
Data, Information, and Systems |
CHAPTER7 |
I N THE PREVIOUS SECTION, WE discussed organizational concerns and issues for security, and now we will cover more technical ones. In these next few chapters, we shall try to define terms and build up common technical knowledge so that when we cover security, sufficient technical understanding will have been developed. In other words, some of the materials in this section may not seem obviously connected to information security, but when we cover securing systems and networks, the connections should become more apparent. In this chapter, we will preview and survey some important technological concepts and define some terms so that as they come up again in subsequent topics, you will be familiar with them.
Chapter 7 Topics
This chapter:
• Discusses business strategy, operations, and tactics as they relate to information and systems.
• Explains information systems technology and software used in organizations.
• Describes data integration and middleware and the movement of information across entities.
• Explores database and data warehouse concepts and designs.
• Deals with service-oriented architecture (SOA), markup languages, and web service technology.
When you finish this chapter, you should:
![]() Know the differences between data and information.
Know the differences between data and information.
![]() Understand what information systems are and how information is shared and integrated within and among enterprises.
Understand what information systems are and how information is shared and integrated within and among enterprises.
![]() Become familiar with relational database architecture and design, along with basic concepts related to information storage and retrieval.
Become familiar with relational database architecture and design, along with basic concepts related to information storage and retrieval.
![]() Be able to discuss the implementation of markup languages and service-oriented architecture in relation to information integration and the Internet.
Be able to discuss the implementation of markup languages and service-oriented architecture in relation to information integration and the Internet.
7.1 Information Systems
When people think about information systems, most often computers come to mind. An information system (IS), however, extends to all organizational information infrastructure including networks, hard copies of documents, computer server rooms, and even physical storage vaults. The primary purpose of an information system is to facilitate the business and its mission. In this preview chapter, we will focus on (1) computer systems, (2) the networks that connect them, and (3) software applications and databases—both in terms of how they are constructed and how they are used.
Along with facilitating businesses and effectively operating in a global marketplace, managers must simultaneously consider the practicality of securing systems and information to prevent breaches or damage. Where many managers see security as an overhead cost of doing business, security is rather like the concept of quality—that is, although these measures may not directly affect the financial bottom line (except negatively as a financial outlay), having poor security (and quality) will indirectly affect the bottom line. For example, consider poor quality on brand reputation or a major security breach on customer trust.
Information and communications systems can be attacked from anywhere in the world nowadays, and this sometimes leaves managers with little or no recourse, unless there has been good planning followed by good actions. Although information and communications technologies can be used unethically and for dubious purposes, the technologies themselves are value neutral, meaning that it is up to people who apply the technologies whether to use them for good or for bad purposes. Before managers can understand how to protect their information infrastructure, they must understand important aspects of how all that works (at least at a high level). That means that before we can really appreciate each of the technological components of security concern, we need to lay some foundations—and so let’s do that by developing our conceptions of the differences between data and information, which will lead into overviews of technologies and concepts that we will elaborate on in subsequent chapters in this section and discuss in more detail relative to security in the section that follows.
7.1.1 The Nature of Data and Information
Data are raw facts without much context. Examples might simply be numbers such as 16, 18, 21, 23, 30, 50, and 65. These numbers have little or no meaning in isolation, unless we add a little bit of context to these raw data such as age = 21. Even then, a person may only infer what this might mean—based on his or her environment, culture, or more specifically, cognitive schema (cognitive schemas are mental models and expectations one develops about the future based on past experience). Information, on the other hand, is contextually enriched data. For example, if we explained that in Florida, the legal age for consuming alcoholic beverages is age 21, but the largest consumers of alcoholic beverages are boys ages 18 to 19, we are now talking about information. Thus you can see that the main difference between data and information is that information has data, but it is contextually enriched such that it is more meaningful.
Among their core features, information systems (IS) facilitate the processes that contextually enrich data to support business functions such as marketing, finance, operations, and human resources management. IS includes applications that help with product requirements for gathering, planning, development, and testing of various IS components. For example, they may consist of supply chain management (SCM) systems, which help enterprise requirement specialists plan just-in-time shipping and receiving and other logistical aspects to ensure minimal cost delivery of products for on-time deliveries. IS may include customer relationship management (CRM) systems, which help the marketing and sales teams track and manage sales prospects and revenue pipelines, or IS may simply represent the underlying technological infrastructure—such as computers, operating systems, programs, and networks.
Information systems are designed to support strategic, tactical, and operational levels of information processing and decision making. Because these are so fundamental to business processes and missions, the technological functions in most organizations typically have a dedicated department, often called Operations, Technical Support, Information Technology (IT), or the Management Information Systems (MIS) department. Increasingly, organizations are adding security departments called Office of Security (OoS), or Security Assurance and Administration (SAA). These latter two types of departments specialize in planning and overseeing security operations, tactics, and strategies— and they are often overseen by a Chief Information Security Officer (CISO).
7.1.2 IS Operations, Tactics, and Strategies
Having sufficient data is important to daily business and tactical operations, which are used in the execution of organizational strategies. The important thing to note here is that information and systems security aims at maintaining business operations. There is no other reason for security other than to act as a function to help ensure that businesses are able to operate. With this in mind, let’s approach some important aspects of information and systems at the operational, tactical, and strategic levels.
We pointed out earlier that data are raw numbers that describe the characteristics of an object or a transaction; for instance, a sales transaction might include the date of the sale, the description of the item, an item number such as a stock-keeping unit (SKU), quantity sold, and so forth. On the other hand, information makes the data useful. For example, information helps managers determine losses from thefts or risks associated with a sole supplier going out of business.
As illustrated, information used at the operational level is primarily associated with day-to-day events that transpire as the result of doing business; at the operational level, managers may want to know, for example, how much money was made and spent in a day, or what is left in the inventory. By contrast, information at the strategic level may involve understanding what the best-selling items are and why, what the margins are on sales items, or where the most and least profitable districts or regions are located. Collectively, information used in operational, tactical, and strategic aspects of organizational processes and decision making helps managers align plans with goals—such as in meeting sales objectives or targeted returns on investments, or maintaining just-in-time inventory stock levels to enhance profitability, finding new markets, differentiating products from competitors, and gaining advantages with buyers and suppliers over rivals [1].
In Focus
In relation to security, data and information are just like data and information for running the business—they allow managers to assess risks and threats to information and systems, and they are used in operational, tactical, and strategic security initiatives.
Depending on the nature of the data or information, and their uses, technologies organize, store, retrieve, and process data and information differently, and there are a variety of security requirements to accompany them. The basis for these stratifications falls under the rubric of information architecture. The notion of information architecture helps managers to conceptualize the areas where data, information, systems, and technologies should be applied across horizontal and vertical strata [2]. Horizontal strata are those functions that cross functional boundaries, whereas vertical strata are those that represent departments or lines of business.
Suppose that in your organization there was a compromise of data—the strata at which the data were compromised would affect different aspects of the corporation. The horizontal strata (meaning the technologies and their rendered information that facilitate all of an organization’s decision making) consist of business architecture, data architecture, and communications architecture. A horizontal stratum therefore may support the operations across the entire organization, called the “value chain.” The vertical stratum, on the other hand, may involve the flows of the information within each of the lines of business (LOBs) at the operational, tactical, and strategic levels (Figure 7.1). Consequently, some of the information is used in carrying out primary business activities, which are those that go directly toward the production and delivery of products and services, and other data and information are supportive (or secondary) in that they involve overhead and infrastructure used in the execution of the primary business activities [3].
Line of business (LOB) integration.
In Focus
A critical point is that operations and tactics must be thought of holistically (sometimes called systemically) with the larger strategic mission of the organization. Relative to security, then, managers must consider the nature of information in terms of protections, and consequences in cases of security breaches.
From an information architecture perspective, security encapsulates all of the protections of information, including accidental or intentional misuse or abuse by people inside or outside the organization. Most engineers and designers in today’s world understand this, but other factors, such as pressures to meet a production deadline or to stay within a budget regarding expenditures, may detract from security objectives. Beyond those competing goals, simply by virtue of the complexity of systems that involve multinational participants in a global marketplace, can be found information security risks and vulnerabilities. Although there are technological aspects of these risks that are well recognized, some major concerns are non-technical. To highlight, as is often asked in a security briefing, when someone purports that so-and-so has presented commentary on threats, trust, or credentials, the security officer may often respond: “How do you know?”
Realize then that data are necessary but not sufficient for making a meaningful decision. Adding context that transforms data may be useful to indicate a current operational picture of a situation into some sort of action, but to make inferences and draw upon more robust meanings, something else is needed! Most systems today help with the data-to-information transformation (along with integration of data sources), but many if not most are quite weak in helping human beings understand the meaning of the information. The term used to describe this problem is information overload.
7.1.3 Information Integration and Exchange
A recent IDC technical report [4] stated that there is an average of 48 applications and 14 databases deployed throughout the typical Fortune 1000 company. Even with data warehouse systems, distributed systems technologies, and various standards that have been implemented to mitigate the problem of what is commonly called information silos, information continues to remain isolated in departments or in vertical lines of business within enterprises.
The problem is made worse when information must traverse across enterprises and among trading partners. Among the issues encountered are (1) reduced management visibility of strategic resources, (2) redundant, inaccurate, and otherwise obsolete information, (3) increased infrastructure and technology expense to maintain the information redundancy or to build custom connections and interfaces to tap into these orphaned data sources, (4) technology limitations that preclude the full use of organizational assets, and (5) the inability to efficiently and effectively transact business with customers and trading partners.
Since the 1970s, Electronic Data Interchange (EDI) formats and standards have emerged in an effort to bring structure and order to the information integration problem. However, even with the development of EDI protocols such as X.12 and EDIFACT, each implementation has required individualized and customized work to adapt to each node in a communications network. This custom approach can be expensive, time-consuming, and static, requiring modification as the result of each change. According to IDC [4], 70 percent of the average IT department budget is devoted to data integration projects. This is because multiple standards continue to exist, and many are incompatible with one another.
Combined with nuances in nearly every business entity and application, the process of exchanging information remains extremely complex and time-consuming to implement. Recently, the Gartner Group reported that a typical enterprise devoted 35–40 percent of its development budget to programs whose sole purpose was to transfer information between different databases and legacy systems. Although a variety of solutions emerged to address the problem by providing interconnection among disparate systems, these solutions have tended to require customized modules and have required many staging points where security may be compromised. They also tend to build custom software modules that “plug in” between specific, popular commercial software applications and sometimes require system administrators to lower the security posture to permit communications among disparate communication environments.
To help integrate the data and information across organizational lines of business, or LOBs, many companies use middleware. As the name implies, this software intervenes between applications and system software or between two different kinds of application software so that information can be exchanged among disparate sources and systems and data types such as integers, floating point numbers, and text strings. Middleware bridges different network protocols; translates, manipulates, and formats different data types through a workflow process; and executes rules such as how to handle errors if they occur. One major class of middleware is known as enterprise application integration (EAI). EAI is specifically designed for integrating and consolidating information among the computer applications in an enterprise.
A common EAI function is to extract data from legacy applications, such as those running on a mainframe computer, with more modern systems such as distributed systems or across desktop platforms. They can also extract, translate, and load (ETL) data among different databases or allow the coexistence of two systems during a migration from one to the other by creating ways for the information to flow to each system in parallel. Some EAI systems require programming, and they use object and message brokers (called object request brokers [ORBs]). Other EAI do not require programming and instead use a business process modeling language (BPML) or web services in service-oriented architecture (SOA).
Enterprise resource planning (ERP) systems are another class of middleware, and these are used to plan and manage production “just in time” by coordinating the supply to the delivery in the production value chain. Therefore, ERP software applications help to manage product release cycles, ordering of materials, automating the purchasing process, managing inventory levels, transacting with suppliers, and tracking customer service requests and orders. Business process management (BPM) is similar to ERP, but it revolves around the business processes in the enterprise. BPM can create workflows, interface with ERP systems to trigger events or pass information among interdependent parties within the production line, and provide managers with information on how well business processes are tracking to key performance indicators (KPIs) and in meeting corporate objectives.
In Focus
It is important to realize that systems that help gather and integrate information to facilitate business functions also leave open many opportunities for security exploits at the application, storage, computer, and networking levels.
Critical information and KPIs are usually displayed on a “dashboard” or a graphical reporting system or printed with a report generator. A graphical user interface (GUI) is a visual display system. It can be a specialized monitor for showing network activity, railroad switching, or power grids, or it can display web content via a browser. GUIs provide features such as pull-down menus, buttons, scroll bars, ribbons, and mouse-driven navigation.
