


Optimizing SQL for performance
The IBM Cognos Business Intelligence (BI) server generates Structured Query Language (SQL) queries to retrieve data from relational databases. Users must wait while the database responds to such queries. This chapter provides guidance for minimizing these wait times.
The chapter contains the following sections:
6.1 Remember that less is faster
The most important aspect to learn from this chapter regarding SQL queries is that less is faster. If all other factors are the same, a simpler SQL statement is satisfied in less time than a more complex SQL statement. Likewise, requests for more data take longer than requests for less data, all else being equal.
As reports are executed, the Cognos query service will plan SQL statements that it requires to obtain data from one or more relational data sources. The physical SQL statements that are generated are dependent upon the SQL semantics and data types supported by the underlying database. The complexity of the generated SQL statements can introduce performance costs both for the underlying data source and for the Cognos server when it needs to perform additional processing locally.
Cognos BI applications that are layered on operational databases frequently require complex joins and expressions to navigate through the data and present values in business terms. In contrast, applications that are layered on cleansed reporting structures, such as star schemas, can benefit from the data transformations applied by the publishing extract, transform, and load (ETL) processes. Reducing the complexity of the joins and expressions in queries can help the relational database management system (RDBMS) plan queries more efficiently and, in turn, reduce processor and memory consumption.
Cognos BI administrators can work with their database administrators to determine which SQL statements return a large number of rows where a small percentage of the row data is presented in a report. Although such SQL statements might not be complex or expensive for the RDBMS to process, they can result in large amounts of data being transferred to the Cognos BI server to be locally processed.
Many of the recommendations in this chapter are also common preferred practices that many RDBMS vendors suggest to improve runtime performance.
6.2 Make use of enforced and non-enforced constraints
Tables in a database can declare constraints that can be considered by the RDBMS query engine for strategies such as join eliminations, query rewrites, and expression optimizations. Primary key, unique key, and foreign key constraints (but not null and table constraints) can be declared for this purpose. Depending on the vendor, these constraints can be declared as either non-enforced or enforced. In a normalized table design including snowflake schemas, non-primary key columns are functionally dependent on the primary key.
To plan SQL statements for the RDBMS to process, the Cognos query service uses enforced constraints defined in a Framework Manager model, such as determinants and join relationships between query subjects. These Framework Manager objects are often created during one of the initial steps of creating a model, but more common is that they are manually defined by the Framework Manager modeler.
Enforced constraints can be defined in a Framework Manager model using join relationships between query subjects and determinants, and can be used during SQL planning by the Cognos query service as it plans SQL statements for the RDBMS to process. These Framework Manager objects are often created in one of the first steps when creating a Framework Manager model, but they are more commonly manually defined by the Framework Manager modeler.
A Framework Manager model can also be constructed on top of databases that expose application objects through SQL views. Those views should be reviewed by the database administrator with respect to the tables that the views reference, because the Framework Manager modeler might not be aware of those tables yet.
When an RDBMS does not support ISO SQL windowed aggregates, an SQL statement will likely be generated using two or more derived tables that include rows at different levels of grouping. The rows from the derived tables will be joined in the SQL statement with predicates (the grouping columns). If the database metadata does not use not null constraints, then the predicate must compare the columns to determine if they are equal in value or if they are both null values. These additional expressions can affect the performance in the RDBMS.
6.3 Use indexes and table organization features
A common challenge for a database administrator is to anticipate the ways that applications attempt to navigate the database. This includes which tables the queries will combine and which tables predicates will be applied against. Using a representative workload, the database administrator can review which tables are most frequently accessed and, in particular, which local set of columns is used to filter and group columns in tables.
Using that knowledge, the database administrator can usually identify indexes or table organization strategies that enable the database to more efficiently select the required rows. The candidate workloads must reflect any ad hoc analysis and exploration of data that can occur within an application. This is important when the database administrator is constrained in terms of what covering indexes or table organizations they can define, which might bias the solution toward the most frequent cases. For example, an application might predominantly categorize measures based on time, customer geography, and product perspectives for which the database administrator can optimize the table designs.
