
Audio Alignment and Temporal Modeling
Abstract
This chapter focuses on audio analysis methods that take into account the temporal evolution of the audio phenomena. This is done by preserving the short-term nature of the feature sequences, in order to either create methods that align two feature sequences or build temporal audio representations using Hidden Markov Models.
Keywords
Sequence alignment
Template matching
Dynamic time warping
DTW
Cost grid
Sakoe-Chiba
Itakura
Smith-Waterman
Hidden Markov Model
HMM
Baum-Welch
Viterbi algorithm
Trellis diagramn
Mixture of Gaussians
This chapter presents several methods that take into account the temporal evolution of the audio phenomena. In other words, we are no longer interested in computing mid-term feature statistics or long-term averages from the audio signals. On the contrary, our main concern is to preserve the short-term nature of the feature sequences in order to (a) devise techniques that are capable of aligning two feature sequences, and (b) build parametric, temporal representations of the audio signals by means of the Hidden Markov modeling methodology. The two goals are complementary in the sense that the former involves non-parametric approaches, whereas the latter aims at deriving parametric stochastic representations of the time-varying nature of the signals. The choice of method depends on the application and the availability of training data. Sometimes non-parametric techniques are the only option, as is, for example, the case with query-by-example scenarios where the user provides an audio example that needs to be detected in a corpus of audio recordings. On the other hand, if sufficient training data are available, it might be preferable to build parametric models, as has traditionally been the case in the speech recognition literature. The chapter starts with sequence alignment techniques and proceeds with a description of the Hidden Markov models (HMMs) and related concepts. We have found it necessary to provide lengthier theoretic descriptions in this chapter. However, care has been taken, so that the presentation is given from an engineering perspective, in order to facilitate the realization of practical solutions.
7.1 Audio Sequence Alignment
In the field of content-based audio retrieval, it is often useful to detect occurrences of an audio pattern in an audio stream, match audio data of varying lengths to a set of predefined templates, compare audio recordings to identify similar parts, and so on. The related terminology has its origins in speech processing literature, where similar problems have been intensively studied over past decades. For example, in an analogy of the word spotting problem in the speech recognition context, we can define the audio spotting or audio tracking task, where the goal is to detect occurrences of an audio example in a corpus of audio data. The audio example can be a digital audio effect that we need to track in the audio stream of a movie or a specific sound of a mammal that is likely to be repeated in a corpus of underwater recordings of very long duration. An endless list of similar examples can be compiled for a diversity of applications, ranging from intrusion detection systems to query-by-humming services. It is important to realize that we are interested in providing non-parametric solutions, i.e. we assume that we have not previously built parametric models that describe the problem at hand, based on prior knowledge.
An important requirement in such application scenarios is the ability to align feature sequences. Although in the literature the term sequence alignment refers to a broad class of problems, we start our discussion with the well-known template matching task, a direct application of which, can be encountered in the design of classifiers, when each class can be represented by one or more reference patterns (prototypes). The key idea behind template matching is that we can quantify how similar (dissimilar) two feature sequences are, even when they are not of equal length. For example, if you record your own voice repeating the word ‘library’ ten times with sufficiently long periods of silence between successive utterances and examine the resulting signals, you will observe that no two words are alike at the signal level. Some phonemes will be of shorter duration, whereas others will last longer, even if the differences are in the order of a few milliseconds. Furthermore, the same phoneme can be louder in some utterances. Yet, all signals are easily perceived by a human as the word ‘library’ and, in addition, if a different word is uttered, we will immediately percieve the difference.
7.1.1 Dynamic Time Warping
In order to deal with the alignment task from an algorithmic perspective, we understand that we need algorithms that are capable of quantifying similarity (dissimilarity) in an optimal way, by taking into account the fact that parts of one sequence may need to be locally stretched or compressed, so that the optimal alignment is achieved. The operations of stretching and compressing audio parts are collectively known as time warping. Due to the fact that time warping is determined dynamically during the joint inspection of two feature sequences, the term Dynamic Time Warping (DTW) is often used to denote the alignment of two feature sequences that represent audio signals.
To proceed further, certain definitions must first be given. Let ![]() and
and ![]() , be the two feature sequences to be aligned. In general,
, be the two feature sequences to be aligned. In general, ![]() and
and ![]() and
and ![]() are
are ![]() -dimensional feature vectors. Furthermore, let
-dimensional feature vectors. Furthermore, let ![]() be a dissimilarity function, e.g. the Euclidean distance function, which is defined as
be a dissimilarity function, e.g. the Euclidean distance function, which is defined as
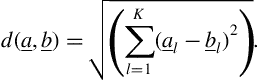
The DTW algorithms start with the construction of a cost grid, ![]() . Assuming that sequences
. Assuming that sequences ![]() and X are placed on the horizontal and vertical axis, respectively, the coordinates of node
and X are placed on the horizontal and vertical axis, respectively, the coordinates of node ![]() are the
are the ![]() th element (feature vector) of X and the
th element (feature vector) of X and the ![]() th element of R. Subsequently, a dynamic programming algorithm is employed. The algorithm starts from node (1,1) and the nodes of the grid are visited row-wise from left to right (an equivalent column-wise visiting scheme can also be adopted). At each node, we compute the accumulated cost to reach the node. At the end of this processing stage, the cost at node
th element of R. Subsequently, a dynamic programming algorithm is employed. The algorithm starts from node (1,1) and the nodes of the grid are visited row-wise from left to right (an equivalent column-wise visiting scheme can also be adopted). At each node, we compute the accumulated cost to reach the node. At the end of this processing stage, the cost at node ![]() represents the total matching cost between the two feature sequences. A zero cost indicates a perfect match. The higher the matching cost, the more dissimilar (less similar) the two sequences.
represents the total matching cost between the two feature sequences. A zero cost indicates a perfect match. The higher the matching cost, the more dissimilar (less similar) the two sequences.
Obviously, there are several open questions: which are the nodes from which a node, ![]() , can be reached? What is the cost of a transition from one node to another? Why is this procedure capable of generating the optimal matching cost? To answer such questions, we now provide a step-by-step description of two popular DTW schemes, which are based on the so-called Sakoe-Chiba [96] and Itakura [97] local path constraints.
, can be reached? What is the cost of a transition from one node to another? Why is this procedure capable of generating the optimal matching cost? To answer such questions, we now provide a step-by-step description of two popular DTW schemes, which are based on the so-called Sakoe-Chiba [96] and Itakura [97] local path constraints.
7.1.1.1 The Sakoe-Chiba Local Path Constraints
Initialization: We start with node (1,1) and set ![]() . Due to the fact that node (1,1) is the first node that we visit, we define its predecessor as the fictitious node (0,0). We are using a separate
. Due to the fact that node (1,1) is the first node that we visit, we define its predecessor as the fictitious node (0,0). We are using a separate ![]() matrix,
matrix, ![]() , to store the (best) predecessor of each node. In this case,
, to store the (best) predecessor of each node. In this case, ![]() .
