
Computer Operating Systems |
CHAPTER10 |
WE HAVE COVERED SOME OF THE BASIC concepts about information systems, databases, and programming. Now in this chapter, we will summarize functions of general-purpose computer operating systems. Rather than simply provide a user’s view, we will delve into some operating systems' internal functions and data structures by examining Microsoft Windows and UNIX-based operating systems, such as Linux, FreeBSD, and MAC/OS, as reference examples. This will provide a conceptual perspective to set the stage for the chapter on host computer security in the next section. We will begin with a view into digital logic and move on to how operating systems work with computer hardware and mediate user activities.
Chapter 10 Topics
This chapter:
• Briefly presents what operating systems do.
• Covers digital architecture and logic.
• Explores how hardware and operating systems interact.
• Helps you to become familiar with data structures and algorithms.
• Examines how user actions translate through Linux (UNIX) and Windows operating systems.
When you finish this chapter, you should:
![]() Have a basic understanding of how hardware and the operating system work together.
Have a basic understanding of how hardware and the operating system work together.
![]() Have an understanding of what processes and threads are and how they are managed.
Have an understanding of what processes and threads are and how they are managed.
![]() Know how a process scheduler works.
Know how a process scheduler works.
![]() Understand interprocess communications.
Understand interprocess communications.
![]() Be able to explain memory management techniques.
Be able to explain memory management techniques.
![]() Have a grasp of file systems and file management.
Have a grasp of file systems and file management.
![]() Know about I/O and the interaction with hardware and drivers.
Know about I/O and the interaction with hardware and drivers.
10.1 Operating Systems: An Introduction
You are probably used to working with computers but perhaps you may not think about how they work. Let’s briefly discuss this before we move into what operating systems are and what they do. Note that there are many types of software systems and applications. At the highest level, such as Microsoft Word, we know this as a “software tool,” but it is written in a programming language. When we launch Word, it also launches several software components such as something called COM (Common Object Model) that allows Word to exchange information (through an interface called Object Linking and Embedding [OLE]) with other applications. If you have ever copied an Excel spreadsheet and pasted it in a Word document, you have experienced COM/OLE at work. The key point is that neither program applications nor hardware would work without an operating system (OS).
10.1.1 Systems and Software
We have already considered programming, but imagine the programming that goes into creating applications such as Microsoft Word. You may already know that you can customize Word by extending it with programming code. For example, if you added the “Developer” tab to your Word application, you could bring up the “development environment.” At this point, you could actually program embedded code into your Word document using Visual Basic. So you get the idea that Visual Basic is a high-level language, like C++, and is used for writing applications, for example, when Visual Basic is embedded in Word. (There are many other high-level languages, as we have noted earlier, besides Visual Basic, such as COBOL, Fortran77, and Pascal.) With a little more coding work, this code could create a message that says “Hello” when you open a document:
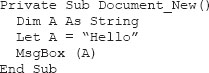
Where high-level programming languages, such as Visual Basic, are useful for writing applications, they are not very useful for writing operating systems. Operating systems must work quickly and be able to communicate directly with the hardware components. Operating systems also must “execute” these high-level programs such as Word.
It is important to realize then that systems are made up of software. A system needs more than just a Microsoft Word application to run; it needs to interact with other software—and much of the interaction is in the form of what we call a client and a server. Most people associate a client and server with the Web, and although that is certainly true, the Microsoft Word editor is a client to the Word server. The server executes when you launch Word and open a document. You can see that software is a broad classification for any type of constructed statements that perform some computerized function; as such, software falls into different categories. Systems software is usually associated with computer operating systems such as Microsoft Windows or Linux, but it could also be software that makes network routers function or that controls certain devices. There are finer classifications of operating systems such as “real time” or “near real time” systems that monitor devices such as process controllers, air traffic control systems, or certain kinds of robotics.
Consequently, applications software consists mainly of the kinds of programs that users interface with to perform some function; for example, Microsoft Word is used to write documents, or a customer relationship management (CRM) application might be used to help track and manage client activity, or an inventory control system or accounting system might be used for business types of tasks, which we have previously mentioned.
Another important class of software involves what is often called middleware. As the name implies, this software intervenes between application and system software or between two different kinds of application software so that information can be exchanged among disparate sources and systems. Middleware can usually bridge between different network protocols, translate, manipulate, and format different data types, and execute rules such as what to do if an error occurs in a translation. A major class of middleware is known as enterprise application integration (EAI) software. EAI is focused on integrating and consolidating information among the computer applications in an enterprise. One common EAI use is to extract data from legacy applications, running on a mainframe computer, and load the data onto more modern systems such as distributed or desktop computers. It can also extract, translate, and load data among different databases, or allow for two systems to exist during a migration by creating ways for the information to flow to each system in parallel.
There are other systems as well, such as enterprise resource planning (ERP) systems used to plan and manage production “just in time” by coordinating the materials through the delivery chain, and business process management (BPM), which is similar to ERP, but it revolves around the business functions in an enterprise. These types of applications usually have a graphical user interface (GUI). A GUI is a visual display of some sort; for example, it can be a specialized monitor for showing network activity, railroads, or power grids, or it can display web content via a browser. The idea of GUI grew from the lumbering interaction that most people were subjected to with textual interfaces such as the UNIX shell or DOS window. GUIs provide features such as pull-down menus, buttons, scroll bars, “hot” images, and mouse-driven navigation—the features that most people associate with human–computer interaction.
Although we gave a list of sample applications you may already be familiar with, there are also programs for specialized scientific functions that OS perform such as running a nuclear plant or performing statistical analyses on data. Software exists for vertical applications such as banking, retailing, manufacturing, and logistical systems. There are utility programs used for doing system maintenance, backups, or automating manual functions. There are programs that are designed to work over the Web, such as to allow you to purchase a book online, and even database management systems that hold data are software applications. The lists in these categories are endless!
10.1.2 What Do OS Do?
In Microsoft Windows, people first see their desktop displaying frequently used program icons on it (Figure 10.1). Clicking on an icon (which is an image that has an associated link to a program) will cause the selected program to execute. This interaction between user, display, and program execution is what we call the “user view” of the system. Sometimes people relate to their computers by means of their user views—and mainly their GUI. This is often Windows Explorer, or sometimes could be a command window. However, the user view of the system and the user interfaces that these provide are not part of the OS, per se; these are support services that use the OS and vice versa.
As we will present later, the main part of an OS is called the kernel. The kernel is responsible for interacting with hardware devices, managing the data loaded into random access memory (RAM) or on the hard disk drive, loading programs into the central processing unit (CPU) for execution, and the like. Depending on whether you use a Microsoft Windows system or a MAC/OS, Linux, or some flavor of UNIX, the kernel will play a smaller or larger role in what the OS does in terms of these responsibilities. For instance, the Windows kernel plays a smaller role and relies more on “subsystems” than do UNIX-based system such as Linux or MAC/OS.
Overall, the OS can be thought of as consisting of programming code and sets of data structures. The programming code is written in a low-level language such as “C” or assembly language, and the data structures are often linked lists or queues (more shortly). Most OS are also “event-driven,” meaning that when a user types on a keyboard or clicks on something with the mouse, or when a storage place in memory becomes full, or when the CPU is ready to execute a new program, a type of signal or event is generated, which causes the OS to notice the event and respond to it. Because many people can use a computer at the same time, and many programs are running at the same time on a computer, the orchestration of these events and the execution of responses are very complex.

FIGURE 10.1
Windows desktop.
From a user perspective, we may see programs in a directory or folder with an “.exe” extension. These executable files lie dormant until a user or another program invokes them. When the program is invoked, it becomes a “process,” which means that the OS allocates memory and sets aside various data structures for the program to run. The process is divided into parts, where some of the parts are only accessible by specific OS processes and other parts may be accessible by a user—a browser is a good example of this. Once the data structures have been created and memory allocations have been done by the OS, the process is placed in a queue until its turn comes to be executed by the CPU. In Windows, there are also “.dll” files (Figure 10.2). These are dynamically linked library files used by executable programs; in a sense, they too are executable, but not on their own.
