
Chapter 1
Model Use: From a Decision-Making Problem to a Set of Research Problems1
1.1. Introduction: why model?
We “model” constantly in the course of everyday life: for each entity we encounter, be it an object, a person, or a process, we create an associated mental image that enables us to give meaning to its existence and behavior. As Valéry states in [VAL 77], “we only think using models”. A model is a formal representation of an object or a set of associated phenomena, which we attempt to circumscribe. It may be seen as an analytical tool used to describe, in a reduced and formalized manner, a particular observed object. In this way, the model acts as an intermediary between the object and the questions we ask to understand the object. Thus, the value of the model resides not in its “reality”, but in its use to explain a given object or a set of phenomena: it takes on a heuristic role in the process of generating knowledge about a given object.
We thus see that the concept of models is part of a “simplification/abstraction” dichotomy, containing aspects of both symbolic representation and reduction of the complexity of the observed object. However, although the model is only a partial representation of this object, or of a certain “reality” of the object (which implies that a large number of possible models exist for a given object), it enables us, in relation to our aims, to reduce this “reality” to a limited number of viewpoints that are intelligible and coherent for the modeler. For this reason, an “intentional” aspect is always present in the creation of a model. Modeling is a subjective activity, involving choices to which the user commits himself/herself. Another expression of this duality is given by Nouvel, who describes modeling as a “negligence strategy” [NOU 02]. Negligence, or the fact of not taking certain aspects of the object into account, is used intentionally to highlight other aspects of this same object. Depending on the refinement of the initial information at the base of the construction of the model, the model will appear, according to Terrasse [TER 05], as the result of a sophisticated strategy or as a form of negligence controlled by abstraction or simplification. Thus, the model plays a triple role, being subjective, projective, and intentional.
However, depending on the construction of the model and the aims of the user, a model may give a simplified or idealized vision of the reality being represented. For example, a model — in the fashion sense of the term — is chosen because he/she represents an ideal form, albeit one which is not representative of the average human physique. According to Thom [THO 03], it is thus easy, through excessive idealization or simplification, to pass from model use into the realm of “magical thinking”. Depending on the degree of freedom allowed, the model may evolve and may be perceived in very different ways. Care is needed to avoid confusing properties of the model with those of the real world, particularly in the context of competitive intelligence where digital artifacts, approximations, extractions, and data visualizations are frequent sources of errors and illusions.
Although a model is, by its very nature, simplistic and “fake”, it allows us to find answers to certain questions. A model is put to use through a process of questioning and testing. This process shows up misunderstandings and inadequate formulations that force us to reconsider the model, to look for other interactions, and/or plan new processes of observation. A main positive attribute of the model is the fact that it is a construct. Thus, we do not seek to know whether the model is “right”, but to analyze its contribution to a process of understanding (and in our particular context, mutual understanding between a watcher and a decision maker) the object constituted by the decision-making problem. Does this mean, then, that a “good” model is a useful model? This is what we will attempt to demonstrate in this chapter, showing the usefulness of a model-based approach in the process of transforming and resolving a decision problem in the context of information gathering.
In the context of this resolution, the watcher acts as the modeler of his/her own activities, both in determining what actions are necessary for the resolution of the information problem and in reducing their cognitive load, which, thanks to a support model, may be concentrated on the essential, but also because the information problem is itself a model of the larger decision problem. This model, created by the watcher, acts as an intermediary, as a pivotal document, and as a support for social and cognitive exchanges between the watcher and the decision maker and between all actors and the model. The resolution of the decision problem will not involve comings and goings between actors and the real world, but follows a more complex pattern of three-way interactions between the actors, the model, and the context of the problem.
Based on Roy’s work [ROY 85], we define the assistance provided by the watcher in resolving the decision problem in the competitive intelligence process as the activity which, based on clearly defined but not necessarily completely formalized models1, helps us to obtain aspects of a response to questions posed by the decision maker in this process, to work together to clarify or simply to favor a behavior in a way that increases the coherence between the evolution of resolution on the one hand, and the aims and preference system of the decision maker for whom the watcher is working on the other hand.
The model that we will now present aims, in addition to promoting the transition from a decision problem to an information-gathering problem and the various comings and goings involved (as the problem does not have a single final definition), to act as an event memory, as past events and analogy play an important role in the decision process. In designing the model, we have aimed to remain as close as possible to Ockham’s principle, that is, to avoid needless multiplication of elements of the model, while striving to be as faithful as possible to Boileau’s formula in describing the model.
1.2. General presentation of the Watcher Information Search Problem model
The Watcher Information Search Problem (WISP) model is made up of a collection of 27 interlinked elements that correspond to different “objects” handled by the watcher in the course of the watching process. These objects, which act as both containers and links, enable the watcher to organize and coordinate different steps of the transformation process — from registering the request to the presentation of results. Each of these objects has a number of attributes (title, date, reference, etc.) that describe its characteristics and promote “cognitive traceability” [KIS 09] of information, activity monitoring, and reuse (Figure 1.1).
