
Chapter 4: Planning the Research Programming Project
Introduction and Goals of This Chapter
Our Project’s High-Level Requirements
Our Project’s Quality Assurance Plan
Our Project’s Data Storage and LIBNAMES
Our Research Programming Technical Specifications
Our goal in this chapter is to plan our research programming project. As you will see, the planning process is a fundamental part of any research programming effort. In my experience, aside from a misunderstanding of data, the lack of a methodical and comprehensive programming plan is the most common reason that research programming efforts struggle or even fail.
I bet I know what you are thinking right now: “Are you kidding me? We are talking about research programming! I mean, how can you plan something that no one has done before? By its very nature, research means adapting to new information and changing approaches to answering questions! Planning is just a waste of time! Besides, I want to get cracking and write some code!” I have to admit that it is very tempting to skip the planning process and just dive right in to the work! After all, for many programmers, writing out a methodical plan is right up there with major dental work! It is not something most people consider particularly fun, especially when we could be combing through data and answering research questions! However, be forewarned: Failure to plan properly will greatly increase the likelihood of rework, costing valuable time and money (and causing unneeded stress and anxiety). For example, can you imagine coding for three months only to realize you forgot to request an important variable? What if you had to put the project on hold while waiting for data to be re-extracted and delivered?
The cornerstone of this chapter is that planning a research programming project is not only possible and necessary, but extremely helpful. Although a formal project plan and documentation may seem like overkill or unnecessarily rigid, it is important to remember that even a small research programming project can become very complicated, use many datasets, process large files, generate a tremendous amount of code, and produce numerous output files.
Viewing a research programming project as the construction of an information system and using traditional information systems approaches to planning mitigates the risk of error and produces a higher quality product. Besides, although no two research programming projects are exactly alike, many similarities exist that make planning a little easier. For example, most every research programming project needs to acquire data, create files for analysis, calculate and summarize results, and generate output. In addition, many research programming efforts must modify code based on the iterative feedback of the research process. Finally, many projects reference code and, importantly, the reasoning behind methodological and coding decisions, many months or even years after the completion of a particular task or the project as a whole (you would be surprised at the speed with which important details and reasoning leave your brain!).
Many planning tools exist and many books cover the science of planning a programming project much more comprehensively than this chapter!1 The tools you choose must meet the specific needs of your project. In my experience, the tools discussed in this book are applicable to the vast majority of research programming efforts. However, there are projects for which you should consider alternative methods. For example, projects that produce reports on a quarterly basis may need a more rigorous and formalized approach that includes separate development and production phases and change request documents. Very short-term projects that will produce a single, simple deliverable may not require much of a formal planning structure.
In this chapter, I recommend an approach to planning a medium or large research programming project, starting with the development of an overall project plan based on the Systems Development Life Cycle (SDLC), an organized approach to planning and executing a programming project. This plan includes instructions for designing quality assurance (QA) procedures, developing a requirements document that defines the objectives of the project at a high level, and creating a set of technical specifications that detail the programming steps required to meet the project objectives.
By the end of this chapter, we will develop our overall project plan, as well as our high-level requirements and QA plan. We introduce the concept of technical specifications, but we will tackle the development of detailed technical specifications in subsequent chapters as we write code.
There are many ways to approach the development of a plan for research programming work. Depending on the complexity and duration of your project, it may suffice to list all of the known tasks starting with requesting data and ending with the production and archiving of output and SAS code. For projects that are more complex, like the research programming effort covered in this book, I prefer to execute the planning process within the framework of the SDLC.
The SDLC is a systematic approach to creating an information system. The SDLC divides the creation of a system into phases, including the development of requirements, the design of the system based on the requirements, the creation and testing of code, implementation of the code, and disposition of the system. While these phases may sound foreign, they are really quite simple when expressed in terms that are more familiar. The SDLC brings order to managing a project by asking those working on the project to:
• Fully develop, define, and document the research questions and the approach to answering those questions
• Develop code that adheres to the approach to answering the questions
• Test, quality assure, execute, document that code, and provide output
• Close out the project (including the destruction of protected, identifiable data as required by CMS)
You can choose from many different SDLC methodologies. Some methodologies, like agile development, facilitate changes during the development of code. Other methodologies, like waterfall, rely on the creation of a more comprehensive plan from the start and, therefore, are less conducive to a project that relies on an iterative process.
