
Chapter 14
Modularity
I just dropped a 1,500-year-old Maya ceramic.
It was already mostly broken…but the sinking feeling in my heart was indescribable. Beneath the giant palapa (open thatched hut) at the Martz farm just south of Benque Viejo del Carmen, a carefully choreographed archaeological dance of sorts had been underway for several hours.
Minanhá, Belize. The Late Classic Maya city center situated between Xunantunich and Caracol was little more than unceremonious piles of rubble amid the milpa (terraced fields of maize and beans), but the dig site would be the summer home of our expedition.
We surveyed and mapped hillsides, selected dig sites, and forged ephemeral canopies from palm fronds to protect us from the tropical sun and our excavations from the tropical downpours.
By day, the dig—excavating for hours, measuring, photographing, sketching, and slowly excising the hillside. Tiny trowels and pickaxes delicately chipping away at the past. Balancing soil on large screens, we sifted dirt from potsherds, from bone, from Belizean bugs, from bottles. If you ever find an empty bottle of One Barrel rum at the bottom of your dig, you've wasted hours if not days of effort—it's the telltale sign that the site has been excavated and subsequently filled in.
By night, the dance—the giant palapa aglow with the flicker of kerosene, a mix of frenetic yet coordinated activity as the day's plunder was brushed, washed, rinsed, photographed, typed, documented, and bagged for transport back to labs in the United States.
Everyone had a role. Several washers whisked dirt from potsherds, dunking these in a series of successively cleaner buckets of water.
In another corner sat the archaeologists, carefully examining and “typing” potsherds and the occasional bone fragments or carved stone.
But the runners facilitated the entire operation, transporting raw materials to the washers, washed potsherds to drying racks, dried pieces to the archaeologists, and a seemingly endless supply of One Barrel rum to glass Coke bottles strewn about the landscape.

The choreographed scene at the Martz farm required tremendous communication, cooperation, and coordination, remarkably similar to that required in modular software design. Everyone had a specific function, which produced assembly-line efficiency while reducing confusion. Software modularity similarly prescribes that individual modules be functionally discrete—that is, they should do one and only one thing.
Not only were our responsibilities specialized, but our interaction with each other was limited. For example, the runner brought me dirty ceramics (and rum) and transported my cleaned ceramics to drying racks, allowing me to focus on work and preventing me from stumbling into someone else's space. Modular software should also be loosely coupled, in that modules are linked to each other through only limited, prescribed methods.
By specializing only in brushing, washing, and rinsing ceramics, I became the master of my domain. And, if the archaeologists wanted to validate or test my performance, they could do so with ease because I had few responsibilities and because those responsibilities were not entangled with those of my peers. Software similarly is significantly easier to test and validate when modules are both functionally discrete and loosely coupled.
Not only were our roles clearly defined, but our communication routes were also specified. The rum runner who gathered bags of debris for us to wash was constantly bounding in and out of the palapa, but primarily interacted with washers at the palapa entrance. I knew precisely where he would drop the ceramics, precisely where to leave my empty Coke bottle for refills, and precisely where he expected to pick up my cleaned ceramics. Modular software is also improved when data and parameters are passed through precise methods to child processes, and when return codes are precisely passed back to parent processes.
But the dance could all be thrown into confusion when our roles were changed. For example, when I was doubling as a rum runner, I had to learn what artifacts I was carrying to which people, where to place them, and how not to collide with others in the palapa. And, when you're stumbling in the wrong place at the wrong time—that's when really old things get dropped and obliterated. Software modularity similarly facilitates security by prescribing rules and modes of communication that guide successful software execution.
DEFINING MODULARITY
Modularity is “the degree to which a system or computer program is composed of discrete components such that a change to one component has minimal impact on other components.”1 Software modules are often said to be functionally discrete and loosely coupled. Functionally discrete describes modules that are typically organized by function and that should perform one and only one function. Loosely coupled describes modules that should interact with each other and with software in very limited, prescribed ways.
A third attribute often ascribed to modular programming is encapsulation, “a software development technique that consists of isolating a system function or a set of data and operations on those data within a module and providing precise specifications for the module.”2 Encapsulation facilitates secure software by ensuring that data and information inside a module do not unintentionally leak beyond the module and that extraneous, external information does not unintentionally contaminate the module. While modularity is much more common in (and beneficial to) object-oriented programming (OOP) third-generation languages (3GLs) that utilize classes and structures, procedural fourth-generation languages (4GLs) like Base SAS can achieve higher quality software when modular design is embraced.
This chapter introduces modularity through SAS software examples that are functionally discrete, loosely coupled, and encapsulated. These core concepts are repeatedly referenced throughout this text, demonstrating the benefits of modular design to various dimensions of quality. chapter 7, “Execution Efficiency,” and chapter 12, “Automation,” demonstrate SAS parallel processing paradigms that can be operationalized only through modular software design.
FROM MONOLITHIC TO MODULAR
As discussed in the “Preface,” data analytic software typically serves a very different purpose from more traditional, user-focused software applications. Applications tend to be interactive; the experience is often driven by variability provided through user input. Data analytic software applications are instead driven by data variability, as data transit one or more transformations or analyses. These two very different software objectives have led to a stark divergence in software design between data analytic and other software. While object-oriented, user-focused applications have evolved into increasingly modular design over the past few decades, data analytic software design has remained predominantly monolithic, espousing behemoth programs that are read from the first line to the last like a novel.
Much of the functionality required by data analytic software does require serialized processing that occurs in prescribed, ordered steps. For example, a data set is ingested, transformed, and subsequently analyzed in rigidly ordered steps. However, because software quality entails delivering not only functionality but also performance, modular software design can often be incorporated into performance-focused aspects of data analytic software. For example, a quality control mechanism to detect data set availability and validity—thereby improving performance—could be built modularly and reused by a number of unrelated SAS programs. Developers accustomed to serialized data analytic software, however, often persist in monolithic design habits even when incorporating performance characteristics that could be modularized. Software quality can often be improved when SAS practitioners embrace modular design, as demonstrated throughout this chapter.
