
Chapter 13. Performance
- Selecting the optimal data set
- OpenCMIS and DotCMIS caches
- Binding performance
- HTTP tuning
As a developer and end user, you know how important performance is for an application. Creating a folder should take only a few milliseconds. If it takes longer than that, sooner or later somebody will complain. If you’ve played with multiple CMIS repositories, you might have discovered that some repositories are faster than others.
The performance of a CMIS application depends on many factors. Of course, the repository is a major factor, but often it isn’t the culprit when an application seems to be slow. This chapter presents a collection of real-world hints about how to avoid bottlenecks and how to improve the performance of CMIS clients and servers.
13.1. CMIS performance
When the first developers picked up OpenCMIS to build applications, there were mixed reactions. A few blog posts on the internet talk about first experiences with CMIS, and OpenCMIS in particular. Some reported something like this: “I quickly got it running and could connect to Alfresco and SharePoint. That’s great! But this CMIS thing is very slow. I don’t know if I should use it in my application.”
What’s the reason for these apparently missed expectations? CMIS looks similar to a filesystem, and people make calls against a repository that are similar to the calls they would make against a filesystem. So on one hand, you have a local filesystem where operations are usually fast. Getting the list of files in a folder or the size of a file takes almost no time. On the other hand, CMIS communicates over a network. Each OpenCMIS method call results in one or more calls to the repository. Each call has to be authenticated, and each request or response must be serialized and parsed. Although almost all of these calls take only a few milliseconds, they add up.
Thus, some of the missed expectations are due to people making an unfair comparison between local filesystem performance and a remote CMIS repository. But other reasons are linked to simple misuse of the library. Here are a few examples:
- A developer with administrator permissions requested all descendants of the root folder, and the repository happily returned them. The response was 170 MB of XML. It worked—both the client and server were able to handle the large response. But it took a moment to transfer this large amount of data. Because the application needed only a fraction of it, the situation was easy to fix. Eventually, the data was reduced to a few kilobytes.
- A development team switched an application from filesystem-based storage to CMIS. They replaced all filesystem operations with CMIS operations. They had one method that returned the file path, one that returned the file size, and one that returned the last modification date. In their CMIS code, each method set up a new OpenCMIS session, fetched the object, and retrieved the requested property. That is, each of these methods performed three or four calls to the repository. They performed 10 calls total per document. With a bit of refactoring, it was easy to reduce this to one call, which saved a few hundred milliseconds per document.
- A developer wanted to display the version histories of a set of documents on a web page. He fetched the version history of each document, grabbed the object ID of each version object, and then fetched the version object. When the documents had many versions, it took a while to load the web page. It turned out that it wasn’t necessary to fetch each version object again. The version history already contained all required information about the version objects. With a few code changes, the web page’s load performance became acceptable.
- A development team built an application and tested it. It worked fine. But when they deployed it into the production environment, performance was much worse compared to the test environment. The culprit was a reverse proxy server in the production environment, which handled the traffic between the repository and the application. This proxy server closed the socket connection after each request, ignoring HTTP Keep-Alive. After the administrator changed the configuration of the proxy server, performance was on par with the test environment.
CMIS can be fast if the application is properly designed, the runtime environment is correctly set up, and the repository plays along. CMIS client libraries make development easy, but as a developer you still have to understand what’s going on under the covers.
The following sections highlight a few critical spots. They’re independent of each other, and not all will be applicable to your application. Keep them in the back of your mind when you’re building your application.
13.2. Selecting the smallest data set
Do you remember chapters 7 and 8, where OperationContext was used everywhere? “Not again!” you might think, but in fact, from a developer’s point of view, the OperationContext is one of the best tools you have to tune your application’s performance.
Here are a few rules of thumb for an efficient CMIS application:
- Only ask for the object details you really, really need. If you can supply filters or, with OpenCMIS and DotCMIS, an OperationContext, do it. Never rely on the default values of the repository, because most of them will give you far more details than you need.
- Where possible, avoid properties that the repository has to calculate. Good candidates to avoid are properties that have to do with versioning and paths. For example, to find out if the document is the latest major version, the repository has to go through the version history. That may take only a fraction of a millisecond per object, and that’s nothing you would identify as a problem during development. But it might make a difference in production with millions of requests per day.
- Allowable actions are handy if you’re implementing a user interface and you want to show users what they can and can’t do with an object. But calculating the allowable action values is expensive for almost all repositories. The server has to check the permissions for all operations covered by the allowable actions. So if you don’t need them, don’t ask for them.
