In this chapter
| Introduction |
| Jobs |
| The type system |
| Syntax |
| Classes and interfaces |
| Code access security |
| Compiling and running X++ as .NET CIL |
| Design and implementation patterns |
X++ is an object-oriented, application-aware, and data-aware programming language. The language is object oriented because it supports object abstractions, abstraction hierarchies, polymorphism, and encapsulation. It is application aware because it includes keywords such as client, server, changecompany, and display that are useful for writing client/server enterprise resource planning (ERP) applications. And it is data aware because it includes keywords such as firstFast, forceSelectOrder, and forUpdate, as well as a database query syntax, that are useful for programming database applications.
You use the Microsoft Dynamics AX designers and tools to edit the structure of application types. You specify the behavior of application types by writing X++ source code in the X++ editor. The X++ compiler compiles this source code into bytecode intermediate format. Model data, X++ source code, intermediate bytecode, and .NET common intermediate language (CIL) code are stored in the model store.
The Microsoft Dynamics AX runtime dynamically composes object types by loading overridden bytecode from the highest-level definition in the model layering stack. Objects are instantiated from these dynamic types. Similarly, the compiler produces .NET CIL from the X++ source code from the highest layer. For more information about the Microsoft Dynamics AX layering technology, see Chapter 21.
This chapter describes the Microsoft Dynamics AX runtime type system and the features of the X++ language that are essential to writing ERP applications. It will also help you avoid common programming pitfalls that stem from implementing X++. For an in-depth discussion of the type system and the X++ language, refer to the Microsoft Dynamics AX 2012 software development kit (SDK), available on MSDN.
Jobs are globally defined functions that execute in the Windows client run-time environment. Developers frequently use jobs to test a piece of business logic because they are easily executed from within the MorphX development environment, by either pressing F5 or selecting Go on the command menu. However, you shouldn’t use jobs as part of your application’s core design. The examples provided in this chapter can be run as jobs.
Jobs are model elements that you create by using the Application Object Tree (AOT). The following X++ code provides an example of a job model element that prints the string “Hello World” to an automatically generated window. The pause statement stops program execution and waits for user input from a dialog box.
static void myJob(Args _args)
{
print "Hello World";
pause;
}The Microsoft Dynamics AX runtime manages the storage of value type data on the call stack and reference type objects on the memory heap. The call stack is the memory structure that holds data about the active methods called during program execution. The memory heap is the memory area that allocates storage for objects that are destroyed automatically by the Microsoft Dynamics AX runtime.
Value types include the built-in primitive types, extended data types, enumeration types, and built-in collection types:
The primitive types are boolean, int, int64, real, date, utcDateTime, timeofday, str, and guid.
The extended data types are specialized primitive types and specialized base enumerations.
The enumeration types are base enumerations and extended data types.
The collection types are the built-in array and container types.
By default, variables declared as value types are assigned their zero value by the Microsoft Dynamics AX runtime. These variables can’t be set to null. Variable values are copied when variables are used to invoke methods and when they are used in assignment statements. Therefore, two value type variables can’t reference the same value.
Reference types include the record types, class types, and interface types:
The record types are table, map, and view. User-defined record types are dynamically composed from application model layers. Microsoft Dynamics AX runtime record types are exposed in the system application programming interface (API).
User-defined class types are dynamically composed from application model layers and Microsoft Dynamics AX runtime class types exposed in the system API.
Interface types are type specifications and can’t be instantiated in the Microsoft Dynamics AX runtime. Class types can, however, implement interfaces.
Variables declared as reference types contain references to objects that the Microsoft Dynamics AX runtime instantiates from dynamically composed types defined in the application model layering system and from types exposed in the system API. The Microsoft Dynamics AX runtime also performs memory deallocation (garbage collection) for these objects when they are no longer referenced. Reference variables declared as record types reference objects that the Microsoft Dynamics AX runtime instantiates automatically. Class type objects are programmatically instantiated using the new operator. Copies of object references are passed as reference parameters in method calls and are assigned to reference variables, so two variables can reference the same object.
Note
More Info Not all nodes in the AOT name a type declaration. Some class declarations are merely syntactic sugar—convenient, human-readable expressions. For example, the class header definition for all rich client forms declares a FormRun class type. FormRun is also, however, a class type in the system API. Allowing this declaration is syntactic sugar because it is technically impossible for two types to have the same name in the Microsoft Dynamics AX class type hierarchy.
The X++ language supports the definition of type hierarchies that specify generalized and specialized relationships between class types and table types. For example, a check payment method is a type of payment method. A type hierarchy allows code reuse. Reusable code is defined on base types defined higher in a type hierarchy because they are inherited, or reused, by derived types defined lower in a type hierarchy.
Tip
You can use the Type Hierarchy Context and Type Hierarchy Browser tools in MorphX to visualize, browse, and search the hierarchy of any type.
The following sections introduce the base types provided by the Microsoft Dynamics AX runtime and describe how they are extended in type hierarchies.
Caution
The Microsoft Dynamics AX type system is known as a weak type system because X++ accepts certain type assignments that are clearly erroneous and lead to runtime errors. Be aware of the caveats outlined in the following sections, and try to avoid weak type constructs when writing X++ code.
The Microsoft Dynamics AX type system doesn’t have a single base type from which all types ultimately derive. However, the anytype type imitates a base type for all types. Variables of the anytype type function like value types when they are assigned a value type variable and like reference types when they are assigned a reference type variable. You can use the SysAnyType class to explicitly box all types, including value types, and make them function like reference types.
The anytype type, shown in the following code sample, is syntactic sugar that allows methods to accept any type as a parameter or allows a method to return different types:
static str queryRange(anytype _from, anytype _to)
{
return SysQuery::range(_from,_to);
}You can declare variables by using anytype. However, the underlying data type of an anytype variable is set to match the first assignment, and you can’t change its type afterward, as shown here:
anytype a = 1;
print strfmt("%1 = %2", typeof(a), a); //Integer = 1
a = "text";
print strfmt("%1 = %2", typeof(a), a); //Integer = 0The common type is the base type of all record types. Like the anytype type, record types are context-dependent types whose variables can be used as though they reference single records or as a record cursor that can iterate over a set of database records.
By using the common type, you can cast one record type to another (possibly incompatible) record type, as shown in this example:
//customer = vendor; //Compile error common = customer; vendor = common; //Accepted
Tables in Microsoft Dynamics AX also support inheritance and polymorphism. This capability offers a type-safe method of sharing commonalities such as methods and fields between tables. It is possible to override table methods but not table fields. A base table can be marked as abstract or final through the table’s properties.
