
Chapter 9. Working with Mondrian and Pentaho
This chapter is recommended for
| Business analysts | |
| Data architects | |
| Enterprise architects | |
| Application developers |
As we pointed out in chapter 1, Mondrian is an OLAP engine. It provides a lot of power, but you need to couple it with an end-user tool to make it effective. As we’ve explored Mondrian’s various capabilities, we’ve used examples of end-user tools use to explain particular points, but we haven’t looked very deeply into any of the specific tools.
In this chapter, we’ll broaden our scope and cover topics that should be of interest to all users of Mondrian. We’re going to take a look at several tools that are commonly used with Mondrian and show how they’re used. These tools are written and maintained by Pentaho, as well as several tools from other companies that work closely with Pentaho. As you’ll see, there is a rich variety of tools tailored to specific needs:
- Pentaho Analyzer—An Enterprise Edition plugin that provides drag-and-drop analysis as well as advanced charting.
- Saiku—An open source, thin-client interface that provides drag-and-drop analysis and charting.
- Community Dashboard Framework (CDF)—An open source tool that allows users to create dashboards based on Mondrian data.
- Pentaho Report Designer (PRD)—An open source desktop application that allows users to create pixel-perfect reports.
- Pentaho Data Integration (PDI)—An ETL tool that’s usually used to populate the data used by Mondrian as described in chapter 3, but it can also use Mondrian as a source of data.
We won’t be providing a complete user guide to each tool—that would take another complete book. But you should get an understanding of what each tool can do for you and how to use it with Mondrian. We’ll also point out any peculiarities associated with each tool as it relates to Mondrian.
9.1. Pentaho Analyzer
Pentaho Analyzer is an enterprise analysis and charting tool. It uses Mondrian as a source of information and provides a graphical interface that allows analysts to easily perform analysis. Analyzer is an Enterprise Edition feature that requires a license from Pentaho to use. It has similar functionality to Saiku with some advanced features such as geomapping and plugin visualizations.
The rest of this section will provide an overview of some of Analyzer’s features as well as some special additions to schemas to support mapping and time dimensions in Analyzer.
9.1.1. Overview of Pentaho Analyzer
Figure 9.1 shows Analyzer with data in a tabular format. On the left is the list of dimensions and measures that you can add to the analysis. These values all come from the cube that you choose when creating an Analyzer report.
Figure 9.1. Pentaho Analyzer

Next to the fields is the current layout. This panel is context sensitive and will change based on the report view. For example, a stacked bar chart allows you to specify a dimension to use for multiple charts, as shown in figure 9.2. In this case, we’re creating a separate chart for each country.
Figure 9.2. Multiple bar charts for each country

The toolbar contains some basic tools such as undo and redo, showing and hiding panels, and other settings. The toolbar also allows you to switch from tabular mode to charts, selecting the specific chart you want to use. Hovering over an icon on the toolbar gives a tip to show what the icon does.
The analysis results area will show either a table of the results or the chosen chart. Through the use of context menus, you can also add things like subtotals and coloring to tables. We’ll describe how to use some of these features in the next section.
9.1.2. Using Analyzer for analysis
Let’s use Analyzer to create a report on Adventure Works’ internet sales. We’ll find customers who purchased more than 10 items, and target them with a new promotion.
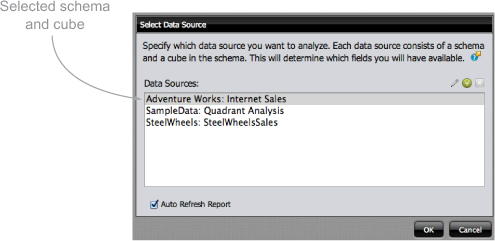
Select File > New > Analyzer Report to create a new Analyzer report, and you’ll get the dialog box shown in figure 9.3. (You could also click one of the icons on the main User Console toolbar.) Choose the Internet Sales cube, and then click OK to enter a new Analyzer report.
Figure 9.3. Select cube for analysis
Click the Report Options button to open the Report Options dialog box, as shown in figure 9.4. You’re not interested in seeing customers who haven’t made a purchase, so make sure the Also show Rows/Columns where the Measure cell is blank check box is unchecked. You can also specify what value is shown in blank cells, and whether totals are shown. Cell drillthrough causes each measure to have a link that can be clicked to see the source data that went into that cell. Freezing headers is useful for large reports so that you can see them when scrolling.
Figure 9.4. Set report options