.
Iteration: We adopt a row-wise visiting scheme (from left to right at each row) and compute the cost, ![]() , to reach node
, to reach node ![]() , as follows:
, as follows:
Equation (7.2) defines the local path constraints of the DTW scheme. Specifically, it defines that the allowable predecessors of node ![]() are the nodes:
are the nodes: ![]() (diagonal transition);
(diagonal transition); ![]() (vertical transition); and
(vertical transition); and ![]() (horizontal transition). In addition, it defines that the cost of the transition from a predecessor to node
(horizontal transition). In addition, it defines that the cost of the transition from a predecessor to node ![]() is equal to the local cost (dissimilarity) between
is equal to the local cost (dissimilarity) between ![]() and
and ![]() . The node that minimizes Eq. (7.2) is the best predecessor of node
. The node that minimizes Eq. (7.2) is the best predecessor of node ![]() and its coordinates are stored in the
and its coordinates are stored in the ![]() matrix. The value
matrix. The value ![]() stands for the optimal (lowest) cost to reach node
stands for the optimal (lowest) cost to reach node ![]() , i.e. the more efficient way to reach the node, given the local path constraints. This is guaranteed by Bellman’s optimality principle [98], which states that the optimal path to reach node
, i.e. the more efficient way to reach the node, given the local path constraints. This is guaranteed by Bellman’s optimality principle [98], which states that the optimal path to reach node ![]() from (1,1) is also optimal for each one of the nodes that constitute the path.
from (1,1) is also optimal for each one of the nodes that constitute the path.
Termination: After the accumulated cost has been computed for all nodes, we focus on node ![]() . The cost to reach this node is the overall matching cost between the two feature sequences. To extract the respective optimal path, we perform a backtracking procedure: starting from node
. The cost to reach this node is the overall matching cost between the two feature sequences. To extract the respective optimal path, we perform a backtracking procedure: starting from node ![]() , we visit the chain of predecessors until we reach the fictitious node (0,0), which is the predecessor of node (1,1). The extracted chain of nodes is known as the best (optimal) path of nodes.
, we visit the chain of predecessors until we reach the fictitious node (0,0), which is the predecessor of node (1,1). The extracted chain of nodes is known as the best (optimal) path of nodes.
Horizontal and vertical transitions in the best path imply that certain time warping was necessary in order to align the two sequences; the longer the horizontal and vertical transitions, the more intense the time warping phenomenon. The Sakoe-Chiba constraints permit arbitrarily long sequences of horizontal or vertical transitions to take place, which implies that they do not impose any time warping limits. This is not always a desirable behavior, hence the need for other types of local constraints, like the Itakura constraints, which are described next.
We provide an implementation of the Sakoe-Chiba DTW scheme in the dynamicTimeWarpingSakoeChiba() function. To call this function, type:
![]()
The first two input arguments are the ![]() -dimensional feature sequences to be aligned. Sequence
-dimensional feature sequences to be aligned. Sequence ![]() is placed on the vertical axis of the grid. The third argument is set to ‘1’ if we want to divide the resulting matching cost (first output argument) by the length (number of nodes) of the best path. This type of normalization is desirable when the DTW scheme is embedded in a classifier that matches unknown patterns against a set of prototypes, because the normalized cost is an arithmetic average that is independent of the length of the sequences that are being matched. The second output argument is the sequence of nodes (pairs of indices) of the optimal alignment path.
is placed on the vertical axis of the grid. The third argument is set to ‘1’ if we want to divide the resulting matching cost (first output argument) by the length (number of nodes) of the best path. This type of normalization is desirable when the DTW scheme is embedded in a classifier that matches unknown patterns against a set of prototypes, because the normalized cost is an arithmetic average that is independent of the length of the sequences that are being matched. The second output argument is the sequence of nodes (pairs of indices) of the optimal alignment path.
7.1.1.2 The Itakura Local Path Constraints
In several audio alignment tasks it is undesirable to permit arbitrarily long sequences of horizontal and vertical transitions, because we expect that two instances of an audio pattern cannot be radically different. It is possible to account for this requirement, if we replace the Sakoe-Chiba scheme with a different set of local constraints. A popular choice are the Itakura local path constraints [97], which are defined as:
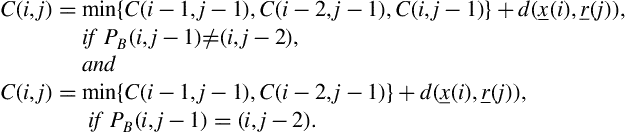
First of all, it can be easily observed that vertical transitions are not allowed at all. Secondly, it is possible to omit feature vectors from the sequence that has been placed on the vertical axis (one feature vector at a time), due to the fact that node ![]() is an allowable predecessor. A third important remark is that two successive horizontal transitions are not allowed due to the constraint that demands
is an allowable predecessor. A third important remark is that two successive horizontal transitions are not allowed due to the constraint that demands ![]() . These properties ensure that time warping cannot be an arbitrarily intense phenomenon. An implication of the Itakura constraints is that
. These properties ensure that time warping cannot be an arbitrarily intense phenomenon. An implication of the Itakura constraints is that ![]() . Furthermore, the Itakura constraints are asymmetric because, in the general case, if the sequences change axes, the resulting matching cost will be different (on the contrary, the Sakoe-Chiba constraints are symmetric).
. Furthermore, the Itakura constraints are asymmetric because, in the general case, if the sequences change axes, the resulting matching cost will be different (on the contrary, the Sakoe-Chiba constraints are symmetric).
The Itakura algorithm is initialized like the Sakoe-Chiba scheme and Eq. (7.3) is repeated for every node. In the end, node ![]() has accumulated the matching cost of the two sequences. The backtracking stage extracts the optimal sequence of nodes, assuming again that the best predecessor of each node has been stored in a separate matrix.
has accumulated the matching cost of the two sequences. The backtracking stage extracts the optimal sequence of nodes, assuming again that the best predecessor of each node has been stored in a separate matrix.
The software library that accompanies this book contains an implementation of the Itakura algorithm in the dynamicTimeWarpingItakura() function. To call this function, type:
![]()
For the sake of uniformity, we have preserved the input and output formats of the dynamicTimeWarpingSakoeChiba() function. Both functions have adopted the Euclidean distance as a dissimilarity measure.
7.1.1.3 The Smith-Waterman Algorithm
The Smith-Waterman (S-W) algorithm was originally introduced in the context of molecular sequence analysis [99]. It is a sequence alignment algorithm that can be used to discover similar patterns of data in sequences consisting of symbols drawn from a discrete alphabet.
An important characteristic of the S-W algorithm is that it employs a similarity function that generates a positive value to denote similarity between two symbols and a negative value for the case of dissimilarity. In addition, it introduces a gap penalty to reduce the accumulated similarity score of two symbol sequences when a part of one sequence is missing from the other. The algorithm is based on a standard dynamic programming technique to reveal the two subsequences that correspond to the optimal alignment. In the field of music information retrieval, the S-W algorithm has been used to provide working solutions for the tasks of cover song identification [100], query-by-humming [101], and melodic similarity [102]. In the more general context of audio alignment, variants of the algorithm that operate on a continuous feature space have been presented in [103,104].
