
![]()
Exploring Database Concepts
This chapter will explain just what SQL Server is, what a database is, and describe the objects that make up those databases. You will learn how data is stored in a database, and you’ll learn about objects, called indexes, that help SQL Server return the results of your queries quickly.
What Is SQL Server?
SQL Server is Microsoft’s relational database management system (RDBMS). An RDBMS stores data in tables according to the relational model. The relational model is beyond the scope of this book, but you can learn more about it by reading Beginning Relational Data Modeling, second edition, by Sharon Allen and Evan Terry (Apress, 2005).
Microsoft makes SQL Server available in many editions, including a free edition called Express, that can be distributed with applications or used to learn about SQL Server and several expensive, full-featured editions (Standard, Business Intelligence, and Enterprise) that are used to store terabytes of data in the most demanding enterprises. There is even a version that lives in the cloud calls Microsoft Azure SQL Database and one that is meant for mobile devices called Compact. Review the article “Features Supported by the Editions of SQL Server 2014” found at http://msdn.microsoft.com/en-us/library/cc645993(v=sql.120).aspx for more information about the editions and features of each. Table 2-1 gives an overview of the editions available. Core T-SQL features and version differences have been around since early versions of SQL Server. Many new versions of SQL Server contain added T-SQL functionality.
Table 2-1. SQL Server 2014 Editions
|
Edition |
Usage |
Expense |
|---|---|---|
|
Occasionally connected systems including mobile devices. |
Free |
|
|
Express |
Great for learning SQL Server and can be distributed with applications. Has limitations to database size, memory, and number of processors used. |
Free |
|
Full featured but used for development only. |
Inexpensive |
|
|
Complete data platform with some high-availability and business intelligence features. Some limitations to memory and CPU usage. |
Expensive |
|
|
All available features. |
Very expensive |
|
|
Business Intelligence |
Used in both large and small companies to deploy comprehensive Business Intelligence solutions. Has limitations to memory and CPU usage. |
Expensive |
|
Cloud version of SQL Server database. |
Pay-as-you-go model |
Many well-known companies trust SQL Server with their data. To read case studies about how some of these companies use SQL Server, visit www.microsoft.com/en-in/SQLserver/default.aspx.
Databases in the Cloud
Cloud computing is becoming more popular as companies and consumers begin storing data “in the cloud.” For example, most smartphones allow backing up data, such as photos, automatically to the cloud. You may be wondering just what the cloud is. I always imagine servers floating around in the sky, but cloud computing actually means that a vendor such as Microsoft supplies computing services via the Internet. Microsoft owns several data centers around the world with thousands of servers supplying these services. Some of the services Microsoft offers for consumers are e-mail (Outlook.com), storage (OneDrive), and Office. For commercial use, they offer Azure hosted storage, web services, virtual machines, databases, and more.
This model allows companies to use only the services and resources they need without investing in hardware and with decreased maintenance and administration. It is also possible to scale out their solutions very quickly. One of the early adopters of Azure services is the company Blue Book. If you would like to read more about how they are using Azure databases, take a look at this case study: www.slideshare.net/msitpro/microsoft-windows-azure-kelly-blue-book-case-study.
There are two ways Microsoft can host your database in the cloud. The first is by installing SQL Server on an Azure virtual machine. Except that the server is hosted by Microsoft, you will work with the SQL Server in the same ways that you do when it is installed on your own server in your own data center. The second way is by creating a Microsoft Azure SQL Database. In this case, you don’t manage the instance at all, just the database(s). There is built-in high availability and disaster recovery. Except for some missing administrative commands and some advanced features, the T-SQL language is mostly the same. An interesting aspect of Microsoft Azure SQL Database is that Microsoft can push out updates and new features on a frequent basis, much more frequently than the traditional SQL Server. You will learn more about Microsoft Azure SQL Database in Chapter 17.
SQL Server is a service, not just an application. Even though you can install some of the editions on a regular workstation, it generally runs on a dedicated server and will run when the server starts; in other words, usually no one needs to manually start the SQL Server. To minimize or practically eliminate downtime for critical systems, SQL Server boasts high-availability features such as clustering, log shipping, database mirroring, and Availability Groups. Think about your favorite shopping web site. You expect it to be available any time day or night and every day. Behind the scenes, a database server, possibly a SQL Server instance, must be running and performing well at all times. Even during necessary maintenance—when applying security patches, for example—administrators must keep downtime to a minimum.
