
Audio Datasets
Abstract
This appendix provides a list of datasets which are available on the Web, that can be used as training and evaluation data for several audio analysis tasks.
Keywords
Audio datasets
Benchmarking
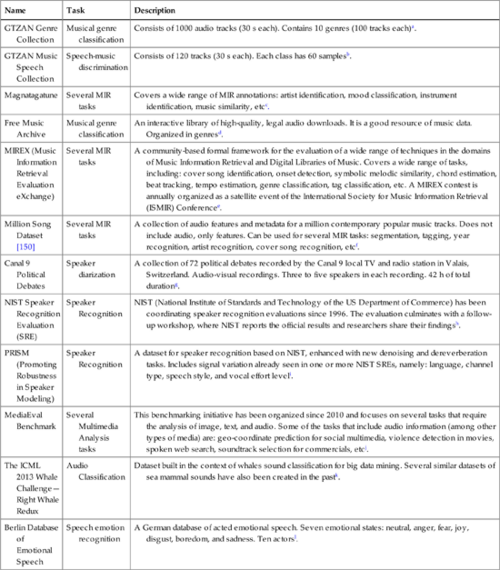
Several datasets and benchmarks that focus on audio analysis tasks are available on the Web. The diversity of the datasets is high with respect to: size, level of annotation, and addressed audio analysis tasks. For example, there are datasets for general audio event classification and segmentation; musical genre classification; speech emotion recognition; speech vs music discrimination; speaker diarization; speaker identification, etc. In addition, these datasets may or may not contain other non-audio media types (e.g. textual or visual information). It is hard to provide a complete list of all available datasets related to audio analysis. Table C.1 simply presents some representative datasets, which are available on the Web, for a selected audio analysis tasks.
A Short List of Available Datasets on Some Audio Analysis Tasks
| Name | Task | Description |
| GTZAN Genre Collection | Musical genre classification | Consists of 1000 audio tracks (30 s each). Contains 10 genres (100 tracks each)a. |
| GTZAN Music Speech Collection | Speech-music discrimination | Consists of 120 tracks (30 s each). Each class has 60 samplesb. |
| Magnatagatune | Several MIR tasks | Covers a wide range of MIR annotations: artist identification, mood classification, instrument identification, music similarity, etcc. |
| Free Music Archive | Musical genre classification | An interactive library of high-quality, legal audio downloads. It is a good resource of music data. Organized in genresd. |
| MIREX (Music Information Retrieval Evaluation eXchange) | Several MIR tasks | A community-based formal framework for the evaluation of a wide range of techniques in the domains of Music Information Retrieval and Digital Libraries of Music. Covers a wide range of tasks, including: cover song identification, onset detection, symbolic melodic similarity, chord estimation, beat tracking, tempo estimation, genre classification, tag classification, etc. A MIREX contest is annually organized as a satellite event of the International Society for Music Information Retrieval (ISMIR) Conferencee. |
| Million Song Dataset [150] | Several MIR tasks | A collection of audio features and metadata for a million contemporary popular music tracks. Does not include audio, only features. Can be used for several MIR tasks: segmentation, tagging, year recognition, artist recognition, cover song recognition, etcf. |
| Canal 9 Political Debates | Speaker diarization | A collection of 72 political debates recorded by the Canal 9 local TV and radio station in Valais, Switzerland. Audio-visual recordings. Three to five speakers in each recording. 42 h of total durationg. |
| NIST Speaker Recognition Evaluation (SRE) | Speaker Recognition | NIST (National Institute of Standards and Technology of the US Department of Commerce) has been coordinating speaker recognition evaluations since 1996. The evaluation culminates with a follow-up workshop, where NIST reports the official results and researchers share their findingsh. |
| PRISM (Promoting Robustness in Speaker Modeling) | Speaker Recognition | A dataset for speaker recognition based on NIST, enhanced with new denoising and dereverberation tasks. Includes signal variation already seen in one or more NIST SREs, namely: language, channel type, speech style, and vocal effort leveli. |
| MediaEval Benchmark | Several Multimedia Analysis tasks | This benchmarking initiative has been organized since 2010 and focuses on several tasks that require the analysis of image, text, and audio. Some of the tasks that include audio information (among other types of media) are: geo-coordinate prediction for social multimedia, violence detection in movies, spoken web search, soundtrack selection for commercials, etcj. |
| The ICML 2013 Whale Challenge—Right Whale Redux | Audio Classification | Dataset built in the context of whales sound classification for big data mining. Several similar datasets of sea mammal sounds have also been created in the pastk. |
| Berlin Database of Emotional Speech | Speech emotion recognition | A German database of acted emotional speech. Seven emotional states: neutral, anger, fear, joy, disgust, boredom, and sadness. Ten actorsl. |
a http://marsyas.info/download/data_sets/![]() .
.
b http://marsyas.info/download/data_sets/![]() .
.
c http://musicmachinery.com/2009/04/01/magnatagatune-a-new-research-data-set-for-mir/![]() .
.
d http://freemusicarchive.org/![]() .
.
e http://www.music-ir.org/mirex/wiki/MIREX_HOME![]() .
.
f http://labrosa.ee.columbia.edu/millionsong/![]() .
.
g http://www.idiap.ch/scientific-research/resources/canal-9-political-debates![]() .
.
h http://www.nist.gov/itl/iad/mig/sre.cfm![]() .
.
i http://code.google.com/p/prism-set/![]() .
.
j http://www.multimediaeval.org/![]() .
.
k http://www.kaggle.com/c/the-icml-2013-whale-challenge-right-whale-redux![]() .
.
l http://www.expressive-speech.net/![]() .
.
Notes:
• Speech emotion recognition has gained significant research interest during the last decade. Therefore, there are several databases, not always based only on speech but on visual cues. It is beyond the purpose of this book to provide a complete report on these datasets. However, a rather detailed description of the available audio-visual emotional databases can be found in http://emotion-research.net/wiki/Databases![]() .
.
• The reader may easily conclude that we have not mentioned databases that focus on Automatic Speech Recognition (ASR). This is because the purpose of the book is to focus on general audio analysis tasks and not on the transcription of spoken words.