Monolithic Software
Monolithic is derived from the Greek words meaning single stone (monos + lithos). Monolithic software describes a behemoth, single-program software product; unfortunately, this is a software design model prevalent in Base SAS and other data analytic development languages. The disadvantages of monolithic software are numerous. Code complexity increases while readability diminishes. Code maintenance is made more difficult and less efficient, because only one developer can modify software at one time. Monolithic software often performs more slowly due to false dependencies, a disadvantage demonstrated in the “False Dependencies” sections in chapter 7, “Execution Efficiency.”
However, the monolithic nature of SAS software design is not without reason. As data processes typically have prerequisites, dependencies, inputs, and outputs, these elements establish a natural precedence of processes from which program flow cannot deviate. For example, the transitive property states that if A is less than B, and B is less than C, then A is also less than C. Similarly, within extract-transform-load (ETL) software, if transformation must precede analysis, and ingestion must precede transformation, then ingestion also must precede analysis, thus prescribing serialized program flow. As demonstrated in Figure 14.1, the transitive property is the reason that the functionality within data analytic software tends to be serialized.
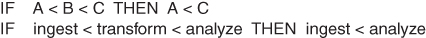
Figure 14.1 Transitive Property of Data Analytic Software
The program flow in Figure 14.1 is typical of serialized ETL processes that are sequenced by function and can be simulated with the following code:
libname perm 'c:perm';
* ingestion;
data perm.raw;
length char1 $10;
char1='burrito';
run;
* transformation;
data perm.trans;
set perm.raw;
char1=upcase(char1);
run;
* analysis;
proc means data=perm.trans;
by char1;
run;This serialization is critical in data analytic development because it provides necessary security and data integrity. Data pedigree can be easily traced from ingestion through transformation to ultimate analysis, providing confidence in analytic products. For example, data that are analyzed can be trusted in part because they must first pass through the Transformation module before analysis can begin. In essence, in data analytic development, there is no “Advance to Go” card and you don't collect $200 until you've earned it.
Because functional prerequisites and inputs cannot be altered, SAS software is often written as a monolithic program that can be read sequentially, from the first line to the last. I recall when I was young in my SAS career, proudly demonstrating a SAS program to a coworker when it had surpassed 2,000 lines. We actually relished writing those behemoth beauties, because every process was self-contained in one program. Scroll up, scroll down, scroll anywhere and the consummate functionality was described in one place. Although we were seated together and supporting a shared mission, my team and I wrote code in silos, rarely interacting with the software that others had developed. Despite sharing some functional and performance endeavors—such as processes that ingested the same data sets or which performed identical quality assurance tasks—our respective programs shared no actual code in common, an unfortunate but all-too-common consequence of monolithic design in end-user development environments.
While functional components in data analytic software often do have prerequisites and inputs that necessitate sequential program flow, when examined more closely, isolated functional and performance objectives can often be extracted and extrapolated elsewhere. For example, from a distance, an ETL process might seem wholly unique, contributing to monolithic design in which serialized code is neither shared nor reused. However, up close, shared objectives such as validating the existence of a data set (before use) or deleting the contents of the WORK library can be generalized. By modularizing these aspects of software, multiple modules or programs can benefit from reusable functionality and performance. In some cases, modular design can even enable modules to run in parallel, thus facilitating faster software.
Modular Software
Modular software design separates software components into discrete modules and is standard design practice within OOP languages and their software products. At a high level, modular design somewhat mimics the user experience when interacting with traditional user-focused applications. For example, when Microsoft Word is opened, you immediately have thousands of options—start typing in the blank document space; open a saved document; modify the margins, font, or format; or myriad other activities. As the application has evolved over time, not only has the functionality continued to increase, but specific functions can be accessed through numerous modalities.
For example, to bold text, you can highlight the text and use the <CTRL><B> keyboard shortcut, right-click the text and select the B icon, select the B icon from the ribbon header, click the <Home> tab and click the B icon, or type <ALT><H><1>. With so many ways to reach the bold function, it's imperative that each method lead to identical functionality. Modular software design capitalizes on this versatility, by calling the same “bold” function by each of these respective methods.
While the mechanics of modular software design within OOP are significantly more complex than this representation, this high-level view demonstrates the multi-directionality endemic within user-focused applications, which contributes to modular design. Data analytic software will never be able to fully escape the clutches of sequential software design—nor do we want it to. Where functional necessity prescribes process sequencing, this orderly program flow facilitates security and data integrity and should never be condemned. After all, as demonstrated in Figure 14.1, it's impossible to analyze data before you've ingested them. However, even when functionality must be sequenced, the adoption of modular design can ensure that software is more readable, reusable, testable, and ultimately more maintainable. And, where more generalizable functionality and performance are required, modular components can be more readily implemented to support a larger swath of software.
MODULARITY PRINCIPLES
The SAS® 9.4 Macro Language, Second Edition, recommends that users “develop your macros using a modular, layered approach” both to reduce software defects and to improve the ease with which defects can be discovered.3 The documentation goes on to recommend modular development, stating “instead of writing one massive program, develop it piece by piece, test each piece separately, and put the pieces together.” This introduction to modularity speaks to its role in facilitating greater software maintainability, readability, and testability. The benefits of modular design, however, are much greater and are described throughout this chapter.
In SAS software development, SAS macros are commonly referred to or conceptualized as modules. While this can be true, not all SAS macros espouse modular software design, and in fact monolithic software can just as easily be developed with SAS macros as without them. Modular software design principles state that software should be:
- Functionally discrete—A software module performs one and only one function.
- Loosely coupled—A software module directly interacts with other modules in as few ways as possible.