SQL Server is feature rich, providing a complete business intelligence suite, impressive management tools, sophisticated data replication features, and much more. These features are well beyond the scope of this book, but I invite you to visit www.apress.com to find books to help you learn about these other topics if you are interested.
SQL Server doesn’t come with a data-entry interface for regular users or even a way to create a web site or a Windows application. To do that, you will most likely use a programming language such as Visual Basic .NET or C#. Calls to the SQL Server via T-SQL can be made within your application code or through a middle tier such as a web service. Regardless of your application architecture, at some point you’ll use T-SQL. SQL Server does have a very nice reporting tool called Reporting Services that is part of the business intelligence suite. Otherwise, you will have to use another programming language to create your user interface outside of the management tools.
Figure 2-1 shows the architecture of a typical web application. The web server requests data from the database server. The clients communicate with the web server.
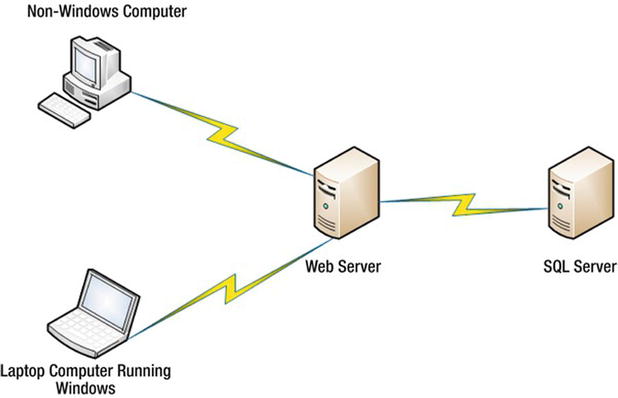
Figure 2-1. The architecture of a typical web application
A database in SQL Server is basically a container that holds several types of objects and data in an organized fashion. Generally, one database is used for a particular application or purpose, though this is not a hard and fast rule. For example, some systems have one database for all the enterprise applications required to run a business. On the other hand, one application could access more than one database.
Start SQL Server Management Studio if it is not already running and connect to the SQL Server instance you installed in Chapter 1. Expand the Databases folder to see the databases installed on the SQL Server. You should be able to see the AdventureWorks database, as shown in Figure 2-2.

Figure 2-2. The databases
Within a database, you will find several objects, but only one type of object, the table, holds the data that we usually think about. In addition to tables, a database can contain other objects, as listed in Table 2-2. Later chapters in this book will cover most of the other objects that are used to make up a database. You’ll find an introduction to indexes later in this chapter.
Table 2-2. The Database Objects
|
Object Type |
Purpose |
|---|---|
|
Views |
A stored query definition that can be used to simplify writing T-SQL statements or to control security to data. |
|
Stored procedures |
A stored T-SQL script that can include queries, data definition statements (DDL) that create or modify objects, and programming logic. Stored procedures can return tabular data results. |
|
User-defined functions |
A user-defined function is similar to a stored procedure but with several differences. They can return tabular data or a single value, but they cannot affect anything outside the function. |
|
Indexes |
A structured that assists the database engine when locating rows. |
|
Constraints |
Rules controlling the behavior of the table and columns and the data that can be stored in a column. |
|
Triggers |
A trigger is a special type of stored procedure that fires when something happens in the database such as a row is inserted or an object is created. |
|
Types |
Each column in a database has rules governing what type of data the column can contain. It is possible to create custom types to help organize the database. |
|
Rules and defaults |
These features are no longer recommended and are only available for backward compatibility. |
|
Plan guides |
This is an advanced feature used to override SQL Server’s behavior for a particular query. It is well beyond the scope of this book. |
|
Sequences |
Sequences are containers holding incrementing numbers. |
|
Synonyms |
Synonyms are nicknames or aliases for database objects. |
|
Assemblies |
Assemblies are references to database objects created in a .Net language. This functionality is called common language runtime (CLR) integration. |
A SQL Server database must comprise at least two files. One is the data file with the default extension .mdf, and the other is the log file with the default extension .ldf. Additional data files, if they are used, will usually have the extension .ndf. Technically, the .mdf, .ldf, and .ndf files can have any given extension name, though it is not recommended to change them from the defaults. Data files can be organized into multiple file groups. File groups are useful for strategically backing up only portions of the database at a time or to store the data on different drives for increased performance. This is just a quick introduction to files and file groups. There are also other files and file groups that are beyond the scope of this book.
The log file in SQL Server stores transactions, or changes to the data, to ensure data consistency. Database administrators can, as required, take frequent backups of the log files to allow the database to be restored to a point in time in case of data corruption, disk failure, or other disaster.
The most important objects in a database are tables because the tables are the objects that store the data and allow you to retrieve the data in an organized fashion. You can represent a table as a grid with columns and rows. The terminology used to describe the data in a database varies depending on the system, but in this book, I will stick with the terms table, row, and column. The following is an example of a table created to hold data about store owners:
CustomerID Title FirstName MiddleName LastName Suffix CompanyName
1 Mr. Orlando N. Gee NULL A Bike Store
2 Mr. Keith NULL Harris NULL Progressive Sports
3 Ms. Donna F. Carreras NULL Advanced Bike Components
4 Ms. Janet M. Gates NULL Modular Cycle Systems
In a normalized database, each table holds information about one type of entity. An entity type might be a student, customer, or vehicle, for example. Each row in a table contains the information about one instance of the entity represented by that table. For example, a row will represent one student, one customer, or one vehicle. Each column in the table will contain one piece of information about the entity. In the vehicle table, there might be a VIN column, a make column, a model column, a color column, and a year column, among others.
Each column within a table has a definition specifying a data type along with rules, called constraints, that enforce the values that can be stored. Constraints include whether a column can be left empty, whether its values must be unique from other rows, whether it is limited to a certain range of values, and so on. You will learn more about constraints in Chapter 14.
In a normalized database, each table will have a primary key that is used to uniquely identify each row. In the previous example, the primary key is CustomerID.
![]() Note You will learn what NULL means in Chapter 3.
Note You will learn what NULL means in Chapter 3.
SQL Server has a rich assortment of data types for storing strings, numbers, money, XML, binary, and temporal data. Start SQL Server Management Studio if it is not running already, and connect to the SQL Server you installed in the “Installing SQL Server Express Edition” section of Chapter 1. Expand the Databases section. Expand the AdventureWorks database and the Tables section. Locate the HumanResources.Employee table, and expand the Columns section. View the properties as shown in Figure 2-3.
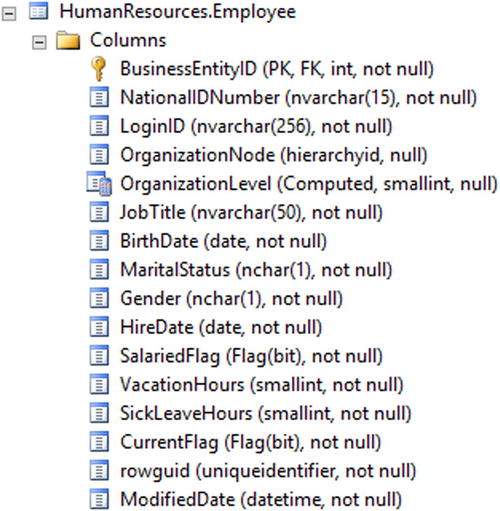
Figure 2-3. The properties of the HumanResources.Employee table
The HumanResources.Employee table contains columns with a variety of data types and one column, OrganizationalLevel, is a computed column defined by a formula. This is designated by the word Computed and the data type returned by the formula, smallint.
SalariedFlag and CurrentFlag have the Flag user-defined data type, which is defined within the database. Developers can create user-defined data types to simplify table creation and to ensure consistency. For example, the AdventureWorks database has a Phone data type used whenever a column contains phone numbers. To see the Phone data type definition, expand the Programmability section, the Type section, and the User Defined Data Types section. Locate and double-click the Phone data type to see the properties (see Figure 2-4).
