
Mathematical relationships help us to understand many aspects of everyday life. For example, body weight is a function of one's calorie intake, income is often related to education and job experience, and poll numbers help us estimate a presidential candidate's odds of being re-elected.
When such relationships are expressed with exact numbers, we gain additional clarity. For example, an additional 250 kilocalories consumed daily may result in nearly a kilogram of weight gain per month; each year of job experience may be worth an additional $1,000 in yearly salary; and a president is more likely to be re-elected when the economy is strong. Obviously, these equations do not perfectly fit every situation, but we expect that they are reasonably correct, on average.
This chapter extends our machine learning toolkit by going beyond the classification methods covered previously and introducing techniques for estimating relationships among numeric data. While examining several real-world numeric prediction tasks, you will learn:
- The basic statistical principles used in regression, a technique that models the size and the strength of numeric relationships
- How to prepare data for regression analysis, and estimate and interpret a regression model
- A pair of hybrid techniques known as regression trees and model trees, which adapt decision tree classifiers for numeric prediction tasks
Based on a large body of work in the field of statistics, the methods used in this chapter are a bit heavier on math than those covered previously, but don't worry! Even if your algebra skills are a bit rusty, R takes care of the heavy lifting.
Regression is concerned with specifying the relationship between a single numeric dependent variable (the value to be predicted) and one or more numeric independent variables (the predictors). As the name implies, the dependent variable depends upon the value of the independent variable or variables. The simplest forms of regression assume that the relationship between the independent and dependent variables follows a straight line.
Note
The origin of the term "regression" to describe the process of fitting lines to data is rooted in a study of genetics by Sir Francis Galton in the late 19th century. He discovered that fathers who were extremely short or extremely tall tended to have sons whose heights were closer to the average height. He called this phenomenon "regression to the mean".
You might recall from basic algebra that lines can be defined in a slope-intercept form similar to y = a + bx. In this form, the letter y indicates the dependent variable and x indicates the independent variable. The slope term b specifies how much the line rises for each increase in x. Positive values define lines that slope upward while negative values define lines that slope downward. The term a is known as the intercept because it specifies the point where the line crosses, or intercepts, the vertical y axis. It indicates the value of y when x = 0.