- Encapsulated—A barrier protects the software module and the rest of the software from unintended interaction with each other.
While the size of software modules is not typically included as a defining characteristic of modularity, software modules are inherently much smaller because they are functionally discrete, loosely coupled, and encapsulated. Some more anecdotal references to modularity define modules as the quantity of code that can fit on one screen—about 20 to 40 lines, depending on font size, screen size, and resolution. Thus, while the aim of building functionally discrete code is to increase flexibility and reusability, this practice also results in significantly smaller segments of code.
Loose coupling and encapsulation are similar, and some texts even describe them synonymously. The presence of one often does signify the presence of the other, but their objectives and thus methods do differ. The primary goal of loose coupling is to facilitate flexibility, principally by severing unnecessary bonds between parent and child processes. A child will always depend on some parent because it must be invoked from somewhere, but loose coupling seeks to ensure that the child can be invoked from as many parents as possible in as many appropriate ways as possible. For example, a module that capitalizes all text in a data set could be flexibly designed so that the transformation could be performed dynamically on any data set with any quantity of variables. This flexibility is demonstrated in the %GOBIG macro in the following “Functionally Discrete” sections.
On the other hand, the primary goal of encapsulation is to facilitate software security through what is commonly referred to as black-box design. In the analogy, a black box is sometimes implemented to protect the confidentiality of information, methods, or actions that occur inside a child process, but more often is implemented to protect the integrity of the child, its parent, the software, and possibly the software environment. For example, transient information inside a module that is required to produce some result but not required to accompany that result should be locally defined so it cannot interact with other aspects of the software. For example, if a counter is required to produce some result within a macro, but the counter value itself has no importance outside the macro after process completion, then the counter should be locally defined and restricted only to the module. Thus, encapsulation can be conceptualized as the black box placed around a software module while loose coupling is the tiny pinhole in the box through which information can be transmitted through prescribed channels.
Functionally Discrete
That software modules should do one and only one thing runs counter to the common practice of shoving as much functionality as possible into a single DATA step. After all, why do in two DATA steps what you can accomplish in one? In general, DATA steps should not be broken apart, as this unnecessarily decreases both execution speed and efficiency. In part due to the fixed costs of input/output (I/O) operations that read and/or write observations, DATA steps that do more are always more efficient than those that do less. Thus, to be clear, hacking up a DATA step into bits will make it smaller but won't demonstrate modular design. In Base SAS, functionally discrete code typically refers to SAS macro language modules that improve software functionality and performance.
Novel Code
Novice coders write novel code—that is, code that reads cover to cover like a novel, from the first DATA step to the final RUN statement. As mentioned in the “Monolithic Software” section, serialized design is expected and unavoidable when data analytic processes must be sequenced due to prerequisites and inputs. However, SAS practitioners can be so accustomed to designing and developing monolithically that they fail to perceive opportunities where modular design would improve program flow or static performance attributes.
The following code simulates monolithic ETL software saved as a single program but conceptualized as three functional modules:
libname perm 'c:perm';
* ingestion;
data perm.raw;
length char1 $10 num1 8;
char1='burrito';
num1=443;
run;
* analysis 1;
proc means data=perm.raw;
by char1;
run;
*analysis 2;
proc freq data=perm.raw;
tables num1;
run;In some cases, this long-windedness is unavoidable and separating data processes into discrete modules—that is, separate programs—would not benefit dynamic or static performance. For example, the following attempt to modularize the ETL code does create a series of macros but provides no improved performance:
libname perm 'c:perm';
* ingestion;
%macro ingest();
data perm.raw;
length char1 $10 num1 8;
char1='burrito';
num1=443;
run;
%mend;
* analysis 1;
%macro anal1();
proc means data=perm.raw;
by char1;
run;
%mend;
* analysis 2;
%macro anal2();
proc freq data=perm.raw;
tables num1;
run;
%mend;
%ingest;
%anal1;
%anal2;All code is still contained inside a single program and that program demonstrates sequential processing of all steps. Nothing has changed except that the complexity of the software has increased due to unnecessary macro definitions and invocations. Faux modularity is often observed in SAS software because certain macro statements, such as %IF–%THEN–%ELSE conditional logic, are viable only inside the confines of a macro. Software may appear to be broken into discrete chunks of functionality, but these delineations are often created only so that macro statements and logic can be utilized.
In this example, both analytic modules could in theory be run in parallel to increase performance. As demonstrated in the “False Dependencies” section in chapter 7, “Execution Efficiency,” because the MEANS and FREQ procedures each require only a shared file lock on the data set, they can be executed simultaneously. The advantages of modularity cannot be realized until monolithic code is conceptualized not as a single entity but rather as discrete functional elements. Through functional decomposition, demonstrated in the “Functional Decomposition” section later in the chapter, this code embarks on its journey toward modularity.
Overly Complex Code
Whereas SAS practitioners should try to cram as much functionality as possible into every DATA step, this data management best practice does not translate to modular design. And that's okay! If you can ingest, clean, and transform your data in a single DATA step, there's no reason to arbitrarily kill one bird with three stones—keep the single DATA step. But certain functionality required in ingesting, cleaning, and transforming data can often be generalized to other software and thus can benefit through modularization and reuse.