Table maps defined in the AOT are a type-safe method of capturing commonalities between record types across type hierarchies, and you should use them to prevent incompatible record assignments. A table map defines fields and methods that safely operate on one or more record types.
The compiler doesn’t validate method calls on the common type. For example, the compiler accepts the following method invocation, even though the method doesn’t exist:
common.nonExistingMethod();
For this reason, you should use reflection to confirm that the method on the common type exists before you invoke it, as shown in this example. For more information, see Chapter 20.
if (tableHasMethod(new DictTable(common.tableId), identifierStr(existingMethod)))
{
common.existingMethod();
}The built-in object type is a weak reference type whose variables reference objects that are instances of class or interface types in the Microsoft Dynamics AX class hierarchy.
The type system allows you to implicitly cast base type objects to derived type objects and to cast derived type objects to base type objects, as shown here:
baseClass = derivedClass; derivedClass = baseClass;
The object type allows you to use the assignment operator and cast one class type to another, incompatible class type, as shown in the following code. The probable result of this action, however, is a run-time exception when your code encounters an object of an unexpected type.
Object myObject; //myBinaryIO = myTextIO; //Compile error myObject = myTextIO; mybinaryIO = myObject; //Accepted
Use the is and as operators instead of the assignment operator to prevent these incompatible type casts. The is operator determines if an instance is of a particular type, and the as operator casts an instance as a particular type, or null if they are not compatible. The is and as operators work on class and table types.
myTextIO = myObject as TextIO;
if (myBinaryIO is TextIO)
{
}You can use the object type for late binding to methods, similar to the dynamic keyword in C#. Keep in mind that a run-time error will occur if the method invoked doesn’t exist.
myObject.lateBoundMethod();
You use the AOT to create extended data types that model concrete data values and data hierarchies. For example, the Name extended data type is a string, and the CustName and VendName extended data types extend the Name data type.
The X++ language supports extended data types but doesn’t offer type checking according to the hierarchy of extended data types. X++ treats any extended data type as its primitive type; therefore, code such as the following is allowed:
CustName customerName; FileName fileName = customerName;
When used properly, extended data types improve the readability of X++ code. It’s easier to understand the intended use of a CustName data type than a string data type, even if both are used to declare string variables.
Extended data types are more than just type definitions that make X++ code more readable. On each extended data type, you can also specify how the system displays values of this type to users. Further, you can specify a reference to a table. The reference enables the form’s rendering engine to automatically build lookup forms for form controls by using the extended data type, even when the form controls are not bound to a data source. On string-based extended data types, you can specify the maximum string size of the type. The database layer uses the string size to define the underlying columns for fields that use the extended data type. Defining the string size in only one place makes it easy to change.
The X++ language belongs to the “curly brace” family of programming languages (those that use curly braces to delimit syntax blocks), such as C, C++, C#, and Java. If you’re familiar with any of these languages, you won’t have a problem reading and understanding X++ syntax.
Unlike many programming languages, X++ is not case sensitive. However, using camel casing (camelCasing) for variable names and Pascal casing (PascalCasing) for type names is considered a best practice. (More best practices for writing X++ code are available in the Microsoft Dynamics AX 2012 SDK.) You can use the Source Code Titlecase Update tool (accessed from the Add-Ins submenu in the AOT) to automatically apply casing in X++ code to match the best practice recommendation.
Common language runtime (CLR) types, which are case sensitive, are one important exception to the casing guidelines. For information about how to use CLR types, see the CLR interoperability section later in this chapter.
You must place variable declarations at the beginning of methods. Table 4-1 provides examples of value type and reference type variable declarations, in addition to example variable initializations. Parameter declaration examples are provided in the Classes and interfaces section later in this chapter.
Table 4-1. X++ variable declaration examples.
Note
String literals can be expressed using either single or double quotes. It is considered best practice to use single quotes for system strings, like file names, and double quotes for user interface strings. The examples in this chapter adhere to this guideline.
Declaring variables with the same name as their type is a best practice. At first glance, this approach might seem confusing. Consider this class and its getter/setter method to its field:
Class Person
{
Name name;
public Name Name(Name _name = name)
{
name = _name;
return name;
}
}Because X++ is not case sensitive, the word name is used in eight places in the preceding code. Three refer to the extended data type, four refer to the field, and one refers to the method (_name is used twice). To improve readability, you could rename the variable to something more specific, such as personName. However, using a more specific variable name implies that a more specific type should be used (and created if it doesn’t already exist). Changing both the type name and the variable name to PersonName wouldn’t improve readability. The benefit of this practice is that if you know the name of a variable, you also know its type.
Note
Previous versions of Microsoft Dynamics AX required a dangling semicolon to signify the end of a variable declaration. This is no longer required because the compiler solves the ambiguity by reading one token ahead, except where the first statement is a static CLR call. The compiler still accepts the now-superfluous semicolons, but you can remove them if you want to.
X++ expressions are sequences of operators, operands, values, and variables that yield a result. Table 4-2 summarizes the types of expressions allowed in X++ and includes examples of their use.
Table 4-2. X++ expression examples.
X++ statements specify object state and object behavior. Table 4-3 provides examples of X++ language statements that are commonly found in many programming languages. In-depth descriptions of each statement are beyond the scope of this book.
Table 4-3. X++ statement examples.
The X++ language has built-in support for querying and manipulating database data. The syntax for database statements is similar to Structured Query Language (SQL), and this section assumes that you’re familiar with SQL. The following code shows how a select statement is used to return only the first selected record from the MyTable database table and how the data in the record’s myField field is printed:
static void myJob(Args _args)
{
MyTable myTable;
select firstOnly * from myTable where myTable.myField1 == "value";
print myTable.myField2;
pause;
}The “* from” part of the select statement in the example is optional. You can replace the asterisk (*) character with a comma-separated field list, such as myField2, myField3. You must define all fields, however, on the selection table model element, and only one selection table is allowed immediately after the from keyword. The where expression in the select statement can include any number of logical and relational operators. The firstOnly keyword is optional and can be replaced by one or more of the optional keywords. Table 4-4 describes all possible keywords. For more information about database-related keywords, see Chapter 17.
Table 4-4. Keyword options for select statements.