Regression equations model data using a similar slope-intercept format. The machine's job is to identify values of a and b so that the specified line is best able to relate the supplied x values to the values of y. There may not always be a single function that perfectly relates the values, so the machine must also have some way to quantify the margin of error. We'll discuss this in depth shortly.
Regression analysis is commonly used for modeling complex relationships among data elements, estimating the impact of a treatment on an outcome, and extrapolating into the future. Although it can be applied to nearly any task, some specific use cases include:
- Examining how populations and individuals vary by their measured characteristics, for use in scientific research across fields as diverse as economics, sociology, psychology, physics, and ecology
- Quantifying the causal relationship between an event and the response, such as those in clinical drug trials, engineering safety tests, or marketing research
- Identifying patterns that can be used to forecast future behavior given known criteria, such as predicting insurance claims, natural disaster damage, election results, and crime rates
Regression methods are also used for statistical hypothesis testing, which determines whether a premise is likely to be true or false in light of the observed data. The regression model's estimates of the strength and consistency of a relationship provide information that can be used to assess whether the observations are due to chance alone.
Regression analysis is not synonymous with a single algorithm. Rather, it is an umbrella for a large number of methods that can be adapted to nearly any machine learning task. If you were limited to choosing only a single method, regression would be a good choice. One could devote an entire career to nothing else and perhaps still have much to learn.
In this chapter, we'll focus only on the most basic linear regression models—those that use straight lines. When there is only a single independent variable it is known as simple linear regression. In the case of two or more independent variables, this is known as multiple linear regression, or simply "multiple regression". Both of these techniques assume that the dependent variable is measured on a continuous scale.
Regression can also be used for other types of dependent variables and even for some classification tasks. For instance, logistic regression is used to model a binary categorical outcome, while Poisson regression—named after the French mathematician Siméon Poisson—models integer count data. The method known as multinomial logistic regression models a categorical outcome; thus, it can be used for classification. The same basic principles apply across all the regression methods, so after understanding the linear case, it is fairly simple to learn the others.
Tip
Many of the specialized regression methods fall into a class of Generalized Linear Models (GLM). Using a GLM, linear models can be generalized to other patterns via the use of a link function, which specifies more complex forms for the relationship between x and y. This allows regression to be applied to almost any type of data.
We'll begin with the basic case of simple linear regression. Despite the name, this method is not too simple to address complex problems. In the next section, we'll see how the use of a simple linear regression model might have averted a tragic engineering disaster.
On January 28, 1986, seven crew members of the United States space shuttle Challenger were killed when a rocket booster failed, causing a catastrophic disintegration. In the aftermath, experts focused on the launch temperature as a potential culprit. The rubber O-rings responsible for sealing the rocket joints had never been tested below 40ºF (4ºC) and the weather on the launch day was unusually cold and below freezing.
With the benefit of hindsight, the accident has been a case study for the importance of data analysis and visualization. Although it is unclear what information was available to the rocket engineers and decision makers leading up to the launch, it is undeniable that better data, utilized carefully, might very well have averted this disaster.
Note
This section's analysis is based on data presented in Dalal SR, Fowlkes EB, Hoadley B. Risk analysis of the space shuttle: pre-Challenger prediction of failure. Journal of the American Statistical Association. 1989; 84:945-957. For one perspective on how data may have changed the result, see Tufte ER. Visual Explanations: Images and Quantities, Evidence and Narrative. Graphics Press; 1997. For a counterpoint, see Robison W, Boisioly R, Hoeker D, Young, S. Representation and misrepresentation: Tufte and the Morton Thiokol engineers on the Challenger. Science and Engineering Ethics. 2002; 8:59-81.
The rocket engineers almost certainly knew that cold temperatures could make the components more brittle and less able to seal properly, which would result in a higher chance of a dangerous fuel leak. However, given the political pressure to continue with the launch, they needed data to support this hypothesis. A regression model that demonstrated a link between temperature and O-ring failure, and could forecast the chance of failure given the expected temperature at launch, might have been very helpful.
To build the regression model, scientists might have used the data on launch temperature and component distresses from 23 previous successful shuttle launches. A component distress indicates one of the two types of problems. The first problem, called erosion, occurs when excessive heat burns up the O-ring. The second problem, called blowby, occurs when hot gases leak through or "blow by" a poorly sealed O-ring. Since the shuttle has a total of six primary O-rings, up to six distresses can occur per flight. Though the rocket can survive one or more distress events, or fail with as few as one, each additional distress increases the probability of a catastrophic failure.
The following scatterplot shows a plot of primary O-ring distresses detected for the previous 23 launches, as compared to the temperature at launch:

Examining the plot, there is an apparent trend. Launches occurring at higher temperatures tend to have fewer O-ring distress events.
Additionally, the coldest launch (53º F) had two distress events, a level which had only been reached in one other launch. With this information at hand, the fact that the Challenger was scheduled to launch at a temperature over 20 degrees colder seems concerning. But exactly how concerned should we be? To answer this question, we can turn to simple linear regression.
A simple linear regression model defines the relationship between a dependent variable and a single independent predictor variable using a line defined by an equation in the following form:
Don't be alarmed by the Greek characters, this equation can still be understood using the slope-intercept form described previously. The intercept, α (alpha), describes where the line crosses the y axis, while the slope, β (beta), describes the change in y given an increase of x. For the shuttle launch data, the slope would tell us the expected reduction in the number of O-ring failures for each degree the launch temperature increases.
Tip
Greek characters are often used in the field of statistics to indicate variables that are parameters of a statistical function. Therefore, performing a regression analysis involves finding parameter estimates for α and β. The parameter estimates for alpha and beta are often denoted using a and b, although you may find that some of this terminology and notation is used interchangeably.
Suppose we know that the estimated regression parameters in the equation for the shuttle launch data are: a = 3.70 and b = -0.048.
Hence, the full linear equation is y = 3.70 – 0.048x. Ignoring for a moment how these numbers were obtained, we can plot the line on the scatterplot like this:

As the line shows, at 60 degrees Fahrenheit, we predict just under one O-ring distress. At 70 degrees Fahrenheit, we expect around 0.3 failures. If we extrapolate our model, all the way to 31 degrees—the forecasted temperature for the Challenger launch—we would expect about 3.70 - 0.048 * 31 = 2.21 O-ring distress events. Assuming that each O-ring failure is equally likely to cause a catastrophic fuel leak means that the Challenger launch at 31 degrees was nearly three times more risky than the typical launch at 60 degrees, and over eight times more risky than a launch at 70 degrees.
Notice that the line doesn't pass through each data point exactly. Instead, it cuts through the data somewhat evenly, with some predictions lower or higher than the line. In the next section, we will learn about why this particular line was chosen.
In order to determine the optimal estimates of α and β, an estimation method known as Ordinary Least Squares (OLS) was used. In OLS regression, the slope and intercept are chosen so that they minimize the sum of the squared errors, that is, the vertical distance between the predicted y value and the actual y value. These errors are known as residuals, and are illustrated for several points in the following diagram:

In mathematical terms, the goal of OLS regression can be expressed as the task of minimizing the following equation:
In plain language, this equation defines e (the error) as the difference between the actual y value and the predicted y value. The error values are squared and summed across all the points in the data.
The solution for a depends on the value of b. It can be obtained using the following formula:
Tip
To understand these equations, you'll need to know another bit of statistical notation. The horizontal bar appearing over the x and y terms indicates the mean value of x or y. This is referred to as the x-bar or y-bar, and is pronounced just like the establishment you'd go to for an alcoholic drink.
Though the proof is beyond the scope of this book, it can be shown using calculus that the value of b that results in the minimum squared error is:

If we break this equation apart into its component pieces, we can simplify it a bit. The denominator for b should look familiar; it is very similar to the variance of x, which is denoted as Var(x). As we learned in Chapter 2, Managing and Understanding Data, the variance involves finding the average squared deviation from the mean of x. This can be expressed as:

The numerator involves taking the sum of each data point's deviation from the mean x value multiplied by that point's deviation away from the mean y value. This is similar to the covariance function for x and y, denoted as Cov(x, y). The covariance formula is:
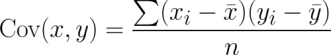
If we divide the covariance function by the variance function, the n terms get cancelled and we can rewrite the formula for b as:

Given this restatement, it is easy to calculate the value of b using built-in R functions. Let's apply it to the rocket launch data to estimate the regression line.
Assume that our shuttle launch data is stored in a data frame named launch, the independent variable x is temperature, and the dependent variable y is distress_ct. We can then use R's cov() and var() functions to estimate b:
> b <- cov(launch$temperature, launch$distress_ct) / var(launch$temperature) > b [1] -0.04753968
From here we can estimate a using the mean() function:
> a <- mean(launch$distress_ct) - b * mean(launch$temperature) > a [1] 3.698413
Estimating the regression equation by hand is not ideal, so R provides functions for performing this calculation automatically. We will use such methods shortly. First, we will expand our understanding of regression by learning a method for measuring the strength of a linear relationship, and then we will see how linear regression can be applied to data having more than one independent variable.
The correlation between two variables is a number that indicates how closely their relationship follows a straight line. Without additional qualification, correlation typically refers to Pearson's correlation coefficient, which was developed by the 20th century mathematician Karl Pearson. The correlation ranges between -1 and +1. The extreme values indicate a perfectly linear relationship, while a correlation close to zero indicates the absence of a linear relationship.
The following formula defines Pearson's correlation:

Using this formula, we can calculate the correlation between the launch temperature and the number of O-ring distress events. Recall that the covariance function is cov() and the standard deviation function is sd(). We'll store the result in r, a letter that is commonly used to indicate the estimated correlation:
> r <- cov(launch$temperature, launch$distress_ct) / (sd(launch$temperature) * sd(launch$distress_ct)) > r [1] -0.5111264
Alternatively, we can use R's correlation function, cor():
> cor(launch$temperature, launch$distress_ct) [1] -0.5111264
The correlation between the temperature and the number of distressed O-rings is -0.51. The negative correlation implies that increases in temperature are related to decreases in the number of distressed O-rings. To the NASA engineers studying the O-ring data, this would have been a very clear indicator that a low temperature launch could be problematic. The correlation also tells us about the relative strength of the relationship between temperature and O-ring distress. Because -0.51 is halfway to the maximum negative correlation of -1, this implies that there is a moderately strong negative linear association.
There are various rules of thumb used to interpret correlation strength. One method assigns a status of "weak" to values between 0.1 and 0.3, "moderate" to the range of 0.3 to 0.5, and "strong" to values above 0.5 (these also apply to similar ranges of negative correlations). However, these thresholds may be too lax for some purposes. Often, the correlation must be interpreted in context. For data involving human beings, a correlation of 0.5 may be considered extremely high, while for data generated by mechanical processes, a correlation of 0.5 may be weak.
Tip
You have probably heard the expression "correlation does not imply causation." This is rooted in the fact that a correlation only describes the association between a pair of variables, yet there could be other unmeasured explanations. For example, there may be a strong association between mortality and time per day spent matching movies, but before doctors should start recommending that we all watch more movies, we need to rule out another explanation—younger people watch more movies and are less likely to die.
Measuring the correlation between two variables gives us a way to quickly gauge the relationships among the independent and dependent variables. This will be increasingly important as we start defining the regression models with a larger number of predictors.
Most real-world analyses have more than one independent variable. Therefore, it is likely that you will be using multiple linear regression for most numeric prediction tasks. The strengths and weaknesses of multiple linear regression are shown in the following table:
|
Strengths |
Weaknesses |
|---|---|
|
We can understand multiple regression as an extension of simple linear regression. The goal in both cases is similar—find values of beta coefficients that minimize the prediction error of a linear equation. The key difference is that there are additional terms for additional independent variables.
Multiple regression equations generally follow the form of the following equation. The dependent variable y is specified as the sum of an intercept term α plus the product of the estimated β value and the x values for each of the i features. An error term (denoted by the Greek letter epsilon) has been added here as a reminder that the predictions are not perfect. This represents the residual term noted previously:
Let's consider for a moment the interpretation of the estimated regression parameters. You will note that in the preceding equation, a coefficient is provided for each feature. This allows each feature to have a separate estimated effect on the value of y. In other words, y changes by the amount βi for each unit increase in xi. The intercept α is then the expected value of y when the independent variables are all zero.
Since the intercept term α is really no different than any other regression parameter, it is also sometimes denoted as β0 (pronounced beta-naught), as shown in the following equation:
Just like before, the intercept is unrelated to any of the independent x variables. However, for reasons that will become clear shortly, it helps to imagine β0 as if it were being multiplied by a term x0, which is a constant with the value 1:
In order to estimate the values of the regression parameters, each observed value of the dependent variable y must be related to the observed values of the independent x variables using the regression equation in the previous form. The following figure illustrates this structure:

The many rows and columns of data illustrated in the preceding figure can be described in a condensed formulation using bold font matrix notation to indicate that each of the terms represents multiple values:
The dependent variable is now a vector, Y, with a row for every example. The independent variables have been combined into a matrix, X, with a column for each feature plus an additional column of '1' values for the intercept term. Each column has a row for every example. The regression coefficients β and residual errors ε are also now vectors.
The goal is now to solve for β, the vector of regression coefficients that minimizes the sum of the squared errors between the predicted and actual Y values. Finding the optimal solution requires the use of matrix algebra; therefore, the derivation deserves more careful attention than can be provided in this text. However, if you're willing to trust the work of others, the best estimate of the vector β can be computed as:
This solution uses a pair of matrix operations—the T indicates the transpose of matrix X, while the negative exponent indicates the matrix inverse. Using R's built-in matrix operations, we can thus implement a simple multiple regression learner. Let's apply this formula to the Challenger launch data.
Using the following code, we can create a basic regression function named reg(), which takes a parameter y and a parameter x and returns a vector of estimated beta coefficients:
reg <- function(y, x) { x <- as.matrix(x) x <- cbind(Intercept = 1, x) b <- solve(t(x) %*% x) %*% t(x) %*% y colnames(b) <- "estimate" print(b) }
The reg() function created here uses several R commands that we have not used previously. First, since we will be using the function with sets of columns from a data frame, the as.matrix() function is used to convert the data frame into matrix form. Next, the cbind() function is used to bind an additional column onto the x matrix; the command Intercept = 1 instructs R to name the new column Intercept and to fill the column with repeating 1 values. Then, a number of matrix operations are performed on the x and y objects:
solve()takes the inverse of a matrixt()is used to transpose a matrix%*%multiplies two matrices
By combining these as shown, our function will return a vector b, which contains the estimated parameters for the linear model relating x to y. The final two lines in the function give the b vector a name and print the result on screen.
Let's apply our function to the shuttle launch data. As shown in the following code, the dataset includes three features and the distress count (distress_ct), which is the outcome of interest:
> str(launch) 'data.frame': 23 obs. of 4 variables: $ distress_ct : int 0 1 0 0 0 0 0 0 1 1 ... $ temperature : int 66 70 69 68 67 72 73 70 57 63 ... $ field_check_pressure: int 50 50 50 50 50 50 100 100 200 ... $ flight_num : int 1 2 3 4 5 6 7 8 9 10 ...
We can confirm that our function is working correctly by comparing its result to the simple linear regression model of O-ring failures versus temperature, which we found earlier to have parameters a = 3.70 and b = -0.048. Since temperature is in the third column of the launch data, we can run the reg() function as follows:
> reg(y = launch$distress_ct, x = launch[2]) estimate Intercept 3.69841270 temperature -0.04753968
These values exactly match our prior result, so let's use the function to build a multiple regression model. We'll apply it just as before, but this time specifying three columns of data instead of just one:
> reg(y = launch$distress_ct, x = launch[2:4]) estimate Intercept 3.527093383 temperature -0.051385940 field_check_pressure 0.001757009 flight_num 0.014292843
This model predicts the number of O-ring distress events versus temperature, field check pressure, and the launch ID number. As with the simple linear regression model, the coefficient for the temperature variable is negative, which suggests that as temperature increases, the number of expected O-ring events decreases. The field check pressure refers to the amount of pressure applied to the O-ring to test it prior to launch. Although the check pressure had originally been 50 psi, it was raised to 100 and 200 psi for some launches, which led some to believe that it may be responsible for O-ring erosion. The coefficient is positive, but small. The flight number is included to account for the shuttle's age. As it gets older, its parts may be more brittle or prone to fail. The small positive association between flight number and distress count may reflect this fact.
So far we've only scratched the surface of linear regression modeling. Although our work was useful to help us understand exactly how regression models are built, R's functions also include some additional functionality necessary for the more complex modeling tasks and diagnostic output that are needed to aid model interpretation and assess fit. Let's apply our knowledge of regression to a more challenging learning task.