A Framework Manager model can also be constructed on top of databases that expose application objects through SQL views. Such views must be reviewed by the database administrator with respect to the expressions within the view or any projected query items about which the Framework Manager modeler might not be aware.
6.4 Review column group statistics
Using a representative workload, the database administrator must review any instances where predicates reference several columns of the same table, such as when data is filtered by Country, Country-Region, and Country-Region-City.
These local predicates allow the database administrator to consider using multi-column indexes that improve the performance associated with the predicates, and to gather relevant statistics to improve cardinality estimation.
|
Note: A review of column group statistics often identifies predicates with inefficient data types, such as character strings, as bottlenecks in query processing. To overcome this, user prompts in models and reports can be configured to display meaningful names (character strings) while more efficient data types, such as integers, are sent for processing by the database. Figure 6-11 on page 76 shows a Report Studio dialog where you set Use and Display values for a prompt. The Use values are what are computations use; the Display values are what users see.
|
6.5 Avoid complex join and filter expressions
The complexity of expressions in the where and join on clauses of a SQL statement can impede planning for the RDBMS, query rewrites to materialized views, or other forms of query acceleration. This section describes two common types of complex expressions and explains several important factors to consider when using them.
6.5.1 Temporal expressions
In many applications, data is selected within a calendar context that is either designated by the user or is based on standard business periods, such as the current month or day. The input values define the range of data to select either in absolute terms or as expressions that are applied to values to derive end points. Operational databases and star schemas can benefit from a common set of extended date attributes that eliminate complex date expressions in SQL. Models and reports that use these tables and columns can present to the database simple predicates instead of complex expressions.
The Cognos BI query service exposes a family of functions that provide common user expressions such as adding and subtracting days and years from dates. These expressions are remapped to the equivalent expressions in the RDBMS and increase the portability of common business temporal expressions. Although the SQL standard defines interval types such as Year_to_Month and Day_to_Second, these interval types might not be supported by a particular vendor's RDBMS. Expressions that use or result in interval types, especially in predicates, can cause query decomposition and an increase in compensatory local processing.
6.5.2 Expressions on table columns in predicates
A predicate is best applied to a table column, not to an expression. If the left side of a predicate applies expressions to a column, it can impede the use of indexes and produce a less accurate estimate of selectivity by the database. Figure 6-1 shows the application of a string scalar function to perform a case-blind string comparison.
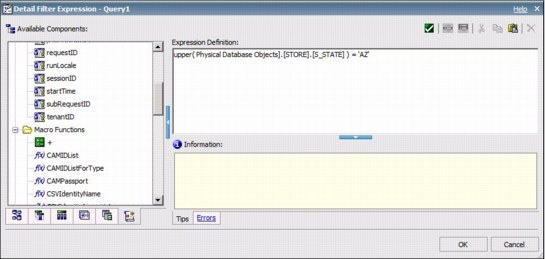
Figure 6-1 Applying expressions on columns in predicates
You can change the expression so that it uses only functions on the right side of the predicate. Alternatively, the database tables can be extended with columns to hold the computed value. Some RDBMS vendors provide the ability to define virtual table columns that are based on expressions that can be indexed.
6.6 Reduce explicit or implicit conversions
Ideally, an expression that serves as a key in a join relationship between tables resolves to the same data type as the corresponding key on the opposite side of the join relationship. This prevents constraining the RDBMS from considering certain join strategies, such as a hash join, because of incompatible data types. The database administrator can determine if the data types of the columns used in table joins are of the same type or of types that do not impede the RDBMS. The Framework Manager modeler must also determine if the join relationships between query subjects and stand-alone filters include expressions that might force implicit or explicit data type conversions.
6.7 Minimize complexity of conditional query items
Reports are frequently designed with complex conditions used in predicates, groupings, and aggregations. Often, conditional expressions are employed so users can choose, at run time, how they want the information customized. These expressions can result in many large conditional expressions, which are more costly for the RDBMS to process than simple column references, literals, or other, more compact expressions.
Cognos BI features, such as Active Reports, can support many interactive user requirements in a manner that is not dependent on query-based approaches. If the queries cannot be avoided altogether, then use query items defined in a Framework Manager model or report, which can eliminate or reduce the complexity of SQL expressions through the use of prompts and parameter maps,
For example, consider reports that must present grouped data where several aggregates are dynamically determined based on conditional logic. The conditional logic is repeated within each aggregate and frequently appears in other predicates and expressions in the statement.
Figure 6-2 shows a simple Cognos SQL statement that generates a set of rows using row constructors. In turn, the row constructors populate the parameter map presented in Figure 6-3. Each row returned by the query generates a key that can be referenced by reports. The values associated with the key will be generated in the query at run time.