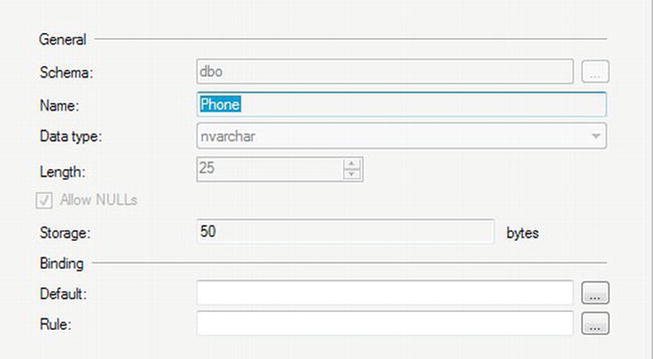
Figure 2-4. The properties of the Phone user-defined data type
Developers can create custom data types, called CLR data types, with multiple properties and methods using a .NET language such as C#. Chapter 16 covers three built-in CLR data types: HIERARCHYID, GEOMETRY, and GEOGRAPHY. The OrganizationNode column is a HIERARCHYID. You will find a wealth of information about data types in SQL Server Books Online by searching for the data type that interests you.
Normalization
Normalization is the process of designing database tables in a way that makes for efficient use of disk space and that allows the efficient manipulation and updating of the data. Generally, normalization allows each piece of information to be stored only once. Normalization is especially important in online transaction processing (OLTP) databases, such as those used in e-commerce. Database architects usually design reporting-only databases in a less normalized manner, often using different design patterns known as dimensional modeling. This allows easier and quicker retrieval of information for reporting because the data is not often updated.
The process of normalization is beyond the scope of this book, but it is helpful to understand why databases are normalized. To learn more about normalization, see Pro SQL Server 2012 Relational Database Design and Implementation by Louis Davidson and Jessica Moss (Apress, 2012).
Figure 2-5 shows how a database design might look before it is normalized. The example is of an order-entry database. There is one table, and that table consists of data about both customers and orders. One problem that you can probably see straightaway is that there is room for only three items per order and only three orders per customer.

Figure 2-5. The denormalized database
Figure 2-6 shows how the database might look once it is normalized. In this case, the database contains a table to hold information about the customer and a table to contain information about the order, such as the order date. The database contains a separate table to hold the items ordered. The order table contains a CustomerID that determines the customer instead of repeating all the customer information in the Order table. The OrderDetail table allows as many items as needed per order. The OrderDetail table contains the OrderID column to specify the correct order.
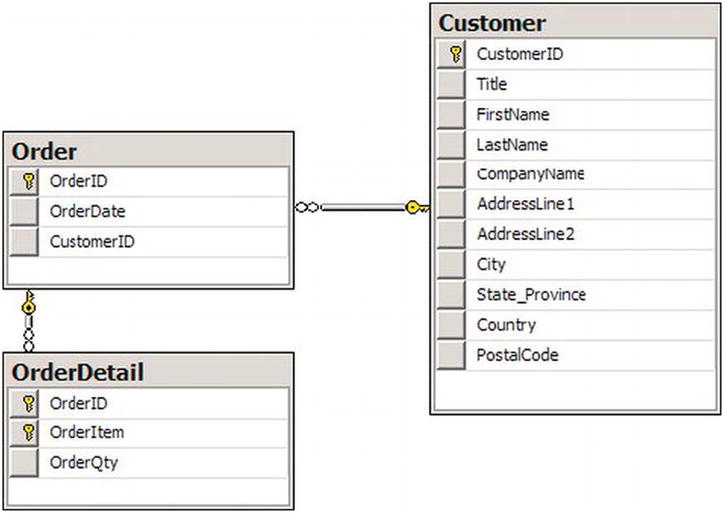
Figure 2-6. The normalized database
It may seem like a lot of trouble to properly define a database upfront. However, it is well worth the effort to do so. I was called in once to help create reports on one of the most poorly designed databases I have ever seen. This was a small Microsoft Access database that was used to record information from interviewing users at a medium-sized company about the applications that the employees used. Each time a new application was entered into the database, a new Yes/No column for that application was created, and the data-entry form had to be modified. The developer, who should have known better, told me that she just didn’t have time to create a properly normalized database. Much more time was spent fighting with this poor design than would have been spent properly designing the database up front.