To restrict the report to customers with 10 purchases, you need a filter. To do this, drag the Sales field to the filter pane. (You can also right-click on a header and select Filter.) The dialog box is shown in figure 9.5.
Figure 9.5. Filter numeric values

There are different kinds of filters based on the type of thing being filtered. The sales filter is based on numeric value, and there are also filters for standard dimensions or time dimensions, shown in figures 9.6 and 9.7.
Figure 9.6. Filter standard dimension values

Figure 9.7. Filter time dimension values

Numeric filters can filter based on values or can be set to show the top or bottom values. For example, you could identify the lowest performing stores to see how they can be improved. Numeric filters make it possible to limit the report to only the important values.
Dimensional filters let you filter on specific levels in a dimension. This can be very helpful if you just want to see a specific territory or state, for example. You can select a value from a list of existing members or even specify a substring to match on. The filters let you include or exclude the matching data.
The final type of filter is based on dates. When a dimension is properly defined as a time dimension, Analyzer will allow you to specify dates related to the type of time, such as year or month. As with standard dimensions, you can include and exclude specific values, but you can also use more interesting filters, such as searching between dates, choosing dates from the last time period, and so on.
9.1.3. Charting with Analyzer
Tables are very powerful for analysis, but graphical representations of data can be even more powerful. Charts give a view of the data that can quickly highlight differences. For example, you may have a bar chart of sales by store where one bar is significantly higher or lower than others. Such a result would suggest further analysis to see why a store is performing above or below average.
Creating charts is as simple as creating tabular reports. But because of the context-based layout panel described previously, it’s much easier to start in the chart mode and create the report rather than start with a table and convert it to a chart. To create a new chart, simply create a new Analyzer report, click the chart icon in the toolbar, and then drag the fields to the appropriate location.
Figure 9.8 shows an example of a stacked bar chart. Unfortunately, this example also demonstrates one of the dangers of charts. If they aren’t all at the same scale, they can misrepresent the data. In this case, New Zealand appears to have dramatically more canceled orders than the United States. But if you look closely, you’ll see that the difference isn’t quite that large.
Figure 9.8. Example of a stacked bar chart

A particularly compelling chart that has been recently added to Analyzer is the Geo Map. This map presents data on a global map and allows you to drill down locally. Figure 9.9 shows the sales of shipped items by country. The size of the bubble indicates the quantity shipped, and the color specifies the quantity of sales. This allows the viewer to easily see where the most sales are in an easy-to-understand visual form.
Figure 9.9. Plotting data on a Geo Map chart

One final point on charts is that Analyzer uses Pentaho’s plugin architecture and allows you to create and use new visualizations. Some users need more than what’s available from the standard charts, so assuming you have the technical skills, you can create your own visualizations. Figure 9.10 shows a chord chart, which links two metrics and uses the width of the connection as a relative size.
Figure 9.10. Plotting data as a chord chart

