
10
Fake News Detection Using Machine Learning Algorithms
M. Kavitha*, R. Srinivasan and R. Bhuvanya
Computer Science & Engineering, Vel Tech Rangarajan Dr. Sagunthala R&D Institute of Science and Technology, Chennai, India
Abstract
Any sorts of untrue information designed to mislead or defame any individual are termed as fake news. In this paper, we describe a technique to spot bogus news using machine learning (ML) architectures. The ever-increasing production and circulation of skewed news stories necessitates an immediate need for software that can automatically discover and detect them. Automated identification of fake news, on the other hand, is extremely difficult because it necessitates the model’s understanding of natural language nuances. Binary classification method was used as a fake news detection technique in the existing methodologies, which restricts the ability of the model to discern how closely the reported news is connected to true news. To address these issues, this paper attempted to design a neural network architecture that could reliably predict the attitude between a given combination of headlines and article bodies. We have fused some advanced ML techniques together which includes the logistic regression and recurrent neural network technique particularly. The implemented approach is better than the existing architectures by 2.5% and achieved accuracy of 90.39% on test data.
Keywords: Machine learning, binary classification, logistic regression, recurrent neural network, fake news detection, natural language
10.1 Introduction
With the abundance of today’s technology, there is unimaginable growth of information online; hence, there exists a necessity to identify the bogus news from the original one. This section encompasses various machine learning (ML) algorithms [17] followed in the previous works to identify the fake news content. Fake news can be identified through both linguistic and non-linguistic cues. M. AlRubaian, M. Al-Qurishi et al. [6] explained that the integrity of data can be defined in terms of trustworthiness, accuracy, fairness, etc. The above-mentioned research developed a model for detecting incredible content on one of the social network Twitter to avoid the spread of dangerous information [15]. The model employs a user-based crawler to collect user information then the user aggregated features are also extracted. A pair-wise compression results in priority vector which will rank the instance features based on the relative importance. Finally, the Naïve Bayes (NB) classifier is adopted to classify the tweets in place of credible or non-credible. This method is considered to be the first work which considers the relative importance to identify the credibility of tweets in microblog analysis. The public opinion gets affected through fake news websites. Hence, Kushal Agarwala et al. [13] explored the natural language processing (NLP) techniques [5]. Natural Language Tool Kit (NLTK) was used to tokenize the body and headlines statement. Various ML algorithms [7] such as Support Vector Machine (SVM), Logistic Regression (LR) [1–3], and NB with Lidstone Smoothing were applied to evaluate the performance. Among the applied algorithms the NB with Lidstone Smoothing achieved with 83% result accuracy. Mahabub Atik [14] identified the fake news by creating an “Ensemble Voting Classifier”. To validate the news, the researchers used a variety of ML classifiers, including NB, SVM, and K-Nearest Neighbor (KNN) [21], Ada Boost, LR, and many other approaches. A resampling procedure known as cross-validation was used, and the top three ML algorithms were selected using the best accuracy score and the chosen algorithms were processed with Ensemble Voting Classifier. A multiclassifier-based Ensemble Coding classifier results in deciding the real and fake news based on soft and hard voting. Nowadays, information can easily be accessible from anywhere. In the age of a technology where now an individual can access and have a detailed knowledge of various events happening around the world with the comfort of his/her own home, people are updating information with increasing inaccuracy and irrelevance, which is usually referred to as false news dissemination. Because the majority of people utilize social media to keep up with news, providing them with accurate and altruistic information is a responsibility that must be fulfilled. Because of the growing number of social media users, news can be quickly published by anyone from anywhere, putting the authorship of news in danger. Fake news is frequently circulated to mislead readers, causing tensions, mental stress, and plenty of other dangerous issues. It is a difficult task to detect those misleading facts based on the content of the news only. The news content is different in terms of styles, the subject form, and the way of delivering it. Thus, it becomes essential to bring an efficient system for its detection. Many researchers and developers have recently focused on detecting fake news. The stance recognition technique, which is the subject of our research, is a novel and innovative way to detect bogus news. The basic aspect of a series of methodologies for assessing the relationship between two pieces of text and, in particular, detecting fake news, is stance detection. With the recent introduction of social media platforms like Facebook and Twitter, it has become much easier to disseminate information to the masses in minutes. While the spread of information is proportional to the expansion of social media, the authenticity of these news articles has deteriorated.
In this study, we look at different methods for predicting the outcome of a news article and news feature pair. The positions between them can be classified as “concur”, “deviate”, “examine”, or “inconsequential” which depends on the similarity content of news article. We looked at a few classic AI models to establish a baseline and then compared the results to cutting-edge deep organizations to determine the position of the article body and feature. We offer a model that can recognize fake news using test methods by exactly anticipating the position between the feature and the news article. We additionally concentrated what diverse hyperboundaries mean for the model presentation and summed up the subtleties for future work. The established model performs good while arranging between all the positions for certain varieties in exactness.
10.2 Literature Survey
In this segment, we will introduce the diverse sort of models, preprocessing strategies, and datasets utilized on the writing. In the time of 2017, two difficulties were proposed by RumorEval (SemEval 2017) and the Fake News Challenge. The previous had two subtasks: one for position identification of an answer to a news and another that endeavored to group the news as evident or bogus. The last is only a position recognition of a news, which groups the answer of a news in concur/dissent, talking about, and random. There are various locales for manual truth keeping an eye on the web like snopes.com and factcheck.org which are the most famous among all. What is more, there are some other particular destinations as well, for spaces like governmental issues, as politifact.com. Conversely, there are additionally a few locales, as theonion.com, that distribute news unequivocally announced phony. The majority of these locales are distributing this information as a parody, diverting, or as a pundit. Many exploration papers produced their dataset from these two sources. Wang submitted statements made by public figures via the LIAR dataset, which was labeled with their authenticity. Zubiaga et al. generated the PHEME dataset, which is suited for rumor research. This dataset compiles a huge number of rumor thread tweets and links them to news stories. Muhammad Syahmi Mokhtar et al. developed a web application that allows users to enter news material or URLs using the LR technique. The authors used model development methodology and proved that LR shows good performance in classification task. Stance detection technique was applied using TF-IDF feature which has shown greater accuracy. As per their research, LR detection model was found to work well in dealing with long and also short input text. It was found that the technique achieved around 79.0% to 89.0% accuracy based on the data used. Due to its capabilities, the Term Frequency–Inversed Document Frequency (TF-IDF) has been demonstrated to be a good feature to utilize in text preparation. After that, this model was combined with a web service that receives news URLs or text news items as input. The “FAKENEWS” app was also used to verify the news’ legitimacy. Joseph Meynard Ogdol et al. tried to address the solution in a unique way of creating a classifier based on a logistic binary regression commonly prevalent in ML and Artificial Intelligence. The sentiments, neutrality, page rank, and content length were measured here to specifically find the structure error ratio for each data to create a model for the fake news classifier. The study used dataset of nearly 10,000 news data for the measurement purpose. The model was subjected to show an 80% accuracy rate and was found capable of classifying legitimate news apart from fake news. A labeled news data-set, third party API’s and a mathematical software tool were used as the resources by the team members. Harika Kudarvalli et al. conducted their research by performing numerous Machine algorithms out of which, with over 92% accuracy, the findings of LR and SVM were promising.