10.1.3 Windows and UNIX (Linux)
Generally speaking, most people are familiar with Microsoft Windows—at least some version or another. However, there have been many changes to the Windows operating system over the recent years, and there seems no end to it either. We are going to cover some of the varieties of Windows ranging from XP to Version 7 and beyond, but in modern times, most of us have already grown familiar with Microsoft Vista or XP versions of Windows. However, Vista created new paradigms to deal with compared to previous versions, along with some unintuitive behaviors in associated applications. This was especially the case in Microsoft applications associated with the OS release, such as its Office 2007 suite, in which new features were added and others were moved around into different locations in a seemingly bewildering and random fashion. Windows version 7 attempted to compensate for some of those quirks and also attended to some of the persistent security flaws in Windows; in the process, it grew to look a little more like a MAC/OS type of operating system than what we were familiar with as Windows users.

FIGURE 10.2
DLLs and components.
In Focus
People grow accustomed to predicting their environments and pay attention mainly to anomalies, such as in new user interfaces and functions. When these change, there are not only new features to learn, but changes that can “fool” people into doing the wrong thing from a security perspective. Linux and other UNIX-based systems such as MAC/OS have presented a much more consistent “look and feel” by introducing incremental changes to the user interfaces rather than radical ones.
Microsoft Windows is a proprietary system, so the code and internals are a partially guarded trade secret. However, there are some published aspects of the OS that can be presented, and many internal parts of it can be inferred as we will describe later. Dave Cutler was the chief architect of the modern Windows OS (beginning with Windows NT). Before joining Microsoft, Cutler designed the Digital Equipment Corporation’s VMS OS, and he (and others) wrote many publications about VMS internals [1]. Although Cutler had a limited hardware platform to work with at the time he joined Microsoft (compared to the more robust DEC VAX mini-computer), there were hints given, for instance, that the new Windows NT architecture was a vastly scaled down version of many of the VMS concepts. At the base level, we need to understand some specific aspects of hardware–OS interaction and digital logic to appreciate how computer security is maintained or compromised.
Predictability is a critical feature to security awareness and human-computer interaction. Each time a software manufacturer changes the “look and feel” of a system, they introduce greater potential for unintentional human errors related to security. Consequently, many security failures blamed on users for omitting security precautions against threats might more appropriately be placed on vendors who radically change their user interfaces (or user experience).
10.2 Digital Architecture
Thus far, we have introduced the notion of how users interact with computers and, more specifically, an operating system, but how do operating systems interact with hardware? This matters because anyone who works in security must realize the entire chain of events from a user to the hardware. For example, how does a person in Beijing, China, cause a computer to crash in Sophia Antipolis, France, or in Toronto, Canada? To understand this, we must start from the ground up! At its most basic level, computers work with binary codes: bits of 1s and 0s. Groups of bits create patterns that are translated into the numbers and characters human beings recognize and vice versa. This scheme allows, for example, a programmer to write a statement that says, “if (a),” which says that if a number represented by variable “a” is any number other than 0, the result is true; otherwise, the result is false. Constructs such as “if (a)” are used to make decisions in program logic, and computer logic uses binary mathematics to represent varying electrical charges in solid-state circuitry. Binary logic, as you know, uses two digits: 0 and 1. Although a 0 may be associated with a lower voltage and a 1 with higher voltage, let’s assume that in most computer systems, a 0 represents a negative physical charge and a 1 represents a positive physical charge, and these charges indicate false and true, respectively. How this binary logic is converted between higher-level coding and interpreted by various components is complex, so we will only provide a basic “functional-level” overview.
10.2.1 Hardware Components
The central processing unit (or CPU) executes the instructions for software applications running at any given time. Software components that communicate directly with the CPU are part of the operating system (OS). The OS must have functions that enable users to enter commands and translate those into codes to be executed by the CPU.
A device driver controls the devices (disk drives, user interfaces, and other hardware devices) and manages the hardware interaction for the OS, and a scheduler (or dispatcher) determines the order that applications are queued to run by the CPU. The CPU is actually composed of a highly dense circuitry, part of which contains a component called the arithmetic logic unit (ALU) that performs computations. Central processors also tend to work with either 32 or 64 bits at time.
Besides their “bit width,” CPUs are also known by the number of their “cores.” A core is a processor that reads and writes instructions, so a single-core processor can handle only one process instruction at a time. However, multi-core processors are now commonplace. These can do reading and writing of instructions in parallel, depending on their number of cores—dual core are two cores, for instance, whereas quad core are four cores—integrated into a single CPU chip.
Random access memory (RAM) consists of integrated circuitry that stores information being accessed by the operating system. When the computer is turned off, anything kept in RAM is lost; thus RAM is said to be volatile. A memory manager controls the data structures in memory. Data are also stored in the computer’s persistent memory such as hard disk drives, flash drives, or tape drives. Here, information is magnetically stored and remains even when the power is turned off; hence the name persistent storage.
Components such as a hard disk drive communicate with the CPU by means of an intermediary component called a controller board. This circuitry handles the exchange of information between RAM, CPU, and other devices. There are controllers (and device drivers) for each hardware component—for instance, hard disk controller, monitor controller, and DVD controller. All of these devices are joined by an electronic pathway called a logic bus, or simply bus. The bus consists of the circuitry by which information is shared among the devices: controllers, RAM, CPU, and other hardware.
There may be a separate bus for high-speed devices, or even between the CPU and a static form of memory called cache. Contained on each one of the circuit boards are logic gate chips. Gates manage the logic flow within and among computer devices and circuitry. Other circuitry one will see on a schematic include resistors and transistors that control the flow of electricity through the circuit board, “buffers” and “registers” that temporarily hold information, amplifiers, relays, and a varied number of other types of circuit.
10.2.2 Binary Logic and Computer Hardware
When information is input into a computer, the CPU translates the binary codes into digits as indicated. The codes are then stored in a variety of circuit chips as groups of electrical charges represented as binary bits. Groups of bits create patterns that are translated into the numbers and characters people recognize. These bits are manipulated by the silicon components inside computers to perform specific roles. Logic gates and other components carry out the commands issued by the programming software. Some of the logic functions are AND, OR, NOT, NAND, and NOR. If we were to look at a computer circuit board diagram, called a schematic, we would see the symbols shown in Figure 10.3.
In Focus
Understanding logic such as AND, OR, and XOR is important in security—for example, creating subnetworks uses logical AND, and cryptographic ciphers use XOR, as we shall see later.
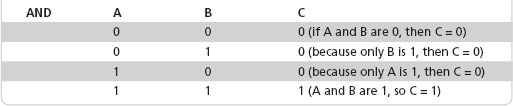
Inside the circuitry represented by these symbols, electrical current is passed (true) or prevented (false) based on the type of logic these symbols perform. The lines at the back of these symbols represent incoming electrical pathways, and the line coming out is the resulting electrical pathway. We can illustrate the logic using truth tables. In truth tables, a 0 represents false or off, and a 1 represents true or on. The truth table for AND in Table 10.1 indicates that when both incoming pathways (labeled A and B) are true (1), then the output (labeled C) is true (1); otherwise the output is false. In other words, it is only when electrical current is present on both incoming pathways that the AND gate will allow current to pass out of the gate.

FIGURE 10.3
Schematic representations of logic gates.
Now consider the truth table for the OR gate as seen in Table 10.2. Unlike the AND gate, the OR gate allows true (1) for an output when only one (or both) incoming pathway(s) is (are) true (1); otherwise, if both pathways are false (0), the output is false (0).
Next, let’s consider the NOT gate in Table 10.3. Notice that the NOT gate has only one incoming pathway (denoted A) and so its purpose is to invert the logic to the output (denoted B). Said another way, NOT simply converts true to false and false to true. As seen in the table, if the input is 1 (true), NOT will change the output to 0 (false); otherwise, if the input is 0 (false), NOT will change the output to 1 (true). Note that some gates may work with positive or negative electrical charges rather than the presence or absence of electrical current (depending on the hardware device).

