
6
List Expressions, UNION, and Subqueries
We have looked at filtering and sorting in Cypher queries in earlier chapters. In this chapter, we will take a look at more advanced options for querying.
We will cover the following topics:
- Working with list expressions
- Working with UNION in Cypher
- Working with subqueries
List expressions provide a powerful paradigm to manipulate list results in Cypher. UNION queries provide the means to combine the results of distinct queries and return data. Subqueries provide a powerful option for executing a query inside another query and using the results in the main query.
Now, let us take a look at list expressions.
Working with list expressions
Cypher provides native support for lists. This means that not only are they treated as first-class entities, such as integers or strings, but all the functions that can create, manipulate, or process the lists are built into Cypher. Let us look at the following functions, all of which are available to process lists:
- range
- head
- tail
- last
- size
- reverse
- reduce
As well as these functions, we can also use list comprehensions. First, we will take a look at the preceding functions, and then we will explore list comprehensions in greater depth.
Let us look at the range function.
Working with the range function
The range function provides a way to create a list with numbers. It takes a start value and an end value with an optional step parameter and returns a list of all integer values bound by start and end. The syntax of the range function is as follows:
range(start, end [, step])
The step value is optional as seen by the syntax. When the step value is not provided it defaults to 1. If you provide a negative step value, this function returns an empty list. Let us look at a few examples:
RETURN range(1,10)
This query is preparing a list of integers starting with a value of 1 and ending with a value of 10, in increments of 1. We can see this aspect in the following figure:
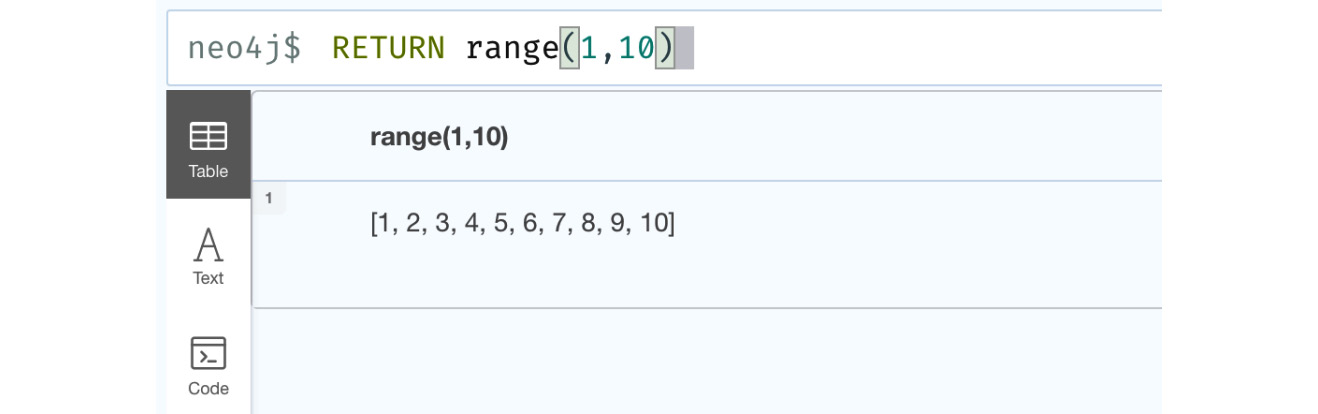
Figure 6.1 – Basic range function usage
In the screenshot, we can see the response when we execute this function. We can see that this function returns a list with values from 1 to 10. Let us look at an example where the step parameter has a value of 3:
RETURN range(5,35,3)
This query is preparing a list of integers starting with a value of 5 and ending with a value of 35 in increments of 3. We can see this in the following figure:
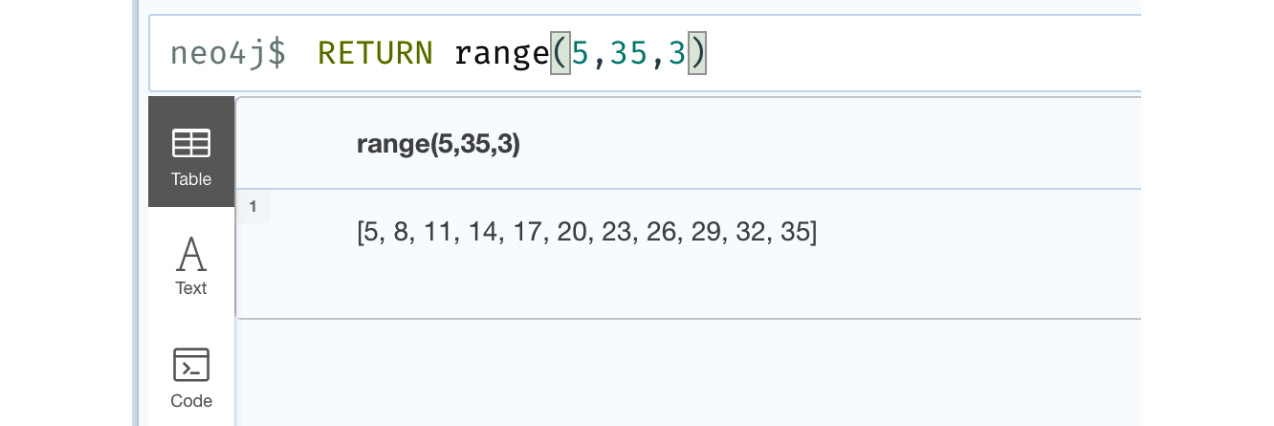
Figure 6.2 – range function usage with a step parameter
In the screenshot, we can see that when we use a step parameter, we get a list of values starting from the start value, with increments of the step value, until we reach the end value.
Now let us look at the head function.
Working with the head function
The head function returns the first element of a list.
Let us look at the usage of the head function:
WITH [1,2,3,4] as list RETURN head(list)
This query is returning the head (first) element of the list, as shown in the following figure:
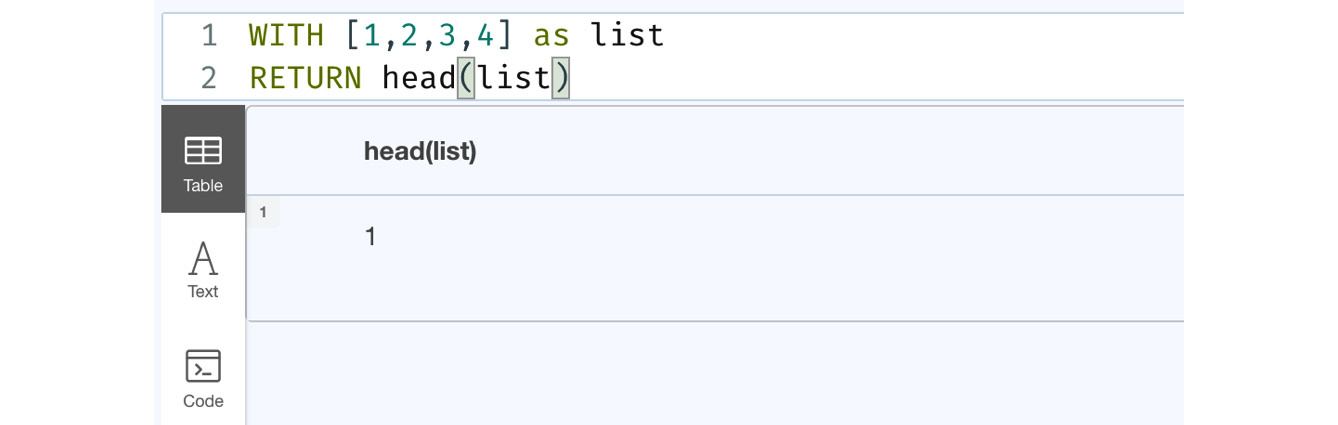
Figure 6.3 – Usage of the head function
This screenshot shows the usage of the head function. We can see that this function returns the first element of the list.
