it is not obvious which site should be the driving site.
Another easy way to determine this is simply by determining which query returns faster. If we want to get the average salary for each department and location, the query would look like the following:
SELECT department_name, city, avg(salary)
FROM employees_big@to_emp_link JOIN departments USING(department_id)
JOIN locations USING (location_id)
GROUP BY department_name, city
ORDER BY 2,1;
DEPARTMENT_NAME CITY AVG(SALARY)
------------------------------ ------------------------------ -----------
Human Resources London 6500
Public Relations Munich 10000
Sales Oxford 8955.88235
Accounting Seattle 10150
Administration Seattle 4400
Executive Seattle 19333.3333
Finance Seattle 8600
Purchasing Seattle 4150
Shipping South San Francisco 3475.55556
IT Southlake 5760
Marketing Toronto 9500
11 rows selected.
Elapsed: 00:00:42.87
Since no driving site hint is specified, the local site is the driving site. If we issue the same query specifying the remote and larger table to be the driving site, we see a benefit simply from the time the query takes to execute:
SELECT /*+ driving_site(employees_big) */ department_name, city, avg(salary)
FROM employees_big@to_emp_link JOIN departments USING(department_id)
JOIN locations USING (location_id)
GROUP BY department_name, city
ORDER BY 2,1;
Elapsed: 00:00:22.24
One more way you can try to determine which site should be the driving site is by figuring out exactly what work is being performed on each site. For example, using the foregoing query as an example, if we do not use the hint, perform the following:
- Retrieve an explain plan for the query.
- On the remote database, determine what part of the query is running remotely.
First, we can see the execution plan of our query. Again, we are not using the driving_site hint.
----------------------------------------------
| Id | Operation | Name |
----------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | SORT GROUP BY | |
| 2 | HASH JOIN | |
| 3 | HASH JOIN | |
| 4 | TABLE ACCESS FULL| LOCATIONS |
| 5 | TABLE ACCESS FULL| DEPARTMENTS |
| 6 | REMOTE | EMPLOYEES_BIG |
----------------------------------------------
Second, we can determine that the operation occurring on the remote database is the SELECT statement and columns for the remote EMPLOYEES_BIG table. You can retrieve this information directly from the data dictionary on the remote database, or a tool such as Enterprise Manager.
SELECT "SALARY","DEPARTMENT_ID"
FROM "EMPLOYEES_BIG" "EMPLOYEES_BIG"
If we repeat the foregoing two steps with the same query, only this time we insert a driving_site hint for the EMPLOYEES table, we get the following results. First, we can get the execution plan of our query with the driving_site hint:
-------------------------------------------------------------
| Id | Operation | Name |
-------------------------------------------------------------
| 0 | SELECT STATEMENT REMOTE| |
| 1 | RESULT CACHE | 326m75n1yb5kt2qysx7f37cy2y |
| 2 | SORT GROUP BY | |
| 3 | HASH JOIN | |
| 4 | HASH JOIN | |
| 5 | REMOTE | LOCATIONS |
| 6 | REMOTE | DEPARTMENTS |
| 7 | TABLE ACCESS FULL | EMPLOYEES_BIG |
-------------------------------------------------------------
Second, we can see which part of the query is being performed on the remote site. In this case, the data was retrieved from Enterprise Manager:
SELECT "A2"."DEPARTMENT_NAME","A1"."CITY",AVG("A3"."SALARY")
FROM "EMPLOYEES_BIG" "A3","DEPARTMENTS"@! "A2","LOCATIONS"@! "A1"
WHERE "A2"."LOCATION_ID"="A1"."LOCATION_ID" AND "A3"."DEPARTMENT_ID"="A2"."DEPARTMENT_ID"
GROUP BY "A2"."DEPARTMENT_NAME","A1"."CITY" ORDER BY "A1"."CITY","A2"."DEPARTMENT_NAME"
Without the driving site hint, we had to move all rows for the EMPLOYEES_BIG table for the SALARY and DEPARTMENT_ID columns. After transporting this data, the query results could be processed.
With the driving_site hint, we had to move all rows for all columns of the DEPARTMENTS and LOCATIONS table to the remote database. Then, the query results could be processed. And, because we used the driving_site hint, after the query results were compiled, the complete result set had to be transported to the local database. Therefore, you need to factor in not only the data moving between databases for the query itself, but also, if you are using the driving_site hint, the results themselves being transported back to the local database where the query originated.