Understanding Indexes
When a user runs a query to retrieve a portion of the rows from a table, how does the database engine determine which rows to return? If the table has indexes defined on it, SQL Server may use the indexes to find the appropriate rows.
There are several types of indexes, but this section covers two types: clustered and nonclustered. A clustered index stores and organizes the table. A nonclustered index is defined on one or more columns of the table, but it is a separate structure that points to the actual table. Both types of indexes are optional, but they can greatly improve the performance of queries when properly designed and maintained. A couple of analogies will help explain how indexes work.
A printed phone directory is a great example of a clustered index. Each entry in the directory represents one row of the table. A table can have only one clustered index. That is because a clustered index is the actual table organized in order of the cluster key. At first glance, you might think that inserting a new row into the table would require all the rows after the inserted row to be moved on the disk. Luckily, this is not the case. The row will have to be inserted into the correct data page. A list of pointers maintains the order between the pages, so the rows in other pages will not have to actually move.
The primary key of the phone directory is the phone number. Usually the primary key is used as the clustering key as well, but this is not the case in our example. The cluster key in the phone directory is a combination of the last name and first name. How would you find a friend’s phone number if you knew the last and first name? Easy—you would open the book approximately to the section of the book that contains the entry. If your friend’s last name starts with an F, you search near the beginning of the book; if it starts with an S, you search toward the back. You can use the names printed at the top of the page to quickly locate the page with the listing. You then drill down to the section of the correct page until you find the last name of your friend. Now you can use the first name to choose the correct listing. The phone number is right there next to the name. It probably takes more time to describe the process than to actually do it. Using the last name plus the first name to find the number is called a clustered index seek.
The index in the back of a book is an example of a nonclustered index. A nonclustered index has the indexed columns and a pointer or bookmark pointing to the actual row. In the case of our example, it contains a page number. Another example could be a search done on Google, Bing, or another search engine. The results on the page contain links to the original web pages. The thing to remember about nonclustered indexes is that you may have to retrieve part of the required information from the rows in the table. When using a book index, you will probably have to turn to the page of the book. When searching on Google, you will probably have to click the link to view the original page. If all the information you need is included in the index, you have no need to visit the actual data.
Although you can have only one clustered index per table, you can have up to 999 nonclustered indexes per table. If you ever need that many, you might have a design problem! An important thing to keep in mind is that although indexes can improve the performance of queries, indexes take up disk space and require resources to maintain. If a table has four nonclustered indexes, every write to that table may require four additional writes to keep the indexes up to date.
I just mentioned that 999 nonclustered indexes is too many. When talking about databases, an answer I hear all the time to the question of how many is too many is “It depends.” The number of indexes allowed per table increased with the release of SQL Server 2008 to take advantage of a couple of new features: sparse columns and filtered indexes. You will learn more about sparse columns in Chapter 16.
A schema is a container that you can use to organize database objects. A schema is a way to organize the tables and object within the database. For example, the AdventureWorks database contains several schemas based on the purpose: HumanResources, Person, Production, Purchasing, and Sales. Each table or other object belongs to one of the schemas.
![]() Note SQL Server 2000 and earlier did not have schemas. Instead the prefix of the object referred to the owner of the object.
Note SQL Server 2000 and earlier did not have schemas. Instead the prefix of the object referred to the owner of the object.
A user can have a default schema. When accessing an object in the default schema, the user doesn’t have to specify the schema name; however, it’s a good practice to do so. If the user has permission to create new objects, the objects will belong to the user’s default schema unless specified otherwise. To access objects outside the default schema, the schema name must be used. Table 2-3 shows several objects along with the schema.
Table 2-3. Schemas Found in AdventureWorks
|
Name |
Schema |
Object |
|---|---|---|
|
HumanResources.Employee |
HumanResources |
Employee |
|
Sales.SalesOrderDetail |
Sales |
SalesOrderDetail |
|
Person.Address |
Person |
Address |
Summary
This chapter provided a quick tour of SQL Server. You learned how databases are structured and designed; you also learned how SQL Server uses indexes to efficiently return data. In Chapter 3, you will get a chance to write your own queries, and you’ll learn about the SELECT statement, the next step in your journey to T-SQL mastery.