
The Exactly once processing paradigm is similar to the at least once paradigm, and involves a mechanism to save the position of the last event received only after the event has actually been processed and the results persisted somewhere so that, if there is a failure and the consumer restarts, the consumer will read the old events again and process them. However, since there is no guarantee that the received events were not processed at all or were partially processed, this causes a potential duplication of events as they are fetched again. However, unlike the at least once paradigm, the duplicate events are not processed and are dropped, thus resulting in the exactly once paradigm.
Exactly once processing paradigm is suitable for any application that involves accurate counters, aggregations, or which in general needs every event processed only once and also definitely once (without loss).
The sequence of operations for the consumer are as follows:
- Save results
- Save offsets
The following is illustration shows what happens if there are a failure and the consumer restarts. Since the events have already been processed but offsets have not saved, the consumer will read from the previous offsets saved, thus causing duplicates. Event 0 is processed only once in the following figure because the consumer drops the duplicate event 0:
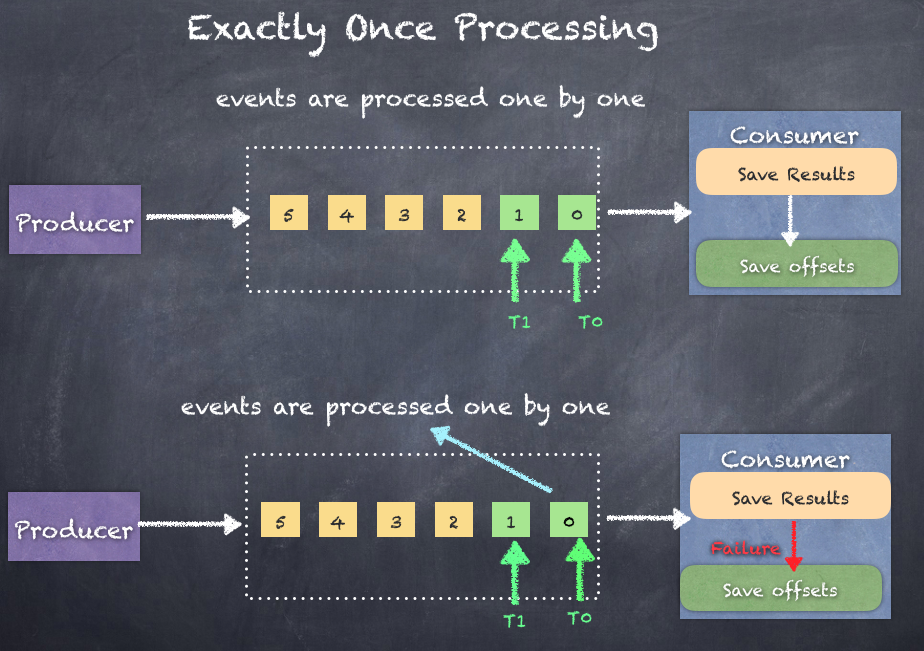
How does the Exactly once paradigm drop duplicates? There are two techniques which can help here:
- Idempotent updates
- Transactional updates
Idempotent updates involve saving results based on some unique ID/key generated so that, if there is a duplicate, the generated unique ID/key will already be in the results (for instance, a database) so that the consumer can drop the duplicate without updating the results. This is complicated as it's not always possible or easy to generate unique keys. It also requires additional processing on the consumer end. Another point is that the database can be separate for results and offsets.
Transactional updates save results in batches that have a transaction beginning and a transaction commit phase within so that, when the commit occurs, we know that the events were processed successfully. Hence, when duplicate events are received, they can be dropped without updating results. This technique is much more complicated than the idempotent updates as now we need some transactional data store. Another point is that the database must be the same for results and offsets.
We will be looking at the paradigms closely when we learn about Spark Streaming and how to use Spark Streaming and consume events from Apache Kafka in the following sections.