14-11. Gathering Extended Query Execution Statistics
Problem
You want to gather extended explain plan statistics for a specific query, and do not want to adversely affect performance for an entire database instance while gathering this information.
Solution
You can use the GATHER_PLAN_STATISTICS hint, which, if placed within a query at runtime, will generate extended runtime statistics. It is a two-step process:
- Execute the query with the
gather_plan_statisticshint. - Use
dbms_xplan.display_cursorto display the results.
See the following example:
SELECT /*+ gather_plan_statistics */
city, round(avg(salary)) avg, min(salary) min, max(salary) max
FROM employees JOIN departments USING (department_id)
JOIN locations USING (location_id)
GROUP BY city;
CITY AVG MIN MAX
------------------------------ ---------- ---------- ----------
London 6500 6500 6500
Seattle 8844 2500 24000
Munich 10000 10000 10000
South San Francisco 3476 2100 8200
Toronto 9500 6000 13000
Southlake 5760 4200 9000
Oxford 8956 6100 14000
Then, you can use dbms_xplan to display the extended query statistics. Ensure that the SQL Plus setting SERVEROUTPUT is set to OFF, else results will not be properly displayed.
SELECT * FROM table(dbms_xplan.display_cursor(format=>'ALLSTATS LAST'));
------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | Buffers |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | | 14| 23 |
| 1 | HASH GROUP BY | | 0 | 23 | 0| 23 |
|* 2 | HASH JOIN | | 0 | 106 | 0| 23 |
|* 3 | HASH JOIN | | 0 | 27 | 0| 16 |
| 4 | VIEW | index$_join$_4| 0 | 23 | 0| 8 |
|* 5 | HASH JOIN | | 0 | | 0| 8 |
| 6 | INDEX FAST FULL SCAN| LOC_CITY_IX | 0 | 23 | 0| 4 |
| 7 | INDEX FAST FULL SCAN| LOC_ID_PK | 0 | 23 | 0| 4 |
| 8 | VIEW | index$_join$_2| 0 | 27 | 0| 8 |
|* 9 | HASH JOIN | | 0 | | 0| 8 |
| 10 | INDEX FAST FULL SCAN| DEPT_ID_PK | 0 | 27 | 0| 4 |
| 11 | INDEX FAST FULL SCAN| DEPT_LOC_IX | 0 | 27 | 0| 4 |
| 12 | TABLE ACCESS FULL | EMPLOYEES | 0 | 107 | 0| 7 |
------------------------------------------------------------------------------------------
There are many other options available using the DISPLAY_CURSOR procedure; refer to the Oracle PL/SQL Packages and Types Reference Guide for a more complete listing of these options.
How It Works
The GATHER_PLAN_STATISTICS hint gathers runtime statistics; therefore the query needs to be executed in order to gather these statistics. If you already have a query that is performing at a substandard optimization level, it may be useful to run your query with the GATHER_PLAN_STATISTICS hint. This can quickly give you information that you simply do not have with a normal explain plan, as it shows you estimated and actual information regarding query statistics. From this, you can determine if the optimizer is optimally executing the SQL, and you can determine if any optimization is needed.
Keep in mind that it does take some resources in order to gather these extra runtime statistics, so use this option with care. It may even be worthwhile to test the runtime differences in some cases. One key benefit of this hint is that the extra statistics are gathered only for the specific query. That way, the scope is limited and has no effect on other processes in the database, or even a particular session. If you wanted a more global setting to gather extended statistics, you can set STATISTICS_LEVEL=ALL at the session or instance level. One quick set of columns to review are the E-Rows and A-Rows columns. By looking at these columns, you can quickly tell if the optimizer is executing the query based on accurate statistics. If there is a large discrepancy between these columns, it is a sign of an inefficient execution plan. The one needed calculation for an accurate analysis is for the E-Rows column. You need to multiply the Starts column with E-Rows to accurately compare the total with A-Rows.
14-12. Enabling Query Rewrite
Problem
You have materialized views in your database environment, and want to have queries that access the source tables that make up the materialized views go against the materialized views directly to retrieve the results.