In order to proceed with the description of the original S-W algorithm, let ![]() and
and ![]() be two symbol sequences, for which
be two symbol sequences, for which ![]() and
and ![]() , are the
, are the ![]() th and
th and ![]() th symbol, respectively. We first need to define a function,
th symbol, respectively. We first need to define a function, ![]() , that takes as input two discrete symbols,
, that takes as input two discrete symbols, ![]() and returns a measure of their similarity. The similarity function,
and returns a measure of their similarity. The similarity function, ![]() , is defined as
, is defined as
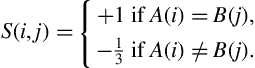
At the next stage, we construct a ![]() similarity grid,
similarity grid, ![]() . We assume that the rows and columns of the grid are indexed
. We assume that the rows and columns of the grid are indexed ![]() and
and ![]() , respectively. Each node of the grid is represented as a pair of coordinates,
, respectively. Each node of the grid is represented as a pair of coordinates, ![]() . The basic idea of the algorithm is that each node accumulates a similarity score by examining a set of nodes known as predecessors. After the accumulated score has been computed for all the nodes of the grid, the node with the highest score wins and a backtracking procedure reveals the two symbol subsequences that have contributed to this maximum score.
. The basic idea of the algorithm is that each node accumulates a similarity score by examining a set of nodes known as predecessors. After the accumulated score has been computed for all the nodes of the grid, the node with the highest score wins and a backtracking procedure reveals the two symbol subsequences that have contributed to this maximum score.
Initialization: The first row and column of the grid are initialized with zeros:
![]()
Iteration: For each node, ![]() , of the grid, we compute the accumulated similarity cost:
, of the grid, we compute the accumulated similarity cost:

A closer inspection of Eq. (7.5) reveals that node ![]() can be reached from the following predecessors:
can be reached from the following predecessors:
• Node ![]() , which refers to a diagonal transition. The local similarity between symbols
, which refers to a diagonal transition. The local similarity between symbols ![]() and
and ![]() is added to the similarity that has been accumulated at node
is added to the similarity that has been accumulated at node ![]() .
.
• Nodes ![]() , which indicate vertical transitions. Such transitions imply a deletion (gap) of
, which indicate vertical transitions. Such transitions imply a deletion (gap) of ![]() symbols from sequence
symbols from sequence ![]() (vertical axis) and introduce a gap penalty,
(vertical axis) and introduce a gap penalty, ![]() , proportional to the number of symbols being deleted.
, proportional to the number of symbols being deleted.
• Nodes ![]() address horizontal transitions,
address horizontal transitions, ![]() symbols long. The associated gap penalty is equal to
symbols long. The associated gap penalty is equal to ![]() and suggests that
and suggests that ![]() symbols need to be skipped from sequence
symbols need to be skipped from sequence ![]() during the sequence alignment procedure.
during the sequence alignment procedure.
• If all the above predecessors lead to a negative accumulated score, then ![]() and the predecessor of
and the predecessor of ![]() is set equal to the fictitious node (0,0).
is set equal to the fictitious node (0,0).
If, on the other hand, the accumulated score is positive, the best predecessor, ![]() , of
, of ![]() is the node that maximizes
is the node that maximizes ![]() ,
,
Equations (7.5) and (7.6) are repeated for all nodes of the grid, starting from node (1,1) and moving from left to right (increasing index ![]() ) and from the bottom to the top of the grid (increasing index
) and from the bottom to the top of the grid (increasing index ![]() ). Concerning the first row and first column of the grid, the predecessor is always set to the fictitious node (0,0). All predecessors,
). Concerning the first row and first column of the grid, the predecessor is always set to the fictitious node (0,0). All predecessors, ![]() , are stored in a separate
, are stored in a separate ![]() matrix to enable the final processing stage (the backtracking operation).
matrix to enable the final processing stage (the backtracking operation).
Backtracking: After ![]() has been computed for all nodes, we select the node that corresponds to the maximum score and follow the chain of predecessors until we encounter a (0,0) node (the algorithm ensures that a (0,0) node will definitely be encountered). The resulting chain of nodes is the best (optimal alignment) path. The coordinates of the nodes of the best path reveal the subsequences of
has been computed for all nodes, we select the node that corresponds to the maximum score and follow the chain of predecessors until we encounter a (0,0) node (the algorithm ensures that a (0,0) node will definitely be encountered). The resulting chain of nodes is the best (optimal alignment) path. The coordinates of the nodes of the best path reveal the subsequences of ![]() and
and ![]() , which have been optimally aligned, and indicate which symbol deletions have taken place. The backtracking procedure can be repeated to generate the second best alignment and so on. Care has to be taken so that each new backtracking operation ignores the nodes that have already participated in the preceding optimal paths.
, which have been optimally aligned, and indicate which symbol deletions have taken place. The backtracking procedure can be repeated to generate the second best alignment and so on. Care has to be taken so that each new backtracking operation ignores the nodes that have already participated in the preceding optimal paths.
We have implemented the standard S-W algorithm in the smithWaterman() function. To reproduce the example in the original paper ([99]), type:
![]()
The first two arguments are molecular sequences and the third argument controls the gap penalty. The fourth argument is set to ‘1’ because we want to have the output of the alignment procedure printed on the screen. If the last argument is set to ‘1’, then a figure with the best path is also plotted. The printout of the function call is:

It can be seen that ![]() has been aligned with
has been aligned with ![]() . The second subsequence is one symbol shorter, hence the deletion of symbol
. The second subsequence is one symbol shorter, hence the deletion of symbol ![]() . The deletion reduces the accumulated similarity score by
. The deletion reduces the accumulated similarity score by ![]() . Furthermore, the mapping of
. Furthermore, the mapping of ![]() to
to ![]() is equivalent to a symbol replacement that reduces the similarity score by
is equivalent to a symbol replacement that reduces the similarity score by ![]() . This is why the alignment score is equal to
. This is why the alignment score is equal to ![]() . Instead of character strings, we can also use the smithWaterman() function to align any type of sequences consisting of discrete symbols. The next example uses integers. Type:
. Instead of character strings, we can also use the smithWaterman() function to align any type of sequences consisting of discrete symbols. The next example uses integers. Type:
![]()
In this case, the output on the screen is:

7.2 Hidden Markov Modeling
A Hidden Markov Model (HMM) is a stochastic automaton that undergoes distinct transitions among states based on a set of probabilities. When the HMM arrives at a state, it emits an observation, which, in the general case, can be a multidimensional feature vector of discrete or continuous elements. The emission of observations is also governed by probabilistic rules.