10.2.3 Hardware Logic and Software Instructions
The CPU, memory, and other hardware devices could not function without logic components and the software to interact with them, and the OS provides the software components that make the hardware work. For example, registers are storages places for instructions. Operating systems also use buffers, which store data temporarily until the data can be processed by the OS. The OS manages various queues and data structures, such as the “stack” and “heap” where a program’s variables and parameters are stored. You may have heard of buffer or stack overflows; they are related to programming problems and some common security attacks, which we will cover later.
In Focus
Buffer overflows are a major security threat. Understanding how systems buffer data is fundamental to knowing what this threat means and how to deal with the threat.
Modern operating systems (e.g., Linux and Windows) use a layered architecture. Each layer communicates with the layer above and below it, and it is the OS that coordinates these layers as each carry out specialized functions. Depending on the type of computer, the CPU may utilize either a CISC (complex instruction set computer) or RISC (reduced instruction set computer) instruction set. A CPU can perform more work with CISC during one instruction cycle, but it cannot execute instruction cycles as fast as when RISC is used.
In Focus
The discussion of MIPS and processor speed you may have heard about is a distraction. It takes more RISC instructions to perform a single CISC instruction, even though it may execute RISC more quickly [1].
Software subsystems link into the OS to provide ancillary or intermediary functions to application programs. In this layered scheme, there are user processes and system processes that represent executing programs. User processes are those generally initiated by an end user, whereas a system process is generally initiated by the OS either as the result of another OS process or on behalf of a user process in the form of what is known as a system call (more later). In any case, a process begins its life as source code, and there are many kinds of programming source code languages such as COBOL, “C,” C++, C#, and JAVA.
Source code is not executable by the computer, as we learned earlier. It requires a compiler to transform the source code into RISC or CISC assembly language instructions. The compiler has a companion program called an assembler (along with a linker/loader) that transforms the assembly language into machine instructions—a low-level nomenclature that ultimately ends up as patterns of 1s and 0s—as we discussed earlier. At this stage, programs become executable, but they reside on hard disk until there is a request for the program to run, at which time the program executable becomes a process, which is managed by the operating system.
10.3 UNIX-Based Operating System Functions
A UNIX-based operating system includes Linux, Free BSD, and MAC/OS. Although each has diverged in terms of feature function, the cores of their systems remain consistently UNIX. The kernel is the central component of a UNIX-based OS, and it consists of the computer’s main set of “privileged” functions (List 10.1). The primary set of functions in a general-purpose kernel consists of the following [2]:
1. A memory manager that determines when and how memory is allocated to processes and what to do when memory fills up; this contains a subsystem called the pager/swapper that moves processes (or portions of processes called pages) from RAM onto a storage space on a hard disk drive called the “swap partition” when RAM becomes full.
2. A process scheduler that determines when and for how long a process can be executed by the CPU.
3. A file system manager that organizes collections of data on storage devices and provides an interface for accessing data.
4. Interprocess communications ( IPC) facilities that handle the various communications between processes or threads.
5. An I/O manager that services input and output requests from hardware.
10.3.1 OS Features
As with most modern operating systems, the UNIX-based (Linux, Free BSD, MAC/OS [hereafter UNIX-based]) kernel is a multi-user, multi-tasking, multi-processing system. It performs process scheduling, process management, memory management, and hardware control. The multi-user capability enables concurrency among users, and the multi-tasking capability allows multiple processes and threads per user to execute. Multiprocessing allows many CPUs to cooperatively execute processes simultaneously [3]. Although most UNIX-based systems provide a GUI such as Gnome, GIMP, X/Windows, or Motif [4], unlike Microsoft Windows, unless through a virtual machine, the interaction with the UNIX-based OS is usually through a command line interface called the shell.
In Focus
Note that the latest trend in OS is what is called a virtual machine. For example, VMWare has a client that allows a user to interact with user applications provided by a VMWare server. The VMWare client appears to be a desktop set of applications, and these interact with a virtual server. When interacting with a system in this way, one may never “see” a primitive “window” prompt.
Windowing capability in UNIX-based systems is provided by layered subsystems, such as X/Windows, Motif, Gnome, and GIMP, but these are not part of the operating system. They are, in fact, program libraries and programs that the OS can use for display. In UNIX-based operating systems, such as Linux, a special privileged user account is called “root” or “superuser.” The root login has special permissions to allow system administration and restricted command operation, allowing superusers to bypass file protections and perform functions that are not generally available to other users. (The Windows operating system equivalent to UNIX superuser is the supervisor mode.)
In Focus
Applications may make system calls to gain privileged functions, whether performed by a command or executed via a program. Programs can also perform privileged functions by having a superuser set a flag on an executable file, called setuid. This allows user functions to directly execute privileged operations.
10.3.2 UNIX-Based (Including Linux and MAC/OS) Processes
After a programmer has written instructions and compiled them, the program is ready to run (we see these as .exe files in a directory listing). A process is therefore an executing program. Processes that create other processes are called parent processes, and the created processes are called child processes. Because processes populate data structures and occupy memory, sometimes small tasks can be accomplished more efficiently using “light-weight” processes or threads. Threads share some of the data structures with their parent processes, so they can only be used for special purposes.
Programs are identified by the user login name and a user identification code (UID), both of which are stored in the UNIX “passwd” file. When a program is executed, these identification numbers are stored in the data structures that are created for the process. A process is also assigned a unique process identification number (PID) by the OS as well as a parent process identifier (PPID) for the process that created it. These PID and PPID are used to identify each other for interprocess communications (IPC).
In Windows, most processes are peers, and so the concept of a pure parent and child relationship is rare. Windows processes, however, do often spawn threads.
Programmers initiate IPC by writing instructions using an application program interface (API). An API is a standard set of codes that a program calls to send a message to another program. This is usually a user-level call—where one program makes a function (method) call to another program written as part of an application. However, when an application wants to invoke an OS function, it makes a system call through an API provided by the OS. For example, if we escaped out of our GUI to a command line interface (UNIX shell) and we typed a command such as ls, a directory listing output would be generated by the ls process, which is spawned by the shell. If we were to look at the UNIX shell source code, we would see a program statement (written in the “C” language) that invokes a process (in this example, “ls”) using the system call “fork.” The fork system call in the shell makes a request of the kernel to create (fork) the “ls” child process.
In Focus
A signal is an IPC that operates as a type of software interrupt. There are a variety of signals, but one that is familiar in UNIX is “kill” (or sighup), where one process (usually the parent) tells another process (usually the child) to terminate.
An External View of UNIX Processes
In the Windows OS, processes can be seen by simultaneously pressing the <ctrl><alt><delete> keys. This brings up the Windows Task Manager, from which processes can be viewed by choosing the Processes tab. Processes in UNIX are usually viewed from the command prompt using the UNIX command ps. For example, the command ps –al will display processes and their status, where the “a” is an option (also called a switch) used to display all processes, and the “l” is an option to display a full (long) listing of processes and their details.
In Focus
In Windows, to view “all,” you must have administrator privileges and select the “show processes from all users” button.
Processes normally run in the foreground, that is, interactively with the user, but they may be made to run in the background, where output continues to be reported to the standard output, which is usually the monitor’s screen or window. This leaves standard input (the user interface by default) free for other interaction. Processes that run in the background, which are called daemons, operate like processes running in the foreground with the exception that the process identification number associated with it (the PID) is reported to the standard output for status and termination by the ps and kill commands in UNIX. The shell will then continue to accept standard input from the user interface and does not wait for the processing to complete.
To highlight with an example, note the command prompt denoted “#” and that background processes are invoked with the “&” at the end of the command line. The following example shows a program compiler executed for a program called tst.c that will produce an output file called test.exe in the background using the &. Notice that it reports a unique process identifier (19823) back to the user interface, and the user can continue to execute other commands while the compilation is in process.
