
As part of an effort to control underage students' drinking of alcoholic beverages at a university, the institution required each student to fill out an anonymous online survey on the topic. The students' demographical information was gathered (sex, age, major, credits completed, current GPA, and so on), as well as responses to questions such as "Do you think it is okay to consume alcohol if you are underage", "Have you ever consumed alcoholic beverages on campus", and so on. A file of the results of the survey was provided in comma-delimited format (CSV).
Following the procedure outlined previously (to tune data), the first step is to load the file into Watson.
As in our previous examples, from the Welcome page, click on Add and then on Upload data:

Then click on Browse:

The next step is to review the data quality. Once we have our file loaded into Watson, we can see that the overall data quality is HIGH, with a score of 77:

Since the score shown is the overall file score, it is advisable to open the file in refinement mode and review the particular fields we are interested in.
Click on the file and then click on Refine:

In Refine, you can see the columns (circled) that you are perhaps interested in. Even though the quality of the data is High Quality, you can see that some columns contain 22% missing values:

Additionally, if you scroll through the columns of data, you'll find that the Sex column has only medium data quality and a score of 67 (see the next image):

If you click on the column header, you'll discover that the column actually contains five unique values: Male, Female, M, F and blank. They are illustrated in the following screenshot:

In this example, we will assume that blanks are invalid responses, and we should exclude all records from our analysis that contain blank as a value for the Sex field. Sometimes, you may want to further scrutinize blank values to determine whether a blank is a non-response, meaning it's a refusal to respond to a survey question. This may be a factor in predicting a specific outcome. Moving on, we will also assume that M means Male and F means Female, and the records should be considered valid and included as part of our analysis.
To prove a point, let's use IBM SPSS modeler to extend our Watson analysis by addressing the issues identified with the Sex field in our file.
To begin with, if we assume that we are going to periodically receive new student survey files (all in the same format), why not set up a process to run the file through that will evaluate identified issues with our data?
After opening modeler, I create a new stream, WatsonStudentSurvey.str. Next, to import our file, I include a var file source node. This node automatically reads data from delimited column text files, and all I'll do is browse to the filename and click on OK, as shown here:

Next, I'll add the record ops node named Select. With this node, you can create a logical condition to include or exclude records. I'll use this node to drop all records in my file that have a blank value for the Sex column. On this node, I add the logic condition as Sex="". Next, I click on Discard for the mode. Then I click on OK, as shown in the following image:

The third node to be used in our little example is the field ops node, Reclassify. This node will be used to reclassify the M and F values in the Sex field (as Male and Female, respectively). This requires only a few simple steps:
- Select Sex under Reclassify field.
- Indicate the original values, M and F.
- Indicate the new values, Male and Female.
- Click on OK.
Shown in the following screenshot:

The final node will be export node Flat File. This node will be used to export our updated file back to a CSV to be imported to Watson. For this node, I can indicate the name and location for modeler to write to and then click on OK:

The connected nodes in our data tuning stream are as follows:

After uploading our tuned file, we see that the new file has a better overall file data quality score:

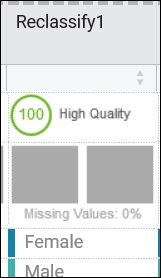
In refine page, we can locate our new column (the modified Sex column named Reclassify1) and see that its data quality score is 100:
With this simple example, you can see how SPSS modeler can be used to extend Watson with an external, automated data tuning process. In our example, we addressed a single column of data, but this can easily be adapted to address just about any issue in any column of your file.
Back in Watson, running a prediction on our file produces (perhaps) a few interesting insights:
