
3
A Collaborative Data Publishing Model with Privacy Preservation Using Group-Based Classification and Anonymity
Carmel Mary Belinda M. J.*, K. Antonykumar, S. Ravikumar and Yogesh R. Kulkarni
Dept. of Computer Science and Engineering, Vel Tech Rangarajan Dr. Sagunthala R & D Institute of Science and Technology, Avadi, India
Abstract
The security of privacy is currently a field of critical importance in data mining. Organizations and corporations in this dynamic environment are constantly trying to somehow get the database of their competitors. A detailed review of such databases can be done to retrieve a variety of confidential and sensitive information, links, connections, inferences, and findings. It can implicitly or explicitly cause a major loss to the database owner. The owners of the database sell their data to third parties for money. If a database is not held until it is revealed to a third party, then the data owner can suffer disasters. We consider the issue of collective publication of data to anonymize horizontally separated data on multiple data providers. The proposed work discusses and contributes to this new challenge of data publishing. First, we introduce the notion of group-based classification, which guarantees that the anonymized data satisfies a given privacy constraint against any group of data providers. We present a collaborative data publishing model with privacy preservation for efficiently checking in a group of records. Privacy preservation can be used to identify abnormal behavior in data sharing. Many privacy-preserving data publishing techniques were developed but failed to consider the data set because of its complexity and domain specific nature. Various organizations release information about persons in public for resource sharing. But maintaining the confidentiality of individual information is a difficult task with various data releases from multiple organizations where coordinating before data publication. The proposed model is compared with traditional models and the results depicts that proposed model exhibits better performance.
Keywords: Data publishing, privacy preservation, classification, anonymity, optimization, data mining
3.1 Introduction
The data publisher is a person in charge of applying PPDM techniques to privacy databases. It should be a trusted individual to publish data. Data publisher must be familiar with sensitive knowledge and rules in advance [2]. It is evaluated at the publisher’s end from all angles before it opens a database for mining purposes to various data users/miners. Data publisher is responsible for the publication of data to allow others to use it easily [11]. Data publishers change their databases to keep confidential information unrevealed to miners. Publisher must spend considerable time building or restructuring the database before sending it to miners/users [17]. The database is not revealed in the original database. All preventive measures should be taken to avoid the leakage of sensitive information prior to publishing the miner’s database. Publisher analyzes the whole database and tries to hide from the database all of the sensitive information, patterns, and inferences. Two types of privacy, personal privacy and collective privacy, are of major concern [13].
Individuals or the organizations may produce data which is collected through various sources for analysis in repository [19]. Data owner may release the collected data to public for analysis or research purposes with good intention. If some intruders access this data, then it may be combined with some external data which is available publicly to get the personal information. To solve this, the data owner releases masked data in such a way to maintain the confidentiality of individuals and data utility [16]. Even this masked data may be linked with external data to disclose confidential information about the individual [18]. The data collection and publishing model is depicted in Figure 3.1.
On the off chance that authority needs to distribute gathered information either freely or to the diggers for information investigation reason without revealing the private subtleties of the delicate information [24]. In such cases, conservation of security might be achieved by anonymizing the records prior to delivering [21]. Security preserving data mining at information distributing is named as privacy preserving data publishing (PPDP). It has been seen that straightforwardly eliminating ascribes that expressly perceive clients is not ordered as compelling measure [12]. Miners can actually perceive by utilizing and delicate traits and semi-identifiers (QIDs). QID is a non-touchy property or a bunch of traits that do not straightforwardly recognize a client, however when it contrasted or joined and information from different sources to unveil the mystery of a record, distinguished as linkage assaults. In an information base, anonymization of records can be carried out by utilizing diverse security models [20]. These models are useful to make secret the character of record’s proprietor by apply one, or a combination of information disinfecting strategies is utilized.