Although this model is presented as a flow chart in Figure 1.1, the WISP is not fixed, as its name suggests (taking the meaning of the word “wisp”, and not just the WISP acronym). It is flexible and adaptable and allows for the addition of new elements, such as annotations. The square brackets [ ], which follow certain labels, indicate that the element is, in fact, a collection, that is, a group of objects. For example, the element <Demand> is associated with a collection of objects, <Formulation>, which correspond to the registration of different formulations and reformulations of the demand produced by the decision maker and by the watcher.
Figure 1.1. General presentation of the WISP model

1.3. Dimensions and aspects of the model
The WISP model is a three-dimensional, multifaceted model that incorporates the notion of the following points of view:
– an analytical dimension, which encompasses the understanding of demand, stakes, and context, the definition of information indicators and all knowledge creation and analysis operations that may be carried out by studying the memorized elements;
– a methodological dimension which, at the first level, is constituted by the capacity for transformation of the decision problem into an information problem (then into research problems), and on a second level by research strategies through which information is identified and knowledge acquired;
– an operational dimension, corresponding to the selection of action plans and the implementation of different steps of resolution of the methodology associated with the WISP model.
The “Need” aspect permits decision-based characterization of the expression of need (the formulated demand) suitable for the stakes and the context of the decision problem being considered; it is made up of the set of information produced by the model to explain the decision problem, the demand, and the associated stakes (Figure 1.2).
Figure 1.2. The “Need” aspect: explanation of requirements and contextualization of demand

The “Project” aspect links the demand to its transformation into information indicators, information problems, and their solutions, and the analysis and presentation of results to the decision maker (Figure 1.3).
The “Research” aspect connects information-gathering problems (through the formulation of the watcher’s research aims and activities) with information elements (solutions) to show the value of indicators (Figure 1.4).
Finally, the “Knowledge” aspect is made up of annotations and analyses of both the results and the process itself by the watcher and by the decision maker. These aspects can be used to determine the boundaries of the model depending on different points of view, and in learning to use the model depending on the chosen aspects.
Figure 1.3. The “Project” aspect: transformation of demand to produce information indicators
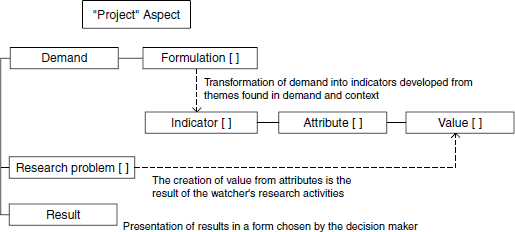
Figure 1.4. The “Research” aspect: provision of indicator values through research

1.4. Description of model elements
1.4.1. Elements describing the decision problem and its context
These elements of the model (Figure 1.5) carry information provided by both the decision maker and the watcher. Their purpose is to assist the decision maker in explicitly expressing needs and in formulating a request for information perfectly adapted to this need. The aim of the watcher is to register the facts that made the decision maker aware of the existence of the decision problem and to allow the decision maker to formulate the stakes linked to this problem. This step is carried out collaboratively with the aim of sharing the first intuitive ideas of both actors.
Figure 1.5. Elements characterizing the decision environment
The different information required for these elements is collected through guided interviews, by carrying out monitoring and by periodic research, the direction of which will be set out in the WISP model. Certain parameters included in these elements are destined for the decision maker alone; others may be shared with the watcher and may act as a basis for discussion.
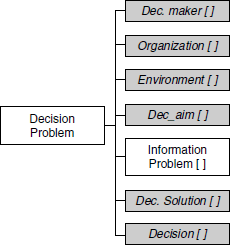
The characterization of the decision problem involves seven elements, all of which appear at the same level in the hierarchical plan. These elements are object collections (represented by square brackets [ ]) that may contain one or more similar items. For example, several decision aims may be involved in a single decision problem, which may also spread over multiple environments and involve a group of decision makers. For a given problem, the elements <Decision Maker>, <Organization>, <Environment>, and <Decision Aim> define the context of the problem; if necessary, references to previous problems or to other problems being dealt with in parallel may also be included.
The information problem, or problems, is also found at this level. Each of these problems includes <Demand>, <Stakes>, <Research Problem>, <Result>, and <Analysis> elements, along with their derived elements and all associated dependencies. Finally, at the end of the information process, we find the elements <Decision Solution> and <Decision>, which encompass, respectively, the whole range of alternatives and possible solutions, and the chosen solution. Each of these elements has several parameters, which may be static, that is, which do not vary through different problems (e.g. the identity of a decision maker), or which may be dynamic, in which case their characteristic information changes in relation to given problems, is highly context dependent, or simply evolves, as when dealing with the level of experience of the decision maker. Transversal (invariable) parameters are imported as they are, will be duplicated for each new problem, and adapted as necessary and memorized.