- Fetching the ACL of an object can be expensive for repositories that support inherited permissions. To compile the ACL of an object, the repository has to visit all parents, and the parents of the parents, and so on, until it hits the root.
- When you fetch an object, you can choose to retrieve no relationships, only the relationships where the object is the source or is the target, or all relationships the object is involved in. Some repositories have to filter which relationships the current user is allowed to see. Even if the number of relationships that the repository returns is small, the repository might have touched a greater number of objects, so only pick what you need. Check whether requesting the relationships with a separate getObjectRelationships call makes more sense than getting the relationships in the same call as getObject or getObjectByPath. This provides much better control over the result set. (The CMIS operation getObjectRelationships is called getRelationships in OpenCMIS and DotCMIS.)
- Prefer getObject to getObjectByPath. getObject is a bit faster for many repositories because many repositories internally organize their objects by object ID, not by path.
- Ask only for objects you really need. Pay special attention to operations that return lists and trees, such as getChildren, query, and getDescendants. With lists and trees, even minimal performance penalties per object multiply quickly. Losing a millisecond per object adds up to a second when a query returns 1,000 results. A second can be a long time for an end user.
- Use paging, and use it wisely. Ask only for the subset you really need. If you present a list to an end user, select only the first few entries. It’s not likely that an end user is interested in the thousandth query result. If you need to iterate over the entire list, go for relatively large pages, because that requires fewer round trips.
- If you have to sort a list, let the repository do it. The repository can do it more efficiently than your application. Most operations that return lists have an order by parameter.
- Select a reasonable tree depth for operations that take a depth parameter. Avoid the value -1 (infinite). Repositories can restrict the number of elements returned in a tree. Because these operations don’t support paging, asking for too many elements can be counterproductive. An incomplete tree is often useless for an application.
- Never use a SELECT * FROM ... query in a production application. Always provide the list of properties you want back. You don’t know how expensive it is for the repository to prepare the result set with all properties.
There shouldn’t been any real surprises in this list; we covered most of these items in previous chapters. But it’s good to recap them here. You may want to use them as a checklist when you encounter a performance issue.
13.3. Performance notes specific to OpenCMIS and DotCMIS
The list of performance considerations covered so far is applicable regardless of which CMIS client you’re using. Here are some items specific to OpenCMIS and DotCMIS:
- When you define a property filter in an OperationContext, OpenCMIS and DotCMIS always add the properties cmis:objectId, cmis:objectTypeId, and cmis:baseTypeId to the filter. This is necessary to construct proper CmisObjects.
- The create methods on the Session object (createDocument, createFolder, and so on) are faster than similar methods on other interfaces. These create methods return only the object ID and not the full-blown new object, which saves a round trip. If you want to create and forget objects, use these methods.
- There’s a getContentStream method on the Session object, which lets you get the content of a document directly without getting the document object. That can save a round trip to the repository.
- There’s also a delete method, which you can use to delete an object without fetching it first. That can save another round trip.
- In the CMIS specification, you’ll find the terms path segment and relative path segment in conjunction with the getChildren and getObjectParents operations. You can turn them on and off in the OperationContext, but there’s no need to turn them on. OpenCMIS and DotCMIS request them automatically if necessary.
- The OperationContext has a setMaxItemsPerPage method, which lets you define the actual page size that’s used when the repository is contacted to retrieve a list. For example, if you iterate over all children in a folder (where the folder has 1,000 children and max items per page is 100), then the library contacts the repository 10 times during the iteration to get a chunk of 100 children. There’s a trade-off between responsiveness and the total time to fetch all items in the list. A high max items per page value decreases the total time to fetch all items because it requires fewer round trips. But it also takes longer to retrieve the first item because a longer list must be compiled, transferred, and parsed first. This value depends on your use case.
- If you explicitly select a page with the getPage method, the max items per page value still applies. If the selected page size is bigger than the max items per page value, the library makes multiple calls until the data for the page has been completely served. If the selected page size is smaller than the max items per page value, the library makes one call that potentially requests more items than necessary for the page. If your page size is small (for example, you want to display the first 10 hits of a query), the page size and the max items per page value should be the same.
Caching is another way to avoid unnecessary calls. The next two sections explain the OpenCMIS and DotCMIS caches.
13.4. Caching
Caching is a common method to increase performance. OpenCMIS and DotCMIS provide several built-in caches (see figure 13.1). Most of them are invisible to the application, and application developers usually don’t need to be familiar with the details. But it helps to know the basics when you debug your application and trace the traffic between client and server.