Figure 3.1 Data collection and publishing model.
Data containing personal data from distributed databases are increasingly needed for sharing. In the healthcare field, for example, there is also a national agenda in developing the National Health Information Network (NHIN) 1 for the sharing of health information with hospitals and other providers [29]. Data analysis protection and publication have, in recent years, received considerable attention as promising approaches to data sharing while safeguarding the personal privacy [10]. The data provider, for example, in a hospital, publishes in a non-interactive model a sanitized “version of the data”, at the time, providing data users with usefulness (for example, researchers) and the protection of data privacy (for example, patients) for individuals represented in the data [23].
Huge information is a moving exploration documented these days because of the advancement of web and computerized climate [28]. Zeroing-in on issues identified with enormous information, treatment of the huge data set has been simplified by distributed computing [25]. The cloud climate helps 1,000,000 clients everywhere on the world to store, oversee, and recover data. One of the significant difficulties engaged with information distributing is protection. Applications, like clinics, bank, government records, and interpersonal interaction destinations do not wish to unveil the data content [30]. Consequently, these applications utilize the choice emotionally supportive network and, in this way, dealt with large information productively. For building the choice help, enormous information should be gathered from the Information Providers (IPs) [22]. Since the information associated with preparing is high, getting the security of every information is troublesome. Prior to pronouncing the information to be public, it is important to conceal the delicate data substance, and this can be alluded to as PPDP. A few works have contributed toward the PPDP, despite the fact that the harmony among security and utility is not accomplished [26].
Information proprietor should utilize great security model and encryption procedures for keeping unique data set secure. In any case, there are a few cases wherein information proprietors need to offer their data sets to others for bringing in cash through it [6]. All things considered they should recruit an information distributer to make changes in the current data set, with the goal that private data in the first data set remaining parts concealed to the information client/excavator. Information publisher ought to be a trustable individual in light of the fact that toward the finish of examination measure information distributer has a deep understanding of the subtleties of the data set, essential data, and productive outcomes broke down from the data set. Digger/client gets some information about data set to the information proprietor or distributer for examination reason, then, at that point, distributer ought to be sufficiently shrewd to take choices in this matter. Prior to trading, data set to the excavator delicate data ought to be ensured. Distributer needs to invest abundant measure of energy to plan or remake the data set prior to sending it to excavator/client. So, most delicate data and deductions drawn from unique data set remaining parts protected after conveyance of data sets to different diggers. Measure of protection conservation relies upon the sort of data sets and level of affectability of the data contained in the first information base [14]. PPDM techniques ought to guarantee a guaranteed level of protection while amplifying the utility of the data set to take into account proficient information mining.
3.2 Literature Survey
Yang, K et al. [1] examined about information order in which information is partitioned into delicate and non-touchy items. Non-sensitive items are those which are prepared to move to the beneficiary with no security saving. Delicate items are those which require protection safeguarding. Different procedures like ordinary mode and touchy mode are talked about. In critical cases assuming delicate data is required, access system and the mode are changed from typical to touchy in which touchy data is likewise accessible.
Jyothi, M et al. [3] explored different spaces of security safeguarding information mining information mining and calculations. Techniques are talked about for conveyed security safeguarding digging and for on a level plane and in an upward direction parceled information. Issue of debasing the viability of the procedures identified with information mining is likewise examined. The paper likewise discusses number of various applications in which protection safeguarding information mining could assume a significant part. An introductory part on the techniques to preserve privacy such as suppression, randomization, summarization, and cryptography is focused. It also discusses the maintenance of data quality while using techniques for protecting privacy. Application fields for privacy protection are also discussed. A case in which two parties had confidential databases was discussed by Ilavarasi, A.K. et al. [4]. If the both parties decide to run a data mining algorithm on their databases, then the database of both parties will be merged, with no secret information disclosed. The work is to safeguard and distribute confidential information for mining purposes on both sides. For secure multi-party calculation, the requirement for a more efficient protocol was necessary.
J. Zhang et al. [5] addressed data mining related privacy issues in broad way. Author also pointed out different approaches that can facilitate to protect sensitive information. It also introduced about four different types of users concerned to area of data mining applications. These are data provider, data collector, data miner, and decision maker. Privacy concerns related to each type of user and the methods that can be used to protect sensitive information at each user level are also discussed. Liabilities of different users are assigned with respect to security of sensitive information.
Huang Xuezhen et al. [8] studied several techniques available for PPDP. An algorithm has been proposed in this paper which focuses on the privacy preservation of anonymous database. This algorithm after preserving the individual privacy does the classification of the data into some pre-specified categories and also checks the classification efficiency. Purpose of the proposed algorithm is to preserve the privacy in such a way after doing reconstruction of the anonymous database, it will not lost its fruitfulness and can be used by the receiver to draw conclusions from it and do classifications on that database.
A new collaborative framework is designed by Lei Xu et al. [9] using vertically partitioned cooccurrence matrices in fuzzy co-cluster structure estimation. In collaborative framework, the cooccurrence information between the objects and the items are stored in many sites. For the distributed data sets, exclusive of information leaks, a privacy preserving procedure is designed in fuzzy clustering for categorical multivariate data (FCCM). A large integer data set shared vertically with two parties [7]. The secured computing divides kth and (k + 1)th while collecting the additional information.
3.3 Proposed Model
Hiding of the sensitive items and rules provides the data publishing in private manner without any restrictions and loss of accuracy. But, algorithm takes large amount of time for optimal hiding. Optimization techniques used to hide the sensitive item sets and for minimizing the side effects while publishing the sensitive items and rules. Optimization preserves the high confidential privacy rules for enhancing the privacy rate of sensitive rules. Optimization technique determines the maximum number of transactions deleted for hiding the sensitive item sets. Though, the privacy preserving accuracy remained unaddressed. Data perturbation–based techniques are used to provide the higher privacy accuracy when hiding the sensitive items and rules. The ensuring of sensitive information and rules for data publishing was not considered. The general problem is that the data publishing complexity arises on hiding the highly confidential data.
The data privacy preservation uses the significant interests in data mining techniques. Data publishing in PPDM suggests a new threats and challenges to the individual privacy and organizational confidentiality. Security is a serious problem while hiding the sensitive rules in data publishing. Several protocols are designed to provide the secure rule hiding for improving the privacy preservation accuracy. Secure mining is a key technique for hiding sensitive rules in order to realize the privacy protection in the data publishing environment. Though, the mining technique provides higher computational costs and logarithmic communication overhead when encryption takes place [27]. Efficient encryption approach is designed to support the sensitive data hiding process. The resultant hiding data is unclear in the encryption model.
Let T = {t1, t2, …} be a set of records with the same attributes gathered from n data providers P = {P1, P2, …, Pn}, such that Ti ⊆ T are records provided by Pi. Let AS be a sensitive attribute with a domain DS. If the records contain multiple sensitive attributes then, we treat each of them as the sole sensitive attribute, while remaining ones we include to the quasi-identifier. However, for our scenarios, we use an approach, which preserves more utility without sacrificing privacy [15]. Let D be the micro data table to be published, which contains n number of attributes, the attributes are represented as follows:
A tuple t € D that is represented as t = (t[a1], t[a2], …, t[an]) where t[ai] is the ai value of t.
The value of each attribute is considered for correlation measurement. A tuple is represented as where is the value of t. Initially, a number of attributes are extracted from the micro data table D. The value of each attribute is selected for correlation measurement. Pearson’s correlation coefficient is broadly used for evaluating correlation between two continuous attributes.
The formula for Pearson’s correlation coefficient (r) is mathematically expressed as follows:

The privacy fitness score is defined as the minimum fitness score of privacy constraints. In our example, scoreFC is defined as follows:

Minimum distance between si points and sj centroids is not always same as the distance between sj points and si centroids. Thus, distance between si and sj is computed using mean of these two values:
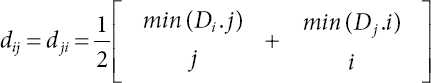
where Di:j is the jth column of Di and Dj:i is ith column of Dj.
Calculate the weight function of every data owner based on the resources allotted and the task to be completed. The weights are calculated as follows:
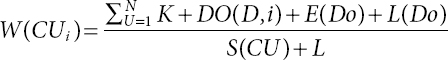
The data transferred by every node is calculated as follows:

Here, Tot is the total data packets, and Tr is the transmitted data packets. σn is the total data packets count transferred by the neighboring nodes in an organization.
The logarithmic functions are calculated for reducing the iterations done on the record set of a data set for providing security before publishing. It is calculated as follows:
The similar records are identified and grouped as a cluster with minimum iterations and is calculated as follows:

In an iterative setting, the “output” of the algorithm is not merely necessary but includes all intermediate results generated and exchanged during the optimization process. Check the data transmitted and data received levels and perform the calculations based on trust factor Tf as
if (TF < β) where β is the Threshold Trust factor.
Data loss is calculated as follows:

The similarity of the data that is gathered and published is calculated as follows:
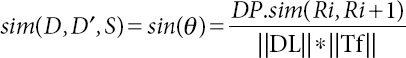
The data publishing rate is calculated as follows:

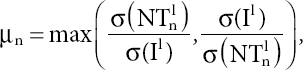
3.4 Results
The proposed model is implemented in python using ANACONDA. The training and testing data sets are merged from the adult data set considered. Records with missing values have been removed. All remaining 45,222 records have been randomly distributed among n providers. As a sensitive attribute AS, we chose occupation with 14 distinct values. The comparison of classification accuracy of proposed model over dLink model and other methods is depicted in Table 3.1.
The classification accuracy of the proposed model is depicted with the traditional models and the accuracy of the proposed model is high when compared to traditional models. Figure 3.2 depicts the accuracy levels of the proposed and traditional models.
The comparison of the privacy preservation rate is depicted in Figure 3.3. The privacy preservation rate of the proposed model is high when compared to traditional methods.
The data publishing security level of the proposed model is depicted in Figure 3.4. The security level for the data publishing is more in the proposed model when compared to traditional models.
Although the data publishing methods eliminate the discovering information like name, disease, and salary but other attributes like gender, age, and zip code are associated to recognize the individual and confidential information. The large amount of data is obtainable, and it is possible to determine more information about individuals from public data.
Table 3.1 Classification accuracy.
| Data set record size | Classification accuracy levels (%) | |||||
| Adult data set | Spain census data set | |||||
| Proposed model | Dlink model | t-closeness | Proposed model | Dlink model | t-closeness | |
| 10,000 | 89 | 78 | 67 | 86 | 75 | 65 |
| 20,000 | 91 | 79 | 69 | 86 | 76 | 66 |
| 30,000 | 91.5 | 82 | 73 | 88 | 78 | 67.5 |
| 40,000 | 93 | 81 | 75 | 89.5 | 79.5 | 69 |
| 50,000 | 95 | 84 | 79 | 91 | 82 | 71.5 |

Figure 3.2 Classification accuracy.

Figure 3.3 Comparison of privacy preservation rate.