Figure 6-2 Cognos SQL generating a set of rows using row constructors

Figure 6-3 Parameter map definition that can be populated by a query
Figure 6-4 shows a query subject with expressions that reference the keys of the parameter map instead of applying an actual calculation on the current date and extracting the year. The resulting SQL, shown in Figure 6-5, contains case expressions with literal values that were retrieved from the parameter map.

Figure 6-4 Query subject with conditional query times referencing parameter maps

Figure 6-5 SQL based on parameter map values
The set of keys and values in query-based parameter maps can be dynamically calculated using SQL concepts supported by a database. For example, Figure 6-6 shows a recursive common table expression that is used to calculate a parameter map representing a rolling, 12-month period based on the current date. The result set generated by this expression is presented in Figure 6-7.

Figure 6-6 Recursive common table expression that is used to calculate a parameter map

Figure 6-7 Resulting rolling period of rows from expression in Figure 6-6
Another approach to present grouped data with dynamically determined aggregation is to use a simple control table with logic to retrieve the requested results from either sets of rows, stored procedures, or other vendor-specific RDBMS mechanisms to generate the series of rows you want. As with the previous examples, the intent is to significantly reduce the number of complex expressions that need to be evaluated in an SQL statement.
Query items in a model or report can also use Cognos BI prompt syntax and macro functionality to reduce expression complexity. A prompt can be defined in terms of values that are displayed to (and selected by) a business user, such as a country name, and the value that is passed to a query based on the name the user selected. The displayed value is typically either a typed-in literal value (such as Market) or a value derived from a query used to populate the prompt. As a result, prompt values can be presented to users with friendly business names for sales territories, and the executed query uses more efficient integer key values that are associated with the display names.
Figure 6-8 shows a simple query item in a report that returns a different column based on the user’s selection. The query item can be used several times in the query for filtering, grouping, and sorting the data, but this requires the expression to be repeated multiple times in the SQL statement, as shown in Figure 6-9.

Figure 6-8 Query item that retrieves data from different columns, depending on user input

Figure 6-9 SQL statement generated from the case expression of Figure 6-8
Another way you can avoid long-running SQL case expressions is by defining prompts that accept valid Cognos BI expressions (tokens). Figure 6-10 shows a prompt macro that is defined to accept a token data type. The token type is provided to the macro expression at run time based on the prompt value the user selects.

Figure 6-10 Prompt macro using token type
Figure 6-11 shows the Static Choices definition screen for a value prompt in Report Studio. The simple values defined in the Display column are presented to users; the corresponding expressions for each of the values are defined in the Use column.

Figure 6-11 Defining Use and Display values for a prompt
Another form of substitution can be defined using the simple case macro expression, as the example in Figure 6-12 shows.
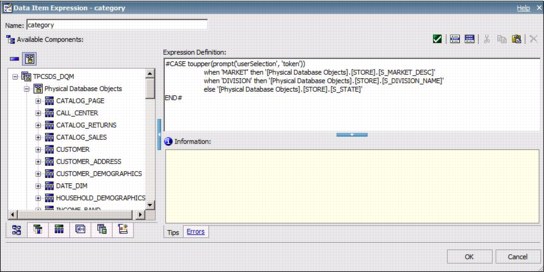
Figure 6-12 Case macro expression to ensure substitution occurs before SQL is submitted
When possible, the Cognos BI server attempts to apply dead code elimination techniques during query planning. In Figure 6-13, the value provided by a prompt is directly compared to a literal value that can be evaluated during planning.
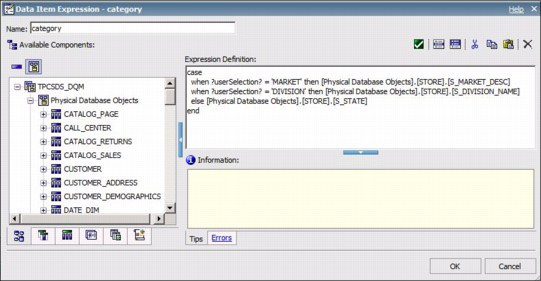
Figure 6-13 Expression that allows for dead code elimination
The result is a simple column reference in the generated SQL statement, as shown in Figure 6-14.

