
Chapter 5. Sources of Semantic Data
You now have some tools for storing, querying, and manipulating semantic data. However, none of this is much fun if you don’t have any data to put into your triplestore. One of the longest-running criticisms of the semantic web was that no one was publishing data using the standards, so they weren’t very useful. Although this certainly held true for a while, these days many more applications, particularly in the social web application realm, are beginning to publish data using semantic web standards.
In this chapter, we will demonstrate how you can obtain and use semantic data from various sources. In doing so, we will also introduce standard vocabularies for describing social networks, music, and movies.
At the end of this chapter, we’ll explore Freebase, a semantically enabled social database that provides strong identifiers for millions of entities and vocabularies for hundreds of subject matter domains.
Friend of a Friend (FOAF)
In the previous chapter we introduced FOAF files as an example of how to show the structure of RDF. The FOAF namespace is used to represent information about people, such as their names, birthdays, pictures, blogs, and especially the other people that they know. Thus FOAF files are particularly good for representing data that appears on social networks, and several social networks allow you to access data about their users as FOAF files.
For example, here’s a file from hi5, one of the largest social networks worldwide, that is located at http://api.hi5.com/rest/profile/foaf/358280494:
<rdf:RDF xmlns:hi5="http://api.hi5.com/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:lang="http://purl.org/net/inkel/rdf/schemas/lang/1.1#">
<foaf:Person rdf:nodeId="me">
<foaf:nick>Toby</foaf:nick>
<foaf:givenName>Toby</foaf:givenName>
<foaf:surName>Segaran</foaf:surName>
<foaf:birthday>1-20</foaf:birthday>
<foaf:img rdf:resource=
"http://photos3.hi5.com/0057/846/782/gE64Yc846782-01.jpg"/>
<foaf:weblog rdf:resource="http://blog.kiwitobes.com"/>
<foaf:gender>male</foaf:gender>
<lang:masters>en</lang:masters>
<foaf:homePage rdf:resource=
"http://www.hi5.com/friend/profile/displayProfile.do?userid=358280494"/>
<foaf:knows>
<foaf:Person>
<foaf:nick>Jamie</foaf:nick>
<rdfs:seeAlso rdf:resource=
"http://api.hi5.com/rest/profile/foaf/241087912"/>
</foaf:Person>
</foaf:knows>
</foaf:Person>
</rdf:RDF>This is Toby’s FOAF file from hi5. Since Toby is very unpopular, his only friend is Jamie. The file also provides a lot of other information about Toby, including his gender, birthday, where you can find a picture of him, and the location of his blog. The FOAF namespace, which you can find at http://xmlns.com/foaf/0.1/, defines about 50 different things that a file can say about a person.
Many other social networks, such as LiveJournal, also publish FOAF files that can be accessed without signing up for an API key. Because of this, it’s almost certain that FOAF files are the most common RDF files available on the Web today.
To reconstruct a portion of the social network from these files, you
can build a simple breadth-first crawler for FOAF files. Graph objects from
RDFLib have a method called parse, which takes a URL and turns it
into an RDF graph, so you don’t need to worry about the details of the
file format. The great thing is that when you parse one FOAF file, you not
only get information about one person, but also the URLs of the
FOAF files of all their friends. This is a very important
feature of the semantic web: in the same way that World Wide Web is
constructed by linking documents together, the semantic web is made up of
connected machine-readable files.
Take a look at the code for a FOAF crawler, which you can download from http://semprog.com/psw/chapter5/foafcrawler.py:
from rdflib.Graph import Graph
from rdflib import Namespace,BNode
FOAF = Namespace("http://xmlns.com/foaf/0.1/")
RDFS = Namespace("http://www.w3.org/2000/01/rdf-schema#")
def make_foaf_graph(starturi, steps=3):
# Initialize the graph
foafgraph = Graph()
# Keep track of where we've already been
visited = set()
# Keep track of the current crawl queue
current = set([starturi])
# Crawl steps out
for i in range(steps):
nextstep = set()
# Visit and parse every URI in the current set, adding it to the graph
for uri in current:
visited.add(uri)
tempgraph = Graph()
# Construct a request with an ACCEPT header
# This tells pages you want RDF/XML
try:
reqObj = urllib2.Request(uri, None, {"ACCEPT":"application/rdf+xml"})
urlObj = urllib2.urlopen(reqObj)
tempgraph.parse(urlObj,format='xml')
urlObj.close()
except:
print "Couldn't parse %s" % uri
continue
# Work around for FOAF's anonymous node problem
# Map blank node IDs to their seeAlso URIs
nm = dict([(str(s), n) for s, _, n in
tempgraph.triples((None, RDFS['seeAlso'], None))])
# Identify the root node (the one with an image for hi5, or the one
# called "me")
imagelist=list(tempgraph.triples((None, FOAF['img'], None)))
if len(imagelist)>0:
nm[imagelist[0][0]]=uri
else:
nm[''],nm['#me']=uri,uri
# Now rename the blank nodes as their seeAlso URIs
for s, p, o in tempgraph:
if str(s) in nm: s = nm[str(s)]
if str(o) in nm: o = nm[str(o)]
foafgraph.add((s, p, o))
# Now look for the next step
newfriends = tempgraph.query('SELECT ?burl ' +
'WHERE {?a foaf:knows ?b .
?b rdfs:seeAlso ?burl . }',
initNs={'foaf':FOAF,'rdfs':RDFS})
# Get all the people in the graph. If we haven't added them already,
# add them to the crawl queue
for friend in newfriends:
if friend[0] not in current and friend[0] not in visited:
nextstep.add(friend[0])
visited.add(friend[0])
# The new queue becomes the current queue
current = nextstep
return foafgraph
if __name__ == '__main__':
# Seed the network with Robert Cook, creator of D/Generation
g = make_foaf_graph('http://api.hi5.com/rest/profile/foaf/241057043', steps=4)
# Print who knows who in our current graph
for row in g.query('SELECT ?anick ?bnick '+
'WHERE { ?a foaf:knows ?b . ?a foaf:nick ?anick . ?b
foaf:nick ?bnick . }',
initNs={'foaf':FOAF}):
print "%s knows %s" % rowThe function make_foaf_graph takes the URI of a FOAF
file and the number of steps to search outward as parameters. Don’t search
too far, or your network will become very large and you may get banned
from the service that you’re crawling. Notice how we simply give the URI
directly to graph.parse, and it takes care of
downloading the file and turning it into an RDF graph.