7.2 Databases
Software applications, for the most part, lead to the creation and/or consumption of data. If we need to store the data to be used in or across applications, the most suitable form is a database system, or database management systems (DBMS), designed to manage simultaneous access to shared data. Most modern database systems are relational, although there are others such as hierarchical and object-oriented databases. When data are stored into a database, we call this persistence.
A relational database management system (RDBMS) organizes data into tables that contain keys, so the indices remain coupled to the data that are related across tables. Tables in RDBMS are connected via primary and foreign keys. These form the linkages that preserve data relationships. When a set of data related to a transaction, such as retrieval of invoice data, is to be reconstructed from a database query, it requires a procedure called a “join” wherein criteria from all the related tables are gathered and a result set or a view is produced and returned to the software application that made the request. Data warehouses are similar in some respects to RDBMS, but they are used more for analytical processes than transactional ones, and so their data are structured, persisted, and retrieved differently from RDBMS.
7.2.1 Relational Databases
Relational databases contain tables of data, which are arranged into rows and columns. Rows represent a “record,” whereas columns represent individual elements or concepts. Tables generally contain a primary key to uniquely identify a row and sometimes carry foreign keys, which represent keys in other tables to which a table is related. Consider Tables 7.1 through 7.4.
If you carefully study the tables presented, and knowing that a primary key must be unique and that there can be many foreign keys associated with it (one to many), you can see that a customer must be uniquely identified by a customer number. The customer has a name and a billing address, which resides in a zip code (for our billing purposes, although it may be physically located in multiple jurisdictions), and the billing address is tied to a particular zip code, because these are unique also. In the zip codes table, there can be only one zip code per location (hence it is a primary key), but zip codes may span one or more cities, so we may not choose to make the city in the table a key. Consider, for example, the cities of Jacksonville, Florida, and Jacksonville, Arkansas. Cities of the same name may appear in multiple states, so we might want to allow duplicate city names even though that may seem inefficient. However, a zip code resides uniquely in a state and city, so we want to associate the zip code with the particular state we want to reference. That will allow the software to determine whether we are talking about Jacksonville, Arkansas, or Jacksonville, Florida.

| ZIP CODE (PK) | CITY | STATE (FOREIGN KEY [FK]) |
| 01463 | Pepperell | Massachusetts |
| 30004 | Alpharetta | Georgia |
| 32326 | Crawfordville | Florida |
| 32327 | Crawfordville | Florida |
| 32901 | Melbourne | Florida |
| 32940 | Melbourne | Florida |

The important takeaway from this slightly technical discussion is that even though a concept appears in a column more than once, structured this way, the RDBMS is smart enough to know not to duplicate the actual data—it simply creates an internal reference from one concept to an associated one—but at design time, we do it this way to make it easier for humans to visualize. This is critical to ensure a database that is efficient and to still maintain a high level of integrity maintenance in the database—and integrity is an important security concept and issue.
Next in the database configuration we have presented, when we reference a particular invoice, we can pull (like an interlocking set of chain links) all the data we need into an application. Note, though, that there are a few particulars: First, we want to minimize the frequency in which a particular concept (column) occurs. In other words, we have a state table that lists each state only once. Why should we have the state of Florida repeated over and over again in a table if we don’t have to? That will only bloat our database and cause greater potential for failures. Second, we must, at all costs, try to avoid adding tables when we add new data. That can be catastrophic!
Finally, as is visible from the tables, there are inherent structures and relationships among them. Relational databases are organized (modeled) into various tables, and their relationships are called normal forms. For instance, the data, such as 30004, are given some context by naming the column “zip code.” This label, along with other information, can be supplied in an RDBMS and is known as metadata (data about data). Examples include constraining how long an input can be, whether it is alphanumeric or strictly numeric, whether it has a particular format such as a date, and so on.
7.2.2 Relational Databases and Maintaining Data Integrity
Designing a relational database begins with entity-relationship modeling, which produces an entity-relationship diagram (ERD). An ERD reflects the entities (tables) and the relationships among them. An important element in the relationships is cardinality, such as whether one table necessarily depends on data in another table (called mandatory), whether there might be associated data that are not essential (called optional), whether there is a one-to-one relationship between one entity and another, or whether there is a one-to-many relationship. For example, a teacher must teach (mandatory) many classes, so perhaps a teachers table would contain columns for teacher ID numbers, names, and departments, and probably has a one-to-many relationship with a classes table. The concept of a key is important in forming these relationships, as we pointed out before. A key uniquely identifies a group of data, such as a student ID number to uniquely identify a student in a students table. Primary keys (PK) are these sorts of indicators, but foreign keys (FK) are links from other tables to associate one table with the others. For example, a student ID number might be a PK in a students table and an FK in a classes table.
An important security concept in the design of relational database tables is to maintain data integrity, and the process of properly designing a relational database to protect data integrity (by removing anomalies) is called normalization [5, 6]. There are seven normal forms [7], and the higher the normal form, the more work the database does to protect the integrity of the data. However, increased normalization also tends to increase the number of tables, which can hurt the performance of the RDBMS. For this reason, most databases implement partially normalized database models [8].
In addition to normalization, another important design aspect involves what are called integrity constraints. The constraints can be applied to records, tables, and relationships among tables. A DBMS can, for example, automatically check the data being stored to ensure that their data types and formatting are what the database expects. Within most RDBMSs, such as Oracle or SQLServer, data integrity may also involve using triggers and stored procedures that force the removal of linked data. Microsoft Access does not support triggers or stored procedures; however, it does have a type of trigger mechanism by a checkbox in a dialog box that says, “Enforce referential integrity.” Access also allows programmers to write macros to do something similar to stored procedures.
Integrity constraints can be set at different levels. Record-level integrity constraints can check the data type and format to ensure that only valid data are entered in the database. For example, you can set up an input mask when you design the table so that no characters other than 0–9 can be entered as a social security number. The DBMS can also automatically monitor the data change at table level using the constraints you set. A simple, automatically built constraint is “no duplicated primary keys are allowed.” At this level, the DBMS will check whether deleting or modifying a record may damage the relationship among tables.
Another important aspect of maintaining integrity deals with the concept of concurrency, meaning to coordinate the interactions among multiple users who are reading and writing to a database through what is called “locking.” When a user updates data in a database, the data must be locked so that no other user can corrupt the data during the process. This issue leads to a question of whether to handle data integrity in a software application or in the database, or a combination of both, but data integrity must be maintained regardless. We can do almost all of the integrity management in the database by eliminating the design anomalies by increasing the normalization. However, the more normal the database, the more tables we tend to have, and consequently, more “cross-table access and locking” are needed, making for less efficient database access.
