
Subsequently, we check the correlation between open issues and repository size for deep learning and open-source.
x = df['open_issues'] y = df['size']
ax.set(title='Deep Learning and Open Source Technologies', xlabel='Number of open issues', ylabel='Repos size')
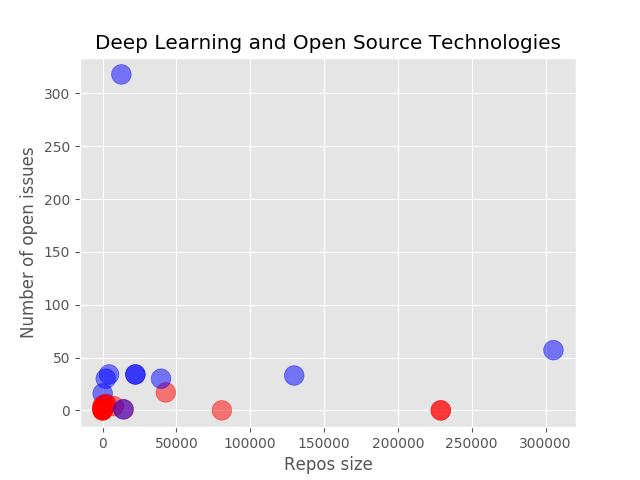
In the distribution between Size and Open Issues, we observe that both deep learning and open-source projects are a mix of large sized projects and smaller projects. However, there isn't a correlation between size of project and the open issues submitted as we see that the project with the most issues submitted is one of the smaller sized ones.