The following %GOBIG macro, which appears in the “Flexibility” section in chapter 18, “Reusability,” dynamically capitalizes all character variables in a data set:
%macro gobig(dsnin= /* old data set in LIB.DSN or DSN format */,
dsnout= /* updated data set in LIB.DSN or DSN format */);
%local dsid;
%local vars;
%local vartype;
%local varlist;
%local i;
%let varlist=;
%let dsid=%sysfunc(open(&dsnin,i));
%let vars=%sysfunc(attrn(&dsid, nvars));
%do i=1 %to &vars;
%let vartype=%sysfunc(vartype(&dsid,&i));
%if &vartype=C %then %let varlist=&varlist %sysfunc(varname(&dsid,&i));
%end;
%let close=%sysfunc(close(&dsid));
%put VARLIST: &varlist;
data &dsnout;
set &dsnin;
%let i=1;
%do %while(%length(%scan(&varlist,&i,,S))>1);
%scan(&varlist,&i,,S)=upcase(%scan(&varlist,&i,,S));
%let i=%eval(&i+1);
%end;
run;
%mend;When the following code is executed, a new Uppersample data set is created, and the values sas and rules become SAS and RULES!, respectively:
data sample;
length char1 $10 char2 $10;
char1='sas';
char2='rules!';
run;
%gobig(dsnin=sample, dsnout=uppersample);The dynamic macro capitalizes values in all text variables and can be implemented on any data set. However, the code is not functionally discrete and, as demonstrated later in the “Loosely Coupled” sections, it unfortunately is highly coupled.
The single functional requirement of the module is to capitalize the values of all text variables within a data set dynamically. And, in a nontechnical sense, this is what the end user perceives as the functional outcome. For example, when I hit <CTRL><B> in Microsoft Word, the characters I've highlighted are made bold—a single functional outcome. However, behind the scenes, the software must assess whether I'm turning off or turning on the bold and whether I've highlighted text or want to affect the cursor and subsequent text I'm about to type. Thus, despite having a single functional outcome, a functional requirement will often have numerous functional and performance objectives subsumed within it that are inherently required.
The %GOBIG macro could still be segmented more granularly. The first function performed opens a stream to the data set, retrieves the number of variables, and makes a comma-delimited list of character variable names. In modular software design, this functionality alone should be represented in a separate macro saved as a separate SAS program. The next function dynamically generates code that capitalizes the values, but the code is unfortunately wrapped inside a DATA step, decreasing reusability and violating the loose coupling principle of modular design. Thus, while the code may have only one functional requirement, other implicit functionality may be required to achieve that goal. The next section demonstrates functional decomposition, which aims to separate monolithic software and overly complex macros into true discrete functionality.
Functional Decomposition
Functional decomposition describes identifying separate functions that software performs, including both functionality explicitly described in technical requirements and functionality implicitly required to meet those objectives. In some cases, functional decomposition is a theoretical exercise and occurs during planning and design before any code has been written. This thought experiment involves decomposition of explicit software requirements to generate implicit tasks that will be required to achieve the necessary function and performance. In other cases, as described later, functional decomposition is the actual breakup of code into smaller chunks.
For example, the %GOBIG macro previously introduced in the “Overly Complex Code” section has a single functional requirement: create a macro that can dynamically capitalize the values of all character variables in any data set. However, during software planning and design, as SAS practitioners begin to conceptualize how this will occur, they functionally decompose the objective into additional functional steps required for success. If the software demands robustness, a first step might be to validate the existence and availability of the data set. A second step could be to create a space-delimited list of the character variables. A third step might be to exit with a return code if no character variables were found. A fourth step could be to generate lines of code dynamically that would capitalize the values with the UPCASE function.
After the thought experiment, it's clear that %GOBIG demonstrates diverse rather than discrete functionality. Developers might decide to coalesce some functions into a single module, while separating other functions into external macros that can be called from reusable macro programs. Thus, as a theoretical exercise, functional decomposition doesn't require software to be built modularly, but rather is intended only to identify distinct parts of composite software or requirements. Functional decomposition is extremely useful early in the SDLC because it enables future development work to be conceptualized, assigned, and scheduled based on overarching requirements. In project management, functional decomposition similarly describes breaking a project into discrete tasks that can be reconstituted to give a fuller perspective of the breadth and depth of the statement of work. Functional decomposition also often exposes unexpected process prerequisites and dependencies that can add complexity to software design—complexity that is much more welcome when discovered early in the SDLC than in the throes of development.
But in software development, functional decomposition does not represent only casual conversation and whiteboard diagramming; more than theory, functional decomposition is the literal cleaving of software into discrete chunks, typically saved as separate programs. For example, the ETL software demonstrated earlier in the “Novel Code” section was broken into three separate macros. However, because the macros were still confined to the same program, no performance gains could be experienced due to this limitation. The macro hinted at reusability, but the code would have had to have been cut-and-pasted into other software—and this only describes code extension or repurposing, not reuse.
During functional decomposition, the second identified implicit task of the %GOBIG requirement was to generate a space-delimited list of all character variables. The following %FINDVARS macro now performs that more specific task:
* creates a space-delimited macro variable VARLIST in data set DSN;
%macro findvars(dsn= /* data set in LIB.DSN or DSN format */,
type= /* ALL, CHAR, or NUM to retrieve those variable types */);
%local dsid;
%local vars;
%local vartype;
%global varlist;
%let varlist=;
%local i;
%let dsid=%sysfunc(open(&dsn,i));
%let vars=%sysfunc(attrn(&dsid, nvars));
%do i=1 %to &vars;
%let vartype=%sysfunc(vartype(&dsid,&i));
%if %upcase(&type)=ALL or (&vartype=N and %upcase(&type)=NUM) or
(&vartype=C and %upcase(&type)=CHAR) %then %do;
%let varlist=&varlist %sysfunc(varname(&dsid,&i));
%end;
%end;
%let close=%sysfunc(close(&dsid));
%mend;But wait, it actually does more! The developer realized that he could add one parameter and alter a single line of code to enable the macro not only to identify all character variable names, but also to identify either all numeric variable names or all variable names in general. With this additional functionality and its modular design, the %FINDVARS macro is a great candidate for inclusion in a reuse library to ensure that other SAS practitioners can benefit from its function and possibly later improve its performance.