Figure 6-14 SQL after code elimination techniques have been applied
This dead code elimination strategy can be used by authors to prune complex branches of logic from a query. For example, Figure 6-15 shows a complex body of logic in a filter that combines expressions and prompts. This logical expression is likely to expand into a more complex expression in the SQL statement that is sent to the RDBMS, as Figure 6-16. shows.

Figure 6-15 Complex expressions with prompts

Figure 6-16 Physical SQL formed from complex expression
The original expression from Figure 6-15 on page 78 can be refactored, as shown in Figure 6-17, to take advantage of constant folding optimizations during query planning that will simplify the generated expression. In this scenario, the expressions are restructured to allow simple column and literal evaluations during planning, which result in more compact SQL at run time.

Figure 6-17 Refactored expression to exploit code elimination
Figure 6-18 shows the simplified SQL that is generated.

Figure 6-18 Simpler generated SQL from re-factored expression
6.8 Review the order of conjunctions and disjunctions
Complex expressions can include terms that are combined with a conjunction (AND), or a disjunction (OR). Although many expression engines attempt to terminate solving expressions as early as possible, a concept called early out, the order of the operations can be optimized by reordering the terms. When rearranging a disjunction, place the most likely conditions first. For conjunctions, place the least likely conditions first.
For example, Figure 6-19 shows an expression that filters rows based on a state and city name. The second OR condition will evaluate whether the state is Texas (TX) before performing potentially long-character comparisons where many of the leading characters of city names can be similar. Subject to the distribution of the data, the comparisons of the city names might need to be reordered to maximize performance.

Figure 6-19 Case statement with conjunctions and disjunctions
Queries that allow users to input large in-lists to filter rows should review whether the values can be expressed using shorter string values or other data types, such as integers, to enable faster evaluation of the values. Very large in-lists might also indicate a report design issue that is allowing or causing users to select a large set of values from a data-driven prompt. With some RDBMS, large in-lists can result in a statement that fails to execute on the database.
6.9 Avoid performance pitfalls in sub-queries
Within a query subject, you can define filters that determine if one or more column values exist in a set of rows returned by one or more sub-queries. For example, a query subject modeled with two detailed filters, as shown in Figure 6-20, results in multiple sub-queries in the SQL statement, as shown in Figure 6-21.

Figure 6-20 Multiple detail filters using sub-queries
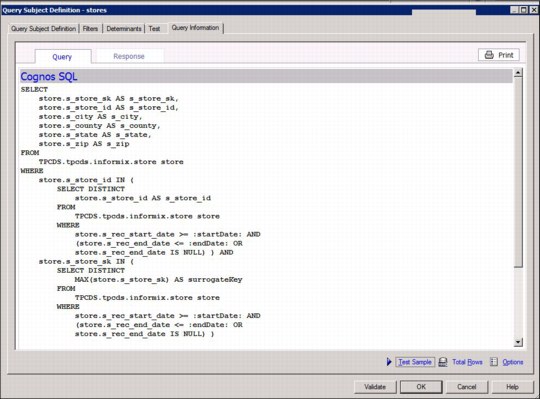
Figure 6-21 SQL statement with multiple sub-queries in a filter
Many types of RDBMS attempt to apply transformations on statements that use sub-queries to optimize performance. Your database administrator can review the execution plans for time-consuming statements involving sub-queries and consider the following information:
•If multiple predicates are used in a filter, consider whether reordering the predicates will improve execution times.
•If multiple predicates are used in a filter and each predicate references another query, consider whether modeling a query subject with equivalent join relationships will improve execution times.
•If a filter uses an equality predicate (=), consider using = ANY() or using IN() instead.
Figure 6-22, Figure 6-23, and Figure 6-24 on page 83 illustrate how defining a relationship can help prevent costly sub-queries.
Figure 6-22 shows a model query subject that references items from another query subject that computes a set of keys corresponding to a given time period. The relationship between the two query subjects is defined with a predicate using two columns. Only one row per key will be returned in this scenario.