The <Decision Maker> element contains individual characteristics of the decision maker: identity, initial training, functions, cognitive style, personality traits (such as Myers Briggs type indicator (MBTI)), and his/her level of expertise for the problem in question. Bouaka [BOU 04], taking inspiration from Hermann’s work [HER 99], suggests adding an emotional dimension to take different emotional reactions into account, reactions that may influence the decision maker during the decision process. Although some of these parameters have not yet been completely formalized, they are mainly intended for use in self-diagnosis and are not intended to be transmitted. In addition to this information, we also find references to the decision problems under consideration. These operations are repeated for each decision maker involved in the decision project.
The <Organization> element contains information about the company. This includes not only data about the company (corporate name, site, legal status, sector of activity, clients, competitors, domains of expertise, resources, etc.) but also information on the way the company is perceived by the decision maker from his/her specific viewpoint. What, then, according to the decision maker, are the strengths and weaknesses of the company? What are its innovational niches? The main function of a business clearly depends not only on the company, but also on the points of view of the individuals that make up the company. The viewpoints of shareholders, employees, syndicates, and management have some similarities, but also palinodes and divergences, and may share doubts and uncertainties that should, in our opinion, be included in the model. In addition to these internal perspectives, we might add external impressions, for example, those of political and economic actors (the region, the state, etc.) and the viewpoints held by competitors and the media. The modeling of any of these different visions may be the subject of specific research in the framework of specialized scouting activities. They may be integrated into this element depending on the nature of the problem and of the aims. Other parameters may also be considered, the nature and number of which vary depending on the depth of the analysis desired. Examples of such parameters include the description of different operational functions of the business (production, service, sales, accounting, R&D, support, etc.), the identification of certain dysfunctional elements, the structure of the information system, its communication policies, its attitude to information in general (circulation, memorization, protection, patents, etc.), the measurement of its economic impact and various indicators (dashboard, indicators of direction, and performance, etc.), its originality, its history, and the way the company is managed. This element may be duplicated depending on the number of entities under consideration and the breakdown of the chosen structure (by subsidiaries, by departments, etc.) or in cases where the decision situation involves several organizations (e.g. an extended company), for example, in the case of a partnership.
The <Environment> collection of elements describes and defines the company’s relationships with the outside world. It aims to identify the factors that the decision maker considers to be environment sensitive, to assist in capturing weak signals, and to identify opportunities and threats. This perception is highly subjective and is subject to implementation. This subjectivity is a source of interest to the watcher, as it is this which provokes strategic action from the decision maker and triggers the problem. This “problem premonition”, which occurs before any decision-making activity, is made up of observations, interpretations, and incorporations of environmental stimuli, showing up filters and biases on the part of the decision makers and certain aspects of their preference system.
We will use Porter’s five competing forces as parameters of the <Environment> element: the description (and perception) of competitors, partners, suppliers, the market, and the clients, to which the results of different specialized scouting activities may be added depending on the domain or domains under consideration. However, we will not attempt to divide the environment into sectors, but rather cover as many domains as possible. Using these parameters, it is also possible to characterize the environment in terms of turbulence, uncertainty, and complexity, and to define endogenous and exogenous indicators to measure and monitor the factors, which the decision maker considers to be critical. The information required to establish these indicators can come from different elements of the model, be the result of specific research activities, or have been collected using questionnaires that, coupled with a Likert scale, for example, allow us to measure the intensity of the revealed factors.
The <Decision Aim> element contains the aim or aims of the decision project or projects concerned. The decision aim, in our opinion, has a triple function: it is a particular and contextual expression of the strategy and current priorities of the business, a partial transformation of the stakes involved in the decision problem, and finally, the source of the information needs of the decision maker for this particular problem. This element may be broken down using a tree of intermediary aims and subgoals (operational, strategic, tactical, etc.) or be duplicated for each of the envisaged aims. It may also contain elements of the business plan that the decision maker considers to be useful.
1.4.2. Chosen solutions and the final decision
The two final elements, <Decision Solution> and <Decision>, regroup the different intentions and alternatives for solving the problem, which may be used by the decision maker. These elements allow the actors involved in the project to assess the project, adjust it by, for example, creating new demands, and “plan” the decision. They also aim to refine what Endsley calls “situation awareness” [END 00] for each actor, that is, the understanding of existing relationships between perceived elements of the environment and the mental projection of the evolution of these elements following specific envisaged solutions.
The <Decision Solution> element collection contains the description of different alternatives. It corresponds to the selection of possible choices for the problem being considered. The parameters (hypothesis, projection, and solution) of these elements contain projections of hypothetical futures based on different scenarios and allow the decision maker to define critical indicators, then to look for the variables that influence these indicators. The other parameters (resources, risks, cost, and validation) regroup the means available and those required to implement the envisaged solution. Each of these may also contain additional specifications; for example, within “resources”, we may find human, financial, and temporal resources alongside raw materials.
The <Decision> element or elements contain the details of the chosen decision and, possibly, a plan of action. It, or they, also contains the link or links to the decision solution to implement (as presented in the previous element) and, in certain cases, the resulting negotiations.
These two elements only mark a provisional solution to the decision problem, as this problem may depend on another problem, be part of a larger problem, or, like the ouroboros, create new problems in a dynamic spiral process. Can we, then, truly believe that a “final” decision might exist, or that a problem could be solved once and for all, and “closed?”
1.4.3. Supporting elements of the information problem
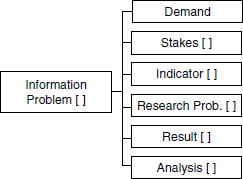
The <Information Problem> or problems — more often the latter — are part of the decision problem through this collection of elements and constitute the point of origin for the transformation of a decision problem into information problems. Several information problems, then, are attached to one decision problem or demand for information. We will explain the reasons for this choice later on.
Six elements (Figure 1.6) are at the root of the problem: the <Demand> that contains the different formulations and reformulations of need in terms of information, the <Stake(s)> involved in the decision problem associated with the demand and its context, the group of information <Indicator(s)> that constitutes a validated expression of the demand, the <Research Problem(s)> that stem partly from the demand and partly from the assignment of values to indicators, and finally the <Result> and <Analysis> elements that contain, respectively, the information produced and the analysis carried out, both on the results and on the decision process.
Figure 1.6. Elements at the root of the information problem
These elements will be filled in by the watcher and supervised by the decision maker. Additionally, some of these elements (particularly those included in, and derived from, the <Research Problem>) will benefit from computer support, which, due to its capacities for automization, will allow the association of data with certain parameters of these elements in a way easily understandable by the watcher.
1.4.4. Demand, stakes, and context
This first group, made up of 10 collections of elements, is the Demand—Stakes—Context (DSC) group (Figure 1.7). This links the four elements representing the context, imported from the decision problem, to two elements representing the demand and four others that will be used to define stakes. This group will also be superposed onto the “need” aspect of the model. The DSC group allows the watcher to contextualize the demands made of him/her (and, through the demand, the need for information that it expresses) and to link the two to the origin of the decision problem and to the environment.
Figure 1.7. Constituent elements of the DSC
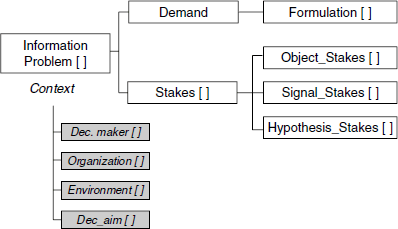
The <Demand> element has certain particularities: it alone plays the role of a “wrapper”, acting as an “envelope” for the <Formulation> set of elements. For each decision problem, there is one single demand, but one that may be made up of several formulations. In the same way, a multiple demand would require the simultaneous coexistence of several decision problems. In our model, we will distinguish between “multiple” and “plural” demands. A multiple demand, which corresponds to multiple stakes, leads to the creation of several decision problems. For example, if a business wishes to improve its brand image and create new markets, it is easy to see that two decision problems may be involved. A plural demand, on the other hand, involves several demand elements. Thus, to improve brand image, a demand may encompass a study of the competition, a quality audit carried out at client level, and a media campaign project, the substance of which requires definition.
In reality, in our model, the decision problem and the associated demand pertain to the element <Object of stakes>. We have chosen a hypothesis where, for as long as the object of the stakes does not change, we are dealing with the same decision problem, of which different formulations will undoubtedly be necessary to outline the demand as clearly as possible. These formulations therefore correspond either to a development in the understanding of the problem or to changes in the context (or even the development of an unexpected situation), which lead to corrections, precisions, or modification of the demand. However, if the emergence of this situation, the detection of new signals, or the incorporation of new factors change the stakes involved in the problem (and thus the object), we consider that the decision maker is now faced with a new problem. Depending on particular cases, this may imply the cessation of activity on the current problem and transformation to deal with the new problem, or replication and division of the current problem into as many problems as proved necessary. Thus, when multiple stakes are involved (the objects of which may conflict), we will be able to look at different solutions to the decision problems and choose one, benefiting one aspect to the detriment of another (e.g. environmental stakes over economic stakes).
The <Formulation> element collection contains different formulations and reformulations of the demand by actors. Although we initially chose to create “formulation” and “reformulation” elements in the model, based on the understanding that the decision maker is responsible for formulation and the watcher for reformulation, in practice we decided to use only formulations, which are, nevertheless, distinguished by author and date information. Thus, in the case of a stipulated demand, the decision maker will be the first “formulator” of the demand. In the case of an implicit demand, the watcher may be responsible for the formulation of the demand based on what he/she understands of the need; the decision maker will then reformulate this first formulation, and so on. In our opinion, reformulation is necessary as it satisfies the need for mutual and shared understanding. It also allows specification of concepts and agreement on common meanings for each concept. From these formulations, the watcher identifies key concepts (or themes of the demand) that will be attached to the <Demand> element itself.