For example, while modular, the %FINDVARS macro contains no exception handling, so it is susceptible to several easily identifiable threats. The data set might not exist or might be locked exclusively, both of which would cause the %SYSFUNC(OPEN) function to fail. This failure, however, would not be passed to the parent process because no return code exists. The code might also want to specify a unique return code if the macro is called to compile a list of character variables and none are found. Notwithstanding these vulnerabilities, additional performance can be added over time with ease when modules are managed within reuse libraries and reuse catalogs, discussed in the “Reuse Artifacts” sections in chapter 18, “Reusability.”
The %FINDVARS macro represents only the second of four implicit functions that were generated from the single functional requirement. The “Modularity” section in chapter 18, “Reusability,” demonstrates the entire modular solution that incorporates %FINDVARS into the %GOBIG macro. For a more robust solution, the “Exception Inheritance” section in chapter 6, “Robustness,” additionally demonstrates an exception handling framework that incorporates exception inheritance. In the next section, the second principle of modular design—loose coupling—is introduced and demonstrated.
Loosely Coupled
Loose coupling increases the flexibility of software modules by detaching them from other software elements. Detachment doesn't mean that modules cannot communicate, but requires that this communication must be limited, flexible, and occur only through prescribed channels. The most ubiquitous example of loose coupling (to SAS practitioners) is the structure prescribed through Base SAS procedures. For example, the SORT procedure is powerful and highly versatile but essentially requires parameters to function, which are conveyed as SORT procedure keywords or options.
The DATA parameter reflects the data set being sorted while the optional OUT parameter specifies the creation of an output data set. The BY parameter includes one or more variables by which the data set is to be sorted and other parameters can additionally modify the functionality of the SORT procedure. Thus, the only way to interact with SORT is through these prescribed parameters, and any deviation therefrom will produce a runtime error—the return code from the SORT procedure that informs the user that something is rotten in the state of Denmark.
Since software modules are often operationalized in Base SAS through SAS macros, limited coupling is enforced through parameters that are passed from a parent process to a child process. If the macro definition is inside the software that calls it, or if the %INCLUDE statement is used to reference an external macro saved as a SAS program, parameters are passed to the child process through the macro invocation. Or, when child processes represent external batch jobs that are spawned with the SYSTASK statement, all information necessary to execute that module must be passed through the SYSPARM parameter to the &SYSPARM automatic macro variable.
To provide another example, the International Space Station (ISS) was built through incremental, modular production and demonstrates loose coupling. Despite the prodigious size of some compartments, each connects only through designated ports, providing structural integrity while limiting the number of precision connections that must be manufactured on Earth and assembled in space. Because individual compartments were constructed by different countries, the connective ports had to be precise and predetermined so that they could be built separately yet joined seamlessly. This connectivity simulates the precision required when passing parameters to software modules.
Not only do ISS compartments have a limited number of ports through which they can connect, but also those ports had to be able to dock flexibly with both Russian Soyuz spacecraft as well as U.S. space shuttles. This flexibility (loose coupling) increased the usefulness and reuse of the ISS, because it could be accessed from multiple space vehicles and countries. Like the ISS, a software module that operates as child process similarly should be flexibly designed so that it can be called by as many processes and programs as possible that can benefit from its functionality. Loose coupling represents the modularity principle that can facilitate this objective.
Loosely Coupled Macros
Loose coupling is especially salient when modularity is achieved through SAS macro invocations as opposed to through SAS batch jobs that spawn new SAS sessions. When a new session is spawned, a SAS module runs with a clean slate—customized system options, global macro variables, library assignments, and other leftover attributes cannot influence the session, so it is more stable. However, when a module is invoked instead by calling a macro—whether defined in the program or defined externally and called with the %INCLUDE statement, the SAS Autocall Macro Facility, or the SAS Stored Compiled Macro Facility—that macro will always be susceptible to elements and environmental conditions in the current SAS session.
At the far end of the coupling spectrum are macros that are completely coupled. For example, the following %SORTME macro relies exclusively on attributes—the data set name and variable name—that are created in the program itself but not passed through the macro invocation. The macro walls, like a sieve, expect this information to percolate from the DATA step:
data mydata;
length char1 $15;
char1='chimichanga';
run;
%macro sortme();
%global sortme_RC;
proc sort data=mydata;
by char1;
run;
%if &syscc>0 %then %let sortme_RC=FAILURE!;
%mend;
%sortme;To decouple the %SORTME macro from the program, all dynamic attributes must be passed through parameters during the macro invocation:
%macro sortme(dsn= /* data set name in LIB.DSN format */,
var= /* BY variable by which to sort */);
proc sort data=&dsn;
by &var;
run;
%mend;
%sortme(dsn=mydata, var=char1);The macro can now be called from other SAS programs because it relies on no host-specific information from the program besides the parameters that are passed. However, the original macro also included exception handling that tested the global macro variable &SYSCC for warning or runtime errors, and this logic must also be decoupled. Macros are porous to global macro variables in a SAS session, even those belonging to irrelevant programs. To ensure %SORTME is not reliant on or contaminated by existent values of &SYSCC or &SORTME_RC, both of these macro variables must be initialized inside the macro:
%macro sortme(dsn= /* data set name in LIB.DSN format */,
var= /* BY variable by which to sort */);
%let syscc=0;
%global sortme_RC;
%let sortme_RC=GENERAL FAILURE;
proc sort data=&dsn;
by &var;
run;
%if &syscc=0 %then %let sortme_RC=;
%mend;
%sortme(dsn=mydata, var=char1);The %SORTME macro is now also decoupled from the global macro variables that it references. All information is passed to the macro through parameters, and from the macro through a single return code &SORTME_RC. The return code is initialized to GENERAL FAILURE so that an abrupt termination of the macro doesn't accidentally report a successful execution, a best practice discussed in the “Default to Failure” section in chapter 11, “Security.”
