
Claude Monet, one of the founders of French Impressionist painting, taught his students to paint only what they saw, not what they knew. He even went as far as to say:
"I wish I had been born blind and then suddenly gained my sight so that I could begin to paint without knowing what the objects were that I could see before me."
Monet rejected traditional artistic subjects, which tended to be mystical, heroic, militaristic, or revolutionary. Instead, he relied on his own observations of middle-class life: of social excursions; of sunny gardens, lily ponds, rivers, and the seaside; of foggy boulevards and train stations; and of private loss. With deep sadness, he told his friend, Georges Clemenceau (the future President of France):
"I one day found myself looking at my beloved wife's dead face and just systematically noting the colors according to an automatic reflex!"
Monet painted everything according to his personal impressions. Late in life, he even painted the symptoms of his own deteriorating eyesight. He adopted a reddish palette while he suffered from cataracts and a brilliant bluish palette after cataract surgery left his eyes more sensitive, possibly to the near ultraviolet range.
Like Monet's students, we as scholars of computer vision must confront a distinction between seeing and knowing and likewise between input and processing. Light, a lens, a camera, and a digital imaging pipeline can grant a computer a sense of sight. From the resulting image data, machine-learning (ML) algorithms can extract knowledge or at least a set of meta-senses such as detection, recognition, and reconstruction (scanning). Without proper senses or data, a system's learning potential is limited, perhaps even nil. Thus, when designing any computer vision system, we must consider the foundational requirements in terms of lighting conditions, lenses, cameras, and imaging pipelines.
What do we require in order to clearly see a given subject? This is the central question of our first chapter. Along the way, we will address five subquestions:
- What do we require to see fast motion or fast changes in light?
- What do we require to see distant objects?
- What do we require to see with depth perception?
- What do we require to see in the dark?
- How do we obtain good value-for-money when purchasing lenses and cameras?
The choice of hardware is crucial to these problems. Different cameras and lenses are optimized for different imaging scenarios. However, software can also make or break a solution. On the software side, we will focus on the efficient use of OpenCV. Fortunately, OpenCV's videoio module supports many classes of camera systems, including the following:
- Webcams in Windows, Mac, and Linux via the following frameworks, which come standard with most versions of the operating system:
- Windows: Microsoft Media Foundation (MSMF), DirectShow, or Video for Windows (VfW)
- Mac: QuickTime
- Linux: Video4Linux (V4L), Video4Linux2 (V4L2), or libv4l
- Built-in cameras in iOS and Android devices
- OpenNI-compliant depth cameras via OpenNI or OpenNI2, which are open-source under the Apache license
- Other depth cameras via the proprietary Intel Perceptual Computing SDK
- Photo cameras via libgphoto2, which is open source under the GPL license. For a list of libgphoto2's supported cameras, see http://gphoto.org/proj/libgphoto2/support.php.
- IIDC/DCAM-compliant industrial cameras via libdc1394, which is open-source under the LGPLv2 license
- For Linux, unicap can be used as an alternative interface for IIDC/DCAM-compliant cameras, but unicap is GPL-licensed and thus not appropriate for use in closed-source software.
- Other industrial cameras via the following proprietary frameworks:
- Allied Vision Technologies (AVT) PvAPI for GigE Vision cameras
- Smartek Vision Giganetix SDK for GigE Vision cameras
- XIMEA API
Note
The videoio module is new in OpenCV 3. Previously, in OpenCV 2, video capture and recording were part of the highgui module, but in OpenCV 3, the highgui module is only responsible for GUI functionality. For a complete index of OpenCV's modules, see the official documentation at http://docs.opencv.org/3.0.0/.
However, we are not limited to the features of the videoio module; we can use other APIs to configure cameras and capture images. If an API can capture an array of image data, OpenCV can readily use the data, often without any copy operation or conversion. As an example, we will capture and use images from depth cameras via OpenNI2 (without the videoio module) and from industrial cameras via the FlyCapture SDK by Point Grey Research (PGR).
Note
An industrial camera or machine vision camera typically has interchangeable lenses, a high-speed hardware interface (such as FireWire, Gigabit Ethernet, USB 3.0, or Camera Link), and a complete programming interface for all camera settings.
Most industrial cameras have SDKs for Windows and Linux. PGR's FlyCapture SDK supports single-camera and multi-camera setups on Windows as well as single-camera setups on Linux. Some of PGR's competitors, such as Allied Vision Technologies (AVT), offer better support for multi-camera setups on Linux.
We will learn about the differences among categories of cameras, and we will test the capabilities of several specific lenses, cameras, and configurations. By the end of the chapter, you will be better qualified to design either consumer-grade or industrial-grade vision systems for yourself, your lab, your company, or your clients. I hope to surprise you with the results that are possible at each price point!