In Focus
The integrity of data must be maintained either in the database or by an application. The more normalized a database, the more it helps to ensure the integrity of the data. Databases should be normalized to at least Third Normal Form to avoid the worst types of anomalies caused by what are called transitive dependencies. For most databases (depending on the size of the database), Third Normal Form provides a straddle point, which means an optimal compromise, between integrity and efficiency. But that means that the application must filter and manage the integrity of data where that job is not given to the database—there are tradeoffs!
From a security point of view, these principles are particularly important because they deal with the issue of data integrity as we have discussed, and if we do not do good work in the design and in database housekeeping, the bad guys might be able to more easily exploit the database. Data and information are assets, no less than the computers we work on. As databases become more exposed to networking, managers and administrators need to maintain vigilance. Some protections that must be in place include using password protections, using access controls to determine to what data users have access, and defining the levels of access the users can have such as read only, adding data, adding tables, deleting tables, and so forth, as we shall discuss later under the concepts of SQL injection and other database attacks.
7.2.3 Data Warehouses
Where relational databases are used for operational and tactical transactions in the business, data warehouses are used more for strategic aspects using analytics. This is important because to thrive, companies must find ways to reduce risk and create new products to position themselves differently. They must deliberately choose a set of products or services that provide a unique mix of value at lower risk. A company can outperform its rivals only if it can establish such a difference that it can preserve. This requires a different set of technologies than those used for storing and retrieving transactional data.
To facilitate this “strategic positioning,” data warehouses are used along with data mining techniques. These technologies and techniques help managers determine how to differentiate their products, find untapped markets, determine competitive threats, and determine who the “best” and “worst” customers are. These fill a critical role in strategic managerial decisions—whether regarding the business or security.
In the vernacular of a data warehouse, inbound channels are information collection points for the database system, which may come from extranets, the Internet, or other sources, and are persisted into mass storage devices. Often, data warehouse information is further extracted out into smaller databases, called “marts,” by a given topic, such as “sales.”
Analytic tools can then be used to scan the information by key indicators to monitor trends and detect changes in business patterns. This process may include, for example, monitoring sales and profits related to a new sales campaign. As a further example, a certain demographic may show a higher risk when the numbers of transactions involving this demographic develop large enough to become statistically significant. This, combined with information from industry partners housed in an information repository, enables companies to gain visibility of this strategic information and utilize a wide range of tools to analyze and augment their product offering, improve their positioning, and avoid marginal or high-loss customers. Analytical tools can be used to monitor the inbound channels, extracting out data in a process using extract-transform-load (ETL) techniques. ETL, using a variety of knowledge discovery methods, transforms and integrates the extracted data into useful business information.
To illustrate, suppose we have gathered data via a point-of-sales (POS) cash register and web browsing (click-stream) of our website, along with other sources, and we now want to persist all that in an operational database, such as a relational database presented earlier. That could be a problem. Instead, we aggregate all these data into a data warehouse, which in some ways resembles a relational database except that the tables are not normalized and are instead organized to store massive amounts of data by other categories such as dates, topics, or clients.
Once we have collected the data, we want to use it to help us in making effective decisions about the business (or security for that matter). Because a data warehouse primarily deals with business concepts such as customers or regulations and so on, rather than on transactional concepts such as purchases or debits and credits, we need effective ways to select the information we desire and then efficiently analyze it. To accommodate these needs, according to Inmon, Imhoff, and Sousa [9], a data warehouse then is (1) subject oriented rather than transaction oriented, (2) designed to be integrated with other systems, (3) time variant, meaning that any record in the data warehouse environment should be accurate relative to a given—specified—moment in time, (4) non-volatile, which refers to the fact that an update does not normally occur in a data warehouse during a specified timeframe; instead, updates only occur on an exception basis. When changes do occur, the time variant snapshot captures only the changes. As a series of snapshots forms, a historical record is formed. Finally, data warehouses (5) can contain both summary and detailed data, but the data are organized in a hierarchical fashion.
7.2.4 Extract-Transform-Load (ETL)
Data are loaded into a data warehouse from heterogeneous data sources, but first they must be subjected to some data transformation using “data-scrubbing tools.” For example, when we surf the Web and visit a site, we may click on various links on that web page. Software watches where we click (this is called a click-stream). Software extracts that click-stream and throws away any clicks that are not on links or perhaps even just on some links, and this is called data scrubbing. The data are then indexed using some company-defined indexing scheme, based on what the company wants to know about its visitors. Perhaps the company may even deposit a text file onto a client called a “cookie” to track these electronic movements. The data are then loaded into a data warehouse.
Because of the volume of data that ends up in this warehouse, as noted earlier, sometimes companies resort to using “data marts,” or smaller distributed database warehouses, which are collections of data adapted to a particular need. Data in the marts are subsets of data from the warehouse that have been tailored to fit the requirements of a department within a company and contain a small amount of detailed data along with summarized data.
It is important to realize that the quality of the data existing in the data warehouse must be protected and that data warehouse extraction must be well organized to enable users to make decisions quickly and effectively. Hence, data quality management is vital to the success of the data warehousing strategy and to security in particular. Extraction tools are a significant part of this. An extraction tool must be able to gain legitimate access to and extract all of the required—but only the relevant—operational data requested [10].
In Focus
Data warehouses are common and important to security because they can help managers look for patterns that might suggest information leakage or planning for sophisticated information or systems attacks.
To transform information contained in data warehouses, we may use online analytical processing (OLAP) technologies or data mining technologies. Although these differ in fundamental ways, data mining and OLAP are both used for gathering business and security intelligence. Data mining and OLAP fall into the category of decision support systems (DSS). DSS have been around for many decades, but recent advances in technology have changed what they do and how they are used. Most decision support systems offer managers or other users such as administrators “canned” (preconfigured) reports. These are basic, predefined, and formatted reports that users run to get a snapshot of current business activity. A requisite for canned reports is a well-defined business question to query against. Submitting free-form (ad hoc) questions to a database is the next logical step in the evolution of reporting. After receiving hard copy reports, business users inevitably have additional questions. OLAP thus takes various forms (slicing and dicing the data by various dimensions and, with complex multi-statement queries, producing multi-dimensional views called cubes), but the common denominator of these forms is that they provide analyses combined with relatively fast, consistent, and interactive access to data from a variety of perspectives.
On the other hand, data mining is much more laborious. With data mining, the analytical tool identifies hypotheses from patterns that emerge, and they tell users where in the data to start the exploration process. Rather than using OLAP statements to filter out values or methodically reduce data into a concise result set, data mining uses algorithms that statistically review the relationships among data elements to determine if patterns exist. There are many kinds of data mining and analytic processes that break data into sets according to some category or grouping, including cluster analysis, which uses statistical approaches to finding patterns from massive amounts of data, and predictive modeling. We will cover these in more detail when we get to the last section of our textbook in the chapters on using data mining and predictive modeling related to security threats.
7.3 Distributed Systems and Information
Until now in this chapter, we have concentrated on data, information, and systems, including how data are transformed into information. We have also covered some high-level concepts related to storage and retrieval, and later we will get into more of the technical mechanics of these functions. At this stage, we will introduce the topic of distributed systems and present two major technical approaches that enable us to distribute systems and information. In other words, we may think of these as the means by which enterprise information integration is done and how applications such as enterprise requirements planning are enabled.
7.3.1 Globalization and Information Exchange
We know that information is shared, integrated, and stored on an enterprise level, and we also know that information is exchanged across organizations by means of various communications technologies. Thomas Friedman suggested that globalization has been behind the increases in networked and distributed systems. He defined globalization as the interweaving of markets, technology, information, and telecommunications systems in such a way that is shrinking the world and enabling us to reach around it [11].
According to Friedman, the world broke away from the Cold War system where division was an overarching principle, and moved in the direction of integration. In this new global framework, all opportunities increasingly flow from interconnections symbolized by the Web. Along these lines, we encounter the term network effects. Simply put, the value of a product or service increases with the number of people who use it. Here the term network refers to the objects (and ultimately people) that are either logically or physically connected to one another. A typical example to illustrate the concept is the telephone. If only one telephone existed, we could say that it would have virtually no value, but as we add telephones, their value increases exponentially with the number of possible connections. With email we see an even greater increase in value because theoretically everyone who has an email account can send a message to anyone they choose at the same time. Although some have taken the position that it was networking and distributed systems that fueled globalization, rather than the other way around, there is no mistaking that both are interdependent.
In Focus
Although email remains an important tool, social media and rich Internet applications on mobile devices are overtaking email as primary communications facilities.
Applications such as word processing programs help fuel network effects. Here the product is not physically interconnected, as is true of the telephone or email system, but the fact that a large number of people in the world use Microsoft Word increases the value of having that particular software compared to the value of owning other, less popular word processing programs. Bob Metcalfe, who was involved in the development of the network medium called Ethernet and who founded the 3Com company, proposed a formula to quantify the concept of network effects, which became known as Metcalfe’s law.
In Focus
Metcalfes law states that the value of a network—that is, its utility to a population—is roughly proportional to the number of users squared.
If we apply Metcalfe’s law to network computing, we would say that when there is only one computer, the value stays at 1, but when there are 10 computers connected in a local area network (LAN), the value soars to 100. In other words, the benefit gains are exponential. Of course, this is only one way to illustrate the power of networking, but the concept of network effects is a useful way of describing some of the phenomena related to the Internet consumer market. Many networking companies cut prices below costs in the hopes that they could gain a critical mass of early adopters. Managers at these companies hoped that by attracting people to their products and services a strategic advantage would be gained. Later, if customers wanted to switch to a comparable competitor product, significant value would be lost; this is the so-called “customer lock-in” and explains why some people continue to use one operating system even when they say they would prefer to use a different one.
Network effects can play out in a number of different ways and situations. For instance, we could say that a large number of freely available web browsers such as Firefox, Opera, and Internet Explorer helped to create rich Internet content and applications because authors and publishers of information knew that they would have a large potential audience. Standards bodies such as the W3C also play a key role in determining network effects; thus, the concept of network effects provides a useful lens through which to view the diffusion of innovative technology as well as the security issues related to them.
7.3.2 Distributed Systems Architecture
At the beginning of this chapter, we presented some applications such as CRM that rely on the concept of “distributed systems.” Distributed systems are applications that run on multiple computers (connected via networks) to complete a business function or transaction. A commonly recognized distributed system is a website for a large commercial enterprise such as Amazon.com. Suppose, for example, that we wanted to purchase a textbook online and we accessed a website called www.mybooksandmusic.com to make the purchase. It is unlikely that the textbook we want will be sitting in some warehouse that the company maintains. Instead, the company may act as an electronic storefront for publishers. The mybooksandmusic.com systems would communicate with various publisher systems to place orders on demand. It is also not likely that a single computer is handling our transaction. It is more likely that mybooksandmusic.com has myriad computers that process customer requests.
One of the more common distributed systems architectures is called an n-tier configuration. This means that there are multiple server computers that are connected horizontally and vertically. Using our website analogy, a horizontal connection among servers would be a collection of web servers that handle the vast number of users who want to connect to the mybooksandmusic website. These “front-end” servers would handle the display of the information and the user interaction. The front-end servers would then be connected via a network to a middle tier of systems that process the business logic, such as placing orders with the book suppliers or performing calculations such as shipping costs. The middle-tier servers connect via a network to database servers where, perhaps, catalog and customer information is stored.
The term n-tier means that the company can have many servers at each of these three horizontal layers (Figure 7.2). As the company’s business grows, mybooksandmusic.com can simply add servers where they are needed; for example, if there are many new users who want to purchase books or music online, a server could be added to the front-end tier; if many new suppliers were added to the business, another server could be added to the middle tier, and as our data stores grow, we can add a server to the database tier. This separation of layers or tiers helps with both extensibility and security.

FIGURE 7.2
N-tier layered systems.
Some of the technologies that are used in distributed systems are “tightly coupled”; by that we mean they are written in technologies that require programs to coordinate through standard interfaces and share some components. An example of this would be an object request broker (ORB), of which there are three major ones: (1) those built on the Object Management Group’s (OMG) Common Object Request Broker Architecture (CORBA), (2) the Distributed Component Object Model (DCOM) from Microsoft, and (3) the Remote Method Invocation (RMI) from Sun Microsystems/Oracle. With these distributed technologies, programmers write interfaces—which consist of data definitions and types that distributed programs expect, along with the names of functions that distributed programs can call. Programmers must also generate connector components (often called stubs and skeletons), which tell the distributed programs how to locate and communicate with each other.