During the design of an HMM it is of crucial importance to decide on the number of states and assign a meaningful stochastic interpretation to each state, so that the nature of the problem is reflected successfully on the structure of the HMM. These are not trivial issues in any sense and usually require a careful study of the stochastic nature of the phenomenon for which the HMM will be designed. For example, a phoneme in a speech recognition task can be modeled with a 3-state HMM, because, from a statistical perspective, the phoneme consists of three different parts (segments) and this is also reflected in the properties of most short-term feature sequences that can be extracted from the phoneme (e.g. the sequence of MFCCs). From a simplified point of view, the three parts refer to the beginning, steady state, and attenuation of the phoneme. As another example, in a speech/music/silence segmentation scenario, it can be useful to assign a class label to each state, leading to a 3-state HMM. As a general remark, the number of states is implicitly dictated by the interpretation of the most important stationarity changes in the signals of the problem at hand.
Another important issue has to do with the selection of the most appropriate features for the signals under study. For example, in speech recognition, it has been customary to use vectors of MFCCs as features and this has also turned out to be a more general trend in the field of audio processing. In the general case, the selected features should be able to reflect the temporal evolution of the signal on a short-term basis, without providing excessive detail. The designer of the HMM must be familiar with various audio features (see also Chapter 4) and needs to be able to experiment with their combinations. Usually, the resulting feature vectors are multidimensional and consist of continuous features. However, in order to provide a gentle introduction to the theory of HMMs, we focus on the case of discrete observations.
7.2.1 Definitions
Let ![]() be the set of HMM states and
be the set of HMM states and ![]() the discrete symbols of the alphabet of observations. The following three matrices represent the HMM, namely:
the discrete symbols of the alphabet of observations. The following three matrices represent the HMM, namely:
• The vector of initial state probabilities, ![]() . Element,
. Element, ![]() is the probability that the HMM starts its operation at the
is the probability that the HMM starts its operation at the ![]() th state.
th state.
• The state transition matrix, ![]() . We define that
. We define that ![]() , i.e.
, i.e. ![]() is the probability that the model jumps from state
is the probability that the model jumps from state ![]() to state
to state ![]() . Obviously,
. Obviously, ![]() is a
is a ![]() matrix and
matrix and ![]() .
.
• The matrix of emission probabilities, ![]() . We define that
. We define that ![]() . This means that
. This means that ![]() is the probability that the
is the probability that the ![]() th symbol of the alphabet is emitted from the
th symbol of the alphabet is emitted from the ![]() th state. It follows that
th state. It follows that ![]() is a
is a ![]() matrix and that
matrix and that ![]() .
.
7.2.2 An Example
Consider a 3-state HMM that is capable of emitting two discrete symbols. The HMM is represented by the following matrices:

It can be observed that the HMM always starts at the first state and that matrix ![]() is upper triangular. The latter implies that we are dealing with a left-to-right model because backward transitions do not exist, or, equivalently, a transition from a state always ends at a state with a higher index. This type of HMM has been very popular in the speech recognition field because it fits well with the temporal evolution of phonemes, the building blocks of speech utterances.
is upper triangular. The latter implies that we are dealing with a left-to-right model because backward transitions do not exist, or, equivalently, a transition from a state always ends at a state with a higher index. This type of HMM has been very popular in the speech recognition field because it fits well with the temporal evolution of phonemes, the building blocks of speech utterances.
Now assume that we ask the following question: what is the probability, ![]() , that the sequence of states
, that the sequence of states ![]() emits the sequence of symbols
emits the sequence of symbols ![]() ? The answer is based on computing the joint probability of the following events:
? The answer is based on computing the joint probability of the following events:
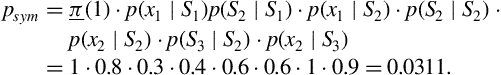
7.2.3 Some Useful Questions
Given an HMM, ![]() , it is important to be able to answer the following questions, which are encountered in almost every application involving HMMs:
, it is important to be able to answer the following questions, which are encountered in almost every application involving HMMs:
1. Find the sequence of states that emits the sequence of observations ![]() with the highest probability. The answer to this question is given by the Viterbi algorithm, a dynamic programming algorithm, which is further described in Section 7.3. The respective probability is also known as the Viterbi score.
with the highest probability. The answer to this question is given by the Viterbi algorithm, a dynamic programming algorithm, which is further described in Section 7.3. The respective probability is also known as the Viterbi score.
2. Compute the sum of probabilities from all sequences that are capable of emitting ![]() . The result is known as the recognition score or recognition probability of the observation sequence given the HMM. To compute this score, we employ the Baum-Welch algorithm, which is presented in Section 7.4.
. The result is known as the recognition score or recognition probability of the observation sequence given the HMM. To compute this score, we employ the Baum-Welch algorithm, which is presented in Section 7.4.
3. Assign values to the parameters of the HMM. So far, we assumed that the matrices (parameters) of the HMM are already known. In practice, they are the outcome of a training stage, which takes as input a set of observation sequences and determines the HMM parameters. The goal of the training stage is to maximize a probabilistic criterion. If Viterbi training is adopted, the training algorithm attempts to maximize the sum of Viterbi scores of all observation sequences of the training set. If Baum-Welch training is used, then the goal is to maximize the respective sum of recognition probabilities. Section 7.5.1 presents an outline of the Viterbi training scheme. The reader is referred to [66] for a detailed treatment of the Baum-Welch training method.
After the HMM has been trained, it can be used both as a recognition machine and a generator of observation sequences, depending on the application context. For example, in a classification problem with four classes, we can train one HMM per class. When an unknown feature sequence is to be classified, it is assigned to the class which is represented by the HMM that has produced the highest recognition (or Viterbi) score. HMMs can be used for numerous other tasks, e.g. for audio tracking and segmentation purposes. It would not be an exaggeration to claim that HMM methodology is the driving technology in several machine learning fields, with speech recognition being an outstanding example.
7.3 The Viterbi Algorithm
The goal of the Viterbi algorithm is to discover the optimal sequence of states given an HMM and a sequence of observations. Here, the term optimal is defined from a probabilistic perspective. In other words, the Viterbi algorithm seeks the sequence of HMM states that maximizes the joint probability of observations given the HMM.
The computational complexity of an exhaustive solution to the task is prohibitively high even for small-sized HMMs and short sequences of observations. For example, if a sequence is 30 observations long and an HMM consists of 5 states, the number of all possible state sequences is ![]() . It is, therefore, not a surprise that the algorithm resorts to dynamic programming principles to achieve its goal.
. It is, therefore, not a surprise that the algorithm resorts to dynamic programming principles to achieve its goal.