According to their findings, NB and Long Short-Term Memory (LSTM) did not perform as well as they had anticipated. The applicability of the algorithms in photographs and videos for better identification of fake news is one of the most essential and interesting use cases for this model. They performed their analysis on Tweets datasets from Twitter by extracting the real time tweets using keywords. They then preprocessed it and retrieved important tweet features from the dataset. To reduce processing load, these features were separated and the tweet information column was removed. Fathima Nada et al. attempted to identify fake content from the news articles automatically. They started by introducing the task’s dataset and then went over the pre-processing, feature extraction, classification, and prediction processes in depth. The preprocessing capacities played out certain activities which were tokenizing, stemming, and exploratory information investigation like reaction variable dispersion and information quality check. Furthermore, they utilized some element extraction methods like basic sack of words, n-grams, and TF-IDF. The model proposed by them researched distinctive element extraction and ML procedures which accomplished a precision of 72% around utilizing TF-IDF highlights and strategic relapse classifier. Abdullah-All-Tanvir and Ehesas Mia Mahir [9] actualized five distinct calculations. Notwithstanding the most widely recognized ML classifier calculations, NB, LR, SVM, and two profound learning strategies, for example, recurrent neural network (RNN) and LSTM were utilized. As the examination is about content information the accompanying thoughts, for example, Count Vectors, TF-IDF, and Word Embedding, were abused. Check Vectors structure a network information where each line addresses the corpus report, every section addresses the corpus term and every cell addresses the recurrence include of a particular term in the current archive. TF-IDF is utilized for data recovery and text mining. Term Frequency is a proportion of how regularly a particular term, for example, “t” shows up in an archive and IDF gauges the significance of a particular term “t”. Lastly, the Word Embedding is a sort of word portrayal that addresses words with comparative importance to have a comparable portrayal. The proposed work investigated a model for perceiving false news from Twitter information. The previously mentioned portrayal procedures of Count Vectors, TF-IDF, and Word Embedding were applied with the ML calculations of NB, LR, and SVM, and further investigated with the profound learning models. While considering the above presentation examination SVM yields the most noteworthy precision of 89% with the portrayal procedure. S. Aphiwongsophon and P. Chongstitvatana [18] exploited the work of identifying the fake news based on Twitter data collected from October 2017 to November 2017. Twenty-two attributes of raw data such as ID, Name, Profile-Image, Friends count, Followers count, and many more are selected from the 948,373 messages. Then, the normalization process is applied which converts the text data into numbers. From the obtained result, replicated data is removed as a pre-processing which will reduce the size of the result to 327,784 messages. ML algorithms such as NB, Neural Networks, and SVM were used to classify the retrieved utterances as believable or unreal.
To detect fake news, Thota, Aswini et al. [19] used deep learning architecture. To anticipate the stance between the headline and the news article, TF-IDF, GloVe, and Word2Vec were combined with the Dense Neural Network (DNN). TF-IDF with DNN resulted in the highest accuracy with 94% and another model based on BoW-DNN achieved the second-highest score. Pérez-Rosas, Verónica and Kleinberg et al. used two different data-sets FakeNewsAMT and Celebrity news which contain news about general views and celebrities, respectively. Several linguistic features such as N-grams, Punctuation, Psycholinguistic features, Readability, and Syntax are applied to build a model for detecting the fake news. The proposed work uses two different annotators to categorize real and fake news. Bajaj Samir et al. exploited various models such as LR, two-layer feed-forward Neural Network, Convolutional Neural Network (CNN), RNN, and Gated Recurrent Unit. The work mainly focuses on NLP which will identify the fake news by applying the linguistic features.
Wenlin Han and Varshil Mehta [20] applied conventional ML calculations and deep learning models [11–12] to identify counterfeit news. Relies upon the source, the phony news strategy is arranged into news and social setting models. The news content is additionally arranged into semantic-based and visual-based. Conventional AI strategies, for example, Deception Modeling, Clustering, NB, TF-IDF, and Probabilistic Context-Free Grammar (PCFG), are applied. Then, again, the profound learning model is misused with CNN, RNN, Hybrid RNN, and CNN. Further, the profound learning model is applied with three distinct variations, for example, LSTM, LSTM (with dropout regularization), and LSTM with CNN. By noticing the acquired outcomes, TF-IDF, Hybrid CNN, and RNN model accomplish better contrasted and different strategies. In order to improve one’s understanding of the world, it is useful to keep up with current events. Fake news will fool people groups. Because the news is bogus, fake news is occasionally utilized to spread gossipy morsels about products or to affect some political administrative jobs. Deception, gossip, fraud, and other types of deception are sometimes related with the term “false news”. Issues relating to such subjects are frequently noted, depending on the categorization. LR, NB, SVM, Random Forest (RF), and deep neural networks are all used to model fake news detection systems (DNN). The proposed model compared all the above ML methods to identify the fake news. After the data pre-processing, stemming and stop words removal is done then the important features are extracted from the text. Out of all the mentioned classification techniques, DNN is more capable of distinguishing between bogus and real news.
Anjali Jain and Avinash Shakya [10] devised a system for detecting bogus news. The NB classifier, SVM, and NLP approaches are all part of the model. Aggregator, News Authenticator, and News Suggestion System are the three key modules that make up the suggested model. Data gathering is the major task of the news aggregator and the news authenticator helps to verify the news by comparing the news with different sites and detect whether the given news is fake or real. The news suggestion system suggests the news to the user based on keywords that the user desires to authenticate. The proposed work achieved about 93% accuracy compared with the individual traditional machine algorithms. Michail Mersinias et al. demonstrated novel method by utilizing class label frequency distance-boosted LR classifier and deep learning methods [39]. In the 21st century impact of fake news has considerably increased, this is due to float of large amount information to the public without filtering. In today era, huge amount of data is produced and flooded in the internet as fake news, which is drawing the attention of the viewers [37]. Revenue is generated just by clicking which is affecting the major events like Political Elections. The government has framed a law to stop the fake news creation and spreading it through online. Due to this spread of fake news, viewers and readers are misguided, reports show that some fake accounts, and social bots are created by Russia. In 2013, there was a fake news floated in Twitter stating that Barack Obama was got injured in Explosion, due that stock value of around 130 billion dollars was wiped out. So, there is a greater demand [38] for stopping as well as detecting the fake news and it is a challenging task too. Using dimensionality reduction approaches like Principal Component Analysis (PCA) and Chi-square methods, Muhammad Umer et al. coupled CNN and LSTM algorithms. The model will classify the articles by giving the labels as unrelated, discuss, agree, or disagree. PCA and Chi-square methods reduce the nonlinear features and produces contextual features. The classification is based on the acceptance level between the headline and the body of the headline. The keywords are used to find the relevancy of the articles and with the help of it the whole content on the body can be identified. Initially, the feature set is converted into word vectors, and then, the feature set is reduced by applying the dimensionality reduction methods like PCA and Chi-square methods. Normally, PCA is the widely used techniques in various applications, which converts the new variable to subset of variable by calculating the correlation between the variables. The Principal Component is computed using co-variance matrix. The PCA features are fed into the embedding layer of the deep model, vectorized, and then fed back to the 1D CNN to extract the features.
