
Chapter 7. Introducing Structured Streaming
In data-intensive enterprises, we find many large datasets: log files from internet-facing servers, tables of shopping behavior, and NoSQL databases with sensor data, just to name a few examples. All of these datasets share the same fundamental life cycle: They started out empty at some point in time and were progressively filled by arriving data points that were directed to some form of secondary storage. This process of data arrival is nothing more than a data stream being materialized onto secondary storage. We can then apply our favorite analytics tools on those datasets at rest, using techniques known as batch processing because they take large chunks of data at once and usually take considerable amounts of time to complete, ranging from minutes to days.
The Dataset abstraction in Spark SQL is one such way of analyzing data at rest.
It is particularly useful for data that is structured in nature; that is, it follows a defined schema.
The Dataset API in Spark combines the expressivity of a SQL-like API with type-safe collection operations that are reminiscent of the Scala collections and the Resilient Distributed Dataset (RDD) programming model.
At the same time, the Dataframe API, which is in nature similar to Python Pandas and R Dataframes, widens the audience of Spark users beyond the initial core of data engineers who are used to developing in a functional paradigm.
This higher level of abstraction is intended to support modern data engineering and data science practices by enabling a wider range of professionals to jump onto the big data analytics train using a familiar API.
What if, instead of having to wait for the data to "settle down,” we could apply the same Dataset concepts to the data while it is in its original stream form?
The Structured Streaming model is an extension of the Dataset SQL-oriented model to handle data on the move:
-
The data arrives from a source stream and is assumed to have a defined schema.
-
The stream of events can be seen as rows that are appended to an unbounded table.
-
To obtain results from the stream, we express our computation as queries over that table.
-
By continuously applying the same query to the updating table, we create an output stream of processed events.
-
The sink could be a storage system, another streaming backend, or an application ready to consume the processed data.
In this model, our theoretically unbounded table must be implemented in a physical system with defined resource constraints. Therefore, the implementation of the model requires certain considerations and restrictions to deal with a potentially infinite data inflow.
To address these challenges, Structured Streaming introduces new concepts to the Dataset and DataFrame APIs, such as support for event time, watermarking, and different output modes that determine for how long past data is actually stored.
Conceptually, the Structured Streaming model blurs the line between batch and streaming processing, removing a lot of the burden of reasoning about analytics on fast-moving data.
First Steps with Structured Streaming
In the previous section, we learned about the high-level concepts that constitute Structured Streaming, such as sources, sinks, and queries. We are now going to explore Structured Streaming from a practical perspective, using a simplified web log analytics use case as an example.
Before we begin delving into our first streaming application, we are going to see how classical batch analysis in Apache Spark can be applied to the same use case.
This exercise has two main goals:
-
First, most, if not all, streaming data analytics start by studying a static data sample. It is far easier to start a study with a file of data, gain intuition on how the data looks, what kind of patterns it shows, and define the process that we require to extract the intended knowledge from that data. Typically, it’s only after we have defined and tested our data analytics job, that we proceed to transform it into a streaming process that can apply our analytic logic to data on the move.
-
Second, from a practical perspective, we can appreciate how Apache Spark simplifies many aspects of transitioning from a batch exploration to a streaming application through the use of uniform APIs for both batch and streaming analytics.
This exploration will allow us to compare and contrast the batch and streaming APIs in Spark and show us the necessary steps to move from one to the other.
Online Resources
For this example, we use Apache Web Server logs from the public 1995 NASA Apache web logs, originally from http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html.
For the purpose of this exercise, the original log file has been split into daily files and each log line has been formatted as JSON. The compressed NASA-weblogs file can be downloaded from https://github.com/stream-processing-with-spark.
Download this dataset and place it in a folder on your computer.
Batch Analytics
Given that we are working with archive log files, we have access to all of the data at once. Before we begin building our streaming application, let’s take a brief intermezzo to have a look at what a classical batch analytics job would look like.
Online Resources
For this example, we will use the batch_weblogs notebook in the online resources for the book, located at https://github.com/stream-processing-with-spark][https://github.com/stream-processing-with-spark].