While the macro appears to be decoupled from the program, modifying the %SORTME macro invocation exposes another weakness. When the parameterized data set is changed from Mydata to PERM.Mydata, this now requires that the PERM library be available inside the macro. While the LIBNAME assignment for PERM may exist in the current SAS session, were the %SORTME macro saved as a SAS program and called as a batch job, the PERM library would not exist unless PERM were already globally defined through SAS metadata, the Autoexec.sas file, a configuration file, or other persistent method. This illustrates the importance of globally defining commonly used artifacts such as persistent SAS libraries and SAS formats.
Loosely Coupled Batch Jobs
Sometimes performance can be improved by replacing serialized program flow with invocations of batch jobs that can facilitate parallel processing and decreased execution time. Because macro variables cannot be passed to a batch job through macro parameters, all necessary information must be passed through the SYSPARM parameter of the SYSTASK statement. For example, the following program (parent process) now executes the Sortme.sas program as a batch job (child process):
libname perm 'c:perm';
data perm.mydata;
length char1 $15;
char1='chimichanga';
run;
%let dsn=perm.mydata;
%let var=char1;
systask command """%sysget(SASROOT)sas.exe"" -noterminal -nosplash -nostatuswin -noicon -sysparm ""&dsn &var"" -sysin ""c:permsortme.sas"" -log ""c:permsortme.log""" status=rc taskname=task;
waitfor _all_;
systask kill _all_;The following child process should be saved as C:permsortme.sas:
libname perm 'c:perm';
%let dsn=%scan(&sysparm,1,,S);
%let var=%scan(&sysparm,2,,S);
%macro sortme(dsn=,var=);
%let syscc=0;
%global sortme_RC;
%let sortme_RC=GENERAL FAILURE;
proc sort data=&dsn;
by &var;
run;
%if &syscc=0 %then %let sortme_RC=;
%mend;
%sortme(dsn=&dsn, var=&var);The PERM library must be assigned inside the child process so that the PERM.Mydata data set can be accessed. However, enabling the batch job to function with the current SYSTASK invocation doesn't guarantee success for later invocations that might reference different libraries. Recall that loose coupling in part is designed to ensure that a child process can be called from as many parents as possible who can utilize the functionality. Thus, a hardcoded solution like this is never recommended. Moreover, if SAS system options were specifically required in the batch process, this request also could not be passed from parent to child given the current paradigm.
To deliver the necessary functionality, the manner in which SYSPARM is passed and parsed must become more flexible. The following updated SYSPARM value will now be passed from the parent process via SYSTASK—hardcoded here for readability, but passed through SAS macro variables in the actual SYSTASK statement:
opt=mprint * lib=perm c:perm * dsn=perm.mydata * var=char1In this example, the asterisk is utilized to tokenize the SYSPARM parameters into individual parameters (tokens) and, within each token, the equal sign is utilized to further tokenize individual parameters into discrete elements. For example, OPT=MPRINT is first read, after which OPT is identified to represent the command to invoke the SAS OPTIONS statement, while MPRINT is identified as the specific option to invoke.
The updated parent process follows, with only the SYSPARM value modified:
libname perm 'c:perm';
data perm.mydata;
length char1 $15;
char1='chimichanga';
run;
%let dsn=perm.mydata;
%let var=char1;
systask command """%sysget(SASROOT)sas.exe"" -noterminal -nosplash -nostatuswin -noicon -sysparm ""opt=mprint * lib=perm c:perm * dsn=&dsn * var=&var"" -sysin ""c:permsortme.sas"" -log ""c:permsortme.log""" status=rc taskname=task;
waitfor _all_;
systask kill _all_;The updated child process, saved again as C:permsortme.sas, now includes an additional %PARSE_PARM macro that tokenizes and parses the &SYSPARM automatic macro variable:
%macro parse_parm();
%local tok;
%let i=1;
%do %while(%length(%scan(&sysparm,&i,*))>1);
%let tok=%scan(&sysparm,&i,*);
%if %upcase(%scan(&tok,1,=))=LIB %then %do;
libname %scan(%scan(&tok,2,=),1,,S) "%scan(%scan(&tok,2,=),2,,S)";
%end;
%else %if %upcase(%scan(&tok,1,=))=OPT %then %do;
options %scan(&tok,2,=);
%end;
%else %if %upcase(%scan(&tok,1,=))=DSN %then %do;
%global dsn;
%let dsn=%scan(&tok,2,=);
%end;
%else %if %upcase(%scan(&tok,1,=))=VAR %then %do;
%global var;
%let var=%scan(&tok,2,=);
%end;
%let i=%eval(&i+1);
%end;
%mend;
%parse_parm;
%macro sortme(dsn=,var=);
%let syscc=0;
%global sortme_RC;
%let sortme_RC=GENERAL FAILURE;
proc sort data=&dsn;
by &var;
run;
%if &syscc=0 %then %let sortme_RC=;
%mend;
%sortme(dsn=&dsn, var=&var);When the parent process executes and calls the Sortme.sas batch job, the %PARSE_PARM macro is able to assign one or more SAS libraries dynamically, ensuring not only that this parent process can pass the PERM library invocation, but also that additional, unspecified parents will be able to pass different library definitions. Although redundant (because the SYSTASK statement itself can specify SAS system options), the %PARSE_PARM macro can also recognize SAS system options and specify these with the OPTIONS statement. Finally, the macro variables &DSN and &VAR that represent the data set name and BY variable, respectively, are also still passed via SYSPARM, albeit in a more flexible form.
This type of dynamism may seem gratuitous and, for many intents and purposes, the added code complexity (inasmuch as time spent designing, developing, and testing a solution) may not provide sufficient business value to warrant its inclusion. Notwithstanding, software that truly demands loose coupling to support development and reuse of independent modules will require this extensive decoupling if modules are intended to be saved as separate SAS programs and executed as batch jobs.
