
For many dimensions, we are not usually worried about changes being made in the underlying system. If a salesperson gets married and their surname changes from "Smith" to "Jones," we just reload the QlikView document and the new surname will appear in the selectors. However, if the same person changes from the inside sales team to the northwest sales team, just updating the data means that sales attributed to that salesperson will no longer get attributed to the correct team.
These changes to the dimensions do not happen very frequently and are called slowly changing dimensions (SCDs). Kimball defines eight different methods of handling SCDs, from Type 0 to Type 7. The first example discussed previously, the change of surname, is an example of Type 1—simply update the value (Type 0 says to use the original value). The second change, where the sales team is updated, should be handled by Type 2—add a new row to the dimension table. Type 1 and Type 2 will be, by far, the most common ways of handling SCDs.
For a full list of the SCD handling types with descriptions, see The Data Warehouse Toolkit or go to http://www.kimballgroup.com/data-warehouse-business-intelligence-resources/kimball-techniques/dimensional-modeling-techniques/.
The rest of this section will talk about Type 2. If we are lucky, either the underlying dataset or the ETL that loads the data warehouse where we are getting our data from will already record start and end dates for the validity of the records, for example, something like the following:
SalesPersonID | Name | Territory | From | To |
|---|---|---|---|---|
1 | Joe Bloggs | NE | 01/01/2009 | |
2 | Jane Doe | Inside | 01/01/2009 | 12/31/2013 |
2 | Jane Doe | NW | 01/01/2014 |
Let's discuss different methods of how we can handle this.
The first method that can be used is just to transform the Type 2 data into Type 1 data and treat it as if the additional records were just updates.
We can use a function in QlikView called FirstSortedValue. The function can be used within a Group By load expression and will return the first value of a field based on the grouped fields and a sort field. Let's look at an example, just using the three rows mentioned previously:
Data: Load * Inline [ SalesPersonID, Name, Territory, From, To 1, Joe Bloggs, NE, 2009-01-01, 2, Jane Doe, Inside, 2009-01-01, 2013-12-31 2, Jane Doe, NW, 2014-01-01, ]; Inner Join (Data) Load SalesPersonID, FirstSortedValue(Distinct Territory, -From, 1) As Territory Resident Data Group by SalesPersonID;
The magic is in the FirstSortedValue function. The parameters are as follows:
The result of this join is shown in the following table:

Of course, this is not what we really want in this situation, and we need to look at further alternatives.
QlikView has a great function called IntervalMatch that works very well in situations where we have start and end dates and we want to match this to a dimension such as a calendar.
To see it in action, let's load some data. First, we will load the tables as separate entities. We should create a unique key in the salesperson table to associate into the fact table. We also need to back-fill the To date with a value if it is blank—we will use today's date:
SalesPerson: Load AutoNumber(SalesPersonID & '-' & Territory & '-' & From, 'SP') As SP_ID, SalesPersonID, Name, Territory, From, If(Len(To)=0, Today(), To) As To Inline [ SalesPersonID, Name, Territory, From, To 1, Joe Bloggs, NE, 2009-01-01, 2, Jane Doe, Inside, 2009-01-01, 2013-12-31 2, Jane Doe, NW, 2014-01-01, ]; Fact: Load * Inline [ OrderDate, SalesPersonID, Sales Value 2013-01-01, 1, 100 2013-02-01, 2, 100 2014-01-01, 1, 100 2014-02-01, 2, 100 ];
Now, this will create a false association:
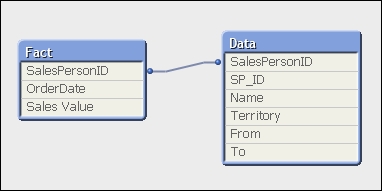
If we do a calculation based on the Sales Person column, we will actually get the correct result:
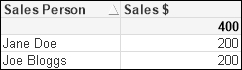
However, if we calculate on Territory, the result is incorrect:

The result actually doesn't look like it makes any sense—although it is perfectly logical if we think about it.
At this stage, we can introduce IntervalMatch:
LinkTable: IntervalMatch(OrderDate, SalesPersonID) Load From, To, SalesPersonID Resident SalesPerson;
This will create a table, called LinkTable, with four fields—OrderDate, SalesPersonID, From, and To—containing the logical association between the order date, sales person, and the from and to dates.
Now, we are not finished because we also have a synthetic key that we should remove. What we need to do is join the SP_ID field from the salesperson table into this link table and then we can join OrderDate, SalesPersonID, and SP_ID from the link table into the fact table. Once that is done, we can drop the link table and also drop SalesPersonID from the fact table (as the association will be on SP_ID).
This will look like the following:
Left Join (LinkTable) Load From, To, SalesPersonID, SP_ID Resident SalesPerson; Left Join (Fact) Load OrderDate, SalesPersonID, SP_ID Resident LinkTable; Drop Table LinkTable; Drop Field SalesPersonID From Fact;
The resulting table structure will look like the following:

The straight table of sales by territory will now look like the following:

The from/to dates that we have in the data source should hopefully be managed by either the source application or an ETL tool. However, sometimes QlikView is the ETL tool, and we need to manage those from/to dates as best we can.
One method we can do is to load the data with a hash key (see Using one of the Hash functions earlier in this chapter) that encapsulates all the field values in each row. We can then store the data to QVD. Using this key, we should be able to detect when the data changes. If it changes, we can then load the new data and add to the data in the QVD.
We can load the initial set of data, with an initial start date, in the following manner:
SalesPerson:
LOAD
Hash256(SalesPersonID, Name, Territory) As HashKey,
SalesPersonID,
Name,
Territory,
'2009-01-01' As From
FROM
[..ScriptsSalesPersonList_Initial.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq);
Store SalesPerson into SalesPerson.QVD;Now, once we have the QVD built, we can have a daily reload process that loads the QVD, loads the current salesperson file, and compares for hashes that don't already exist. If there are a few that don't exist, we can add them with today as the From date in the following manner:
SalesPerson_Temp:
LOAD HashKey,
SalesPersonID,
Name,
Territory,
From
FROM
SalesPerson.QVD
(qvd);
Concatenate (SalesPerson_Temp)
LOAD
Hash256(SalesPersonID, Name, Territory) As HashKey,
SalesPersonID,
Name,
Territory,
Date(Today(), 'YYYY-MM-DD') As From
FROM
[..ScriptsSalesPersonList_Current.txt]
(txt, codepage is 1252, embedded labels, delimiter is ',', msq)
Where Not Exists(HashKey, Hash256(SalesPersonID, Name, Territory));
Store SalesPerson_Temp into SalesPerson.QVD;As long as the data in the current dataset doesn't change, the existing QVD will stay the same. If it does change, the new or updated rows will be added to the QVD.
Now, you may have noticed that I have called the table SalesPerson_Temp. This is because I am not finished with it yet. I need to now calculate the To date. I can do this by sorting the list by salesperson and date, with the date in descending order—that means that the first row for each salesperson will be the most recent date and therefore the To date will be today. On subsequent rows, the To date will be the previous row's From date minus one day:
SalesPerson:
Load
SalesPersonID,
Name,
Territory,
From,
Date(If(Previous(SalesPersonID)<>SalesPersonID,
Today(),
Previous(From)-1), 'YYYY-MM-DD') As To
Resident
SalesPerson_Temp
Order by SalesPersonID, From Desc;
Drop Table SalesPerson_Temp;Now, we have our table with to/from dates that we can use with an interval match as demonstrated in the previous section.