The <Stakes> collection of elements, itself made up of three collections, is used to characterize the stakes involved in the decision problem from the point of view of the decision maker and opposes them to the demand and the context.
The <Object of Stakes> is the target on which the decision maker wishes to act, the <Signal> is what incites the decision maker to begin considering the decision problem, and the <Hypothesis> corresponds to the perceived risks and gains and to the envisaged consequences of a lack of action on the part of the decision maker. These parameters justify the decision aims, and the attainment of this goal contributes to their fulfillment. The action taken by the decision maker is logical from his/her point of view, based on what the decision maker stands to gain or lose during the resolution of the project, that is, through the identified stakes. While these stakes are often multiple, ambiguous, and sometimes contradictory, we consider that these stakes relate to the quality of perceived information, to environmental constraints, to the preferences of the decision maker, and to the decision maker’s value judgments. With a better perception of the stakes involved, the watcher is able to understand, via the formulated demand, which parameters of the decision problem hold the greatest importance for the decision maker. However, we are aware that part of these stakes will not be communicated to the watcher. Is the watcher, then, responsible for bringing forth results, based on personal reflection, from the hidden stakes of the decision maker? Does the watcher need to develop “psyops” [DAU 82] to “win over the heart and spirit” of the decision maker? These aspects are sensitive and the watcher must define the borders of his/her investigative territory and not overstep the limits. The relationships between actors themselves involve “risks and stakes which are decisive in self-image, defense of territory, maintenance or breaking of links” [PIC 06]. Thus, personal issues (concerning identity, territory, and position) always intervene as overlays to professional issues; once again, the watcher should act intelligently and show proof of good sense. Moreover, as Salomé emphasizes [SAL 02], it is difficult to establish a respectful and tolerant partnership when one of the two actors is not free (from hidden stakes in particular), as this will mean priority is given to former allegiances. Nevertheless, the decision maker must find the means of breaking free from the circle of prejudices; the formulation of stakes seems, to us, to be a suitable means of doing this.
After obtaining the titles of stakes involved, the watcher will establish a typology of stakes based on the different domains of the business (economic, strategic, commercial, social, etc.), depending on projections (short, medium, or long term) and, finally, based on the priority accorded to each by the decision maker.
1.4.5. Information indicators
The creation of a group of indicators constitutes the core of the WISP model and corresponds to the validated translation of the demand into a particular “documentary” language. The concept of indicators used here is not dissimilar to that of performance indicators used in the dashboard of the decision maker. However, it differs in that an information indicator does not measure performance, but characterizes, by its attributes, a notion for an individual and at a given moment (“what Z understands by X…”). Nevertheless, the similarities with performance indicators are not negligible, as they synthesize information in a limited data set with a presentation chosen to correspond to the decision maker’s preferences. We will consider the information indicator as a meaningful document, the result of an element of information, a means of processing, or a method defined by attributes with observable and qualifiable properties and which may be evaluated in relation to an information demand formulated by the decision maker and analyzed in the light of stakes perceived by the watcher.
Several families of information indicators may be identified. The first, and most important, of these directly concerns the demand and is made up of “notional” information indicators. These indicators allow the description of key concepts associated with the demand and the characterization of notions used in breaking these concepts down by characteristics (which we will call “attributes”). We are therefore more interested in the particular meaning the decision maker gives to a term (the “notion”) than in the general meaning of the term (which is more strongly attached to the concept). As Grise highlights [GRI 96], there are two well-determined and complementary fields of knowledge: the field of conceptual structures and the field of notional structures. Conceptual knowledge, which leads to logically structured provisional truths, is that used by scientists. In this case, it refers to thought structures built from axioms with logical conclusions where natural language merely plays a supporting role. Notional knowledge is constructed through communications, without necessarily having recourse to scientific truths, but with interpretations from personal experience which are more or less likely to be accepted by other parties as relevant. Notional knowledge also stems from culturally and psychologically determined beliefs present in each individual. A notional information indicator therefore contains the subjectivity of meaning (of a term) accorded by the decision maker in the particular context of the problem.
The second family brings together methodological information indicators. It concerns procedural knowledge, which the watcher transforms into indicators, mainly to enable their reuse in the research process. Examples include particular requests, sources to use in relation to a given theme, hints and tips to use to obtain information more quickly and securely, and so on. A methodological information indicator therefore encapsulates a certain savoir faire possessed by the watcher, with the aim of reusing this knowledge in other situations and for other problems. This knowledge is mainly oriented toward information gathering, but may also concern the characterization of notional indicators or any other element of the model.