From there, it’s easy to query the graph using SPARQL with the
namespaces that have been defined (FOAF and RDFS) to find people in the
graph and their seeAlso property:
SELECT ?burl WHERE {?a foaf:knows ?b . ?b rdfs:seeAlso ?burl . }
initNs={'foaf':FOAF,'rdfs':RDFS}This returns a list of URIs on the right side of the
seeAlso property that tell us where to find more
information about the people in the graph. If these URIs haven’t already
been visited, they’re added to the queue of URIs that we want to parse and
add to the graph.
The main method builds a graph from a starting node and uses a
simple query to find all the relationships in the graph and the nicknames
(foaf:nick) of the people in those relationships. Try
this from the command line:
$ python foafcrawler.py Michael knows Joy Susan knows Ellen Michael knows Joe Mark knows Genevieve Michael knows James Michael knows Kimberly Jon knows John Michael knows Stuart Susan knows Jayce Toby knows Jamie etc...
You can change the starting point and even the social network used
by changing the call to make_foaf_graph. If you like,
you can find out whether your favorite social network supports FOAF and
build a graph around yourself and your friends.
Also, remember that although we’ve used the resources exposed by hi5 in this example, FOAF files can be published by anyone. Rather than joining a social network, you could put a FOAF file on your own web server that connects to other people’s files in hi5 or LiveJournal or even FOAF files that they have created themselves. By having a standard way of describing information about people and the relationships between them, it’s possible to separate the network of people from the particular site on which it happens to exist.
You can try crawling a distributed social network by starting with Tim Berners-Lee’s FOAF page. Change the line that seeds the network to:
g=make_foaf_graph('http://www.w3.org/People/Berners-Lee/card',steps=2)Running the code now should crawl out from Tim Berners-Lee, not just within the W3C site, but anywhere his “see also” links point to.
Graph Analysis of a Social Network
Being able to crawl and store graphs such as social networks means you can also apply a little graph theory to understand more about the nature of the graph. In the case of a social network, several questions come to mind:
Who are the most connected people?
Who are the most influential people? (We’ll see in a moment how “most influential” may differ from “most connected.”)
Where are the cliques?
How much do people stick within their own social groups?
All of these questions can be explored using well-studied methods
from graph theory. Later in this section we’ll analyze the FOAF graph,
but first we need to get a Python package called NetworkX. You can download NetworkX from http://networkx.lanl.gov/, or if
you have Python setuptools, install it with
easy_install:
$ easy_install networkx
Figure 5-1 shows a simple graph with lettered nodes that we’ll use for a first example. In the following Python session, we’ll construct that graph and run some analyses on it to demonstrate the different features of NetworkX:
>>> import networkx as nx
>>> g = nx.Graph()
>>> g.add_edges_from([('a', 'b'), ('b', 'c'),
... ('b', 'd'), ('b', 'e'), ('e', 'f'), ('f', 'g')]) # Add a few edges
>>> g.add_edge('c','d') # Add a single edge
>>> nx.degree(g,with_labels=True) # Node degree
{'a': 1, 'c': 2, 'b': 4, 'e': 2, 'd': 2, 'g': 1, 'f': 2}
>>> nx.betweenness_centrality(g) # Node centrality
{'a': 0.0, 'c': 0.0, 'b': 0.7333, 'e': 0.5333, 'd': 0.0, 'g': 0.0, 'f': 0.3333}
>>> nx.find_cliques(g) # Cliques
[['b', 'c', 'd'], ['b', 'a'], ['b', 'e'], ['g', 'f'], ['f', 'e']]
>>> nx.clustering(g,with_labels=True) # Cluster coefficient
{'a': 0.0, 'c': 1.0, 'b': 0.1666, 'e': 0.0, 'd': 1.0, 'g': 0.0, 'f': 0.0}
>>> nx.average_clustering(g) # Average clustering
0.30952380952380959
A few different concepts are illustrated in this session. We start
by creating a graph and adding the edges to it
(a->b, b->c, etc.) so that
it represents the graph in Figure 5-1. Then we run
a few different analyses on the graph:
degreeCalculates the degree of every node, which is simply the number of nodes connected to this node. It returns a dictionary with every node label and its degree. From the result you can see, for example, that node
chas two nodes connected to it.betweenness_centralityCalculates the centrality of the node. Centrality is defined as the percentage of shortest paths in the graph that pass through that node—that is, when a message is passed from one random node to another random node, what is the chance that it will have to go through this node? Centrality is sometimes considered a measure of the importance or influence of a node, since it tells how much information must pass through it or how much the network would be disrupted if the node was removed. In this example, node
bis the most central. Nodeeis much more central than noded, even though they both have two neighbors.find_cliquesFinds all the cliques in the graph. A clique is a group of nodes that are all connected to one another, like a tight-knit group of friends in a social network. The smallest cliques have only two members, which just means two nodes are connected. The more interesting cliques are larger—in this case,
b,c, anddare all directly connected to one another (b->c,b->d, andc->d), so they form a clique.clusteringCalculates the clustering coefficient of each node. This is a bit more complicated, but it’s basically a measure of how cliquish a node is, calculated from the fraction of its neighbors that are connected to one another. In this case,
dhas a clustering coefficient of 1.0, meaning it is only connected to nodes that are also connected to each other.b, on the other hand, has a coefficient of 0.1666 because even though it’s part of theb,c,dclique, it is also connected to other nodes outside the clique.average_clusteringJust the average of the clustering coefficient of all the nodes in the graph. It’s useful as a measure of how cliquish the graph is overall. Social networks tend to be very cliquish, while computer networks are usually not very cliquish at all.
Here’s some code for creating a social graph by crawling a set of FOAF files and then running a few NetworkX analyses on it. You can download this file from http://semprog.com/psw/chapter5/socialanalysis.py:
from rdflib import Namespace
from foafcrawl import make_foaf_graph
import networkx as nx
FOAF = Namespace("http://xmlns.com/foaf/0.1/")
RDFS = Namespace("http://www.w3.org/2000/01/rdf-schema#")
if __name__=='__main__':
# Build the social network from FOAF files
rdf_graph = make_foaf_graph('http://api.hi5.com/rest/profile/foaf/241057043',
steps=5)
# Get nicknames by ID
nicknames = {}
for id, nick in rdf_graph.query('SELECT ?a ?nick '+
'WHERE { ?a foaf:nick ?nick . }',
initNs={'foaf':FOAF,'rdfs':RDFS}):
nicknames[str(id)] = str(nick)
# Build a NetworkX graph of relationships
nx_graph = nx.Graph()
for a, b in rdf_graph.query('SELECT ?a ?b '+
'WHERE { ?a foaf:knows ?b . }',
initNs={'foaf':FOAF,'rdfs':RDFS}):
nx_graph.add_edge(str(a), str(b))
# Calculate the centrality of every node
cent = nx.betweenness_centrality(nx_graph)
# Rank the most central people (the influencers)
most_connected = sorted([(score, id) for id, score in cent.items()],
reverse=True)[0:5]
print 'Most Central'
for score, id in most_connected:
print nicknames[id], score
print
# Calculate the cluster-coefficient of every node
clust = nx.clustering(nx_graph, with_labels=True)
# Rank the most cliquish people
most_clustered = sorted([(score, id) for id, score in clust.items()],
reverse=True)[0:5]
print 'Most Clustered'
for score, id in most_clustered:
print nicknames[id], score
print
for clique in nx.find_cliques(nx_graph):
if len(clique) > 2:
print [nicknames[id] for id in clique]This code builds off the make_foaf_graph
function that we defined earlier. After creating the FOAF graph, it
creates a table of nicknames (for convenience of displaying results
later) and then queries for all the relationships, which it copies to a
NetworkX graph object. It then uses some of the NetworkX functions we
just discussed to create lists of the most central people (the ones
through whom the most information must pass) and the most cliquish
people (the ones whose friends all know each other).
Here are some ideas for other things you could try:
Find the differences between people’s rankings according to degree and according to centrality. What are the patterns you noticed that cause people’s rankings to differ between these two methods?
Find and display the cliques in the social network in an interesting way.
hi5 is a mutual-friendship network; that is, if X is friends with Y, then Y is friends with X. Find an example of a social network where friendships can be one-way and use NetworkX’s
DiGraphclass to represent it.
FOAF was one of the earliest standards, and it’s published by a lot of sites, so there’s plenty of it on the Web to find, load, and analyze. Public RDF isn’t just for social networks, though—in the rest of this chapter you’ll see sources for many different types of datasets.
Linked Data
Crawling from one FOAF document to another, as we did in the previous section, is an example of using “Linked Data.” We used the RDF data provided in one graph to guide us to other graphs of data, and as we combined the data from all these graphs, we were able to build a more complete picture of the social network.
This is an example of how strong identifiers can be used to seamlessly join multiple graphs of data. The semantic web, as envisioned by the W3C, is in effect a Giant Global Graph constructed by joining many small graphs of data distributed across the Web. To showcase this type of structure, a community for Linking Open Data (LOD) has emerged, developing best practices around the publication of distributed semantic data.
While RDF provides standard ways for serializing information, the Linking Open Data community has developed standard methods for accessing serialized RDF over the Web. These methods include standard recipes for dereferencing URIs and providing data publishers with suggestions about the preparation and deployment of data on the Web.
While a community of publishers is necessary to bring the Giant Global Graph to fruition, equally important is a community of applications that utilize this collection of distributed semantic data to demonstrate the value of such a graph. This section will explore how to access pieces of the Linked Data cloud and discuss some of the issues involved in building successful Linked Data applications.
As you progress through this book, we hope that you not only find semantic applications easy to build, but also that you see the value of publishing your own data into the Giant Global Graph. And while the Linked Data architecture doesn’t currently provide any mechanisms for writing data into the global graph, we will explore Freebase as a semantic data publishing service for Linked Data at the end of this chapter.
The Cloud of Data
As we have seen, FOAF files are a vast distributed source of semantic data about people. There is no central repository of FOAF data; rather, individuals (and systems) that “know” about a specific relationship publish the data in a standardized form and make it publicly available. Some of this data is published to make other data more “findable”—the publisher hoping that by making the data publicly available it will generate more traffic to a specific website as other systems make reference to their information. Others publish information to reduce the effort of coordinating with business partners. And still others publish information to identify sources of proprietary subscription data (in hopes of enticing more systems to subscribe). While there are as many reasons for publicly revealing data as there are types of data, the result is the same: the Internet is positively awash in data.
From a data consumer’s perspective, this information is strewn haphazardly about the Web. There is no master data curator; there is no comprehensive index; there is no central coordinator. Harnessing this cloud of data and making it appear as though there were a master coordinator weaving it into a consistent database is the goal of the semantic web.
Are You Your FOAF file?
We have been using URIs to identify things in the real world, like
people and places—and that’s a good thing. But when you request the data from a URI such as http://semprog.com/ns/people/colin, you
don’t really expect to get back a serialized version of Colin. Rather,
you expect to get back something like FOAF data that describes
Colin.
This subtlety is the reason that many FOAF data generators use anonymous (blank) nodes when describing a person. The FOAF system doesn’t have a URI that represents the real person that is distinct from the information resource being produced. This is somewhat like describing something in terms of its attributes without ever naming the object—though obtuse, it does work in many cases. (“I’m thinking of a U.S. President who was impeached and was concerned about what the definition of is was.”)
Semantic web architecture makes a distinction between real-world objects, such as Colin, and the information resources that describe those objects, such as Colin’s FOAF file. To make this distinction clear, well-designed semantic web systems actually use distinct URIs for each of these items, and when you try to retrieve the real-world object’s URI, these systems will refer you to the appropriate information resource.
There are two methods for making the referral from the real-world object to the information resource: a simple HTTP redirect, and a trick leveraging URI fragment (or “hash”) identifiers. The redirect method is very general and robust, but it requires configuring your web system to issue the appropriate redirects. The second method is very simple to implement, but it’s more limited in its approach.
The HTTP redirect method simply issues an HTTP 303 “see other” result code when a real-world object’s URI is referenced. The redirect contains the location of the information resource describing the real-world object. See Figure 5-2.

The method using fragment identifiers takes advantage of the fact that when an HTTP client requests a URI with a fragment identifier, it first removes the fragment identifier from the URI, thereby constructing a separate URI that it requests from the web system. The URI requested (the URI without the fragment identifier) represents the information resource, which can be delivered by the web system.
We have said that URIs act as strong identifiers, uniquely identifying the things described in RDF statements. By “strong identifier,” we mean that you can refer to a resource consistently across any RDF statement by using the URI for the resource. No matter where in the universe a URI is used, a specific URI represents one and only one resource. And similarly, a URI represents the same resource over time. A URI today should represent the same resource tomorrow. URIs are not only strong, they should also be stable.
In Chapter 4 we pointed out that every URL is a URI, but how many times have you gone to a URL that used to produce useful information, only to discover that it now produces an HTTP 404 result? If URIs represent strong, stable identifiers, then the information resources produced by dereferencing a URI should also remain stable (or rather, available).
Serving information resources using URIs with fragment identifiers is an easy solution when your RDF is in files. But because URIs should be stable, you must not be tempted to “reorganize” your RDF files should your data expand, as moving resource descriptions between files would change their URIs. It is important to remember that RDF is not document-centric, it is resource-centric, and URIs are identifiers, not addresses. See Figure 5-3.

When working with Linked Data, remember that not all URIs can be dereferenced. Although it is unfortunate that we can’t learn more about those resources, they still represent useful identifiers. Also, not all URIs representing real-world objects are handled by well-behaved web systems. You will find many examples of RDF information resources being served directly when requesting a real-world object.
So for now, you are not your FOAF file. But perhaps when transporter technology is perfected and humans are assigned a mime type, we will provide an addendum to this book with information on the best practices for retrieving humans through dereferenceable URIs.
Consuming Linked Data
Let’s exercise much of what you have learned while walking across a few sources of Linked Data. In this example, we will query multiple data sources, obtaining a critical piece of information from each that will allow us to query the next source. As we query each data source, the information we obtain will be stored in a small internal graph. After we reach the final data source, we will be able to query our internal graph and learn things that none of the sites could tell us on their own.
If this sounds like the “feed-forward inference” pattern we used in Chapter 3, that’s no accident. Our rules in this case know how to use identifiers from one data source to obtain data from another data source. Part of what we obtain from each data source is a set of identifiers that can be used with another data source. This type of pattern is very common when working with semantic data, and we will revisit it again and again.
In this section we are going to build a simple Linked Data application that will find musical albums by artists from countries other than the U.S. Our application will take the name of a country as input and will produce a list of artists along with a sample of their discography and reviews of their albums. To find the information required to complete this task, the application will contact three separate data sources, using each to get closer to a more complete answer.
The British Broadcasting Company (BBC) has a wealth of information about music in its archives, including a large collection of record reviews that are not available anywhere else on the Web. Fortunately, the BBC has begun publishing this information as RDF. While the BBC data provides useful information about the significant albums an artist has produced, it provides very little general context data about the artist. In addition, the BBC does not provide a query interface, making it impossible to isolate record reviews of bands that reside in a particular country. But because the BBC’s data uses strong identifiers, we can use other Linked Data to find the information we want.
The BBC data uses identifiers provided by the MusicBrainz music metadata project. The MusicBrainz project is a well-regarded community effort to collect information about musical artists, the bands they play in, the albums they produce, and the tracks on each album. Because MusicBrainz is both a well-curated data collection and a technology-savvy community, its identifiers are used within many datasets containing information about musical performances.
MusicBrainz itself does not provide Linked Data dereferenceable URIs, but Freebase—a community-driven, semantic database that we will look at later—uses MusicBrainz identifiers and provides dereferenceable URIs. Freebase also connects the MusicBrainz identifiers to a number of other strong identifiers used by other data collections.
DBpedia, an early Linked Data repository, is an RDF-enabled copy of
Wikipedia. Freebase and DBpedia are linked by virtue of the fact that
both systems include Wikipedia identifiers (so they are able to generate
owl:sameAs links to one another). DBpedia also
provides a SPARQL interface, which allows us to ask questions about
which Wikipedia articles discuss bands that reside in a specific
country. From the results of this query, we will follow the Linked Data
from one system to the next until we get to the BBC, where we will
attempt to find record reviews for each of the bands. See Figure 5-4.
You can build this application as we work through the code. Alternatively, you can download it, along with other demonstrations of consuming Linked Data, from http://semprog.com/psw/chapter5/lod.
Let’s start by defining the namespaces that we’ll be using throughout the application and constructing a dictionary of the namespace prefixes to use across our queries. We will also create a few simple utility functions for submitting requests via HTTP to external services.
Caution
Caveat dereferencer! This Linked Data application depends on the availability of three independent web services. Over time the functionality, or even existence, of these services may change. If you run into problems with this or any other Linked Data application, try sending a few requests manually to each service using wget or curl to see if the service is working as you expect.

"""
Example of using Linked Data
1) from DBpedia: get bands from a specific country
2) from Freebase: get Musicbrainz identifiers for those bands
3) from the BBC: get album reviews for those bands
"""
import urllib2
from urllib import quote
from StringIO import StringIO
from rdflib import Namespace, Graph, URIRef
countryname = "Ireland" #also try it with "Australia"
dbpedia_sparql_endpoint =
"http://dbpedia.org/sparql?default-graph-uri=http%3A//dbpedia.org&query="
#namespaces we will use
owl = Namespace("http://www.w3.org/2002/07/owl#")
fb = Namespace("http://rdf.freebase.com/ns/")
foaf = Namespace("http://xmlns.com/foaf/0.1/")
rev = Namespace("http://purl.org/stuff/rev#")
dc = Namespace("http://purl.org/dc/elements/1.1/")
rdfs = Namespace("http://www.w3.org/2000/01/rdf-schema#")
nsdict = {'owl':owl, 'fb':fb, 'foaf':foaf, 'rev':rev, 'dc':dc, 'rdfs':rdfs}
#utilities to fetch URLs
def _geturl(url):
try:
reqObj = urllib2.Request(url)
urlObj = urllib2.urlopen(reqObj)
response = urlObj.read()
urlObj.close()
except:
#for now: ignore exceptions, 404s, etc.
print "NO DATA"
response = ""
return response
def sparql(url, query):
return _geturl(url + quote(query))
def fetchRDF(url, g):
try: g = g.parse(url)
except: print "fetch exception"Next we will start defining functions that operate on specific data sources. Each function will take a reference to our internal graph as an argument, then determine if there is something new it can add to the data by contacting an external source. If so, it contacts the external source and adds the data to the internal triplestore. If our functions are well-written, they should only contact the external source when they detect that there is information missing in the local graph and they know that the external source will supply it. Much like the multi-agent blackboard described in Chapter 3, we should be able to call the functions repeatedly and in any order, allowing them to opportunistically fill in information when they are called.
To start the process, we will define a function that queries DBpedia with our one input parameter, the name of a country. DBpedia will provide a list of rock bands originating from that country and supply us with their Freebase identifiers:
def getBands4Location(g):
"""query DBpedia to get a list of rock bands from a location"""
dbpedia_query = """
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX dbpp: <http://dbpedia.org/property/>
PREFIX dbpo:<http://dbpedia.org/ontology/>
PREFIX dbpr:<http://dbpedia.org/resource/>
CONSTRUCT {
?band owl:sameAs ?link .
} WHERE {
?loc dbpp:commonName '""" + countryname + """'@en .
?band dbpo:homeTown ?loc .
?band rdf:type dbpo:MusicalArtist .
?band dbpo:genre dbpr:Rock_music .
?band owl:sameAs ?link .
FILTER regex(?link, "freebase")
}"""
print "Fetching DBpedia SPARQL results (this may take a few seconds)"
dbpedia_data = sparql(dbpedia_sparql_endpoint, dbpedia_query)
g.parse(StringIO(dbpedia_data),format='xml') #put results in local triplestore
print "done with dbpedia query"Next we will define a function that looks for bands that have a Freebase identifier but do not have information about the band’s name filled in. For each band in this state, the function will contact Freebase and add what it learns to our internal graph:
def getMBZIDs(g):
"""Query the local triplestore to find the Freebase links for each band
and load the Freebase data for the band into the local triplestore"""
#Freebase provides the canonical name for each band,
#so if the name is missing, we know that we haven't asked Freebase about it
fbquery = """
SELECT ?fblink WHERE{
?band owl:sameAs ?fblink .
OPTIONAL { ?fblink fb:type.object.name ?name . }
FILTER regex(?fblink, "freebase", "i")
FILTER (!bound(?name))
}"""
freebaserefs = [fref[0] for fref in g.query(fbquery, initNs=nsdict)]
print "Fetching " + str(len(freebaserefs)) + " items from Freebase"
for fbref in freebaserefs:
fetchRDF(str(fbref), g)
Our next functions will look for bands that have a BBC identifier but for which we have no review information. The first function retrieves artist information from the BBC to obtain information about the albums the artist has made. The second function looks for albums that don’t have review information and retrieves the text of the review from the BBC archive:
def getBBCArtistData(g):
"""For each MusicBrainz ID in the local graph try to retrieve a review from
the BBC"""
#BBC will provide the album review data,
#so if its missing we haven't retrieved BBC Artist data
bbcartist_query = """
SELECT ?bbcuri
WHERE {
?band owl:sameAs ?bbcuri .
OPTIONAL{
?band foaf:made ?a .
?a dc:title ?album .
?a rev:hasReview ?reviewuri .
}
FILTER regex(?bbcuri, "bbc", "i")
FILTER (!bound(?album))
}"""
result = g.query(bbcartist_query, initNs=nsdict)
print "Fetching " + str(len(result)) + " artists from the BBC"
for bbcartist in result:
fetchRDF(str(bbcartist[0]), g)
def getBBCReviewData(g):
#BBC review provides the review text
#if its missing we haven't retrieved the BBC review
album_query = """
SELECT ?artist ?title ?rev
WHERE {
?artist foaf:made ?a .
?a dc:title ?title .
?a rev:hasReview ?rev .
}"""
bbc_album_results = g.query(album_query, initNs=nsdict)
print "Fetching " + str(len(bbc_album_results)) + " reviews from the BBC"
#get the BBC review of the album
for result in bbc_album_results:
fetchRDF(result[2], g)Finally, we will sequence the use of our “rules” in the body of our application. We start by populating a local graph with the results of our DBpedia SPARQL query that identifies bands from the country of our choosing. Next we call each of our rule functions to fill in missing data.
While we call the functions in an obvious sequence, you could rework this section to loop over the calls to each data acquisition function, emitting completed review data as it is obtained. In theory, should a data source become unavailable, the application would just keep iterating through the rules until the data became available, allowing the review to be retrieved. Similarly, you should be able to modify the body of this application so that you can “inject” new countries into the application and have the application kick out additional reviews as new input becomes available:
if __name__ == "__main__":
g = Graph()
print "Number of Statements in Graph: " + str(len(g))
getBands4Location(g)
print "Number of Statements in Graph: " + str(len(g))
getMBZIDs(g)
print "Number of Statements in Graph: " + str(len(g))
getBBCArtistData(g)
print "Number of Statements in Graph: " + str(len(g))
getBBCReviewData(g)
print "Number of Statements in Graph: " + str(len(g))
final_query = """
SELECT ?name ?album ?reviewtext
WHERE {
?fbband fb:type.object.name ?name .
?fbband owl:sameAs ?bband .
?bband foaf:made ?bn0 .
?bn0 dc:title ?album .
?bn0 rev:hasReview ?rev .
?rev rev:text ?reviewtext .
FILTER ( lang(?name) = "en" )
}"""
finalresult = g.query(final_query, initNs=nsdict)
for res in finalresult:
print "ARTIST: " + res[0] + " ALBUM: " + res[1]
print "------------------------------"
print res[2]
print "=============================="
This application makes use of Freebase as a semantic switchboard, exchanging one identifier for another. Freebase can also provide a map of data resources that use specific types of identifiers, and it can itself be a source of information about a wide variety of subjects. In the next section we will look at Freebase in greater depth and examine some of the services it provides to make writing semantic applications a bit easier.
Freebase
Freebase is an open, writable, semantic database with information on millions of topics ranging from genes to jeans. Within Freebase, you can find data from international and government agencies, private foundations, university research groups, open source data projects, private companies, and individual users—in short, anyone who has made their data freely available. And as the name suggests, Freebase doesn’t cost anything to use. All the data in it is under a Creative Commons Attribution (CC-BY) license, meaning it can be used for any purpose as long as you give credit to Freebase.
Like the structures we have been examining, Freebase is a graph of data, made up of nodes and links. But unlike the RDF graphs we have looked at so far, Freebase envelops this raw graph structure with a query system that allows developers to treat these structures as simple objects that are associated with one or more Freebase types. A type, in Freebase, is a collection of properties that may be applied to the object, linking it to other objects or literal values.
An Identity Database
Freebase has information on millions of entities (or “topics”), and the data is actively curated by the community of users (and a wide variety of algorithmic bots) to ensure that each entity is unique. That is, each Freebase topic represents one, and only one, semantically distinct “thing.” Said another way, everything within Freebase has been reconciled (or smushed!). In theory, you should never find duplicated topics, and when they do occur, the community merges the data contained in the two topics back into one. This active curation is a part of what makes Freebase useful as an identity database. When you dereference a Freebase identifier, you will get back one and only one object. All information for the topic, including all other identifiers, are immediately available from that one call.
As a semantic database, strong identifiers play a central role within Freebase.
Every topic has any number of strong, stable identifiers that can be
used to address it. These identifiers are bestowed on topics by Freebase
users and by external, authoritative sources alike. Topic identifiers
are created by establishing links from a topic to special objects in
Freebase called namespaces. The links between topics and namespaces also
contain a key value. The ID for a topic is computed by concatenating the
ID of a parent namespace, a slash
(/), and the value of the key link connecting the
topic to the namespace. For
instance, the band U2 is represented by the topic with the key value of
a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432 in the namespace
with the ID /authority/musicbrainz. The ID for the U2
topic can thus be represented as /authority/musicbrainz/a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432.
The MusicBrainz namespace ID can similarly be understood as having a key
with the value musicbrainz in
the namespace with the ID /authority, and so on back
to the root namespace.
As we will see, Freebase IDs are useful within the Freebase system and also serve as externally dereferenceable URIs. This means that not only can you refer to any Freebase topic in your own RDF, but any data you add to Freebase can be referenced by others through RDF.
RDF Interface
As we saw earlier in the Linked Data section, Freebase provides an RDF Linked Data interface, making Freebase a part of the Giant Global Graph. As a community-writable database, this means that any data (or data model) within Freebase is immediately available as Linked Data, and thus you can use Freebase to publish semantic data for use in your own Linked Data applications.
You can construct a dereferenceable URI representing any object in Freebase by
taking an ID for the object, removing the first slash
(/), replacing the subsequent slashes with dots
(.), and appending this transformed ID on the base
URI http://rdf.freebase.com/ns/. For instance, the
actor Harrison Ford (the one who appeared in Star
Wars) has the Freebase ID
/en/harrison_ford. You can find out what Freebase
knows about him by dereferencing the URI
http://rdf.freebase.com/ns/en.harrison_ford.
These URIs represent the things Freebase has information about, so
the URI http://rdf.freebase.com/ns/en.harrison_ford
represents Harrison Ford the actor. Since Freebase can’t produce
Harrison Ford the actor, but it can provide information about him, this
URI will be redirected with an HTTP 303 response to the URI for the
information resource about him. If your request includes an HTTP ACCEPT
header indicating a preference for
application/rdf+xml content, you will be redirected
to the information resource at
http://rdf.freebase.com/rdf/en/harrison_ford. (You
can also request N-triples, N3,
and turtle with the appropriate ACCEPT headers.) If you make the request with an ACCEPT header (or
preference) for text/html, you will be redirected to
the standard HTML view within Freebase.com.
Freebase Schema
Not only does Freebase allow users to add data to the graph, it also allows them to extend the data model to fit their data. Data models within Freebase are called schemas and are broken down along areas of interest called domains. Domains serve only to collect components of a data model; they have no specific semantic value.
In Freebase, any object can have one or more types. Types provide a basic categorization of objects within Freebase and indicate what properties you might expect to find linked to the object. Since Freebase properties specify the link between two objects, they serve the same role as RDF predicates (in fact, the Freebase RDF interface uses properties as predicates). Unlike an object-oriented programming language, or some of the RDF models we will examine in later chapters, Freebase types do not have inheritance. If you want to say that something is also a more abstract type, you must explicitly add the type to the object.
For instance, in Freebase, Harrison Ford is of type
actor, which resides in the film
domain (/film/actor), and he is also typed as a
person, which resides in the
people domain (/people/person).
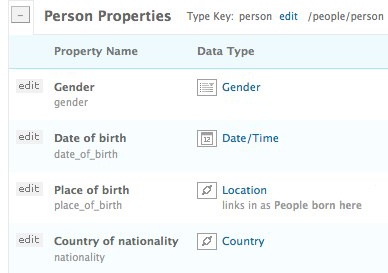
The person type has properties such as
date_of_birth, nationality, and
gender. As in RDF, these properties represent links
connected to the object representing Harrison Ford. Properties such as
date_of_birth represent literals, whereas properties
for things like nationality and
gender represent links to other objects. Properties
in Freebase not only indicate whether they are links to literals or
other objects, but they also specify the type of object at the other end
of the link. Therefore, you know that when you reference the
gender property on the person
schema, you will find an object with the gender type
on the other end of the link. See Figure 5-5.
Similarly, the actor type has a
film property. It too is a link to another object,
but rather than linking directly to a film object, it
connects to a performance object that is itself
connected to a film. This performance object serves
the same purpose as a blank node in RDF, allowing us to express
information about the relationship between two entities—in this case, allowing us to
identify the character the actor played in the film. Unlike an RDF
model, however, these “mediating” nodes are first-class objects in
Freebase and therefore have strong, externally referenceable
identifiers. See Figure 5-6.

As you might have guessed from our examples, the ID of a type in
Freebase is the domain that the type is contained in, followed by a key
for that type. That is, a domain (such as people) is
also a namespace, and types have keys (e.g., person)
in domains (giving the people type the ID
/people/person). Similarly, types operate as
namespaces for properties, so the full ID for the birthday property is
/people/person/date_of_birth.
Every object in Freebase is automatically given the type
object (/type/object), which
provides properties available to all objects, such as
name, id, and
type. The type property
(/type/object/type) is used to link the object with
type definitions. For instance, Harrison Ford is an object of type
actor, by virtue of having a
/type/object/type link to the
/film/actor object. In a self-similar fashion, types
themselves are nothing more than objects that have a
/type/object/type link to the root type object
/type/type. See Figure 5-7.

Since the RDF interface can provide information about any object
in Freebase, you can ask for an RDF description of each type used by the
/en/harrison_ford object. The type description will
include information about the properties used by the type, and you can
continue the investigation by asking the interface for the definition of
specific properties in RDF.
For example, we can ask about the /film/actor
type using the wget command-line tool:
wget -q -O - --header="ACCEPT:text/plain" http://rdf.freebase.com/ns/film.actor
This returns a triple that tells us that
/film/actor has a property called
film (/film/actor/film):
<http://rdf.freebase.com/ns/film.actor>
<http://rdf.freebase.com/ns/type.type.properties>
<http://rdf.freebase.com/ns/film.actor.film>.We can then ask for the definition of the film
property with:
wget -q -O - --header="ACCEPT:text/plain" http://rdf.freebase.com/ns/film.actor.film
MQL Interface
Freebase uses a unique query language called MQL (pronounced like nickel, but with an M). Unlike SPARQL’s graph pattern approach, MQL uses tree-shaped query-by-example structures to express queries. With MQL, you indicate the node and link arrangement you are searching for, filling in constraints along the structure and leaving blank slots where you want results returned. The query engine then searches the graph and returns a list of all structures that match the shape of the query and the embedded constraints. The query engine will also complete the structure, filling in any blank slots with information from the graph for each match it finds.
MQL query structures are expressed using JavaScript Object Notation (JSON), making them very easy to construct and parse in Python. JSON array structures are used where a result component may have multiple values, and JSON objects are used to select named properties. For instance, to discover Harrison Ford’s birthday, you would write:
{"id":"/en/harrison_ford, "/people/person/date_of_birth":null}MQL allows you to use the property key to shorten the expression if the type of the object is explicitly declared as a constraint in the query. Thus, the query just shown can also be expressed as:
{"id":"/en/harrison_ford", "type":"/people/person", "date_of_birth":null}Similarly, since the type of object at the other end of a property
link is known via the schema, when specifying properties of objects
returned by properties “higher up” in the query tree, you can use their
shortened IDs. For instance, if we ask for the film
property on Harrison Ford, when treated as a
/film/actor, we would retrieve all his /film/performance objects. Since these
performance objects themselves aren’t that
interesting, we will want to obtain the film property
for each of these performance objects. Because the
query processor knows the type of each of these objects, we can ask for
them using just the property key:
{
"id":"/en/harrison_ford",
"type":"/film/actor",
"film":[{ "film":[] }]
}When a constraint is left empty in a query, in most cases Freebase will fill the slot with the name of the object or the value of the literal that fills the slot. One exception to this is when an empty constraint would be filled by an object used by the type system; in these cases, the ID of the object is returned.
We can, however, tell Freebase exactly what we want to see from
each object returned by using curly braces ({}) to expand the object
and call out specific properties in the dictionary. Thus, to get the
names of the movies Harrison Ford has acted in and the directors of
those movies, we can write:
{
"id":"/en/harrison_ford",
"type":"/film/actor",
"film":[{ "film":[{"name":null, "directed_by":[] }] }]
}And we can expand the director object further,
constraining our query to find only female directors who have worked
with Harrison Ford (note that we must use the full property ID for the
gender constraint since the
directed_by property returns a
/film/director object):
[{
"id":"/en/harrison_ford",
"type":"/film/actor",
"film":[{ "film":[{"name":null,
"directed_by":[{"name":null, "/people/person/gender":"Female"}] }] }]
}]MQL has many additional operators that allow you to further constrain queries, but this quick introduction should give you enough background on the Freebase data model to start making queries on your own.
Using the metaweb.py Library
Calls are made to the Freebase services using HTTP GET requests (or optionally POST for some services when the payload is large). But rather than learning the various parameters for each call, it is easier to grab a copy of the metaweb.py library that handles the HTTP requests for you.
The metaweb.py library covered in this section is available from http://www.freebase.com/view/en/appendix_b_metaweb_py_module and makes use of the simplejson library for encoding and decoding JSON structures. You can download the simplejson library from http://code.google.com/p/simplejson.
Tip
Enhanced versions of metaweb.py are posted on Google Code; they provide additional features and access to lower-level APIs should you need them in the future.
Place a copy of metaweb.py in your working directory and start an interactive Python session. Let’s start by making the Harrison Ford query that lists all his movies:
>> import metaweb
>> null = None
>> freebase = metaweb.Session("api.freebase.com") #initialize the connection
>> q = {"id":"/en/harrison_ford", "type":"/film/actor", "film":[{ "film":null }] }
>> output = freebase.read(q)
>> print str(output)
{u'type': u'/film/actor', u'id': u'/en/harrison_ford', u'film': [{u'film':
[u'Air Force One']},
{u'film': [u'Apocalypse Now']}, {u'film': [u'Blade Runner']}, {u'film':
[u'Clear and Present Danger']},
{u'film': [u'Firewall']}, {u'film': [u'Frantic']}, {u'film':
[u'Hollywood Homicide']},...Of course, we can iterate over pieces of the result structure to make the output a bit more clear:
>> for performance in output['film']: print performance['film'] Air Force One Apocalypse Now Blade Runner Clear and Present Danger Firewall Frantic Hollywood Homicide ....
By default, Freebase will return the first 100 results of a query,
but MQL provides a cursor mechanism that lets us loop through pages of
results. The metaweb.py library provides a
results method on the session
object, which returns a Python iterator that makes cursor operations
transparent.
This time, let’s look at all films in Freebase that list a female director (notice that the query is surrounded by square brackets, indicating that we believe we should get back multiple results):
>> q2 = [{"name":null, "type":"/film/film",
"directed_by":[{ "/people/person/gender":"Female" }] }]
>> gen = freebase.results(q2)
>> for r in gen:
... print r["name"]
15, Park Avenue
3 Chains o' Gold
30 Second Bunny Theater
36 Chowringee Lane
A League of Their Own
A New Leaf
A Perfect Day
Une vraie jeune fille
....In addition to packaging access to the query interface,
metaweb.py provides a number of other methods for
accessing other Freebase services. For instance, if you query for
properties that produce objects of type
/common/content, you can fetch the raw content (text,
images) using the blurb and thumbnail methods. Try looking at the
documentation in the source for the search method and see whether you
can find topics about your favorite subject.
Interacting with Humans
Unlike machines, humans do well with ambiguous names, which can
make it challenging when soliciting input from humans for semantic
applications. If you provide a simple input box asking United States
residents to enter the country of their residence, you will obtain input
ranging from simple acronyms like “US” to phrases like “The United
States of America”, all of which ostensibly identify the country
<http://rdf.freebase.com/ns/en.united_states>.
The problem is compounded when users enter semantically ambiguous data. For
example, it’s likely that users who “idolize” Madonna form more than one
demographic.
One obvious solution is to create an enumeration of “acceptable” responses that are equated with strong identifiers. Although this will work, unless you generate an extremely large list of options, you will substantially limit your users’ expressive power. With over 14.1 million unique, named entities, Freebase provides a sufficiently diverse yet controlled lexicon of things users might want to talk about—and each comes with a strong identifier.
To facilitate the use of Freebase for human input, the “autocomplete” widget used within the Freebase site has been made available as an open source project. With about 10 lines of JavaScript, you can solicit strong identifiers in a user-friendly way. To see how easy it is, let’s build a very simple web page that will generate the RDF URI for a Freebase topic. Open your favorite plain-text editor and create the following page:
<head>
<script type="text/javascript"
src="http://ajax.googleapis.com/ajax/libs/jquery/1.3/jquery.min.js">
</script>
<script type="text/javascript"
src="http://controls.freebaseapps.com/suggest"></script>
<link rel="stylesheet" type="text/css"
href="http://controls.freebaseapps.com/css" />
<script>
function getRDF(){
var freebaseid = document.getElementById("freebaseid").value;
var rdfid = freebaseid.substr(1).replace(///g,'.'),
var rdfuri = "http://rdf.freebase.com/ns/" + rdfid;
document.getElementById("rdfuri").innerHTML = rdfuri;
}
</script>
</head>
<body>
<form>
URIref for: <input type="text" id="topicselect" />
<input type="hidden" name="freebaseid" id="freebaseid">
<input type="button" onclick='getRDF()' value="Fetch Data">
</form><p>
RDF URI: <span id="rdfuri"></span><p>
<script type="text/javascript">
$(document).ready(function() {
$('#topicselect').freebaseSuggest({})
.bind("fb-select", function(e, data)
{$('#freebaseid').val(data.id); getRDF();});
});
</script>
</body>Open the page in your web browser and start typing the word
“Minnesota” into the text box. Freebase Suggest will bring up a list of topics related to
the stem of the word as you are typing. Once you have the selected the
topic of interest, jQuery fires the function bound to
fb-select. In this case, the Freebase ID
(data.id) of the topic selected is placed in the
hidden text input box ($('#freebaseid')). When you
click the “Fetch Data” button, a simple JavaScript function reformats
the Freebase ID into the Freebase RDF ID and provides a link to the
Freebase Linked Data interface.
The Freebase Suggest code provides a number of simple hooks that allow you to customize not only the appearance of the widget, but also how it behaves. For instance, you can provide custom filters to limit the topics presented and custom transformations to display different pieces of information specific to your task.
We have barely scratched the surface of Freebase in this book; Freebase provides various other services to facilitate application development, and it provides a complete JavaScript development environment for building customized APIs and small applications. You can learn more about these and other Freebase services at http://www.freebase.com.
Throughout this chapter we’ve introduced new vocabularies, such as FOAF and Freebase Film. We’ve provided a page of vocabularies at http://semprog.com/docs/vocabularies.html, which we’ll keep updated with the ones we think are useful and interesting. In the next chapter, we’ll look at how to go about creating an ontology, which is a formal way of defining a semantic data model.