Many authors have written books on the SDLC, and a complete study is out of the scope of this text. For our purposes, we will not focus on choosing an SDLC methodology because the basic steps of any SDLC methodology are a sufficient framework for our project plan. The basic steps of the SDLC, as adapted for our research programming purposes, are:
1. Initiation, Planning, and Design
a. Develop and finalize high-level project requirements
b. Develop a plan for quality assurance
c. Develop and finalize a project flowchart
d. Develop and finalize initial research programming specifications
e. Develop quality assured programming specifications and system flow diagram
f. Request data based on programming specifications and systems design
2. Develop and Test Code
a. Develop code according to plan and design
b. Test and quality assure code
3. Implementation
a. Execute code in batch and retain logs, lists, and milestone datasets
4. Disposition
a. Document code
b. Archive final code, logs, lists, and data (if applicable and according to contractual arrangements)
c. Destroy data as applicable
For the remainder of this chapter we will focus on fleshing out Step 1. More specifically, we will flesh out high-level requirements and the quality assurance plan for our project (Step 1.a. and Step 1.b.), and discuss the programming technical specifications (Step 1.c. and Step 1.d). However, as discussed in the introduction, we will not actually write the technical specifications until we tackle coding in subsequent chapters. The discussion of technical specifications in subsequent chapters is really for instructional purposes; in an ideal world, we would draft technical specifications prior to launching our programming effort and simply tweak them as we work through our research. Therefore, Chapters 5-8 focus on Step 1.d. through Step 1.f. (Initiation, Planning and Design), as well as Step 2 (Develop and Test Code). In fact, Chapter 5 through Chapter 9 (and some of Chapter 10) essentially read like very detailed technical specifications that contain a lot of instructional information! Chapter 10 includes information on Step 3 and Step 4.
The purpose of high-level requirements is to state the objectives of the project in very broad terms. These requirements assist us in getting a handle on the goals of the project and staying on course throughout the life of the project. Typically, requirements list the research questions, source data needs, output requirements, and timeframes. The high-level requirements for our research programming project are:
• We will write programs to answer the research questions described in Chapter 1.
• We will create descriptive output to answer the research questions posed in Chapter 1.
• We will use Medicare claims and enrollment data for calendar year 2010. Specifically, we will request enrollment data and all Medicare Part A and Part B claims data for all beneficiaries seen by the providers in our study population for that calendar year.
• We will use a desktop PC with ample storage and BASE SAS to perform all data work for our project.
• We will complete our project objectives in three months.
• We will destroy all data in compliance with contractual agreements upon successful completion of the project.
The purpose of a quality assurance (QA) plan is to explicitly state the project’s QA objectives and determine a plan of attack for meeting those objectives. Our objective is to develop code that accurately reflects the objectives outlined in the programming specifications. To this end, we will adhere to the following QA rules:
• We will QA our programming specifications.
• We will perform unit testing (testing individual sections of code) and debugging.
• We will employ technical peer reviews of our code.
• We will test the integration of the system as a whole.
• We will investigate the validity of our output.
• We will batch submit our code in production and clearly label and save our logs and lists. In addition, we will erase output before resubmitting (this avoids accidentally using data from prior submissions of code).
The reader will need to trust me that the development and integration of our code is unit tested and debugged and the requirements and code were reviewed by peers. The reader will also need to take me at my word that I batch submitted all code, as well as clearly labeled copies of logs and lists and adhered to sound data management practices.
This section discusses the creation of a flowchart of the steps involved in executing our research programming project. Flowcharts and diagrams help the programmer discover and work through design issues both within programs and between programs that, when integrated, comprise a system. In addition, they serve as a very useful form of documentation, summarizing many pages of complex processes in a couple of pictures. Before we go too far down the road of creating our flowchart, it is helpful to discuss terminology and distinguish between common types of flowcharts and diagrams. Terms like flowchart, flow diagram, process flowchart, and process map are often used interchangeably. Because this is not a book about flowcharts and diagrams, we will keep things simple and use the term “flowchart” when discussing any picture that describes how processes and controls work together as a project, a program, or a system. We will use the term “diagram” when we describe the flow of data. More specifically, in this book:
• Project flowcharts focus on the workflow of tasks for a project, or within a specific task in a project. We will create a workflow diagram for our project in this section.
• Program flowcharts describe the flow of programs within a system (a set of programs), while others describe the flow of processing steps within a single program.2
• Data flow diagrams describe the flow of data within or between programs.
The below project flowchart, Figure 4.1, focuses on the flow of tasks that we must accomplish to complete our research programming project. The purpose of our flowcharting exercise is to document the steps involved in executing our research programming project, describe how steps may interact with each other, and assist in planning our work. It is the equivalent of a blueprint for building a house and helps us plot out each step and identify the most efficient arrangement of our activities.