More specifically, it creates a cost grid (trellis diagram) by placing the states, ![]() of the HMM on the vertical axis and the sequence of observations,
of the HMM on the vertical axis and the sequence of observations, ![]() , on the horizontal axis. Each node,
, on the horizontal axis. Each node, ![]() , accumulates a probabilistic score,
, accumulates a probabilistic score, ![]() , which is interpreted as the probability to reach state
, which is interpreted as the probability to reach state ![]() , via an optimal sequence of states, after emitting the first
, via an optimal sequence of states, after emitting the first ![]() observations. The Viterbi algorithm computes the probability
observations. The Viterbi algorithm computes the probability ![]() for every node of the trellis diagram, starting from the first column (
for every node of the trellis diagram, starting from the first column (![]() ). The maximum value at the last column is, therefore, the probability to emit the complete sequence of observations via an optimal sequence of states, which is subsequently extracted by means of a standard backtracking operation. We now provide a description of the steps of the Viterbi algorithm in the case of discrete observations. Remember that
). The maximum value at the last column is, therefore, the probability to emit the complete sequence of observations via an optimal sequence of states, which is subsequently extracted by means of a standard backtracking operation. We now provide a description of the steps of the Viterbi algorithm in the case of discrete observations. Remember that ![]() is the vector of initial state probabilities,
is the vector of initial state probabilities, ![]() is the state transition matrix, and
is the state transition matrix, and ![]() is the matrix of observation probabilities (Section 7.2).
is the matrix of observation probabilities (Section 7.2).
Initialization: Assign values to the nodes of the first column of the grid:
![]()
It has been assumed that each symbol of the discrete alphabet has been given a positive identity. As a result, the feature sequence is actually a sequence of symbol identities and ![]() stands for the probability that the
stands for the probability that the ![]() th state emits the symbol with identity
th state emits the symbol with identity ![]() .
.
Iteration: For the ![]() th column,
th column, ![]() , compute the probability
, compute the probability ![]() :
:
An interesting observation is that the computation of ![]() only takes into account the previous column of the grid (
only takes into account the previous column of the grid (![]() ). This is also known as the first-order Markovian property. The equation examines each node of the previous column as a potential predecessor of the node
). This is also known as the first-order Markovian property. The equation examines each node of the previous column as a potential predecessor of the node ![]() . To this end,
. To this end, ![]() , is multiplied with the product
, is multiplied with the product ![]() , which is interpreted as the joint probability of the transition
, which is interpreted as the joint probability of the transition ![]() and the emission of symbol
and the emission of symbol ![]() from state
from state ![]() . In the end, the winner is the transition that yields the maximum probabilistic score. Bellman’s optimality principle [98] ensures that the resulting value,
. In the end, the winner is the transition that yields the maximum probabilistic score. Bellman’s optimality principle [98] ensures that the resulting value, ![]() , will represent the score of the optimal sequence of states that has ended with state
, will represent the score of the optimal sequence of states that has ended with state ![]() and has emitted the subsequence of observations until (including) the
and has emitted the subsequence of observations until (including) the ![]() th time instant. To enable backtracking, the coordinates of the best predecessor of node
th time instant. To enable backtracking, the coordinates of the best predecessor of node ![]() are stored in a separate matrix,
are stored in a separate matrix, ![]() , so that:
, so that:
![]()
Termination: Detect the maximum value at the last column of the grid. This value is also known as the Viterbi score of the HMM for the given sequence of observations. The node that contains the Viterbi score serves to start a backtracking procedure that visits each column in reverse order until the first column is reached. The resulting chain of nodes reveals the best-state sequence (best-path).
We have implemented the Viterbi algorithm for discrete observations in the scaledViterbiDisObs() function, which is based on a ‘scaling’ technique that deals with arithmetic stability issues due to the repeated multiplication of probabilities. The scaling method is based on the fact that if logarithms are used in Eq. (7.7), the products will be replaced by summations without affecting monotonicity. The scaled version of Eq. (7.7) is
To call the scaledViterbiDisObs() function, type:
![]()
where ![]() , and
, and ![]() are the vector of initial probabilities, the transition matrix, the matrix of observation probabilities, and the sequence of observations (symbol identities), respectively. The output of the algorithm is the scaled version of the Viterbi score and the best-state sequence (vector of state identities).
are the vector of initial probabilities, the transition matrix, the matrix of observation probabilities, and the sequence of observations (symbol identities), respectively. The output of the algorithm is the scaled version of the Viterbi score and the best-state sequence (vector of state identities).
7.4 The Baum-Welch Algorithm
Instead of seeking the best-state sequence, it is often desirable to compute the sum of scores of all the sequences of states that are capable of generating a given sequence of observations. A small modification in Eq. (7.7) can provide the answer to this question. Specifically, if the maximization operator is replaced with a summation, Eq. (7.7) becomes:
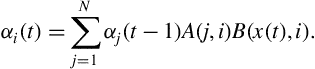
Equation (7.9) is computed for every node of the trellis diagram, following the node visiting scheme that was also adopted for the Viterbi algorithm. In the end, the values of the last column (![]() th column) are summed to produce the Baum-Welch score (or recognition probability),
th column) are summed to produce the Baum-Welch score (or recognition probability), ![]() , of the HMM, given the sequence of observations:
, of the HMM, given the sequence of observations:
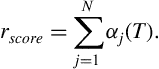
For this algorithm, it no longer makes sense to store the best predecessor of each node into a separate matrix and seek the best sequence of states, because every possible sequence of states contributes to the recognition score.
We have implemented a scaled version of the Baum-Welch algorithm in the scaledBaumWelchDisObs() function. The scaling technique is more complicated in this case, compared to the Viterbi method, and the reader is referred to [66] for a detailed description on the subject. To call the scaledBaumWelchDisObs() function, type:
![]()
The function has preserved the input format of the scaledViterbiDisObs() function. Obviously, the recognition score is the only output argument in this case.
Further to the functions that operate on discrete observations, we also provide their counterparts for the case of continuous features. The respective functions have been implemented in the scaledViterbiContObs() and scaledBaumWelchContObs() m-files. The notable difference is the format of the argument that refers to emission of observations at each state. In the case of continuous features, it no longer makes sense to use a simple matrix format and we need to resort to a more complicated structure based on cell arrays, so that the pdf of each state is modeled successfully. A more detailed description is given in the next section in conjunction with the training procedure.
7.5 HMM Training
The goal of the training stage is to ‘learn’ the parameters of the HMM. In the case of discrete observations, these are the vector of initial probabilities, ![]() , the state transition matrix,
, the state transition matrix, ![]() , and the matrix of emission probabilities,
, and the matrix of emission probabilities, ![]() . If continuous, one-dimensional observations are used, we will need to estimate a probability density function per state. For the more general case of continuous, multidimensional observations, we resort to multidimensional probability density functions to model the emission of observations at each state.
. If continuous, one-dimensional observations are used, we will need to estimate a probability density function per state. For the more general case of continuous, multidimensional observations, we resort to multidimensional probability density functions to model the emission of observations at each state.
Irrespective of the nature of observations, the HMM training stage requires a training dataset, i.e. a set consisting of sequences of observations representative of the problem under study. The basic training steps are as follows:
1. Initialize the HMM parameters, either randomly or based on some prior knowledge of the problem at hand.
2. Compute the score (Baum-Welch or Viterbi), ![]() , for each sequence,
, for each sequence, ![]() , of the training set, where
, of the training set, where ![]() and
and ![]() is the number of training sequences.
is the number of training sequences.
