
In Chapter 3, Best Practices for Loading Data, we discussed fast loading using incremental load and binary load.
The fastest way of loading data into QlikView is to use the Binary statement. Binary will load the whole data table, symbol tables, and other data from one QVW file (Qlik Sense can binary load from either a QVW or QVF file).
The fastest way of getting a single table into QlikView is from an optimized load QVD because it contains a data table and symbol table.
In this section, we will explore some other options that we need to be aware of to load data quickly.
This might not fit exactly into a chapter on script, but it is something that we need to be aware of and because the script defines the data size, the compression setting will define the on-disk size of the Qlik file. By default, QlikView will compress a QVW file when saving it using a high compression setting. We can change this so that medium compression is used, or we can turn off compression all together.
The main difference, obviously, is the on-disk size of the resultant file. We need to think about the algorithm that is being used to create the compression. It will require additional time for the file to be compressed. For smaller QVW files, this is not really a consideration. However, as the files begin to grow more than 1 GB or more, the compression takes longer and longer and this might become an issue for timings of reloads. For example, a 5 GB application might, depending on the hardware, take 5 minutes or so to compress and save. The same document, when saved without compression, might only take seconds. This is especially a consideration when saving to a network drive.
To change the settings for a particular QlikView document, navigate to Settings | Document Properties | General | Save Format:
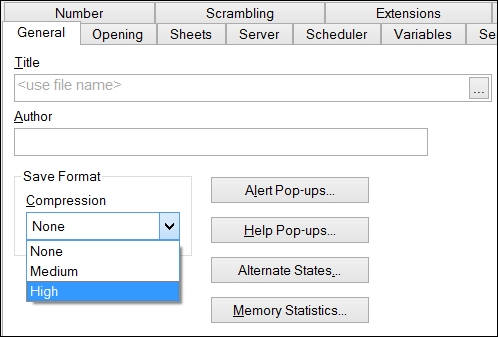
We can also specify this setting at a user level for the creation of new documents, in Settings | User Preferences | Save:

If disk space is not an issue, then there is probably no real benefit in allowing compression for larger applications. The applications will save quicker without it. For smaller applications, there is little difference in time.
Obviously, if we are binary loading the data from a QVW that has been compressed, then there will be that extra step of having to decompress the data. The fastest way of getting data into QlikView is by binary loading from an uncompressed QVW on very fast hardware—solid state disks are the best. We always need to balance the speed requirements with the disk space overhead.
We have already discussed how the quickest way of loading a table of data is from a QVD file. This load will be listed in the script execution dialog box as (qvd optimized):

If we perform any additional calculations on this QVD data as it is being loaded—for example, adding additional fields based on QlikView functions, performing most where clauses, and so forth—then the optimized load will be lost and a normal, row-by-row, data load processing will be performed. Of course, if the QVD files are local to your reload engine (either the server or desktop), then that reload will still be quite fast.
There are a few things that we can do when loading QVDs that make sure that as optimal a load as possible will happen.
The only things that we can do to a QVD load that will retain the optimization are:
- Rename fields with the
Asstatement - Use a
Where ExistsorWhere Not Existsclause
The second option here is interesting because we know that a normal Where clause will cause a nonoptimized load. Therefore, if we can think of a way to use existing data, or perform a load of a temporary table that we can use with the Exists clause to keep the optimization.
For example, if we are loading some sales order detail lines into a data model in which we have already restricted the sales order headers, we can use an Exists clause on the ID field that associates them:
SalesOrderHeader: Load * From SalesOrderHeader.qvd (qvd) Where Match(Year,2013,2014); SalesOrderLine: Load * From SalesOrderLine.qvd (qvd) Where Exists(OrderID);
In fact, we can replace the Where clause in the header table by preloading the years that we want in a temporary table:
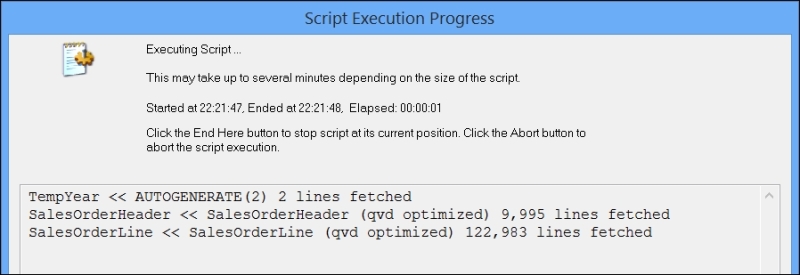
TempYear: Load 2012+RowNo() As Year AutoGenerate(2); SalesOrderHeader: Load * From SalesOrderHeader.qvd (qvd) Where Exists(Year); //Where Match(Year,2013,2014); SalesOrderLine: Load * From SalesOrderLine.qvd (qvd) Where Exists(OrderID); Drop Table TempYear;
If we look at the script execution dialog, we will see that the QVDs are optimized in loading:
Let's imagine a scenario where we want to load sales information from Sales.QVD and then concatenate budget information from Budget.QVD. The script might look like this:
Fact: Load DateID, SalesPersonID, CustomerID, ProductID, SalesQty, SalesValue From Sales.QVD (QVD); Concatenate (Fact) Load DateID, SalesPersonID, CustomerID, ProductID, BudgetQty, BudgetValue From Budget.QVD (QVD);
In this example, the Sales.QVD file will load optimized because we are not making any changes to it. The Budget.QVD file will not load optimized because it is being appended to the existing table and they do not have the same fields, so QlikView has some work to do.
What happens here is that QlikView will initially load a data table and symbol tables to accommodate the sales information. When we concatenate the budget information, there might be some additional entries into the symbol table but there will be a significant change to the data table, which will have to be widened to accommodate the index pointers for new fields. This change will be barely noticeable on a load of records measured in thousands, but if we have many millions of rows in one or both of the QVDs, then the delay will be significant.
If we were to take a step back and assuming an ETL approach is in place, when generating the QVDs, we should use the null() function to add the fields into the Sales table from the Budget table and add the fields into the Budget table into the Sales table, then both QVDs will load optimized. For example, in the transformation script, we might have code like this:
Sales: Load DateID, SalesPersonID, CustomerID, ProductID, SalesQty, SalesValue, Null() As BudgetQty, Null() As BudgetValue From SalesSource.QVD (QVD); Store Sales into Sales.QVD; Drop Table Sales; Budget: Load DateID, SalesPersonID, CustomerID, ProductID, BudgetQty, BudgetValue, Null() As SalesQty, Null() As SalesValue From BudgetSource.QVD (QVD); Store Budget into Budget.QVD; Drop Table Budget;
Then, when loading into the final document we can do this:
Fact: Load * From Sales.QVD; Load * From Budget.QVD;
Both QVDs will load optimized.