
In this section, we will discuss tuning parameters and technique for machine learning models such as hyperparameter tuning, random search parameter tuning, and grid search parameter tuning and cross-validation.
Hyperparameter tuning is a technique for choosing the right combination of parameters based on the performance of presented data. It is one of the fundamental requirements to obtain meaningful and accurate results from machine learning algorithms in practice. For example, suppose we have two hyperparameters to tune for a pipeline presented in Figure 3, a Spark ML pipeline model using a logistic regression estimator (dash lines only happen during pipeline fitting).
We can see that we have put three candidate values for each. Therefore, there would be nine combinations in total. However, only four are shown in the diagram, namely Tokenizer, HashingTF, Transformer and Logistic Regression (LR). Now we want to find the one that will lead to the model with the best evaluation result eventually. As we have already discussed in Chapter 6, Building Scalable Machine Learning Pipelines, the fitted model consists of the tokenizer, the hashing TF feature extractor, and the fitted logistic regression model:
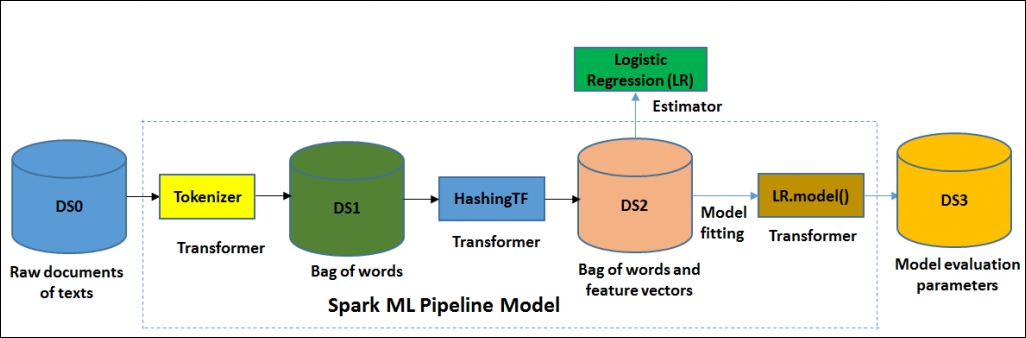
Figure 3: Spark ML pipeline model using logistic regression estimator (dash lines only happen during pipeline fitting)
Figure 3 shows the typical workflow of the previously mentioned pipeline. The dash line however happens only during the pipeline fitting.
As mentioned earlier, the fitted pipeline model is a transformer. The transformer can be used for prediction, model validation, and model inspection. In addition, we also argued that one ill-fated distinguishing characteristic of the ML algorithms is that typically they have many hyperparameters that need to be tuned for better performance.
For example, the degree of regularizations in these hyperparameters is distinctive from the model parameters optimized by the Spark MLlib. As a consequence, it is really hard to guess or measure the best combination of hyperparameters without expert knowledge of the data and the algorithm to use. Since the complex dataset is based on the ML problem type, the size of the pipeline and the number of hyperparameters may grow exponentially (or linearly), the hyperparameter tuning becomes cumbersome even for an ML expert, not to mention that the result of the tuning parameters may become unreliable
According to Spark API documentation provided at http://spark.apache.org/docs/latest/ml-guide.html, a unique and uniform API is used for specifying Spark ML Estimators and Transformers. A ParamMap is a set of (parameter, value) pairs with a Param as a named parameter with self-contained documentation provided by Spark. Technically, there are two ways for passing the parameters to an algorithm as specified in the following options:
- Setting parameters. For example, if an LR is an instance of
LogisticRegression(that is, Estimator), you can call thesetMaxIter()method as follows:LR.setMaxIter(5). It essentially fits the model pointing the regression instance as follows:LR.fit(). In this particular example, there would be at most five iterations. - The second option involves passing a
ParamMapstofit()ortransform()(refer Figure 1 for details). In this circumstance, any parameters will be overridden by theParamMapspreviously specified via setter methods in the ML application-specific codes or algorithms.
Tip
An excellent way to create a shortlist of well-performing algorithms for your dataset is to use the Caret package in R since tuning in Spark is not that robust. Caret is a package in R created and maintained by Max Kuhn from Pfizer. Development started in 2005 and was later made open source and uploaded to CRAN which is actually an acronym which stands for Classification And Regression Training (CARET). It was initially developed out of the need to run multiple different algorithms for a given problem. Interested readers can have a look at that package for theoretical and practical consideration by visiting: http://topepo.github.io/caret/index.html.
