


Administration
This chapter describes configuring the query service, data source administration, and cache management. Administrators can learn how to tune the query service effectively and about preferred practices for managing their BI content.
The chapter contains the following sections:
2.1 Configuring the query service
When you install the application tier component of IBM Cognos Business Intelligence (BI), the query service is included and enabled by default. The query service can be disabled, and its JVM prevented from launching, by using Cognos Configuration.
Most tuning options for the query service are located in Cognos Administration. To configure settings for the query service, log in to Cognos Administration and then navigate to the Dispatchers and Services area of the Configuration tab to locate the QueryService object (highlighted in Figure 2-1).

Figure 2-1 QueryService object on Configuration tab of Cognos Administration
The query service has three categories of settings that can be configured: environment, logging, and tuning. By default, each instance of the query service acquires applicable configuration settings from its parent. You can override the acquired values by setting them explicitly on the Settings tab of the Set properties window for the QueryService.
2.1.1 Memory sizing
Although the query service can operate as a 32-bit Java process in 32-bit installations of Cognos BI servers, 64-bit servers are preferred. The initial size and size limit of the JVM heap for the query service can be set in Cognos Administration on the Settings tab of the QueryService object. By default, both the size and size limit are set to 1 GB. For details about setting query properties, see the product information center:
In production environments where IBM Cognos Dynamic Cubes is not employed, a good practice is to set the initial heap size to 4 GB and the limit to 8 GB (a 64-bit server is required for memory settings above 2 GB). Then, you can monitor system resource usage during peak periods and adjust the settings accordingly.
For a server that is operating one or more Cognos Dynamic Cubes, the size limit of the query service should be set in accordance with the Cognos Dynamic Cubes hardware sizing recommendations.
The recommendations are available in an IBM developerWorks article:
Monitoring the JVM heap size of the query service
You also can monitor metrics related to the JVM heap size of the query service. Figure 2-2 shows the JVM metrics view of the QueryService in Cognos Administration, which you can access by navigating to the system area of the Status tab and then selecting the QueryService object for a particular server.

Figure 2-2 Query service JVM metrics monitor
You can assign a high water mark or threshold for the JVM heap size to cause the indicators to change color when the JVM heap grows beyond the threshold. You then may want to assign more memory to a query service when it approaches its configured JVM heap size limit during peak periods.
Using these query service metrics available in Cognos Administration, you can ensure that there is enough memory both for typical workloads and for additional, infrequent queries that require more memory
The preferred settings for the query service JVM heap are an initial size of 4096 MB and a maximum size of 8192 MB. The intention of these settings is for the system to use 4 GB or less most of the time, with an additional buffer of 4 GB to handle temporary loads. You can monitor the high value of the committed heap size to detect if the heap usage is too small. Figure 2-3 on page 14 shows the JVM usage at the time of system startup.

Figure 2-3 Query service JVM metrics monitor at startup
If the system never needs more than 4 GB of heap, the committed heap size will never increase. It will stay at 4,294,967,296 bytes. The current heap size high value indicates the maximum amount of heap that has been used. Because the peak heap size frequently approaches the committed heap size, the JVM may increase committed heap size. If your workload causes the heap to always expand above the initially requested heap size, the initially requested heap size can be increased. If the workload always causes the heap to expand to the maximum size, the JVM heap size is too small. Figure 2-4 shows a JVM where the committed heap size has expanded.
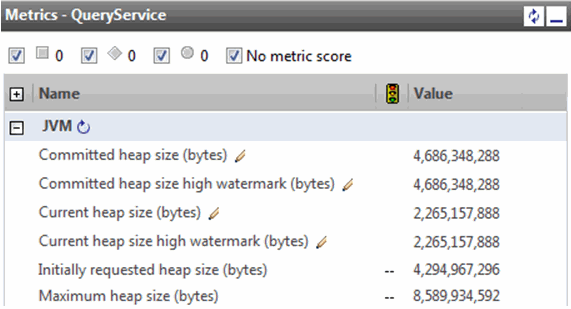
Figure 2-4 Committed heap size expansion
In Figure 2-4, the heap expanded but the current heap size is much smaller than the committed heap size. This is not unusual because of how the JVM operates. The JVM heap is split into a nursery, or new generation, memory space and a tenured, or old generation, memory space. If one of these memory spaces is frequently low, the JVM will try to expand it. In the case of Figure 2-4, the committed heap was increased in order to grow one of these two heap segments. By increasing the initially requested heap size to 5 GB, the heap expansion will be avoided entirely.