The following code example demonstrates how to use a table index clause to suggest the index that a database server should use when querying tables. The Microsoft Dynamics AX runtime appends an order by clause and the index fields to the first select statement’s database query. Records are thus ordered by the index. The Microsoft Dynamics AX runtime can insert a query hint into the second select statement’s database query, if the hint is feasible to use.
static void myJob(Args _args)
{
MyTable1 myTable1;
MyTable2 myTable2;
while select myTable1
index myIndex1
{
print myTable1.myField2;
}
while select myTable2
index hint myIndex2
{
print myTable2.myField2;
}
pause;
}The following code example demonstrates how the results from a select query can be ordered and grouped. The first select statement specifies that the resulting records must be sorted in ascending order based on myField1 values and then in descending order based on myField2 values. The second select statement specifies that the resulting records must be grouped by myField1 values and then sorted in descending order.
static void myJob(Args _args)
{
MyTable myTable;
while select myTable
order by Field1 asc, Field2 desc
{
print myTable.myField;
}
while select myTable
group by Field1 desc
{
print myTable.Field1;
}
pause;
}The following code demonstrates use of the avg and count aggregate functions in select statements. The first select statement averages the values in the myField column and assigns the result to the myField field. The second select statement counts the number of records the selection returns and assigns the result to the myField field.
static void myJob(Args _args)
{
MyTable myTable;
select avg(myField) from myTable;
print myTable.myField;
select count(myField) from myTable;
print myTable.myField;
pause;
}Caution
The compiler doesn’t verify that aggregate function parameter types are numeric, so the result that the function returns could be assigned to a field of type string. The result will be truncated if, for example, the average function calculates a value of 1.5 and the type of myField is an integer.
Table 4-5 Describes the aggregate functions supported in X++ select statements.
Table 4-5. Aggregate functions in X++ select statements.
Description | |
|---|---|
avg | Returns the average of the non-null field values in the records the selection returns. |
count | Returns the number of non-null field values in the records the selection returns. |
Returns the maximum of the non-null field values in the records the selection returns. | |
Returns the minimum of the non-null field values in the records the selection returns. | |
Returns the sum of the non-null field values in the records the selection returns. |
The following code example demonstrates how tables are joined with join conditions. The first select statement joins two tables by using an equality join condition between fields in the tables. The second select statement joins three tables to illustrate how you can nest join conditions and use an exists operator as an existence test with a join condition. The second select statement also demonstrates how you can use a group by sort in join conditions. In fact, the join condition can comprise multiple nested join conditions because the syntax of the join condition is the same as the body of a select statement.
static void myJob(Args _args)
{
MyTable1 myTable1;
MyTable2 myTable2;
MyTable3 myTable3;
select myField from myTable1
join myTable2
where myTable1.myField1=myTable2.myField1;
print myTable1.myField;
select myField from myTable1
join myTable2
group by myTable2.myField1
where myTable1.myField1=myTable2.myField1
exists join myTable3
where myTable1.myField1=myTable3.mField2;
print myTable1.myField;
pause;
}Table 4-6 describes the exists operator and the other join operators that can be used in place of the exists operator in the preceding example.
Table 4-6. Join operators.
Operator | Description |
|---|---|
exists | Returns true if any records are in the result set after executing the join clause. Returns false otherwise. |
notExists | Returns false if any records are in the result set after executing the join clause. Returns true otherwise. |
Returns the left outer join of the first and second tables. |
The following example demonstrates use of the while select statement that increments the myTable variable’s record cursor on each loop:
static void myJob(Args _args)
{
MyTable myTable;
while select myTable
{
Print myTable.myField;
}
}You must use the ttsBegin, ttsCommit, and ttsAbort transaction statements to modify records in tables and to insert records into tables. The ttsBegin statement marks the beginning of a database transaction block; ttsBegin-ttsCommit transaction blocks can be nested. The ttsBegin statements increment the transaction level; the ttsCommit statements decrement the transaction level. The outermost block decrements the transaction level to zero and commits all database inserts and updates performed since the first ttsBegin statement to the database. The ttsAbort statement rolls back all database inserts, updates, and deletions performed since the ttsBegin statement. Table 4-7 provides examples of these transaction statements for single records and operations and for set-based (multiple-record) operations.
The last example in Table 4-7 demonstrates the method RowCount. Its purpose is to get the count of records that are affected by set-based operations; namely, insert_recordset, update_recordset, and delete_from.
By using RowCount, it is possible to save one round-trip to the database in certain application scenarios; for example, when implementing insert-or-update logic.
Table 4-7. Transaction statement examples.
It is a best practice to use the X++ exception handling framework instead of programmatically halting a transaction by using the ttsAbort statement. An exception (other than the update conflict and duplicate key exceptions) thrown inside a transaction block halts execution of the block, and all of the inserts and updates performed since the first ttsBegin statement are rolled back. Throwing an exception has the additional advantage of providing a way to recover object state and maintain the consistency of database transactions. Inside the catch block, you can use the retry statement to run the try block again. The following example demonstrates throwing an exception inside a database transaction block:
static void myJob(Args _args)
{
MyTable myTable;
boolean state = false;
try
{
ttsBegin;
update_recordset myTable setting
myField = "value"
where myTable.id == "001";
if(state==false)
{
throw error("Error text");
}
ttsCommit;
}
catch(Exception::Error)
{
state = true;
retry;
}
}The throw statement throws an exception that causes the database transaction to halt and roll back. Code execution can’t continue inside the scope of the transaction, so the runtime ignores try and catch statements when inside a transaction. This means that an exception thrown inside a transaction can be caught only outside the transaction, as shown here:
static void myJob(Args _args)
{
try
{
ttsBegin;
try
{
...
throw error("Error text");
}
catch //Will never catch anything
{
}
ttsCommit;
}
catch(Exception::Error)
{
print "Got it";
pause;
}
catch
{
print "Unhandled Exception";
pause;
}
}Although a throw statement takes the exception enumeration as a parameter, using the error method to throw errors is considered best practice. The try statement’s catch list can contain more than one catch block. The first catch block in the example catches error exceptions. The retry statement jumps to the first statement in the outer try block. The second catch block catches all exceptions not caught by catch blocks earlier in the try statement’s catch list. Table 4-8 describes the Microsoft Dynamics AX system Exception data type enumerations that can be used in try-catch statements.
Table 4-8. Exception data type enumerations.
Element | Description |
|---|---|
Thrown when a user presses the Break key or Ctrl+C. | |
Thrown when an unrecoverable error occurs in a CLR process. | |
Thrown when an unrecoverable error occurs in the demand method of a CodeAccessPermission object. | |
Thrown when an error occurs in the use of a Dynamic Data Exchange (DDE) system class. | |
Thrown when a duplicate key error occurs during an insert operation. The catch block should change the value of the primary keys and use a retry statement to attempt to commit the halted transaction. | |
DuplicateKeyExceptionNotRecovered | Thrown when an unrecoverable duplicate key error occurs during an insert operation. The catch block shouldn’t use a retry statement to attempt to commit the halted transaction. |
Error[a] | Thrown when an unrecoverable application error occurs. A catch block should assume that all database transactions in a transaction block have been halted and rolled back. |
Thrown when an unrecoverable internal error occurs. | |
Thrown when a mathematical error occurs like division by zero, logarithm of a negative number, or conversion between incompatible types. | |
Thrown when an attempt is made to pass a CLR object from the client to the server tier or vice versa. The Microsoft Dynamics AX runtime doesn’t support automatic marshaling of CLR objects across tiers. | |
Thrown by the Microsoft Dynamics AX kernel if a database error or database operation error occurs. | |
Timeout | Thrown when a database operation times out. |
Thrown when an update conflict error occurs in a transaction block using optimistic concurrency control. The catch block should use a retry statement to attempt to commit the halted transaction. | |
Thrown when an unrecoverable error occurs in a transaction block using optimistic concurrency control. The catch block shouldn’t use a retry statement to attempt to commit the halted transaction. | |
[a] The error method is a static method of the global X++ class for which the X++ compiler allows an abbreviated syntax. The expression Global::error(“Error text”) is equivalent to the error expression in the code examples earlier in this section. Don’t confuse these global X++ methods with Microsoft Dynamics AX system API methods, such as newGuid. | |
UpdateConflict and DuplicateKeyException are the only data exceptions that a Microsoft Dynamics AX application can handle inside a transaction. Specifically, with DuplicateKeyException, the database transaction isn’t rolled back, and the application is given a chance to recover. DuplicateKeyException facilitates application scenarios (such as Master Planning) that perform batch processing and handles duplicate key exceptions without aborting the transaction in the midst of the resource-intensive processing operation.
The following example illustrates the usage of DuplicateKeyException:
static void DuplicateKeyExceptionExample(Args _args)
{
MyTable myTable;
ttsBegin;
myTable.Name = "Microsoft Dynamics AX";
myTable.insert();
ttsCommit;
ttsBegin;
try
{
myTable.Name = "Microsoft Dynamics AX";
myTable.insert();
}
catch(Exception::DuplicateKeyException)
{
info(strfmt("Transaction level: %1", appl.ttsLevel()));
info(strfmt("%1 already exists.", myTable.Name));
info(strfmt("Continuing insertion of other records"));
}
ttsCommit;
}In the preceding example, the catch block handles the duplicate key exception. Notice that the transaction level is still 1, indicating that the transaction hasn’t aborted and the application can continue processing other records.
The X++ language includes statements that allow interoperability (interop) with .NET CLR assemblies and COM components. The Microsoft Dynamics AX runtime achieves this interoperability by providing Dynamics AX object wrappers around external objects and by dispatching method calls from the Microsoft Dynamics AX object to the wrapped object.
You can write X++ statements for CLR interoperability by using one of two methods: strong typing or weak typing. Strong typing is recommended because it is type safe and less error prone than weak typing, and it results in code that is easier to read. The MorphX X++ editor also provides IntelliSense as you type.
The examples in this section use the .NET System.Xml assembly, which is added as an AOT references node. (See Chapter 1, for a description of programming model elements.) The programs are somewhat verbose because the compiler doesn’t support method invocations on CLR return types and because CLR types must be identified by their fully qualified name. For example, the expression System.Xml.XmlDocument is the fully qualified type name for the .NET Framework XML document type.
The following example demonstrates strongly typed CLR interoperability with implicit type conversions from Microsoft Dynamics AX strings to CLR strings in the string assignment statements and shows how CLR exceptions are caught in X++:
static void myJob(Args _args)
{
System.Xml.XmlDocument doc = new System.Xml.XmlDocument();
System.Xml.XmlElement rootElement;
System.Xml.XmlElement headElement;
System.Xml.XmlElement docElement;
System.String xml;
System.String docStr = 'Document';
System.String headStr = 'Head';
System.Exception ex;
str errorMessage;
try
{
rootElement = doc.CreateElement(docStr);
doc.AppendChild(rootElement);
headElement = doc.CreateElement(headStr);
docElement = doc.get_DocumentElement();
docElement.AppendChild(headElement);
xml = doc.get_OuterXml();
print ClrInterop::getAnyTypeForObject(xml);
pause;
}
catch(Exception::CLRError)
{
ex = ClrInterop::getLastException();
if( ex )
{
errorMessage = ex.get_Message();
info( errorMessage );
}
}
}The following example illustrates how static CLR methods are invoked by using the X++ static method accessor ::.
static void myJob(Args _args)
{
System.Guid g = System.Guid::NewGuid();
}The following example illustrates the support for CLR arrays:
static void myJob(Args _args)
{
System.Int32 [] myArray = new System.Int32[100]();
myArray.SetValue(1000, 0);
print myArray.GetValue(0);
}X++ supports passing parameters by reference to CLR methods. Changes that the called method makes to the parameter also change the caller variable’s value. When non-object type variables are passed by reference, they are wrapped temporarily in an object. This operation is often called boxing and is illustrated in the following example:
static void myJob(Args _args)
{
int myVar = 5;
MyNamespace.MyMath::Increment(byref myVar);
print myVar; // prints 6
}The called method could be implemented in C# like this:
// Notice: This example is C# code
static public void Increment(ref int value)
{
value++;
}The second method of writing X++ statements for CLR uses weak typing. The following example shows CLR types that perform the same steps as in the first CLR interoperability example. In this case, however, all references are validated at run time, and all type conversions are explicit.
static void myJob(Args _args)
{
ClrObject doc = new ClrObject('System.Xml.XmlDocument'),
ClrObject docStr;
ClrObject rootElement;
ClrObject headElement;
ClrObject docElement;
ClrObject xml;
docStr = ClrInterop::getObjectForAnyType('Document'),
rootElement = doc.CreateElement(docStr);
doc.AppendChild(rootElement);
headElement = doc.CreateElement('Head'),
docElement = doc.get_DocumentElement();
docElement.AppendChild(headElement);
xml = doc.get_OuterXml();
print ClrInterop::getAnyTypeForObject(xml);
pause;
}The first statement in the preceding example demonstrates the use of a static method to convert X++ primitive types to CLR objects. The print statement shows the reverse, converting CLR value types to X++ primitive types. Table 4-9 lists the value type conversions that Microsoft Dynamics AX supports.
Table 4-9. Type conversions supported in Microsoft Dynamics AX.
CLR Type | Microsoft Dynamics AX Type |
|---|---|
Byte, SByte, Int16, UInt16, Int32 | int |
Byte, SByte, Int16, UInt16, Int32, Uint32, Int64 | int64 |
DateTime | utcDateTime |
Double, Single | real |
Guid | guid |
String | str |
Microsoft Dynamics AX Type | CLR Type |
int | Int32, Int64 |
int64 | Int64 |
utcDateTime | DateTime |
real | Single, Double |
guid | Guid |
str | String |
The preceding code example also demonstrates the X++ method syntax used to access CLR object properties, such as get_DocumentElement. The CLR supports several operators that are not supported in X++. Table 4-10 lists the supported CLR operators and the alternative method syntax.
The following features of CLR can’t be used with X++:
Public fields (can be accessed by using CLR reflection classes)
Events and delegates
Generics
Inner types
Namespace declarations
The following code example demonstrates COM interoperability with the XML document type in the Microsoft XML Core Services (MSXML) 6.0 COM component. The example assumes that you’ve installed MSXML. The MSXML document is first instantiated and wrapped in a Microsoft Dynamics AX COM object wrapper. A COM variant wrapper is created for a COM string. The direction of the variant is put into the COM component. The root element and head element variables are declared as COM objects. The example shows how to fill a string variant with an X++ string and then use the variant as an argument to a COM method, loadXml. The statement that creates the head element demonstrates how the Microsoft Dynamics AX runtime automatically converts Microsoft Dynamics AX primitive objects into COM variants.
static void Job2(Args _args)
{
COM doc = new COM('Msxml2.DomDocument.6.0'),
COMVariant rootXml =
new COMVariant(COMVariantInOut::In,COMVariantType::VT_BSTR);
COM rootElement;
COM headElement;
rootXml.bStr('<Root></Root>'),
doc.loadXml(rootXml);
rootElement = doc.documentElement();
headElement = doc.createElement('Head'),
rootElement.appendChild(headElement);
print doc.xml();
pause;
}With the macro capabilities in X++, you can define and use constants and perform conditional compilation. Macros are unstructured because they are not defined in the X++ syntax. Macros are handled before the source code is compiled. You can add macros anywhere you write source code: in methods and in class declarations.
Table 4-11 shows the supported macro directives.
Table 4-11. Macro directives.
The following example shows a macro definition and reference:
void myMethod()
{
#define.HelloWorld("Hello World")
print #HelloWorld;
pause;
}As noted in Table 4-11, a macro library is created under the Macros node in the AOT. The library is included in a class declaration header or class method, as shown in the following example:
class myClass
{
#MyMacroLibrary1
}
public void myMethod()
{
#MyMacroLibrary2
#MacroFromMyMacroLibrary1
#MacroFromMyMacroLibrary2
}A macro can also use parameters. The compiler inserts the parameters at the positions of the placeholders. The following example shows a local macro using parameters:
void myMethod()
{
#localmacro.add
%1 + %2
#endmacro
print #add(1, 2);
print #add("Hello", "World");
pause;
}When a macro library is included or a macro is defined in the class declaration of a class, the macro can be used in the class and in all classes derived from the class. A subclass can redefine the macro.
X++ allows single-line and multiple-line comments. Single-line comments start with // and end at the end of the line. Multiple-line comments start with /* and end with */. You can’t nest multiple-line comments.
You can add reminders to yourself in comments that the compiler picks up and presents to you as tasks in its output window. To set up these tasks, start a comment with the word TODO. Be aware that tasks not occurring at the start of the comment, (for example, tasks that are deep inside multiple-line comments,) are ignored by the compiler.
The following code example contains comments reminding the developer to add a new procedure while removing an existing procedure by changing it into a comment:
public void myMethod()
{
//Declare variables
int value;
//TODO Validate if calculation is really required
/*
//Perform calculation
value = this.calc();
*/
...
}You can document XML methods and classes directly in X++ by typing three slash characters (///) followed by structured documentation in XML format. The XML documentation must be above the actual code.
The XML documentation must align with the code. The Best Practices tool contains a set of rules that can validate the XML documentation. Table 4-12 lists the supported tags.
Table 4-12. XML tags supported for XML documentation.
Tag | Description |
|---|---|
<summary> | Describes a method or a class |
<param> | Describes the parameters of a method |
<returns> | Describes the return value of a method |
<remarks> | Adds information that supplements the information provided in the <summary> tag |
<exception> | Documents exceptions that are thrown by a method |
<permission> | Describes the permission needed to access methods using CodeAccessSecurity.demand |
<seealso> | Lists references to related and relevant documentation |
The XML documentation is automatically displayed in the IntelliSense in the X++ editor.
You can extract the written XML documentation for an AOT project by using the Add-Ins menu option Extract XML Documentation. One XML file is produced that contains all of the documentation for the elements inside the project. You can also use this XML file to publish the documentation.
The following code example shows XML documentation for a static method on the Global class:
/// <summary>
/// Converts an X++ utcDateTime value to a .NET System.DateTime object.
/// </summary>
/// <param name="_utcDateTime">
/// The X++ utcDateTime to convert.
/// </param>
/// <returns>
/// A .NET System.DateTime object.
/// </returns>
static client server anytype utcDateTime2SystemDateTime(utcDateTime _utcDateTime)
{
return CLRInterop::getObjectForAnyType(_utcDateTime);
}You define types and their structure in the AOT, not in the X++ language. Other programming languages that support type declarations do so within code, but Microsoft Dynamics AX supports an object layering feature that accepts X++ source code customizations to type declaration parts that encompass variable declarations and method declarations. Each part of a type declaration is managed as a separate compilation unit, and model data is used to manage, persist, and reconstitute dynamic types whose parts can include compilation units from many object layers.
You use X++ to define logic, including method profiles (return value, method name, and parameter type and name). You use the X++ editor to add new methods to the AOT, so you can construct types without leaving the X++ editor.