Figure 6-22 Model query subject joined to another query subject
Figure 6-23 shows the other query subject that computes the desired set of stores based on date criteria provided by the user. The query subject defines a determinant that groups the data by store and computes the highest applicable key using an aggregate.

Figure 6-23 Query subject that groups data and computes the key using an aggregate
The SQL that is generated is shown in Figure 6-24. Sub-queries are avoided because the query subjects are referenced though a join relationship instead of a detail filter using a predicate. In more complex statements that reference the effective-date query subject multiple times, the SQL statement might include a named query within a common table expression if the RDBMS supports that construct. Otherwise, a new sub-query is generated several times as a derived table.
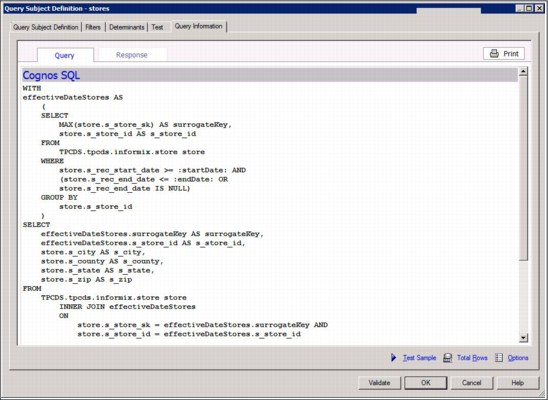
Figure 6-24 Generated SQL using query subjects with join relationships
|
Note: A join to a query must not change the cardinality of the required results. Be sure to verify whether the query will return distinct rows by default. A sub-query can be changed to a query subject that generates a derived table that contains a distinct or group by operation that removes duplicates.
|
6.10 Avoid unnecessary outer joins
Outer joins enable applications to return result sets when one or more tables in a statement lack associated data. Queries that use outer joins restrict various join optimization strategies and join ordering that the RDBMS sometimes uses with inner joins. A model might be constructed to always use outer joins that may not, in fact, be required by the business questions posed by a report. In these cases, the model can be extended with additional query subjects that describe inner join relationships.
Report authors can also consider using master-detail relationships that will retain data from the master query even if there are no details. This is similar to the intent of a left outer join.
In a star schema design, fact rows should be associated to members in the corresponding dimensions. In some cases, the actual business key for a fact might not be known as the fact data is delivered. It is preferred that the dimensions include a designate member that represents an unknown member. This enables the join relationships to avoid using outer joins and thus simplify the reporting experience for business users who want to select and group measures based on the unknown category.
6.11 Avoid using SQL expression to transpose values
Application authors who are familiar with SQL can construct expressions that attempt to massage database values for display. In several cases, such expressions can be replaced by using the available data type formatting, layout, and report expression features in the Framework Manager model and Cognos BI report authoring interfaces. Using the available formatting and layout facilities can reduce overhead in the RDBMS and provide locale-aware rendering.
Example 6-1 demonstrates how you can initiate multiple data type conversions, substrings, and concatenations to display a date value in a particular way rather than using the Data Format rendering option available in various authoring interfaces.
Example 6-1 Date formatting through data processing instead of rendering processing
Substring(Cast ( dateField, char(10)),6,2) || ‘-‘ || Substring(Cast ( dateField, char(10)),9,2) || Substring(Cast ( dateField, char(10)),1,4)
Application authors can define data-driven prompts that allow users to input values in a form that must be converted before the values can be used in a predicate. Ideally, the input values are transformed within the prompt definitions. Cognos BI provides a set of macro expressions that enable various forms of string expressions to be parsed and converted into the appropriate type of literal in the SQL statement.
Figure 6-25 shows a macro function that uses a mask specification to extract the year and month from the current date in a predicate where an application is storing an integer column that is intended to allow all days in a month to be selected. This solution does not require a between predicate within a _first_of_month and _last_of_month expression, which can take a relatively long time to process.