2.1.2 Throughput sizing
With every new release of Cognos BI, optimizations are introduced to maximize the query service’s throughput. The query service’s cache management system continues to be optimized, too. These improvements reduce user wait times because the Cognos BI server retrieves objects from its own in-memory cache faster than it does from a query to a remote data source. The query service JVM is multi-threaded and makes use of available processors.
As of Cognos BI version 10.2, the maximum number of threads that the query service can process concurrently is determined dynamically based on the number of processes and affinity settings defined for the ReportService within Cognos Administration. By default, the Cognos BI server is configured to have two report service processes with eight low-affinity and two high affinity threads for each. With these settings, the query service is capable of sending 20 concurrent queries to data sources.
If an administrator uses Cognos Administration to adjust either the affinities or the number of available processes for the ReportService, the query service will automatically adjust to allow the increase in concurrent requests without requiring any additional query service-specific configuration changes.
The preferred starting point for tuning your Cognos BI server is to leave the affinity settings at their default values and set the number of report service processes to 1.5 times number of available processors. For example, if your Cognos BI server is the only application running on hardware that has two processors, set the number of processes for the report service during peak and non-peak periods to three as a starting point, and then monitor system resource usage and adjust the number accordingly.
Increasing the query service’s throughput is intended to reduce the risk of a user waiting while their query is queued because the Cognos BI server is operating at capacity. Yet in certain high-load scenarios, additional throughput might result in longer user wait times. This additional wait time is attributed to the fact that each concurrent request must establish its own data source connection and in-memory cache instead of re-using one that was created by a previous request. For example, when using a query service configured for four report service processes, each with eight low-affinity and two high-affinity threads, a concurrent 40-user load test will send all 40 requests concurrently. This, in turn, will result in 40 simultaneous data source connections. If the settings were such that only 10 data source connections could be opened concurrently, then the remaining 30 requests would be satisfied by reusing one of the 10 initial data source connections, thus reducing the overall load on the underlying data source. In situations where the overall data source load causes the request performance to suffer significantly, you can reduce the number of processes for the report service to limit throughput and make better use of caching.
Batch reporting
The Cognos BI architecture differentiates between the processing of interactive and non-interactive requests. All requests that are initiated through user activity are processed by the report service; scheduled or event-driven activity is processed by the batch report service. The query service returns results retrieved from data sources to the requesting batch or report service.
Scheduled reporting is a critical aspect of any large-scale enterprise reporting solution. The effective management of low or non-interactive usage time periods, in combination with an organization’s data refresh cycles, provides an opportunity for administrators to prepare as much information as possible during off-peak times for later retrieval by users.
Reports can be scheduled on an individual, one-by-one basis, but this can be a burden when you have many reports to schedule. Instead, you can use jobs to execute scheduled activities. A job is a container of scheduled processing activities that run in a coordinated manner. Instead of scheduling individual reports, a job allows multiple reports to execute using the same schedule. Each activity within a job is given a sequence order based on how the job was selected. Jobs can be submitted to run either all at once (all activities in the job execute simultaneously) or in sequence (activities execute one at a time based on their sequence order).
The query service throughput for batch requests is determined in the same manner used for interactive requests, except that the associated properties of the BatchReportService in Cognos Administration are retrieved rather than those for the ReportService.
2.1.3 Multi-server environments
By default, Cognos BI loads balance dynamic query report executions among all of the application tier servers that are operating active query services in the environment. If existing servers are at capacity during peak periods, you can add more servers to scale your environment up to accommodate more requests.