Figure 13.1. Built-in OpenCMIS session caches at a glance
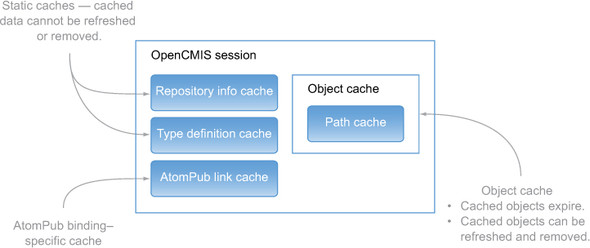
There are two types of caches. The first type caches static data that’s unlikely to change. The second type deals with object data that does change during runtime. The next two sections explain these caches.
Caches for other CMIS client libraries
Other client libraries may not provide built-in caches, but applications can build something similar on top. All programming languages provide the means to build a simple cache infrastructure. Web applications could, for example, use the HTML5 Web Storage. Although the following sections talk about the OpenCMIS caches and interfaces, these topics are also relevant for your homemade caches.
13.4.1. Caching static data
In a production environment, several things in CMIS are static and can be cached on the client side without side effects. These are mainly the repository info and the type definitions. This data is needed—directly or indirectly—over and over again in an application. So fetching it only once and caching it makes sense.
OpenCMIS transparently caches repository info and type definitions. The Session object manages all caches. You can turn these caches off or change the cache sizes when you set up the session. Usually you don’t have to change the cache settings—you can live with the defaults. But if your application deals with more than 100 different object types at the same time, you may want to increase the type definition cache size.
In development environments, type definitions may change while your application is running. New and removed types won’t harm your application. New types will be picked up when the application loads an object with this type for the first time. Removed types will stay in the cache, but there shouldn’t be any objects referencing them. When type definitions are modified and the type definition is already cached, OpenCMIS may throw exceptions when the first object that uses the changes is loaded. If you find yourself in this situation, you can either clear all caches by calling clear on the Session object or create a new Session object.
A session per user
You may wonder why these caches are attached to a session. Wouldn’t it be possible to have one repository info cache and one type definition cache for all sessions in the JVM? Wouldn’t that save additional calls and memory? This is a valid idea, but it doesn’t work that way. A session is bound to a user. A repository can return different repository info and different type definitions for each user. For example, the display names of type and property definitions can be localized for each user (see figure 13.2). Some users may not be allowed to see certain type definitions. And the repository info may return different repository capabilities if the user has admin privileges.
Figure 13.2. An OpenCMIS session is bound to a user. Each user has its own cache because a repository can return user-specific data. Here, three different users retrieved the same type definitions, and the repository returned localized display names.

The Session object and the caches belong together. That’s why you should always keep your Session object. Create one when you need it, and then reuse it whenever possible. Creating a second Session object for the same user is equivalent to throwing away your caches. And that adversely affects application performance.
The AtomPub link cache
There’s another cache in OpenCMIS that you’ll probably never notice because it resides deep down the stack. It caches AtomPub links (see section 11.2.2) and is crucial for the performance of the AtomPub binding implementation. This cache is mentioned here for those who want to build their own binding library. You should keep track of the links in Atom entries and feeds; they’re required for subsequent calls to the repository.
The cache settings can be adjusted with session parameters when the session is created. In contrast to the other two caches, it’s updated very frequently because each entry refers to a CMIS object. The cache size should reflect the number of objects your application is dealing with. The default cache size of 400 entries should work for most scenarios.
Apart from caching Atom links, caching whole objects can drastically increase the application performance. It’s a bit more difficult to manage, though. Let’s explore the OpenCMIS object cache.
13.4.2. Caching objects
Assume you’re developing a web application. It uses Ajax calls to refresh certain areas of your web page. Multiple Ajax calls refer to the same CMIS document. One call updates the properties view, another refreshes the ACL view, and a third lists the document renditions. Usually, different server threads serve each call.
Each thread could load the document data separately, but that would be a waste of time, bandwidth, and memory. Because this is the chapter about performance, we have a solution for you.
OpenCMIS has an object cache. Whenever you call getObject or getObjectByPath, it will first look into its cache. If the object is available, the method won’t fetch it from the repository but will serve it from the cache (see figure 13.3). Because OpenCMIS is thread-safe, you can and should reuse its objects across multiple threads.
Figure 13.3. Routing getObject and getObjectByPath calls through the object and path cache. If the requested object isn’t in the cache, the request is forwarded to the repository.