In this example, after the compiler was invoked in the background, the user then executed a sort of the contents from one file and sent the sorted output to another file (using the redirection or > symbol), and this too was done in the background. The user instructed that the contents of “dfile” be sent to the soft program through redirection (<) and the output of that file be sorted and sent to a file named “sorted” (>), also in the background (&). This too received a unique process identification code: 27482. At the UNIX command line, if we executed the ps command, we would see the following, where STAT reflects running in the background (d) or in the foreground (r) and the device that invoked the command:

Process and Memory Management
The memory manager is responsible for handling the data structures and managing the available RAM. Remember that data structures are little more than data (or variables containing values) that are stored at specific memory addresses. The memory manager must ensure that proper data are stored in proper locations and that there are no overlaps or that data that have been unreferenced (deallocated) are returned to reassignment and reuse by other processes.
The memory manager also attempts to load all the processes and threads and their data structures into RAM because all processes and their data structures have to be resident in memory for the CPU to execute them. For processes, there are two classifications of data structures: user data structures (specifically the user structure) and kernel data structures (i.e., the proc structure). User data structures contain information a process uses, such as indexes and descriptors for open files and their permissions. Kernel data structures are used by the OS to manage the user data structures [5].
A program’s “process” memory is divided into four logical segments: (1) the program text segment, (2) the data segment, (3) block segment space, and (4) the stack segment. These segments are managed by the operating system as part of a user structure. The user structure contains system information about the state of the process such as system calls pending and files open and being accessed. The text segment contains the code portion of a program and associated registers. The data segment contains variables and pre-initialized data. The block storage space (or bss) contains the “heap” for storage allocation for uninitialized data. The stack is used for automatic variables and for passing parameters. These segments are decomposed from this logical grouping into virtual address groupings managed by the kernel, as seen in Figure 10.4.
Many processes are “shared text,” meaning they each use the same text region simultaneously with other processes. Examples are the shell, editors, and compilers. When an editor is invoked, for example, its text region is the same as the other editors being executed on the system so programs may logically contain a text segment, although physically, they reside in separate address spaces. In other words, processes may share (reside in) the same set of virtual addresses but not the same physical addresses (more later).
In Focus
Virtual memory includes a swap partition on disk to enable greater memory capacity than provided with RAM only.
Processes and their data structures sit idle in queues while they wait for an execution time slice (quantum) from the CPU, which is handled by the kernel’s scheduler. If RAM becomes full while they are in this wait state, the user data structures (with the exception of the text data structure) can be moved to disk to the swap partition, whereas the kernel data structures (and text structure) for the process must remain resident in memory. This is because the kernel data structures that remain in memory are needed by the pager/swapper (or dispatcher in Windows) to locate and retrieve the user data structures from the swap partition when the CPU calls for that process to execute.
UNIX-based systems such as Linux and MAC/OS (like Windows) support demand paging virtual memory—where only portions of processes are required to be “paged” out to the swap partition when memory becomes full. This feature allows memory storage to be greater than the physical RAM in the system, and it improves OS performance by shortening the storage and retrieval time when the pieces have to be written to disk or brought back into memory.
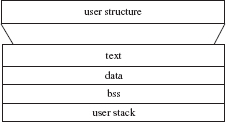
FIGURE 10.4
Memory segmentation and data structures.
UNIX is a true demand paging system, allowing for virtual addressing. The processes in memory are usually divided into pages of 1024 bytes (depending on the hardware platform). The virtual memory method breaks processes into pages, and inactive pages of these processes are relocated to swap partition on disk when memory becomes full. When a page is referenced that is not resident in memory, a “page fault” occurs, and the pager/swapper must retrieve it from disk [6].
When a process terminates either voluntarily or as initiated by the OS, the OS frees up the process’s memory and other resources and data structures, removes the process from the process table (proc table), and makes its memory and other resources available to other processes. Sometimes an error may cause a parent process to terminate before its children processes exit, making them orphans. In those cases, some data structures may be left in memory, and the children processes (called zombies in UNIX or rogues in Windows) will need to have their data structures removed. UNIX has a process called init that “adopts” these orphaned processes and does this “cleanup” work [6, 7].
Process Control and Scheduling
Process management and memory management are closely related in the UNIX OS. Processes that are created require the allocation of memory, and process components must be relocated between memory segments. The CPU must also have a way for processes to be scheduled for execution. The scheduler identifies “runnable” processes waiting in queue, selects them based on priority, and allocates a quantum of CPU time.
Data structures called the process control block (PCB) contain information about processes needed by the scheduler, such as the process identifier (PID), process state (e.g., running, which means executing in the CPU, ready to run, or blocked in a wait state), a program counter (values that determine which instruction of the process should execute next), a CPU scheduling priority, credentials (data that determines the resources this process can access), a pointer to the process creator (parent process), pointers to processes created (children), pointers to locate the process data and instructions in memory, and pointers to allocated resources (such as files on disk).
In Focus
Pointers are containers of addresses or locations of other containers.
The PCB also stores the register contents, which is called the execution context. This is information about the processor on which the process was last running when it transiftioned out of the running state into a waiting state. The execution context of a process is computer specific but typically includes the contents of general-purpose registers that contain process data, in addition to process management registers such as those that store pointers to a process’s address space. This enables the OS to restore a process execution context when the process returns to a running state. When a process transitions from one state to another, the OS must update information in the PCB for that process. The OS maintains pointers to each process PCB in a system-wide or per-user process table (the proc table) so that it can access the PCB quickly.
Processes fall into two categories: system processes and user processes. System (or kernel) processes always take precedence over user processes in their execution order. User processes started after logging in receive default execution priorities by the kernel, which subsequently degrade as the processes use the CPU. The UNIX scheduler is a “fair” scheduler, designed for time sharing, and the only control a user has over process scheduling priority is through the use of system calls nice and renice. A user may only decrease his or her process priority (i.e., to be nice), not increase it. On the other hand, the computer system administrator, or superuser (root) in UNIX, may temporarily increase a process priority. Eventually, however, as the process receives CPU time, it begins again to degrade in priority according to its status and whether it is a kernel versus a user process [5].
In Focus
The scheduler will pick a process to execute by taking into account the following rules: (1) kernel processes run before user processes, (2) short processes run before longer ones, and (3) processes that have waited for a long time run before those that recently ran.
Process priorities can range from 0 to 127, with lower numbers having higher priorities in UNIX. The user process priority is a combination of a value called PUSER maintained for a process, which is initially set to 50 (best ever priority), plus the nice value, plus CPU time used. Based on CPU time used, the process priority number is increased, giving it a lower priority, every 1/100 of a CPU second. Processes with better priority (i.e., < 50) are reserved for system processes such as daemons and user processes performing I/O. As processes go through their life cycles, they may be transitioned in and out of the queue depending on their state and regardless of their priority. In other words, even a high-priority process may be transitioned out of the CPU and back into the queue if it becomes blocked (e.g., waiting for an event to occur).
In Focus
Processes in a zombie state have exited and are waiting to be cleaned up (e.g., deallocation of memory, stack, tables). While in a zombie state, the process cleans up the data structures that have been allocated by it before exiting, although some data structures will be left behind in memory. The parent process must then clean up what remains of the process data structures left in memory. If the parent process terminates before the child does, the UNIX system init process will assume the role of the parent, adopt orphaned children, and do the cleanup work. The init process is a system process that is created at boot time.
10.3.3 The UNIX-Based File System
In most cases, people relate either to files in directories or folders, or data in a database. Whereas in Windows, file elements are managed via a file bitmap scheme, in UNIX, a file can be a container or an executable program. A file has a name and an owner, and permissions are given to others to read, modify, or execute its contents. The routines responsible for creating, protecting, and providing access to files are known collectively as the UNIX file system. The manner in which data are stored on a particular device is called the file structure, which has both a physical and a logical structure. The physical structure of the file determines how bits that represent data are arranged on storage surfaces such as a disk and is largely managed by the hardware controller for a device. The logical structure determines how data are maintained, accessed, and presented to a user, largely managed by a device driver [8].
In Focus
The file system software and device drivers share in the responsibility of maintaining, accessing, and presenting data to users from the software standpoint. The controllers and disk and tape drive hardware share in the responsibility for storing and accessing the information from the hardware standpoint.