These characteristics are filtered again in five dimensions with 64 filters, and then, some of them are returned to the max pooling layer to extract the most significant features. Some features are fed into the LSTM layer for series modeling to find the relevant keywords which is hidden. The model produced 97.8% accuracy by determining the comparative sentences from a news article. NLP has a well-defined task which is to detect the stance. Earlier studies show that target-specific stance detection is used in tweets and for online debates which is structural, lexical, and linguistic features. Initially, stance detection was kicked off in 2017. Fake News Challenge-1 (FNC-1) is based on ensemble method that combines both gradient boosted decision trees and deep CNN with Google News Pretrained vectors. The accuracy of the model was 82.02%. Another model used multilayer perceptron (MLP) methods which obtained 81.97% accuracy. Also, one of the existing techniques used Bags of Words (BOW), Term Frequency and TF-IDF as features and produced 81.72% accuracy. FNC-1 task combined RNN with max-pooling and neural attention mechanisms to produce 83.8% accuracy. The model used deep recurrent model to calculate statistical features and neural embedding, the method produced 89.29% accuracy. Preprocessing converts the raw data to system understandable format. It is performed on FNC-1 dataset, which will convert the characters to small case letters, removal of stop words, tokenization, and stemming. The difficulty in detecting false news stems from the fact that humans find it difficult to distinguish between fake and authentic news. Particularly, the use of language in fake news is complex. Rashkin explores the distinctions between fake news language usage and true news language usage in three forms of false news: satire, hoax, and propaganda. Her research demonstrates that subjective, intensifying, and hedging words, among other linguistic qualities, play a part in the creation of fake news, with the purpose of introducing imprecise, obscuring, dramatizing, or sensationalizing language. Consequently, applying feature-predicated approaches will be labor-intensive and time-consuming. R. Sandrilla et al. informed COVID-19 commenced to affect diverse people in different ways. People get infected and develop mild to mitigate illness.
So, the public from sundry places transpired to expose their cerebrations about COVID-19 on sundry platforms. This paved the way for the engenderment and development of fake news about COVID-19. When people are in desideratum of access to high quality evidence still, they face vigorous barriers to take suggested actions. To understand the bamboozling information WHO has developed to fortify infodemic to fight against the epidemic disease and to stop the reader from bamboozling evidence. The word “infodemic” was coined to describe the risks of distortion phenomena in virus outbreak management, because it has the potential to speed up the epidemic by inciting and collapsing gregarious replication. It is something with a surplus of information which can be either true to the evidence and some may not. The aim of the infodemic is not to eliminate but to manage the situation to avert and to respond to the bamboozling information. Because amassing the data from the convivial media or the other news media platforms without fact checking may astringently affect the general public’s lifestyle, harmony, the old one’s emotional psychology and their noetic demeanors. In the expeditious spread of COVID-19, the globe is in grief and facing the situation of identifying the fictitiously unauthentic or the genuine news propagation. The authentic news avails to mitigate the calamity, whereas the unauthentically spurious one amplifies it. This erratic situation inspires the researcher to understand and to develop a model which will avail to apperceive the transmuting nature of news in convivial media cognate to COVID-19 pandemic.
This investigation will avail to analyze and detect fake news in convivial media with less effort. It mainly fixates on gregarious media fake news cognate to COVID-19 the opensource dataset has been accumulated for detection of misinformation. During the pandemic, a classifier based on ML is being created to detect falsehoods. We also put our model through rigorous testing in a range of challenging situations, indicating that it can attain extraordinarily high precision. The following article is divided into four pieces. The findings of prior relevant studies in this field are analysed and examined in the literature review. The methods part goes through data collecting, data annotation, data cleaning and prepossessing, and data exploration in great detail. The primary and minor findings of the study are highlighted in the relegation outcome section. The COVID-19 outbreak exposed a parallel epidemic driven by bogus news. This quandary of illuding information interrupts the public health communication and withal leads to mass fear and solicitousness. In the meanwhile, few researchers investigated their studies and brought forward the issues in highly philomath field cognate to illuding information engendered by the gregarious networks on this COVID-19 pandemic. The investigation on fake news propagation deploys sundry ML techniques to avail the public in relegating the data that they are viewing is fictitiously unauthentic or not. This study is done by relegating and comparing the data provided with some pre-kenned data that contains both misleading and inaccurate information. Typically, in order to develop a working model to detect the bamboozling information practicing, the ML techniques and methods are very consequential. The ML techniques must undergo certain stages to consummately train and develop a detection model starting from data preprocessing to feature detection and extraction. Authors in [22, 23] state that the stages starting from data preparation, data cull, and data extraction facilitates in handling the immensely colossal magnitude of data required for building a detection model. There subsist many illuding information detection websites; however, most of the websites are human predicated where the analysis done in this detection model is manual. Though the manual detection is done by highly expertise people it has few drawbacks as high extravagant, slow in process, highly subjective, very tuff in handling the substantial quantity of data. As a result, [24] explored combining ML with erudition engineering to detect bogus news. Hence, [25] proposed an automated relegation that represents a prolific trend of study. Many researchers worked on detecting fake news detection model [26] surveyed on many automated illuding information systems and proposed a few detection models that lead to detection of mis information. In this context, misinformation cognate to COVID-19 has been incrementing in an expeditious pace due to pandemic. They were expeditious to spread illusory information. In [27], it is reasoned out on Description Logics to detect inconsistencies between the trusted and untrusted news.
The spread of COVID-19 in Astute cities is visualized using an innovative mathematical approach. To prevent the propagation of COVID-19 fake news, the researchers developed an integrated system incorporating ML approaches [28]. Because the COVID-19 pandemic and the growth of the infodemic are happening at the same time, it is critical to provide a strategy to combat false information. To detect disinformation during the COVID outbreak, a multilingual cross-domain dataset was assembled, and a ML-based classifier was developed [29]. The unauthentically spurious news about the corona virus has become an incrementing fame in the diffusion of shaping the news histories online. The videos posts and articles cognate to the current pandemic are extensively disseminated throughout the convivial network platforms. The researcher proposed a novel multi-level voting ensemble model utilizing 12 classifiers amalgamated to soothsay predicated on their erroneous prognostication ratio [30]. Spreading of this COVID-19 pandemic disease not only transmuted the salubrious comportment among the globe but expeditiously given space to spread the erroneous news in directing or bamboozling the public in numerous rumors [8]. In spite of these rumors, public not only had very earnest impact on their salubrious lifestyle but erroneous increase in the spread of virus along with the unauthentically spurious information. An elderly man father of three was said to have committed himself after auricularly discovering his COVID-19 diagnosis, according to an article [31]. Mitigating data outside of the unauthentically fabricated news piece itself may become an important part of automatic fake news identification [4] as some of the above-mentioned papers establish physical touch. This is so-called “Network” strategy, which can be beneficial and advantageous in instances when text classification is difficult. Several researchers have also added factors relating to social media, which is the most widely used medium for spreading fake news. It is critical to consider how fake news spreads in such scenarios, as well as the role that users play. The difficulty of detecting fake news using filtered data is one that arises frequently.
ML algorithms that detect false news via text analysis have a disadvantage in that they cannot predict fake news early on, when the information needed for verification or debunking is not available due to the early stages of news dissemination. As a consequence, a model based on a Convolutional Network is built to discover news propagation channels based on people who share it, which reduces detection precision. Detection based on global and local user variations can identify false news with far greater precision than existing systems. Text analysis fails when news stories are too short, but convolutional networks can be used to investigate them. They can create erudition graphs that can determine the sincerity of two things’ cognition. These models would produce background information erudition graphs, which could be trained to create entity cognitions in order to assess truth or falsity. It is suggested that a structured erudition network be used to collect background knowledge. Despite the fact that the erudition graphs were created with a tiny quantity of data, they were proved to be capable of delivering acceptable results. Authors in [32] describe a network-based strategy to studying how news is transmitted, who shares it, and how these spreaders are related. These patterns are then used to detect bogus news at different levels of the network. Fake news spreads faster and has more and stronger spreader interaction, according to the research, which is denser for networks with similar interests and behaviours. One disadvantage is that, despite the fact that only a little quantity of network information is required, news must be spread on social media before it can be discovered. Another method that focuses on user involvement combines text analysis with a social-based strategy that evaluates how often and by whom material is shared or “liked”. It has been proved that Facebook content may be accurately labeled as false news based on the users who “like” it. The negative is that in order to yield worthwhile results, the content must include a certain amount of “social interaction”. Authors in [33] also propose a visual examination of aspects such as the group behavior of users that propagate fake news, and the initial source of news. This would be accomplished using a cumulated text analysis and network analysis model that takes into account the three features of false news: the article text, the user replication it receives, and the user source that promotes it. An integrated method such as this is said to increase precision and generality while also providing a superior representation of users and articles. Authors in [34] also offered cumulation strategies, demonstrating the need of merging verbal expressions with overall “credibility patterns” of politicians using ML classifiers. Similarly, authors in [35] developed a diffusive network model based on explicit and latent features extracted from a text and achieved excellent results not only in identifying fake news articles, but also in identifying news engenderers and types of news subjects, where a record of credibility can be visually perceived and assessed. In the effort to eradicate fake news propagated on social media, the latter two categories are deemed more important than the news itself. Automatic fake news identification [16] is difficult, according to [36], because the language used in such articles is purposely difficult to differentiate from legitimate stories, and distinguishing satirical news from fake news is even more difficult. Traditional false news detection methods, such as linguistic approaches, do not work with political news due to the complexity of the language. This method is based on a hybrid ML-human crowd model, where human input is used based on machine categorization accuracy. A cumulated method additionally mitigates the pristinely crowd-sourced strategy’s low scalability in terms of cost and latency.
Wang et al. [40] proposed an Event Adversarial Neural Network (EANN), which comprises of three primary segments: the multi-modular element extractor, the phony news finder, and the occasion discriminator. The multimodal include extractor is answerable for separating the printed furthermore, visual highlights from posts. It helps out the phony news identifier to get familiar with the discriminable portrayal for the recognition of phony news. Hardalov et al. [41] utilized a mix of etymological, believability and semantic highlights to separate among genuine and counterfeit news. In the implemented work, phonetic highlights incorporate (weighted) n-grams and standardized number of exceptional words per article. Believability highlights incorporate capitalization, accentuation, pronoun use, and conclusion extremity highlights created from dictionaries [44]. Text semantics were examined utilizing implanting vectors strategy. All component classifications were tried autonomously and in mix dependent on self-made datasets. The best presentation was accomplished utilizing all accessible highlights. Ma et al. [42] noticed changes in semantic properties of messages over the lifetime of talk utilizing SVM in view of time arrangement highlights; at that point, they indicated great outcomes in the early discovery of an arising talk. Besides, Conroy et al. [43] showed that the best outcomes for counterfeit news recognition could be accomplished while consolidating semantic and network highlights.
To merge metadata with text, Wang [45, 46] planned a cross breed CNN (or ConvNet). The best presentation was accomplished when fusing diverse metadata highlights. Lendavi and Reichel [47] explored logical inconsistencies in gossipy tidbits arrangements of microposts by dissecting posts at the content comparability level. The creators contend that jargon and token succession cover scores can be utilized to produce signals to veracity appraisal, in any event, for short also, boisterous writings. Joulin et al. [48] proposed a content order model dependent on n-gram highlights, dimensionality decrease, and a quick estimation of the softmax classifier. This quick content classifier is based upon an item quantization technique all together to limits the softmax over N reports; therefore, it gives exact outcomes with less preparing and assessment time [49].
Zhou et al. [50] proposed a complete description of the cutting edge in fake news location in online media. Aggarwal et al. identified four distinct features of phishing tweets based on URLs, conventions to inquire about information bases content, and adherents organizations, which present a similar issue to false and non-tenable tweets but can potentially cause huge monetary mischief to someone tapping on the connections associated with these “phishing” messages. Yardi et al. created three element types for spam recognition on Twitter [51]; which incorporates looks for URLs, coordinating username examples, and location of watchwords from as far as anyone knows spam messages [52]. O’Donovan et al. distinguished the most helpful pointers of valid and noncredible tweets as URLs, specifies, retweets, and tweet lengths [53]. Different chips away at the believability and veracity distinguishing proof on Twitter incorporate Gupta et al. that built up a system also, constant evaluation framework for approving creators content on Twitter as they are being posted [54]. Their approach doles out a graduated believability score or rank to each tweet as they are posted live on the informal organization stage.
10.3 Methodology
The popularity of social media has attracted spammers to disseminate large amount of spam messages. Studies of the past shows that most spam messages are produced automatically by bots. Therefore, bot spammer detection can reduce the number of spam messages in social media significantly. In this project, we have tried to identify if a particular social media account is malicious or real. The two categories that have been considered for the result bins are bots or non bots as shown in Figure 10.1. These are as follows:
- Accurately categorize the headline/body pair as related or unrelated earns 0.25 points.
- Score 0.75 points for correctly classifying related pairs as agree, disagree, or debate.