Not only can you create your own charts, but because these are plugins, you can reuse charts that are created by others. In the future, it’s likely that the Pentaho community will provide a number of charts to represent data in a variety of ways. At this time, the process isn’t well documented, but you should be able to find examples on the Pentaho site.
9.1.4. Special schema annotations for using Analyzer
When dealing with time and geomapped data, Analyzer requires special annotations in the Mondrian schema to make these data types work well. Time annotations allow Analyzer to create special time-based calculations, and geomapped data allows Analyzer to show the data on maps. In this section, we’ll show you what to add to your schema to get the full benefits of time and geomapped data.
Annotating for time dimensions
Analyzer requires that levels in a time dimension have an AnalyzerDateFormat annotation for each level. This tells Analyzer how to format the date for queries, and it uses Java date format notation. For example, a four-digit year is specified as [yyyy]. Listing 9.1 shows an example of annotating the month level.
Listing 9.1. Annotating the month level for Analyzer
<Level name="Months" column="MONTH_NAME"
ordinalColumn="MONTH_ID"
type="String" uniqueMembers="false"
levelType="TimeMonths" hideMemberIf="Never">
<Annotations>
<Annotation name="AnalyzerDateFormat">
[yyyy].['QTR'q].[MMM]
</Annotation>
</Annotations>
</Level>
Annotating for Geo Maps
For Analyzer to display items on a map, you need to tell it how to find the geographical location of dimension members. There are two different approaches for annotating locations. The first is to specify a level, such as country, state, or city. The second is to specify latitude and longitude. This means, of course, that the location information must exist in the data warehouse.
Listing 9.2 shows the declaration of a state level. Table 9.1 shows the possible annotations.
Table 9.1. Geo annotations
|
Annotation |
Required? |
Value(s) |
|---|---|---|
| Data.Role | Required | Geography—indicates that members of the level have a geographical location. |
| Geo.Role | Required | Name of a geographical classification; country, state, city, and zip are typical values, but you can use any value supported by the location service. If Geo.Role has the special value location, Analyzer will look for properties of the level called latitude and longitude. |
| Geo.RequiredParents | Optional | Comma-separated list of parent classifications. |
Listing 9.2. Annotating the state level for Analyzer
<Level name="State Province"
column="STATE"
type="String"
levelType="Regular"
hideMemberIf="Never">
<Annotations>
<Annotation name="Data.Role">Geography</Annotation>
<Annotation name="Geo.Role">state</Annotation>
<Annotation name="Geo.RequiredParents">country</Annotation>
</Annotations>
</Level>
If you don’t have a geography dimension, you can still geotag data using latitude and longitude, and it will be shown on the map. Latitude and longitude are added as properties and tagged with the Geo roles to indicate that they are latitude and longitude, as shown in listing 9.3. As long as you have the data, you can geotag any level where it makes sense.
Listing 9.3. Annotating the latitude and longitude for Analyzer
<Level name="Customer Location"
column="CUSTOMERNUMBER"
type="Numeric"
uniqueMembers="false">
<Annotations>
<Annotation name="Data.Role">Geography</Annotation>
<Annotation name="Geo.Role">location</Annotation>
</Annotations>
<Property name="Latitude" column="CUSTLAT" type="Numeric" />
<Property name="Longitude" column="CUSTLON" type="Numeric"/>
</Level>
Now that you understand how to use Analyzer, let’s look at how to use Saiku, an open source alternative to Analyzer.
9.2. Saiku
We covered Saiku in chapter 2, so we won’t go into detail about how to use it again here. Because Analyzer requires an enterprise license, Saiku is a good choice for a drag-and-drop tool that has no licensing costs. Even if you do have Analyzer, many people use Saiku for its ability to generate MDX queries because it generates much easier-to-read MDX than Analyzer.
Another reason to use Saiku is that it has a standalone version that doesn’t require Pentaho at all. Simply download the server and start it running. This is a very handy approach if you simply want to do analysis without the other overhead that comes with the entire Pentaho suite. And because Saiku is open source, you can even contribute to the project.
When running Saiku as a plugin, there are some things to be aware of. First, Saiku has its own library of files in the saiku/lib folder. This means that if you should need a different library for only Saiku, you can place it in this folder.
A second consideration is that by default Saiku will not use Mondrian’s cache, so if you install something like the Community Data Cache, you might wonder why nothing is being cached. Reconfiguring Saiku to use Mondrian’s cache is easy. Simply run the script saiku-shareMondrian.sh to have Saiku use the same Mondrian version as Pentaho, including sharing the cache. Note that this means Saiku will also use the same libraries as Pentaho.
Hopefully you now have a feel for Analyzer and Saiku and understand some of the trade-offs between the two. In the next section, we’ll show you how to create dashboards based on Mondrian data.
9.3. Community Dashboard Framework
The Community Dashboard Framework (CDF) is another project from Webdetails for creating interactive dashboards. The dashboards are written in a combination of HTML, JavaScript, and CSS, which means that you will need technically skilled people to develop CDF dashboards. It also means that the dashboards can be highly interactive and do anything that a dynamic web page can do.
This section will give you a brief introduction to CDF and describe how to use Mondrian as a source of data for CDF components. We’ll also discuss a complementary project, Community Data Access (CDA), that abstracts the Mondrian connection from the dashboard while adding additional features.
9.3.1. Creating a CDF dashboard
A typical dashboard consists of at least three files:
- An .xcdf file that defines the dashboard
- An HTML file that serves as a template for dashboard
- A JavaScript file that contains the actions of the dashboard, including the MDX queries
Additional files commonly seen in more complex dashboards include cascading style sheets, static images, and possibly additional JavaScript files. Because CDF dashboards are essentially dynamic HTML pages, they can include anything that a regular dynamic HTML page can, including jQuery or other framework files. The additional files don’t even have to reside in the same directory, allowing you to create common files for reuse by other dashboards.
Listing 9.4 shows the contents of an .xcdf file. The two most important values are the title and template. The title is what will be displayed in the Pentaho User Console and can be localized. The template is the HTML file that will be used to create the dashboard.
Listing 9.4. Declaring a CDF dashboard