Solution
The REWRITE hint can be used to direct the optimizer to use a materialized view. The materialized view must have query rewrite enabled, and statistics for the materialized view and the associated objects should be current to increase the likelihood for a query to be rewritten. See the following example:
SELECT /*+ rewrite(dept_sal_mv) */ department_id,
sum(nvl(salary+(salary*commission_pct),salary)) total_compensation
FROM employees
GROUP BY department_id
having sum(nvl(salary+(salary*commission_pct),salary)) > 10000
ORDER by 2;
We can see here that the optimizer used the materialized view in the execution plan, rather than processing the entire query and recalculating the summary:
-----------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | SORT ORDER BY | |
| 2 | MAT_VIEW REWRITE ACCESS FULL| DEPT_SAL_MV |
-----------------------------------------------------
How It Works
Materialized views are very commonly used to store the result set for often-executed queries. While regular views are simply stored queries in the data dictionary, materialized views are essentially tables that store the result for these queries. Usually, they are created when there are complex joins, summaries, or aggregations occurring within a query. The following example is a materialized view that is calculating the total compensation for each department for a company. Let's say this query is often used by executives of this company to determine how their particular department is doing in terms of distributing compensation to its employees:
CREATE MATERIALIZED VIEW DEPT_SAL_MV
ENABLE QUERY REWRITE
AS
SELECT department_id,
sum(nvl(salary+(salary*commission_pct),salary)) total_compensation
FROM employees
GROUP BY department_id;
Since the results are stored in the database, there is no need for the optimizer to reprocess the query to retrieve the data. The end-user community does not have to execute a complex join or aggregation over and over, so it is a considerable performance benefit. Some users may not be aware of the materialized views in your environment, and may be executing the raw queries against the star schema or other tables. It is here that the REWRITE hint may help in improving performance on queries that could use a materialized view.
If you enable query rewrite for a materialized view, and if a query executes where the results can be found in that materialized view, the optimizer may choose to “rewrite” the query to go directly against the materialized view, rather than process the query itself. Generally, no hint is required, because if query rewrite is enabled, the optimizer will attempt to rewrite the query. However, it's possible the optimizer may not choose to rewrite the query to use the materialized view, even though that is the desired outcome. In those instances, you can place a hint within your query to have the optimizer use the materialized view, regardless of the execution cost. You can place the actual view name within the hint, or place the hint without the view name:
SELECT /*+ rewrite */ department_id,
sum(nvl(salary+(salary*commission_pct),salary)) total_compensation
FROM employees
GROUP BY department_id
having sum(nvl(salary+(salary*commission_pct),salary)) > 10000
ORDER by 2;
Conversely, you can also use a NOREWRITE hint if, for some reason, you do not want the optimizer to use the materialized view. One possible reason is that the data in the materialized view is stale compared to the source table(s), and you want to ensure you are getting the most current data. Here we can see that the optimizer bypassed the use of the materialized view and resummarized the data directly from the EMPLOYEES table:
SELECT /*+ norewrite */ department_id,
sum(nvl(salary+(salary*commission_pct),salary)) total_compensation
FROM employees
GROUP BY department_id
having sum(nvl(salary+(salary*commission_pct),salary)) > 10000
ORDER by 2;
------------------------------------------
| Id | Operation | Name |
------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | SORT ORDER BY | |
| 2 | FILTER | |
| 3 | HASH GROUP BY | |
| 4 | TABLE ACCESS FULL| EMPLOYEES |
------------------------------------------
14-13. Improving Star Schema Query Performance
Problem
You work in a data warehouse environment that contains star schemas, and you want to improve the performance of queries.