An alternative to this “tightly coupled” approach is what is often called service-oriented architecture (SOA). A conventional description of SOA is that it is an ability to loosely couple information for disparate systems and provide services through proxy structures [12]. To try to ground this abstract idea, let’s utilize some examples beginning with a question: What if a computer system needed to transact business with some other computer system in the network cloud with no prior knowledge of the other system or prearrangement for how to communicate?
In Focus
Service-oriented architecture (SOA) is a vague term, and nailing down the exact meaning is elusive. Further muddying the waters is that the term has recently intertwined with a reference for a collection of facilities called web services.
For example, suppose we offered insurance brokerage services to automobile owners and wanted to get them the best price for coverage. We would need to get quotes for them from all the available independent insurance underwriters to compare. As you might imagine, we need to first find their web services, then determine how to interact with them, and lastly determine how to secure the transmission.
One of the ways to address these issues is to use the eXtensible Markup Language (XML) along with the Web Services Description Language (WSDL), which is an XML format for describing web services as a set of endpoints for messages. Thus WSDL is basically a markup language that describes the network protocols for the services and ways to exchange messages. Specifically, it defines how client applications locate and communicate with a service provider. Trading partners or company lines of businesses that operate using different data formats can exchange WSDL directly, even though sometimes it makes more sense to use a registry. A registry is a mechanism that allows for advertising services analogous to the Yellow Pages in a telephone book. The Universal Description and Discovery Integration (UDDI) is an XML-based registry (repository) and API that allows organizations to advertise their services on the Web. In other words, UDDI advertises services using WSDL. Companies create WSDL for their services and then register these into the repository to list their names, products, and web addresses, along with other important information such as what delivery methods to use. Client processes can simply look up the services from the registry and determine at runtime how to find and connect (bind) and exchange information with the services.
7.3.3 Markup: HTML and XML
Services and distributed systems typically depend on a flexible markup language that can be interpreted at runtime. An important feature of markup language is the ability to disengage the underlying implementation of a system from the functions performed by the system. As an example, in the ability to surf the Web with browsers, most people think of the Hypertext Markup Language (HTML). HTML allows a web page developer to create a display for a browser using static symbols and rules, which are used as a form of grammar by the browser program (such as Internet Explorer or Firefox). The HTML grammar is predefined by tags, such as <p>, which signals to the browser to start a new paragraph, the tag <strong>, which indicates to the browser to bold the text, and so forth. For the most part, tags used for formatting are ended using a slash, as in the following: <strong>This sentence would be bold</strong>. Markup such as this consists of ways for creating and manipulating information in a textual form that can be read by a standard program.
However, using a static grammar such as HTML does not afford flexibility for adaptive systems. Thus the XML was created to enable a collection of facilities and information structures to be manipulated and distributed among computer applications, between computer systems, and even over the Web. Like HTML, XML contains markup codes to describe the contents of a page or a data structure. XML is “extensible” because, unlike HTML, the markup symbols are unbounded and are user-defined; hence, XML describes the content in user-definable terms for what an XML document contains. As an example, if we placed the tag <email> inside the markup in an XML document, we could use the data contained between the tag and its end tag </email> to indicate an email address for a given record, and we could define a name attribute such as <name>Mike</name> as a recipient.
In Focus
The benefits of markup such as XML are that information can be processed by humans or computer programs and that the contents can be stored in a database, retained as a text file, or even displayed on a monitor or computer screen by a browser.
Now, we illustrate how XML works: A computer manufacturer might agree on a standard method to describe information about a computer, such as the computer model, a serial number, its processor speed, memory size, and peripheral options. When they want to exchange inventory information with trading partners such as customers and suppliers, they can describe the computer using XML so that the information can be passed among systems and stored in repositories without regard to the trading partners’ systems and technologies.
The XML markup form of describing information even allows a mobile program called an agent to sift through the XML documents, similar to how a web crawler or bot might be used by Bing or Google to find relevant documents on the Web from a keyword query string. Companies can use XML to share information in a consistent way and locate specific documents or even elements within documents. An example of an XML document follows:

Repeating the collections of tags is in hierarchical form in order to produce record structures, as in the following XML markup example:
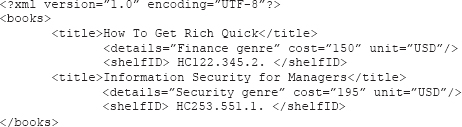
Note that XML can be displayed in a browser, passed back and forth between trading partners, or even stored (persisted) in its entirety in a database.
7.3.4 Parsing Markup
At this stage, it should be clear how information can be flexibly “marked up” into a document that can then be shared among people or computers. Realize now that we need some sort of dictionary to describe to people or computer translators what the tags mean and what types of data are contained in the document. For this, systems must share a markup document called a schema. Schemas (or DTD) act rather like dictionaries that match attributes defined in XML with their definitions, for example, by defining the data types: integers, strings, floating point numbers, and so on. By sharing schemas, various entities (companies, trading partners, etc.) can interpret a given XML document.
In Focus
The differences between a DTD and a schema are minor. The major difference is that the schema was adopted more widely as a standard data definition. They both must define the data types in the XML document and specify whether the items are mandatory or optional, along with processing parameters. It is the format of the specification that makes the major difference.
Where a browser is used to interpret HTML, a parser is used to interpret XML. There are a variety of parsers available, and there are various ways an XML document can be parsed. Two that are common are DOM (document object model) and SAX (simple access protocol interface for XML). The DOM way of parsing collects the entire XML document into memory in a tree structure, starting with the top level, or root, element. The parser then “walks down” the tree, interpreting the contents of each node in the tree structure of the XML. The SAX parser does not load an entire document in memory, but rather, it gets the contents of the XML document using calls to its Application Program Interface, or API (known as event parsing). Each way is used for different purposes: If information needs recursive referencing, DOM is used more often; if the data are being accessed only once, then SAX is used more often.
With the implementation of the Simple Object Access Protocol (SOAP), parsing and processing XML documents have become, well, simpler. SOAP is an enabling technology for XML originally developed by Microsoft. It has informational components, such as a header, that contain information that aids in exchanging and processing XML documents between applications. In addition to exchanging data among systems, XML can also be used to present information to a browser or to generate other types of documents. For this, we can use something called an XML style sheet and translator (XSLT). XSLT is used for parsing through the XML document and generating HTML for display in the browser or to render in some other fashion.
In Focus
SOAP is a formatting technology for an XML parser program to use for routing and inspecting XML documents.