Next, we will look at the tail function.
Working with the tail function
The tail function returns all the elements except for the first element of a list.
Let us look at the usage of the tail function:
WITH [1,2,3,4] as list RETURN tail(list)
This query returns the tail part of a list, which is the list without the first element, as shown in the following figure:
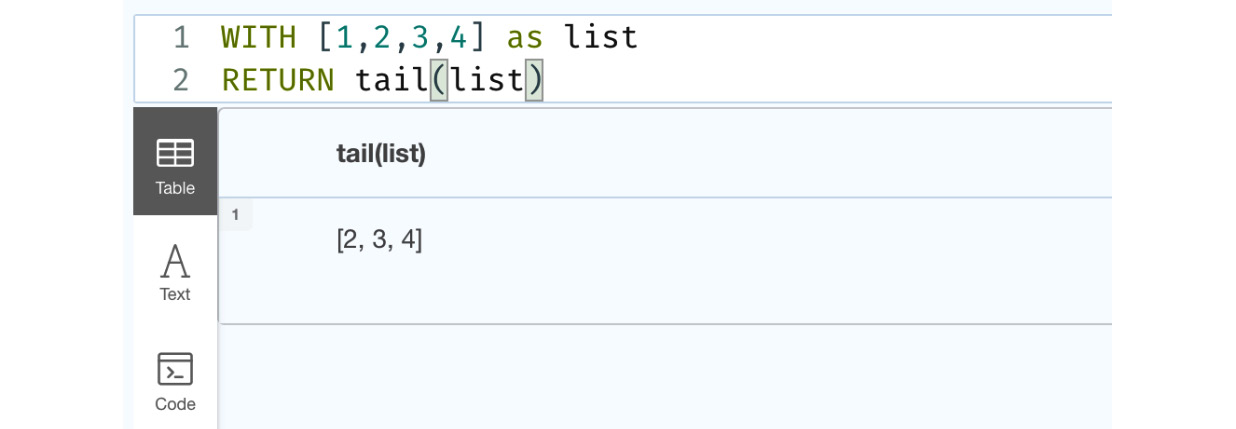
Figure 6.4 – Usage of the tail function
This screenshot shows the usage of the tail function. We can see that the tail function returns a list without the first element of the input list provided.
Next, we will look at the last function.
Working with the last function
The last function returns the last element in a list.
Let us look at the usage of the last function:
WITH [1,2,3,4] as list RETURN last(list)
This query returns the last element of a list, as shown in the following figure:
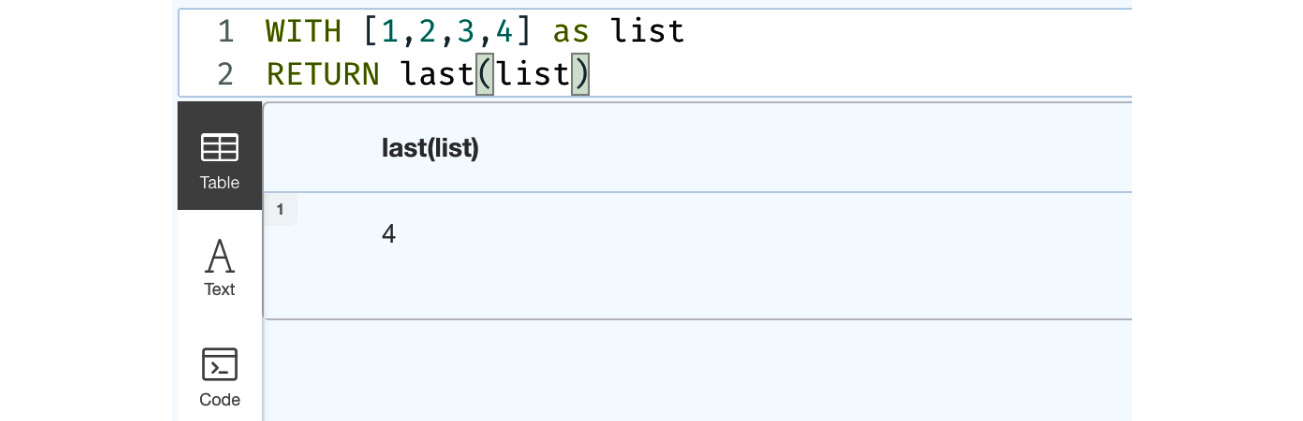
Figure 6.5 – Usage of the last function
This screenshot shows the usage of the last function. We can see that this function returns the last element in a list.
Next, we will look at the size function.
Working with the size function
The size function returns the last element in a list.
Let us look at the usage of the size function:
WITH [1,2,3,4,10,15] as list RETURN size(list)
This query returns the size of a list, as shown in the following figure:
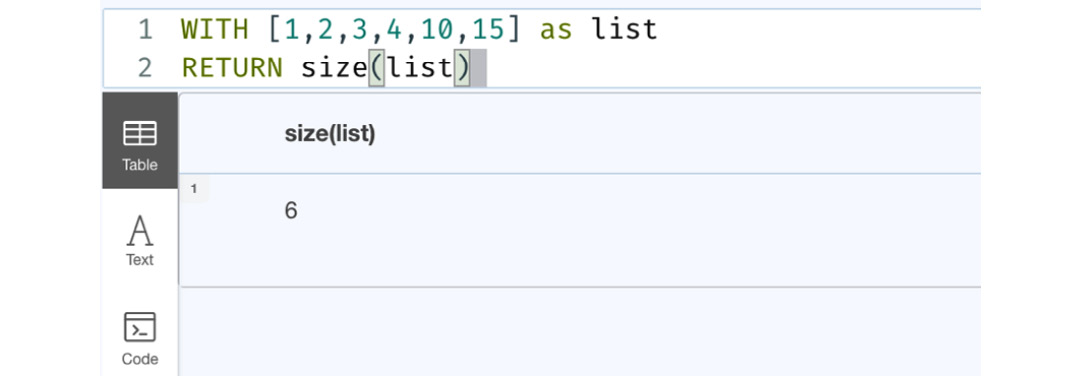
Figure 6.6 – Usage of the size function
This screenshot shows the usage of the size function. We can see this function returns the size of a list.
Next, we will look at the reverse function.
Working with the reverse function
The reverse function returns the elements of a list in reverse order.
