
And now we come to the moment of truth. How does any of this apply to my code? In order to answer this question, we are going to use the open source Encog machine learning framework for our next demonstration. You can download our sample project following the instructions for the web location of the files for the book. Please make sure you have it loaded and open in Visual Studio before proceeding:

We are going to create a sample application that will demonstrate replacing back propagation with Particle Swarm Optimization. If all goes well, from the outside looking in you will not notice a difference.
You will be able to run this sample out of the box and follow along. We will be using the XOR problem solver, but instead of using back propagation it will be using the Particle Swarm Optimization we've been discussing. Let's dig a little deeper into the code. The following is the data that we will be using to implement this example:
/// Input for the XOR function.
public static double[][] XORInput = {new[] {0.0, 0.0},new[] {1.0, 0.0},new[] {0.0, 1.0},new[] {1.0, 1.0}};
/// Ideal output for the XOR function.
public static double[][] XORIdeal = {new[] {0.0},new[] {1.0},new[] {1.0},new[] {0.0}};
Pretty straightforward.
Now let's look at the sample application itself. The following is how the XORPSO implementation is done:
///Create a basic training data set using the supplied data shown above
IMLDataSet trainingSet = new BasicMLDataSet(XORInput, XORIdeal);
///Create a simple feed forward network
BasicNetworknetwork = EncogUtility.SimpleFeedForward(2, 2, 0, 1, false);
///Create a scoring/fitness object
ICalculateScore score = new TrainingSetScore(trainingSet);
///Create a network weight initializer
IRandomizer randomizer = new NguyenWidrowRandomizer();
///Create the NN PSO trainer. This is our replacement function from back prop
IMLTrain train = new NeuralPSO(network, randomizer, score, 20);
///Train the application until it reaches an error rate of 0.01
EncogUtility.TrainToError(train, 0.01);
network = (BasicNetwork)train.Method;
///Print out the results
EncogUtility.Evaluate(network, trainingSet);
When we run this sample application here is what it looks like. You will notice that it appears exactly like the normal XOR sample from the outside looking in:
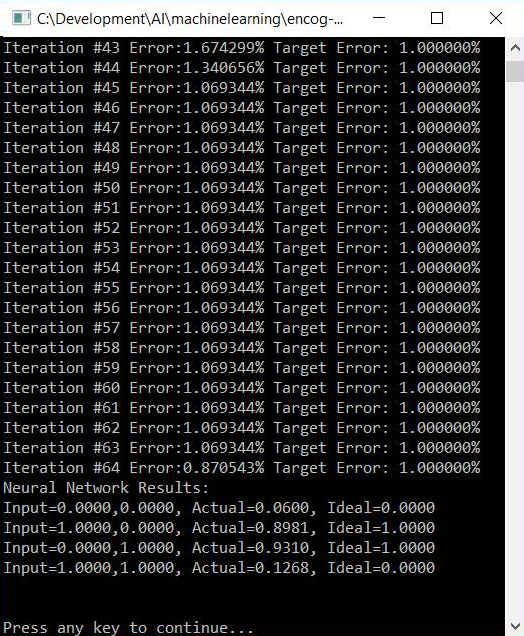
You will notice that, when training is completed, we are very close to our ideal scores.
Now let's talk about the internals. Let's look at some of the internal variables used to make this work. The following is where you will see why we spent time early on with our basic theory. It should all be familiar to you now.
Declare the variable m_populationSize. A typical range is 20 - 40 for many problems. More difficult problems may need a much higher value. It must be low enough to keep the training process computationally efficient:
protected int m_populationSize = 30;
This determines the size of the search space. The positional components of particle will be bounded to [-maxPos, maxPos]. A well chosen range can improve the performance. -1 is a special value that represents boundless search space:
protected double m_maxPosition = -1;
This maximum change one particle can take during one iteration imposes a limit on the maximum absolute value of the velocity components of a particle, and affects the granularity of the search. If too high, particles can fly past the optimum solution. If too low, particles can get stuck in local minima. It is usually set to a fraction of the dynamic range of the search space (10% was shown to be good for high dimensional problems). -1 is a special value that represents boundless velocities:
protected double m_maxVelocity = 2;
For c1, cognitive learning rate >= 0 (the tendency to return to the personal best position):
protected double m_c1 = 2.0;
For c2, social learning rate >= 0 (tendency to move towards the swarm best position):
protected double m_c2 = 2.0;
Inertia weight, w, controls global (higher-value) versus local exploration of the search space. It is analogous to temperature in simulated annealing and must be chosen carefully or gradually decreased over time. The value is usually between 0 and 1:
protected double m_inertiaWeight = 0.4;
All these variables should be familiar to you. Next, the heart of what we are doing involves the UpdateParticle function, shown as follows. This function is responsible for updating the velocity, position, and personal best position of a particle:
public void UpdateParticle(int particleIndex, bool init)
{
int i = particleIndex;
double[] particlePosition = null;
if (init)
{
Create a new particle with random values (except the first particle, which has the same value as the network passed to the algorithm):
if (m_networks[i] == null)
{
m_networks[i] = (BasicNetwork)m_bestNetwork.Clone();
if (i > 0) m_randomizer.Randomize(m_networks[i]);
}
particlePosition = GetNetworkState(i);
m_bestVectors[i] = particlePosition;
Randomize the velocity:
m_va.Randomise(m_velocities[i], m_maxVelocity);
}
else
{
particlePosition = GetNetworkState(i);
UpdateVelocity(i, particlePosition);
Velocity clamping:
m_va.ClampComponents(m_velocities[i], m_maxVelocity);
New position  :
:
m_va.Add(particlePosition, m_velocities[i]);
Pin the particle against the boundary of the search space (only for components exceeding maxPosition):
m_va.ClampComponents(particlePosition, m_maxPosition);
SetNetworkState(i, particlePosition);
}
UpdatePersonalBestPosition(i, particlePosition);
}
Each particle will need to have its velocity updated, as you can see in the preceding code. This function will use the inertia weight, cognitive, and social terms to compute the velocity of the particle. This function encompasses the standard Particle Swarm Optimization formula as we described in the pseudo-code earlier in this chapter:
protected void UpdateVelocity(int particleIndex, double[] particlePosition)
{
int i = particleIndex;
double[] vtmp = new double[particlePosition.Length];
Standard PSO formula for inertia weight:
m_va.Mul(m_velocities[i], m_inertiaWeight);
Standard PSO formula for cognitive term:
m_va.Copy(vtmp, m_bestVectors[i])
m_va.Sub(vtmp, particlePosition);
m_va.MulRand(vtmp, m_c1);
m_va.Add(m_velocities[i], vtmp);
Standard PSO formula for social term:
if (i != m_bestVectorIndex)
{
m_va.Copy(vtmp, m_pseudoAsynchronousUpdate ? m_bestVectors[m_bestVectorIndex] : m_bestVector);
m_va.Sub(vtmp, particlePosition);
m_va.MulRand(vtmp, m_c2);
m_va.Add(m_velocities[i], vtmp);
}
}
And this is how we substituted Particle Swarm Optimization for the standard backward propagation. Simple, right?