7.3.5 RDF and Ontology Markup
Because XML is hierarchical in structure and therefore inefficient to process in large volume, that is, in order to gather intelligence, the W3C standards body has embarked on a revolutionary way to reorganize information in the Web, coined the “Semantic Web.” Semantics is a name given to a group of technologies that evolved from XML to provide enriched and better contextualized information, thus enhancing the human ability to make meaning out of information. As such, a type of markup called Resource Description Framework (RDF) was developed to provide more relational intelligence (semantics) in web systems. In other words, RDF is based on XML, but it is an attempt to make better use of metadata (data about data) by extending the markup to form relationships among documents.
For example, using the technology of search engines, if we were going to write a research paper, we might first do a search using keywords on the topic. A typical search engine would sift through metadata looking for keywords or combinations of keywords, cross linkages, and other cues that might help match, and then we would receive back from the search engine lists of links, many of which might not be relevant. RDF, on the other hand, establishes internally defined relationships among documents by embedded Uniform Resource Identifiers (URIs), and the relationships among documents are expressed in triples: subject, verb, and object. With RDF statements, I might make assertions in separate RDF documents such as:
1. Michael is a professor.
2. Michael teaches information security for managers.
3. Michael has an office at the college of business building.
In Focus
RDF markup allows for information to be more flexibly created and linked together to increase the relevance of queries for related information.
From RDF, ontologies evolved to organize bodies of related information and provide semantic rules and context, as illustrated in the differences between these two sentences: Wave to the crowd versus Let’s catch the next wave. Although ontologies and ontology markup are beyond the scope of this textbook because they require an extensive understanding of programming concepts, we will briefly mention them here because they are important for managers to consider in terms of security as this technology evolves. An ontology in the context of our textbook is a controlled vocabulary in a specific knowledge domain that provides structure for representing concepts, properties, and allowable values for the concepts. As suggested, ontologies are created using a markup language, and documents are linked together with Uniform Resource Identifiers (URIs). URIs resemble URLs in that they are used by browsers to find web pages, but they differ in some subtle ways—in particular, URIs extend beyond web pages to include other media.
In Focus
There are upper and lower ontologies: Upper ontologies are nomothetic—that is, they deal with generalized concepts. Lower ontologies are ideographic—that is, they represent domain-specific relationships. Domain specific means that a doctor in a medical ontology is a physician, whereas a doctor in an educational ontology is a professor.
Because ontology markup builds on RDF, ontology markup languages include all the RDF characteristics. Just as with RDF, the predicate portion of the ontology definition is a property type for a resource, such as an attribute, relationship, or characteristic, and the object is the value of the resource property type for the specific subject. However, although RDF enables URI linkages, these are based on a relational structure, but the Ontology Web Language (OWL) and the DARPA Agent Markup Language with the Ontology Inference Layer (DAML+OIL) use RDF to form a more object-oriented markup used in organizing related bodies of information.
Ontology markup therefore establishes rules and enables inheritance features in which the constructs can form superclass-subclass relationships. For example, a disjoint relationship could be expressed such that A is a B, C is a B, but A is not C; such as, a dog is an animal, a cat is an animal, but a dog is not a cat. In the DAML+OIL markup that follows, we could assert an expression that a class Female is a subclass of Animal, but a Female is not a Male even though Male is also a subclass of Animal [13]:

7.3.6 Active Semantic Systems
Without some way to gather and utilize information stored in ontologies, these would be little more than passive data warehouses or, more specifically, data marts. However, although they consist of largely undifferentiated masses (non-normalized) snapshots of data, at least with data warehouses, statistical programs can mine patterns from them in a relatively efficient manner for making future predictions. Ontologies would be less efficient because they consist of text documents that need to be parsed before mining could take place, or before an online analytical process (OLAP) could produce meaningful multidimensional views of the related data.
The good news is that there are technologies to deal with this problem that have recently emerged, and some that are on the cusp. Before we get to those, let’s first take stock of where we are and consider the relationships among markups because we have presented many concepts in this overview introduction. We noted that more intelligent systems need a more active type of bot or crawler that can traverse URIs and make inferences about what it “learns.” The most advanced of these are called goal-directed agents. Agents (such as Aglets from IBM and those developed from the open source Cougaar framework) range widely in terms of their capabilities.
Simple utility agents have little more capability than a web search engine, but a goal-directed agent can collect information and perform evaluations, make inferences, determine deviations from a current state and an end state (goal), and even make requests of systems that the agent “visits.” Consequently, with the advancement of semantic technologies, there is the classic tradeoff between functionality and security. To mitigate, agents generally work in a sandbox or a self-contained area—such as a given companys ontology—and employ a variety of security techniques such as authentication (more later).
In Focus
The Ontology Web Language (OWL) extended DAML+OIL to form what are called information models. The emergence of these new markup languages has transformed the simple attribute-value pairs of XML into representations of subject-verb-object relationships with RDF and combined with the ability to create “classes” out of these documents. They can be organized into collections of knowledge domains (ontologies) using ontology markup languages, such as OWL. It is in this evolution (called semantic fusion) that the silos of legacy data may integrate in new, more flexible ways with the corporate information infrastructure.
7.3.7 Agent Frameworks and Semantic Fusion
Agent frameworks are part of semantic fusion, which provides a different way to advertise and discover services than has existed in systems to date. Semantic fusion and agent frameworks allow users to specify parameters and program or write scripting to surf through the vast set of URI linkages for relevant information based on specific contexts within an ontology because these are usually vast expanses of information reservoirs. Using semantic persistence engines, ontologies can even be stored as subject-verb-object (triples) in databases.
The key issue is that finding information using agents may produce more relevant query results, but potentially also may be less secure because they traverse from system to system and are intelligent enough to make decisions based on what they find.
In contemporary systems, information is typically drawn out of an environment and stored away in a data warehouse, where it is later examined for patterns by using various analytics, but much of the important information may have changed in the dynamic environment since the time the data were extrapolated into the closed system. This closed-system static model of pattern discovery is inherently limited [14]. Moreover, with data warehousing analytics, the user must provide the problem context. By way of using the Web as an analogy, the user must “drive” the search for information with the assistance of a technology such as a crawler or bot. This has widely recognized limitations.
Specifically, the Web is a sea of electronic texts and images. When we look for something of interest, unless someone provides us with a Universal Resource Locator (URL) link where we can find the relevant material, we must resort to a search engine that gathers up links for documents that are possibly related to our topic. We then begin a hunt from the search results, sifting through the links looking for those that might match our interests. When we find a page that seems relevant at first and begin reading through the material, we may discover that it is not what we had in mind.