Let us look at the usage of the reverse function:
WITH [1,2,3,4,10,15] as list RETURN reverse(list)
This query returns a list in reverse order, as shown in the following figure:
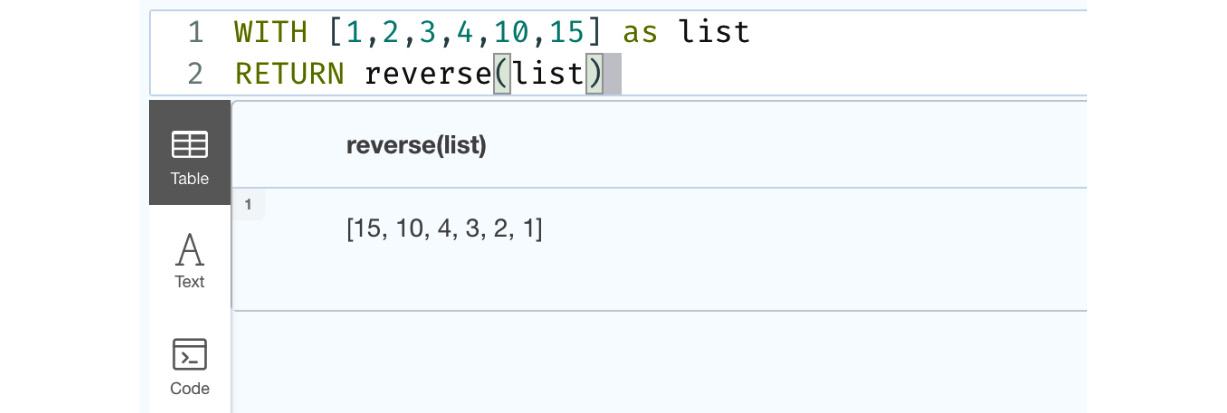
Figure 6.7 – Usage of the reverse function
This screenshot shows the usage of the reverse function. We can see it returns a list with values in reverse order.
Next, we will look at the reduce function.
Working with the reduce function
The reduce function is used to aggregate a result by traversing the list. This function will iterate through each of the elements in the given list, run the expression on element e, while taking into account the current partial result, and store the new partial result in the accumulator value:
The syntax of this function looks like this. reduce(accumulator = initial, variable IN list | expression)
The following table explains the arguments of the reduce function:
|
Name |
Description |
|
accumulator |
A variable that will hold the result, and the partial results, as we iterate through the list. |
|
initial |
Expression to assign an initial value to the accumulator. |
|
list |
An expression that returns a list. |
|
variable |
The variable is used to assign the element while we iterate through the list. |
|
expression |
The expression will run once for each value in the list, and produce the result value. |
Figure 6.8 – Arguments of the function
Let us look at the usage of this function:
WITH [1,2,3,4,10,15] as list RETURN reduce(sum=0, x in list | sum + x) as total
This query returns the sum of all the values in the list, as shown in the following figure:
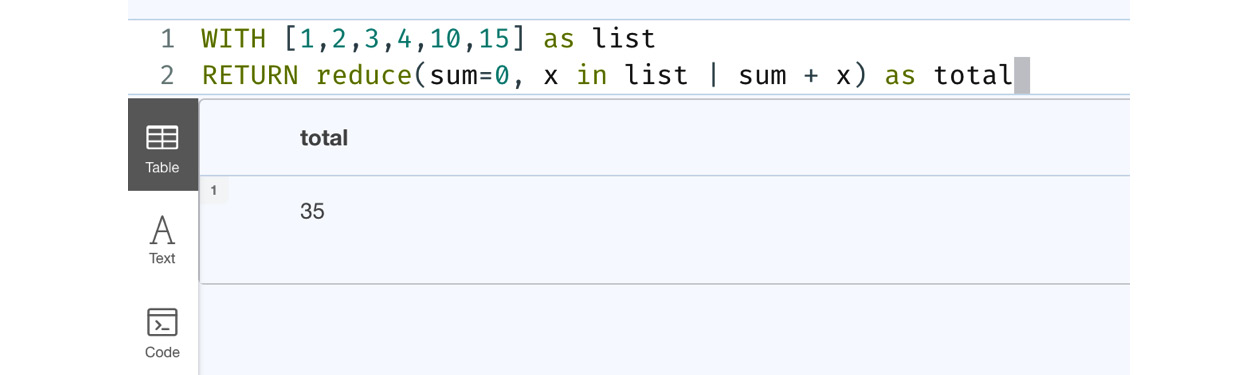
Figure 6.9 – Usage of the reduce function
From the screenshot, we can see the reduce function here is used to calculate the sum of the values in the list.
Let us take a look at another example to calculate the sum of squares:
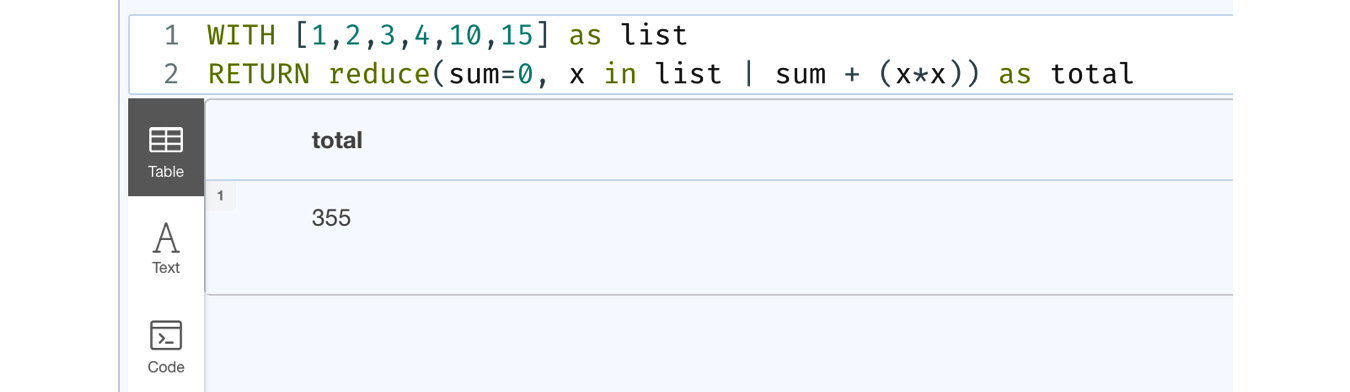
Figure 6.10 – Usage of the reduce function – 2
From the screenshot, we can see that we got the sum of squares of the list values as the final result.
Next, we will look at list comprehensions.
Working with list comprehensions
List comprehensions are a means to create lists from other lists, based on expression evaluation of the elements of the original list. They are similar to set comprehensions.
Let us look at an example where we get a list of the squares of even values in the list:
WITH [1,2,3,4,10,15] as list RETURN [x in list WHERE x % 2 = 0 | x*x ] as squareList
This query returns a list with the square values of only the even numbers in the list, as shown in the following figure:
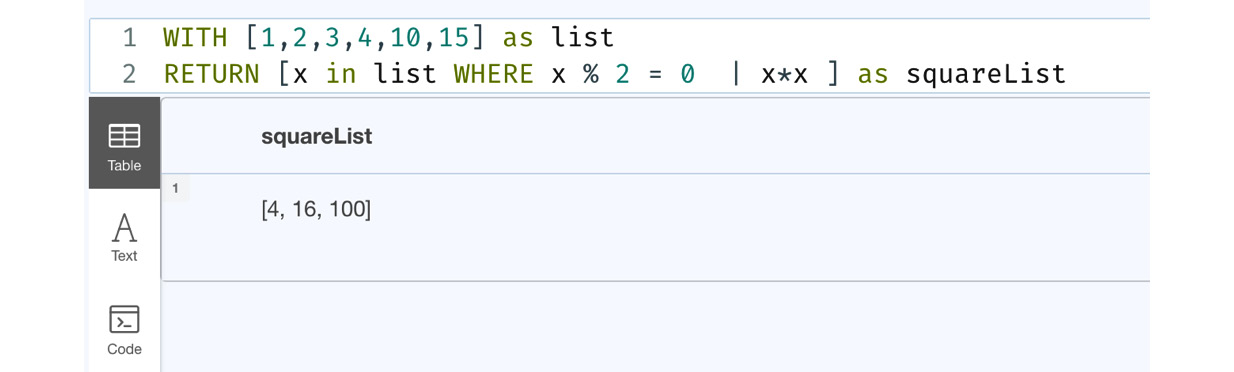
Figure 6.11 – Usage of list comprehensions
From the screenshot, we can see that list comprehension returns a list of squares of values, which are even in the original list.
