
Separate out search results by the depth at which they appear in a site.
Google’s a mighty big haystack under which to find the needle you seek. And there’s more, so much more; some experts believe that Google and its ilk index only a bare fraction of the pages available on the Web.
Because the Web’s getting bigger all the time, researchers have to come up with lots of different tricks to narrow down search results. Tricks and—thanks to the Google API—tools. This hack separates out search results appearing at the top level of a domain from those beneath.
Why would you want to do this?
Clear away clutter when searching for proper names. If you’re searching for general information about a proper name, this is one way to clear out mentions in news stories, etc. For example, the name of a political leader like Tony Blair might be mentioned in a story without any substantive information about the man himself. But if you limited your results to only those pages on the top level of a domain, you would avoid most of those “mention hits.”
Find patterns in the association of highly ranked domains and certain keywords.
Narrow search results to only those bits that sites deem important enough to have in their virtual foyers.
Skip past subsites, the likes of home pages created by J. Random User on their service provider’s web server.
#!/usr/local/bin/perl
# gootop.cgi
# Separates out top level and sub-level results
# gootop.cgi is called as a CGI with form input
# Your Google API developer's key
my $google_key='insert key here';
# Location of the GoogleSearch WSDL file
my $google_wdsl = "./GoogleSearch.wsdl";
# Number of times to loop, retrieving 10 results at a time
my $loops = 10;
use strict;
use SOAP::Lite;
use CGI qw/:standard *table/;
print
header( ),
start_html("GooTop"),
h1("GooTop"),
start_form(-method=>'GET'),
'Query: ', textfield(-name=>'query'),
' ',
submit(-name=>'submit', -value=>'Search'),
end_form( ), p( );
my $google_search = SOAP::Lite->service("file:$google_wdsl");
if (param('query')) {
my $list = { 'toplevel' => [], 'sublevel' => [] };
for (my $offset = 0; $offset <= $loops*10; $offset += 10) {
my $results = $google_search ->
doGoogleSearch(
$google_key, param('query'), $offset,
10, "false", "", "false", "", "latin1", "latin1"
);
foreach (@{$results->{'resultElements'}}) {
push @{
$list->{ $_->{URL} =~ m!://[^/]+/?$!
? 'toplevel' : 'sublevel' }
},
p(
b($_->{title}||'no title'), br( ),
a({href=>$_->{URL}}, $_->{URL}), br( ),
i($_->{snippet}||'no snippet')
);
}
}
print
h2('Top-Level Results'),
join("
", @{$list->{toplevel}}),
h2('Sub-Level Results'),
join("
", @{$list->{sublevel}});
}
print end_html;Gleaning a decent number of top-level domain results means throwing
out quite a bit. It’s for this reason that this
script runs the specified query a number of times, as specified by
my $loops = 10;, each loop picking up 10 results,
some subset being top-level. To alter the number of loops per query,
simply change the value of $loops. Realize that
each invocation of the script burns through $loops
number of queries, so be sparing and don’t bump that
number up to anything ridiculous—even 100 will eat through a
daily alotment in just 10 invocations.
The heart of the script, and what differentiates it from your average Google API Perl script [Hack #50], lies in this snippet of code:
push @{
$list->{ $_->{URL} =~ m!://[^/]+/?$!
? 'toplevel' : 'sublevel' }
}What that jumble of characters is scanning for is
:// (as in http://) followed by
anything other than a / (slash), thereby sifting
between top-level finds (e.g., http://www.berkeley.edu/welcome.html) and
sublevel results (e.g., http://www.berkeley.edu/students/john_doe/my_dog.html).
If you’re Perl savvy, you may have noticed the
trailing /?$; this allows for the eventuality that
a top-level URL ends with a slash (e.g., http://www.berkeley.edu/), as is often true.
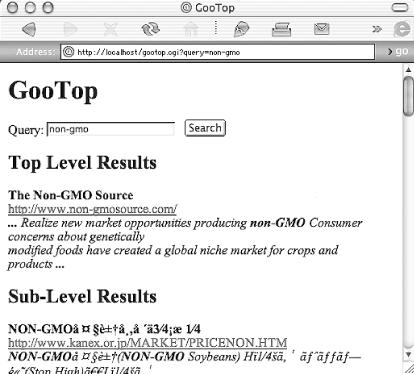
This hack runs as a CGI script. Figure 6-16 shows
the results of a search for non-gmo (Genetically
Modified Organisms, that is).
There are a couple of ways to hack this hack.
Perhaps your interests lie in just how deep results are within a site or sites. A minor adjustment or two to the code, and you have results grouped by depth:
...
foreach (@{$results->{'resultElements'}}) {
push @{ $list[scalar ( split(///, $_->{URL} . ' ') - 3 ) ] },
p(
b($_->{title}||'no title'), br( ),
a({href=>$_->{URL}}, $_->{URL}), br( ),
i($_->{snippet}||'no snippet')
);
}
}
for my $depth (1..$#list) {
print h2("Depth: $level");
ref $list[$depth] eq 'ARRAY' and print join "
",@{$list[$depth]};
}
}
print end_html;
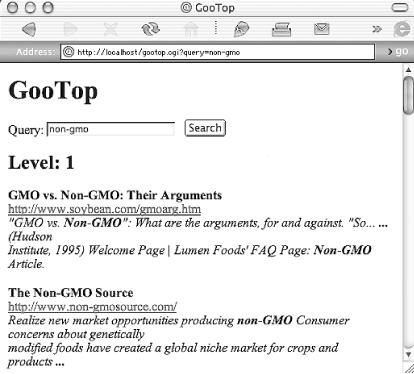
Figure 6-17 shows that non-gmo
search again using the depth hack.
Along with the aforementioned code hacking, here are a few query tips to use with this hack:
Consider feeding the script a date range [Hack #11] query to further narrow results.
Keep your searches specific, but not too much so for fear of turning up no top-level results. Instead of
cats, for example, use"burmese cats", but don’t try"burmese breeders" feeding.Try the link: [Section 1.5] syntax. This is a nice use of a syntax otherwise not allowed in combination [Hack #8] with any others.
On occasion,
intitle:works nicely with this hack. Try your query without special syntaxes first, though, and work your way up, making sure you’re getting results after each change.