3. Compute the sum of scores, ![]() , that quantifies the extent to which the HMM has learned the problem. This is the quantity that the training stage seeks to maximize.
, that quantifies the extent to which the HMM has learned the problem. This is the quantity that the training stage seeks to maximize.
4. If ![]() remains practically unchanged between successive iterations, terminate the training stage, otherwise, proceed to the next step.
remains practically unchanged between successive iterations, terminate the training stage, otherwise, proceed to the next step.
5. Update the HMM parameters. The procedure, which updates the weights, depends on the nature of the features and the type of score that has been adopted.
6. Repeat from Step 2.
HMM training is a machine learning procedure. As is often the case with learning algorithms, the initialization scheme plays an important role. For example, if a parameter is initialized to a zero, it will never change value. Another effect of poor initialization is that the training algorithm may get trapped at a local maximum. Furthermore, there are several issues related to the size and quality of the training set. For example, a common question is how many training sequences are needed, given the size (number of parameters) of an HMM. The tutorial in [66] provides pointers to several answers to these issues. In the next section, we present the basics of Viterbi training for sequences of discrete observations. The Viterbi training scheme was chosen because its simplicity allows for an easier understanding of the key concepts that underlie HMM training.
7.5.1 Viterbi Training
Assume that we have initialized an HMM by means of an appropriate initialization scheme. Viterbi training follows the aforementioned training outline and is based on the idea that if each training sequence is fed as input to the HMM, the Viterbi algorithm can be used to compute the respective score and best-state sequence.
7.5.1.1 Discrete Observations
The procedure, which updates the HMM parameters, is based on computing frequencies of occurrences of events following the inspection of the extracted best-state sequences. For example, consider that the following two sequences of observations and respective best-state sequences are available during the HMM training stage, where ![]() , are the HMM states and
, are the HMM states and ![]() the two discrete symbols of the alphabet:
the two discrete symbols of the alphabet:

To understand the update rule, let us focus on element ![]() , which stands for the probability
, which stands for the probability ![]() , i.e. the probability that the model makes a self-transition to
, i.e. the probability that the model makes a self-transition to ![]() . If we inspect the two best-state sequences, we understand that this particular self-transition has only occurred once. In addition, it can be observed that, in total, three transitions took place from
. If we inspect the two best-state sequences, we understand that this particular self-transition has only occurred once. In addition, it can be observed that, in total, three transitions took place from ![]() to any state. The conditional probability,
to any state. The conditional probability, ![]() , is therefore updated as follows:
, is therefore updated as follows:
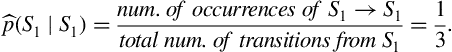
If this rationale is repeated for every element of matrix ![]() , the updated matrix,
, the updated matrix, ![]() , is:
, is:
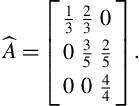
In the general case,

We now turn our attention to matrix ![]() . In this case, the update rule for element
. In this case, the update rule for element ![]() is:
is:

In the above example, ![]() .
.
Finally, the vector, ![]() , of initial probabilities is updated as:
, of initial probabilities is updated as:
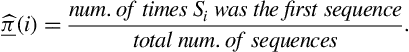
In our example, ![]() .
.
We provide an implementation of the Viterbi training scheme for the case of discrete observations in the viterbiTrainingDo() function. Before you call this function, you need to decide on the number of states, the length of the discrete alphabet, and wrap the training set in a cell array (![]() , fifth input argument in the call below). Each cell contains a sequence of discrete observations (symbol identities). To call the function, type:
, fifth input argument in the call below). Each cell contains a sequence of discrete observations (symbol identities). To call the function, type:
![]()
The first four input arguments serve to initialize the training procedure. The sixth input argument controls the maximum number of iterations (epochs) during which the training set will be processed until the algorithm terminates. The algorithm computes a sum of scores at the beginning of each iteration. If the absolute difference of this cumulative score is considered to be negligible between two successive iterations, i.e. the absolute difference is less than ![]() (last input argument), the algorithm terminates, even if the maximum number of epochs has not been reached. The first three output arguments refer to the trained HMM. The last argument (
(last input argument), the algorithm terminates, even if the maximum number of epochs has not been reached. The first three output arguments refer to the trained HMM. The last argument (![]() ) is a vector, the
) is a vector, the ![]() th element of which is the sum of Viterbi scores in the beginning of the
th element of which is the sum of Viterbi scores in the beginning of the ![]() th stage.
th stage.
7.5.1.2 Continuous Observations
If we are dealing with continuous, one-dimensional (or multidimensional) feature sequences, the updating procedure for vector ![]() and matrix
and matrix ![]() is unaltered. However, a different approach needs to be adopted for emission probabilities because a continuous feature space demands the use of probability density functions at each state. In this case, it is common to assume that each pdf is a multivariate Gaussian or a mixture of multivariate Gaussians. In practice, the latter is a very popular assumption, because a pdf can be well approximated by a mixture of a sufficient number of Gaussians to the expense of increasing the number of parameters to be estimated.
is unaltered. However, a different approach needs to be adopted for emission probabilities because a continuous feature space demands the use of probability density functions at each state. In this case, it is common to assume that each pdf is a multivariate Gaussian or a mixture of multivariate Gaussians. In practice, the latter is a very popular assumption, because a pdf can be well approximated by a mixture of a sufficient number of Gaussians to the expense of increasing the number of parameters to be estimated.
The m-file viterbiTrainingMultiCo provides an implementation of the Viterbi training scheme for the general case of continuous, multidimensional features, under the assumption that the density function at each state is Gaussian. The main idea is that we inspect the output of the Viterbi scoring mechanism and, for each state, we assemble the feature vectors that were emitted by the state. The resulting set of vectors is used as input to a Maximum Likelihood Estimator [5], which returns the mean vector and covariance matrix of the multivariate Gaussian. To call the viterbiTrainingMultiCo function, type:
![]()
The ![]() input argument is a nested cell array, the length of which is equal to the number of states. The
input argument is a nested cell array, the length of which is equal to the number of states. The ![]() th cell,
th cell, ![]() , is a vector of cells:
, is a vector of cells: ![]() and
and ![]() are the mean vector and covariance matrix of the pdf of the
are the mean vector and covariance matrix of the pdf of the ![]() th state. The
th state. The ![]() input argument is also a cell array: each cell contains a multidimensional feature sequence. The remaining input arguments have the same functionality as in the viterbiTrainingDo() function. Concerning the output arguments, a notable difference is the
input argument is also a cell array: each cell contains a multidimensional feature sequence. The remaining input arguments have the same functionality as in the viterbiTrainingDo() function. Concerning the output arguments, a notable difference is the ![]() cell array, the format of which follows the
cell array, the format of which follows the ![]() input variable.
input variable.