Cognos BI version 10.2.1 does not permit a single query execution to write to the in-memory query service cache of multiple Cognos BI servers. Only the server that executed the query can have its cache primed by that query. So to best take advantage of query service caching in a multi-server environment, all content that might use a common cache should be tied to a single server (assuming the load is not too great for the one server to handle). By configuring advanced dispatcher routing (ADR), you can route requests based on a Cognos security profile (user, group or role), or by package. Using ADR, you can minimize the number of cache misses by directing package A content to server X only, and package B content to server Y only.
For more information about advance dispatcher routing, see the product information center:
2.2 Data source administration
Figure 2-5 shows how objects are organized in the data source connection area of Cognos Administration.

Figure 2-5 Structure of data source administration objects
At the highest level are data sources. A data source is really only a container for one or more connections. When running a report, one or more data sources are accessed based on how the Framework Manager model was defined. Therefore, the user must appropriate permissions on the data source object (or objects) being referenced by the report.
Every data source object must contain one or more connection objects. A connection holds information such as the type of data provider being accessed and the provider’s server hostname and port number. If a user has permissions on only one connection within a data source, then that connection is automatically used. If a user has permissions on more than one connection within a data source, then the user is prompted to declare which connection they want to use when they run the report.
Within every connection object there can be one sign-on object, more than one sign-on object, or no sign-on object. A sign-on object simply holds the user name and password needed to connect to the database (as defined by the connection object). If a user has permissions on only one sign-on within a connection, then that sign-on is automatically used. If a user has permissions on more than one sign-on within a connection, then the user is prompted to declare which sign-on to use when running the report. If a user does not have permissions on any sign-ons or there are no sign-ons defined in the connection, then that user is prompted to enter a user name and password for a secured database when running the report.
2.2.1 Connection command blocks
Connection command blocks are mechanisms with which the Cognos BI server can send additional context to a data source. Data source administrators want to know details about applications that connect to their database systems and they use this information for auditing, workload management, and troubleshooting.
Open connection, open session, close session, and close connection command blocks can be defined on the last window of the New data source wizard in Cognos Administration. Using these command blocks, Cognos BI administrators can give database administrators details about reporting and analysis applications and the users who are accessing them. These details might include the default set of information about authenticated users that is retrieved from authentication providers.
This information can be extended by specifying custom namespace mappings in Cognos Configuration. Using the mechanisms built into your database, you can implement the most appropriate methods of passing Cognos context to the database. The macro functions supported by the query service can provide information in a command block about users and reporting application objects, such as packages, reports, or queries. All macro functions can return values when referenced from a command block, which allows for application context to be passed to the data source from a command block. Macro functions that reference parameter maps in a model may also be used.
More information about connection command blocks including instructions and numerous examples are in the product information center:
2.2.2 JDBC drivers
The query service employs Java Database Connectivity (JDBC) driver files to connect to non-OLAP data sources. Appropriate driver .jar files must be made available to the query service, so you must have access to the JDBC driver provided by your database vendor.
Start by selecting the driver version that matches the version of your data source. This version can vary depending on software updates, patches, revisions, and service packs. For some JDBC drivers, you might also need to make appropriate license files available to the query service.
With the driver version selected, use the following procedure to make driver and license files available to the query service.:
1. Install the appropriate database software.
2. Copy the JDBC driver file (or files) to the c10_locationwebappsp2pdWEB-INFlib directory.
3. Stop and restart the Cognos BI server.
You can choose to use a JDBC 4.0 driver (if your vendor offers one) or a JDBC 3.0 driver. For IBM DB2®, the drivers are named db2jcc4 and db2jcc, respectively. You can use either a JDBC 4.0 or 3.0 driver as the query service is not dependent on JDBC methods, which only exist when a JDBC 4.0 driver is present.