The last family of indicators concerns reporting and results and is used in analyzing both the results of scouting and the process as a whole. It may contain performance indicators, such as a measurement of the costs (temporal, financial, etc.) involved in a given research activity, and the quantification of use of a search engine or information bank or even an inventory of sources consulted, broken down by nature (human, internet, databases, etc.) for the current problem. This may also consist of identifying a certain number of “quality” indicators referring to the process, for example, the time spent on research, financial cost of the information sources used or the number of requests carried out, fulfilled information demands, rejected documents, and so on, over a given period.
The characterization of (notional) <Indicators> is a two-step process. First, the watcher identifies the “titles” of these indicators and then creates a list of <Attributes> used in their definition. This list is presented to the decision maker for validation or rejection of various attributes. Second, the watcher, using an information-gathering process, assigns different <Values> to those attributes chosen for use.
The <Attribute> element collection contains different characteristics of notions linked to the decision maker’s demand. For example, a competitor may be defined by looking for the name of its director, geographic location, sales figures, and sector of activity in a particular problem. In another case, information on partners and the number of patents obtained will be the determining factor. Each attribute has a status (validated, not validated, to be validated), a description, a type, an origin, and a priority level.
Each attribute can have one or more <Values>. These values generally take the form of information extracted from documents. For example, to assign a value to the attribute “sales”, the watcher must look for this information for each identified competitor in various sources. These sources must be identified, and then the relevant information must be found and extracted from the source document(s). Sources should be compared if the data given are different, and the chosen value must then be assigned to the corresponding attribute. This research thus creates a certain number of research problems linked to the value assignment process. Each <Value> element, like <Attribute> elements, has a title, a status, a description, and a link to the document(s) in which it was found.
1.4.6. Elements of research problems
The elements of the <Research Problem> collection cover the research activity of the watcher in its entirety, from the explicit formulation of <Research Aims> to the extraction of <Information> from <Documents>. In the WISP model, the research problem is set apart from the research and information practices of the watcher. These practices (Figure 1.8) include the collection of data, mainly concerning different elements of the model and directly accessible data. At the end of this collection activity, the real information-gathering stage begins, involving an initial hunt for clues to define titles and attributes of indicators, and a “problem” activity that consists of finding values for these attributes.
Before beginning research, the watcher is invited to formulate his/her intentions, that is, to provide an expression of the research process in natural language. This explicit formulation of the research aims is another particularity of our model. This expression of aims gives meaning to the strategies used in its fulfillment (requests, surveys, database searches, etc.) and to the selection of documents to use. As Hameline [HAM 79] points out, for a research intention to become operational, “its content must be expressed as unequivocally as possible”. The goal of this formulation of aims is to remove ambiguities, to provide explicit characterization of the object of the research, and to define requirements expressed through constraints.
Figure 1.8. Watcher information practices

The <Research Object> element contains different objects sought after by the watcher. More often than not, this concerns a specific piece of information or the object containing this information (or an information network). To continue using the previous example, to provide a value for the attribute “sales”, the research object may be “the sales figures of competitor X”, but also “the register of commerce”, “a telephone number for Paul (a college friend who works for X)”, “open-access financial portals”, “issue Y of review Z”, and so on. All these objects will be connected to this attribute and will produce a corresponding number of research problems. We can therefore find problems and solutions that overlap, responding to intermediate goals, themselves defined by subaims but all generated to respond to one single goal: to find a value for the attribute concerned.
The <Predicate> is the predicative verb in the formulated aim. Given that aims are expressed following the structure “I want to <Predicate> + article + <Research Object>…”, the predicative verb is always used in the infinitive. Examples of this include “define”, “find”, “consult”, “question”, “compare”, “know”, “check”, and so on. The main interest of this is that these verbs are transitive and directly introduce the object of the research. The use of a particular verb may also lead to the acquisition of information by inference through retrospective analysis of the process. For example, “find” implies that the watcher is already aware of the existence of a piece of information; “check” suggests that the watcher already possesses the information but wants to check it against new facts or validate it. “Define” might suggest that the watcher already has vague knowledge of the object but requires clarification to avoid erroneous interpretation, for example.
Each objective may contain one or more <Constraints>. A <Constraint> element has a title and a type which define its nature. For example, we might find quantitative constraints (e.g. at least one, a maximum, more than 10), qualitative constraints (validated information, free source, etc.), or temporal constraints (time taken <1 h, before date T, etc.). These constraints are those imposed by the watcher in relation to the research problem or problems and are not attached to the information demand, although there may be a cause-and-effect relationship between the information demand and the constraints.
Following the formulation of aims, the watcher implements strategies to respond to these aims. These strategies are contained in the <Solution Hypothesis> element collection. Then, depending on the <Source>, <Tool>, and <Method> used, the watcher will obtain a collection of <Documents> which may or may not demand further attention. If the required information is found in the document, it is attached to the <Information> element. The registration of these documents and of the actions carried out using them (such as information extraction, annotations, or following hypertext links) may be done using computer-based tools for automation, extraction, and content management.