You use X++ class declarations to declare protected instance variable fields that are members of application logic and framework reference types. You can’t declare private or public variable fields. You can declare classes as abstract if they are incomplete type specifications that can’t be instantiated. You can also declare them final if they are complete specifications that can’t be further specialized. The following code provides an example of an abstract class declaration header:
abstract class MyClass
{
}You can also structure classes into single-inheritance generalization or specialization hierarchies in which derived classes inherit and override members of base classes. The following code shows an example of a derived class declaration header that specifies that MyDerivedClass extends the abstract base class MyClass. It also specifies that MyDerivedClass is final and can’t be further specialized by another class. Because X++ doesn’t support multiple inheritance, derived classes can extend only one base class.
final class MyDerivedClass extends MyClass
{
}X++ also supports interface type specifications that specify method signatures but don’t define their implementation. Classes can implement more than one interface, but the class and its derived classes should together provide definitions for the methods declared in all the interfaces. If it fails to provide the method definitions, the class itself is treated as abstract and cannot be instantiated. The following code provides an example of an interface declaration header and a class declaration header that implements the interface:
interface MyInterface
{
void myMethod()
{
}
}
class MyClass implements MyInterface
{
void myMethod()
{
}
}A field is a class member that represents a variable and its type. Fields are declared in class declaration headers; each class and interface has a definition part with the name classDeclaration in the AOT. Fields are accessible only to code statements that are part of the class declaration or derived class declarations. Assignment statements are not allowed in class declaration headers. The following example demonstrates how variables are initialized with assignment statements in a new method:
class MyClass
{
str s;
int i;
MyClass1 myClass1;
public void new()
{
i = 0;
myClass1 = new MyClass1();
}
}A method on a class is a member that uses statements to define the behavior of an object. An interface method is a member that declares an expected behavior of an object. The following code provides an example of a method declaration on an interface and an implementation of the method on a class that implements the interface:
interface MyInterface
{
public str myMethod()
{
}
}
class MyClass implements MyInterface
{
public str myMethod();
{
return "Hello World";
}
}Methods are defined with public, private, or protected access modifiers. If an access modifier is omitted, the method is publicly accessible. The X++ template for new methods provides the private access specifier. Table 4-13 describes additional method modifiers supported by X++.
Table 4-13. Method modifiers supported by X++.
Method parameters can have default values that are used when parameters are omitted from method invocations. The following code sample prints “Hello World” when myMethod is invoked with no parameters:
public void myMethod(str s = "Hello World")
{
print s;
pause;
}
public void run()
{
this.myMethod();
}A constructor is a special instance method that is invoked to initialize an object when the new operator is executed by the Microsoft Dynamics AX runtime. You can’t call constructors directly from X++ code. The sample on the next page provides an example of a class declaration header and an instance constructor method that takes one parameter as an argument.
class MyClass
{
int i;
public void new(int _i)
{
i = _i;
}
}The purpose of delegates is to expose extension points where add-ons and customizations can extend the application in a lightweight manner without injecting logic into the base functionality. Delegates are methods without any implementation. Delegates are always protected and cannot have a return value. You declare a delegate using the delegate keyword. You invoke a delegate using the same syntax as a standard method invocation:
class MyClass
{
delegate void myDelegate(int _i)
{
}
private void myMethod()
{
this.myDelegate(42);
}
}When a delegate is invoked, the runtime automatically invokes all event handlers that subscribe to the delegate. There are two ways of subscribing to delegates: declaratively and dynamically. The runtime does not define the sequence in which event handlers are invoked. If your logic relies on an invocation sequence, you should use mechanisms other than delegates and event handlers.
To subscribe declaratively, right-click a delegate in the AOT and then select New Event Handler Subscription. On the resulting event handler node in the AOT, you can specify the class and the static method that will be invoked. The class can be either an X++ class or a .NET class.
To subscribe dynamically, you use the keyword eventhandler. Notice that when subscribing dynamically, the event handler is an instance method. It is also possible to unsubscribe.
class MyEventHandlerClass
{
public void myEventHandler(int _i)
{
...
}
public static void myStaticEventHandler(int _i)
{
...
}
public static void main(Args args)
{
MyClass myClass = new MyClass();
MyEventHandlerClass myEventHandlerClass = new MyEventHandlerClass();
//Subscribe
myClass.myDelegate += eventhandler(myEventHandlerClass.myEventHandler);
myClass.myDelegate +=
eventhandler(MyEventHandlerClass::myStaticEventHandler);
//Unsubscribe
myClass.myDelegate -= eventhandler(myEventHandlerClass.myEventHandler);
myClass.myDelegate -=
eventhandler(MyEventHandlerClass::myStaticEventHandler);
}
}Regardless of how you subscribe, the event handler must be public, return void, and have the same parameters as the delegate.
As an alternative to delegates, you can achieve a similar effect by using pre- and post-event handlers.
You can subscribe declaratively to any class and record type method by using the same procedure as for delegates. The event handler is invoked either before or after the method is invoked. Event handlers for pre- and post-methods must be public, static, void, and either take the same parameters as the method or one parameter of the XppPrePostArgs type.
The simplest, type-safe implementation uses syntax where the parameters of the method and the event handler method match.
class MyClass
{
public int myMethod(int _i)
{
return _i;
}
}
class MyEventHandlerClass
{
public static void myPreEventHandler(int _i)
{
if (_i > 100)
{
...
}
}
public static void myPostEventHandler(int _i)
{
if (_i > 100)
{
...
}
}
}If you need to manipulate either the parameters or the return value, the event handler must take one parameter of the XppPrePostArgs type.
To create such an event handler, right-click the class, and then select New pre- or post-event handler. The XppPrePostArgs class provides access to the parameters and the return values of the method. You can even alter parameter values in pre-event handlers and alter the return value in post-event handlers.
class MyClass
{
public int myMethod(int _i)
{
return _i;
}
}
class MyEventHandlerClass
{
public static void myPreEventHandler(XppPrePostArgs _args)
{
if (_args.existsArg('_i') &&
_args.getArg('_i') > 100)
{
_args.setArg('_i', 100);
}
}
public static void myPostEventHandler(XppPrePostArgs _args)
{
if (_args.getReturnValue() < 0)
{
_args.setReturnValue(0);
}
}
}Classes and methods can be decorated with attributes to convey declarative information to other code, such as the runtime, the compiler, frameworks, or other tools. To decorate the class, you insert the attribute in the classDeclaration element. To decorate a method, you insert the attribute before the method declaration:
[MyAttribute("Some parameter")]
class MyClass
{
[MyAttribute("Some other parameter")]
public void myMethod()
{
...
}
}The first attribute that was built in Microsoft Dynamics AX 2012 was the SysObsoleteAttribute attribute. By decorating a class or a method with this attribute, any consuming code is notified during compilation that the target is obsolete. You can create your own attributes by creating classes that extend the SysAttribute class:
class MyAttribute extends SysAttribute
{
str parameter;
public void new(str _parameter)
{
parameter = _parameter;
super();
}
}Code access security (CAS) is a mechanism designed to protect systems from dangerous APIs that are invoked by untrusted code. CAS has nothing to do with user authentication or authorization; it is a mechanism allowing two pieces of code to communicate in a manner that cannot be compromised.
Caution
X++ developers are responsible for writing code that conforms to Trustworthy Computing guidelines. You can find those guidelines in the white paper “Writing Secure X++ Code,” available from the Microsoft Dynamics AX Developer Center (http://msdn.microsoft.com/en-us/dynamics/ax).