Figure 4.1: Research Programming Flowchart
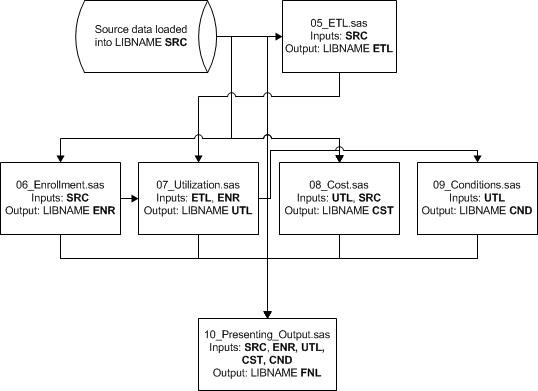
This flowchart pictorially represents our programming plan as follows:
• As we will discuss in Chapter 5 (and mentioned briefly in Chapter 1), our source data are comprised of extracted claims and enrollment SAS data sets, as well as a finder file of providers and associated beneficiary identifiers. In addition, as we will discuss in Chapter 6, we downloaded a geographic code file from the internet into our source data library.
• The program 05_ETL.sas, developed in Chapter 5, transforms our source claims SAS data files. The output is used in our work in Chapter 7 (to delimit our claims data using the continuous enrollment information derived in Chapter 6).
• The program 06_Enrollment.sas, developed in Chapter 6, uses the enrollment source SAS data set to create a continuous enrollment data set. It also uses the geographic codes file loaded into a SAS data set to add state and county names to a data set of continuously enrolled beneficiaries. This output is used in Chapters 7 and 10 for demographic information and to delimit our claims data, keeping only those claims for continuously enrolled beneficiaries.
• The program 07_Utilization.sas, developed in Chapter 7, uses the source claims SAS data sets transformed in the program 05_ETL.sas as well as the continuous enrollment data created in the program 06_Enrollment.sas to create claims files delimited to contain only claims for continuously enrolled beneficiaries. It also creates inpatient claims data delimited to acute short stay hospitals. These claims are used to calculate utilization, cost, and quality measurements in Chapters 7, 8, and 9, respectively. In addition, utilization summary files created in the program 07_Utilization.sas are used in Chapter 10.
• The program 08_Cost.sas, developed in Chapter 8, uses the claims data created in the program 07_Utilization.sas to compute measures of cost to Medicare. It also uses the raw carrier source data set to perform an exercise in working with a data set comprised of one record per claim line. Cost summary files created in the program 08_Cost.sas are used in Chapter 10.
• The program 09_Conditions.sas, developed in Chapter 9, uses the claims data created in the program 07_Utilization.sas (as well as the E&M utilization summary created in that same program) to identify beneficiaries with diabetes or COPD, and to compute certain measurements for those beneficiaries. Summary files created in the program 09_Conditions.sas are used in Chapter 10.
• The program 10_Presenting_Output.sas, developed in Chapter 10, uses summary files created in the programs 07_Utilization.sas, 08_Cost.sas, and 09_Conditions.sas, as well as enrollment data created in 06_Enrollment.sas, and our “finder file” of providers and associated beneficiaries.
Before we begin any programming, it is worth drawing on the above discussion to determine the SAS libraries we will use for storing our example project’s data sets. We will use the following LIBNAME statements for the remainder of our work. Our data storage plan involves separating input and output data sets logically by task (or, in our case, chapter). The storage path may differ for each reader based on the organization of storage on your particular system.
• libname SRC 'C:DATA�0_Source_Data': This library contains all data received from CMS’s data distribution contractor, loaded into SAS data sets using code that came with our data (which will not be displayed in this book). The library also contains any other source data files, including the finder file SAS data set received from CMS and geographic codes file. I recommend making a backup copy of this source data folder if possible—as long as we are acting in accordance with any contractual arrangements, and we remember to delete it as part of the disposition of our project (see Chapter 10).
• libname ETL 'C: DATA�5_ETL': This library contains the “extracted, transformed, and loaded” data. For example, this folder contains the claims data modified to contain one claim per record (as briefly discussed in Chapter 3 and covered in more detail in Chapter 5) for use throughout the remainder of our project.
• libname ENR 'C:DATA�6_Enrollment': This library contains the output (and milestone data) from our work on enrollment. For example, the data set containing enrollment and state and county name information for beneficiaries identified as continuously enrolled throughout 2010 (ENR.CONTENR_2010_FNL) is stored in this library.
• libname UTL 'C:DATA 07_Utilization': This library contains the output (and milestone data) from our work measuring utilization.
• libname CST 'C:DATA�8_Cost': This library contains the output (and milestone data) from our work measuring cost.
• libname CND 'C:DATA�9_Conditions': This library contains the output (and milestone data) from our work studying chronic conditions and simple quality measurements.
