
Chapter 1: An Overview of Amazon EMR
This chapter will provide an overview of Amazon Elastic MapReduce (EMR), its benefits related to big data processing, and how its cluster is designed compared to on-premises Hadoop clusters. It will then explain how Amazon EMR integrates with other Amazon Web Services (AWS) services and how you can build a Lake House architecture in AWS.
You will then learn the difference between the Amazon EMR, AWS Glue, and AWS Glue DataBrew services. Understanding the difference will make you aware of the options available when deploying Hadoop or Spark workloads in AWS.
Before going into this chapter, it is assumed that you are familiar with Hadoop-based big data processing workloads, have had exposure to AWS basis concepts, and are looking to get an overview of the Amazon EMR service so that you can use it for your big data processing workloads.
The following topics will be covered in this chapter:
- What is Amazon EMR?
- Overview of Amazon EMR
- Decoupling compute and storage
- Integration with other AWS services
- EMR release history
- Comparing Amazon EMR with AWS Glue and AWS Glue DataBrew
What is Amazon EMR?
Amazon EMR is an AWS service that provides a distributed cluster for big data processing. Now, before diving deep into EMR, let's first understand what big data represents, for which EMR is a solution or tool.
What is big data?
The beginnings of enormous volumes of datasets date back to the 1970s, when the world of data was just getting started with data centers and the development of relational databases, despite the fact that the concept of big data was still relatively new. These technology revolutions led to personal desktop computers, followed by laptops, and then mobile computers over the next several decades. As people got access to devices, the data being generated started growing exponentially.
Around the year 2005, people started to realize that users generate huge amounts of data. Social platforms, such as Facebook, Twitter, and YouTube generate data faster than ever, as users get access to smart products or internet-related services.
Put simply, big data refers to large, complex datasets, particularly those derived from new data sources. These datasets are large enough that traditional data processing software can't handle its storage and processing efficiently. But these massive volumes of data are of great use when we need to derive insights by analyzing them and then address business problems with it, which we were not able to do before. For example, an organization can analyze their users' or customers' interactions with their social pages or website to identify their sentiment against their business and products.
Often, big data is described by the five Vs. It started with three Vs, which includes data volume, velocity, and variety, but as it evolved, the accuracy and value of data also became major aspects of big data, which is when veracity and value got added to represent it as five Vs. These five Vs are explained as follows:
- Volume: This represents the amount of data you have for analysis and it really varies from organization to organization. It can range from terabytes to petabytes in scale.
- Velocity: This represents the speed at which data is being collected or processed for analysis. This can be a daily data feed you receive from your vendor or a real-time streaming use case, where you receive data every second to every minute.
- Variety: When we talk about variety, it means what the different forms or types of data you receive are for processing or analysis. In general, they are broadly categorized into the following three:
- Structured: Organized data format with a fixed schema. It can be from relational databases or CSVs or delimited files.
- Semi-structured: Partially organized data that does not have a fixed schema, for example, XML or JSON files.
- Unstructured: These datasets are more represented through media files, where they don't have a schema to follow, for example, audio or video files.
- Veracity: This represents how reliable or truthful your data is. When you plan to analyze big data and derive insights out of it, the accuracy or quality of the data matters.
- Value: This is often referred to as the worth of the data you have collected as it is meant to give insights that can help the business drive growth.
With the evolution of big data, the primary challenge became how to process such huge volumes of data, because the typical single system processing frameworks were not enough to handle them. It needed a distributed processing computing framework that can do parallel processing.
After understanding what big data represents, let's look at how the Hadoop processing framework helped to solve this big data processing problem statement and why it became so popular.
Hadoop – processing framework to handle big data
Though there were different technologies or frameworks that came to handle big data, the framework that got the most traction is Hadoop, which is an open source framework designed specifically for storing and analyzing big datasets. It allows combining multiple computers to form a cluster that can do parallel distributed processing to handle gigabyte- to petabyte-scale data.
The following is a data flow model that explains how the input data is collected, stored into Hadoop Distributed File System (HDFS), then processed with Hive, Pig, or Spark big data processing frameworks and the transformed output becomes available for consumption or is transferred to downstream systems or external vendors. It represents a high-level data flow, where input data is collected and stored as raw data. It then gets processed as needed for analysis and then made available for consumption:

Figure 1.1 – Data flow in a Hadoop cluster
The following are the main basic components of Hadoop:
- HDFS: A distributed filesystem that runs on commodity hardware and provides improved data throughput as compared to traditional filesystems and higher reliability with an in-built fault tolerance mechanism.
- Yet Another Resource Negotiator (YARN): When multiple compute nodes are involved with parallel processing capability, YARN helps to manage and monitor compute CPU and memory resources and also helps in scheduling jobs and tasks.
- MapReduce: This is a distributed framework that has two basic modules, that is, map and reduce. The map task reads the data from HDFS or a distributed storage layer and converts it into key-value pairs, which then becomes input to the reduce tasks, which ideally aggregates the map output to provide the result.
- Hadoop Common: These include common Java libraries that can be used across all modules of the Hadoop framework.
In recent years, the Hadoop framework became popular because of its massively parallel processing (MPP) capability on top of commodity hardware and its fault-tolerant nature, which made it more reliable. It was extended with additional tools and applications to form an ecosystem that can help to collect, store, process, analyze, and manage big data. Some of the most popular applications are as follows:
- Spark: An open source distributed processing system that uses in-memory caching and optimized execution for fast performance. Similar to MapReduce, it provides batch processing capability as well as real-time streaming, machine learning, and graph processing capabilities.
- Hive: Allows users to use distributed processing engines such as MapReduce, Tez, or Spark to query data from the distributed filesystem through the SQL interface.
- Presto: Similar to Hive, Presto is also an open source distributed SQL query engine that is optimized for low-latency data access from the distributed filesystem. It's used for complex queries, aggregations, joins, and window functions. The Presto engine is available as two separate components in EMR, that is, PrestoDB and PrestoSQL or Trino.
- HBase: An open source non-relational or NoSQL database that runs on top of the distributed filesystem that provides fast lookup for tables with billions of rows and millions of columns grouped as column families.
- Oozie: Enables workflow orchestration with Oozie scheduler and coordinator components.
- ZooKeeper: Helps in managing and coordinating Hadoop component resources with inter-component-based communication, grouping, and maintenance.
- Zeppelin: An interactive notebook that enables interactive data exploration using Python and PySpark kind of frameworks.
Hadoop provides a great solution to big data processing needs and it has become popular with data engineers, data analysts, and data scientists for different analytical workloads. With its growing usage, Hadoop clusters have brought in high maintenance overhead, which includes keeping the cluster up to date with the latest software releases and adding or removing nodes to meet the variable workload needs.
Now let's understand the challenges on-premises Hadoop clusters face and how Amazon EMR comes as a solution to them.
Challenges with on-premises Hadoop clusters
Before Amazon EMR, customers used to have on-premises Hadoop clusters and faced the following issues:
- Tightly coupled compute and storage architecture: Clusters used to use HDFS as their storage layer, where the data node's disk storage contributes to HDFS. In the case of node failures or replacements, there used to be data movement to have another replica of data created.
- Overutilized during peak hours and underutilized at other times: As the autoscaling capabilities were not there, customers used to do capacity planning beforehand and add nodes to the cluster before usage. This way, clusters used to have a constant number of nodes; during peak usage hours, cluster resources were overutilized and during off-hours, they were underutilized.
- Centralized resource with the thrashing of resources: As resources get overutilized during peak hours, this leads to the thrashing of resources and affects the performance or collapse of hardware resources.
- Difficulty in upgrading the entire stack: Setting up and configuring services was a tedious task as you needed to install specific versions of Hadoop applications and when you planned to upgrade, there were no options to roll back or downgrade.
- Difficulty in managing many different deployments (dev/test): As the cluster setup and configuration was a tedious task, developers didn't have the option to quickly build applications in new versions to prove feasibility. Also, spinning up different development and test environments was a time-consuming process.
To overcome the preceding challenges, AWS came up with Amazon EMR, which is a managed Hadoop cluster that can scale up and down as workload resource needs change.
Overview of Amazon EMR – managed and scalable Hadoop cluster in AWS
To give an overview, Amazon EMR is an AWS tool for big data processing that provides a managed, scalable Hadoop cluster with multiple deployment options that includes EMR on Amazon Elastic Compute Cloud (EC2), EMR on Amazon Elastic Kubernetes Service (EKS), and EMR on AWS Outposts.
Amazon EMR makes it simple to set up, run, and scale your big data environments by automating time-consuming tasks such as provisioning instances, configuring them with Hadoop services, and tuning the cluster parameters for better performance.
Amazon EMR is used in a variety of applications, including Extract, Transform, and Load (ETL), clickstream analysis, real-time streaming, interactive analytics, machine learning, scientific simulation, and bioinformatics. You can run petabyte-scale analytics workloads on EMR for less than half the cost of traditional on-premises solutions and more than three times faster than open source Apache Spark. Every year, customers launch millions of EMR clusters for their batch or streaming use cases.
Before diving into the benefits of EMR compared to an on-premises Hadoop cluster, let's look at a brief history of Hadoop and EMR releases.
A brief history of the major big data releases
Before we go further, the following diagram shows the release period of some of the major databases:

Figure 1.2 – Diagram explaining the history of major big data releases
As you can see in the preceding diagram, Hadoop was created in 2006 based on Google's MapReduce whitepaper and then AWS launched Amazon EMR in 2009. Since then, EMR has added a lot of features and its recent launch of Amazon EMR on EKS provides the great capability to run Spark workloads in Kubernetes clusters.
Now is a good time to understand the benefits of Amazon EMR and how its cluster is configured to decouple compute and storage.
Benefits of Amazon EMR
There are numerous advantages of using Amazon EMR, and this section provides an overview of these advantages. This will in turn help you when looking for solutions based on Hadoop or Spark workloads:
- Easy to use: You can set up an Amazon EMR cluster in minutes without having to worry about provisioning cluster instances, setting up Hadoop configurations, or tuning the cluster.
You get the ability to create an EMR cluster through the AWS console's user interface (UI), where you have both quick and advanced options to specify your cluster configurations, or you can use AWS command-line interface (CLI) commands or AWS SDK APIs to automate the creation process.
- Low cost: Amazon EMR pricing is based on the infrastructure on top of which it is deployed. You can choose from the different deployment options EMR provides, but the most popular usage pattern is with Amazon EC2 instances.
When we configure or deploy a cluster on top of Amazon EC2 instances, the pricing depends on the type of EC2 instance and the Region you have selected to launch your cluster. With EC2, you can choose on-demand instances or you can reduce the cost by purchasing reserved instances with a commitment of usage. You can lower the cost even further by using a combination of spot instances, specifically while scaling the cluster with task nodes.
- Scalability: One of the biggest advantages of EMR compared to on-premises Hadoop clusters is its elastic nature, using which you can increase or decrease the number of instances of your cluster. You can create your cluster with a minimal number of instances and then can scale your cluster as the job demands. EMR provides two scalability options, autoscaling and managed scaling, which scales the cluster based on resource utilization.
- Flexibility: Though EMR provides a quick cluster creation option, you have full control over your cluster and jobs, where you can make customizations in terms of setup or configurations. While launching the cluster, you can select the default Linux Amazon Machine Images (AMIs) for your instances or integrate custom AMIs and then install additional third-party libraries or configure startup scripts/jobs for the cluster.
You can also use EMR to reconfigure apps on clusters that are already running, without relaunching the clusters.
- Reliability: Reliability is something that is built into EMR's core implementation. The health of cluster instances is constantly monitored by EMR and it automatically replaces failed or poorly performing instances. Then new tasks get instantiated in newly added instances.
EMR also provides multi-master configuration (up to three master nodes), which makes the master node fault-tolerant. EMR also keeps the service up to date by including stable releases of the open source Hadoop and related application software at regular intervals, which reduces the maintenance effort of the environment.
- Security: EMR automatically configures a few default settings to make the environment secure, including launching the cluster in Amazon Virtual Private Cloud (VPC) with required network access controls and configuring security groups for EC2 instances.
It also provides additional security configurations that you can utilize to improve the security of the environment, which includes enabling encryption through AWS KMS keys or your own managed keys, configuring strong authentication with Kerberos, and securing the in-transit data through SSL.
You can also use AWS Lake Formation or Apache Ranger to configure fine-grained access control on the cluster databases, tables, or columns. We will dive deep into each of these concepts in later chapters of the book.
- Ease of integration: When you build a data analytics pipeline, apart from EMR's big data processing capability, you might also need integration with other services to build the production-scale implementation.
EMR has native integration with a lot of additional services and some of the major ones include orchestrating the pipeline with AWS Step Functions or Amazon Managed Workflows for Apache Airflow (MWAA), close integration with AWS IAM to integrate tighter security control, fine-grained access control with AWS Lake Formation, or developing, visualizing, and debugging data engineering and data science applications built in R, Python, Scala, and PySpark using the EMR Studio integrated development environment (IDE).
- Monitoring: EMR provides in-depth monitoring and audit capability on the cluster using AWS services such as CloudWatch and CloudTrail.
CloudWatch provides a centralized logging platform to track the performance of your jobs and cluster and define alarms based on specific thresholds of specific metrics. CloudTrail provides audit capability on cluster actions. Amazon EMR also has the ability to archive log files in Amazon Simple Storage Service (S3), so you can refer to them for debugging even after your cluster is terminated.
Apart from CloudWatch and CloudTrail, you can also use the Ganglia monitoring tool to monitor cluster instance health, which is available as an optional software configuration when you launch your cluster.
Decoupling compute and storage
When you integrate an EMR cluster for your batch or streaming workloads, you have the option to use the core node's HDFS as your primary distributed storage or Amazon S3 as your distributed storage layer. As you know, Amazon S3 provides a highly durable and scalable storage solution and Amazon EMR natively integrates with it.
With Amazon S3 as the cluster's distributed storage, you can decouple compute and storage, which gives additional flexibility. It enables you to integrate job-based transient clusters, where S3 acts as a permanent store and the cluster core node's HDFS is used for temporary storage. This way, you can decouple different jobs to have their own cluster with the required amount of resources and scaling in place and avoid having an always-on cluster to save costs.
The following diagram represents how multiple transient EMR clusters that contain various steps can use S3 as their common persistent storage layer. This can also help for disaster recovery implementation:

Figure 1.3 – Multiple EMR clusters using Amazon S3 as their distributed storage
Now that you understand how EMR provides flexibility to decouple compute and storage, in the next section, you will learn how you can use this feature to create persistent or transient clusters depending on your use case.
Persistent versus transient clusters
Persistent clusters represent a cluster that is always active to support multi-tenant workloads or interactive analytics. These clusters can have a constant node capacity or a minimal set of nodes with autoscaling capabilities. Autoscaling is a feature of EMR, where EMR automatically scales up (adds nodes) or scales down (removes nodes) cluster resources based on a few cluster utilization parameters. In future chapters, we will dive deep into EMR scaling features and options.
Transient clusters are treated more as job-based clusters, which are short-lived. They get created with data arrival or through scheduled events, do the data processing, write the output back to target storage, and then get terminated. These also have a constant set of nodes to start with and then scale to support the additional workloads. But when you have transient cluster workloads, ideally Amazon S3 is used as a persistent data store so that after cluster termination, you still have access to the data to perform additional ETL or business intelligence reporting.
Here is a diagram that represents different kinds of cluster use cases you may have:
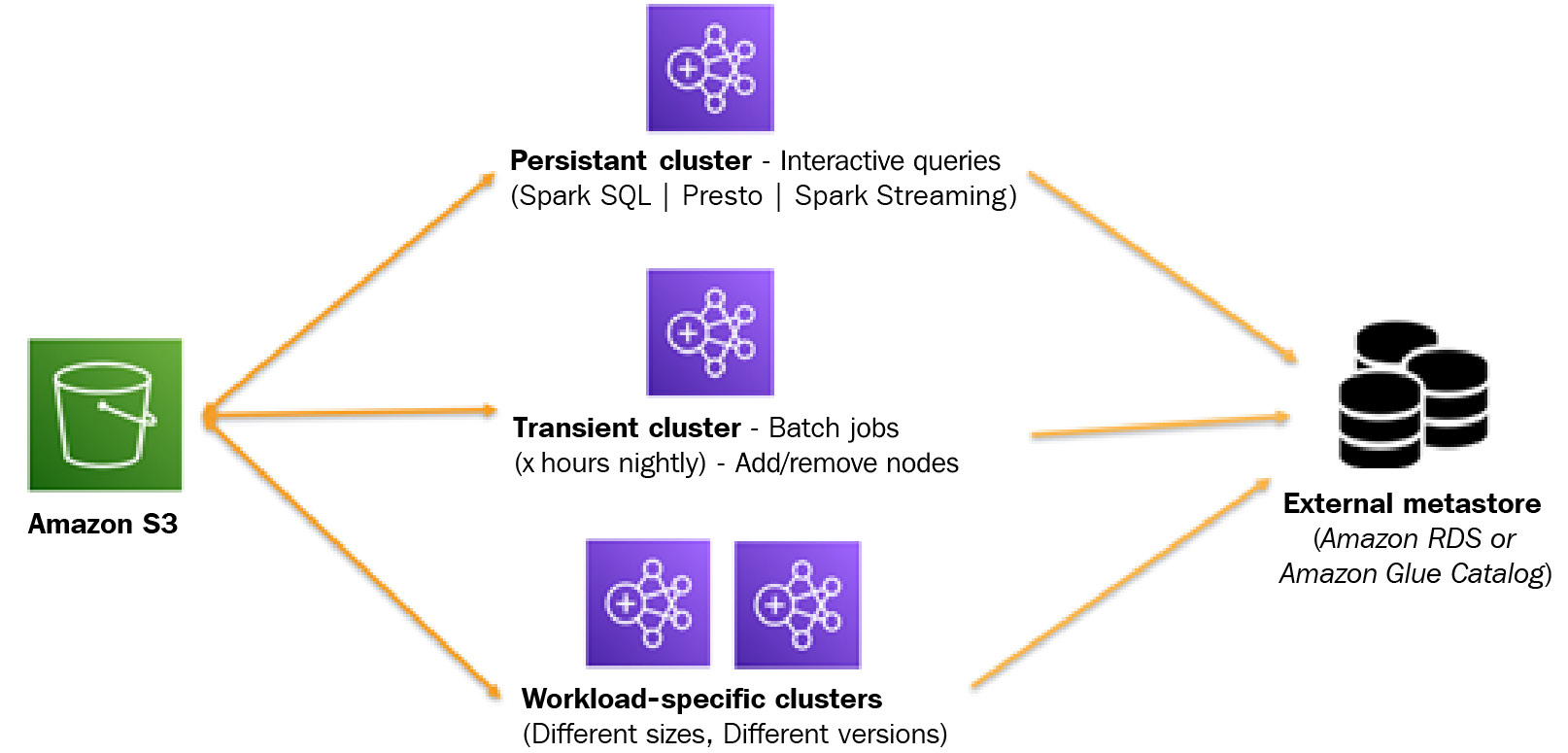
Figure 1.4 – EMR architecture representing cluster nodes
As you can see, all three clusters are using Amazon S3 as their persistent storage layer, which decouples compute and storage. This will facilitate scaling for both compute and storage independently, where Amazon S3 provides scaling with 99.999999999% (11 9s) durability and the cluster compute capacity can scale horizontally by adding more core or task nodes.
As represented in the diagram, transient clusters can be scheduled jobs or multiple workload-specific clusters running in parallel to do ETL on their datasets, where each workload cluster might have workload-specific cluster capacity.
When you implement transient clusters, often the best practice is to externalize your Hive Metastore, which means if your cluster gets terminated and becomes active again, it does not need to create Metastore or catalog tables again. When you are externalizing Hive Metastore of your EMR cluster, you have the option to use an Amazon RDS database as a Hive Metastore or you can use AWS Glue Data Catalog as your Metastore.
Integration with other AWS services
By now, you have got a good overview of Amazon EMR and its architecture, which can help you visualize how you can execute your Hadoop workloads on Amazon EMR.
But when you build an enterprise architecture for a data analytics pipeline, be it batch or real-time streaming, there are a lot of additional benefits to running in AWS. You can decouple your architecture into multiple components and integrate various other AWS services to build a fault-tolerant, scalable architecture that is highly secure.
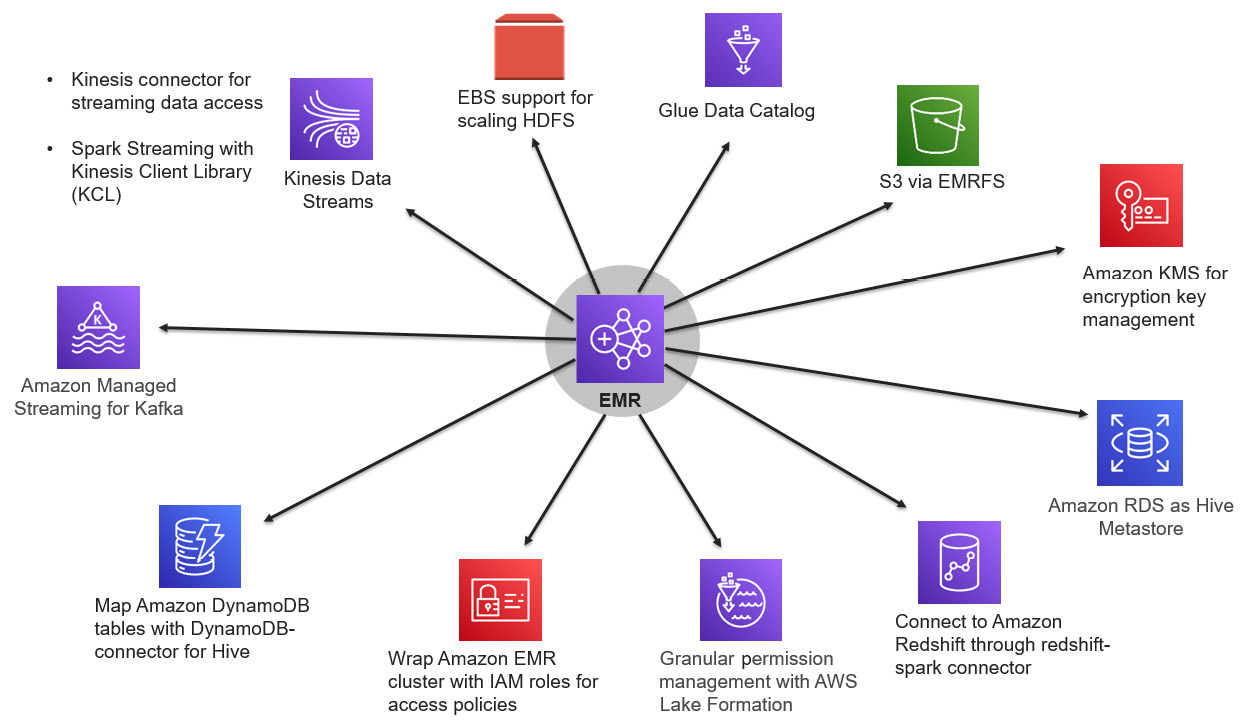
Figure 1.5 – Representing EMR integration with other AWS services
The preceding figure is a high-level diagram that shows how you can integrate a few other AWS services with Amazon EMR for an analytics pipeline. These are just a few sets of services listed to give you an idea, but there are a lot of other AWS services that you can integrate which you deem fit for your use case.
Now let's get an overview of these services and understand how they integrate with Amazon EMR.
Amazon S3 with EMR File System (EMRFS)
Out of all the AWS services, Amazon S3 takes the top spot as any data analytics architecture built on top of AWS will have S3 as a persistent or intermediate data store. When we build a data processing pipeline with Amazon EMR, S3 integration is natively supported through EMR File System (EMRFS). When a job communicates with an Amazon S3 path to read or write data, it can access S3 with the s3:// prefix.
Amazon Kinesis Data Streams (KDS)
Amazon Kinesis Data Streams (KDS) is a commonly used messaging service within AWS to build real-time streaming pipelines for use cases such as website clickstreams, application log streams, and Internet of Things (IoT) device event streams. It is scalable and durable and continuously captures gigabytes of data per second with multiple sources ingesting to it and multiple consumers reading from it in parallel.
It provides Kinesis Producer Library (KPL), which data producers can integrate to push data to Kinesis, and also provides Kinesis Consumer Library (KCL), which data-consuming applications can integrate to access the data.
When we build a real-time streaming pipeline with EMR and KDS as a source, we can use Spark Structured Streaming, which integrates KCL internally to access the stream datasets.
Amazon Managed Streaming for Kafka (MSK)
Similar to KDS, Apache Kafka is also a popular messaging service in the open source world that is capable of handling massive volumes of data for real-time streaming. But it comes with the additional overhead of managing the infrastructure.
Amazon Managed Streaming for Kafka (MSK) is a fully managed service built on top of open source Apache Kafka that automates Kafka cluster creation and maintenance. You can set up a Kafka cluster with a few clicks and use that as an event message source when you plan to implement a real-time streaming use case with EMR and Spark Streaming as the processing framework.
AWS Glue Data Catalog
AWS Glue is a fully managed ETL service that is built on top of Apache Spark with additional functionalities, such as Glue crawlers and Glue Data Catalog. Glue crawlers help autodetect the schema of source datasets and create virtual tables in Glue Data Catalog.
With EMR 5.8.0 or later, you can configure Spark SQL in EMR to use AWS Glue Data Catalog as its external metastore. This is great when you have transient cluster scenarios that need an external persistent metastore or multiple clusters sharing a common catalog.
Amazon Relational Database Service (RDS)
Similar to Glue Data Catalog, you can also use Amazon Relational Database Service (RDS) to be the external metastore for Hive, which can be shared between multiple clusters as a persistent metastore.
Apart from being used as an external metastore, in a few use cases, Amazon RDS is also used as an operational data store for reporting to which data gets ingested through EMR big data processing, which pushes aggregated output to RDS for real-time reporting.
Amazon DynamoDB
Amazon DynamoDB is an AWS-hosted, fully managed, scalable NoSQL database that delivers quick, predictable performance. As it's serverless, it takes away the infrastructure management overhead and also provides all security features, including encryption at rest.
In a few analytical use cases, DynamoDB is used to store data ingestion or extraction-related checkpoint information and you can use DynamoDB APIs with Spark to query the information or define Hive external tables with a DynamoDB connector to query them.
Amazon Redshift
Amazon Redshift is an MPP data warehousing service of AWS using which you can query and process exabytes of structured or semi-structured data. In the data analytics world, having a data warehouse or data mart is very common and Redshift can be used for both.
In the data analytics use cases, it's a common pattern that after your ETL pipeline processing is done, the aggregated output gets stored in a data warehouse or data mart and that is where the EMR-to-Redshift connection comes into the picture. Once EMR writes output to Redshift, you can integrate business intelligence reporting tools on top of it.
AWS Lake Formation
AWS Lake Formation is a service that enables you to integrate granular permission management on your data lake in AWS. When you define AWS Glue Data Catalog tables on top of a data lake, you can use AWS Lake Formation to define access permissions on databases, tables, and columns available in the same or other AWS accounts. This helps in having centralized data governance, which manages permissions for AWS accounts across an organization.
In EMR, when you try to pull data from Glue Data Catalog tables and use it as an external metastore, then your EMR cluster processes such as Spark will go through Lake Formation permissions to access the data.
AWS Identity and Access Management (IAM)
AWS Identity and Access Management (IAM) enables you to integrate authentication and authorization for accessing AWS services through the console or AWS APIs. You can create groups, users, or roles and define policies to give or restrict access to specific resources or APIs.
While creating an EMR cluster or accessing its API resources, every request goes through IAM policies to validate the access.
AWS Key Management Service (KMS)
When you think of securing your data while it's being transferred through the network or being stored in a storage layer, you can think of cryptographic keys and integrating an encryption and decryption mechanism. To implement this, you need to store your keys in a secured place that integrates with your application well and AWS Key Management Service (KMS) makes that simple for you. AWS KMS is a highly secure and resilient solution that protects your keys with hardware security modules.
Your EMR cluster can interact with AWS KMS to get the keys for encrypting or decrypting the data while it's being stored or transferred between cluster nodes.
Lake House architecture overview
Lake House is a new architecture pattern that tries to address the shortcomings of data lakes and combines the best of data lakes and data warehousing. It acknowledges that the one-size-fits-all strategy to analytics eventually leads to compromises. It is not just about connecting a data lake to a data warehouse or making data lake access more structured; it's also about connecting a data lake, a data warehouse, and other purpose-built data storage to enable unified data management and governance.
In AWS, you can use Amazon S3 as a data lake, Amazon EMR or AWS Glue for ETL transformations, and Redshift for data warehousing. Then, you can integrate other relational NoSQL data stores on top of it to solve different big data or machine learning use cases.
The following diagram is a high-level representation of how you can integrate the Lake House architecture in AWS:
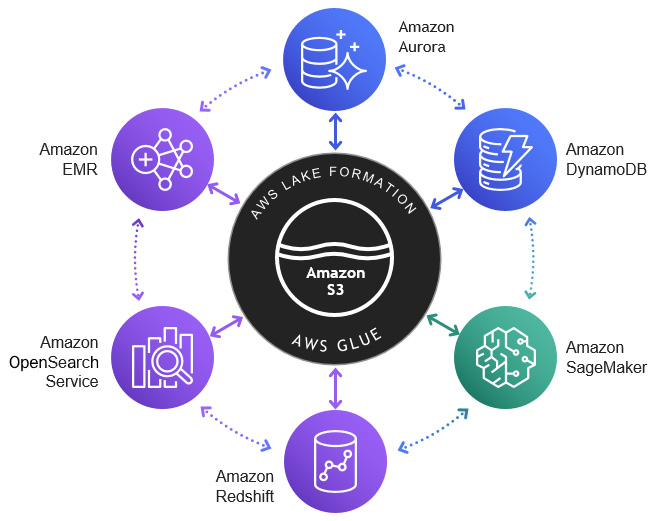
Figure 1.6 – Lake House architecture reference
As you can see in the preceding diagram, we have the Amazon S3 data lake in the center, supported by AWS Glue for serverless ETL and AWS Lake Formation for granular permission management.
Around the centralized data lake, we have the following:
- Amazon EMR for batch or streaming big data processing
- Amazon OpenSearch service for log analytics or search use cases
- Amazon Redshift for data warehousing or data mart use cases
- Amazon DynamoDB for key-value NoSQL store
- Amazon Aurora for operational reporting or external metastore
- Amazon SageMaker for machine learning model training and inference
As explained previously, the Lake House architecture represents how you can bring in the best of multiple services to build an ecosystem that addresses your organization's analytics needs.
EMR release history
As Amazon EMR is built on top of the open source Hadoop ecosystem, it tries to stay up to date with the open source stable releases, which includes new features and bug fixes.
Each EMR release comprises different Hadoop ecosystem applications or services that fit together with specific versions. EMR uses Apache Bigtop, which is an open source project within the Apache community to package the Hadoop ecosystem applications or components for an EMR release.
When you launch a cluster, you need to select the EMR cluster version and with advanced options, you can identify which version of each Hadoop application is integrated into that EMR release. If you are using AWS SDK or AWS CLI commands to create a cluster, you can specify the version using the release label. Release labels follow a naming convention of emr-x.x.x, for example, emr-6.3.0.
The EMR documentation clearly lists each release version and the Hadoop components integrated into it.
The following is a diagram of the EMR 6.3.0 release, which lists a few components of Hadoop services that are integrated into it and how it compares to previous releases of EMR 6.x:
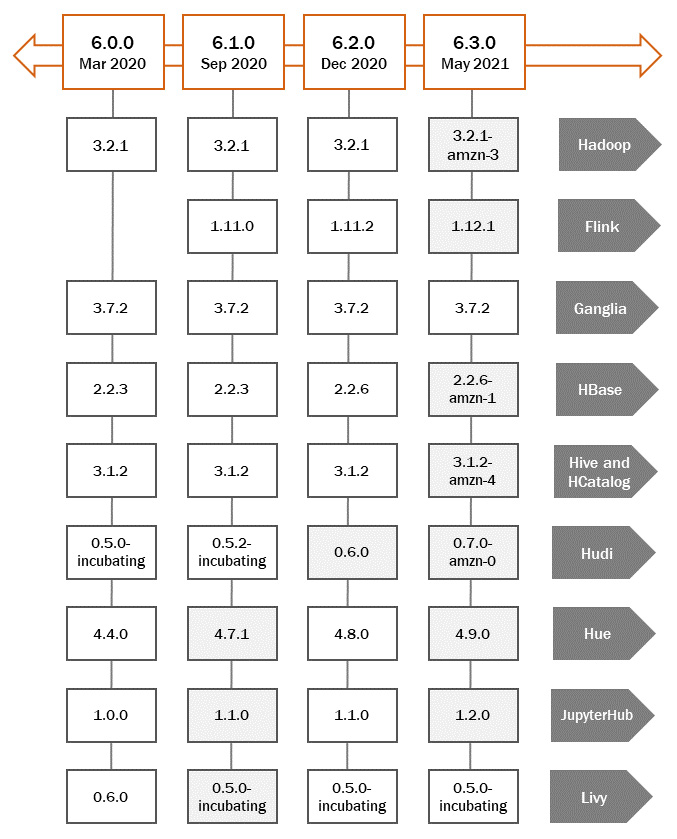
Figure 1.7 – Diagram of EMR release version comparison
If you were using open source Hadoop or any third-party Hadoop clusters and then migrating to EMR, it is best to go through the release documentation, understand different versions of Hadoop applications integrated into it, find the different configurations involved related to security, network access, authentication, authorization, and so on, and then evaluate it against your current Hadoop cluster to plan for migration.
With this, you have got a good overview of Amazon EMR, its benefits, its release history, and more. Now, let's compare it with a few other AWS services that are also based on Spark workloads and understand how they compare with Amazon EMR.
Comparing Amazon EMR with AWS Glue and AWS Glue DataBrew
When you look at today's big data processing frameworks, Spark is very popular for its in-memory processing capability. This is because it gives better performance compared to earlier Hadoop frameworks, such as MapReduce.
Earlier, we talked about different kinds of big data workloads you might have; it could be batch or streaming or a persistent/transient ETL use case.
Now, when you look for AWS services for your Spark workloads, EMR is not the only option AWS provides. You can use AWS Glue or AWS Glue DataBrew as an alternate service too. Customers often get confused between these services, and knowing what capabilities each of them has and when to use them can be tricky.
So, let's get an overview of these alternate services and then talk about what features they have and how to choose them by use case.
AWS Glue
AWS Glue is a serverless data integration service that is simple to use and is based on the Apache Spark engine. It enables you to discover, analyze, and transform the data through Spark-based in-memory processing. You can use AWS Glue for exploring datasets, doing ETL transformations, running real-time streaming pipelines, or preparing data for machine learning.
AWS Glue has the following components that you can benefit from:
- Glue crawlers and Glue Data Catalog: AWS Glue crawlers provide the benefit of deriving a schema from an S3 object store, where they scan a subset of data and create a table in Glue Data Catalog, on top of which you can execute SQL queries through Amazon Athena.
- Glue Studio and jobs: Glue Studio provides a visual interface to design ETL pipelines, which autogenerates PySpark or Scala scripts, which you can modify to integrate your complex business logic for data integration.
- Glue workflows: This enables you to build workflow orchestration for your ETL pipeline that can integrate Glue crawlers or jobs to be executed in sequence or parallel.
Please note, AWS Glue is a serverless offering, which means you don't have access to the underlying infrastructure and its pricing is based on Data Processing Units (DPUs). Each unit of DPU comprises 4 vCPU cores and 16 GB memory.
Example architecture for a batch ETL pipeline
Here is a simple reference architecture that you can follow to build a batch ETL pipeline. The use case is when data lands into the Amazon S3 landing zone from different sources and you need to build a centralized data lake on top of which you plan to do data analysis or reporting:

Figure 1.8 – Example architecture representing an AWS Glue ETL pipeline
As you can see in the diagram, we have the following steps:
- Step 1: Data lands into the Amazon S3 landing zone from different data sources, which becomes the raw zone for the data.
- Step 2-3: You will be using Glue crawlers and jobs to apply data cleansing, standardization, and transformation, and then make it available in an S3 data lake bucket for consumption.
- Step 4-6: Integrates flow to consume the data lake data for data analysis and business reporting. As you can see, we have integrated Amazon Athena to query data from Glue Data Catalog and S3 through standard SQL and integrated Amazon QuickSight for business intelligence reporting.
If you note, Glue crawlers and Glue Data Catalog are represented as a common centralized component for ETL transformations and data analysis. As your storage layer is Amazon S3, defining virtual schema on top of it will help you to access data through SQL as you do in relational databases.
AWS Glue DataBrew
AWS Glue DataBrew is a visual data preparation tool that assists data analysts and data scientists prepare data for data analysis or machine learning model training and inference. Often, data scientists spend 80% of their time preparing the data for analysis and 20% of the time on model development.
AWS Glue DataBrew solves that problem, where data scientists can save the effort of the steps from custom coding to clean, normalized data by building a transformation rule on the visual UI in minutes. AWS Glue DataBrew has 250+ prebuilt transformations (for example, filtering, adding derived columns, filtering anomalies, correcting invalid values, and joining or merging different datasets) that you can use to clean or transform your data, and it converts the visual transformation steps into a Spark script under the hood, which gives you faster performance.
It saves the transformation rules as recipes that you can apply to multiple jobs and can configure your job output format, partitioning strategy, and execution schedule. It also provides additional data profiling and lineage capability.
AWS Glue DataBrew is serverless, so you don't need to worry about setting up a cluster or managing its infrastructure resources. Its pricing is pretty similar to other AWS services, where you only pay for what you use.
Example architecture for machine learning data preparation
The following is a simple reference architecture that represents a data preparation use case for machine learning prediction and inference:

Figure 1.9 – An overall architecture representing data preparation with AWS Glue DataBrew
As you can see in the diagram, we have the following steps:
- Steps 1-2: Represents AWS Glue DataBrew reading data from the S3 input bucket and, after processing, writing the output back to the S3 output bucket
- Steps 3-4: Represents Amazon SageMaker using the processed data of the data bucket for machine learning training and inference, which also integrates Jupyter Notebook for model development
Now, let's look at how to decide which service is best for your use case.
Choosing the right service for your use case
Now, after getting an overview of all three AWS services, you can take note of the following guidelines when choosing the right service for your use case:
- AWS Glue DataBrew: If you are trying to build an ETL job or pipeline with Spark but you are new to Hadoop/Spark or you are not good at writing scripts for ETL transformations, then you can go for AWS Glue Data Brew, where you can use the GUI-based actions to preview your data and apply necessary transformation rules.
This is great when you receive different types of file formats from different systems and don't want to spend time writing code to prepare the data for analysis:
- Pros: Does not require you to learn Spark or scripting languages for preparing your data and also, you can build a data pipeline faster.
- Cons: Just because you are relying on the UI actions to build your pipeline, you lose the flexibility of building complex ETL operations that are not available through the UI. Also, it does not support real-time streaming use cases.
- Target users: Data scientists or data analysts can take advantage of this service as they spend time preparing the data or cleansing it for analysis and their objective is not to apply complex ETL operations.
- Use cases: Data cleansing and preparation with minimal ETL transformations.
- AWS Glue: If your objective is to build complex Spark-based ETL transformations by joining different data sources and you are looking for a serverless solution to avoid infrastructure management hassles, then AWS Glue is great.
On top of the Spark-based ETL job capability, AWS Glues crawlers, Glue Data Catalog, and workflows are also great benefits:
- Pros: Great for serverless Spark workloads that support both batch and streaming pipelines. You can use AWS Glue Studio to generate base code, on top of which you can edit.
- Cons: AWS Glue is limited to only Spark workloads and with Spark, you can use only Scala and Python. Also, if you have persistent cluster requirements, Glue is not a great choice.
- Target users: Data engineers looking for Spark-based ETL engines are best suited to use AWS Glue.
- Use cases: Batch and streaming ETL transformations and building a unified data catalog.
- Amazon EMR: As you have understood by now, AWS Glue or AWS Glue DataBrew are great for Spark-based workloads only and are great if you are looking for serverless options. But there are a lot of other use cases where organizations go with a combination of different Hadoop ecosystem services (for example, Hive, Flink, Presto, HBase, TensorFlow, and MXNet) or would like to have better control of not only the infrastructure, instance type and so on but also specific versions of Hadoop/Spark services they would like to use.
Also, sometimes you will have use cases where you might look for persistent Hadoop clusters that need to be used by multiple teams for different purposes, such as data analysis/preparation, ETL, real-time streaming, and machine learning models. EMR is a great fit there:
- Pros: Gives control to choose cluster capacity, instance types, and Hadoop services you need with version selection and also provides auto- and managed scaling features. Also provides flexibility to use spot instances for cost savings and have better control of the network and security of your cluster.
- Cons: Not a serverless offering like AWS Glue, but that's the purpose of EMR, to give you better control to configure your cluster.
- Target users: EMR can be used by mostly all kinds of users who deal with data on a daily basis, such as data engineers, data analysts, and data scientists.
- Use cases: Batch and real-time streaming, machine learning, interactive analytics, genomics, and so on.
I hope this gave you a good understanding of how you can choose the right AWS service for your Hadoop or Spark workloads and also how they compare with each other in terms of features, pros, and cons.
Summary
Over the course of this chapter, we got an overview of the Hadoop ecosystem and EMR and learned about its benefits and the problem statement it solves.
After covering those topics, we got an overview of other AWS services that integrate with EMR to build an end-to-end AWS cloud-native architecture. We followed that with a discussion of the Lake House architecture and EMR releases.
Finally, we covered how EMR compares with other Spark-based AWS services, such as AWS Glue and AWS Glue DataBrew, and how to choose the right service for your use case.
That concludes this chapter! Hopefully, you have got a good overview of Amazon EMR and are now ready to dive deep into its architecture and deployment options, which will be covered in the next chapter.
Test your knowledge
Before moving on to the next chapter, test your knowledge with the following questions:
- You have an on-premises persistent Hadoop cluster, where you have a lot of Hive SQL jobs and very few Spark ETL jobs are available. This cluster serves multiple teams and also helps in interactive analytics.
You are assigned the job to plan for AWS cloud migration. Which AWS service is best suited for you?
- You have received a JSON file from your source system that you would like to flatten and apply a few standardizations to for your machine learning model prediction. This process needs to be repeated every day so that the machine learning prediction can predict the output for the next day. Which AWS service will you use?
- You have a requirement to build a real-time streaming application, where you need to integrate a scalable message bus and Spark Streaming consumer application. You are looking for a managed messaging service that can scale as the number of streaming events increase or decrease. What will you use?
- Which AWS services will you choose for the message bus and Spark processing consumer application?
Further reading
The following are a few resources you can refer to for further reading:
- About EMR releases: https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-release-components.html
- EMR release history: https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-whatsnew-history.html