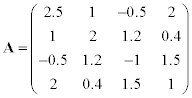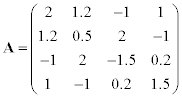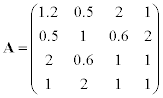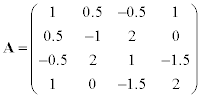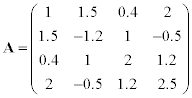Computational Eigenvalue Problems
Finding the eigenvalues of a square matrix is a problem that arises in a wide variety of scientific and engineering applications. These applications include, for example, problems involving structural vibrations, energy levels in quantum systems, molecular vibrations, and analysis of systems of linear differential equations. The eigenvalue problem is a special case of the nonlinear problem, so the only way to compute eigenvalues is to use iterative methods. This chapter presents two of the most important numerical techniques for solving eigenvalue problems: the power method and the QR method. We restrict our attention to eigenvalues of real matrices, although much of the theory extends to matrices with complex entries. We begin with a short review of basic facts regarding eigenvalue problems.
9.1 Basic Facts concerning Eigenvalue Problems
Common linear algebra background is presented in section 8.1. Here we will consider some specific definitions related to the eigenvalue problem. In general, this problem is formulated as
where A and M are square N by N matrices and pair (λn, zn) is an eigenvalue and associated eigenvector. In particular, this problem arises in the analysis of structural vibrations. We restrict our attention to a simpler problem (the standard eigenvalue problem):
The spectrum of a matrix A is the set of all N eigenvalues of A, and these eigenvalues are defined as zeros of the characteristic polynomial det(A−λI). Eigenvectors zn (n = 1.…, N) form a system of orthonormal vectors:
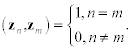
In general, a square matrix A may have complex eigenvalues. Only matrices with a special property have exclusively real eigenvalues. These matrices are called Hermitian. Let “H” denote the successive application of two operations: complex conjugation and transposition, then a matrix A is Hermitian if A = AH. In particular, a real symmetric matrix is a special case of a Hermitian matrix.
To be more specific, let us assume the following numbering of eigenvalues:
By this means, λ1 is the eigenvalue with smallest magnitude and λN is the eigenvalue with largest magnitude.
The Rayleigh quotient for a matrix A is

for any x ≠ o. It plays an important role in the computation of eigenvalues because of its interesting properties, which are (1) λ1 ≤ ρ(x) ≤ λN for all nonzero x∈RN; (2) if x = zn, then λ(x) = λn; and (3) on the basis of the previous property, the residual vector for the eigenvalue problem is introduced as
and the inequality ![]() r(x)
r(x)![]() ≤
≤ ![]() Ax − αx
Ax − αx![]() holds for any λ. Therefore, if x is some approximation to zn, then λ(x) is the best approximation to λn
holds for any λ. Therefore, if x is some approximation to zn, then λ(x) is the best approximation to λn
9.2 Localization of Eigenvalues
Often one can obtain information about the location of eigenvalues in the complex plane without much computational effort. One of the easiest methods to use is based on the following theorem.
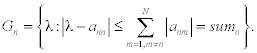
The set Gn defined in expression (9.2) is called the nth Gerschgorin disk of A. When all eigenvalues are real, then Gerschgorin disks are simply intervals. If n disks form the domain G isolated from other disks, then G contains exactly n eigenvalues of a matrix A. Hence the union of the Gerschgorin disks contains all eigenvalues of a matrix A. It is sometimes possible to get information about the disk that contains a single eigenvalue. This can be realized for matrices with specific properties, namely: if at some n for all k = 1, …, N(k ≠ n), the following inequalities are fulfilled
then the Gerschgorin disk |λ − ann| ≤ sumn contains a single eigenvalue.
9.3 Power Method
This is a classical method used mainly in finding the dominant eigenvalue and eigenvector associated with this eigenvalue. It is not a general method, but it might be useful in a number of situations. For example, it is sometimes an appropriate method for large sparse matrices. In addition, the scheme of this method reveals some important aspects of the eigenvalue problem.
The power method is an iterative process to find eigenvectors of A. To begin with, let us perform some preliminary analysis. Take some initial vector x(0) and suppose that all eigenvalues are different in magnitude. One can expand the vector x(0) in terms of eigenvectors of A:
Multiplying the vector x(0) repeatedly by the matrix A, we obtain
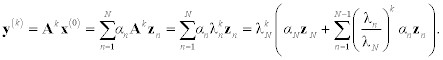
When k → ∞, y(k): approaches a vector that is collinear with zN. Thus, taking successive powers of A yields information about its eigenvalue λN. It is easy to find the dominant eigenvalue from this iteration. Taking into account the second property of the Rayleigh quotient, λ(y(k)) approaches λN when k → ∞.
Incorporating these observations, one can suggest the following implementation of the power method:
1) Define an initial vector x(0),
2) For every k = 0. 1, …, compute y(k + 1) = Ax(k),
3) Compute the next approximation as x(k + 1) = y(k + 1)/![]() y(k + 1)
y(k + 1)![]() . (This procedure, called normalization, is used to prevent either machine overflow or underflow.)
. (This procedure, called normalization, is used to prevent either machine overflow or underflow.)
4) Conclude the process if at some k, ![]() x(k + 1) − x(k)
x(k + 1) − x(k)![]() ≤ εp… Then x(k + 1) is an approximate eigenvector zN and sN = ρ(x(k)) is an approximate dominant eigenvalue λN.
≤ εp… Then x(k + 1) is an approximate eigenvector zN and sN = ρ(x(k)) is an approximate dominant eigenvalue λN.
Convergence of the power method
If all |λn| are different and (zn,x(0)) ≠ 0, then
and the following estimate holds:

Thus, the rate of convergence of the power method depends on the gap between |λN − 1| and |λN|.
If we need only the eigenvalue of a symmetric matrix A, then we can perform many fewer iterations. Let x(k) be some approximation to zn, so zn = x(k) + e(k) and ![]() e(k)
e(k)![]() = δ. The Rayleigh quotient for the vector x(k) is
= δ. The Rayleigh quotient for the vector x(k) is
By this means, approximation x(k) converges linearly to zn, but λ(x(k)) converges quadratically to λn.
The following implementation of power method is used to find the eigenvalue and eigenvector of the given square matrix. The function takes three input arguments; the square matrix, initial guess vector and error tolerance.
We want to find out an eigenvector and the corresponding eigenvalue for the given matrix in the following.
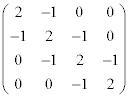
The pwr function will be called as follows.
Vector x is the eigenvector whereas value of l (3.6180) is an eigenvalue of the matrix A. It took 34 iterations to reach the solution with the desired accuracy of 10− 5.
9.4 Inverse Iteration
The method of inverse iteration amounts to the power method applied to an appropriate inverse matrix. Let us consider briefly the main ideas behind the method. By multiplying by A− 1, we can rewrite eigenvalue problem (9.1) in the following form:
This means that the eigenvector of a matrix A is the eigenvector of the matrix A− 1 and λn(A− 1) = 1/λn(A). Let us take some initial vector x(0) and expand it in terms of eigenvectors of A:
Multiplying the vector x(0) repeatedly by the matrix A− 1, we obtain

When k → ∞, y(k) approaches a vector that is collinear with z1. Thus, taking successive powers of A− 1 yields information about the eigenvalue of A, which is smallest in magnitude. In practice, we do not compute A− 1 explicitly. Instead, it is much less expensive to solve Ay = x with respect to y, then compute y = A− 1x. Incorporating these observations, we can suggest the following implementation of the method of inverse iteration:
(1) Define an initial vector x(0).
(2) For every k = 0, 1, …, solve the system of linear equations Ay(k + 1) = x(k).
(3) Compute the next approximation as x(k + 1) = y(k + 1)/![]() y(k + 1)
y(k + 1)![]() .
.
(4) Conclude the process if at some k, ![]() x(k + 1) − x(k)
x(k + 1) − x(k)![]() ≤ εp. Then x(k + 1) is an approximate eigenvector z1, and s1 = λ(x(k + 1)) is an approximate eigenvalue λ1.
≤ εp. Then x(k + 1) is an approximate eigenvector z1, and s1 = λ(x(k + 1)) is an approximate eigenvalue λ1.
Convergence of the method of inverse iteration
If all |λn| are different and (z1,x(0)) ≠ 0, then
and the following estimate holds:

Thus, the rate of convergence of the method of inverse iteration depends on the gap between |λ1| and |λ2|.
The method of inverse iteration is more expensive than the power method, because we have to solve a system of linear equations at every step of the iterative process. However, the matrix A remains the same as we iterate, so we can initiate the algorithm by computing a factorization for A once (see 8.6), and then each iteration requires only forward and backward substitutions.
The following function implements the inverse iteration method. It uses the Jacobi function to solve the system of linear equations. The function signature is the same as in previous implementation of pwr method.
We apply this function on the same problem as in the last section.
This method finds a different eigenvector and eigenvalue compared to last method but it takes only 10 iterations. The actual cost of this method is hidden in solving the system of linear equations using the Jacobi method.
9.5 Iteration with a Shift of Origin
Often in practice it is more convenient to apply iterations not to a matrix A, but to the matrix B = A − σI (σ = const ≠ 0 is a shift of origin). This essentially does not change eigenvalue problem (9.1), because eigenvectors of A coincide with those of the matrix B and λn(A) = λn(B) + σ. In this case the power method will converge to some eigenvector zn associated with the eigenvalue
and the asymptotic error constant is
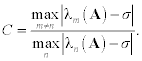
The method of inverse iteration will converge to some eigenvector zn associated with the eigenvalue
and the asymptotic error constant is

There are two situations in which we should use a shift of origin. In the first case, let |λN| and |λN − 1| be equal or very close for a given matrix A. By using the power method, we will fail to get convergence either to zN or to zN − 1 (or convergence will be very slow). When λ ≠ 0, all λn(B) are different in magnitude; therefore, we will get convergence.
For the second situation in which we should use a shift of origin, suppose we seek the eigenvalue of A lying closest to a prescribed point ß,
Then the method of inverse iteration with σ = ß converges to zm.
In the following, we implement the power and inverse iteration methods with shift of origin. These implementations are based on the previous implementations. The function signatures remain the same except the addition of shift parameter, s.
We apply the above functions to find the eigenvector and eigenvalue for the following matrix.

9.6 The QR Method
The most widely used method for computing eigenvalues is the QR method. This method has several valuable features: (1) it finds all eigenvalues of a matrix; (2) its behavior in the presence of equal-magnitude eigenvalues allows us to get some useful information about the spectrum of a matrix; and (3) it is simplified when the matrix under consideration is symmetric.
The idea of the QR method is simple. Given A, we factorize A = A(0) = QR, where Q is an orthogonal matrix and R is an upper triangular matrix. We then compute a new matrix A(1) = RQ. The procedure continues by induction: given A(k) = Q(k)R(k), we compute A(k + 1) = R(k)Q(k). The procedure is straightforward, but it produces a very interesting result: if all |λn| are different, then

By this means, we can compute all eigenvalues in one iterative process. However, the QR method as outlined requires too much arithmetic to be practical. For a general matrix A, each QR factorization requires O(N3) operations. To overcome this obstacle, one can perform an initial transformation on A that reduces it to a form for which succeeding QR factorizations are much cheaper. In particular, we begin the QR method by converting A to HA, which is in Hessenberg form:
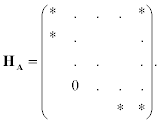
After this reduction, it is possible to compute the QR factorization of the initial matrix A(0) = HA in O(N2) operations. More importantly, each matrix A(k) remains in Hessenberg form. For symmetric matrices, the Hessenberg form is tridiagonal, so much less arithmetic and storage are required. To evaluate convergence, we can monitor the decay of the subdiagonal entries an + l.n in the matrices A(k); alternatively we can also monitor the decay of
The following algorithm summarizes all considerations outlined:
1) Reduce A to Hessenberg form, A → Ha = A(0).
2) For every k = 0, 1, …, compute the QR factorization of A(k): A(k) = Q(k),R(k); then the approximation that follows is A(k + 1) = R(k)Q(k).
then the entries ann(k) are approximate eigenvalues of A and |λn(A) − ann(k)| ≤ εp.
If all |λn| are different, then the matrices A(k) will converge to an upper triangular matrix T (see (9.4)), which contains the eigenvalues λn in diagonal positions. If A is symmetric, the sequence {A(k)} converges to a diagonal matrix.
The following estimate of convergence holds:
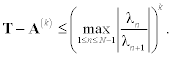
As we can see, convergence is absent if only two eigenvalues have equal magnitude (or it is slow, if their magnitudes are close). This is not so rare, especially for nonsymmetric matrices, because in this case eigenvalues occur as complex conjugate pairs. As with the power method of section 9.5, we can use shifts of origin in order to achieve convergence.
The qr function to find the QR factors of a matrix is a built-in function so there is no need to implement again. In the following function, we use this method to find out all eigenvalues of a given matrix.
We want to find out all the eigenvalues of the following matrix.
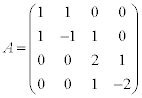
The answer is incorrect since it takes zero iteration to reach the solution which is impossible. Now, we will shift the origin of given matrix A by s = 1 then apply the same function.
The shift matrix converged to the solution in 7 iterations. In order to get the eigenvalues of original matrix A, we subtracted the shift value s = 1 from vector l.
9.7 Exercises
Given symmetrical matrix A, solve one of the following problems:
1. calculate the dominant eigenvalue using the power method,
2. calculate the smallest in magnitude eigenvalue using the inverse iteration,
Methodical comments: to solve systems of linear equations in the method of inverse iteration use the LU-factorization; to transform matrix into Hessenberg form in QR method use the function hess (A).