The JDBC standard uses terms such as type-2 and type-4 to describe key architectural implementations. A type-2 driver is a JDBC driver which combines Java code on top of non-Java libraries that must be installed on the machine. A type-4 driver is written entirely in Java and communicates with the server using the internal protocol the server understands. A vendor might offer a type-2 driver and in some cases deliver functionality that is not provided in their type-4 driver. If your vendor offers a type-2 or type-4 driver, assume that only the type-4 driver is tested in the IBM lab unless stated otherwise on the Software Compatibility Report (SPCR) for the version of Cognos BI you are using. The SPCRs for Cognos BI products are on the Cognos support website:
In certain cases, a vendor may offer more than one JDBC driver that is capable of interacting with its servers. For instructions of how to configure the JDBC connection to a particular type of data source, see the following resources:
•Product information center:
•Cognos support website:
2.2.3 OLAP connections
The query service connects to OLAP data sources such as IBM Cognos TM1, SAP BW, Oracle Essbase, and Microsoft Analysis Services through vendor-specific full, or thick, client software that must be installed on the same server as the query service. Many vendors distribute their runtime clients with numbers that match the server version with which the clients were initially released. In some cases, however, the clients can be released with their own version numbers and release cycles.
Typically, you must configure certain environment variables to allow the query service to locate the corresponding OLAP client. For instructions on how to configure the native client connection to a particular type of OLAP data source, see the product information center and the Cognos support website at the addresses provided at the end of the previous sub-section.
XMLA support
The query service can query Microsoft Analysis Services through XMLA, the industry standard for analysis. XMLA is based on web standards such as XML, SOAP, and HTTP and therefore does not require any additional client software to be made available to the Cognos BI server. XMLA allows the query service installed on Linux and UNIX platforms to support Microsoft Analysis Services (which has a native client available only on Windows operating systems).
2.2.4 ERP and CRM data sources
The query service also supports a variety of ERP and CRM providers including SAP ECC, Oracle Siebel, and Salesforce.com, each of which are treated as relational databases. For instructions of how to configure connections to these data sources, see the product information center and the Cognos support website at the addresses provided at the end of 2.2.2, “JDBC drivers” on page 18.
2.3 Cache management
This section covers administrative aspects of managing the query service’s cache. See Chapter 3, “Metadata modeling” on page 25 for details about the types of objects that can be cached in the Java memory and the conditions for which those objects may be reused.
2.3.1 Priming the cache
The query service’s in-memory cache can be primed (populated with reusable objects) only by means of executing reports, either in batch mode or interactively.
Reports that retrieve the most commonly accessed data are best scheduled to execute before business hours. This minimizes the wait times for users during the day. An effective way of priming the cache in this manner is to create a job consisting of simple reports that include the data most frequently consumed during interactive analysis.
Results that are cached from one user’s request may be used for another user’s request (under default settings) only if both users have the same data security profiles. This is explained in Chapter 3, “Metadata modeling” on page 25. So, to prime the cache for the greatest possible number of users, consider scheduling the same report to run under various security profiles.
Reports that are ideal for cache priming include those from a known set of dashboards that a majority of users will use. For example, if there is a set of dashboards or reports that most users use as a starting point, these reports are good candidates for priming because all of those users can benefit from the fast performance that cached values can provide.
Reports that contain large volumes of data and many levels of hierarchies are also good candidates for cache priming because other reports that contain a subset of the data and metadata retrieved when executing the original report might benefit from the associated cached objects.
2.3.2 Clearing the cache
Java garbage collection is a term used to describe memory management operations in which memory associated with artifacts that are not actively being used by the program are automatically reclaimed under certain conditions. In this case, Java garbage collection automatically begins clearing out memory when the configured size of the query service’s JVM heap nears the limit of available space. Yet it is best not to rely on this safeguard. The problem with approaching an out-of-memory condition is that processor cycles result in being devoted to garbage collection instead of query executions.
Clear cache operations can be initiated manually or scheduled from Cognos Administration. The Query Service Caching section of the Configuration tab allows for manual cache clearing and writing the cache state to file for one or more server groups. The Write cache state feature creates the following time-stamped XML file showing the state of all OLAP caches.
c10logsXQESALDump_all_all_all_timestamp.xml
In a distributed installation, each report server that has an OLAP cache writes the cache state file to its local logs directory.