First, we load the log files, encoded as JSON, from the directory where we unpacked them:
// This is the location of the unpackaged files. Update accordinglyvallogsDirectory=???valrawLogs=sparkSession.read.json(logsDirectory)
Next, we declare the schema of the data as a case class to use the typed Dataset API.
Following the formal description of the dataset (at NASA-HTTP ), the log is structured as follows:
The logs are an ASCII file with one line per request, with the following columns:
Host making the request. A hostname when possible, otherwise the Internet address if the name could not be looked up.
Timestamp in the format “DAY MON DD HH:MM:SS YYYY,” where DAY is the day of the week, MON is the name of the month, DD is the day of the month, HH:MM:SS is the time of day using a 24-hour clock, and YYYY is the year. The timezone is –0400.
Request given in quotes.
HTTP reply code.
Bytes in the reply.
Translating that schema to Scala, we have the following case class definition:
importjava.sql.TimestampcaseclassWebLog(host:String,timestamp:Timestamp,request:String,http_reply:Int,bytes:Long)
Note
We use java.sql.Timestamp as the type for the timestamp because it’s internally supported by Spark and does not require any additional cast that other options might require.
We convert the original JSON to a typed data structure using the previous schema definition:
importorg.apache.spark.sql.functions._importorg.apache.spark.sql.types.IntegerType// we need to narrow the `Interger` type because// the JSON representation is interpreted as `BigInteger`valpreparedLogs=rawLogs.withColumn("http_reply",$"http_reply".cast(IntegerType))valweblogs=preparedLogs.as[WebLog]
Now that we have the data in a structured format, we can begin asking the questions that interest us. As a first step, we would like to know how many records are contained in our dataset:
valrecordCount=weblogs.count>recordCount:Long=1871988
A common question would be: “what was the most popular URL per day?”
To answer that, we first reduce the timestamp to the day of the month. We then group by this new dayOfMonth column and the request URL and we count over this aggregate. We finally order using descending order to get the top URLs first:
valtopDailyURLs=weblogs.withColumn("dayOfMonth",dayofmonth($"timestamp")).select($"request",$"dayOfMonth").groupBy($"dayOfMonth",$"request").agg(count($"request").alias("count")).orderBy(desc("count"))topDailyURLs.show()+----------+----------------------------------------+-----+|dayOfMonth|request|count|+----------+----------------------------------------+-----+|13|GET/images/NASA-logosmall.gifHTTP/1.0|12476||13|GET/htbin/cdt_main.plHTTP/1.0|7471||12|GET/images/NASA-logosmall.gifHTTP/1.0|7143||13|GET/htbin/cdt_clock.plHTTP/1.0|6237||6|GET/images/NASA-logosmall.gifHTTP/1.0|6112||5|GET/images/NASA-logosmall.gifHTTP/1.0|5865|...
Top hits are all images. What now? It’s not unusual to see that the top URLs are images commonly used across a site.
Our true interest lies in the content pages generating the most traffic.
To find those, we first filter on html content and then proceed to apply the top aggregation we just learned.
As we can see, the request field is a quoted sequence of [HTTP_VERB] URL [HTTP_VERSION]. We will extract the URL and preserve only those ending in .html, .htm, or no extension (directories). This is a simplification for the purpose of this example:
valurlExtractor="""^GET (.+) HTTP/d.d""".rvalallowedExtensions=Set(".html",".htm","")valcontentPageLogs=weblogs.filter{log=>log.requestmatch{caseurlExtractor(url)=>valext=url.takeRight(5).dropWhile(c=>c!='.')allowedExtensions.contains(ext)case_=>false}}
With this new dataset that contains only .html, .htm, and directories, we proceed to apply the same top-k function as earlier:
valtopContentPages=contentPageLogs.withColumn("dayOfMonth",dayofmonth($"timestamp")).select($"request",$"dayOfMonth").groupBy($"dayOfMonth",$"request").agg(count($"request").alias("count")).orderBy(desc("count"))topContentPages.show()+----------+------------------------------------------------+-----+|dayOfMonth|request|count|+----------+------------------------------------------------+-----+|13|GET/shuttle/countdown/liftoff.htmlHTTP/1.0" | 4992|| 5| GET /shuttle/countdown/ HTTP/1.0"|3412||6|GET/shuttle/countdown/HTTP/1.0" | 3393|| 3| GET /shuttle/countdown/ HTTP/1.0"|3378||13|GET/shuttle/countdown/HTTP/1.0" | 3086|| 7| GET /shuttle/countdown/ HTTP/1.0"|2935||4|GET/shuttle/countdown/HTTP/1.0" | 2832|| 2| GET /shuttle/countdown/ HTTP/1.0"|2330|...