We can see from our earlier usage of the reduce function that we cannot use a conditional traversal of a list. In list comprehensions, we cannot iterate through a list and create a single value out of it. However, we can combine both of these to do some complex operations. Say we want to calculate the sum of squares but only when the value is even; we can combine both to achieve that. Let us see the query that can help us accomplish this:
WITH [1,2,3,4,10,15] as list RETURN reduce( total = 0 , y in [x in list WHERE x % 2 = 0 | x ] | total+y*y) as sumOfSquares
Let us see the result of the execution of this query
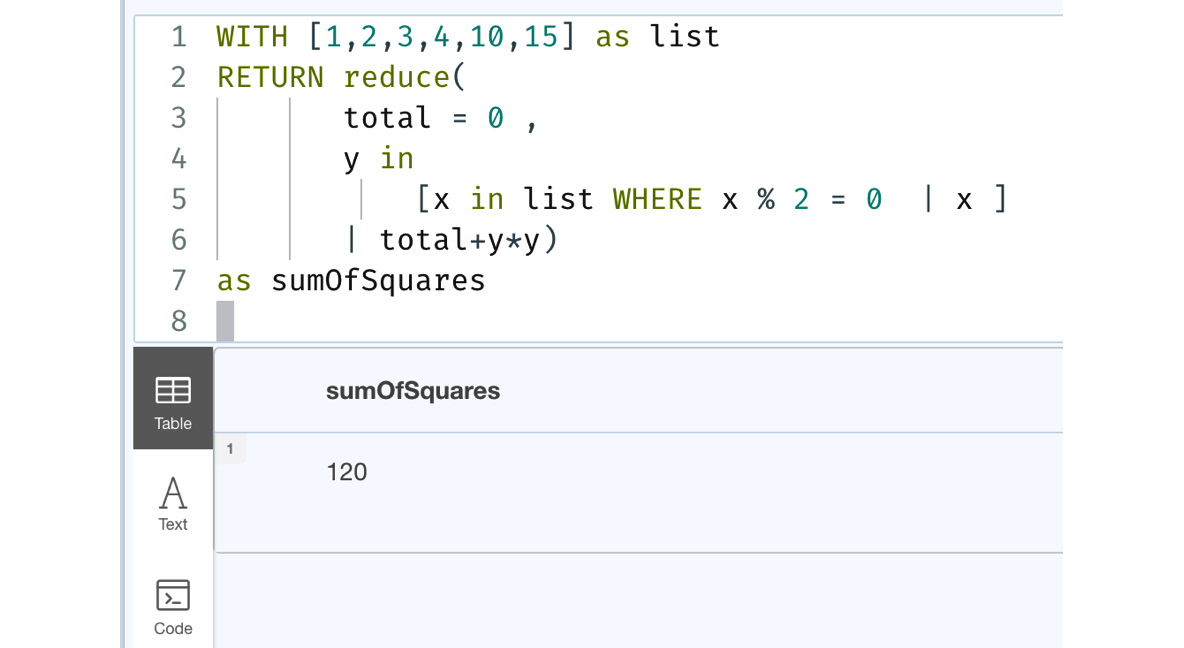
Figure 6.12 – Usage of list comprehensions and the reduce function
We can see from the result that we can get a single by filtering the list for even numbers from the original list and using the reduce function to calculate the sum of squares.
We will take a look at using UNION cypher queries in the next section.
Working with UNION in Cypher
The UNION clause combines the results of two or more queries and returns the results. It works pretty similarly to how it works in SQL queries. Normally, we use the UNION clause when we want to combine the results of multiple, disparate queries returning similar datasets.
Let’s look at an example usage of the UNION clause:
MATCH (p:Patient)-[:HAS_ENCOUNTER]->()-[:HAS_DIAGNOSIS]->(d) WHERE p.id='f237e253-9052-a038-7c9e-dbd9a1d7da32' RETURN d.code as drug UNION MATCH (p:Patient)-[:HAS_ENCOUNTER]->()-[:HAS_DIAGNOSIS]->(d) WHERE p.id='ffa580de-08e5-9a47-b12a-db312ad6825b' RETURN d.code as drug
This query returns the diagnosis codes used among two patients, as shown in the following figure:
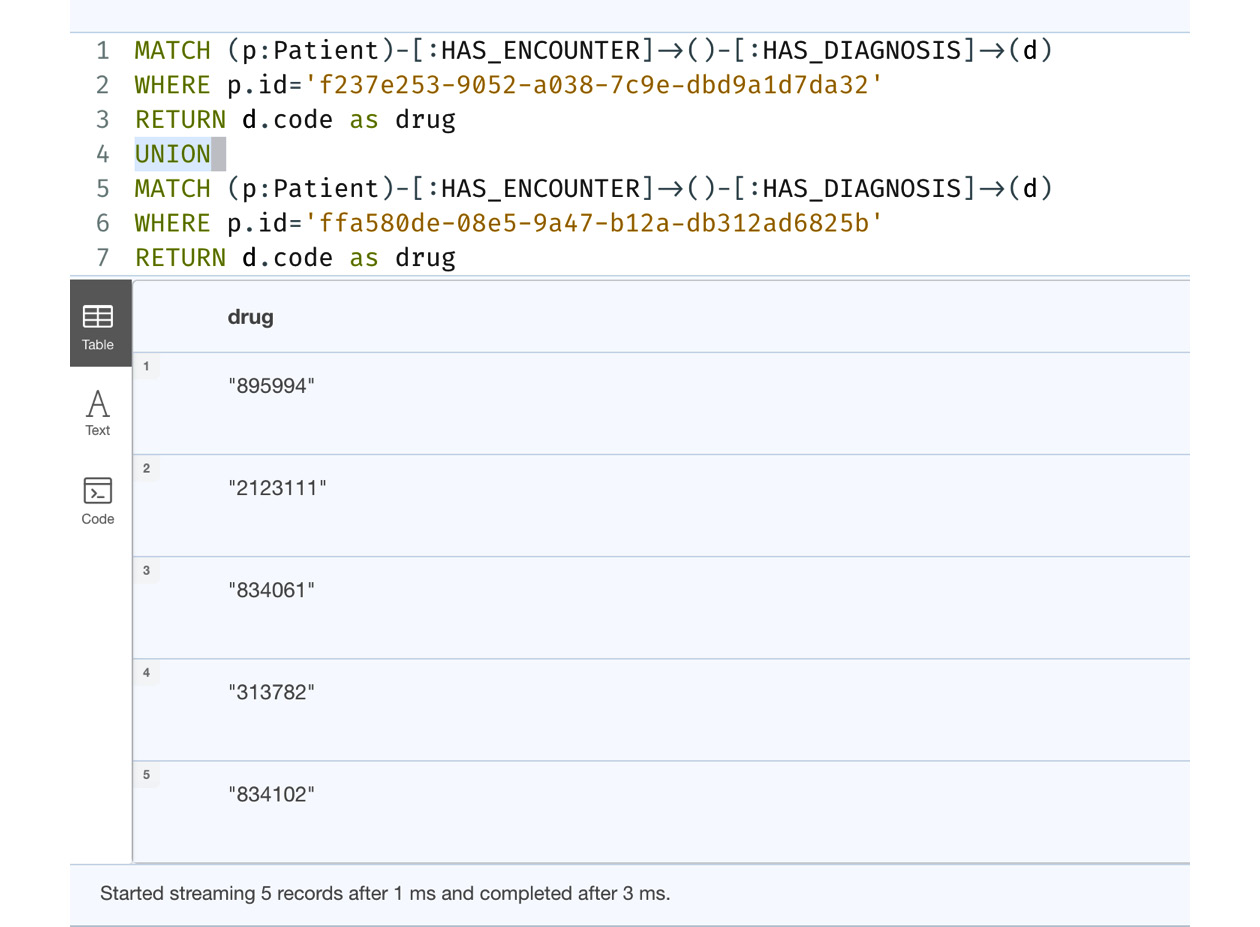
Figure 6.13 – Usage of the UNION clause
We can see there are five records returned. The UNION clause eliminates duplicate records in the results if there are any.
We could have written the same query without using the UNION clause. Let’s take a look at that query and see if there are any differences in the response:
MATCH (p:Patient)-[:HAS_ENCOUNTER]->()-[:HAS_DIAGNOSIS]->(d) WHERE p.id='f237e253-9052-a038-7c9e-dbd9a1d7da32' OR p.id='ffa580de-08e5-9a47-b12a-db312ad6825b' RETURN d.code as drug
This query returns the diagnosis codes used among two patients, as shown in the following figure:

Figure 6.14 – Query without the UNION clause for comparison
We can see from the screenshot that this query returns 10 records in total. We can also see that there are duplicate records. This explains the difference between this query and the UNION query. The UNION query removed duplicates and returned the distinct values.
Say we don’t want to eliminate duplicates in the response; then, we need to use the UNION ALL clause, as shown here:
MATCH (p:Patient)-[:HAS_ENCOUNTER]->()-[:HAS_DIAGNOSIS]->(d) WHERE p.id='f237e253-9052-a038-7c9e-dbd9a1d7da32' RETURN d.code as drug UNION ALL MATCH (p:Patient)-[:HAS_ENCOUNTER]->()-[:HAS_DIAGNOSIS]->(d) WHERE p.id='ffa580de-08e5-9a47-b12a-db312ad6825b' RETURN d.code as drug
Let us look at the response to this query:
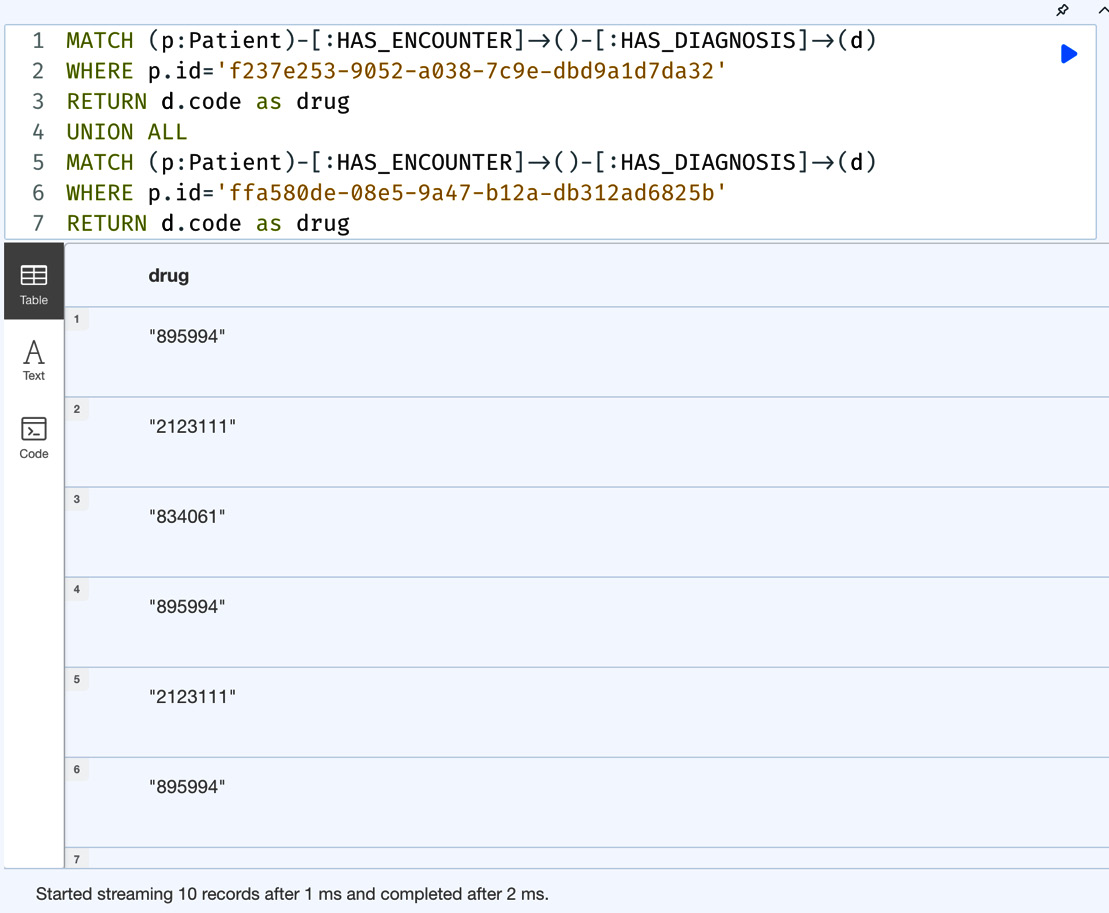
Figure 6.15 – Usage of the UNION ALL clause
From the screenshot, we can see that the UNION ALL query returns 10 records, some of which are duplicates. This matches what we are expecting from the response.
While the example we have used for the UNION query could have been built using a single query, it showcases its capabilities.
Next, we will take a look at working with subqueries in Cypher.
Working with subqueries
Cypher allows you to write subqueries using the CALL clause. There are two types of subqueries available:
- Returning subqueries
- Unit subqueries
The subqueries are evaluated for each incoming row that is provided by the parent query.
Let us work with returning subqueries first.
Working with returning subqueries
Subqueries that end with a RETURN statement are called returning subqueries. Every row from a returning subquery is combined with the input row to prepare the result of the query. This means the final output of the outer query can be impacted by the subquery returned values.
Note
If a subquery does not return any rows, then there will not be any rows returned by the outer query.