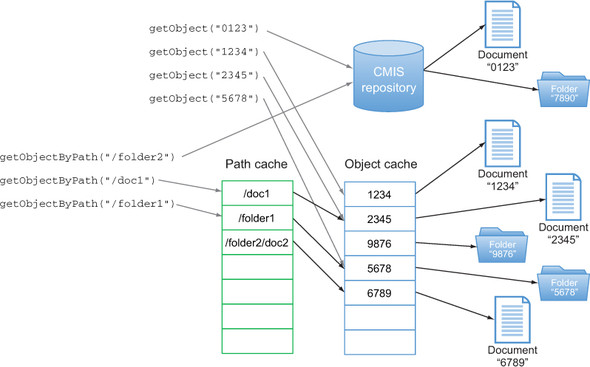
An object is the same object in the cache if the object ID is same and the same OperationContext (remember chapter 7) was used to retrieve the object. That is, an object can be in the cache more than once with a different set of metadata. This is another reason to keep the number of OperationContexts small and to reuse these objects.
The default cache is an LRU cache; each object expires after two hours. An additional cache keeps a mapping from the object path to the object ID; these cache entries time out after 30 minutes. All these characteristics can be adjusted when you create the session. You can even provide your own cache implementation or turn off the cache entirely.
Caches are good for performance, but they have a common problem: they can become stale. Sometimes you want a fresh object, and there are multiple ways to achieve that.
The OperationContext has a flag that controls whether the cache should be used (or not) for an operation. That’s handy if you repeatedly need fresh data. Set up such an OperationContext that turns off the cache, and reuse it, like this:

If you want to disable the cache for all operations that don’t take an OperationContext, you can do this:
session.getDefaultContext().setCacheEnabled(false);
A more individual way is to call refresh on an object. The object will contact the repository and ask for the same set of data it was originally created with. If the object no longer exists in the repository, refresh will throw a CmisObjectNotFoundException:
try {
doc.refresh();
} catch(CmisObjectNotFoundException notFound) {
}
A common misuse of refresh is this:

The first request for the object loads the object and then immediately refreshes it. That is, there are two calls to the repository, and the second one isn’t necessary.
Usually you want to refresh an object only after a certain period of time. Each object knows when it was last refreshed. If you need to know that too, call getRefreshTimestamp. This timestamp is also used for the refreshIfOld method. refreshIfOld takes a duration in milliseconds. If the object has been refreshed within this time span, refreshIfOld doesn’t do anything. Otherwise, it contacts the repository and refreshes the object:

How would you use this? Let’s go back to the web page example with the parallel Ajax requests. Each thread can call refreshIfOld with a duration of, let’s say, 10 seconds. Because Ajax requests are usually pretty close together, only the first call that hits the server refreshes the document data. It doesn’t matter which call is first.
Whether 5 seconds, 5 minutes, or 50 minutes is the best duration depends on your application. If your documents don’t change often, a long duration may be acceptable. A website with many visitors can reduce the load of the repository and improve the site’s performance with an appropriately long duration.
A tricky combination is the cache and the getObjectByPath method. The cache maps the path of an object to the object. If somebody deletes the object and creates a new object with the same path, the cache won’t recognize this and will return the old object (until it expires in the cache). Calling refresh on an object won’t help because it tries to reload the object by its ID. Because an object with this ID doesn’t exist anymore, you always get a CmisObjectNotFoundException. The pattern to deal with this situation is shown in the following listing.
Listing 13.1. Dealing with a deleted and re-created document at the same path

This listing tries to get the content of a document that was retrieved earlier by path. Someone deleted the original document, and now getContentStream throws a CmisObjectNotFoundException because there’s no longer a document with this object ID. That is, the object is invalid, and you can remove it from the cache. Then you try fetching the document again by path. If there’s a new document, you get the content stream. If there’s nothing at this path, you have to deal with it.
The static data cache described in the previous section resides in the low-level API implementation and therefore is available for both the low-level and high-level APIs of OpenCMIS and DotCMIS. The object cache is a feature of the high-level API. If you’re using the low-level API, you have to build your own object data cache.
13.5. Selecting the fastest binding
Performance varies widely among the three bindings. The Web Services binding is the slowest of the three. The AtomPub binding is significantly faster. And the Browser binding is even faster than the AtomPub binding.
To give you a rough idea of the differences, we ran a test set using a typical mix of operations against a fast repository on a fast network without compression. The AtomPub binding run was about three times faster than the Web Services binding run. And the Browser binding run was two times faster than the AtomPub binding run, as shown in figure 13.4.
Figure 13.4. Performance differences of the three CMIS bindings. The Browser binding is the fastest.

The absolute numbers depend on the repository, client, network setup, authentication method, and so on. If you have a choice, test all available bindings. OpenCMIS makes switching the binding pretty easy (see chapter 11).