A version of the Viterbi scheme for the case of Gaussian mixtures (function viterbiTrainingMultiCoMix()) is also provided in the accompanying software library. The header of the viterbiTrainingMultiCoMix() function has preserved the format of viterbiTrainingMultiCo(), although in this case, the ![]() argument is more complicated to reflect the fact that we have adopted Gaussian mixtures. At the end of this chapter, we provide several exercises that will help you gain a better understanding of the Viterbi training schemes that have been discussed.
argument is more complicated to reflect the fact that we have adopted Gaussian mixtures. At the end of this chapter, we provide several exercises that will help you gain a better understanding of the Viterbi training schemes that have been discussed.
7.6 Exercises
1. (D5) This exercise combines techniques from several other chapters. Complete the following steps:
• Record your voice 10 times creating 10 WAVE files. Name the files a1.wav, a2.wav, ![]() , a5.wav, b1.wav, b2.wav,
, a5.wav, b1.wav, b2.wav, ![]() , b5.wav. The a{1-5}.wav files contain your voice singing a short melody that you like. Files b{1-5}.wav contain a different melody. Place all files in a single folder.
, b5.wav. The a{1-5}.wav files contain your voice singing a short melody that you like. Files b{1-5}.wav contain a different melody. Place all files in a single folder.
• Write a function, say ![]() , that loads a WAVE file and uses a silence detector to remove the silence/background noise from the beginning and end of the recording. Then, it uses a short-term feature extraction technique to generate a sequence of MFCCs from the file.
, that loads a WAVE file and uses a silence detector to remove the silence/background noise from the beginning and end of the recording. Then, it uses a short-term feature extraction technique to generate a sequence of MFCCs from the file.
• Write a second function, ![]() , that takes as input the path to a folder and calls
, that takes as input the path to a folder and calls ![]() for each WAVE file in the folder. The resulting feature sequences are grouped in a cell array,
for each WAVE file in the folder. The resulting feature sequences are grouped in a cell array, ![]() .
.
• Select in random a feature sequence (example) from the ![]() array and match it against all the other sequences using the Itakura local path constraints. Mark the top three results. They correspond to the three lowest matching costs. How many of them come from the same melody with the random example? Does the lowest matching cost refer to the correct melody?
array and match it against all the other sequences using the Itakura local path constraints. Mark the top three results. They correspond to the three lowest matching costs. How many of them come from the same melody with the random example? Does the lowest matching cost refer to the correct melody?
• Repeat using the Sakoe-Chiba constraints.
2. (D4) In a way, the previous exercise designs a binary classifier of melodies. Repeat the experiment using the leave-one-out validation method and compute the classification accuracy. An error occurs whenever none of the two lowest matching scores corresponds to the correct melody.
3. (D4) This exercise is about the so-called endpoint constraints that can be used to enhance a Dynamic Time Warping scheme. Specifically, let ![]() and
and ![]() be the lengths of feature sequences
be the lengths of feature sequences ![]() and
and ![]() , respectively. Sequence
, respectively. Sequence ![]() is placed on the vertical axis of the DTW cost grid. Modify the dynamicTimeWarpingItakura() function so that instead of demanding that the backtracking procedure starts from node
is placed on the vertical axis of the DTW cost grid. Modify the dynamicTimeWarpingItakura() function so that instead of demanding that the backtracking procedure starts from node ![]() , we examine the nodes
, we examine the nodes ![]() and select the one that has accumulated the lowest matching cost.
and select the one that has accumulated the lowest matching cost. ![]() is a user-defined parameter. Its value depends on how much silence/background noise we expect to encounter after the end of the useful signal. For example, if the short-term processing hop size is equal to 20 ms and we expect that, on average, due to segmentation errors, 200 ms of silence are expected to be encountered at the end of the useful part of the feature sequence, then,
is a user-defined parameter. Its value depends on how much silence/background noise we expect to encounter after the end of the useful signal. For example, if the short-term processing hop size is equal to 20 ms and we expect that, on average, due to segmentation errors, 200 ms of silence are expected to be encountered at the end of the useful part of the feature sequence, then, ![]() . This exercise assumes that the sequence that has been placed on the horizontal axis is ‘clean.’ If this is not the case, we may have to seek the lowest matching score in more than one column at the right end of the grid.
. This exercise assumes that the sequence that has been placed on the horizontal axis is ‘clean.’ If this is not the case, we may have to seek the lowest matching score in more than one column at the right end of the grid.
4. (D5) Further to the right endpoint constraints, modify the dynamicTimeWarpingItakura() function, so that it can also deal with silence/background noise in the beginning (left endpoint) of the signal that has been mapped on the vertical axis?
5. (D4) Load the WindInstrumentPitch mat-file from the accompanying library. It contains the cell array ![]() , with pitch-tracking sequences that have been extracted from a set of monophonic recordings of a wind instrument, the clarinet. Select at random a pitch sequence, say
, with pitch-tracking sequences that have been extracted from a set of monophonic recordings of a wind instrument, the clarinet. Select at random a pitch sequence, say ![]() , and concatenate, in random order, all the remaining sequences, to create one single, artificial sequence,
, and concatenate, in random order, all the remaining sequences, to create one single, artificial sequence, ![]() . Use the smithWaterman() function to detect the subsequence of
. Use the smithWaterman() function to detect the subsequence of ![]() that is most similar to
that is most similar to ![]() . Before you feed the sequences to the smithWaterman() function, round each value to the closest integer. Use different colors to plot in the same figure sequence
. Before you feed the sequences to the smithWaterman() function, round each value to the closest integer. Use different colors to plot in the same figure sequence ![]() and the pattern that has been returned by the smithWaterman() function. Repeat the experiment several times and comment on your results. Hint: The best path reveals the endpoints of the subsequence that is most similar to the query (sequence X).
and the pattern that has been returned by the smithWaterman() function. Repeat the experiment several times and comment on your results. Hint: The best path reveals the endpoints of the subsequence that is most similar to the query (sequence X).
6. (D4) Repeat the previous experimental setup. However, this time, quantize each pitch value to the nearest semitone frequency. For convenience, we assume that the frequencies, ![]() , of the semitones of the chromatic scale span five octaves in total, starting from 55 Hz, i.e. they are given by the equation:
, of the semitones of the chromatic scale span five octaves in total, starting from 55 Hz, i.e. they are given by the equation:
![]()
Have the results improved in comparison with the previous exercise, which was simply rounding each pitch value to the closest integer?
7. (D4) In this exercise, you are asked to implement a variant of the Smith-Waterman algorithm that can receive as input, continuous, multidimensional feature vectors. To this end, you will need to modify the similarity function, so that it can operate on multidimensional feature vectors. A similarity function, ![]() , that can be adopted is the cosine of the angle of two vectors,
, that can be adopted is the cosine of the angle of two vectors, ![]() and
and ![]() , which is defined as:
, which is defined as:
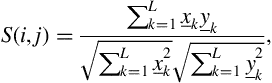
where ![]() is the dimensionality of the feature space. By its definition, the proposed similarity measure is bounded in
is the dimensionality of the feature space. By its definition, the proposed similarity measure is bounded in ![]() . Negative values indicate dissimilarity. An interesting property of the cosine of the angle of two vectors is that it is invariant to scaling. A physical interpretation of scaling is that if the two vectors are multiplied by constants, the cosine of their angle is not affected.