The .xcdf file tells Pentaho that this is a dashboard, and it calls the CDF plugin to render the dashboard. CDF will use the template file to load all of the resources needed for the dashboard. The template file actually gets loaded into a separate template that can be used globally by all CDF dashboards, allowing you to customize the look and feel of all dashboards. The style tag specifies which outermost template to use. See the CDF documentation for information on how to change the global template files, because this involves creating and deploying a new HTML file.
The template file contains three logical sections, as shown in listing 9.5. The first is basic HTML that will define locations for CDF to render the objects. In this example, we’re only adding a pie chart, so we just have a single div to hold the resulting chart. For a complex dashboard, you might have multiple div tags and use tables or CSS to lay out the dashboard.
The second section is the declaration of the objects. In this example, we first define the pie chart and then create a pie chart based on the definition. Because we’re using Mondrian, we specify an MDX type, the catalog to use, the data source for the data, and the actual query. This example uses Steel Wheels, the sample dataset that comes with Pentaho. There are a few additional settings, such as height and width, that should also be specified but that are not shown here.
Listing 9.5. Defining a CDF dashboard with a pie chart


Once the dashboard has been loaded into the repository, you can run it and see the results, as shown in figure 9.11. In this case, we have the sales by territory as a pie chart.
Figure 9.11. CDF pie chart

9.3.2. Using Community Data Access
In the previous example, we embedded the query directly into the dashboard, but there are a few problems with this approach. First, it potentially exposes the details of your data to anyone who has access to the dashboard. Second, it makes the data access difficult to change should you decide to change the type of data source.
To solve these problems and add extra functionality, there’s another project called Community Data Access (CDA) that allows you to separate the source of data from the dashboard. Users will only see that you’re using CDA, but not the original source of the data. CDA supports a wide variety of data source types in addition to Mondrian, such as SQL and Pentaho Data Integration (PDI). You can also combine data from multiple sources into a single query using CDA and make that available to the dashboard as well.
CDA data access is defined in a separate file with a .cda extension. Listing 9.6 shows a CDA file that returns the same results as the previous query. There are two sections: the first defines the data sources to use and the second defines the specific query and the results returned.
Listing 9.6. Declaring a CDA descriptor


Once you have a CDA file defined, you can edit the original CDF file to change the data access from MDX to CDA. Listing 9.7 shows the new definition for the pie chart. It’s all the same except that the MDX has been replaced with CDA settings. Once you run the chart, it looks identical to the previous one.
Listing 9.7. Defining a CDF dashboard with a pie chart