Figure 3.4 Data publishing security level.
Hence, people are aware of the privacy interruptions on their personal data and are very reluctant to distribute their sensitive information. In addition, various organizations release the information about persons in public for resource sharing. But the confidential information of an individual may be compromising with the various data releases.
3.5 Conclusion
Privacy-preserving data publishing is a method for preserving the privacy and utility and preventing the attack during data transmission and publication. The objective of the privacy is discussed as sharing of information in a controlled way. It is an efficient method to distribute anonymous data and ensure privacy against identity disclosure rate of an individual. Securing the privacy of the data in an organization by developing the optimization-driven anonymization is developed in this work. The proposed model introduces a group-based classification for performing classification and also for privacy preservation. The proposed anonymization scheme developed the anonymization database by choosing the optimal values for the anonymization. Based on the fitness, the proposed model develops the anonymized database with high utility and privacy. Experimentation of the proposed model with the group-based classification is done by evaluating the database. Several organizations release information about individuals in public for resource sharing as per law of the country. But the confidential information of an individual may be affected by several composition attacks through the various releases of data. An effective method is introduced for improving the privacy and reducing the composition attacks in data sharing. The sensitive attributes are sorted to measure the distance between the sensitive values for reducing the information loss.
References
1. Yang, K., Zhang, K., Jia, X., Hasan, M.A., Shen, X.S., Privacy Preserving Attribute-Keyword Based Data Publish-Subscribe Service on Cloud Platforms. Inf. Sci., 387, 116–131, 2017.
2. Hua, J., Tang, A., Pan, Q., Choo, K.K.R., Ding, H., Ren, Y., Practical–Anonymization for Collaborative Data Publishing Without Trusted Third Party. Secur. Commun. Netw., 2017, 9532163, 10, 2017.
3. Jyothi, M. and Rao, M.C.S., Preserving the Privacy of Sensitive Data Using Data Anonymization. Int. J. Appl. Eng. Res., 12, 8, 1639–1663, 2017.
4. Ilavarasi, A.K. and Sathiyabhama, B., An Evolutionary Feature Set Decomposition Based Anonymization for Classification Workloads: Privacy Preserving Data Mining. Cluster Comput., 20, 4, 3515–3525, 2017.
5. Zhang, J. et al., On Efficient and Robust Anonymization for Privacy Protection on Massive Streaming Categorical Information. IEEE Trans. Dependable Secure Comput., 14, 5, 507–520, Sept.-Oct. 1, 2017.
6. Wu, X., Zhu, X., Wu, G.Q., Ding, W., Data Mining With Big Data. IEEE Trans. Knowl. Data Eng., 26, 1, 97–107, 2014.
7. Yang, J., Liu, Z., Jia, C., Lin, K., Cheng, Z., New Data Publishing Framework in the Big Data Environments, in: Proceedings of IEEE International Conference on P2P, Parallel, Grid, Cloud, and Internet Computing, pp. 363–366, 2014.
8. Xuezhen, H., Jiqiang, L., Zhen, H., Jun, Y., A New Anonymity Model for Privacy-Preserving Data Publishing, in: Communications System Design, pp. 47–59, 2014.
9. Xu, L., Jiang, C., Wang, J., Yuan, J., Ren, Y., Information Security in Big Data: Privacy and Data Mining. IEEE Access, 2, 1149–1176, 2014.
10. Xu, Y., Ma, T., Tang, M., Tian, W., A Survey of Privacy Preserving Data Publishing Using Generalization and Suppression. Int. J. Appl. Math. Inf. Sci., 8, 3, 1103–1116, 2014.
11. Fung, B., Wang, K., Chen, R., Yu, P., Privacy-Preserving Data Publishing: A Survey of Recent Developments. ACM Comput. Surv., 42, 1–53, 2010.
12. Liu, P. and Li, X., An Improved Privacy Preserving Algorithm for Publishing Social Network Data, in: Proceedings of International Conference on High-Performance Computing and Communications & Embedded and Ubiquitous Computing, IEEE Computer Society, pp. 888–895, 2013.
13. Tang, J., Cui, Y., Li, Q., Ren, K., Liu, J., Buyya, R., Ensuring Security and Privacy Preservation for Cloud Data Services. ACM Comput. Surv., 49, 1, 13.1–13.39, 2016.
14. Zakerzadeh, H., Aggarwal, C.C., Barker, K., Privacy-Preserving Big Data Publishing, in: Proceedings of the 27th International Conference on Scientific and Statistical Database Management, ACM, p. 26, 2015.
15. Martin, K., Wang, W., Agyemang, B., Efran: Efficient Scalar Homomorphic Scheme on MapReduce for Data Privacy Preserving, in: Proceedings of IEEE International Conference on Cyber Security and Cloud Computing, ACM, pp. 66–74, 2016.
16. Fung, B.C.M., Wang, K., Yu, P.S., Anonymizing Classification Data for Privacy Preservation. IEEE Trans. Knowl. Data Eng., 19, 5, 711–725, May 2007.
17. Xiao, X. and Tao, Y., Anatomy: Simple and Effective Privacy Preservation, in: Proc. of 32nd Int‘l Conf. Very Large Data Bases (VLDB ‘06), pp. 139–150, 2006.
18. Goswami, P. and Madan, S., Privacy Preserving Data Publishing and Data Anonymization Techniques: A Review, in: Proceedings of IEEE International Conference on Computing, communication and Automation, pp. 139–142, 2017.
19. Allard, T., Nguyen, B., Pucheral, P., METAP: Revisiting Privacy Preserving data Publishing Using Secure Devices. Distrib. Parallel Database, 32, 2, 191–244, 2014.
20. Jaina, I., Jain, V.K., Jain, R., Correlation Feature Selection Based Improved-Binary Particle Swarm Optimization for Gene Selection and Cancer Classification. Appl. Soft Comput., 62, 203–215, 2018.
21. Sabin Begum, R. and Sugumar, R., Novel Entropy-Based Approach for Cost-Effective Privacy Preservation of Intermediate Datasets in Cloud. Clust. Comput., 22, 9581–9588, 2017, https://doi.org/10.1007/s10586-017-1238-0.
22. Komninos, N. and Junejo, A.K., Privacy Preserving Attribute-Based Encryption for Multiple Cloud Collaborative Environment, in: Proceedings of IEEE/ACM 8th International Conference on Utility and Cloud Computing, pp. 595–600, 2015.
23. Fahad, A., Tari, Z., Almalawi, A., Goscinski, A., PPFSCADA: Privacy Pre-Serving Framework for SCADA Data Publishing. Future Gener. Comput. Syst., 37, 496–511, 2014.
24. Wang, H., Privacy-Preserving Data Sharing in Cloud Computing. J. Comput. Sci. Technol., 25, 3, 401–414, 2010.
25. Dwork, C., Differential Privacy: A Survey of Results, in: Proc. of the 5th Intl. Conf. on Theory and Applications of Models of Computation, pp. 1–19, 2008.
26. Fung, B.C.M., Wang, K., Chen, R., Yu, P.S., Privacy-Preserving Data Publishing: A Survey of Recent Developments. ACM Comput. Surv., 42, 14:1–14:53, June 2010.
27. Dwork, C., A Firm Foundation for Private Data Analysis. Commun. ACM, 54, 86–95, January 2011.
28. Mohammed, N., Fung, B.C.M., Hung, P.C.K., Lee, C., Centralized and Distributed Anonymization for High-Dimensional Healthcare Data. ACM Trans. Knowl. Discovery Data, 4, 4, 18:1–18:33, October 2010.
29. Jiang, W. and Clifton, C., Privacy-Preserving Distributed k-anonymity, in: DBSec, vol. 3654, pp. 924–924, 2005.
30. Jiang, W. and Clifton, C., A Secure Distributed Framework for Achieving k-anonymity. VLDB J., 15, 4, 316–333, 2006.
- *Corresponding author: [email protected]