In the Microsoft Dynamics AX implementation of CAS, trusted code is defined as code from the AOT running on the Application Object Server (AOS). The first part of the definition ensures that the code is written by a trusted X++ developer. Developer privileges are the highest level of privileges in Microsoft Dynamics AX and should be granted only to trusted personnel. The second part of the definition ensures the code that the trusted developer has written hasn’t been tampered with. If the code executes outside the AOS—on a client, for example—it can’t be trusted because of the possibility that it was altered on the client side before execution. Untrusted code also includes code that is executed through the runBuf and evalBuf methods. These methods are typically used to execute code generated at run time based on user input.
CAS enables a secure handshake between an API and its consumer. Only consumers who provide the correct handshake can invoke the API. Any other invocation raises an exception.
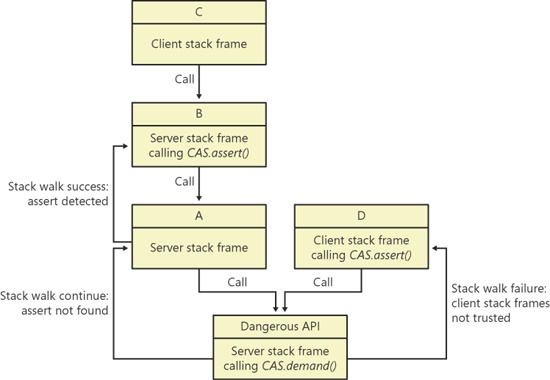
The secure handshake is established through the CodeAccessPermission class or one of its specializations. The consumer must request permission to call the API, which is done by calling CodeAccessPermission.assert. The API verifies that the consumer has the correct permissions by calling CodeAccessPermission.demand. The demand method searches the call stack for a matching assertion. If untrusted code exists on the call stack before the matching assertion, an exception is raised. This process is illustrated in Figure 4-1.
The following code contains an example of a dangerous API protected by CAS and a consumer providing the correct permissions to invoke the API:
class WinApiServer
{
// Delete any given file on the server
public server static boolean deleteFile(Filename _fileName)
{
FileIOPermission fileIOPerm;
// Check file I/O permission
fileIOPerm = new FileIOPermission(_fileName, 'w'),
fileIOPerm.demand();
// Delete the file
System.IO.File::Delete(_filename);
}
}
class Consumer
{
// Delete the temporary file on the server
public server static void deleteTmpFile()
{
FileIOPermission fileIOPerm;
FileName filename = @'c: mpfile.tmp';
// Request file I/O permission
fileIOPerm = new FileIOPermission(filename, 'w'),
fileIOPerm.assert();
// Use CAS protected API to delete the file
WinApiServer::deleteFile(filename);
}
}
WinAPIServer::deleteFile is considered to be a dangerous API because it exposes the .NET API System.IO.File::Delete(string fileName). Exposing this API on the server is dangerous because it allows the user to remotely delete files on the server, possibly bringing the server down. In the example, WinApiServer::deleteFile demands that the caller has asserted that the input file name is valid. The demand prevents use of the API from the client tier and from any code not stored in the AOT.
Caution
When using assert, make sure that you don’t create a new API that is just as dangerous as the one that CAS has secured. When you call assert, you are asserting that your code doesn’t expose the same vulnerability that required the protection of CAS. For example, if the deleteTmpFile method in the previous example had taken the file name as a parameter, it could have been used to bypass the CAS protection of WinApi::deleteFile and delete any file on the server.
All X++ code is compiled into Microsoft Dynamics AX runtime bytecode intermediate format. This format is used by the Microsoft Dynamics AX runtime for Microsoft Dynamics AX client and server code.
Further, classes and tables are compiled into .NET common intermediate language (CIL). This format is used by X++ code executed by the Batch Server and in certain other scenarios.
The X++ compiler only generates Microsoft Dynamics AX runtime bytecode to generate CIL code; you must manually press either the Generate Full IL or Generate Incremental IL button. Both are available on the toolbar.
The main benefit of running X++ as CIL is performance. Generally the .NET runtime is significantly faster than the X++ runtime. In certain constructions, the performance gain is particularly remarkable:
Constructs with many method calls—Under the covers in the X++ runtime, any method call happens through reflection, whereas in CIL, this happens at the CPU level.
Constructions with many short-lived objects—Garbage collection in the Microsoft Dynamics AX runtime is deterministic, which means that whenever an instance goes out of scope, the entire object graph is analyzed to determine if any objects can be deallocated. In the .NET CLR, garbage collection is indeterministic, which means that the runtime determines the optimal time for reclaiming memory.
Constructions with extensive use of.NET interop—When running as X++ code as CIL, all conversion and marshaling between the runtimes are avoided.
Note
The capability to compile X++ into CIL requires that X++ syntax be as strict as the syntax in managed code. The most noteworthy change is that overridden methods must now have the same signature as the base method. The only permissible discrepancy is the addition of optional parameters.
One real-life example where running X++ code as .NET CIL makes a significant difference is in the compare tool. The compare algorithm is implemented as X++ code in the SysCompareText class. Even though the algorithm has few method calls, few short-lived objects, and no .NET interop, the switch to CIL means that within a time frame of 10 seconds, it is now possible to compare two 3,500-line texts, whereas the AX runtime can only handle 600 lines in the same time frame. The complexity of the algorithm is exponential. In other words the performance gain gets even more significant the larger the texts become.
All services and batch jobs will automatically run as CIL. If you want to force X++ code to run as CIL in non-batch scenarios, you use the methods runClassMethodIL and runTableMethodIL on the Global class. The IL entry point must be a static server method that returns a container and takes one container parameter:
class MyClass
{
private static server container addInIL(container _parameters)
{
int p1, p2;
[p1, p2] = _parameters;
return [p1+p2];
}
public server static void main(Args _args)
{
int result;
XppILExecutePermission permission = new XppILExecutePermission();
permission.assert();
[result] = runClassMethodIL(classStr(MyClass),
staticMethodStr(MyClass, addInIL), [2, 2]);
info(strFmt("The result from IL is: %1", result));
}
}So far, this chapter has described the individual elements of X++. You’ve seen that statements are grouped into methods, and methods are grouped into classes, tables, and other model element types. These structures enable you to create X++ code at a higher level of abstraction. The following example shows how an assignment operation can be encapsulated into a method to clearly articulate the intention of the code.
control.show();
is at a higher level of abstraction than
flags = flags | 0x0004;
By using patterns, developers can communicate their solutions more effectively and reuse proven solutions to common problems. Patterns help readers of source code to quickly understand the purpose of a particular implementation. Bear in mind that even as a code author, you spend more time reading source code than writing it.