Suppose you have selected your hyperparameters, and by applying tuning, you now also need to find the features. In this regard, a full grid search of the space of hyperparameters and features is computationally too intensive. Therefore, you need to perform a fold of the K-fold cross-validation instead of a full grid search:
- Tune the required hyperparameters using cross-validation on the training set of the fold, using all the available features
- Select the required features using those hyperparameters
- Repeat the computation for each fold in K
- The final model is constructed on all the data using the N most prevalent features that were selected from each fold of CV
The interesting thing is that the hyperparameters would also be tuned again using all the data in a cross-validation loop. Would there be a large downside from this method as compared to a full grid search? In essence, I am doing a line search in each dimension of free parameters (finding the best value in one dimension, holding that constant then finding the best in the next dimension), rather than every single combination of parameter settings.
The most important downside for searching along single parameters instead of optimizing them altogether is that you ignore interactions. It is quite common that, for instance, more than one parameter influences model complexity. In that case, you need to look at their interaction in order to successfully optimize the hyperparameters. Depending on how large your data set is and how many models you compare, optimization strategies that return the maximum observed performance may run into trouble (this is true for both grid search and your strategy).
The reason is that searching through a large number of performance estimates for the maximum skims the variance of the performance estimate: you may just end up with a model and training/test split combination that accidentally happens to look good. Even worse, you may get several perfect-looking combinations, and the optimization then cannot know which model to choose and thus becomes unstable.
The default method for optimizing tuning parameters in the train is to use a grid search. This approach is usually effective but, in cases when there are many tuning parameters, it can be inefficient. There are a number of models where this can be beneficial in finding reasonable values of the tuning parameters in a relatively short time. However, there are some models where the efficiency in a small search field can cancel out other optimizations. Unfortunately, the current implementation in Spark for hyperparameter tuning does not provide any technique for random search tuning.
Tip
In contrast, for example, a number of models in CARET utilize the sub-model trick where M tuning parameter combinations are evaluated; potentially far fewer than M model fits are required. This approach is best leveraged when a simple grid search is used. For this reason, it may be inefficient to use a random search. Finally, many of the models wrapped by train have a small number of parameters. The average number of parameters is 1.7. To use a random search, another option is available in trainControl called search. Possible values of this argument are grid and random. The built-in models contained in CARET contain code to generate random tuning parameter combinations. The total number of unique combinations is specified by the tuneLength option to train.
Cross-validation (also called the Rotation Estimation (RE)) is a model validation technique for assessing the quality of the statistical analysis and results. The target is to make the model generalize towards an independent test set.
One of the perfect uses of the cross-validation technique is making a prediction from a machine learning model. Technically, it will help if you want to estimate how a predictive model will perform accurately in practice when you deploy it as an ML application.
During the cross-validation process, a model is usually trained with a dataset of a known type. Conversely, it is tested using a dataset of unknown type. In this regard, cross-validation help describes a dataset to test the model in the training phase using the validation set.
However, in order to minimize the flaws in the machine learning model such as overfitting and underfitting, the cross-validation technique provides insights into how the model will generalize to an independent set.
There are two types of cross-validation that can be typed as follows:
- Exhaustive cross-validation: This includes leave-p-out cross-validation and leave-one-out cross-validation
- Non-exhaustive cross-validation: This includes the K-fold cross-validation and repeated random sub-sampling validation cross-validation
Detailed discussion of these will not be conducted in this book due to page limitation. Moreover, using Spark ML and Spark MLlib, readers will be able to perform the cross-validation following our examples in the next section.
Except for the time series data, in most of the cases, the researcher/data scientist/data engineer uses 10-fold cross-validation instead of testing on a validation set (where K = 10). This is the most widely used cross-validation technique across the use cases and problem type. Moreover, to reduce the variability, multiple iterations of cross-validation are performed using different partitions; finally, the validation results are averaged over the rounds across.
Using cross-validation instead of conventional validation has two main advantages outlined as follows:
- Firstly, if there is not enough data available to partition across the separate training and test sets, there's the chance of losing significant modelling or testing capability.
- Secondly, the K-fold cross-validation Estimator has a lower variance than a single hold-out set Estimator. This low variance limits the variability and is again very important if the amount of available data is limited.
In these circumstances, a fair way to properly estimate the model prediction and related performance is to use cross-validation as a powerful general technique for model selection and validation.
A more technical example will be shown in the Machine learning model selection section. Let's draw a concrete example to illustrate this. Suppose, we need to perform manual features and a parameter selection for the model tuning and, after that, perform a model evaluation with a 10-fold cross-validation on the entire dataset. What would be the best strategy? We would suggest you go for the strategy that provides an optimistic score as follows:
- Divide the dataset into training, say 80%, and testing 20% or whatever you chose
- Use the K-fold cross-validation on the training set to tune your model
- Repeat the CV until you find your model optimized and therefore tuned
- Now use your model to predict on the testing set to get an estimate of out-of-model errors