To improve readability in this example, no exception handling is provided; however, in production software, all parameters should be validated and, with each successive level of tokenization, additional exception handling should prescribe program flow when exceptional values are encountered. Exception handling techniques are demonstrated throughout chapter 6, “Robustness,” and the validation of macro parameters and return codes is discussed in the “Macro Validation” sections in chapter 11, “Security.”
Passing SAS Global Macro Variables
Passing a global macro variable through a SAS macro invocation may seem uncanny, but it's one of the final indicators of loosely coupled code. For example, the following code creates PERM.Mydata, then prints the data set using a title supplied through the global macro variable &TIT1:
libname perm 'c:perm';
%let tit1=Mmmmm Mexican food;
data perm.mydata;
length char1 $15;
char1='chimichanga';
run;
proc print data=perm.mydata;
title "&tit1";
run;The PRINT procedure simulates a more complex process, so, espousing modular design, a SAS practitioner might wrap this functionality inside a macro module:
%macro print(dsn= /* data set name in LIB.DSN format */);
proc print data=&dsn;
title "&tit1";
run;
%mend;
%print(dsn=perm.mydata);The %PRINT macro can now be both defined and invoked in the same program, or the %PRINT macro could be saved as a separate SAS program so that it can be utilized by other parent processes as well. This second usage, however, exposes the vulnerability that the global macro variable &TIT1, while defined in this parent process, is not necessarily defined in other parent processes. Thus, as demonstrated in the following code, loose coupling necessitates that even global macro variables be explicitly passed through macro parameters:
%macro print(dsn= /* data set name in LIB.DSN format */,
title1= /* title */);
proc print data=&dsn;
title "&title1";
run;
%mend;
%print(dsn=perm.mydata, title1=&tit1);Although this additional effort may seem redundant, it is necessary to ensure loose coupling. Because loose coupling represents the tiny pinhole in black-box design through which all interaction with a module must be prescribed and limited, if %PRINT is receiving information directly from global macro variables (in lieu of being appropriately passed parameters), the integrity of the macro is compromised. Moreover, the revised %PRINT macro can now be saved as a SAS program and called by a subsequent, independent parent process which will easily be able to identify the necessity to pass the parameter TITLE1 due to its presence in the macro definition.
Encapsulated
The objectives of loose coupling and encapsulation are similar, as well as many of the techniques used to achieve them. However, encapsulation focuses on facets of security—including confidentiality and integrity, aiming to protect modules as well as the larger body of software. Loose coupling, on the other hand, focuses on software and module flexibility, seeking to ensure that modules can be reused in as many ways and by as many processes as possible. In general, because of the overlap between these two objectives, they are often achieved in tandem.
Every surface has two sides, so in the black-box analogy that represents an encapsulated module, dual roles of encapsulation exist. The interior surface of the box aims to prevent the module from harming the parent process that called it or its software while the exterior surface aims to prevent the parent process and its software environment from harming the module. Because SAS global macro variables can unfortunately pass freely in and out of black boxes, they are often a focus of encapsulation discussions. The encapsulation of macro variables is further discussed and demonstrated in the “Macro Encapsulation” section in chapter 11, “Security.”
Encapsulating Parents
The first test for software encapsulation is to run software from a fresh SAS session in which no code has been executed. Because modified SAS system options, global macro variables, WORK library data sets, open file streams, and locked data sets can all persist until a SAS session is terminated, only a clean slate can ensure a stable, consistent, uncontaminated environment. This freshness is one of the primary benefits of spawning SAS batch jobs, which execute in new SAS sessions.
It's critical that all global macro variables be uniquely named to avoid confusion, collisions, and corruption. Confusion results when software readability is diminished because of similarly named variables or, in some cases, reuse of macro variable names. Collision and corruption can occur when macro variable names are not unique and interact in unexpected ways. For example, the following code initially creates the global macro variable &PATH to represent the SASROOT directory:
%let path=%sysget(SASROOT);
%put PATH: &path;However, when a %PATHOLOGY macro is called, it reassigns the &PATH macro, unknowingly overwriting the original value:
%macro pathology();
%global path;
%let path=pathogen;
%mend;
%pathology;
%put PATH: &path;
PATH: pathogenTo overcome this vulnerability, where global macro variables are intended to be enduring, consider macro names that are unlikely to be reused, even erring on the side of long and unwieldy to ensure that reuse is unlikely. Global macro variables are not the only vulnerability; local macro variables can also contaminate parent processes. The following code is intended to write the ASCII characters 65 through 69 (i.e., A through F) twice:
%macro inner(); * child;
%do i=65 %to 69;
%put -- %sysfunc(byte(&i));
%end;
%mend;
%macro outer(); * parent;
%do i=1 %to 2;
%put &i;
%inner;
%end;
%mend;
%outer;However, the code iterates only once and produces the following output:
1
-- A
-- B
-- C
-- D
-- EIn this example, because the macro variable &I in the %INNER macro was not defined as a local macro variable, it overwrites the &I in the %OUTER macro. When %INNER completes the first iteration, the value of &I is 70 and, when this value is assessed by the %DO loop within %OUTER, the %DO loop exits because 70 is greater than the threshold value 2. To remedy this error, %I must at least be defined as local within %INNER, but because %OUTER itself could also be invoked at some point as a child process, both instances of %I should be distinguished as local macro variables:
* CHILD;
%macro inner();
%local i;
%do i=65 %to 69;
%put -- %sysfunc(byte(&i));
%end;
%mend;
* PARENT;
%macro outer();
%local i;
%do i=1 %to 2;
%put &i;
%inner;
%end;
%mend;
%outer;While these examples have demonstrated the perils of macro variable creation and initialization, child processes can have other unintended effects on parent processes. For example, if a child process fails to unlock a data set (that it has explicitly locked), fails to close a data stream (that it has opened), fails to redirect log output (that it has directed with PRINTTO), or fails to KILL (or WAITFOR) a SYSTASK statement, each of these events can adversely affect functionality and performance once program flow returns to the parent process. In all cases, the best prevention of damage to parent processes is to launch child processes as batch jobs while the best remedy to limit damage is to prescribe exception handling that identifies exceptions and runtime errors within child processes and communicates these to parent processes.