CDF and CDA provide a nice way to create a dashboard, but many users also want data in reports. The next section will show you how to create tabular reports with Mondrian data.
9.4. Pentaho Report Designer
Pentaho Report Designer (PRD) is a pixel-perfect report-designing tool. It’s a standalone tool that runs independently of the Pentaho BA server, and it can be downloaded from http://reporting.pentaho.com. If you install using the Pentaho graphical installer, it will be placed in the design-tools directory. Start it as you would any other Java application.
PRD allows you to use a variety of data sources to create nicely formatted reports for users. Reports typically contain header and footer information, tabular data, and charts. Furthermore, a Pentaho report can include parameters that allow a user to filter the data. In this section, we’ll give you a brief overview of what reports can do, show you how to use Mondrian as a source of data, and discuss how to use a dynamic schema processor with reports. We won’t show you all the details of creating reports, but we’ll focus on the Mondrian-specific aspects.
Reports are most commonly based on data from relational databases using SQL to get the data. But PRD supports a wide variety of input sources, such as Mondrian, Pentaho Data Integration, big data sources such as Hadoop, and NoSQL databases such as MongoDB. With the use of scripted data sources for languages such as Groovy and Beanshell, the number of data sources is almost limitless.
9.4.1. Creating an OLAP data source
Let’s look at how you can use PRD to create a report based on Mondrian. First, open up PRD and select New Report. You’ll see something very similar to the blank canvas shown in figure 9.12.
Figure 9.12. Blank report

The first thing to do is set a source of data. There are a number of ways to specify the data type, but we’ll use the Data tab. Click the Data tab, and then click the database icon at the top. You’ll see a pop-up menu like that shown in figure 9.13. Click OLAP and choose Pentaho Analysis to create a Mondrian-based connection. You’ll notice that there are multiple OLAP options. We’ll just cover the basic one here, since that’s the most common one.
Figure 9.13. Choose OLAP data source

After the data source editor opens (as shown in figure 9.14), you can set the values for the data source. You can use the Browse button and browse to the Mondrian schema. Note that the path to the schema will become part of the report definition—when the report is deployed, it’ll look for the schema at the same path. This means that you need some approach to make sure the report will find the schema in the environment it’s deployed to, or else the report will need to be updated to point to the correct path.
Figure 9.14. Entering the OLAP settings

The next thing to select is the data source you want to use. This is a configured connection. Pentaho has a standard way of configuring connections to the database that we won’t cover here, but you can choose to use standard JDBC settings or JNDI. Whenever possible, you should use JNDI because it allows you to have a development report that points to development data, and then as the report goes through QA and into production, only the JNDI settings need to change, not the report.
After setting the database, click the green button with a “+” sign on it, to the right of Available Queries. This creates a new query. Give the query a descriptive name that makes it easy to tell what the query does. Finally, enter a valid MDX query. This query will return the values to use in the report.
Experiment with the order of rows and columns
One word of caution: the order of the columns and rows can cause your report to get different values, including member names rather than the measures you might expect. You may need to experiment with the query to get the values you want in your report.
Now that you have the query, close the data source editor and you’ll see the available fields you can use in the report. Figure 9.15 shows the completed report. Several data fields have been put onto the details section, and this section will repeat for each line in the results. There’s also a page header that gets added to each page, containing the report name. The report header will be displayed before the details, so you can put the column headers there. You can also put a total in the report footer that will show how many items were ordered by each product line.
Figure 9.15. Populated report template

At this point, you have a complete report that can be run. Figure 9.16 shows the report with data. The values are all pulled from the MDX query executing against the database. You could now publish this report to the Pentaho server for other users to run.
Figure 9.16. Report with data

9.4.2. Using parameters
One problem with reports is that they can get pretty long. Users often want to see only some of the data at any given time. In Analyzer you can create filters to restrict the data, and Pentaho Report Designer offers a similar capability through the use of parameters.
The first step is to create a query to populate the parameters. You could also just hard code the value (for example, if you want to specify a dimension), but in this case we’re going to parameterize the country to allow users to restrict by country. Because of the way the query is returned, the territory needs to be in the rows, and since you can’t specify a ROWS value in MDX without a column, you need to also specify something on the COLUMNS. In this case, we’ll just ignore the column values. Listing 9.8 shows the MDX query for the territories.
Listing 9.8. Getting the territories for parameters
SELECT
NON EMPTY {[Product].[Line].Members} ON COLUMNS,
NON EMPTY {[Markets].[Territory].Members} ON ROWS
FROM [SteelWheelsSales]
Once you have a query, you can create a parameter to use. Figure 9.17 shows the configuration for the parameter. Select the query, and then select the fields to use. In this case, we’ll use a drop-down list.
Figure 9.17. Defining the territory parameter