Implementations of patterns are typically recognizable by the names used for classes, methods, parameters, and variables. Arguably, naming these elements so that they effectively convey the intention of the code is the developer’s most difficult task. Much of the information in existing literature on design patterns pertains to object-oriented languages, and you can benefit from exploring that information to find patterns and techniques you can apply when you’re writing X++ code. Design patterns express relationships or interactions between several classes or objects. They don’t prescribe a specific implementation, but they do offer a template solution for a typical design problem. In contrast, implementation patterns are implementation specific and can have a scope that spans only a single statement.
This section highlights some of the most frequently used patterns specific to X++. More descriptions are available in the Microsoft Dynamics AX SDK on MSDN.
These patterns apply to classes in X++.
To set and get a class field from outside the class, you should implement a parameter method. The parameter method should have the same name as the field and be prefixed with parm. Parameter methods come in two flavors: get-only and get/set.
public class Employee
{
EmployeeName name;
public EmployeeName parmName(EmployeeName _name = name)
{
name = _name;
return name;
}
}The purpose of the constructor encapsulation pattern is to enable Liskov’s class substitution principle. In other words, with constructor encapsulation, you can replace an existing class with a customized class without using the layering system. Just as in the layering system, this pattern enables changing the logic in a class without having to update any references to the class. Be careful to avoid overlayering because it often causes upgrade conflicts.
Classes that have a static construct method follow the constructor encapsulation pattern. The construct method should instantiate the class and immediately return the instance. The construct method must be static and shouldn’t take any parameters.
When parameters are required, you should implement the static new methods. These methods call the construct method to instantiate the class and then call the parameter methods to set the parameters. In this case, the construct method should be private:
public class Employee
{
...
protected void new()
{
}
protected static Employee construct()
{
return new Employee();
}
public static Employee newName(EmployeeName name)
{
Employee employee = Employee::construct();
employee.parmName(name);
return employee;
}
}To decouple a base class from derived classes, use the SysExtension framework. This framework enables the construction of an instance of a class based on its attributes. This pattern enables add-ons and customizations to add new subclasses without touching the base class or the factory method:
class BaseClass
{
...
public static BaseClass newFromTableName(TableName _tableName)
{
SysTableAttribute attribute = new SysTableAttribute(_tableName);
return SysExtensionAppClassFactory::getClassFromSysAttribute(
classStr(BaseClass), attribute);
}
}
[SysTableAttribute(tableStr(MyTable))]
class Subclass extends BaseClass
{
...
}Many classes require the capability to serialize and deserialize themselves. Serialization is an operation that extracts an object’s state into value-type data; deserialization creates an instance from that data.
X++ classes that implement the Packable interface support serialization. The Packable interface contains two methods: pack and unpack. The pack method returns a container with the object’s state; the unpack method takes a container as a parameter and sets the object’s state accordingly. You should include a versioning number as the first entry in the container to make the code resilient to old packed data stored in the database when the implementation changes.
public class Employee implements SysPackable
{
EmployeeName name;
#define.currentVersion(1)
#localmacro.CurrentList
name
#endmacro
...
public container pack()
{
return [#currentVersion, #currentList];
}
public boolean unpack(container packedClass)
{
Version version = RunBase::getVersion(packedClass);
switch (version)
{
case #CurrentVersion:
[version, #CurrentList] = packedClass;
break;
default: //The version number is unsupported
return false;
}
return true;
}
}The patterns described in this section—the find and exists methods, polymorphic associations (Table/Group/All), and Generic Record References—apply to tables.
Each table must have the two static methods find and exists. They both take the primary keys of the table as parameters and return the matching record or a Boolean value, respectively. Besides the primary keys, the Find method also takes a Boolean parameter that specifies whether the record should be selected for update.
For the CustTable table, these methods have the following profiles:
static CustTable find(CustAccount _custAccount, boolean _forUpdate = false) static boolean exist(CustAccount _custAccount)
The Table/Group/All pattern is used to model a polymorphic association to either a specific record in another table, a collection of records in another table, or all records in another table. For example, a record could be associated with a specific item, all items in an item group, or all items.
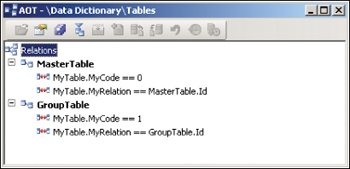
You implement the Table/Group/All pattern by creating two fields and two relations on the table. By convention, the name of the first field has the suffix Code; for example, ItemCode. This field is modeled using the base enum TableGroupAll. The name of the second field usually has the suffix Relation; for example, ItemRelation. This field is modeled by using the extended data type that is the primary key in the foreign tables. The two relations are of the type Fixed field relation. The first relation specifies that when the Code field equals 0 (TableGroupAll::Table), the Relation field equals the primary key in the foreign master data table. The second relation specifies that when the Code field equals 1 (TableGroupAll::Group), the Relation field equals the primary key in the foreign grouping table.
Figure 4-2 shows an example.
The Generic Record Reference pattern is a variation of the Table/Group/All pattern. This pattern is used to model an association to a foreign table. It comes in three flavors: (a) an association to any record in a specific table, (b) an association to any record in a fixed set of specific tables, and (c) an association to any record in any table.
All three flavors of this pattern are implemented by creating a field that uses the RefRecId extended data type.
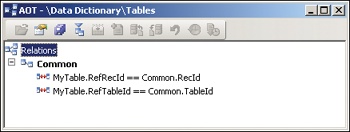
To model an association to any record in a specific table (flavor a), a relation is created from the RefRecId field to the RecId field of the foreign table, as illustrated in Figure 4-3.
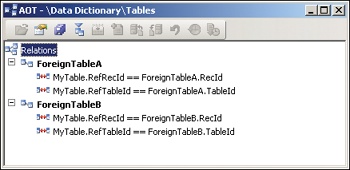
For flavors b and c, an additional field is required. This field is created by using the RefTableId extended data type. To model an association to any record in a fixed set of specific tables (flavor b), a relation is created for each foreign table from the RefTableId field to the TableId field of the foreign table, and from the RefRecId field to the RecId field of the foreign table, as shown in Figure 4-4.
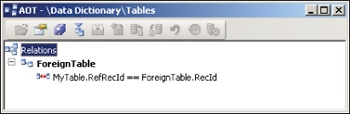
To model an association to any record in any table (flavor c), a relation is created from the RefTableId field to the generic table Common TableId field and from the RefRecId field to Common RecId field, as shown in Figure 4-5.