UNIX File Management
The smallest addressable unit of data on UNIX is a byte. Because of its size, the byte is not a convenient unit for either the storage of information or its transfer between the main memory of the computer and the disk and tape devices it supports. Instead, bytes are packed into larger units called blocks to form files. The UNIX OS provides for the methods of keeping data, protecting the data, and accessing the information on a per-file basis, but there is no standard record organization and no standard record access method. Instead, the information is stored in the file on a byte-by-byte basis, and record management must be accomplished by user routines and database management systems that are not by the OS.
Because UNIX was created before databases became commonplace, only some rudimentary database functionality was incorporated into the file system architecture. For example, the UNIX system provides the system calls flock and lockf for file and data locking, but user file access programs must manage these system calls. A file may contain program source code, data, compiled and executable code, or other types of information. There are four main types of files, seen in List 10.2.
UNIX File Protections
Files have protections to prevent access by unauthorized users, although the system administrator (superuser) on UNIX may bypass these protections. Note also that whereas Windows has four levels of file protections, the native UNIX file system has only three, as seen in Figure 10.5.
In UNIX-based systems such as Linux, because files can be executable (i.e., a program), processes become associated with a user based on login information and the file ownership given to the file. The user identification number (UID) associated with the login name is compared to that of the file to determine accessibility. In other words, the file protections specify whether a given UID has proper authority to access a file (along with the type of access). The creator of a file or directory is the owner unless the ownership is manually changed with the chown utility.
• Text (ASCII files): Consists of text lines, usually created with an editor.
• Binary Files: Usually fixed-size records, containing any byte values, mostly used by compilers, assemblers, and linkers, for objects and executables.
• Directory Files: A logically hierarchical table of contents that contains a list of names of other files and directory files, along with their associated index numbers called inodes that uniquely identify the files and tell UNIX where the files are found.
• Special Files: Descriptors for devices such as disks, tapes, and monitors (also called terminals or ttys in UNIX).

FIGURE 10.5
UNIX file protections.
A group number is also assigned to the file. This number would be the same for users sharing common information or data, such as members of the same development project, cost center, organization, or division. Thus as indicated, file protections consist of read, write, and execute, and they are specified for a user (owner), a group, or public access. Protections may be set using the chmod command and an octal number, or code, by the owner or superuser. A dash, “-”, in place of a protection letter indicates that the permission to perform that operation is denied. Let’s consider an example, seen in Figure 10.6.
Note that the permissions are shown in octal codes and are displayed r (read), w (write), and x (execute). Execute permissions on program files makes sense; execute on a directory is unique. It refers to allowing others to view the contents of a directory. The fourth bit (to ownership given to the file. The user identification number (UID) associated with the login name is compared to that of the file to determine accessibility. In other words, the file protections specify whether a given UID has proper authority to access a file (along with the type of access). The creator of a file or directory is the owner unless the ownership is manually changed with the chown utility.

FIGURE 10.6
UNIX permission bits.
In UNIX, files and directories are organized in a tree structure. The parent of all directories is called the root directory. The search path determines where the OS looks for files. The “.” refers to the current working directory, whereas refers to its parent directory.
If the flag bit is set to 2, the file may have the group ID (GID) set on execution. This allows a program to access files using the setgid system call. If a file belongs to a different group than the one the process belongs to, and if file protections do not allow group access, the setgid allows access to a file that would normally require superuser privileges. If the flag bit is set to 4, the file may have the user ID (UID) set on execution. This allows a program to access files using the setuid system call. If a file belongs to a different user other than the process, and if file protections do not allow public access, setuid likewise allows a user access that would normally require superuser privileges. All of these permission-setting capabilities in UNIX are convenient for users and administrators, but they are weakly protected, and they are particularly vulnerable to exploits. We will illustrate with a command sequence:
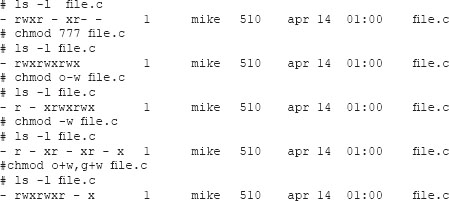
The illustration we presented shows file protections or permissions as r, w, x, or a—if permissions are not granted, for user, group, and the world. By default, the flag bit on files is set to 0 when a file is created, but this can be changed by the superuser to be 1 (sticky bit), 2 (set group id), 4 (set user id), or 7 (set all flags on). As with files, the ls command with the -ld option will list the protections associated with the current working directory. When a user creates a file, the ownership of the file is by default assigned to the user. There are times when it is useful to change the ownership of a file to another user or its permissions. The chmod command is used to change the default protections for a file or directory, and the chown command may be used to change the owner of a file, as seen in the command sequence that follows:
![]()
One way an administrator can implement file protections on some UNIX-based platforms, such as Linux, is to ensure that common files cannot be overwritten or changed. This is done by setting the immutable flag when logged in as superuser. One becomes superuser by logging into the system with the login name “root” or by typing “su” after logging in and supplying the appropriate password. The immutable flag prevents files from being changed, renamed, deleted, or linked to another file. The chattr command is used to set the immutable flag on files, as follows:
![]()
In Focus
It is important to realize from a security standpoint that once someone has superuser (root) access, they may create setuid files that can allow superuser access even after the superuser password has been changed.
Files may have links from one file to another. A link is created using the ln command, and these can be seen by an increase in the link count on the linked file. Linking files makes it possible for users to share a single file without having to copy it or require a reference to the file via the absolute file name. Links can be convenient, but they also present a variety of security risks. Note that there are two types of links: hard links and symbolic links.
Hard links make it possible for a user to remove a link to a file, thus removing the file for him or herself without removing the file altogether, and this is done with the rm command. When the link count becomes 0, the file goes away and the disk space is then unallocated, making the space available for reuse by other files. Symbolic links work similarly but may be established for files or directories on another device or file system. In order to remove a file (remove link) on a file that a user does not own, the user must have “write” privileges. If the user does not own the file but is in the same group as the owner, “write” privileges are required for the group. If the user is not the owner of the file and is not in the same group as the owner, write protection is required for public access. If the user is the owner of the file but does not have write protections, when the user attempts to remove the file, the system will prompt for an override of the protection set on the file.
10.3.4 Disk Memory Management
In memory, among other things, the kernel data structures are allocated to locate data stored on the disk drive, and the file system manager is responsible for the organization of data on disk. It is important that we point out that just as Windows has different file systems (e.g., FAT, NTFS) UNIX also has different file systems. To highlight this, we will contrast the native file systems on BSD UNIX with UNIX System V In both UNIX file systems, data are organized on disk in logically localized regions. This is done in order to reduce searching of the file system for related information. The first block located on disk is called the boot block, and this maintains the necessary information for the system to organize itself when the system comes up, such as how to determine where to find the kernel.
The next logically contiguous segment maintains the block called the super block. Static information about the UNIX file system is stored in the super block, such as disk block size, data fragment size, and disk layout policy—or the physical configuration of the data into their sectors and within concentric circles called cylinders. It is beyond this configuration where there is a departure between the various native file systems on UNIX. Note that the term “native” is used because there are other file systems for UNIX such as the “Andrew” file system, which is more resilient and secure than native UNIX ones.
In Focus
On UNIX-BSD systems, cylinder group maps contain replicated dynamic segments of information such as arrays used in allocation of files and data space. Note, however, that on System V UNIX file systems, the dynamic information is kept only in the super block and is not replicated, making that file system more “fragile.” On BSD systems, cylinder group maps maintain information about logically contiguous segments of information related to a group of files called cylinder groups.
Whether text, binary, directory, or device (special) file, each has a structure called an inode. The inodes are numbered, and they contain important information depending upon the file type. For example, text and data file inodes contain data such as the size of the file, the date it was created, protections, ownership, and pointers to blocks of data held by the file. Directory file inodes include data such as a list of inode numbers and file names located immediately below the directory in the directory tree. The file system maintains information about inodes in the “ilist” (Figure 10.7).