Returning subqueries are very useful when we want to apply sorting and extra filtering to UNION queries. When we use the UNION clause, it is not possible to apply any sorting. Let us take a look at a UNION query with sorting using a subquery:
CALL {
MATCH (p:Patient)-[:HAS_ENCOUNTER]->()-[:HAS_DIAGNOSIS]->(d)
WHERE p.id='f237e253-9052-a038-7c9e-dbd9a1d7da32'
RETURN d.code as drug
UNION
MATCH (p:Patient)-[:HAS_ENCOUNTER]->()-[:HAS_DIAGNOSIS]->(d)
WHERE p.id='ffa580de-08e5-9a47-b12a-db312ad6825b'
RETURN d.code as drug
}
RETURN drug
ORDER BY drug DESCThis query should return the drugs in descending order. Let’s execute the query and check:
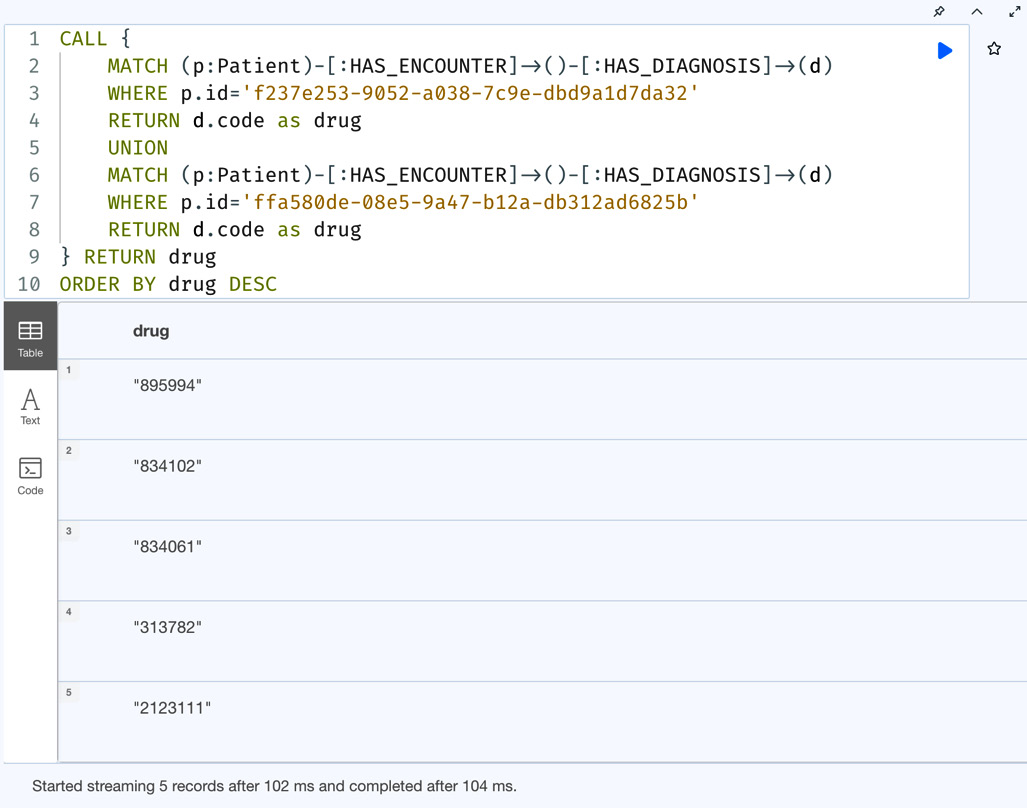
Figure 6.16 – Usage of a subquery to sort UNION results
We can see from the screenshot that the drug codes are returned in descending order. It is also possible to apply extra filtering or use this data to execute another set of queries.
Let us modify the query to get the drug names after getting the codes:
CALL {
MATCH (p:Patient)-[:HAS_ENCOUNTER]->()-[:HAS_DIAGNOSIS]->(d)
WHERE p.id='f237e253-9052-a038-7c9e-dbd9a1d7da32'
RETURN d as drug
UNION
MATCH (p:Patient)-[:HAS_ENCOUNTER]->()-[:HAS_DIAGNOSIS]->(d)
WHERE p.id='ffa580de-08e5-9a47-b12a-db312ad6825b'
RETURN d as drug
}
WITH drug
RETURN drug.code as code, drug.description as nameIn this query, after the subquery returns the drug node and we get the drug code and drug name.
Let’s execute the query and check the results:
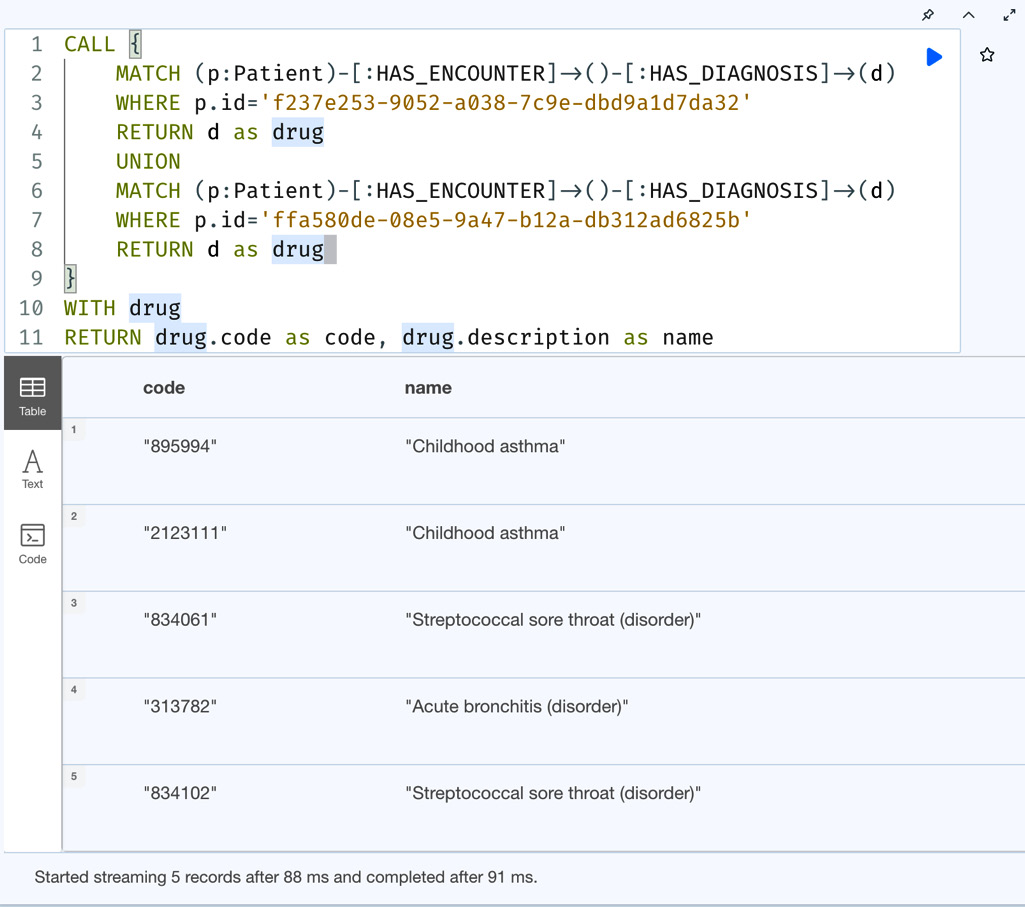
Figure 6.17 – Usage of the subquery to perform extra logic on the UNION results
We can see from the screenshot that we can take the results from a UNION subquery and perform extra logic on the results.
Note
This is where subqueries differ from SQL subqueries. SQL subqueries are limited to joining aspects. In Cypher, after a subquery, we can perform extra logic.
In the preceding query, we started with a subquery and processed the results later. If we have some data before we go into the subquery, then we have to use the WITH clause to pass the data to the subquery.
Let’s look at an example of this:
UNWIND [1, 2, 3] AS x
CALL {
WITH x
RETURN x * x AS y
}
RETURN x, yThis query processes the list in the outer query and assigns each element to a variable named x. To pass this variable to the subquery, which calculates the square of that value, we have to use the WITH clause.