One last word about the AtomPub binding: the content of a document is Base64-encoded when you’re creating a document with createDocument. That is, the content size grows by approximately a third when it’s transferred over the wire. That doesn’t matter when you’re uploading typical office documents, but it makes a difference when you’re uploading big video files or X-ray images. A workaround is to create an empty document first and then add the content to the document with setContentStream or appendContentStream, which don’t encode the content.
If the repository doesn’t allow or support setContentStream or appendContentStream, you should at least test whether the server supports client compression, because Base64 compresses very well. The next section explains how to turn that on. It also covers other HTTP-related and binding-independent performance hints.
13.6. Tuning HTTP for CMIS
All CMIS bindings are based on HTTP, and thus tuning HTTP performance helps CMIS applications and servers. Let’s walk through the most important aspects.
13.6.1. HTTP Keep-Alive
HTTP 1.1 defines that clients and servers should support Keep-Alive connections. That is, a socket connection between client and server should be reused for multiple requests. This is an important feature of CMIS because applications usually send a burst of requests to the repository. Here’s a simple example: the application wants to create a document in a folder. This may lead to the following sequence of calls:
1. getObjectByPath (get folder object)
2. getTypeDefinition (get the folder’s type, if not already cached)
3. getTypeDefinition (get the document’s type, if not already cached)
4. createDocument (create the document)
5. getObject (retrieve the newly created document to present the metadata to the user)
With Keep-Alive, this can happen over one connection. There’s no overhead for establishing multiple connections. This overhead can be considerable, especially if you use HTTPS. Many SSL handshakes can affect application performance.
There’s usually nothing you have to do to enable Keep-Alive. Most client libraries and repositories support it out of the box. But be prepared for a nasty surprise when you deploy your repository and your application in your production environment. Load balancers, proxy servers, and firewalls may not have Keep-Alive activated. If you encounter much worse performance after you move your application from the development to the production environment, check whether Keep-Alive is enabled along the way.
13.6.2. Compression
CMIS sends XML and JSON requests and responses over the wire. Both compress very well. The size of an AtomPub feed shrinks between 5% and 95% when it’s compressed. Compression can burst application performance, especially on slow networks and over the internet.
How do you enable compression? We have to look at requests and responses separately. Let’s start with responses.
Clients can request response compression by setting the HTTP header Accept-Encoding. OpenCMIS does that if you turn on compression when you set up the session (see chapter 6, section 6.5.2):
parameter.put(SessionParameter.COMPRESSION, "true");
That doesn’t necessarily mean the repository returns a compressed response. Some repositories support it out of the box, and others don’t. Check with the repository vendor as well as the application server vendor. If you can configure it, the following MIME types at least should be compressed:
- application/atomsvc+xml
- application/atom+xml;type=entry
- application/atom+xml;type=feed
- application/cmisquery+xml
- application/cmisallowableactions+xml
- application/cmisatom+xml
- application/cmistree+xml
- application/cmisacl+xml
- application/json
- application/xml
- text/xml
OpenCMIS can also compress requests. Turn on client compression when you set up the session, like this:
parameter.put(SessionParameter.CLIENT_COMPRESSION, "true");
OpenCMIS uses gzip to compress the XML and JSON payloads. Only a few repositories can handle compressed requests, though. Check with the repository vendor and application server vendor to find out if the repository you’re working with supports this feature.
The CMIS Workbench lets you switch request and response compression on and off in the login dialog box. Use a debug proxy, and watch the traffic as described in chapter 11. You’ll see that compression can make a huge difference.
13.6.3. Authentication and cookies
Chapter 12 covered the use of cookies for authentication. It’s important to mention it here again in the context of performance. Turning on cookies can drastically boost performance for some repositories because the repository has to check the user credentials only once per session. Try using the CMIS Workbench with and without cookies to test whether it makes a difference for the repository you want to use.
To turn on cookie support in OpenCMIS, use this session parameter:
parameter.put(SessionParameter.COOKIES, "true");
13.6.4. Timeouts
Connection and read timeouts aren’t performance-related. They control how quickly a call should fail if the application can’t connect to the repository. The end user’s perception of application performance may be related to this aspect.
You can set the timeouts in milliseconds as session parameters, as follows:
![]()
13.7. Summary
In this chapter, we discussed different factors that affect the performance of a CMIS application. Although repository performance plays a big role, several other factors, such as network infrastructure and application design, may have an impact. Read and make sure you understand the hints in this chapter before you start your first real CMIS application. Also be sure to revisit this chapter before you put your application into production.
If you’ve ever thought about building your own CMIS server, then the next chapter is what you’ve been waiting for. It covers the OpenCMIS Server Framework.