The inodes that are available to be allocated to a file are maintained in a “free inode list.” A small number of addresses of free inodes in the free inode list are cached in a “free inode array” for quick access. On BSD UNIX file systems, the free inode array is kept in the cylinder group maps. On System V UNIX file systems, the free inode array is kept in the super block.
UNIX works with two copies of active inodes. One copy resides on disk, whereas another is kept in memory for efficiency. The inodes in memory are kept in the in-core inode table, and disk copies of inodes are updated from in-core copies. In memory, in-core inodes contain additional chaining pointers (forward and backward), which are not present in the inode copy on disk [5].

FIGURE 10.7
File pointers and ilist structures.
In addition to file type, file protections, and file creation information, the kernel keeps track of pointers to the associated data blocks in various “ilist” data structures (Figure 10.8). As files are created, added to, or deleted, the inodes and data associated with them are relocated from list to list. For increased speed of file access, the most recently used (active) inodes are buffered and hash indexed within kernel memory to prevent having to read the inode table on disk each time the file is accessed. Data blocks are also buffered in memory; thus the lists are constantly in flux, and if the system crashes or is improperly shut down, the inode tables can become corrupted.

FIGURE 10.8
Inode data structures.
An orderly shutdown in UNIX is crucial to flush the buffers and write out all the temporary data to disk. This is referred to as a fragile file system because if the computer is shut down without clearing the buffers first, using the shutdown command, this buffered information will be lost and can cause corruption of the file system. The UNIX fsck program is run to repair the file system. Attackers know this vulnerability, and if they can determine a system is UNIX-based, including Linux, MAC/OS, FreeBSD, they can exploit this by using a denial of service (DoS) attack.
Data blocks are groups of information held by a file. Data are handled in blocks both on disk and in memory for efficiency in dealing with related amounts of information. Each file system has a basic block size, determined by the system manager at the time the file system is created. On BSD file systems, data blocks are generally 4096 bytes and have fragments, usually 1024 bytes. If less than a full block is written to disk, a fragment is written so as not to waste disk space. On System V file systems, there are no fragments; there are only data blocks consisting usually of 1024 bytes. BSD file systems are called “fast file systems” because of this grouping of information into cylinder groups and because of the organization of data blocks and fragments. The fast file system will store fragments of data until it is opportune to copy fragments to full blocks. For this scheme to work efficiently, the disk must retain about 10 percent free space [1, 6].
10.3.5 UNIX System Input–Output (I/O) and Device Drivers
Input–output, or I/O, are all the facilities that pass data bits between devices. For the most part, I/O means sending grouped bits of data from one process and device to another, but the grouped sizes depend on the hardware used. There are two major types of I/O devices in UNIX: block devices and character devices. Block devices are those that can transfer blocks of data rather than bytes, such as disks, USB drives, and tapes. Character-type devices are those that transfer data bytes (character by character) such as printers and monitors (called terminals or ttys in UNIX). The grouping of data for processing is known as buffering or “cooked mode” in UNIX. Buffered I/O in UNIX is queued in a buffer cache in kernel memory rather than on a per-process basis. Data in block buffers are flushed by the kernel every 30 seconds unless the fsync system call is executed, or the sync command is typed at the command line, which queues the memory flush for a convenient (lazy) cycle. Block device buffering is handled using four queues depending on the kinds of data they hold: (1) BQ_locked is used for permanent buffers such as disk super block data, (2) BQ_lru is used for active data such as data blocks related to files that have been opened, (3) BQ_age is used for non-useful data (free data, such as data blocks associated with a deleted file), and (4) BQ_empty is used for buffers available to allocate to processes for temporary storage.
In addition to buffered I/O, both block and character I/O device drivers offer non-buffered I/O, called “raw mode” in UNIX. For raw block I/O, characters bypass the internal buffering mechanisms; with raw character I/O, characters are passed directly from a set of data structures in what is called the raw queue to the input process without any manipulation of the characters. Character I/O also offers a third option called cbreak, or “half-cooked” mode. In the cbreak mode, there are some limited character manipulations possible, which are performed within the device driver itself. That is, in cbreak mode, characters are sent to the process as soon as they are typed with little manipulation except that characters are echoed, and interrupt, parity, and delays are managed by the driver; however, there is no processing of erase, terminate (kill), or end-of-text characters. Character buffers are flushed by a program calling the fflush subroutine on output, or with a new-line character (<return>) on input.
Device files in UNIX are called “special” files, and special files differ depending on how they interact with the OS and their device drivers. One of the unique attributes of the UNIX system is this ability to have devices appear as files causing the file system and the I/O subsystem to overlap significantly. There are many data structures associated with files and I/O. An example is the “open file table” that contains file descriptors of the information needed to access an underlying file object. The file system and I/O subsystem have components partially contained in the user data structures and partially maintained by the kernel, and the data that are passed between processes must be stored while waiting to be processed.
Special files can be seen from the command prompt with the ls command of the /dev directory, but the listing displays special file characteristics. The listing shows leading characters (b or c) that indicate whether the special file is a block or character mode file. Other file attributes are also shown, such as the creation date and the type of device, along with major and minor device numbers. The major device number is an index to a table in the kernel code called the device switch table, used to access the associated device driver for that device. The device switch table is divided into block and character device tables called the bdevsw and cdevsw, respectively.
The minor device number associated with the file is passed into the driver to determine a device type or function. The meaning of the minor device number differs from device to device depending on the type; for example, the minor device number on a UNIX monitor or terminal (called tty) device generally represents a port number, whereas on tape devices, it directs the driver to rewind or not rewind the tape. In other words, the minor device numbers serve as an index or an entry point into the device driver for performing specific actions, such as to get data from a buffer or put data in a queue.
In Focus
In the UNIX file system, there are device files (special files) that designate device types. Files that are raw block devices have names that are preceded with “r”—for example, “rraO.” Special files for cooked block devices are not preceded by an “r”—for example, “raO.” Raw I/O for character devices is set with the raw flag from a command called stty, or using the cbreak option, which is also set using stty.
The entire function of a driver is to get and send data to and from some device. In addition, the driver may check to ensure that the data are good using parity or cyclic redundancy checks. When the computer boots up, the device driver has what is called a probe routine that initializes the devices and announces to the computer’s bus that the devices are ready, including specifying the interrupt level for the device by setting binary bits in what is called an interrupt mask. As data are sent back and forth from devices and processes in the system, all the processes that read and write data make calls to the driver’s “open” function. When all communications have ceased, the last process running makes a call to the driver’s “close” function, which cleans up the queues and signals the I/O process termination [8].
Disk device drivers are responsible for handling I/O between RAM (and also static cache memory) and the disk drive. The driver must determine what data segments (called sectors) are already allocated and what segments are available for storing new data. This process is called a storage allocation policy or strategy. Although logically, strategies for writing data to a disk drive may follow a first fit or a best fit or other type of procedure, on disk the data are written to cylinders (the concentric rings on a disk platter) in groupings according to the amount of data and based on the rotation speed of the disk for reading and writing optimization by the hardware, and this is handled by the disk device driver. The first fit strategy takes a block of data and writes it to the first available location. Although this strategy is quicker than best fit at the initial storage of data, the retrieval of the data is slower than best fit because the data are scattered around the disk. Thus first fit is best at storage time, whereas best fit is faster at retrieval time because the data are more logically contiguous.
Input from monitors (called terminals or ttys in UNIX) uses serial communications. On the computer’s communications circuit board resides a universal receiver-transmitter, or UART. This hardware chip gathers data from and places data into a buffer. These buffers are read and written character by character by the tty device driver. In UNIX, there are two levels of tty driver, the line switch driver and line discipline driver. The driver is also divided into a top half and a bottom half. The line switch driver essentially handles the control of the conversation, and it takes the data and sets the bits for invoking hardware interrupts. The line discipline driver reads and writes the data in and out of the buffer queues. Using the system call ioctl, the line switch driver (linesw) calls the line discipline to set the device controls, such as data transmission rates and parity checking. The ttread and ttwrite and ttinterrupt functions are then used by the driver to coordinate the reading and writing from the various queues.