Let’s execute the query and check the results:
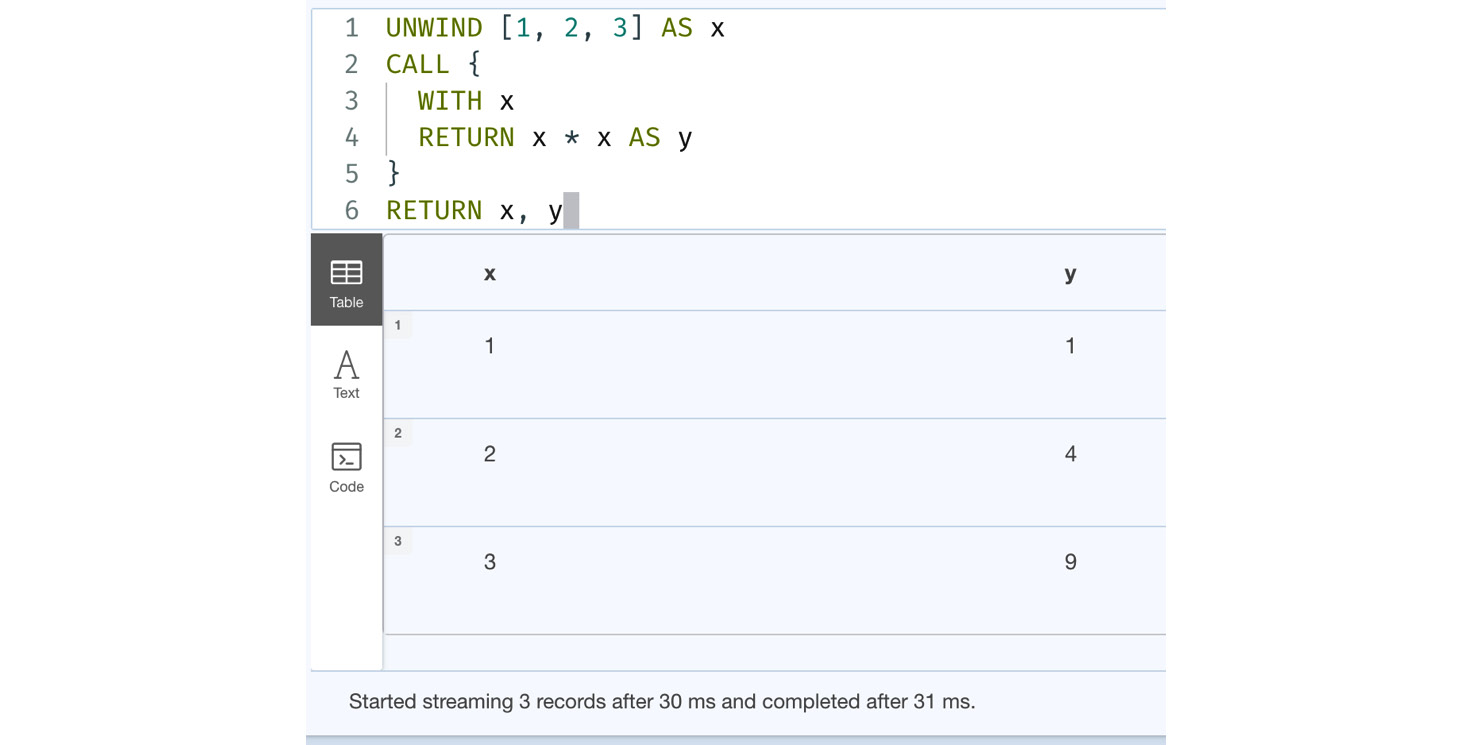
Figure 6.18 – Passing data to the subquery
We can see the results of this query in the screenshot. If we do not use the WITH clause in the query, it throws an error that looks as follows:
Variable `x` not defined (line 3, column 10 (offset: 38))
It is also possible to combine the results from the outer query and subquery. Let’s look at an example of this:
MATCH (p:Patient {id:'f237e253-9052-a038-7c9e-dbd9a1d7da32'})
CALL {
WITH p
MATCH (p)-[:HAS_ENCOUNTER]->()-[:HAS_DIAGNOSIS]->(d)
RETURN d as drug
}
WITH DISTINCT p, drug
RETURN
p.firstName as firstName,
drug.code as code,
drug.description as drugIn this query, we find a patient and can use a subquery to get all the drugs that were prescribed to him and return the patient’s first name, drug code, and drug name. We are also using the DISTINCT clause here to make sure that even if a drug is prescribed more than once, we are only returning the code and name once.
Let’s look at this query execution.
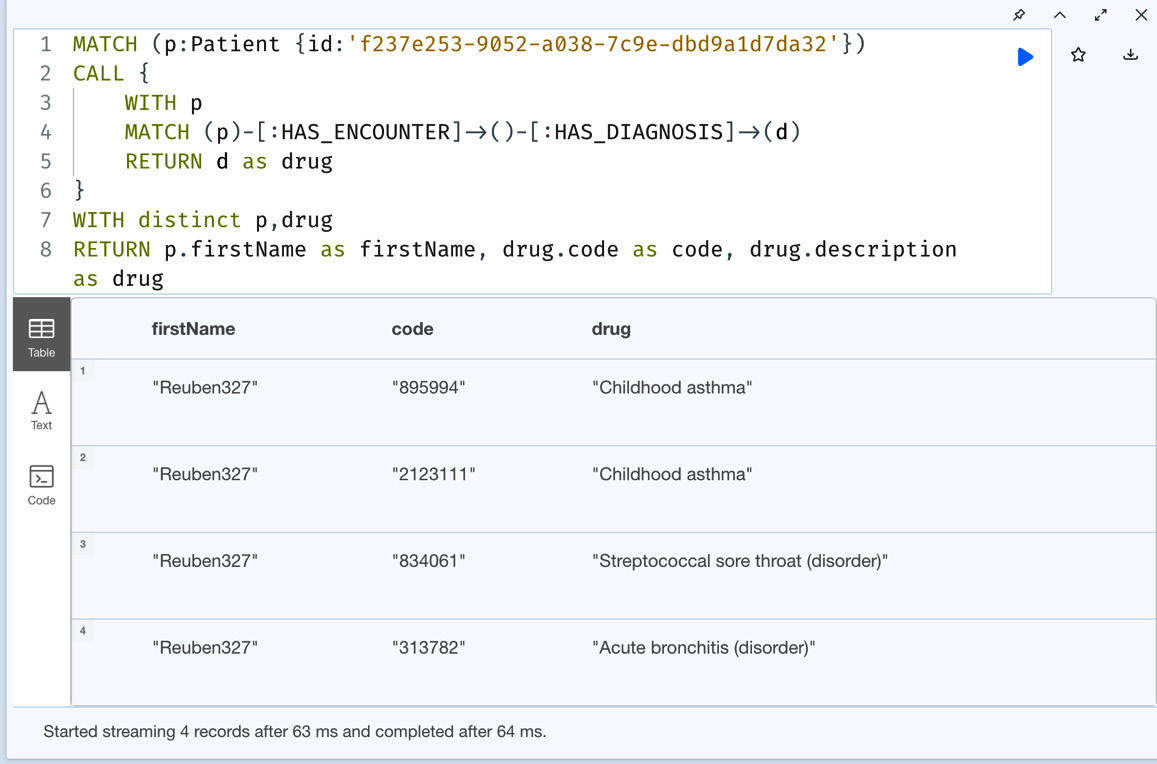
Figure 6.19 – Combing data from an outer query and a subquery
We can see from the screenshot that we can combine the data from an outer query and a subquery and return the results. Now, let’s take a look at unit subqueries.