Pure relational caching
Results from pure relational queries are retained in memory only while the data source connection remains open. This is different from dimensional queries, such as those for DMR packages, which, as of Cognos BI version 10.2, persist in-memory until a manual or scheduled clear cache operation occurs. Query service data source connections have a default idle timeout of 300 seconds (5 minutes), but this can be set to a different value using the Properties window of the query service in Cognos Administration. For details about modifying these properties, see the product information center:
DMR, SAP BW, Oracle Essbase, and Cognos Dynamic Cubes caching
The typical cache management strategy when using DMR packages, SAP BW, Oracle Essbase, and Cognos Dynamic Cubes is to schedule a clear cache operation following a load of new data in the underlying data source. These caches can be cleared using the query service administration task wizard in Cognos Administration (shown in Figure 2-6). These cache clearing tasks can be targeted at a specific package or data source. An asterisk (*) entered in either the package or data source field is considered a wild card that will clear everything.

Figure 2-6 New query service administrative task wizard
TM1 caching
The query service can detect updates in Cognos TM1 cubes and automatically clear any associated stale data from its memory. Therefore taking any action to clear the cache for TM1 data sources is unnecessary.
2.3.3 Automating cache operations
The query service can be instructed to perform cache operations automatically in response to external events. The Cognos BI Software Development Kit (SDK), trigger-based scheduling, and the query service’s command line API are the three primary mechanisms for which you can automate query service cache operations in conjunction with external business operations such as loading new data into your data warehouse.
The SDK and trigger-based scheduling are the most popular mechanisms to add query service cache operation automation into programming scripts and are explained in the standard product documentation. Use of the query service command-line API does not appear in the product documentation. However, because some system administrators might find the syntax of the command-line API more convenient than that of the SDK or trigger-based scheduling, the query service command-line API is explained here.
Managing cache operations with the SDK
The Cognos BI SDK provides a platform-independent automation interface for working with Cognos BI services and components. The SDK uses a collection of cross-platform web services, libraries, and programming interfaces. You can choose to automate a specific task or you can program the entire process, from modeling through to reporting, scheduling, and distribution.
The query service administration task wizard in Cognos BI was built using the Cognos BI Software Development Kit (SDK). Any task that can be defined through the wizard can also be established programmatically using the SDK. For more information, see the Cognos BI SDK documentation or the following developerWorks article:
Managing cache operations with trigger-based scheduling
Both priming the query service (by running reports) and clearing the service caches can be scheduled using the standard scheduling interface of Cognos Connection. There, you can use triggers to schedule certain actions based on an occurrence, such as a database refresh or receipt of an email. The occurrence acts as a trigger causing the entry to run, such as when you run a report every time a database is refreshed. Trigger-based scheduling can help prevent exposing users to stale data. Triggers provide a mechanism for which to implement a script for the routine presented in Figure 2-7. To set up a trigger occurrence, see the following documentation:

Figure 2-7 Scripting to optimize cache lifecycles
Managing cache operations with the command-line API
In addition to the Cognos Administration interface for executing and scheduling cache management tasks, a command-line API enables manual and automated cache management outside the normal Cognos BI administration environment. The command-line utility is located in the c10in directory and has either of the following names, depending on your operating system:
•QueryServiceAdminTask.sh
•QueryServiceAdminTask.bat
The QueryServiceAdminTask utility accepts up to two arguments:
•Cache operation (mandatory)
Here you specify one of the following values to select the corresponding cache operation:
– A value of 1 to clear the cache
– A value of 2 to write the cache state
•Cache subset (optional)
Use this argument to specify the portion of the cache to which the operation applies by naming a data source, catalog, and cube (separated by forward slashes). You can use the wildcard character (*) to represent all data source, catalog, or cube names. Omitting this argument causes the cache operation to apply to the entire cache.
For example, to clear the cache for all cubes in all catalogs under all data sources, enter the following command in a command shell:
queryServiceAdminTask 1 "*/*/*"
Optionally, you can enter this command:
queryServiceAdminTask 1
Entering QueryServiceAdminTask -help in a command shell displays detailed usage instructions for the utility.
Because this command-line utility makes an immediate task request, it does not go through the job scheduler and monitoring service. Consequently, it affects only the Cognos BI server on which the command is run.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.