
A blending of the Google and Amazon web service APIs.
Google doesn’t have a lock on the API concept. Other companies and sites, including online bookstore Amazon, have their own APIs. Mockerybird’s Book Watch Plus (http://mockerybird.com/bookwatch-plus/bookwatch-plus.cgi) blends the Google and Amazon APIs with a feed of information from the Book Watch service (http://onfocus.com/BookWatch/) to create a list of books, referrals to them in Google, and a list of items that people who bought that book on Amazon also bought. Figure 6-15 illustrates this.
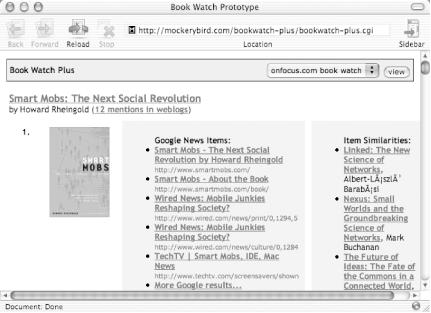
Book Watch Plus does several things to generate its page of information. First, it grabs a page of books most frequently mentioned on weblogs. That list is generated by another service run by Paul Bausch’s Book Watch service.
Book Watch Plus wrangles the ISBNs (unique identifiers for books) and then places a couple of calls. The first is to the Amazon web service for detailed information on the book. Then Google is queried via the Google Web API for items related to the book. All this information is aggregated on a regular basis rather than on the fly for each visitor. Results are cached in XML and displayed in the form of a web page via the HTML::Template Perl module.
Tip
You might think that with all this fetching and displaying of information, the hack would be a bit involved, and you’d be right. Running the hack requires two modules, a code snippet, and a template. They’re all available at http://mockerybird.com/bookwatch-plus/.
You’ll need two modules for Book Watch Plus: AmazonAPI and GoogleAPI.
The AmazonAPI module is available at http://mockerybird.com/bookwatch-plus/AmazonAPI.pm. You’ll have to get yourself a free Amazon Associates account (http://amazon.com/webservices/) before you can use it. Most of the module you can use as it stands, but you will have to make a small alteration to the beginning of the code:
# Your Amazon.com associates id and Web Services Dev Token. # (learn more about these here: http://amazon.com/webservices/) my $ASSOCIATE_ID = 'mockerybird'; my $AMAZON_DEV_TOKEN = 'a-token'; # The directory you'd like to store cached asins: # (it defaults to the same directory as the script, but you'll # probably want to change that.) my $XML_DIR = "./";
You’ll need to replace
mockerybird with your own Amazon Associate ID, and
a-token with your own Web Services Development
Token.
If you want to have the cached book information stored in a different
directory than where the script is located, you’ll
need to change the my $XML_DIR line to the
directory of your choice.
For example, if your associate ID were tara,
developer token googlehacks, and preferred cache
directory /home/tara/google/bookwatchplus/cache,
those lines should read:
# Your Amazon.com associates id and Web Services Dev Token. # (learn more about these here: http://amazon.com/webservices/) my $ASSOCIATE_ID = 'tara'; my $AMAZON_DEV_TOKEN = 'googlehacks'; # The directory you'd like to store cached asins: # (it defaults to the same directory as the script, but you'll # probably want to change that.) my $XML_DIR = "/home/tara/google/bookwatchplus/cache";
(Note the changes highlighted in bold.)
The GoogleAPI.pm
module is available at http://mockerybird.com/bookwatch-plus/GoogleAPI.pm.
You’ll have to make a couple of changes to this
module as well; the lines you’re after are:
package GoogleAPI; # The directory you'd like to store cached asins: # (it defaults to the same directory as the script, but you'll # probably want to change that.) my $XML_DIR = "./"; # <-- PUT A DIRECTORY HERE TO STORE XML # Get your Google API key here: # http://www.google.com/apis/download.html my $key = ""; # <-- PUT YOUR KEY HERE
Just like the AmazonAPI, you’ll have an option to
change the directory to which cached information is saved. If you
want to change the directory (by default, the information is saved in
the same directory where the script is installed) change the
my $XML_DIR line. You’ll also
need to put your Google developer’s key on the
my $key = ""; line.
If your Google Web API developer’s key were
12BuCK13mY5h0E/34KN0cK@ttH3Do0R and preferred
cache directory
/home/tara/google/bookwatchplus/cache, those lines
should read:
package GoogleAPI; # The directory you'd like to store cached asins: # (it defaults to the same directory as the script, but you'll # probably want to change that.) my $XML_DIR = "/home/tara/google/bookwatchplus/cache"; # <-- PUT A DIRECTORY HERE TO STORE XML # Get your Google API key here: # http://www.google.com/apis/download.html my $key = "12BuCK13mY5h0E/34KN0cK@ttH3Do0R"; # <-- PUT YOUR KEY HERE
(Note the changes highlighted in bold.)
There’s a sample template available at http://mockerybird.com/bookwatch-plus/bookwatch-plus.txt.
Finally, you’ll need the CGI script itself; it’s available at http://mockerybird.com/bookwatch-plus/bookwatch-plus-cgi.txt. You’ll need to change several variables on the CGI script. They’re listed at the beginning of the script and are as follows:
-
$default_book_rss_feed_url The RSS feed you want as the default for the hack
-
$book_display_template The default template with which you want to display the Book Watch items
-
$number_of_items_in_list Number of items to display
-
$number_of_google_results Number of results from Google (defaults to 5)
-
$number_of_amazon_similarities Number of similar items listed at Amazon (defaults to 5)
-
$xml_cache_directory Where to store the XML cache materials
-
$num_minutes_to_cache_rss_feeds For how long your RSS feeds should be stored before being refreshed
In addition to these variables, you can alter the list of RSS feeds
used by the site, from which the program gets its book information.
If you don’t have any RSS feeds in mind, leave the
ones that are here alone and don’t alter the
$default_book_rss_feed_url above.