We can see that the most popular page that month was liftoff.html, corresponding to the coverage of the launch of the Discovery shuttle, as documented on the NASA archives. It’s closely followed by countdown/, the days prior to the launch.
Streaming Analytics
In the previous section, we explored historical NASA web log records. We found trending events in those records, but much later than when the actual events happened.
One key driver for streaming analytics comes from the increasing demand of organizations to have timely information that can help them make decisions at many different levels.
We can use the lessons that we have learned while exploring the archived records using a batch-oriented approach and create a streaming job that will provide us with trending information as it happens.
The first difference that we observe with the batch analytics is the source of the data. For our streaming exercise, we will use a TCP server to simulate a web system that delivers its logs in real time. The simulator will use the same dataset but will feed it through a TCP socket connection that will embody the stream that we will be analyzing.
Online Resources
For this example, we will use the notebooks weblog_TCP_server and streaming_weblogs found in the online resources for the book, located at https://github.com/stream-processing-with-spark.
Connecting to a Stream
If you recall from the introduction of this chapter, Structured Streaming defines the concepts of sources and sinks as the key abstractions to consume a stream and produce a result.
We are going to use the TextSocketSource implementation to connect to the server through a TCP socket.
Socket connections are defined by the host of the server and the port where it is listening for connections.
These two configuration elements are required to create the socket source:
valstream=sparkSession.readStream.format("socket").option("host",host).option("port",port).load()
Note how the creation of a stream is quite similar to the declaration of a static datasource in the batch case.
Instead of using the read builder, we use the readStream construct and we pass to it the parameters required by the streaming source.
As you will see during the course of this exercise and later on as we go into the details of Structured Streaming, the API is basically the same DataFrame and Dataset API for static data but with some modifications and limitations that you will learn in detail.
Preparing the Data in the Stream
The socket source produces a streaming DataFrame with one column, value, which contains the data received from the stream. See “The Socket Source” for additional details.
In the batch analytics case, we could load the data directly as JSON records. In the case of the Socket source, that data is plain text.
To transform our raw data to WebLog records, we first require a schema. The schema provides the necessary information to parse the text to a JSON object. It’s the structure when we talk about structured streaming.
After defining a schema for our data, we proceed to create a Dataset, following these steps:
importjava.sql.TimestampcaseclassWebLog(host:String,timestamp:Timestamp,request:String,http_reply:Int,bytes:Long)valwebLogSchema=Encoders.product[WebLog].schemavaljsonStream=stream.select(from_json($"value",webLogSchema)as"record")valwebLogStream:Dataset[WebLog]=jsonStream.select("record.*").as[WebLog]

Obtain a schema from the
case classdefinition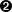
Transform the text
valueto JSON using the JSON support built into Spark SQL
Use the
DatasetAPI to transform the JSON records toWebLogobjects
As a result of this process, we obtain a Streaming Dataset of WebLog records.
Operations on Streaming Dataset
The webLogStream we just obtained is of type Dataset[WebLog] like we had in the batch analytics job.
The difference between this instance and the batch version is that webLogStream is a streaming Dataset.
We can observe this by querying the object:
webLogStream.isStreaming>res:Boolean=true
At this point in the batch job, we were creating the first query on our data: How many records are contained in our dataset?
This is a question that we can easily answer when we have access to all of the data.
However, how do we count records that are constantly arriving?
The answer is that some operations that we consider usual on a static Dataset, like counting all records, do not have a defined meaning on a Streaming Dataset.
As we can observe, attempting to execute the count query in the following code snippet will result in an AnalysisException:
valcount=webLogStream.count()>org.apache.spark.sql.AnalysisException:QuerieswithstreamingsourcesmustbeexecutedwithwriteStream.start();;
This means that the direct queries we used on a static Dataset or DataFrame now need two levels of interaction.
First, we need to declare the transformations of our stream, and then we need to start the stream process.
Creating a Query
What are popular URLs? In what time frame? Now that we have immediate analytic access to the stream of web logs, we don’t need to wait for a day or a month (or more than 20 years in the case of these NASA web logs) to have a rank of the popular URLs. We can have that information as trends unfold in much shorter windows of time.
First, to define the period of time of our interest, we create a window over some timestamp. An interesting feature of Structured Streaming is that we can define that time interval on the timestamp when the data was produced, also known as event time, as opposed to the time when the data is being processed.
Our window definition will be of five minutes of event data. Given that our timeline is simulated, the five minutes might happen much faster or slower than the clock time. In this way, we can clearly appreciate how Structured Streaming uses the timestamp information in the events to keep track of the event timeline.
As we learned from the batch analytics, we should extract the URLs and select only content pages, like .html, .htm, or directories. Let’s apply that acquired knowledge first before proceeding to define our windowed query:
// A regex expression to extract the accessed URL from weblog.requestvalurlExtractor="""^GET (.+) HTTP/d.d""".rvalallowedExtensions=Set(".html",".htm","")valcontentPageLogs:String=>Boolean=url=>{valext=url.takeRight(5).dropWhile(c=>c!='.')allowedExtensions.contains(ext)}valurlWebLogStream=webLogStream.flatMap{weblog=>weblog.requestmatch{caseurlExtractor(url)if(contentPageLogs(url))=>Some(weblog.copy(request=url))case_=>None}}
We have converted the request to contain only the visited URL and filtered out all noncontent pages. Now, we define the windowed query to compute the top trending URLs:
valrankingURLStream=urlWebLogStream.groupBy($"request",window($"timestamp","5 minutes","1 minute")).count()
Start the Stream Processing
All of the steps that we have followed so far have been to define the process that the stream will undergo. But no data has been processed yet.
To start a Structured Streaming job, we need to specify a sink and an output mode.
These are two new concepts introduced by Structured Streaming:
-
A
sinkdefines where we want to materialize the resulting data; for example, to a file in a filesystem, to an in-memory table, or to another streaming system such as Kafka. -
The
output modedefines how we want the results to be delivered: do we want to see all data every time, only updates, or just the new records?
These options are given to a writeStream operation. It creates the streaming query that starts the stream consumption, materializes the computations declared on the query, and produces the result to the output sink.
We visit all these concepts in detail later on. For now, let’s use them empirically and observe the results.
For our query, shown in Example 7-1, we use the memory sink and output mode complete to have a fully updated table each time new records are added to the result of keeping track of the URL ranking.
Example 7-1. Writing a stream to a sink
valquery=rankingURLStream.writeStream.queryName("urlranks").outputMode("complete").format("memory").start()
The memory sink outputs the data to a temporary table of the same name given in the queryName option.
We can observe this by querying the tables registered on Spark SQL:
scala>spark.sql("show tables").show()+--------+---------+-----------+|database|tableName|isTemporary|+--------+---------+-----------+||urlranks|true|+--------+---------+-----------+
In the expression in Example 7-1, query is of type StreamingQuery and it’s a handler to control the query life cycle.
Exploring the Data
Given that we are accelerating the log timeline on the producer side, after a few seconds, we can execute the next command to see the result of the first windows, as illustrated in Figure 7-1.
Note how the processing time (a few seconds) is decoupled from the event time (hundreds of minutes of logs):
urlRanks.select($"request",$"window",$"count").orderBy(desc("count"))

Figure 7-1. URL ranking: query results by window
We explore event time in detail in Chapter 12.
Summary
In these first steps into Structured Streaming, you have seen the process behind the development of a streaming application. By starting with a batch version of the process, you gained intuition about the data, and using those insights, we created a streaming version of the job. In the process, you could appreciate how close the structured batch and the streaming APIs are, albeit we also observed that some usual batch operations do now apply in a streaming context.
With this exercise, we hope to have increased your curiosity about Structured Streaming. You’re now ready for the learning path through this section.