. Negative values indicate dissimilarity. An interesting property of the cosine of the angle of two vectors is that it is invariant to scaling. A physical interpretation of scaling is that if the two vectors are multiplied by constants, the cosine of their angle is not affected.
Modify the smithWaterman() function, so that it can deal with continuous, multidimensional feature vectors, by adopting the aforementioned similarity function.
8. (D5) Create a MATLAB function that enhances the Viterbi algorithm. In its standard version, the algorithm examines the nodes ![]() , of the previous column of the grid to compute the score at node
, of the previous column of the grid to compute the score at node ![]() . Furthermore, the cost,
. Furthermore, the cost, ![]() , of the transition
, of the transition ![]() is equal to
is equal to
![]()
where ![]() is the
is the ![]() th observation, assuming a discrete alphabet. In this enhanced version,
th observation, assuming a discrete alphabet. In this enhanced version, ![]() previous columns need to be searched. Furthermore, we depart from the world of discrete observations and assume that the feature sequence consists of continuous, multidimensional feature vectors. In addition, the cost of the transition,
previous columns need to be searched. Furthermore, we depart from the world of discrete observations and assume that the feature sequence consists of continuous, multidimensional feature vectors. In addition, the cost of the transition, ![]() , is now defined as:
, is now defined as:
![]()
We can see that the new transition cost is a function of the ![]() feature vectors,
feature vectors, ![]() . For example, if we work with a two-state HMM, where each state is interpreted as an audio class, (e.g. speech vs music), we can define that
. For example, if we work with a two-state HMM, where each state is interpreted as an audio class, (e.g. speech vs music), we can define that
![]()
which is the posterior probability that the ![]() feature vectors belong to the
feature vectors belong to the ![]() class (speech or music). If, in addition, the transitions among states are equiprobable, the proposed enhanced Viterbi scheme solves the segmentation problem that was also examined in Section 6.1.2 from a cost-function optimization perspective.
class (speech or music). If, in addition, the transitions among states are equiprobable, the proposed enhanced Viterbi scheme solves the segmentation problem that was also examined in Section 6.1.2 from a cost-function optimization perspective.
In this exercise, your implementation, say ![]() , will receive as input a vector of initial probabilities, a transition matrix, the
, will receive as input a vector of initial probabilities, a transition matrix, the ![]() parameter, a feature sequence, and the name of the m-file in which function
parameter, a feature sequence, and the name of the m-file in which function ![]() is implemented. The output is the enhanced Viterbi score and the best-state sequence.
is implemented. The output is the enhanced Viterbi score and the best-state sequence.
9. (D5) Develop a very simple, HMM-based classifier of melodies. Load the WindInstrumentPitch mat-file. Further to the ![]() array, a second cell array,
array, a second cell array, ![]() is also loaded into memory. It contains the names of the clarinet files from which the pitch sequences were extracted. Naming convention requires that all filenames that start with the same digit refer to variations of the same melody. For example, clarinet11e.wav and clarinet11i.wav are variations of the melody in the clarinetModel1.wav file. You will now need to go through the following steps:
is also loaded into memory. It contains the names of the clarinet files from which the pitch sequences were extracted. Naming convention requires that all filenames that start with the same digit refer to variations of the same melody. For example, clarinet11e.wav and clarinet11i.wav are variations of the melody in the clarinetModel1.wav file. You will now need to go through the following steps:
(a) Plot the sequence that refers to the clarinetmodel2.wav file. The respective tag in the ![]() cell array is ‘clarinetmodel2.wav.’ It can be observed that it is a sequence of five notes.
cell array is ‘clarinetmodel2.wav.’ It can be observed that it is a sequence of five notes.
(b) Round each value to the closest integer.
(c) Create a left-to-right, 5-state HMM, where each state corresponds to a note. Each state is only linked with itself and the next state in the chain. The initial probability of the first state is equal to 1.
(d) Each state emits discrete observations. The highest emission probabilities stem from a narrow range of integers around the frequency of the note. The range of integers is a user-defined parameter and its physical meaning is our tolerance with respect to the pitch frequency of the note. All frequencies outside the narrow interval of tolerance are assigned very low probabilities, in the order of 0.001.
(e) Create a second HMM for the melody in the clarinetmodel1.wav file. The respective tag in the ![]() cell array is ‘clarinetmodel1.wav.’
cell array is ‘clarinetmodel1.wav.’
(f) After you construct the two HMMs and set their parameters manually (no training is involved), select a variation of one of the two melodies, e.g. the ![]() sequence. Feed the sequence to both HMMs and compare the Viterbi scores.
sequence. Feed the sequence to both HMMs and compare the Viterbi scores.
(g) Repeat for all variations and compute the classification accuracy.
10. (D5) This exercise simulates an audio tracking scenario:
(a) Load the musicSmallData mat-file. It contains feature sequences from 15 audio recordings.
(b) Use only the MFCCs and discard the rest of the features.
(c) Select the sequence of MFCCs from one recording and use it as the example to be searched.
(d) Concatenate all sequences of MFCCs (including the example) to form a single sequence, ![]() .
.
(e) Distort sequence ![]() as follows: every
as follows: every ![]() feature vectors (
feature vectors (![]() is a user parameter), select one vector in random. Generate a random number,
is a user parameter), select one vector in random. Generate a random number, ![]() , in the interval
, in the interval ![]() . If
. If ![]() , repeat the selected feature vector once, i.e. insert a copy of the vector next to the existing one. If
, repeat the selected feature vector once, i.e. insert a copy of the vector next to the existing one. If ![]() , add random noise to each MFCC coefficient of the vector. The intensity of the noise should not exceed a threshold that is equal to (
, add random noise to each MFCC coefficient of the vector. The intensity of the noise should not exceed a threshold that is equal to (![]() the magnitude of the coefficient). Finally, if
the magnitude of the coefficient). Finally, if ![]() , perform a random permutation of the
, perform a random permutation of the ![]() feature vectors.
feature vectors.
(f) Use the Itakura and Sakoe-Chiba local path constraints to detect the example in the distorted version of sequence ![]() . It is important to remember that, for this task, backtracking can start from any node of the last
. It is important to remember that, for this task, backtracking can start from any node of the last ![]() columns (
columns (![]() is a user-defined parameter) and Y is placed on the vertical axis.
is a user-defined parameter) and Y is placed on the vertical axis.
(g) Repeat the detection operation using the Smith-Waterman algorithm. Use the cosine of the angle of two feature vectors as a local similarity function.
(h) Experiment with different examples and comment on the results.