
Chapter 6. Spark’s Resilience Model
In most cases, a streaming job is a long-running job. By definition, streams of data observed and processed over time lead to jobs that run continuously. As they process data, they might accumulate intermediary results that are difficult to reproduce after the data has left the processing system. Therefore, the cost of failure is considerable and, in some cases, complete recovery is intractable.
In distributed systems, especially those relying on commodity hardware, failure is a function of size: the larger the system, the higher the probability that some component fails at any time. Distributed stream processors need to factor this chance of failure in their operational model.
In this chapter, we look at the resilience that the Apache Spark platform provides us: how it’s able to recover partial failure and what kinds of guarantees we are given for the data passing through the system when a failure occurs. We begin by getting an overview of the different internal components of Spark and their relation to the core data structure. With this knowledge, you can proceed to understand the impact of failure at the different levels and the measures that Spark offers to recover from such failure.
Resilient Distributed Datasets in Spark
Spark builds its data representations on Resilient Distributed Datasets (RDDs). Introduced in 2011 by the paper “Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing” [Zaharia2011], RDDs are the foundational data structure in Spark. It is at this ground level that the strong fault tolerance guarantees of Spark start.
RDDs are composed of partitions, which are segments of data stored on individual nodes and tracked by the Spark driver that is presented as a location-transparent data structure to the user.
We illustrate these components in Figure 6-1 in which the classic word count application is broken down into the different elements that comprise an RDD.

Figure 6-1. An RDD operation represented in a distributed system
The colored blocks are data elements, originally stored in a distributed filesystem, represented on the far left of the figure. The data is stored as partitions, illustrated as columns of colored blocks inside the file. Each partition is read into an executor, which we see as the horizontal blocks. The actual data processing happens within the executor. There, the data is transformed following the transformations described at the RDD level:
-
.flatMap(l => l.split(" "))separates sentences into words separated by space. -
.map(w => (w,1))transforms each word into a tuple of the form(<word>, 1)in this way preparing the words for counting. -
.reduceByKey(_ + _)computes the count, using the<word>as a key and applying a sum operation to the attached number. -
The final result is attained by bringing the partial results together using the same
reduceoperation.
RDDs constitute the programmatic core of Spark.
All other abstractions, batch and streaming alike, including DataFrames, DataSets, and DStreams are built using the facilities created by RDDs, and, more important, they inherit the same fault tolerance capabilities.
We provide a brief introduction of the RDDs programming model in “RDDs as the Underlying Abstraction for DStreams”.
Another important characteristic of RDDs is that Spark will try to keep their data preferably in-memory for as long as it is required and provided enough capacity in the system. This behavior is configurable through storage levels and can be explicitly controlled by calling caching operations.
We mention those structures here to present the idea that Spark tracks the progress of the user’s computation through modifications of the data. Indeed, knowing how far along we are in what the user wants to do through inspecting the control flow of his program (including loops and potential recursive calls) can be a daunting and error-prone task. It is much more reliable to define types of distributed data collections, and let the user create one from another, or from other data sources.
In Figure 6-2, we show the same word count program, now in the form of the user-provided code (left) and the resulting internal RDD chain of operations.
This dependency chain forms a particular kind of graph, a Directed Acyclic Graph (DAG).
The DAG informs the scheduler, appropriately called DAGScheduler, on how to distribute the computation and is also the foundation of the failure-recovery functionality, because it represents the internal data and their dependencies.
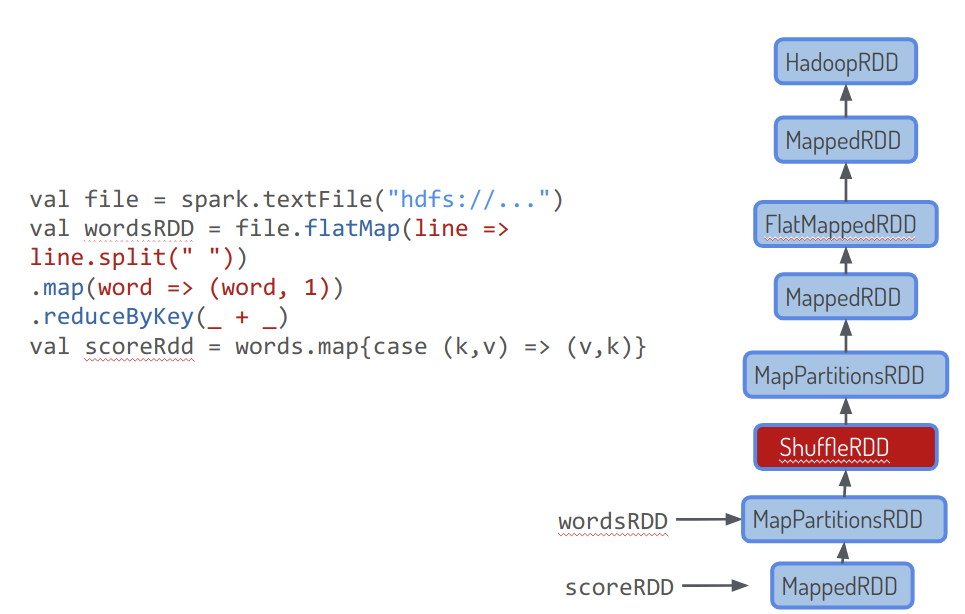
Figure 6-2. RDD lineage
As the system tracks the ordered creation of these distributed data collections, it tracks the work done, and what’s left to accomplish.
Spark Components
To understand at what level fault tolerance operates in Spark, it’s useful to go through an overview of the nomenclature of some core concepts. We begin by assuming that the user provides a program that ends up being divided into chunks and executed on various machines, as we saw in the previous section, and as depicted in Figure 6-3.

Figure 6-3. Spark nomenclature
Let’s run down those steps, illustrated in Figure 6-3, which define the vocabulary of the Spark runtime:
- User Program
-
The user application in Spark Streaming is composed of user-specified function calls operating on a resilient data structure (RDD, DStream, streaming DataSet, and so on), categorized as actions and transformations.
- Transformed User Program
-
The user program may undergo adjustments that modify some of the specified calls to make them simpler, the most approachable and understandable of which is map-fusion.1 Query plan is a similar but more advanced concept in Spark SQL.
- RDD
-
A logical representation of a distributed, resilient, dataset. In the illustration, we see that the initial RDD comprises three parts, called partitions.
- Partition
-
A partition is a physical segment of a dataset that can be loaded independently.
- Stages
-
The user’s operations are then grouped into stages, whose boundary separates user operations into steps that must be executed separately. For example, operations that require a shuffle of data across multiple nodes, such as a join between the results of two distinct upstream operations, mark a distinct stage. Stages in Apache Spark are the unit of sequencing: they are executed one after the other. At most one of any interdependent stages can be running at any given time.
- Jobs
-
After these stages are defined, what internal actions Spark should take is clear. Indeed, at this stage, a set of interdependent jobs is defined. And jobs, precisely, are the vocabulary for a unit of scheduling. They describe the work at hand from the point of view of an entire Spark cluster, whether it’s waiting in a queue or currently being run across many machines. (Although it’s not represented explicitly, in Figure 6-3, the job is the complete set of transformations.)
- Tasks
-
Depending on where their source data is on the cluster, jobs can then be cut into tasks, crossing the conceptual boundary between distributed and single-machine computing: a task is a unit of local computation, the name for the local, executor-bound part of a job.
Spark aims to make sure that all of these steps are safe from harm and to recover quickly in the case of any incident occurring in any stage of this process. This concern is reflected in fault-tolerance facilities that are structured by the aforementioned notions: restart and checkpointing operations that occur at the task, job, stage, or program level.
Spark’s Fault-Tolerance Guarantees
Now that we have seen the “pieces” that constitute the internal machinery in Spark, we are ready to understand that failure can happen at many different levels. In this section, we see Spark fault-tolerance guarantees organized by “increasing blast radius,” from the more modest to the larger failure. We are going to investigate the following:
-
How Spark mitigates Task failure through restarts
-
How Spark mitigates Stage failure through the shuffle service
-
How Spark mitigates the disappearance of the orchestrator of the user program, through driver restarts
When you’ve completed this section, you will have a clear mental picture of the guarantees Spark affords us at runtime, letting you understand the failure scenarios that a well-configured Spark job can deal with.
Task Failure Recovery
Tasks can fail when the infrastructure on which they are running has a failure or logical conditions in the program lead to an sporadic job, like OutOfMemory, network, storage errors, or problems bound to the quality of the data being processed (e.g., a parsing error, a NumberFormatException, or a NullPointerException to name a few common exceptions).
If the input data of the task was stored, through a call to cache() or persist() and if the chosen storage level implies a replication of data (look for a storage level whose setting ends in _2 , such as MEMORY_ONLY_SER_2), the task does not need to have its input recomputed, because a copy of it exists in complete form on another machine of the cluster.
We can then use this input to restart the task. Table 6-1 summarizes the different storage levels configurable in Spark and their chacteristics in terms of memory usage and replication factor.
| Level | Uses disk | Uses memory | Uses off-heap storage | Object (deserialized) | # of replicated copies |
|---|---|---|---|---|---|
|
1 |
||||
|
X |
1 |
|||
|
X |
2 |
|||
|
X |
X |
1 |
||
|
X |
X |
2 |
||
|
X |
1 |
|||
|
X |
2 |
|||
|
X |
X |
X |
1 |
|
|
X |
X |
X |
2 |
|
|
X |
X |
1 |
||
|
X |
X |
2 |
||
|
X |
1 |
If, however, there was no persistence or if the storage level does not guarantee the existence of a copy of the task’s input data, the Spark driver will need to consult the DAG that stores the user-specified computation to determine which segments of the job need to be recomputed.
Consequently, without enough precautions to save either on the caching or on the storage level, the failure of a task can trigger the recomputation of several others, up to a stage boundary.
Stage boundaries imply a shuffle, and a shuffle implies that intermediate data will somehow be materialized: as we discussed, the shuffle transforms executors into data servers that can provide the data to any other executor serving as a destination.
As a consequence, these executors have a copy of the map operations that led up to the shuffle. Hence, executors that participated in a shuffle have a copy of the map operations that led up to it. But that’s a lifesaver if you have a dying downstream executor, able to rely on the upstream servers of the shuffle (which serve the output of the map-like operation). What if it’s the contrary: you need to face the crash of one of the upstream executors?
Stage Failure Recovery
We’ve seen that task failure (possibly due to executor crash) was the most frequent incident happening on a cluster and hence the most important event to mitigate. Recurrent task failures will lead to the failure of the stage that contains that task. This brings us to the second facility that allows Spark to resist arbitrary stage failures: the shuffle service.
When this failure occurs, it always means some rollback of the data, but a shuffle operation, by definition, depends on all of the prior executors involved in the step that precedes it.
As a consequence, since Spark 1.3 we have the shuffle service, which lets you work on map data that is saved and distributed through the cluster with a good locality, but, more important, through a server that is not a Spark task. It’s an external file exchange service written in Java that has no dependency on Spark and is made to be a much longer-running service than a Spark executor. This additional service attaches as a separate process in all cluster modes of Spark and simply offers a data file exchange for executors to transmit data reliably, right before a shuffle. It is highly optimized through the use of a netty backend, to allow a very low overhead in transmitting data. This way, an executor can shut down after the execution of its map task, as soon as the shuffle service has a copy of its data. And because data transfers are faster, this transfer time is also highly reduced, reducing the vulnerable time in which any executor could face an issue.
Driver Failure Recovery
Having seen how Spark recovers from the failure of a particular task and stage, we can now look at the facilities Spark offers to recover from the failure of the driver program. The driver in Spark has an essential role: it is the depository of the block manager, which knows where each block of data resides in the cluster. It is also the place where the DAG lives.
Finally, it is where the scheduling state of the job, its metadata, and logs resides. Hence, if the driver is lost, a Spark cluster as a whole might well have lost which stage it has reached in computation, what the computation actually consists of, and where the data that serves it can be found, in one fell swoop.
Cluster-mode deployment
Spark has implemented what’s called the cluster deployment mode, which allows the driver program to be hosted on the cluster, as opposed to the user’s computer.
The deployment mode is one of two options: in client mode, the driver is launched in the same process as the client that submits the application. In cluster mode, however, the driver is launched from one of the worker processes inside the cluster, and the client process exits as soon as it fulfills its responsibility of submitting the application without waiting for the application to finish.
This, in sum, allows Spark to operate an automatic driver restart, so that the user can start a job in a “fire and forget fashion,” starting the job and then closing their laptop to catch the next train. Every cluster mode of Spark offers a web UI that will let the user access the log of their application. Another advantage is that driver failure does not mark the end of the job, because the driver process will be relaunched by the cluster manager. But this only allows recovery from scratch, given that the temporary state of the computation—previously stored in the driver machine—might have been lost.
Checkpointing
To avoid losing intermediate state in case of a driver crash, Spark offers the option of checkpointing; that is, recording periodically a snapshot of the application’s state to disk.
The setting of the sparkContext.setCheckpointDirectory() option should point to reliable storage (e.g., Hadoop Distributed File System [HDFS]) because having the driver try to reconstruct the state of intermediate RDDs from its local filesystem makes no sense: those intermediate RDDs are being created on the executors of the cluster and should as such not require any interaction with the driver for backing them up.
We come back to the subject of checkpointing in detail much later, in Chapter 24. In the meantime, there is still one component of any Spark cluster whose potential failure we have not yet addressed: the master node.
Summary
This tour of Spark-core’s fault tolerance and high-availability modes should have given you an idea of the main primitives and facilities offered by Spark and of their defaults. Note that none of this is so far specific to Spark Streaming or Structured Streaming, but that all these lessons apply to the streaming APIs in that they are required to deliver long-running, fault-tolerant and yet performant applications.
Note also that these facilities reflect different concerns in the frequency of faults for a particular cluster. These facilities reflect different concerns for the frequency of faults in a particular cluster:
-
Features such as setting up a failover master node kept up-to-date through Zookeeper are really about avoiding a single point of failure in the design of a Spark application.
-
The Spark Shuffle Service is here to avoid any problems with a shuffle step at the end of a long list of computation steps making the whole fragile through a faulty executor.
The later is a much more frequent occurrence. The first is about dealing with every possible condition, the second is more about ensuring smooth performance and efficient recovery.
1 The process by which l.map(foo).map(bar) is changed into l.map((x) => bar(foo(x)))