The human eye is sensitive to certain wavelengths of electromagnetic radiation. We call these wavelengths "visible light", "colors", or sometimes just "light". However, our definition of "visible light" is anthropocentric as different animals see different wavelengths. For example, bees are blind to red light, but can see ultraviolet light (which is invisible to humans). Moreover, machines can assemble human-viewable images based on almost any stimulus, such as light, radiation, sound, or magnetism. To broaden our horizons, let's consider eight kinds of electromagnetic radiation and their common sources. Here is the list, in order of decreasing wavelength:
- Radio waves radiate from certain astronomical objects and from lightning. They are also generated by wireless electronics (radio, Wi-Fi, Bluetooth, and so on).
- Microwaves radiated from the Big Bang and are present throughout the Universe as background radiation. They are also generated by microwave ovens.
- Far infrared (FIR) light is an invisible glow from warm or hot things such as warm-blooded animals and hot-water pipes.
- Near infrared (NIR) light radiates brightly from our sun, from flames, and from metal that is red-hot or nearly red-hot. However, it is a relatively weak component in commonplace electric lighting. Leaves and other vegetation brightly reflect NIR light. Skin and certain fabrics are slightly transparent to NIR.
- Visible light radiates brightly from our sun and from commonplace electric light sources. Visible light includes the colors red, orange, yellow, green, blue, and violet (in order of decreasing wavelength).
- Ultraviolet (UV) light, too, is abundant in sunlight. On a sunny day, UV light can burn our skin and can become slightly visible to us as a blue-gray haze in the distance. Commonplace, silicate glass is nearly opaque to UV light, so we do not suffer sunburn when we are behind windows (indoors or in a car). For the same reason, UV camera systems rely on lenses made of non-silicate materials such as quartz. Many flowers have UV markings that are visible to insects. Certain bodily fluids such as blood and urine are more opaque to UV than to visible light.
- X-rays radiate from certain astronomical objects such as black holes. On Earth, radon gas, and certain other radioactive elements are natural X-ray sources.
- Gamma rays radiate from nuclear explosions, including supernovae. To lesser extents the sources of gamma rays also include radioactive decay and lightning strikes.
NASA provides the following visualization of the wavelength and temperature associated with each kind of light or radiation:
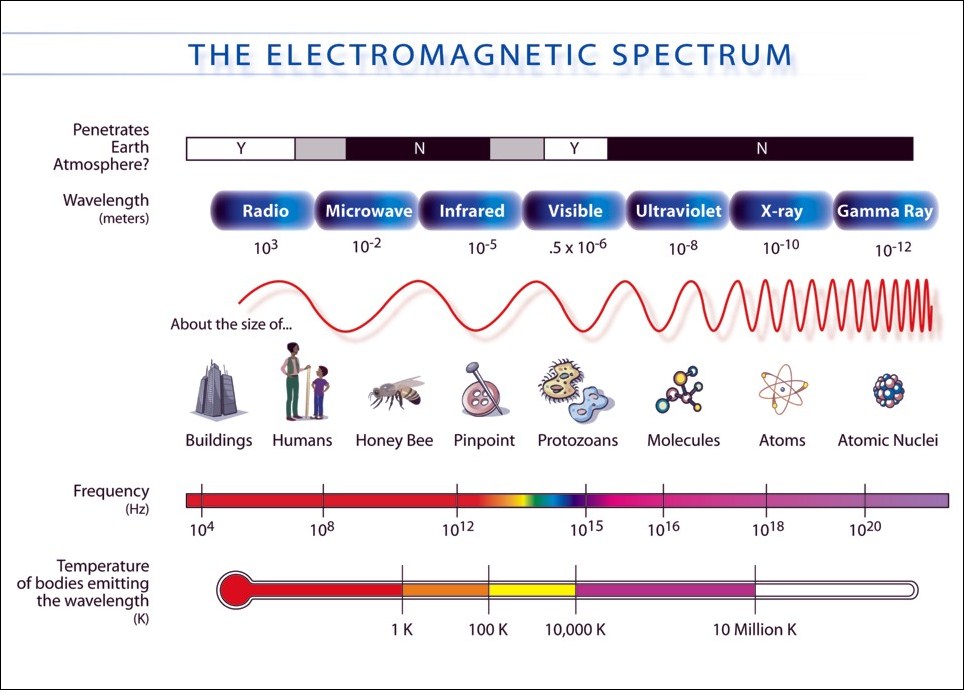
Passive imaging systems rely on ambient (commonplace) light or radiation sources as described in the preceding list. Active imaging systems include sources of their own so that the light or radiation is structured in more predictable ways. For example, an active night vision scope might use a NIR camera plus a NIR light.
For astronomy, passive imaging is feasible across the entire electromagnetic spectrum; the vast expanse of the Universe is flooded with all kinds of light and radiation from sources old and new. However, for terrestrial (Earth-bound) purposes, passive imaging is mostly limited to the FIR, NIR, visible, and UV ranges. Active imaging is feasible across the entire spectrum, but the practicalities of power consumption, safety, and interference (between our use case and others) limit the extent to which we can flood an environment with excess light and radiation.
Whether active or passive, an imaging system typically uses a lens to bring light or radiation into focus on the surface of the camera's sensor. The lens and its coatings transmit some wavelengths while blocking others. Additional filters may be placed in front of the lens or sensor to block more wavelengths. Finally, the sensor itself exhibits a varying spectral response, meaning that for some wavelengths, the sensor registers a strong (bright) signal, but for other wavelengths, it registers a weak (dim) signal or no signal. Typically, a mass-produced digital sensor responds most strongly to green, followed by red, blue, and NIR. Depending on the use case, such a sensor might be deployed with a filter to block a range of light (whether NIR or visible) and/or a filter to superimpose a pattern of varying colors. The latter filter allows for the capture of multichannel images, such as RGB images, whereas the unfiltered sensor would capture monochrome (gray) images.
The sensor's surface consists of many sensitive points or photosites. These are analogous to pixels in the captured digital image. However, photosites and pixels do not necessarily correspond one-to-one. Depending on the camera system's design and configuration, the signals from several photosites might be blended together to create a neighborhood of multichannel pixels, a brighter pixel, or a less noisy pixel.
Consider the following pair of images. They show a sensor with a Bayer filter, which is a common type of color filter with two green photosites per red or blue photosite. To compute a single RGB pixel, multiple photosite values are blended. The left-hand image is a photo of the filtered sensor under a microscope, while the right-hand image is a cut-away diagram showing the filter and underlying photosites:
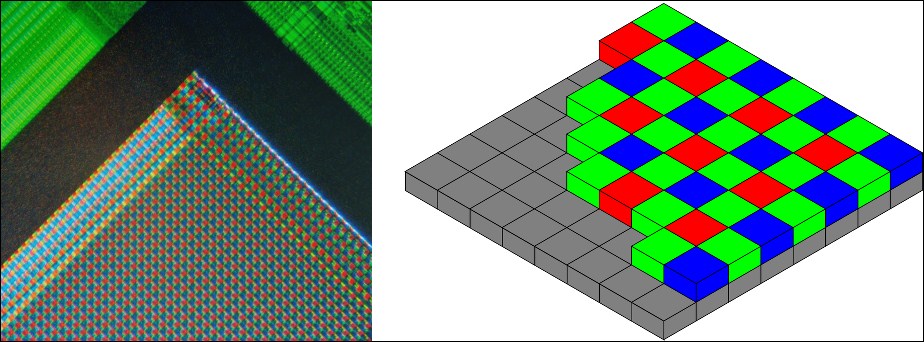
As we see in this example, a simplistic model (an RGB pixel) might hide important details about the way data are captured and stored. To build efficient image pipelines, we need to think about not just pixels, but also channels and macropixels—neighborhoods of pixels that share some channels of data and are captured, stored, and processed in one block. Let's consider three categories of image formats:
- A raw image is a literal representation of the photosites' signals, scaled to some range such as 8, 12, or 16 bits. For photosites in a given row of the sensor, the data are contiguous but for photosites in a given column, they are not.
- A packed image stores each pixel or macropixel contiguously in memory. That is to say, data are ordered according to their neighborhood. This is an efficient format if most of our processing pertains to multiple color components at a time. For a typical color camera, a raw image is not packed because each neighborhood's data are split across multiple rows. Packed color images usually use RGB channels, but alternatively, they may use YUV channels, where Y is brightness (grayscale), U is blueness (versus greenness), and V is redness (also versus greenness).
- A planar image stores each channel contiguously in memory. That is to say, data are ordered according to the color component they represent. This is an efficient format if most of our processing pertains to a single color component at a time. Packed color images usually use YUV channels. Having a Y channel in a planar format is efficient for computer vision because many algorithms are designed to work on grayscale data alone.
An image from a monochrome camera can be efficiently stored and processed in its raw format or (if it must integrate seamlessly into a color imaging pipeline) as the Y plane in a planar YUV format. Later in this chapter, in the sections Supercharging the PlayStation Eye and Supercharging the GS3-U3-23S6M-C and other Point Grey Research cameras, we will discuss code samples that demonstrate efficient handling of various image formats.
Until now, we have covered a brief taxonomy of light, radiation, and color—their sources, their interaction with optics and sensors, and their representation as channels and neighborhoods. Now, let's explore some more dimensions of image capture: time and space.