As we have presented, character mode devices store characters in a queue called the raw queue. When a line of characters is terminated with the <return> key, the device driver copies the raw queue data (handling deletes and escapes) into the canonical queue. The canonical queue is a staging area for data so that the driver can pass “clean” data to a receiving process. On output from a process, the characters are stored in a “Cblock,” which does not need character processing. The Cblock is a block contained in a linked list called the clist. Cblocks are allocated dynamically in the clist as output from a process increases until it can be passed by the device driver to the device (see Workman [8] for examples).
10.4 Microsoft Windows Operating System
By now, we know that Microsoft changes operating system versions frequently, but in spite of their many versions and changes, a major shift occurred when Microsoft hired Dave Cutler away from Digital Equipment Corporation (DEC) to design a version of DEC’s operating system written for their PDP and then later their VAX mini-mainframe systems for a PC, which we now have come to call Windows NT [5]. The Microsoft Windows derivatives such as XP, Vista, and Windows V.7 all stem from this change. As a result, Windows has had to evolve from a PC (MS-DOS) operating system into a commercially capable system akin to the DEC (now HP) mini-mainframe operating system (Open/VMS). Windows, like UNIX, was designed to be a general-purpose computer and network OS. Over the years, it has developed along the Windows NT architecture (for example, witness Windows FAT file system compared to NTFS). The main goal for a general-purpose OS is to make many complex computing tasks easy for the user. It also takes a lot of burden off the application software by coordinating different devices and getting rid of repetitive functions that each software program has to go through. Windows shares many features with the Digital Equipment (now HP) VMS operating system [1], but also offers some of the design features of MAC/Linux/UNIX.
10.4.1 Windows as a Reference Example
Windows was developed to focus on ease-of-use computing for home and small office computer users. It has evolved to provide many network operating systems (NOS) capabilities, so it has become popular for that dual-purpose role. There has been an evolution toward using general-purpose OS, such as Windows, as NOS because of Window’s low-cost, multi-use, multi-threaded, and multi-tasking capabilities (especially beginning with Windows Version 7). Multi-tasking means that a computer can handle several programs at the same time, and multi-threaded multi-tasking takes this concept further by breaking down a program into smaller threads that manage tasks on a finer-grained scale for efficiency.
In Focus
Unlike DEC/HP OpenVMS, which automatically names file versions, UNIX and Windows write over files unless specifically requested otherwise.
The rapid escalation toward dual-purpose systems was fueled by Windows servers, especially with Windows Server 2003 and 2008, given the ability to serve as domain controllers; however, Windows has gradually expanded server capabilities with each new server release. Also, Windows has offered a roaming user profile, which has allowed users to log in from any networked computer in the same Windows environment to display the same desktop and retain the settings saved by the user. Moreover, Windows supports the industry standard TCP/IP protocols including DNS and DHCP, and it has added its own network resource naming and discovery tools such as WINS (Windows Internet Naming Service).
Windows also provides extensive event and account logging facilities, which feeds information into a report-generation program. It supports all levels of redundant array (RAID) disks for backup and restore. Microsoft’s domain architecture has become a convenient way to organize network resources. By using the domain structure, Windows allows users to access one account and have one password to access network resources scattered around in multiple servers. Once a server is set up, we have a choice among primary domain controller, backup domain controller (BDC), and stand-alone server in terms of the server’s role in the network [3].
Let’s quickly survey the Windows architecture, subsystems, and executive managers. At the base layer of the Windows system is the hardware abstraction layer, or HAL. This exports a virtual interface to the rest of the Windows system to enable dynamic software configurations on top of hardware. In other words, it enables software to interact more flexibly with the underlying hardware by hiding the hardware specifics from the software [9].
Examine Figure 10.9. Notice that the executive consists of a group of services that support the subsystems, and it acts as a critical divide between user functions and kernel functions. Integral subsystems support basic OS services through the executive. Key integral subsystems are the security service, the workstation, and server services. Environment subsystems execute in user mode and provide functions through its API. Win32 is the most fundamental of these, providing the interface for operating system services, GUI capabilities, and functions to control the I/O. The login process is handled by the Win32 subsystem called the graphical identification and authentication dynamic-link library (GINA), which creates the initial process and its context for a user, known as the user desktop [2, 10, 11].
In Windows, kernel drivers and the microkernel work as intermediaries for hardware and OS functions. A microkernel is a design approach where only limited system functions are performed by the kernel [8] and most of the OS work is parceled out to subsystems or “managers” [9]. The object manager in Windows intermediates access to system resources. All resources are therefore abstracted as objects. The I/O manager controls the I/O system calls from applications and services in user memory space, intermediating between them and the I/O device drivers. The IPC manager handles the communication between the environment subsystems and servers running in the executive, which consist of all the “privileged” subsystems and managers [7].
The virtual memory manager is similar to the virtual memory manager in the UNIX operating system, enabling the use of disk caches as auxiliary system memory. The process manager handles process and thread creation and termination. The PnP manager handles plug-and-play features (i.e., hardware support) mostly at boot time, or when a new device is added to the system, and the power manager controls power-related events and interrupts, and assists in an orderly system shutdown. The security reference monitor makes access control decisions and manages what parts of processes or threads run in protected kernel mode, and the Windows manager deals with graphical display devices and communications.
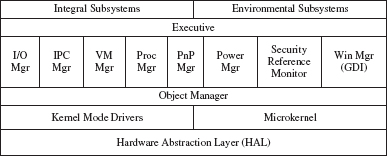
FIGURE 10.9
Windows architecture.
Windows memory management is handled by the virtual memory manager (VMM), which employs a “lazy allocation policy.” This is a method of postponing the allocation of pages and page table entries in memory until they are flushed to disk at a convenient time for the OS.
10.4.2 Windows Microkernel, Memory, and I/O Management
In the UNIX OS (and its derivatives: Linux, FreeBSD, MAC/OS, and others), the kernel plays a significant role in the intermediation of user and system processes. In Windows, however, the kernel plays a more specialized role; hence it is called a microkernel. The Windows microkernel mainly facilitates the transactions between the executive and the subsystems and assumes four primary functions: (1) process/thread scheduling, (2) interrupt and exception handling, (3) low-level processor synchronization for symmetric multiprocessing, and (4) restoration of the system context after a system crash. Like UNIX, the kernel is never preempted or swapped out of memory, and like the UNIX scheduler, the Windows dispatcher manages process and thread queuing for execution by the CPU. Unlike the UNIX “fair” round-robin scheduler, Windows uses a 32-level prioritization, allowing a much greater level of granularity in scheduling [11].
Like UNIX, Windows is a multi-tasking OS. Each process has its own set of code, data, system resources, and state. Resources include virtual address space, files, and synchronization objects through callable application program interfaces (API). These subsystems send messages among processes by passing the messages through the executive where security checking is performed to ensure that subsystem processes do not interfere with each other. As with UNIX, Windows programs are essentially networked in terms of how they communicate, even if they are not passing data over a network. By that, we mean that the OS uses network-style interprocess communications; networking IPC mechanisms are all built into how the OS and processes work together.
A similar technique to the UNIX I/O “signal” implementation is the exception handling mechanism in Windows, which manages events such as the termination of a process by the user. In cases where errors are thrown, such as from an invalid memory access, the OS uses the structured exception handler. In the Windows vernacular, daemon processes are services, which are generally long-running user mode applications that start when the system is booted and continue running across user sessions. In Windows, much of the IPC occurs through an “object model” and as indicated; this is the part of the operating system that is related to the allocation and operation of system resources. In Windows, the term protected indicates processes that run in a separate virtual memory address space from other processes. As with UNIX-based systems, Windows has user and kernel (or supervisor) modes of operation. The user mode includes applications such as those designated Win32, along with protected subsystems.
Also, as with the system-level processes on UNIX, kernel mode processes have special privileges that enable access to protected memory addresses, including those occupied by user processes. The kernel mode of Windows contains the executive as well as the system kernel. The purpose of the executive is to export generic services for protected subsystems to call to obtain OS services such as file operations, I/O, and synchronization services. This partitioning of the protected subsystems and the executive enables the kernel to control how the operating system uses the CPU, performs scheduling and multi-processor synchronization, and exports objects to applications.