Working with unit subqueries
Unit subqueries do not use the RETURN clause. This means we can only perform data updates when we use this pattern. Since there is no RETURN clause in the subquery, the number of rows returned by the enclosing query is not affected by what the subquery does.
Let’s look at an example of a unit subquery:
UNWIND range (1, 5) AS index
CALL {
WITH index
CREATE (t:Test {id:index})
}
RETURN indexIn this query, the subquery creates a node and does not return any data. Let’s see the execution results of this query:
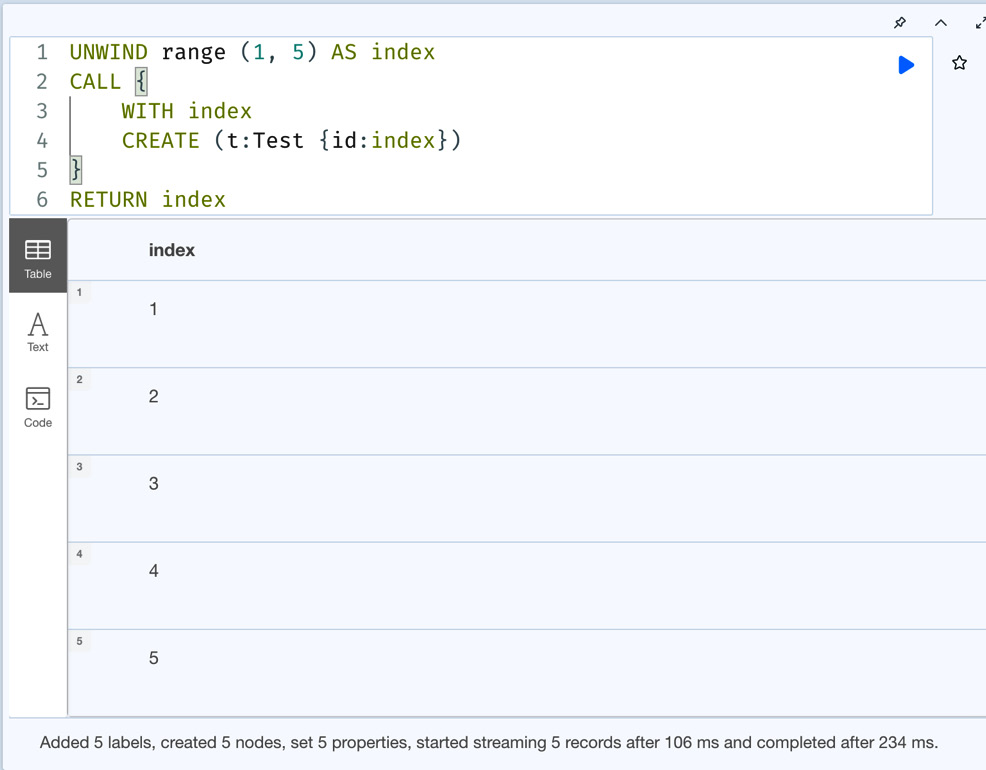
Figure 6.20 – Example usage of the unit subquery
From the screenshot, we can see that this query returns the index. Also, we can see from the status that we have created five nodes. Unit subqueries can be used to perform batch commits in a single query. In this case, each subquery executes in a separate transaction. The syntax for this looks as follows:
CALL {
sub query …
} IN TRANSACTIONSLet’s try an example. We can delete the Test nodes we created in the earlier query using batch mode, with two nodes deleted per batch. The query looks like this:
MATCH (n:Test)
CALL {
WITH n
DETACH DELETE n
} IN TRANSACTIONS OF 2 ROWSLet’s run this query in the browser and see what happens:
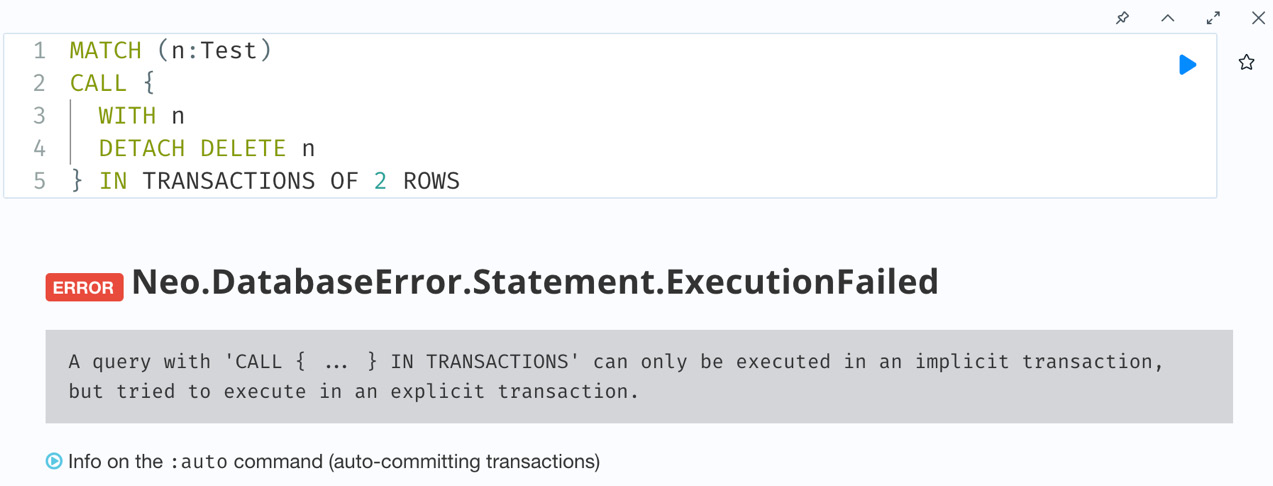
Figure 6.21 – Example usage of a unit subquery in batch mode – error
You can see from the screenshot that it fails to run with an error. This is because when we use the IN TRANSACTIONS clause, the outer query must run in its own transaction. It cannot be part of an explicit transaction. Let’s fix it and run the query again:
:auto MATCH (n:Test)
CALL {
WITH n
DETACH DELETE n
} IN TRANSACTIONS OF 2 ROWSLet’s see whether the query succeeds now:

Figure 6.22 – Example usage of a unit subquery in batch mode – fixed
We can see that the query is successful now and five nodes were deleted. If we were to run this query from an application, such as a Java driver, then we should not use the:auto prefix. This is browser-specific command usage.
Summary
In this chapter, we have learned about using list expressions, UNION queries, and subqueries. We worked with multiple functions to process lists, using the reduce function to calculate a single value by iterating through a list, using list comprehensions to manipulate lists, combining list comprehensions and the reduce function with filter expressions to calculate a single value, using UNION to combine the results of multiple queries, using UNION ALL to keep the duplicates from multiple queries, using subqueries to apply to filters and for sorting UNION queries, using subqueries to perform isolated updates, and finally using the IN TRANSACTIONS clause, along with subqueries, to perform batch updates in separate transactions.
In the next chapter, we will take a deeper look at how lists and maps form the core of Cypher data types, and how these data types can make working with data much easier.