Figure 6-25 Macro function using a mask specification to extract year and month from current date
|
Note: Although relatively uncommon, the timestampMask() macro can be used for data sources that do not provide equivalent scalar functions. This is important for many business reports that frequently filter or group data by a temporal context, because it can simplify the SQL statements that are submitted to the underlying database.
|
Figure 6-26 shows how an inputted string value is transformed from dd/mm/yyyy format into yyyy-mm-dd format to accommodate the method in which a particular application stores character representations of date values.

Figure 6-26 Macro expression to transform character representations of date values
6.12 Apply predicates before groupings
You can take steps to improve performance even when the RDBMS is unable to apply predicates prior to a grouping operation, or when the RDBMS ignores candidate materialized views. The predicate is likely to be applied to a value expression that is computing the minimum value of an attribute in association with a determinant in the Framework Manager model.
A Framework Manager model governor, Grouping of measure attributes, can be changed to include the attributes in the grouping list. Figure 6-27 on page 87 shows a query that projects three columns from a model query subject. The country and state columns are defined in as a group by determinant with state as an attribute that is determined by the two columns. Based on the setting of the model governor, the generated SQL statement can include the attribute as a column in the group by clause or with an aggregate. If a report attempts to filter data using that attribute, the RDBMS might not push the predicate ahead of the grouping operation, or it might be unable to match a materialized view.

Figure 6-27 Attribute predicate applied to an aggregated column
6.13 Trace SQL statements back to reports
The SQL statements generated by the Cognos BI query service can optionally contain embedded comments that can include application context. This enables administrators to gather workloads and see the reports and packages to which the SQL statements correspond.
The ability to see comments in dynamic SQL at the database server level depends on whether the database vendor supports the concept, and requires that the client driver not remove the comments during parsing.
Many of the macro functions described in Chapter 4, “Macros” on page 43 can be used to customize the information about the request’s context. You can use macros and session parameters to tie queries to the particular user that ran the report.
Previously authored reports have user-defined names; ad hoc analysis and query gestures are assigned system-generated names. Both user-specified names and system-generated names can help administrators to monitor workloads.
Figure 6-28 on page 88 displays SQL that the Cognos BI query service submitted to a database. The first line of the SQL is a comment string with the following items:
•The name of the authenticated user, or anonymous when no authentication was used
•The location and name of the report that was executed
•The name of the business query in the executed report
•An internal request identifier that can be used to link to the audit database data
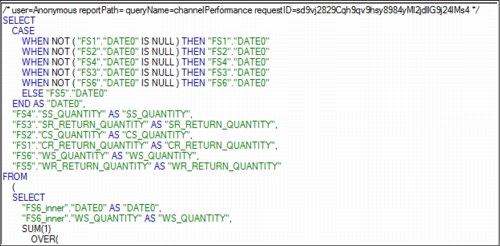
Figure 6-28 Cognos generated SQL with comments appended for auditing purposes
You can enable or disable query service comment logging in SQL statements by using the Generate comments in native SQL setting that is shown in Figure 6-29. The steps are as follows:
1. Launch the IBM Cognos Administration portal page.
2. On the Configuration tab, select Dispatchers and Services.
3. Select the Query Service and then select the Set properties action.
4. On the Settings page, select the Logging category and change the value for the Generate comments in native SQL name.
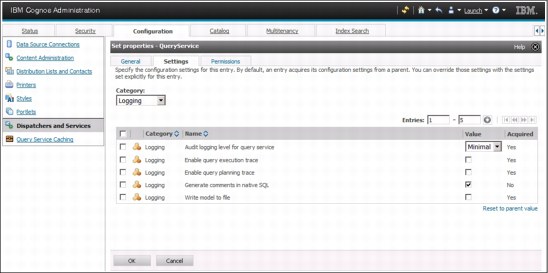
Figure 6-29 The Generate comments in native SQL setting of the Query Service
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.