The information taken from the document will then be attached to the attribute of the corresponding indicator as a value. In this way, it becomes possible that a piece of information discovered (by serendipity or zemblanity) while looking for other information may be linked to the correct indicator at any time. In any case, we obtain “cognitive traceability” [KIS 07, KIS 09] and physical traceability of the element of information, from its extraction via the origins of the research up to the decision problem that justified its selection (Figure 1.9).
Figure 1.9. Cognitive and physical traceability of information

This traceability provides a number of access points for documents and information and, by its very existence, gives meaning to the nature of these links.
1.4.7. Analysis and presentation of results
At the end of the research process, we find the two last element collections of the model.
The <Result> element contains the results produced by scouting, presented in a way specified at the time the demand was made. This parameter will therefore be specified from the earliest formulations so that the information may be presented in the most suitable way possible, enabling easy interpretation and allowing the decision maker to make a decision. The solution to the information problem may take the form of an overview report, a contingency table, a series of histograms and various graphics, or a list produced by extracting certain elements of the model, presented in a more or less detailed manner.
In this model, we distinguish between two different forms of analysis: the analysis carried out on the results of the scouting process, produced by the decision maker with assistance from experts in the domain(s) concerned, and the analysis of the process itself presented in the form of reporting and result indicators. These two categories of analysis are associated with this element. However, if certain aspects of analysis are concerned essentially with the decision problem, it is best to include them in the <Decision Solutions> element instead. The <Analysis> element therefore contains both a collection of indicators (of performance, quality, etc.) and a link, which, like the <Result> element, directs the user toward one or more external documents containing the analytical reports.
1.4.8. Common parameters for all model elements
All elements of the model are dated and identified from the moment of their creation to allow users to refer to them at any point without ambiguity. Associated with a “date” parameter, it is thus possible to restitute an element in relation to another element or one part of the model in relation to a different part. The importance of chronology in identifying the order and succession of actions and events is therefore clear. The chronological record organizes events by data of occurrence, but also depending on the goals of the person responsible for creating the record. A chronology of the evolution of formulations, an overview of stakes and solutions, or the series of actions undertaken when processing documents would look different depending on whether the watcher or the decision maker created the chronology, for example. The use of these two parameters also allows this succession of facts and actions to be reviewed at a later date — as when reviewing the performance of an athlete or team captured on video — and gives a new understanding and unexpected knowledge of this succession.
In the same way, we may obtain a “paused” image giving access to all elements of a given moment: documents, information in the state in which it was found by the author, and information for recontextualization (what was the demand being processed? What was the company’s perception of the environment at that moment? What information was available when making a particular decision?) and to measure development from the past situation to the present moment. This viewpoint on temporal evolution is at the heart of competitive intelligence, as it promotes understanding of the past and feedback, activities that may be grouped together, using Bickford’s phrase, as “lessons learned” [BIC 00].
We have also chosen to harmonize element parameters that will, in the main, have a (type), an address (uri), a title or the contents of the element (text), a (description), and a (status).
1.4.9. Knowledge building through annotation
The use of annotations in the WISP model follows the methodological propositions set out in Explore, Query, Analyze, and Annotate (EQuA2te), developed by David et al. [DAV 03]. EQuA2te is a methodology developed for the exploration, analysis, and production of knowledge aimed principally at decision makers, and it aims to facilitate management and exploitation of a base of strategic data linked to a knowledge base concerning the system user. In this way, it covers the means used to give the decision maker the ability to explore, query, analyze, and annotate this knowledge base, built around previous personal activities. However, the same principle may be applied to the watcher who may also be confronted with (research) problems similar to others encountered in the past, which may be adapted to help with the current problem. Furthermore, knowledge production can surpass the factual and methodological aspects of research and apply to the whole competitive intelligence process. For this reason, we have planned for annotation of the scouting process itself as well as its results.
In the WISP model, the <Annotation> element is an independent element that may be inserted into any other element of the model. The defining characteristic of an annotation is the fact of being “anchored” (a link known as “uri” in our model) to a portion of the target document (structural text zone, word or group of words, image, etc.). If the model itself becomes a document, as is the case here, we can insert an annotation anywhere in the document; we must simply provide the element ID as the target of the annotation. The <Annotation> element contains the same parameters as the other elements of the model. We have, however, added a “rights” parameter to authorize or limit visibility of annotations for specific groups or categories of actors.
Using annotation, which promotes the production and exchange of knowledge, the model itself, through the process it represents, becomes a basis for communication and collaboration between the watcher and the decision maker. This support allows the two actors to “know what is really happening”, thanks to scenarization of the competitive intelligence process. This contributes to the analysis of anomalies and incidents, the search for causes and consequences, and the definition of the means of correction and improvement. This formalization of the process assists the development of experience management within the company and provides a favorable environment for the creation and capitalization of knowledge based on this experience.