Solution
Oracle has a specific solution called “star transformation,” which was designed to help improve performance against star schemas in the data warehouse environment. Oracle has the STAR_TRANSFORMATION and FACT hints to help improve query performance using star schemas. In your queries, you can use the STAR_TRANSFORMATION or the FACT hint, or you can use both. The following query is an example of how to use these hints:
SELECT /*+ star_transformation */ pr.prod_category, c.country_id,
t.calendar_year, sum(s.quantity_sold), SUM(s.amount_sold)
FROM sales s, times t, customers c, products pr
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND pr.prod_id = s.prod_id
AND t.calendar_year = '2011'
GROUP BY pr.prod_category, c.country_id, t.calendar_year;
To use just the FACT hint, simply place the fact table name or alias within parentheses in the hint:
SELECT /*+ fact(s) */ pr.prod_category, c.country_id,
At times, the optimizer will be more likely to perform star transformation when both hints are present:
SELECT /*+ star_transformation fact(s) */ pr.prod_category, c.country_id,
Here is a typical explain plan that has undergone star transformation:
-----------------------------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH GROUP BY | |
| 2 | HASH JOIN | |
| 3 | HASH JOIN | |
| 4 | HASH JOIN | |
| 5 | PARTITION RANGE ALL | |
| 6 | TABLE ACCESS BY LOCAL INDEX ROWID| SALES |
| 7 | BITMAP CONVERSION TO ROWIDS | |
| 8 | BITMAP AND | |
| 9 | BITMAP MERGE | |
| 10 | BITMAP KEY ITERATION | |
| 11 | BUFFER SORT | |
| 12 | TABLE ACCESS FULL | CUSTOMERS |
| 13 | BITMAP INDEX RANGE SCAN | SALES_CUST_BIX |
| 14 | BITMAP MERGE | |
| 15 | BITMAP KEY ITERATION | |
| 16 | BUFFER SORT | |
| 17 | VIEW | index$_join$_016 |
| 18 | HASH JOIN | |
| 19 | INDEX FAST FULL SCAN | PRODUCTS_PK |
| 20 | INDEX FAST FULL SCAN | PRODUCTS_PROD_CAT_IX |
| 21 | BITMAP INDEX RANGE SCAN | SALES_PROD_BIX |
| 22 | TABLE ACCESS FULL | TIMES |
| 23 | TABLE ACCESS FULL | CUSTOMERS |
| 24 | VIEW | index$_join$_004 |
| 25 | HASH JOIN | |
| 26 | INDEX FAST FULL SCAN | PRODUCTS_PK |
| 27 | INDEX FAST FULL SCAN | PRODUCTS_PROD_CAT_IX |
-----------------------------------------------------------------------
Note
-----
- star transformation used for this statement
How It Works
Before you start running star queries, there are two key configuration elements that need to be taken care of before star transformation can occur:
- Ensure the
star_transformation_enabledparameter is set toTRUE. - Ensure that on the fact table, there is a bitmap index on every dimension foreign key column.
If you are at a point to want to use a hint within a star schema, be it the FACT hint or the STAR_TRANSFORMATION hint, it is assumed you have a properly configured environment, else these hints will not be used by the optimizer. These hints are not required for star transformation, but by using either or these hints, the optimizer will look to do transformation. Even with the hint, however, the optimizer may choose to ignore the request, based on what it thinks the best execution plan will be for the query. Star queries are very efficient and perform very well, because the transformation is designed to operate specifically with star schemas.
If, for some reason, you want to avoid the use of star transformation for your query, simply use the no_star_transformation hint, and the optimizer will bypass the use of star transformation:
SELECT /*+ no_star_transformation */ pr.prod_category, c.country_id,
t.calendar_year, sum(s.quantity_sold), SUM(s.amount_sold)
FROM sales s, times t, customers c, products pr
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND pr.prod_id = s.prod_id
AND t.calendar_year = '2011'
GROUP BY pr.prod_category, c.country_id, t.calendar_year;
From the explain plan, we can see that the optimizer did not transform our query:
---------------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | HASH GROUP BY | |
| 2 | NESTED LOOPS | |
| 3 | NESTED LOOPS | |
| 4 | NESTED LOOPS | |
| 5 | NESTED LOOPS | |
| 6 | PARTITION RANGE ALL | |
| 7 | TABLE ACCESS FULL | SALES |
| 8 | TABLE ACCESS BY INDEX ROWID| PRODUCTS |
| 9 | INDEX UNIQUE SCAN | PRODUCTS_PK |
| 10 | TABLE ACCESS BY INDEX ROWID | CUSTOMERS |
| 11 | INDEX UNIQUE SCAN | CUSTOMERS_PK |
| 12 | INDEX UNIQUE SCAN | TIMES_PK |
| 13 | TABLE ACCESS BY INDEX ROWID | TIMES |
---------------------------------------------------------
At times, it can be tricky to get the star transformation to take place. It is critically important that you have properly configured the star schema with all the appropriate bitmap indexes. Even having one missing bitmap index can affect the ability to have star transformation occur for your queries, so it is important to be very thorough and validate the configuration, especially regarding the bitmap indexes. Some star schemas also employ the use of bitmap join indexes between the fact and dimension tables to aid in achieving star transformation.