Batch processing can eliminate many of the security concerns that exist when a child process is called. For example, in the black-box paradigm, the parent provides inputs to and receives outputs and return codes from children, but should be unaware of other child functionality. For example, in calling a child process by invoking a SAS macro, that child process could alter global macro variables or delete the entire WORK library relied upon by the parent process—because both parent and child are running in the same session. However, when a child process is instead initiated as a batch job, the new SAS session cannot access the global macro variables, WORK library, or system options of the parent session, thus providing protection against a number of threats.
In other cases, threats cannot be avoided, but they must be detected. An exception handling framework that detects and handles exceptions and runtime errors in child processes, provides necessary exception inheritance to parent processes, and prescribes a fail-safe path (if process or program termination is necessary) is the best method to minimize damage caused by software failure within child processes. Fail-safe paths are further discussed in the “Fail-Safe Path” section in chapter 11, “Security.”
Encapsulating Children
Nobody puts Baby in a corner, but sometimes you need to put Baby in a big black box. As demonstrated in the previous “Loosely Coupled” section, macros are susceptible to elements of the SAS session, such as global macro variables, system options, and WORK library data sets. Thus, modules should only rely on information passed through SAS macro parameters or the SYSPARM option. In some cases, module functionality will be dependent upon SAS system options, and if user permissions allow certain options to be changed within the SAS session, it is possible that these could have been modified.
The most effective way to protect child processes is to ensure they receive the necessary information from the parent, whether passed through macro parameters, the SYSTASK parameter, or some other modality. Especially where these parameters are dynamically passed, quality control routines within child processes should validate parameters to ensure that sufficient (and valid) information exists to continue. Macro validation is further discussed and demonstrated in the “Macro Validation” sections in chapter 11, “Security.”
BENEFITS OF MODULARITY
Modularity is so central to software development best practices that some static performance attributes not only benefit from but require modular software design. Most other static performance attributes are conceptualized primarily as investments, because they support software maintainability but don't directly influence dynamic performance. Functional decomposition and modular software design, however, are often prerequisites to implementing parallel processing solutions that can increase software speed. In the following sections, the benefits of modularity are discussed relative to other dimensions of software quality.
Maintainability
Software maintainability can be greatly increased where software is divided into discrete modules and saved as separate SAS programs. In addition to being big and cumbersome, monolithic software products represent single programs that cannot be modified efficiently because multiple developers cannot edit the code simultaneously. When software is divided into modules of discrete functionality, several SAS practitioners can tackle different maintenance activities concurrently to achieve faster maintenance and, if software functionality has been interrupted, a faster recovery period.
Readability
Software is inherently more readable when it fits on one screen. A study by Ko et al. recorded software developers' software development and maintenance tasks and found they spent “35 percent of their time with the mechanics of redundant but necessary navigations between relevant code fragments.”4 Tremendous amounts of time are consumed merely navigating within software as developers ferret out dependencies, prerequisites, inputs, outputs, and other information so that they can perform development tasks. The implication is that modular software is much easier to read and thus results in more efficient software maintenance and management activities.
Testability
Unit testing describes testing done on a single unit or module of code and is ideally suited for modular software design. Because functionally discrete code is only intended to do one thing, this simplicity of function translates into simplicity of testing. Furthermore, by reducing module interaction through loose coupling methods that prescribe precision in parameter passing and return code generation, testable components are more easily isolated and their behavior validated. Monolithic code is difficult to test through a formalized test plan with test cases because of the inherent complexity and multifunctionality.
Stability
Code stability is substantially increased due to loose coupling of modules. If one component needs to be modified, in many cases, other aspects of the software can remain intact. For example, the %SORTME macro in the “Loosely Coupled Macros” section dynamically sorts a data set, given parameters for the data set name and sort variable:
%macro sortme();
%global sortme_RC;
proc sort data=mydata;
by char1;
run;
%if &syscc>0 %then %let sortme_RC=FAILURE!;
%mend;However, if maintenance was required to replace the SORT procedure with an equivalent SQL procedure sort or hash object sort, these modifications could be made within the %SORTME macro without disturbing or even accessing its parent process. This degree of stability facilitates software integrity and reduces subsequent software testing following maintenance because relatively smaller chunks of software must be modified with each maintenance activity.
Reusability
Software modules are much more reusable when they are functionally discrete and loosely coupled. Modules that perform several functions can sometimes be bundled together efficiently when those functions are related and commonly used together, such as determining whether a library exists, then whether a data set exists, and finally whether that data set is unlocked and can be accessed. Whenever functionality is bundled, however, the risk exists that some aspect of the functionality will not apply for reuse situations, thus requiring development of a similar but slightly divergent module. In robust software, loose coupling also benefits software reuse because prerequisites, inputs, and outputs can be validated within an exception handling framework.
Execution Efficiency
Functional decomposition of software into discrete elements of functionality is the first step toward critical path analysis that can demonstrate where process bottlenecks lie and where parallel processing could be implemented to increase performance. By conceptualizing software as bits of discrete functionality rather than one composite whole, SAS practitioners can better understand individual requirements, prerequisites, and dependencies of specific functions, thus enabling them to better manage program flow and system resources during software execution.
WHAT'S NEXT?
Over the next few chapters, the benefits of modular software design are demonstrated as they relate to static dimensions of software quality. The next chapter introduces readability, which facilitates code that can be more readily and rapidly comprehended. Readability is often the most evanescent of all performance attributes, disappearing with the addition of other dynamic dimensions of quality that inherently add content and complexity. Thus, the balance of modularity and readability is an important one, because through modular design, readability can often be maximized even as additional functionality and performance are incorporated.