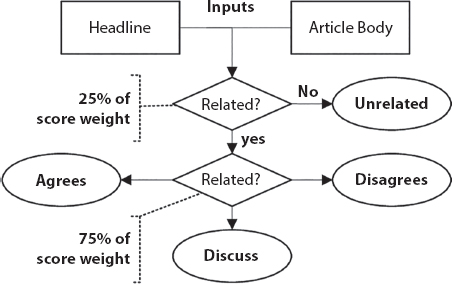
Figure 10.1 Fake news evaluation matrix.
This score weighting schema is designed for the consideration that identifying the relating stance is easier than discovering a stance toward an orientation.
The cycle is a two-stage progress, conceding a modest quantity of credit for effectively recognizing “related” versus “random” feature/article sets, and accurately ordering the “concur”/“deviate”/“talk about” connection between sets that is by all accounts related. Subsequently, to set up a basic execution benchmark, we have attempted to actualize a fast Jaccard closeness scorer that can contrast features and individual sentences from their purported matched or comparable article. By discovering greatest and normal Jaccard closeness scores across all sentences in the article and picking suitable limit esteems, we were at that point ready to accomplish around 90% exactness on the connected/disconnected assignment, so it is expected a decent precision execution when moving to profound learning. The datasets for the undertaking have been taken from the Fake News Challenge association. The set decently comprises of just shy of 50,000 “position” tuples, with each tuple 2 comprising of the following:
- A feature that should be contrasted against an article with decides its position toward the article. Word means the features range from 2 to fairly at least 40, with a normal length of ~11 around.
- The ID of an article against which the feature is to be analyzed, which can be utilized to discover the content of the article body in a different record. Article lengths range from 1 to almost 5,000 words or somewhere in the vicinity, with a normal length of around 360 words.
- The genuine position of the feature regarding the article. The complete number of real features and articles is 1683 of each; however, on the grounds that most features are coordinated against various articles, the quantity of individual preparing tests is a lot bigger. The genuine class breakdown for the preparation set is generally 73% “inconsequential”, 18% “examine”, 7% “concur”, and 2% “oppose this idea”.
For building our grouping models, we have chosen a bunch of about 3,000 positions to fill in as an advancement set (for the presentation assessment and hyperboundary tuning), and left the rest of preparing. We at first utilized an irregular example of preparing guides to choose the individuals from our informational collection, yet we stressed that the way that novel features and articles that are utilized generally in different instances of preparing could prompt “spillage” of preparing information at assessment time. Hence, we additionally tried different things with unequivocally isolating exceptional features to have a place with either the preparation or informational collections, yet never both.
10.3.1 Data Retrieval
Twitter is our main source of information. After registering for a Twitter Developer account, we were given credentials to begin gathering tweets. We downloaded tweets containing terms such as parliament, politics, corona-virus, oil, and rising market prices, among others. User and tweet data also provided ID, username, tweet text, and whether the user is verified. The user verified column served as our decision variable, and it was assumed that if a user verified account sent a tweet, it was most likely authentic news. Information passed through authorized accounts is also thought to be reliable. As a result, it is natural that before awarding a confirmed blue tick to a user’s account, Twitter goes through a rigorous verification procedure. Users who want their accounts verified must go through a long procedure in which Twitter verifies and authenticates their accounts online. To make the analysis more user-friendly, we converted our user verified column into a label that replaces the text with 0 if the individual is verified and 1 if they are not. The dataset will be pre-processed extensively before being used to analyze the tweets.
10.3.2 Data Pre-Processing
The retrieved dataset was converted to lower case letters, with all punctuation deleted. Users tend to employ emoticons and various punctuations when data is collected from Twitter, which makes our recognition procedure more difficult. Columns that were found to be empty were eliminated. The dataset was filtered to remove repetitive characters such as URL tags and stop words. Hashtags have also been eliminated.
10.3.3 Data Visualization
Once the data has been cleansed and is ready to be given to the model, we can better understand it by visualizing its elements in graphs or plots.
The lowest idf used in our model are
[“said”, “told”, “people”, “according”, “year”, “time”, “news”, “just”, “new”, “reports”]
The highest idf we use in the dataset are
[“real problem”, “point videos”, “real renderings”, “screens used”, “authenticity document”, “having salespeople”, “having surgery”, “maintained price”, “authenticity looking”, “summaries”]
10.3.4 Tokenization
Tokenization refers to the process of breaking down a large collection of text into smaller lines, words, or, in any case, creating words in a non-English language. NLTK modules from python provide the capabilities of tokenization. We used Regex Tokenizer, which removes tokens either by using the provided regex example to split the content (default) or by coordinating the regex over and again (if holes are bogus). Sifting tokens while limiting their length is also possible with discretionary bounds. It recovers a variety of strings that have become unusable.
10.3.5 Feature Extraction
Extracting features is a dimensionality reduction cycle in which the raw data is reduced to more groups for processing. Hence, we are shortening the compiler’s handling session and increasing the speed with which we can detect the word’s estimation. One of the characteristics of these massive informational indexes is that many elements necessitate a large number of registered assets to process. As seen in Figure 10.2, TF-IDF stands for “Term Frequency–Inverse Document Frequency”. This is a method to evaluate a word in records which permits us to process each word and implies the significance of the word in the report. This strategy is a generally utilized method in Information Retrieval and Text Mining. Term Frequency sums up how regularly a given word shows up inside an archive. Inverse Document Frequency scales down words that seem a great deal across records. When the highlights have been separated from our dataset, the whole dataset is not needed for additional investigation. Subsequently, we can drop the content section to speed up.

Figure 10.2 Feature extraction.
10.3.6 Machine Learning Algorithms
10.3.6.1 Logistic Regression
This approach is used to predict the probability of an unmodified ward variable. A subordinate variable is a two-factor variable that comprises information coded as 1 (for example, achievement) or 0 (for example, no achievement) (no, disappointment, etc.). The LR model is similar to the Linear Regression model, but it employs a more complex cost work, which is referred to as the Sigmoid capacity. The computed relapse hypothesis suggests that the expense work should be limited to a number between 0 and 1. As a result, straight capacities overlook it because it can have a value more than 1 or less than 0, which is unimaginable according to the theory of calculated relapse Equation (10.1). It is divided into three categories: binomial, multinomial, and ordinal. The LR accuracy level is 0.903, and the confusion matrix is displayed in Figure 10.3.
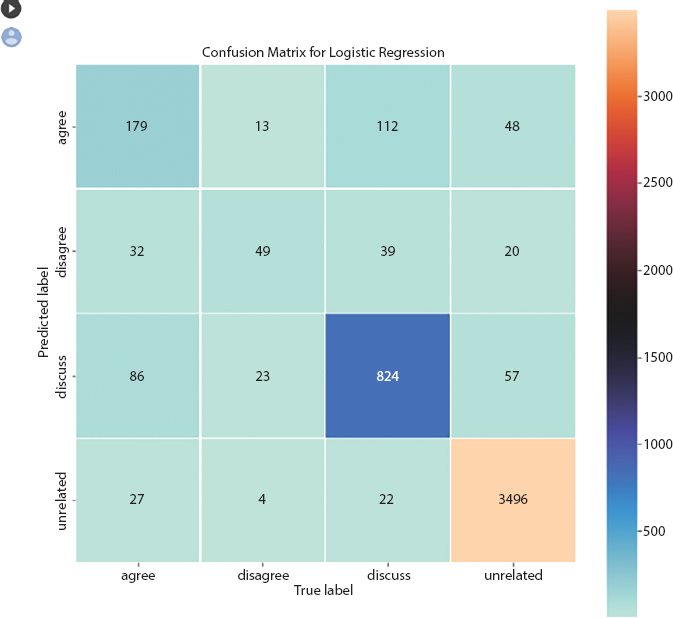
Figure 10.3 Confusion matrix of logistic regression.
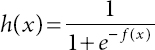
10.3.6.2 Naïve Bayes
A NB classifier is a probabilistic AI model which is utilized for grouping task. The essence of the work depends on the Bayes hypothesis appeared in Equation (10.2). Gullible Bayes mulls over two straightforward suspicions: a) predictors are autonomous and b) all the indicators have an equivalent effect on the result. The precision level accomplished utilizing NB is 0.437, and disarray network is appeared in Figure 10.4.

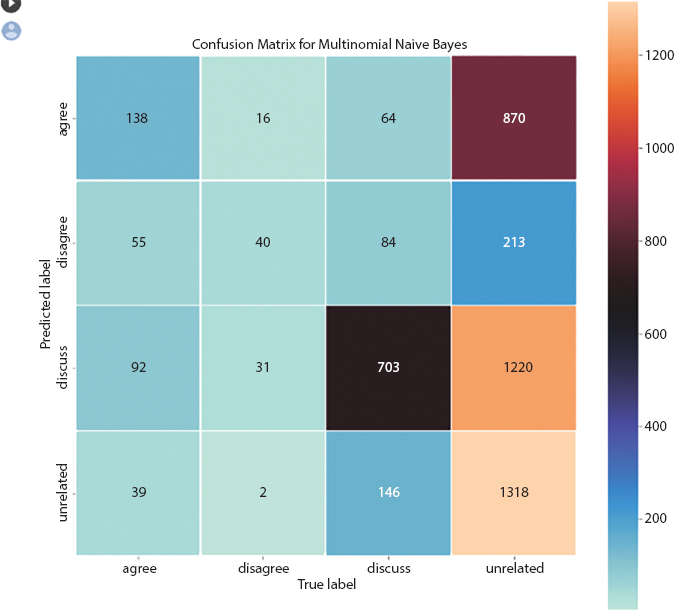
Figure 10.4 Confusion matrix of Naïve Bayes.
10.3.6.3 Random Forest
In AI, the RF comprises of various trees. The trees being referenced here are choice trees. In this way, the calculation involves an irregular assortment or an arbitrary determination of a woodland tree. The exactness level accomplished utilizing RF is 0.805, and disarray network is appeared in Figure 10.5.
10.3.6.4 XGBoost
XGBoost is a very adaptable and adjustable tool that can address a wide range of relapsing, grouping, and positioning challenges, as well as client-defined target capacities. It is readily available as open-source programming and can be used in a variety of stages and interfaces. Equation (10.3) shows the structure of XGBoost. The accuracy level achieved using RF is 0.437, and confusion matrix is shown in Figure 10.6.
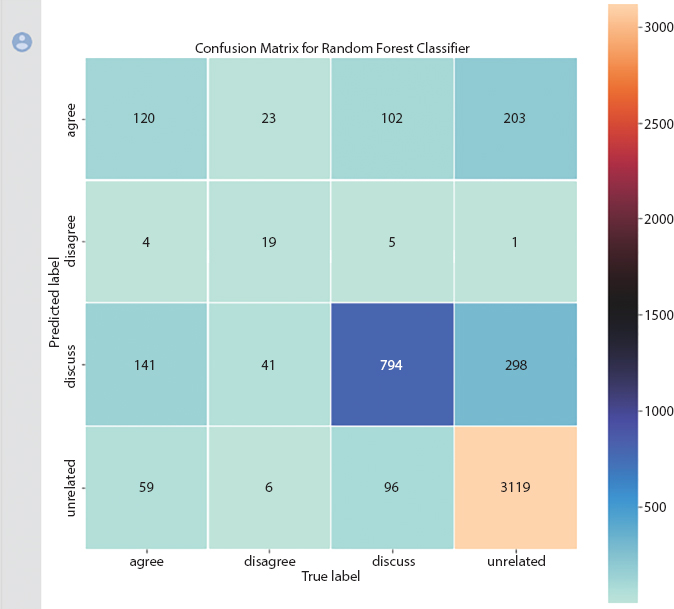
Figure 10.5 Confusion matrix for random forest classifier.
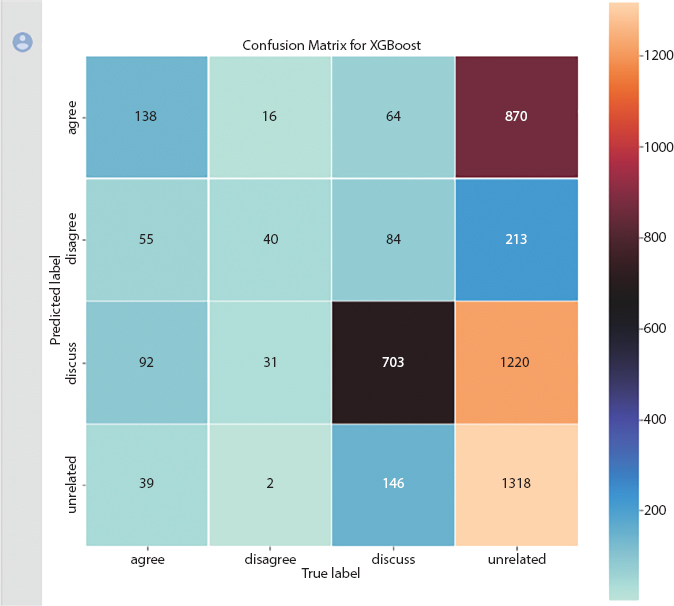
Figure 10.6 Confusion matrix for XGBoost algorithm.

The data is trained to learn the features, and the network of each technique is formed. Following that, testing is carried out to assess the performance of our constructed model utilizing performance metrics such as accuracy, precision, recall and f1-score.
10.4 Experimental Results
The intersection of body and headline along with union of body and headline is calculated. The length of common words between body and headline divided by length of all the words of body and headline and labeled it as word overlap feature. This is the process of distillation where we have identified the rank/latent variable which is used further for model training and prediction. Four algorithms, LR, multinomial NB, RF, and XGBoost classifiers were used to train the model and predict the stance type. The above algorithms were implemented and results are shown. Figure 10.7 shows the summary of accuracies for all the algorithms combined.

Figure 10.7 Accuracy level of machine learning algorithms.
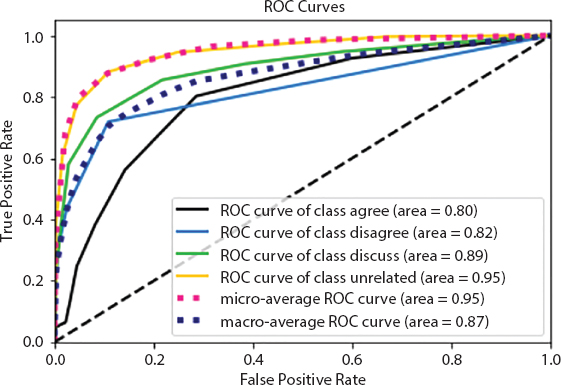
Figure 10.8 ROC curve of random forest for all four classes.
Baseline system is basically a system with TF-IDF vectors as its features. Improved system is run with TF-IDF vectors, Cosine similarity, and Word Overlap, and it is clearly seen that how drastically the accuracy scores has been improved. Initially, it was created with just one classifier: RF and one feature: TF-IDF vectors but the accuracy was not turning up good. Hence, as part of improved system, multiple classifiers were added: LR and seven multinomial NB along with features: TF-IDF vectors, Cosine similarity, and Word Overlap. Figure 10.8 shows the ROC curve of RF model for all the four stance detection types outlined with different colors.
10.5 Conclusion
Detecting fake news seems to be a herculean task, as it is very difficult to identify and predict which news is genuine and which is not out of the thousands of news generating daily. At the same time, it is the need of the hour to detect it faster and aware and prevent the news readers from getting deceived easily. We have successfully presented a model by using four different algorithms which are 1) NB, 2) LR, 3) RF, and 4) XGBoost. Thus, with the aid of these four important algorithms, we have got around 90.39% accuracy along with a faster response too.
References
1. Nada, F., Khan, B.F., Maryam, A., Nooruz-Zuha, Ahmed, Z., Fake news detection using logistic regression. Int. Res. J. Eng. Technol. (IRJET), 06, 05, pp. 1601–1603, May 2019.
2. Pérez-Rosas, V., Bennett, K., Lefevre, A., Mihalcea, R., Automatic detection of fake news. Proceedings of the 27th International Conference on Computational Linguistics, pp. 3391–3401, 2018.
3. Mokhtar, M.S., Jusoh, Y.Y., Admodisastro, N., Pa, N.C., Amruddin, A.Y., Fakebuster: Fake News Detection System Using Logistic Regression Technique In Machine Learning. Int. J. Eng. Adv. Technol. (IJEAT), 9, 1, pp. 2407–2410, October 2019.
4. Liao, W. and Lin, C., Deep Ensemble Learning for News Stance Detection. 5 th International Conference on Computational Social Science IC2S 2, July 17-20, 2019.
5. Ibrishimova, M.D. and Li, K.F., A machine learning approach to fake news detection using knowledge verification and natural language processing, International Conference on Intelligent Networking and Collaborative Systems (INCoS): Advances in Intelligent Networking and Collaborative Systems, pp. 223–234, 2019.
6. Ogdol, J.M.G. and Samar, B.-L.T., Binary Logistic Regression based Classifier for Fake News, J. High. Educ. Res. Discipl., [Online], 3.1 (2018): n. pag. Web. 12, Sep. 2021
7. Katsaros, D., Stavropoulos, G., Papakostas, D., Which machinelearning paradigm for fake news detection? IEEE/WIC/ACMInternational Conference on Web Intelligence (WI), pp. 383–387, 2019.
8. Wu, K., Yang, S., Zhu, K.Q., False rumors detection on sina weibo by propagation structures, in: Data Engineering (ICDE), 2015 IEEE 31st International Conference on. IEEE, pp. 651–662, 2015.
9. Abdullah-All-Tanvir, Mahir, E.M., Akhter, S., Huq, M.R., Detecting Fake News using Machine Learning and Deep Learning Algorithms. 2019 7th International Conference on Smart Computing & Communications (ICSCC), Sarawak, Malaysia, Malaysia, pp. 1–5, 2019.
10. Jain, A., Shakya, A., Khatter, H., Gupta, A.K., A smart System for Fake News Detection Using Machine Learning. 2019 International Conference on Issues and Challenges in Intelligent Computing Techniques (ICICT), Ghaziabad, India, pp. 1–4, 2019.
11. Vaishnavi R., and Anitha Kumari S., Fake News Detection using Deep Learning, International Journal of Innovative Technology and Exploring Engineering (IJITEE) , Volume-9 Issue-9, July 2020.
12. Hiramath, C.K. and Deshpande, G.C., Fake News Detection Using Deep Learning Techniques. 2019 1st International Conference on Advances in Information Technology (ICAIT), Chikmagalur, India, pp. 411–415, 2019.
13. Agarwalla, K., Nandan, S., Nair, V.A., Deva Hema, D., Fake News Detection using Machine Learing and Natural Language Processing. Int. J. Recent Technol. Eng., 7, 6, pp. 844–847, March 2019.
14. Mahabub, A., A robust technique of fake news detection using Ensemble Voting Classifier and comparison with other classifiers. SN Appl. Sci., 2, 1–9, 2020.
15. AlRubaian, M., Al-Qurishi, M., Al-Rakhami, M., Rahman, S.M.M., Alamri, A., A multistage credibility analysis model for microblogs. 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Paris, pp. 1434–1440, 2015.
16. Pérez-Rosas, V., Kleinberg, B., Lefevre, A., Mihalcea, R., Automatic Detection of Fake News, Published in COLING, pp. 1–11, 2018.
17. Mandical, R.R., Mamatha, N., Shivakumar, N., Monica, R., Krishna, A.N., Identification of Fake News Using Machine Learning. 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, pp. 1–6, 2020.
18. Aphiwongsophon, S. and Chongstitvatana, P., Detecting Fake News with Machine Learning Method. 2018 15th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Chiang Rai, Thailand, pp. 528–531, 2018.
19. Thota, A., Tilak, P., Ahluwalia, S., Lohia, N., Fake News Detection: A Deep Learning Approach. SMU Data Sci. Rev., 1, 3, pp. 1–20, 2018, Article 10. Available at: https://scholar.smu.edu/datasciencereview/vol1/iss3/10.
20. Han, W. and Mehta, V., Fake News Detection in Social Networks Using Machine Learning and Deep Learning: Performance Evaluation. 2019 IEEE International Conference on Industrial Internet (ICII), Orlando, FL, USA, pp. 375–380, 2019.
21. Kavitha, M., Suganthy, M., Srinivasan, R., Intelligent learning system using data mining-ilsdm. Int. J. Innovative Technol. Exploring Eng., 8, 9, 505–508, 2019.
22. Tyagi, A.K., Machine learning with big data, in: Proc. SUSCOM, Jaipur, India, pp. 1011–1020, 2019.
23. 12. Elhadad, M.K., Li, K.F., Gebali, F., Fake news detection on social media: A systematic survey, in: Proc. IEEE PACRIM, Victoria, BC, Canada, Aug. 2019, pp. 1–9.
24. Ahmed, S., Hinkelmann, K., Corradini, F., Combining Machine Learning with Knowledge Engineering to detect Fake News in Social Networks-a survey, in: Proceedings of the AAAI 2019 Spring Symposium on Combining Machine Learning with Knowledge Engineering (AAAI-MAKE 2019), A. Martin, K. Hinkelmann, A. Gerber, D. Lenat, F. van Harmelen, P. Clark (Eds.), Stanford University, Palo Alto, California, USA, March 25-27, 2019.
25. Kumar, R. and Verma, R., KDD techniques: A survey. Int. J. Electron. Comput. Sci. Eng., 1, 4, 2042–2047, Aug. 2008.
26. Kaliyar, R.K. and Singh, N., Misinformation detection on online social media—A survey, in: Proc. 10th Int. Conf. Comput., Commun. Netw. Technol. (ICCCNT), pp. 1–6, Jul. 2019.
27. Groza, A., Detecting fake news for the new coronavirus by reasoning on the Covid-19 ontology, Natural language arguments and computation, pp. 1–17, 2020.
28. Hashem, I.A.T., Ezugwu, A.E., Al-Garadi, M.A., Abdullahi, I.N., Otegbeye, O., Ahman, Q.O., Mbah, G.C.E., Shukla, A.K., Chiroma, H., A Machine Learning Solution Framework for Combatting COVID-19 in Smart Cities from Multiple Dimensions MedRxiv: The Preprint Server For Health Sciences, pp. 1–68, 2020.
29. Shahi, G.K. and Nandini, D., Fake Covid -- A Multilingual Cross-domain Fact Check News Dataset for COVID-19, Association for the Advancement of Artificial Intelligence, pp. 1–9, 2020
30. Kaur, S., Kumar, P., and Kumaraguru, P.. Automating fake news detection system using multi-level voting model. Soft Computing, vol. 24, pp. 9049–9069, 2020.
31. Moscadelli, A., et al. Fake news and covid-19 in Italy: results of a quantitative observational study. Int. J. Environ. Res. Public Health, 17.16, pp. 5850, 2020.
32. Zhou, X., Zafarani, R., Shu, K., Liu, H., Fake news: Fundamental theories, detection strategies and challenges, in: Proceedings of the twelfth ACM international conference on web search and data mining, pp. 836–837, 2019.
33. Ruchansky, N., Seo, S., Liu, Y., Csi: A hybrid deep model for fake news detection, in: Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, pp. 797–806, 2017.
34. Zhang, J., Dong, B., Philip, S.Y., Deep diusive neural network based fake news detection from heterogeneous social networks, in: 2019 IEEE International Conference on Big Data (Big Data), IEEE, pp. 1259–1266, 2019.
35. Fernández-Reyes, F.C. and Shinde, S., Evaluating deep neural networks for automatic fake news detection in political domain, in: Simari G., Fermé E., Gutiérrez Segura F., Rodríguez Melquiades J. (eds.) Advances in Artificial Intelligence - IBERAMIA 2018. Lecture Notes in Computer Science, vol 11238. Springer, 2018.
36. Shabani, S. and Sokhn, M., Hybrid machine-crowd approach for fake news detection, in: 2018 IEEE 4th International Conference on Collaboration and Internet Computing (CIC), IEEE, pp. 299–306, 2018.
37. Kim, K.-H. and Jeong, C.-S., Fake news detection system using article abstraction, in: 2019 16th International Joint Conference on Computer Science and Software Engineering (JCSSE), IEEE, pp. 209–212, 2019.
38. Rehm, G., An infrastructure for empowering internet users to handle fake news and other online media phenomena, in: International Conference of the German Society for Computational Linguistics and Language Technology, Springer, pp. 216–231, 2017.
39. Ruchansky, N., Seo, S., Liu, Y., Csi: A hybrid deep model for fake news detection, in: Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, ACM, pp. 797–806, 2017.
40. Yaqing, W. et al., Eann: Event adversarial neural networks for multimodal fake news detection, in: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ACM, pp. 849–857, 2018.
41. Hardalov, M., Koychev, I., Nakov, P., In search of credible news, in: International Conference on Artificial Intelligence: Methodology, Systems, and Applications, Springer, pp. 172–180, 2016.
42. Ma, J., Gao, W., Wei, Z., Lu, Y., Wong, K.-F., Detect rumors using time series of social context information on microblogging websites, in: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, ACM, pp. 1751–1754, 2015.
43. Conroy, N.J., Rubin, V.L., Chen, Y., Automatic deception detection: Methods for finding fake news. Proceedings of the Association for Information Science and Technology, vol. 52, no. 1, pp. 1–4, 2015.
44. Ciampaglia, G.L. et al., Computational fact checking from knowledge networks. PLoS One, 10, 6, e0128193, 2015.
45. Wang, W. Y., Liar, Liar Pants on Fire: A New Benchmark Dataset for Fake News Detection, Association for Computational Linguistics, pp. 1–5, 2017.
46. Ferreira, W. and Vlachos, A., Emergent: a novel data-set for stance classifi-cation, in: Proceedings of the conference of the North American chapter of the association for computational linguistics: Human language technologies, pp. 1163–1168, 2016.
47. Lendvai, P. and Reichel, U.D., Contradiction detection for rumorous claims, Proc. Extra-Propositional Aspects of Meaning (ExProM) in Computational Linguistics, Osaka, Japan, pp. 31–40, 2016.
48. Joulin, A. et al., Fasttext. zip: Compressing text classification models, a Proceedings of 5th International Conference on Learning Representations, pp. 1–13, 2016.
49. Joulin, A., Grave, E., Bojanowski, P., Mikolov, T., Bag of tricks for efficient text classification, Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, pp. 427–431, 2017.
50. Zhou, X. and Zafarani, R., Fake news: A survey of research, detection methods, and opportunities, ACM Comput. Surv. 1, 1, Article 1, pp. 1–37, 2020.
51. Aggarwal, A., Rajadesingan, A., Kumaraguru, P., Phishari: automatic real-time phishing detection on twitter, in: eCrime Researchers Summit (eCrime), IEEE, pp. 1–12, 2012.
52. Yardi, S., Romero, D., Schoenebeck, G. et al., Detecting spam in a twitter network. First Monday, 15, 1, pp. 1–4, 2009.
53. O’Donovan, J., Kang, B., Meyer, G., Hollerer, T., Adalii, S., Credibility in context: An analysis of feature distributions in twitter, in: Privacy, Security, Risk and Trust (PASSAT), 2012 international conference on and 2012 international conference on social computing (SocialCom), IEEE, pp. 293–301, 2012.
54. Gupta, A., Kumaraguru, P., Castillo, C., Meier, P., Tweetcred: Real-time credibility assessment of content on twitter, in: International Conference on Social Informatics, Springer, pp. 228–243, 2014.
- *Corresponding author: [email protected]