The best way of using SparkR is from RStudio. Your R program can be connected to a Spark cluster from RStudio using R shell, Rescript, or other R IDEs.
Option 1. Set SPARK_HOME in the environment (you can check https://stat.ethz.ch/R-manual/R-devel/library/base/html/Sys.getenv.html), load the SparkR package, and call sparkR.session as follows. It will check for the Spark installation, and, if not found, it will be downloaded and cached automatically:
if (nchar(Sys.getenv("SPARK_HOME")) < 1) {
Sys.setenv(SPARK_HOME = "/home/spark")
}
library(SparkR, lib.loc = c(file.path(Sys.getenv("SPARK_HOME"), "R", "lib")))
Option 2. You can also manually configure SparkR on RStudio. For doing so, create an R script and execute the following lines of R code on RStudio:
SPARK_HOME = "spark-2.1.0-bin-hadoop2.7/R/lib"
HADOOP_HOME= "spark-2.1.0-bin-hadoop2.7/bin"
Sys.setenv(SPARK_MEM = "2g")
Sys.setenv(SPARK_HOME = "spark-2.1.0-bin-hadoop2.7")
.libPaths(c(file.path(Sys.getenv("SPARK_HOME"), "R", "lib"), .libPaths()))
Now load the SparkR library as follows:
library(SparkR, lib.loc = SPARK_HOME)
Now, like Scala/Java/PySpark, the entry point to your SparkR program is the SparkR session that can be created by calling sparkR.session as follows:
sparkR.session(appName = "Hello, Spark!", master = "local[*]")
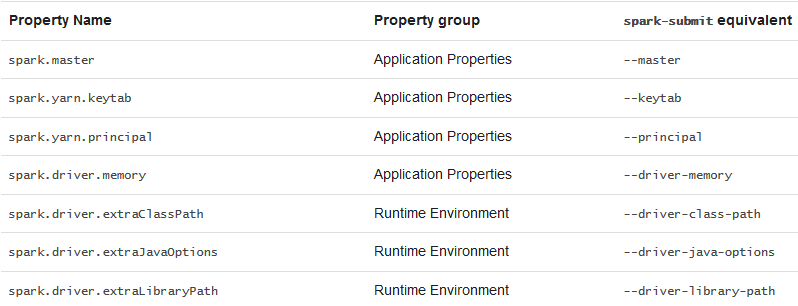
Furthermore, if you want, you could also specify certain Spark driver properties. Normally, these application properties and runtime environment cannot be set programmatically, as the driver JVM process would have been started; in this case, SparkR takes care of this for you. To set them, pass them as you would pass other configuration properties in the sparkConfig argument to sparkR.session() as follows:
sparkR.session(master = "local[*]", sparkConfig = list(spark.driver.memory = "2g"))
In addition, the following Spark driver properties can be set in sparkConfig with sparkR.session from RStudio: