
Chapter 7. Publishing Semantic Data
Publishing semantic data often results in a “network effect” because of the connections that occur between datasets. For example, publishing restaurant data can suddenly open up a new application for a connected geographic dataset. Campaign finance data is made more accessible by its connections to politicians and their voting records. As more semantic data is published, existing semantic data becomes more useful, which in turn increases the scope and usefulness of the applications that can be built.
The main barrier to publishing semantic data has been that many of the standards are complicated and confusing, and there has been a lack of good tools. Fortunately, there have been several efforts to create simpler semantic web standards that make it easier for both designers and developers to publish their data. Another promising trend is that thousands of web applications now have open APIs and are publishing machine-readable data with implicit semantics that can easily be translated to the explicit semantics that we’ve been covering. All of this has led to early efforts by some very large web properties to consume semantic data and use it to enhance their applications.
In this chapter we’ll look at two emerging standards, Microformats and RDFa, that aim to make publishing semantic data far easier for web designers by simply extending the already familiar HTML syntax. We’ll also look at ways to take data that you might already have access to—either through existing online APIs or in spreadsheets and relational databases—put that data into an RDF store, and publish it using the same Linked Open Data techniques you saw in Chapter 5. After reading this chapter, we hope that you’ll be both prepared and inspired to publish explicit semantics more often in your future work, making the sharing and remixing of data easier for everyone.
Embedding Semantics
One of the major criticisms of semantic web formats like RDF/XML is that they are too complicated and too much of a hassle for a designer or webmaster to bother implementing. Furthermore, a huge amount of information is already available on HTML pages, and duplicating it in a different format is both a significant upfront investment and an ongoing maintenance hassle.
Microformats and RDFa work to address these issues by allowing users to embed semantic tags in existing web pages. By making a few small changes to a web page, the semantics of the hyperlinks and information on the page become explicit, and web crawlers can more accurately extract meaning from the page. We’ll look at both of these standards here and consider their strengths and drawbacks.
Microformats
Microformats are intended to be a very simple way for web
developers to add semantic data to their pages by using the familiar
HTML class attribute. The website http://microformats.org defines a
variety of microformats, both stable and under development. To
understand how they work, take a look at this simple example of an
hCard, a business-card-like microformat for giving information
about a person or organization that can be embedded in HTML:
<div class="vcard"> <div class="fn">Toby Segaran</div> <div class="org">The Semantic Programmers</div> <div class="tel">919-555-1234</div> <a class="url" href="http://kiwitobes.com/">http://kiwitobes.com/</a> </div>
The first div uses the class
attribute to tell us that it contains a vcard. The
hCard specification (which you can find at http://microformats.org) defines
several fields, including:
The HTML elements within the vcard
div have classes matching these properties. The
values for the properties are the text inside the tags, so the hCard
shown earlier is describing a person whose full name is “Toby Segaran”
and who works for “The Semantic Programmers”. By taking an existing HTML
web page and adding microformat annotations, you make the page more
interpretable by a machine. For instance, a web crawler could use
microformats found on a website to build a database of people and their
phone numbers, employers, and web pages.
The earlier hCard example is just a list of fields that would appear on a web page as a small table or box, but most of the interesting information on web pages is contained within natural language text. In many cases a fragment of text makes reference to a single thing such as a place, a person, or an event, and microformats can be used to add semantics to these references. Here is an example of using the “hCalendar event” microformat to add semantics to a sentence:
<p class="vevent">
The <span class="summary">English Wikipedia was launched</span>
on 15 January 2001 with a party from
<abbr class="dtstart" title="2001-01-15T14:00:00+06:00">2</abbr>-
<abbr class="dtend" title="2001-01-15T16:00:00+06:00">4</abbr>pm at
<span class="location">Jimmy Wales' house</span>
(<a class="url" href=
"http://en.wikipedia.org/wiki/History_of_Wikipedia">more information</a>)
</p>This example shows the use of the summary,
dtstart, dtend,
location, and url properties from
the vEvent microformat, which are added to an existing sentence to
capture some of the semantics of what the sentence says. It also
illustrates the case where the information we want to show differs from
the information we want to capture. Notice how the displayed start time
within the dtstart is simply 2.
This is sufficient for display but not sufficient for a parser, so it is
overridden by the title attribute, which gives the
complete time in ISO 8601 date format.
Again, by using this microformat you can add semantic data to a page and make it possible for crawlers to create more interesting applications. In this case, historical data about past events could be republished as a timeline or made searchable by the timeframe of the events described.
Here’s one more example of a microformat that you should probably be using on your own website! It’s the hResume microformat, which allows you to describe your work and educational experience. It is particularly interesting because it nests the hCalendar and hCard microformats inside it, showing how microformats can build on each other:
<div class="hresume">
...
<li class="experience vevent vcard">
<object data="#name" class="include"></object>
<h4 class="org summary">
<a href="http://www.metaweb.com" >
Metaweb Technologies
</a>
</h4>
<p class="organization-details">1000-5000 employees</p>
<p class="period">
<abbr class="dtstart" title="2003-06-01">January 2008</abbr>
—<abbr class="dtend" title="2005-08-01">December 2009</abbr>
<abbr class="duration" title="P2Y3M">(1 year 11 months)</abbr>
</p>
<p class="description">
Designed and implemented large-scale data-reconciliation techniques.
</p>
</li>
...
</div>This example shows one experience line item extracted from a
larger hResume div. Notice how the
li tag has a class attribute with
experience (from hResume), vEvent
(from the hCalendar microformat), and vCard (from the
hCard microformat). Besides the fact that there are fewer class names to
remember, mixing formats like this means that a crawler that isn’t aware
of the hResume format could still determine that there was an
organization called “Metaweb” and know its URL if it understood the
hCard microformat.
LinkedIn, the largest professionally focused social network, embeds the hResume microformat in its public profile pages.
RDFa
We described RDFa in Chapter 4 when we covered RDF serializations, but RDFa is really a mechanism for publishing semantic data within standard web pages. Like microformats, it works by adding attributes to tags that define fields. However, it also allows anyone to define a namespace in the same way that RDF/XML does. Because of this, publishers aren’t restricted to officially sanctioned vocabularies, and they can define their own if nothing appropriate already exists.
The attributes used for RDFa are different from those used for microformats, but they serve similar functions. Here (again) are some of the more important attributes defined by RDFa:
aboutA URI (or safe CURIE) used as a subject in an RDF triple. By default, the base URI for the page is the root URI for all statements. Using an
aboutattribute allows statements to be made where the base URI isn’t the subject.relrevCURIEs expressing reverse relationships between two resources.
propertyCURIEs expressing relationships between a resource and a literal.
srcA URI resource expressing an RDF object (as an inline embedded item).
contenthrefA URI resource expressing an RDF object (as inline clickable).
resourceA URI (or safe CURIE) expressing an RDF object when the object isn’t visible on the page.
datatypetypeof
The namespace being used is specified in the same way as in RDF/XML, XHTML, or any XML-based format, by using xmlns attributes. CURIEs are a superset of XML QNames, so in the examples that follow we will simply use QName constructions where CURIEs are required.
Here’s a simple example of using the familiar FOAF namespace to embed some semantic information into HTML:
<body xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:foaf="http://xmlns.com/foaf/0.1/">
<h1>Toby's Home Page</h1>
<p>My name is
<span property="foaf:firstname">Toby</span> and my
<span rel="foaf:interest" resource="urn:ISBN:0752820907">favorite
book</span> is the inspiring <span about="urn:ISBN:0752820907"><cite
property="dc:title">Weaving the Web</cite> by
<span property="dc:creator">Tim Berners-Lee</span></span>
</p>
</body>A sentence about Toby has been marked up with semantics specifying that he’s a person with the first name “Toby” and that he likes a book called “Weaving the Web”, which has the creator “Tim Berners-Lee”.
The body tag contains two XML namespaces—FOAF, specified by the
xmlns:foaf attribute, and the Dublin Core namespace,
specified by xmlns:dc, the same way these were
declared in Chapter 5. The
property attribute uses the defined namespace to
indicate what the contents of a
tag mean, and the resource attribute is used to
specify a unique identifier for the tag. Thus, we know exactly which
“Toby” it is and which book we’re referring to.
Here is a simpler example that uses the beer
namespace, which you can find at http://www.purl.org/net/ontology/beer:
<div xmlns:beer="http://www.purl.org/net/ontology/beer#">
<div about="#Guiness" typeof="beer:Stout">
<span property="beer:hasAlcoholicContent">7.5</span>% Alcohol
</div>
</div>RDFa is relatively easy to add to existing web pages, whether they’re dynamic or static. At the time of this writing, there are more large services publishing microformats than RDFa, which is a newer standard. However, services that consume embedded semantics (which we’ll get to in a moment) are striving for compatibility with both. If you want to use semantics that aren’t supported by an existing microformat, you’ll have to use RDFa. Since it’s best if everyone is using the same schemas, check out http://www.schemaweb.info/ to see if someone has already created a schema for your application.
Yahoo! SearchMonkey
Services that consume embedded semantic data are already starting to appear. One of the earliest examples is SearchMonkey, an effort by Yahoo! to integrate structured and semantic data into Yahoo!’s search results. At the time of this writing, it’s still very much under development, but we believe that it gives a first hint of what’s possible when publishers provide even a small amount of structured data along with their human-readable pages.
There are two parts to SearchMonkey. As the Yahoo! web crawler indexes websites, SearchMonkey extracts structured data from the pages. Then, the SearchMonkey APIs allow developers to create SearchMonkey applications that format structured data into richer, more useful search results. A few of these applications are already part of Yahoo!’s main search results—Figure 7-1 shows an example of a result I get when I search for “dosa mission san francisco” in Yahoo! search.

For structured data, SearchMonkey currently supports several standards and approaches, including RDFa, microformats, an Atom-based update feed, and the OpenSearch API. All of these methods deliver structured metadata about web pages on your website when it is being indexed by Yahoo!. Without this structured data, Yahoo!’s crawling and indexing process has to analyze the text and links on your web pages to try to discern what your website is about and whether it is a useful result to someone’s search query. By using a data schema and adding structure to the pages on your site, you’re making it easier for Yahoo! to understand your content, and Yahoo! can then do a better job of displaying your website as a search result.
Creating a Yahoo! SearchMonkey application generally involves a small amount of PHP, which is hosted by Yahoo!. We won’t go into the details here, but you can learn more at http://developer.yahoo.com/searchmonkey/. Figure 7-2 shows a few examples of applications that developers have already created and placed in the Yahoo! Search Gallery, which users can add to enrich their search results.

Google’s Rich Snippets
Google has also started indexing semantic data expressed as RDFa. Like SearchMonkey, Google’s initial use of RDFa metadata is to locate information on the page that can be used to enrich search results. To guide content developers, Google has published a small vocabulary covering frequently searched subjects such as people, organizations, products, and reviews.
When a content creator embeds RDFa that uses the http://rdf.data-vocabulary.org/rdf.xml vocabulary on a page, Google’s search system will use the RDFa to locate specific pieces of content to display in query results. For instance, by identifying where on the page the product review rating is located, along with markup indicating the price and the person writing the review, CNET’s product reviews deliver summary information to users much faster than similar, nonsemantically enabled results returned by the same query. See Figure 7-3.

Dealing with Legacy Data
While it’s great that data is increasingly available on the Web in standard formats, it’s also true that the vast majority of data that most people have access to—both on the Web and in their private data store—is not. In this section we’ll look at a few examples covering open APIs, web pages, and relational databases, to help you get some idea of how you might incorporate different kinds of data into your RDF triplestore and be able to publish it in one of the semantic web formats we’ve discussed.
Although we’ll take you through code for getting data from a few different places, the purpose of this section is really to show you a basic pattern for taking data from anywhere and converting it to RDF, so you can both store it and republish it for consumption by other applications. This generally breaks down into three steps:
Identify and parse a source of data.
Find or create a schema that matches your data.
Map the data to that namespace and make some RDF.
Simple enough, right? Now let’s try it out on some real datasets.
Internet Video Archive
The Internet Video Archive (IVA) is an aggregator of video content, such as movie trailers and video game previews, that you can find at http://internetvideoarchive.com. It provides an API that allows developers to include video clips on their sites and that also gives lots of information about movies, music, and TV shows. To get started, you’ll need to get an API key by going to http://api.internetvideoarchive.com/. This should take only a few seconds, but if you’d rather not bother getting an API key, we’ve provided static versions of the files on http://semprog.com.
The Movies API exposes several methods, which are accessible through
simple REST requests. You can search for movies by name, look for what’s
new on DVD, or, as we’ll do in this case, look at data about movies
currently in theaters. To see how this API call works, point your web
browser to http://www.videodetective.com/api/intheaters.aspx?DeveloperId={YOUR
KEY} (or http://semprog.com/data/intheatres.xml)
and you should see something like this:
<items Page="1" PageSize="100" PageCount="1" TotalRecordCount="69">
<item>
<Description>QUANTUM OF SOLACE Video</Description>
<Title>QUANTUM OF SOLACE</Title>
<Studio>Columbia Pictures</Studio>
<StudioID>255</StudioID>
<Rating>PG-13</Rating>
<Genre>Action-Adventure</Genre>
<GenreID>1</GenreID>
<Warning>Sex, violence</Warning>
<ReleaseDate>Sat, 01 Nov 2008 00:00:00 GMT</ReleaseDate>
<Director>Marc Forster</Director>
<DirectorID>18952</DirectorID>
<Actor1>Giancarlo Giannini</Actor1>
<ActorId1>2929</ActorId1>
<Actor2>Judi Dench</Actor2>
<ActorId2>4446</ActorId2>
<Actor3>Daniel Craig</Actor3>
<ActorId3>14053</ActorId3>
...
<PublishedId>629936</PublishedId>
<Link>http://www.videodetective.com/titledetails.aspx?publishedid=808130</Link>
<Duration>143</Duration>
<DateCreated>Fri, 11 Apr 2008 13:31:00 GMT</DateCreated>
<DateModified>Wed, 29 Oct 2008 11:04:00 GMT</DateModified>
<Image>http://www.videodetective.com/photos/1263/05308032_.jpg</Image>
<EmbedCode>
<
Generally, the fields in the film schema used by Freebase, which
you can see in Figure 7-4, approximately match the
fields in the XML file that we’re getting from the IVA. There is one
notable exception: the Freebase schema has
Performances instead of Actors. If
you drill down into the definition, you’ll see that a performance links
to both an Actor and a Role, which
describes the character that the actor plays in the film. In the case of
IVA, the characters aren’t given, so we’ll leave Role
empty for our example. Our goal is to translate the XML records into a
graph that looks like what you see in Figure 7-5.
Now that we have the source and the schema, we can write the code to download and parse the XML, and then put it in an RDF store using our namespaces. Take a look at IVAtoRDF.py, which you can download from http://semprog.com/psw/chapter7/IVAtoRDF.py. The first section is just a few inserts and namespace definitions, a pattern you’ll use again and again as you express new datasets as RDF:
from rdflib.Graph import ConjunctiveGraph
from rdflib import Namespace, BNode, Literal, RDF, URIRef
from urllib import urlopen
from xml.dom.minidom import parse
FB = Namespace("http://rdf.freebase.com/ns/")
IVA_MOVIE= Namespace("http://www.videodetective.com/titledetails.aspx?publishedid=")
IVA_PERSON= Namespace("http://www.videodetective.com/actordetails.aspx?performerid=")
RDFS = Namespace("http://www.w3.org/2000/01/rdf-schema#")
In this code, we’re using the Freebase and RDF namespaces. Since
the IVA doesn’t have an official schema for expressing their data in
RDF, we’ve also invented some new namespaces to represent items coming
from the IVA. We’ve imported parse from the minidom
API that comes with Python to parse the XML.
The next piece of code defines a method that parses the XML from
IVA into a list of dictionaries. Each dictionary will contain the movie
ID, title, director, and actors. The director and actors are also
dictionaries, each containing an ID and a name. You could extract even
more information about the movie from the XML, but we’ll keep it simple
for this example. The main method here is
get_in_theaters, which opens and parses the XML file
and then uses standard DOM operations to get the relevant data:
# Returns the text inside the first element with this tag
def getdata(node,tag):
datanode = node.getElementsByTagName(tag)[0]
if not datanode.hasChildNodes(): return None
return datanode.firstChild.data
# Creates a list of movies in theaters right now
def get_in_theaters():
# use this if you have a key:
#stream =
urlopen('http://www.videodetective.com/api/intheaters.aspx?DeveloperId={KEY}')
# otherwise use our copy of the data:
stream = urlopen('http://semprog.com/data/intheatres.xml')
root=parse(stream)
stream.close()
movies=[]
for item in root.getElementsByTagName('item'):
movie={}
# Get the ID, title, and director
movie['id'] = getdata(item,'PublishedId')
movie['title'] = getdata(item,'Title')
movie['director'] = {'id':getdata(item,'DirectorID'),
'name':getdata(item,'Director')}
# Actor tags are numbered: Actor1, Actor2, etc.
movie['actors'] = []
for i in range(1,6):
actor = getdata(item,'Actor%d' % i)
actorid = getdata(item,'ActorId%d' % i)
if actor != None and actorid != None:
movie['actors'].append({'name':actor, 'id':actorid})
movies.append(movie)
return moviesNow here’s the interesting part: we want to take the dictionary
and express it as a graph like the one shown in Figure 7-5. To do this, we’re going to loop over all the
movies, construct a node representing each one, and add the literal
properties, the ID and the title, to that node. Next we’ll create a
director node and link it to the movie. Finally (and this is the
slightly tricky part), we’ll loop over each actor and create an
anonymous performance node and an
actor node. The actor gets linked to the performance,
and the performance gets linked to the movie.
If this seems overly complicated, remember that the
performance node is there so that if we ever decide
to add the name of the character to the actor, we’ll have a concept of
“performance”—that is, a node to which the role can be connected:
# Generate an RDF Graph from the Movie Data
def make_rdf_graph(movies):
mg = ConjunctiveGraph()
for movie in movies:
# Make a movie node
movie_node = IVA_MOVIE[movie['id']]
mg.add((movie_node,DC['title'], Literal(movie['title'])))
# Make the director node, give it a name and link it to the movie
dir_node = IVA_PERSON[movie['director']['id']]
mg.add((movie_node,FB['film.film.directed_by'], dir_node))
mg.add((dir_node, DC['title'], Literal(movie['director']['name'])))
for actor in movie['actors']:
# The performance node is a blank node -- it has no URI
performance = BNode()
# The performance is connected to the actor and the movie
actor_node = IVA_PERSON[actor['id']]
mg.add((actor_node,DC['title'], Literal(actor['name'])))
mg.add((performance, FB['film.performance.actor'], actor_node))
# If you had the name of the role, you could also add it to the
# performance node, e.g.
# mg.add((performance, FB['film.performance.role'],
# Literal('Carrie Bradshaw')))
mg.add((movie_node, FB['film.film.performances'], performance))
return mgFinally, we just need a main method to tie it all together. Since
the IVA API has a lot of different options, we could replace
get_in_theaters with another function that returns a
dictionary of movies, and convert that to RDF instead:
if __name__=='__main__':
movies = get_in_theaters()
movie_graph = make_rdf_graph(movies)
print movie_graph.serialize(format='xml')What we’ve done here, and what you’ll be seeing for the remainder of this section, is extracted the data from its source and recreated it with explicit semantics. Additionally, where possible, we’ve pointed to a published schema so that others who are using that schema can easily consume the data, and those who aren’t can at least read what all the fields mean. As an exercise, see if you can find another published film schema. Then, figure out how many movies are available in RDF using that schema, and alter the code so it creates an RDF file using that namespace.
Tables and Spreadsheets
A huge amount of data, both on the Web and saved on people’s computers, is in tabular formats—many people believe that there’s more business data in Excel spreadsheets than in any other format. As we learned in Chapter 1, and as we’ve been seeing throughout this book, data in tables is easy to read but difficult to extend, and more importantly, it can’t easily be combined with data from other sources.
To extend the previous example, consider the following CSV file, which was exported from Excel and can be downloaded from http://semprog.com/psw/chapter7/MovieReviews.csv. It’s a pretty simple file, with just three fields: a movie name, a rating, and a short review. It matches the movies provided in the sample file in the previous section:
QUANTUM OF SOLACE,3,"This film will please action fans, but the franchise has all... FILTH AND WISDOM,1,Madonna's directorial debut is unconvincing and incoherent ROLE MODELS,4,"Juvenile, ridiculous and predictable, yet it still manages to be... FEARS OF THE DARK,5,"This French animated horror portmanteau is monochrome and... CHANGELING,2,What could have been a dramatic and tumultuous film ends up boring...
What we’re going to do here demonstrates how semantic data can be combined from multiple sources using different schemas. In the previous section we used the Freebase movie schema, but Freebase contains mostly facts and doesn’t have any fields for opinions or reviews. However, there’s a standard RDF review vocabulary available at http://www.purl.org/stuff/rev# that we can use to attach the reviews in the file to the movies already in the graph. The review vocabulary is not specific to movies, and can be used for describing reviews of anything. Even though the Freebase schema that we used doesn’t support movie reviews, we can add them simply by including another namespace. Even better, the namespace is a de facto standard and is used in hReview microformats, so there will certainly be other services able to read it.
The following code, which you can download from http://semprog.com/psw/chapter7/MergeTabReviews.py, shows how to add the reviews to the existing graph. It first creates the movie graph using the functions defined earlier, then loops over the CSV file and searches for movies by name to find the appropriate node. For each movie, it creates a BNode representing the review, and then adds the rating and review text to the review node. The final addition to the node is a reference to Toby, who wrote the review:
from rdflib.Graph import ConjunctiveGraph
from rdflib import Namespace, BNode, Literal, RDF, URIRef
from IVAtoRDF import FB,DC,get_in_theaters,make_rdf_graph
from csv import reader
# Reviews Namespace
REV=Namespace('http://www.purl.org/stuff/rev#')
if __name__=='__main__':
# Create a graph of movies currently in theaters
movies = get_in_theaters()
movie_graph = make_rdf_graph(movies)
# Loop over all reviews in the CSV file
for title, rating, review in reader(open('MovieReviews.csv', 'U')):
# Find a movie with this title
match = movie_graph.query('SELECT ?movie WHERE {?movie dc:title "%s" .}'
% title, initNs={'dc':DC})
for movie_node, in match:
# Create a blank review node
review_node = BNode()
# Connect the review to the movie
movie_graph.add((movie_node, REV['hasReview'], review_node))
# Connect the details of the review to the review node
movie_graph.add((review_node, REV['rating'], Literal(int(rating))))
movie_graph.add((review_node, DC['description'], Literal(review)))
movie_graph.add((review_node, REV['reviewer'],
URIRef('http://semprog.com/people/toby')))
# Search for movies that have a rating of 4 or higher and the directors
res=movie_graph.query("""SELECT ?title ?rating ?dirname
WHERE {?m rev:hasReview ?rev .
?m dc:title ?title .
?m fb:film.film.directed_by ?d .
?d dc:title ?dirname .
?rev rev:rating ?rating .
FILTER (?rating >= 4)
}""", initNs={'rev':REV, 'dc':DC, 'fb':FB})
for title,rating,dirname in res:
print '%s %s %s' % (title, dirname, rating)At the end of the code is a SPARQL query to find the movie title, director, and rating for everything with a rating of 4 or higher. Although in this case you only have one review for each movie, it’s possible to attach multiple review nodes to each one. That way, the query would search for everything that anyone rated 4 or higher. Running this program gives the output:
$ python MergeTabReviews.py FEARS OF THE DARK Marie Caillou 5 ROLE MODELS David Wain 4
Notice that we’ve merged data from two different sources using two different schemas, and we can use both in a single query. This was possible because the movies had the same names in both datasets. If there were spelling mistakes or different punctuation, we would have had to clean them up in both sources to make the query possible.
Legacy Relational Data
Almost all business and web applications are built on relational databases that are generally queryable with SQL. There are a number of reasons that we’ve explored so far for why one might choose to expose this relational data in a standard semantic format like RDF. In addition to the extensibility advantages of representing data semantically, it also makes it easy to share with others.
To demonstrate the conversion of typical relational data into RDF, we’ll consider an incredibly simple schema for a message board, shown in Figure 7-6. The database consists of four tables that contain messages, users, and subjects. They are connected in the standard way, with foreign keys and an intermediate table for the many-many relationship between subjects and messages.
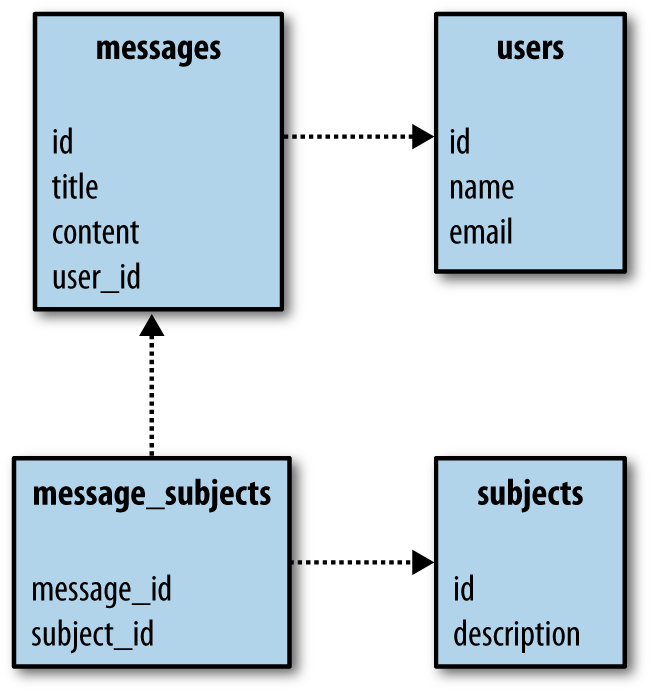
We’ve provided a SQL schema at http://semprog.com/psw/chapter7/message_board.sql. It creates the tables and inserts fake data into them. We had actually hoped to find a set of SQL data that you could just download, but there’s very little out there. This perhaps demonstrates the point that SQL is a good tool for manipulating data but not as good for publishing and sharing data.
Our goal is to take this data and republish it as RDF using the
Semantically-Interlinked Online Communities (SIOC,
pronounced “shock”) vocabulary, which is used to semantically describe conversations
happening online. Messages published in SIOC can be more easily
understood by aggregators, much like RSS feeds, but also have the
ability to be connected across sites through the
has_reply and reply_of properties.
This means that it’s possible to find the threads of conversations that
are decentralized and published across the Web.
The code to do the conversion is available at http://semprog.com/psw/chapter7/message_board_to_sioc.py. Let’s look through it so you can learn the basics of how this conversion works. The first part of the file defines all the namespaces we’ll be using. SIOC and several others are used, including FOAF, since that’s the standard way of expressing email addresses. We also throw in a namespace for this message board:
import sqlite3,os
from rdflib.Graph import ConjunctiveGraph
from rdflib import Namespace, BNode, Literal, RDF, URIRef
from urllib import urlopen
SIOC=Namespace('http://rdfs.org/sioc/ns#')
DC = Namespace("http://purl.org/dc/elements/1.1/")
DCTERMS = Namespace('http://purl.org/dc/terms/')
FOAF = Namespace("http://xmlns.com/foaf/0.1/")
RDFS = Namespace("http://www.w3.org/2000/01/rdf-schema#")
# Fake namespace for this message board
MB = Namespace('http://messageboard.com/')The load_data function simply creates a sqlite
database and runs all the SQL statements in the input file. This will
get run by our main method as follows if it can’t find a message_board database. Usually you would
be starting with an already populated database, not a series of SQL
statements, but this is the easiest way for us to distribute the
data:
# load the SQL file into a database
def load_data(sqlfile, dbfile):
conn = sqlite3.connect(dbfile)
cur = conn.cursor()
f = file(sqlfile)
for line in f: cur.execute(line)
f.close()
conn.commit()
conn.close()The function that actually queries the database and creates the
RDF graph is message_board_to_sioc. It’s very
simple—all it does is query the tables one at a time and create the
relevant nodes. Except for in the message_subjects
table, each row represents a node in a graph. Because we’re using unique
names in namespaces to refer to nodes, it’s possible to refer to them
before creating all their details, which means we don’t have to do any
joins! Just select from the table and create nodes in the graph:
# convert the message board SQL database to SIOC
def message_board_to_sioc(dbfile):
sg = ConjunctiveGraph()
sg.bind('foaf', FOAF)
sg.bind('sioc', SIOC)
sg.bind('dc', DC)
conn = sqlite3.connect(dbfile)
cur = conn.cursor()
# Get all the messages and add them to the graph
cur.execute('SELECT id, title, content, user FROM messages')
for id, title, content, user in cur.fetchall():
mnode = MB['messages/%d' % id]
sg.add((mnode, RDF.type, SIOC['Post']))
sg.add((mnode, DC['title'], Literal(title)))
sg.add((mnode, SIOC['content'], Literal(content)))
sg.add((mnode, SIOC['has_creator'], MB['users/%s' % user]))
# Get all the users and add them to the graph
cur.execute('SELECT id,name,email FROM users')
for id, name, email in cur.fetchall():
sg.add((mnode, RDF.type,SIOC['User']))
unode = MB['users/%d' % id]
sg.add((unode, FOAF['name'], Literal(name)))
sg.add((unode, FOAF['email'], Literal(email)))
# Get subjects
cur.execute('SELECT id,description FROM subjects')
for id, description in cur.fetchall():
sg.add((mnode, RDF.type,DCTERMS['subject']))
sg.add((MB['subjects/%d' % id], RDFS['label'], Literal(description)))
# Link subject to messages
cur.execute('SELECT message_id,subject_id FROM message_subjects')
for mid, sid in cur.fetchall():
sg.add((MB['messages/%s' % mid],SIOC['topic'], MB['subjects/%s'] % sid))
conn.close()
return sgOf course, this is a very simple database, and most relational
databases will probably have many more tables. The important thing to
understand is that this code takes a SQL database, which has implicit
semantics, and converts it to an RDF graph, which has explicit
semantics. It does this by taking the implied connections between tables
(e.g., a user_id of 1 in a row in the messages
table), and restating them in a standard vocabulary (e.g., triples like
(message:10 has_creator user:1), where
has_creator is defined by SIOC).
Finally, the main method ties it all together:
if __name__=="__main__":
if not os.path.exists('message_board.db'):
load_data('message_board.sql', 'message_board.db')
sg = message_board_to_sioc('message_board.db')
print sg.serialize(format='xml')If you run message_board_to_sioc, you should
see the RDF/XML version of the messages. Plug-ins are available for many
of the popular blogging and message board platforms, which you can find at http://sioc-project.org.
RDFLib to Linked Data
In the previous section, you saw how to take datasets stored or published in other formats and load them into RDFLib, then generate all the XML for the graph you built. In practice, if you were consuming a very large graph with hundreds of thousands of nodes, you probably wouldn’t want to publish the graph as a single XML file. In this section, we’ll look at a more practical way to take a graph that you’ve built in RDFLib and turn it into a set of files that could be easily consumed by a crawler.
In Chapter 5 you learned about the Linking Open Data community, which has developed a set of conventions for building graph datasets that are distributed across the Internet. You can use the same ideas to republish a large graph as a series of files, which could then be served from one or more web servers.
The following is a simple example of how to do this with the data collected from the Internet Video Archive. You can download this example from http://semprog.com/psw/chapter7/publishedLinkedMovies.py:
from rdflib.Graph import ConjunctiveGraph
from rdflib import Namespace, BNode, Literal, RDF, URIRef
import IVAtoRDF
FB = Namespace("http://rdf.freebase.com/ns/")
DC = Namespace("http://purl.org/dc/elements/1.1/")
IVA_MOVIE= Namespace("http://www.videodetective.com/titledetails.aspx?publishedid=")
IVA_PERSON= Namespace("http://www.videodetective.com/actordetails.aspx?performerid=")
RDFS = Namespace("http://www.w3.org/2000/01/rdf-schema#")
movies = IVAtoRDF.get_in_theaters()
movie_graph = IVAtoRDF.make_rdf_graph(movies)
fq = movie_graph.query("""SELECT ?film ?act ?perf ?an ?fn WHERE
{?film fb:film.film.performances ?perf .
?perf fb:film.performance.actor ?act .
?act dc:title ?an.
?film dc:title ?fn .
}""",
initNs={'fb':FB,'dc':DC})
graphs={}
for film, act, perf, an, fn in fq:
filmid = fn.split(',')[0].replace(' ','_') + '_' + str(film).split('=')[1]
actid = an.replace(' ','_') + '_' + str(act).split('=')[1]
graphs.setdefault(filmid, ConjunctiveGraph())
graphs.setdefault(actid, ConjunctiveGraph())
graphs[filmid].add((film, FB['film.film.performance.actor'], act))
graphs[filmid].add((act, OWL['sameAs'], actid + '.xml'))
graphs[filmid].add((film, DC['title'], fn))
graphs[actid].add((act, FB['film.actor.performance.film'], film))
graphs[actid].add((film, OWL['sameAs'], filmid + '.xml'))
graphs[actid].add((act, DC['title'], an))
for id, graph in graphs.items():
graph.serialize('open_films/%s.xml' % id)
This code first calls a couple of methods from
IVAtoRDF to generate the movie graph. It then generates
a set of files for the movies and another set of files for the actors, in
each case using a SPARQL query to pull out all the important data about
the particular entity of interest. The data is amended with
owl:sameAs links, which refer to the other files in the
set, and each entity is saved in a small graph that is in turn saved to a
small RDF/XML file. The names of the XML files include the full names of
the actors and movies to make things easier for search engines, and they
also include the IDs to ensure uniqueness if two movies have the same
name.
Executing this code will create a series of XML files like this:
Bill_Murray_761.xml BODY_OF_LIES_39065.xml BREAKFAST_WITH_SCOT_48168.xml Brigette_Lin_38717.xml
For example, if you look at
BODY_OF_LIES_39065.xml, you can see that the
owl:sameAs links refer to other “information
resources,” so that a crawler knows where to go to find out more about
each entity referred to in the file:
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF
xmlns:_3="http://rdf.freebase.com/ns/"
xmlns:_4="http://purl.org/dc/elements/1.1/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
>
<rdf:Description rdf:about=
"http://www.videodetective.com/titledetails.aspx?publishedid=390615">
<_3:film.film.performance.actor rdf:resource=
"http://www.videodetective.com/actordetails.aspx?performerid=4998"/>
<_3:film.film.performance.actor rdf:resource=
"http://www.videodetective.com/actordetails.aspx?performerid=7349"/>
<_3:film.film.performance.actor rdf:resource=
"http://www.videodetective.com/actordetails.aspx?performerid=59108"/>
<_3:film.film.performance.actor rdf:resource=
"http://www.videodetective.com/actordetails.aspx?performerid=30903"/>
<_3:film.film.performance.actor rdf:resource=
"http://www.videodetective.com/actordetails.aspx?performerid=61052"/>
<_4:title>BODY OF LIES</_4:title>
</rdf:Description>
<rdf:Description rdf:about=
"http://www.videodetective.com/actordetails.aspx?performerid=4998">
<rdfs:seeAlso rdf:resource="Leonardo_DiCaprio_4998.xml"/>
</rdf:Description>
<rdf:Description rdf:about=
"http://www.videodetective.com/actordetails.aspx?performerid=30903">
<rdfs:seeAlso rdf:resource="Oscar_Isaac_30903.xml"/>
</rdf:Description>
... etc.You can now upload the serialized data to a web server and contribute it to the cloud of Linked Data. While making the raw RDF files available is useful, to properly participate in the Linked Open Data community your web server should be configured to handle requests as depicted in Figure 5-2. That is, it should direct people from the URI representing the real-world entity to an information resource that describes it in context. Fortunately, there are well-vetted recipes available online for configuring the Apache server to do this. One place to start is the W3C’s “Best Practices Recipes for Publishing RDF Vocabularies” at http://www.w3.org/TR/swbp-vocab-pub/.
Once you have uploaded all the files to a server, you have successfully created and published a Linked Data set! Someone else could now publish another file that lists which of your URLs are the “sameAs” movie URLs from Wikipedia, Netflix, IMDB, or a movie review site like Rotten Tomatoes. Then a crawler (similar to the one you built in Chapter 5) could construct queries that worked across all of these datasets. The goal of Linked Open Data is to answer questions like, “Which movies starring Kevin Bacon that were favored by more than 80% of critics are available for rent right now?” without any one person or company owning all of the data.
This example generates static RDF/XML files about movies. This data isn’t constantly changing, and therefore it can be useful even if the static files are updated only occasionally. However, for applications in which the data is constantly changing, it makes more sense to dynamically generate the RDF/XML on the fly.
For instance, if we had access to a live message board server, we
could extend message_board_to_sioc.py to generate live
Linked Data using a simple WSGI server. WSGI (Web Server Gateway
Interface) is a standard method for interfacing Python applications and
web servers. In Chapter 10 we will use CherryPy,
a simple Python application server, but for our current purposes we will
use the SimpleServer built into the WSGI reference implementation, which is now a standard
Python library.
The message board data has a number of interesting facets that systems might want information about: users, subjects, and messages. We will limit ourselves to dealing with users and messages, but you should be thinking about how you could extend it (with just a few extra lines of code) to handle requests for subjects.
Each user will have a unique URI of the form
http://ourserver/users/<userid>,
and similarly we will assign each message a URI of the form
http://ourserver/messages/<messageid>.
When a system attempts to dereference a URI, we will inspect the URI
requested to determine whether it is asking for a real-world entity or an
information resource. If the request is for a real-world entity, we will
redirect the system to the location of the information resource. If the
request is for an information resource, we will inspect the request to
determine whether it is asking for information about a user or a message,
and create an appropriate CONSTRUCT SPARQL query to provide the
information requested. The results of the SPARQL query will be serialized
into RDF/XML and sent back as the response.
When the server is first initialized, it uses the
message_board_to_sioc module to load the message board
data into the graph that is used by the SPARQL queries. If you had access
to a live relational database, you could modify the code so that instead
of dumping the complete SQL database into a graph at startup, you could
populate a small in-memory graph on
each request that contained only the resources necessary to fulfill the
inquiry specified by the URI.
The code for the complete server is available at http://semprog.com/psw/chapter7/message_board_LOD_server.py.
Place the server file in the same directory as the message_board_to_sioc module and SQL data,
and execute the file:
import os
from wsgiref import simple_server
import rdflib
from rdflib import Namespace
import message_board_to_sioc
from message_board_to_sioc import SIOC, DC, DCTERMS, FOAF, RDFS, MB
"""
A very simple Linked Open Data server
It does not implement content negotiation (among other things)
...and only serves rdf+xml
"""
server_addr = "127.0.0.1"
server_port = 8000
infores_uri_component = "/rdf"
def rewrite(environ):
#add infores first path segment
return "http://" + environ["HTTP_HOST"] + infores_uri_component +
environ["PATH_INFO"]
def test_handler(environ):
resp = {"status":"200 OK"}
resp["headers"] = [("Content-type", "text/html")]
outstr = ""
for k in environ.keys():
outstr += str(k) + ": " + str(environ[k]) + "<br>"
resp["body"] = [outstr]
return resp
def redirect(environ):
resp = {"status":"303 See Other"}
resp["headers"] = [("Location", rewrite(environ))]
return resp
def servedata(environ):
#Additional ns' for the queries
ourserver = "http://" + server_addr + ":" + str(server_port) + "/"
MBMSG = Namespace(ourserver + "messages/")
MBUSR = Namespace(ourserver + "users/")
path = environ["PATH_INFO"]
resp = {"status":"200 OK"}
resp["headers"] = [("Content-type", "application/rdf+xml")]
if environ["PATH_INFO"].find("users") != -1:
#user request query
userid = "mbusr:" + path[path.rindex("/") + 1:]
query = """CONSTRUCT {
""" + userid + """ sioc:creator_of ?msg .
?msg dc:title ?title .
""" + userid + """ foaf:name ?name .
} WHERE {
?msg sioc:has_creator """ + userid + """ .
?msg dc:title ?title .
""" + userid + """ foaf:name ?name .
} """
else:
#message request query
msgid = "mbmsg:" + path[path.rindex("/") + 1:]
query = """CONSTRUCT {
""" + msgid + """ dc:title ?title .
""" + msgid + """ sioc:has_creator ?user .
""" + msgid + """ sioc:content ?content .
} WHERE {
""" + msgid + """ dc:title ?title .
""" + msgid + """ sioc:has_creator ?user .
""" + msgid + """ sioc:content ?content .
} """
bindingdict = {'sioc':SIOC,
'dc':DC,
'dcterms':DCTERMS,
'foaf':FOAF,
'rdfs':RDFS,
'mb':MB,
'mbmsg':MBMSG,
'mbusr':MBUSR}
resp["body"] = [sg.query(query, initNs=bindingdict).serialize(format='xml')]
return resp
def error(environ, errormsg):
resp = {"status":"400 Error"}
resp["headers"] = [("Content-type", "text/plain")]
resp["body"] = [errormsg]
def application(environ, start_response):
"""Dispatch based on first path component"""
path = environ["PATH_INFO"]
if path.startswith(infores_uri_component):
resp = servedata(environ)
elif path.startswith("/messages/") or
path.startswith("/users/"):
resp = redirect(environ)
elif path.startswith("/test/"):
resp = test_handler(environ)
else:
resp = error(environ, "Path not supported")
start_response(resp["status"], resp["headers"])
if resp.has_key("body"):
return resp["body"]
else:
return ""
if __name__ == "__main__":
#initialize the graph
if not os.path.exists('message_board.db'):
message_board_to_sioc.load_data('message_board.sql', 'message_board.db')
serverlocation = server_addr + ":" + str(server_port)
#change the MB namespace to the base URI for this server
message_board_to_sioc.MB = Namespace("http://" + serverlocation + "/")
sg = message_board_to_sioc.message_board_to_sioc('message_board.db')
httpd = simple_server.WSGIServer((server_addr,
server_port),simple_server.WSGIRequestHandler)
httpd.set_app(application)
print "Serving on: " + serverlocation + "..."
httpd.serve_forever()As a test, try accessing the test_handler method,
which will dump out the contents of the WSGI request environment
dictionary, by pointing your web browser to http://127.0.0.1:8000/test/. If
everything is working, you should see something like this:
PATH_INFO: /test/ SERVER_PORT: 8000 HTTP_KEEP_ALIVE: 300 HTTP_ACCEPT_CHARSET: ISO-8859-1,utf-8;q=0.7,*;q=0.7 REMOTE_HOST: localhost HTTP_ACCEPT_ENCODING: gzip,deflate ...
Now try fetching the data for user 5 using the URI
http://127.0.0.1:8000/users/5. Depending on how your
web browser is configured to handle content with the mime type
application/rdf+xml, you may either be prompted to save
a file or you’ll see the raw RDF/XML in your browser frame. If your system
has wget or curl, you can also test the server by making requests from the
command line using something like this:
$ wget -q -O - http://127.0.0.1:8000/users/5
Tip
If you get an error about the CONSTRUCT query, your RDFLib may not be current. Users have reported problems with CONSTRUCT queries on various platform configurations prior to 2.4.1. To obtain the latest RDFLib from SVN, see the Tip.
The WSGI server we created is rather bare-bones, but it does fulfill
the requirements for serving Linked Data. Still, there are some obvious
modifications you may want to make. For one thing, the server makes no
attempt to actually “negotiate” the type of data it provides—ideally, it
should inspect the Accept header provided by the client
and, based on the server’s preferences, return an accommodating form of
data. For instance, if the client
indicated that it preferred receiving RDF in N3 format, the server could
modify the format parameter in the serialization call
for the graph produced by the CONSTRUCT SPARQL query. Alternatively, if
the client doesn’t know how to consume RDF and has a preference for HTML,
it would be good to return a redirect to a URI that produces
human-friendly output.
If you do make modifications to the server, you can verify that its behavior still conforms to the Linked Data community’s best practices by using the Vapour test suite available on SourceForge. If your modifications to the server are available on the public Internet, you can use a hosted version of Vapour available from http://validator.linkeddata.org/vapour.