1.5. Conclusion: toward flexibility in the model
As with any model, this model is designed to be modified. As in cartography, it constitutes a “map” of elements and is used for orientation and progress; however, it also needs to be adapted to the stride and way of walking of the user, like a pair of shoes. Furthermore, as Korzybski states, “a map is not the territory” [KOR 98]. A model may be useful in understanding and outlining the space (or territory) of a decision problem, but it is not, nor will it ever be, universal in nature. In the same way that the demand is not the same thing as the need, the model is conditioned by the perceptions of the designer and is simply a material to be adopted and adapted by each user, who models it for their own usage and using their own representations.
The WISP model, which we have presented in this chapter, is based on two fundamental hypotheses:
– The decision maker must be convinced of the benefits of their information request and be certain that the information produced will not create a problem larger than that which he/she has to solve.
– The decision maker must be certain that the time invested in discussion with the watcher and, mostly, in discussions based on the reformulation of demands, the expression of stakes, and the definition of indicators will allow optimization of the research process and thus, in the long term, save time.
Throughout the testing of this model, we have noticed that in cases where these two hypotheses were fulfilled and as the information needs of the decision maker were better known and recognized, there was more scope for revision, free expression, and demonstrations of trust. However, the formulation of research aims for the watcher is based on new practices, requiring a learning process and solid collaboration based on confidence and on recognized and shared capabilities.
1.6. Bibliography
[BIC 00] BICKFORD J., “Sharing lessons learned in the Department of Energy”, AAAI-00 Intelligent Lessons Learned Systems Workshop, Austin, Texas, USA, 31 July 2000.
[BOU 04] BOUAKA N., Développement d’un modèle pour l’explicitation d’un problème décisionnel: un outil d’aide à la décision dans un contexte d’intelligence économique, Thesis in ICT, University of Nancy 2, Nancy, December 2004.
[DAU 82] DAUGHERTY W.E., “Origin of Psyop Terminology”, in MACLAURIN R.D. (ed.), Military Propoganda: Psychological Warfare and Operations, Praeger Publishers, New York, p. 257, 1982.
[DAV 03] DAVID A., THIERY O., “L’Architecture EQuA2te et son application à l’intelligence économique”, Proceedings of the Conference “Intelligence Économique: Rechercheset Applications”, Nancy, France, April 2003.
[END 00] ENDSLEY M.R., GARLAND D.J., Situation Awareness Analysis and Measurement, LEA, Mahwah, NJ, USA, 2000.
[GRI 96] GRISE J.B., Logique et langage, Ophrys, Paris, 1996.
[HAM 79] HAMELINE D., Les Objectifs pédagogiques en Formation Initiale et Continue, ESF, Paris, 1979.
[HER 99] HERMANN N., The Creative Brain, Atlantic Books, New York, 1999.
[KIS 07] KISLIN P., Modélisation du problème informationnel du veilleur dans la démarche d’intelligence économique, Thesis in ICT, University of Nancy 2, Nancy, November 2007.
[KIS 09] KISLIN P., “Tracer, Annoter et Mémoriser: Trois Actions pour Asseoir la Collaboration-Confiance du Veilleur et du Décideur”, Actes de VSST’2009, Nancy, France, 2009.
[KOR 98] KORZYBSKI A., Une carte n’est pas le territoire: prolégomènes aux systèmes non-aristotéliciens et à la sémantique générale, Editions de l’éclat, Paris, 1998.
[NOU 02] NOUVEL P., Enquête sur le concept de modèle, Collection Science, Histoire et Société, PUF, Paris, 2002.
[PIC 06] PICARD D., MARC E., Petit traité des conflits ordinaires, Le Seuil, Paris, 2006.
[ROY 85] ROY B., Méthodologie multicritère d’aide à la décision, Economica, Paris, 1985.
[SAL 02] SALOMÉ J., Jamais seuls ensemble: Comment vivre à deux en restant différents, Editions de l’Homme, Paris, October 2002.
[TER 05] TERRASSE M.N., SAVONNET M., LECLERCQ E., GRISON T., BECKER G., “Points de vue croisés sur les notions de modèle et métamodèle”, IDM’2005, Paris, France, 30 June 2005.
[THO 03] THOM R., “Stabilité Structurelle et Morphogénèse: Essai d’une théorie générale des modèles”, in Thom R., Bompard-Porte M. (dir.), Œuvres complètes, CD-ROM, IHES, Bures-sur-Yvette, March 2003.
[VAL 77] VALÉRY P., Cahiers, NRF, Paris, 1977.
1 Chapter written by Philippe KISLIN.
1 For example, the two models developed by the SITE-LORIA team, namely MEPD and WISP [BOU 04, KIS 07].