In Focus
Windows takes a different approach than UNIX for file I/O. Rather than using linked lists for files and file I/O, Windows uses what is called a cluster map.
In addition to processes, for performance reasons, Windows natively supports lightweight processes or threads, which share some of the data structures with its siblings. Windows also supports even smaller process fragments called fibers, also known as lightweight threads. Fibers are run from a thread and share the same memory and process contexts and data structures. Fibers are usually used in applications that serve a large number of users, such as database systems. Unlike UNIX, Windows processes are not generally formed of parent/child relationships. The process creation passes a type of pointer called a process handle and an identifier to the process it spawns. Thus, the operating system treats processes as peers [9].
In Focus
The Windows master file table (MFT) is compared to the UNIX file system management inode data structures. The MFT stores information about files on a disk including file names, file permissions, and the size of the files (in fixed-size blocks). In Windows, the I/O strategy is determined when the master boot record is read, which reads a configuration file; thus, the disk layout policy is determined by the configuration file read when the computer is booted. The device driver then uses the strategy for appropriately laying down and reading the data, and all this happens in kernel (protected) mode.
10.4.3 Windows Processes and Security Management
As the name implies, the service control manager (SCM) in Windows is responsible for service management. The security context of a process determines the capabilities of the service. Most services run as a local system account that has elevated access rights on the local host but has no privileges on the network domain. If a service needs to access network resources, it must run as a domain user with sufficient privileges to perform the required tasks. As we will discuss in more detail when we get to the chapter on host security, Windows has four main security components: (1) executive or kernel mode, (2) protected servers (user mode), (3) network subsystem (both kernel and user modes), and (4) administrator tools (user mode). Each process has a table of object handles that enable a process to access system resources maintained by the object manager. A handle is software reference to a memory address. Each handle describes the type of access the process has to the object (read, write, etc.).
The object manager ensures that access is only granted if compatible with the handle. When a process requests a resource for the first time, the object manager asks the security reference monitor to decide if the process may acquire a handle to it. Subsequent accesses to the same resource will not involve the security reference monitor because a handle granting the type of access will be already available in the process handle table. Processes are themselves objects in the system. A process essentially contains a handle table containing all objects to which it has access, process virtual, private address space, an associated space in the physical memory, and a list of threads. Because processes are objects in Windows, they can be accessed directly (if a handle to them exists), and each thread has its own execution context, including registers and stack pointers [7].
10.4.4 Microsoft Registry
The Windows Registry is a configuration database that maintains information about applications, users, and hardware on a system (Figure 10.10). The Registry uses registry keys, called HKEY, to denote an entry in the configuration database. There are HKEY entries for each component, listed under a root node such as HKEY_LOCAL_ MACHINE, which is the root of configuration components for a local system. The configuration manager is the part of the executive that is responsible for maintaining the Registry. Software ranging from device drivers to user applications use the Registry for locating executables and coordinating IPC and for keeping track of information such as user preferences. The Registry provides a convenient, centralized store of configuration information, but it is a source of host computer threats, which we will examine later in the chapter on computer security.

FIGURE 10.10
Regeidt view of registry.
In the late 1980s and early 1990s, there were four main CPU competitors: Motorola, Intel, National Semiconductor, and Digital Equipment Corporation. The competitive nature of “micro-processing” eliminated a couple of them [5]. Creating software to operate high-demand operating systems to make these CPUs work properly further complicated matters. (Old timers call this the RISC versus CISC wars). Two variants emerged from the rubble: Windows and UNIX (including strains such as Linux and MAC/OS).
We have now covered operating systems concepts and using UNIX and Windows examples, and we have seen that modern operating systems are layered and modular. UNIX is portable to a variety of hardware platforms, although there are still differences between UNIX versions and various platforms (for example, between MAC/OS, Linux, and Free BSD). Windows, on the other hand, is a single-source OS from Microsoft that runs on a few (mostly Intel or Advanced Microdevices [AMD]) platforms. The trend for operating systems is toward smaller, more specialized “microkernels” such as seen in Windows.
We learned that UNIX and Windows are virtual memory systems. With virtual memory, a partition on the disk drive is set aside for temporary storage of process and thread data structures if RAM becomes full. Processes are divided into memory pages split into text, data, and stack segments. User process (and thread) data structures are maintained separately from kernel data structures. If memory becomes full, the pager/swapper will begin moving pages to the swap partition on disk.
We also learned that the scheduler is responsible for switching runnable processes from the run queue into the CPU for execution. In so doing, the scheduler scans the “proc table” to find runnable processes. If a process is idle (i.e., marked “sleeping”), it is blocked waiting for an event. If a process is a zombie, it has terminated and is waiting to have its data structures cleaned out of memory. These basic functions must be performed (regardless of what they are called) by almost any OS. Now we will turn our attention to networks and networking.
Topic Questions
10.1: What does RISC stand for?
10.2: What does a process scheduler do?
10.3: What does a memory manager do?
10.4: Processes are divided into what two types?
10.5: A device driver controls the devices (disk drives, user interfaces, and other hardware devices) and manages the hardware interaction for the:
___ Computer hardware
___ Operating system
___ Bus controller
___ Main static memory
10.6: A memory manager controls the data structures in memory.
___ True
___ False
10.7: CISC stands for:
___ Complicated InstructionS for Computer
___ Complex Instruction Set Computer
___ Component InStruction Controller
___ Conversion Instructions for Systems Components
10.8: A general OS consists of the following subsystems or functions:
(a) __________
(b) __________
(c) __________
(d) __________
(e) __________
10.9: The object manager ensures that access is only granted if compatible with the handle.
___ True
___ False
10.10: Windows NT was one of the first clean breaks from the MS-DOS past.
___ True
___ False
Questions for Further Study
Q10.1: Why is layering a good approach to operating system design?
Q10.2: How are files allocated and managed in a UNIX system?
Q10.3: What are inodes and data blocks, and how do they relate to each other?
Q10.4: Compare the UNIX inode data structures with the Windows file (bit) map.
Q10.5: Explain how operating systems and host computer security might be related. Give five examples.
A bus is an electronic pathway among devices.
Daemons are processes that operate like processes running in the foreground with the exception that the process identification is reported and the user can continue working.
Device drivers signal the CPU for control of how the device interrupts and data are processed.
File system manager is a component responsible for the organization of data on disk.
Virtual memory allows address space greater than physical space.
References
1. Kenah, L. J., & Bate, S. F. (1984). VAX/VMS internals and data structures. Boston, MA: Digital Press.
2. Harris, J. A. (2002). Operating systems. New York, NY: McGraw-Hill.
3. Elmarsi, R., Carrick, A. G., & Levine, D. (2010). Operating systems: A spiral approach. New York, NY: McGraw-Hill.
4. Gancarz, M. (2003). The Linux and Unix philosophy. Amsterdam, the Netherlands: Elsevier.
5. Workman, M., & Coleman, M. (1990). The Ultrix operating system: Internal OS workings for the DECStart program. Boston, MA: Digital Press.
6. Leffler, S. J., McKusick, M. K., Karels, M. J., & Quarterman, J. S. (1989). The design and implementation of the 4.3BSD UNIX operating system. Reading, MA: Addison-Wesley.
7. Deitel, H. M., Dietel, P. J., & Choffnes, D. R. (2004). Operating systems. Upper Saddle River, NJ: Pearson/Prentice Hall.
8. Workman, M. (1989). The DECStart and the Ultrix operating system: DEC Ultrix and its internal processing. Maynard, MA: Digital Press.
9. Silberschatz, A., Galvin, P. B., & Gagne, G. (2007). Operating systems concepts with JAVA. New York, NY: John Wiley & Sons.
10. de Medeiros, B. (2005). Windows security: A synopsis on host protection, 59, 23–30. Tallahassee: Florida State University Press.
11. Tanenbaum, A. S. (2008). Modern operating systems. Upper Saddle River, NJ: Pearson/Prentice Hall.