With semantic fusion, advertisement and discovery of ontology models are done using agents. Agents are similar to web search engine crawlers or bots, but they have greater inferential capabilities. For example, they can evaluate information as they retrieve it. There are many types of agents depending on the roles they fulfill. Middle agents act as intermediaries or brokers among ontologies, support the flow of information across systems by assisting in locating and connecting the information providers with the information requesters, and assist in the discovery of ontology models and services based on a given description. There are a number of different types of middle agents that are useful in the development of complex distributed multi-agent systems [15].
Other types of agents include matchmakers. These do not participate in the agent-to-agent communication process; rather, they match service requests with advertisements of services or information and return matches to the requesters. Thus matchmaker agents (also called yellow page agents) facilitate service provisioning. There are also blackboard agents that collect requests and broker agents that coordinate both the provider and consumer processes.
In Focus
Agents, such as Cougaar, not only have the capability to traverse from system to system to collect information similar to bots and crawlers, but they can perform evaluative logic and execute instructions.
Therefore, agents have a capability that enables software to “understand” (meaning evaluate) the contents of web pages, and they provide an environment in which software agents can roam from page to page and carry out sophisticated tasks on behalf of their users, including drawing inferences and making requests. With this new technology, we might advertise through a website that We-Provide-Air-Transportation. Agents would be able to meander from airline website to website, searching for those semantic relationships and performing tasks such as telling an airline website that “Mike-Wants-To-Make-A-Reservation” and then providing the “Amount-Mike-Will-Pay.”
In Focus_
Today, the Web is a passive sea of electronic data, where users have to navigate through links to find resources of interest, but the Web of tomorrow will be an active system. We havent yet realized the range of opportunities that what the W3C is calling the Semantic Web will open up for humankind. Facilitated by software agents, we will have new ways in which we can share, work, and learn in a virtual community—but the security and privacy issues associated with this capability are profound.
In this chapter, we covered data and information, some applications used in integrating information, and enterprise information integration, along with applications that utilize them such as customer relationship management systems. We also covered relational database concepts and introduced data warehousing. We highlighted the emergence of new markup languages and how they have transformed the simple attribute-value pairs of XML into representations of relationships with RDF and, when combined with the ability to create “classes” out of these documents, how they can be organized into collections of knowledge domains (ontologies) using ontology markup languages, such as OWL. As we shall discuss later, these technologies may also present a whole new range of security threats.
Agents, such as Cougaar and Aglets, not only have the capability to traverse from system to system to collect information similar to bots and crawlers, but they can perform evaluative and inferential logic, and they can execute instructions. We will explore these and other technologies in more detail in subsequent chapters. Once we are done, you should have a good handle on how various technologies work and techniques to help ensure that resources are reasonably secure.
Topic Questions
7.1: Relational databases are designed based on what two elements?
7.2: What differentiates XML from HTML?
7.3: What does WSDL do?
7.4: The term value chain refers to the activities and departments involved in delivering a companys product or service.
___ True
___ False
7.5: Multi-dimensional views of data (cubes) are produced from queries of data warehouses by using:
___ Relational database queries
___ SQL Select * from MyData
___ Online Analytical Processing (OLAP)
___ Data mining
7.6: A “yellow pages” for WSDL is:
___ UDDI
___ An object request broker (ORB)
___ A special folder that is shared
___ SOAP
7.7: A disruptive technology is one that can change a paradigm.
___ True
___ False
7.8: A__________links markup documents together.
7.9: In reference to technologies, the term value neutral means:
___ They nullify people’s value systems.
___ It is up to people who apply technologies as to whether they are used for good or for bad purposes.
___ They are used as leverage with a customer or supplier, or over a competitor.
___ They cause people to have to personalize technologies.
7.10: Ontology markup establishes rules and enables inheritance features in which the constructs can form superclass–subclass relationships.
___ True
___ False
Questions for Further Study
Q7.1: Why has SOA become a popular method for trading information among distributed systems?
Q7.2: What are agent frameworks, and what purpose do they serve? How do they differ from web crawlers or bots?
Q7.3: What security problems might be created by using SOA?
Q7.4: What are two technologies that can be used for persistence of RDF documents?
Q7.5: Give some pros and cons to tightly coupled versus loosely coupled distributed technologies.
Agent frameworks are part of semantic fusion.
Disruptive technology has sufficient inertia to change a paradigm.
Electronic Data Interchange (EDI) standards emerged in an effort to bring structure and order to the information integration problem.
Normalization is the process of designing relational databases to eliminate anomalies.
Value chain consists of activities that a company performs in order to deliver its products or services.
References
1. Porter, M. E. (1979). How competitive forces shape strategy. New York, NY: Free Press.
2. Porter, M. E. (1996, November–December). What is strategy? Harvard Business Review, pp. 61–78.
3. Synnott, W. R. (1987). The information weapon: Winning customers and markets with technology. New York, NY: John Wiley & Sons.
4. Hendrick, S. D., Ballou, M. C., Fleming, M., Hilwa, A., & Olofson, C. W. (2011). Worldwide application development and deployment 2011 and top 10 predictions. Framingham, MA: International Data Group (IDC).
5. Connolly, T., & Begg, C. (2005). Database systems: A practical approach to design, implementation and management. New York, NY: Addison-Wesley.
6. Tillman, G. (1993). A practical guide to logical data modeling. New York, NY: McGraw-Hill.
7. Kroenke, D. (2002). Database processing. Upper Saddle River, NJ: Prentice Hall.
8. Hoechst, T., Melander, N., & Chabris, C. (1990). A guide to Oracle. New York, NY: McGraw-Hill.
9. Inmon, W. H., Imhoff, C., & Sousa, R. (2001). Corporate information factory. Boston, MA: John Wiley & Sons.
10. Webb, T., & Will, D. (1999). Performance improvement through information management. London, UK: Springer.
11. Friedman, T. L. (2005). The world is flat. New York, NY: Farrar, Straus & Giroux.
12. Workman, M. (2010). A behaviorist perspective on corporate harassment online: Validation of a theoretical model of psychological motives. Computers & Security, 29, 831–839.
13. Miller, E. (1998). An introduction to resource description framework. Retrieved July 6, 2010, from http://www.dlib.org/dlib/may98/miller/05miller.html
14. Churchman, C. W. (1971). The design of inquiring systems: Basic concepts of systems and organization. New York, NY: Basic Books.
15. Murray, D. (1995). Developing reactive software agents. AI Expert, 10, 26–29.