• libname FNL 'C:DATA10_Results': This library contains the output (and milestone data) from our work presenting the results of our example programming project.
Note that the folders are numbered so they can be sorted to appear in the order in which the code is executed.
As stated above, we will tackle the creation of detailed technical specifications in Chapters 5 through 10. However, it is worth pausing to introduce the concept of technical specifications in advance of those chapters. The purpose of programming specifications is to guide the development of SAS code by providing written instructions on what the SAS code must do to create the required output. In addition, specifications document the reasoning behind important methodological and coding decisions. Specifications come in many forms and describe what needs to be done at many different levels; some specifications state the project objectives (“what” must be done) at a very high level, while other types of specifications provide a lot of detail on “how” to do what needs to be done.
Research programming specifications are different from other kinds of programming specifications in that they contain less upfront detail and more room for iterative development and discovery. Typically, good research programming specifications state the objectives of the project (by clearly describing the research questions intended to be answered) and provide information on the inputs required (including the datasets and variables needed), the calculations to be performed, and the required output. Therefore, team members that understand the research questions and the data must write the specifications. Even if you are a one-person team who is formulating the research questions and answering them by writing and executing SAS code, it is worth creating specifications because they help identify all of the processing steps upfront. At the least, it is a best practice to use programming specifications to guide any code walkthrough or technical review of our code.
Construction and carpentry provide many excellent metaphors for programming. I am fond of home improvement projects (and it is a good thing I am, because there is no shortage of such projects around my house, which was built in 1855!). I often find myself thinking about how building a table, installing a chair rail, or patching up an old wall made of field stone is like building a system of code. For example, we can consider plans based on the SDLC to be architectural blueprints. Similarly, technical specifications are the programmer’s equivalent to the carpenter’s mantra of “measure twice and cut once.” Technical specifications help you think through what data you will need, what variables you will use, and any issues related to data processing and storage. If you cut a piece of crown molding to an incorrect length, it can result in the need to purchase (or worse, rebuild) replacement crown molding and perform the measuring and cutting again. In the same way, if you fail to identify and think through all of the major steps in your programming effort, it can result in moving forward with data extraction and coding only to later realize that you left something out. For example, planning how you will identify beneficiaries who are continuously enrolled in Medicare Fee-for-Service helps you to formulate your study population. Repeating the data extraction for the study population to compensate for a mistake can result in a lot of lost time! In the end, even the best plans will not execute exactly as planned (it is research, after all), so it is important to document changes that happen along the way.
In this chapter, we planned our research programming project. The planning process is a fundamental part of any research programming effort. The fact that we are performing research and expect to encounter many unknowns is not an excuse for circumventing the planning process. Rather, the existence of unknown information in our project is a very good reason to devote a lot of time to formulating our project plan. Indeed, the lack of appropriate planning is perhaps the major reason for the failure of research programming projects. To this end, we discussed the following:
• Our recommended approach to planning a medium or large research programming project involves starting with the development of an overall project plan based on the Systems Development Life Cycle (SDLC).
• A plan based on the SDLC includes instructions for quality assurance (QA), a requirements document defining the objectives of the project at a high level, and a set of technical specifications that describe in detail the programming steps required to meet the project objectives.
• The basic steps of the SDLC are initiation, planning and design, developing and testing code, implementation, and project disposition.
• High-level requirements state the objectives of the project in very broad terms, and assist us in identifying the goals of the project and staying focused throughout the life of the project. Typically, requirements list the research questions, source data needs, output requirements, and timeframes. We developed high-level requirements for our research programming project.
• A QA plan explicitly states the project’s QA objectives and determines a plan of attack for meeting those objectives. We developed a QA plan for our research programming project.
• Flowcharts and diagrams help the programmer discover and work through design issues both within programs and between programs that comprise a system. In addition, they serve as a very useful form of documentation, summarizing many pages of complex processes in a couple of pictures. We developed a flowchart of the major tasks involved in our research programming project.
• Technical specifications guide the development of SAS code by providing written instructions on what the SAS code must do to create the required output. In addition, specifications document the reasoning behind important methodological and coding decisions. Good research programming specifications state the objectives of the project and provide information on the inputs required, the calculations to be performed, and the required output. We will develop our project’s technical specifications in Chapter 5 through Chapter 10.
• We laid out the data storage strategy for our programming work, numbering the folders so they can be sorted in the order in which the code is executed.
1 See, for example, McConnell, Steve. 2004. Code Complete, Second Edition. Washington: Microsoft Press.
2 It would be best to have detailed technical specifications in hand when creating the flowchart for a program or system of programs. We will not create flowcharts for our programs or data flow diagrams in this book, but I do recommend it for planning and documentation purposes.