Now that the parameter has been defined, it needs to be added to the original query to filter the data. There are really two ways to filter in MDX. The first is to use a WHERE clause, which is essentially the same as adding a hidden axis that selects only some data. Because we’re restricting on a dimension that’s already in the query, we can’t use a WHERE, because that would cause Markets to be on two axes. In this case, we can filter by specifying the territory in the SELECT.
The last step is to update the original query to use the parameter. Listing 9.9 shows the new query. Note that the market will now be populated with the children values of the territory selected from the parameter, as indicated by ${Territories}. Figure 9.18 shows the results of running the report with a parameter.
Figure 9.18. The report with a territory parameter

Listing 9.9. Restricting the territory with a parameter
SELECT
NON EMPTY {[Product].[Line].Members} ON COLUMNS,
NON EMPTY CrossJoin(
[Markets].[${Territories}].Children,
{[Measures].[Quantity]})
ON ROWS
FROM [SteelWheelsSales]
Slicing
We’ve been using the term filter because that’s a common term for reporting. It’s also common to see the term slicing used in OLAP when talking about restricting data.
9.4.3. PRD and the dynamic schema processor
The last thing to mention about Mondrian and PRD is the use of dynamic schema processors. PRD uses a different connection approach than Analyzer, Saiku, and other tools. PRD contains the definition as part of the report. Because of this, you need to set a dynamic schema processor in the report definition.
To specify the DSP you want to use, edit the data source and add a new global script, as shown in figure 9.19. This script will be called when the report is generated and will set the DSP to use; the value specified is the class name of the DSP. Note that you need to deploy the class into the classpath of the reporting engine so it can be found at runtime.
Figure 9.19. Adding a global script

The previous sections showed you how to create visualizations based on Mondrian data. But sometimes users just want to get data from Mondrian and do something with it. The next section covers extracting Mondrian data using PDI.
9.5. Pentaho Data Integration
Pentaho Data Integration (PDI) is a desktop tool that allows you to extract data from a variety of sources, modify the data, and then send it to a variety of outputs. The most common use of PDI is to perform ETL, as described in some detail in chapter 3, but PDI can be used in any situation where you need to get and manipulate data. This section will describe how to use PDI to extract data from Mondrian. From there, you can use the data as you would from any other data source.
The first step is to create a new transformation. This is done by selecting File > New > Transformation. Once you have a transformation, you can connect to the database.
Figure 9.20 shows the View tab. Right-click Database Connections and select New. You’ll get the standard database connection form shown in figure 9.21. Enter the connection information for the data mart being used by Mondrian.
Figure 9.20. PDI view

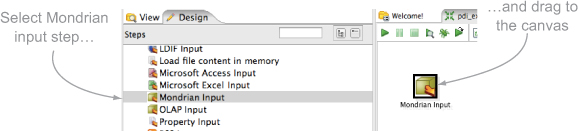
So far you’ve created a connection to the database with the data for Mondrian. Now you just need to hook it up to a schema and get some data. From the Design tab, open the Input folder and drag a Mondrian Input step onto the canvas. You should now have a transformation that looks similar to figure 9.22.
Figure 9.21. Database connection information

Figure 9.22. Adding a Mondrian input
Next, enter the catalog, database connection, and query into the step dialog box, as shown in figure 9.23. After the settings are entered, click the Preview button to see the results. Figure 9.24 shows the sales by category.
Figure 9.23. Setting Mondrian values

Figure 9.24. Results of query
![]()
At this point, you can use the data as you would any other input from PDI.
9.6. Summary
In this chapter, we took a look at some of the most widely used tools for working with Mondrian data sources. For each tool, we provided a brief overview and some high-level instructions on how to use it with Mondrian. We also provided some tips and considerations to be aware of when using each tool. You should now have a good idea of what each tool provides in the way of functionality and generally understand when it might be useful.
In particular, we covered the following tools:
- Pentaho Analyzer
- Saiku
- Community Dashboard Framework
- Pentaho Report Designer
- Pentaho Data Integration
Despite all the power these tools provide, they may not meet all your needs. Perhaps you want to link Mondrian directly to your system, or perhaps you want to create a simplified user interface. In the next chapter, we’ll take a look at how developers can create new tools to work directly with Mondrian to meet these needs.