
8.3. Image Features
Before discussing image features, it is important to keep in mind that content-based retrieval does not depend on a complete description of the pictorial content of the image. It is sufficient that a retrieval system presents similar images (i.e., similar in some user-defined sense). The description of the content by image features should serve that goal primarily.
One such goal can be met by using invariance as a tool to deal with the accidental distortions in the image content introduced by the sensory gap. From Section 8.2.2, it is clear that invariant features may carry more object-specific information than other features, as they are insensitive to the accidental imaging conditions such as illumination, object pose, and camera viewpoint. The aim of invariant image features is to identify objects no matter how or from where they are observed, at the loss of some of the information content.
Therefore, the degree of invariance, should be tailored to the recording circumstances. In general, a feature with a very wide class of invariance loses the power to discriminate among object differences. The aim is to select the tightest set of invariants suited for the expected set of nonconstant conditions. What is needed in image search is a specification of the minimal invariant conditions in the specification of the query. The minimal set of invariant conditions can only be specified by the user, as it is part of his or her intention. For each image retrieval query, a proper definition of the desired invariance is in order. Does the applicant wish to search for the object in rotation and scale invariance? illumination invariance? viewpoint invariance? occlusion invariance? The oldest work on invariance in computer vision has been done in object recognition, as reported among others in [119] for shape and [181] for color. Invariant description in image retrieval is relatively new but quickly gaining ground; for a good introduction, see [15, 30, 57].
8.3.1. Color
Color has been an active area of research in image retrieval, more than in any other branch of computer vision. Color makes the image take values in a color vector space. The choice of a color system is of great importance for the purpose of proper image retrieval. It induces the equivalent classes to the actual retrieval algorithm. However, no color system can be considered universal, because color can be interpreted and modeled in different ways. Each color system has its own set of color models, which are the parameters of the color system. Color systems have been developed for different purposes:
display and printing processes: RGB, CMY
television and video transmittion efficiency: YIQ, YUV
color standardization: XYZ
color uncorrelation: I1I2I3
color normalization and representation: rgb, xyz
perceptual uniformity: U*V*W*, L*a*b*, L*u*v*
intuitive description: HSI, HSV
With this large variety of color systems, the inevitable question is which color system to use for which kind of image retrieval application. To this end, criteria are required to classify the various color systems for the purpose of content-based image retrieval.
First, an important criterion is that the color system is independent of the underlying imaging device. This is required when images in the image database are recorded by different imaging devices, such as scanners, cameras, and camrecorders (e.g., images on the Internet). Another prerequisite might be that the color system should exhibit perceptual uniformity, meaning that numerical distances within the color space can be related to human perceptual differences. This is important when images that should be visually similar (e.g., stamps, trademarks, and paintings databases) are to be retrieved. Also, the transformation needed to compute the color system should be linear. A nonlinear transformation may introduce instabilities with respect to noise, causing poor retrieval accuracy. Further, the color system should be composed of color models that are understandable and intuitive to the user. Moreover, to achieve robust image retrieval, color invariance is an important criterion. In general, images and videos are taken from objects from different viewpoints. Two recordings made of the same object from different viewpoints will yield different shadowing, shading, and highlighting cues.
When there is no variation in the recording or in the perception, then the RGB color representation is a good choice. RGB-representations are widely used today. They describe the image in its literal color properties. An image expressed by RGB makes most sense when recordings are made in the absence of variance, as is the case, for instance, for art paintings [72], the color composition of photographs [47], and trademarks [88, 39], where 2D images are recorded in frontal view under standard illumination conditions.
A significant improvement over the RGB-color space (at least for retrieval applications) comes from the use of normalized color representations [162]. This representation has the advantage of suppressing the intensity information and hence is invariant to changes in illumination intensity and object geometry.
Others approaches use the Munsell or the L*a*b*-spaces because of their relative perceptual uniformity. The L*a*b* color system has the property that the closer a point (representing a color) is to another point, the more visually similar the colors are. In other words, the magnitude of the perceived color difference of two colors corresponds to the Euclidean distance between the two colors in the color system. The L*a*b* system is based on the 3D coordinate system based on the opponent theory using black-white L*, red-green a*, and yellow-blue b* components. The L* axis corresponds to the lightness, where L* = 100 is white and L* = 0 is black. Further, a* ranges from red +a* to green –a*, while b* ranges from yellow +b* to blue -b*. The chromaticity coordinates a* and b* are insensitive to intensity and have the same invariant properties as normalized color. Care should be taken when digitizing the nonlinear conversion to L*a*b*-space [117].
The HSV-representation is often selected for its invariant properties. Further, the human color perception is conveniently represented by these color models, where V is an attribute in terms of which a light or surface color may be ordered on a scale from dim to bright. S denotes the relative white content of a color, and H is the color aspect of a visual impression. The problem of H is that it becomes unstable when S is near zero due to the nonremovable singularities in the nonlinear transformation, in which a small perturbation of the input can cause a large jump in the transformed values [62]. H is invariant under the orientation of the object with respect to the illumination intensity and camera direction and hence is more suited for object retrieval. However, H is still dependent on the color of the illumination [57].
A wide variety of tight photometric color invariants for object retrieval were derived in [59] from the analysis of the dichromatic reflection model. They derive for matte patches under white light the invariant color space ![]() , only dependent on sensor and surface albedo. For a shiny surface and white illumination, they derive the invariant representation as
, only dependent on sensor and surface albedo. For a shiny surface and white illumination, they derive the invariant representation as ![]() and two more permutations. The color models are robust against major viewpoint distortions.
and two more permutations. The color models are robust against major viewpoint distortions.
Color constancy is the capability of humans to perceive the same color in the presence of variations in illumination that change the physical spectrum of the perceived light. The problem of color constancy has been the topic of much research in psychology and computer vision. Existing color constancy methods require specific a priori information about the observed scene (e.g., the placement of calibration patches of known spectral reflectance in the scene), which is not feasible in practical situations, [48, 52, 97] for example. In contrast, without any a priori information, [73, 45] use illumination-invariant moments of color distributions for object recognition. However, these methods are sensitive to object occlusion and cluttering, as the moments are defined as an integral property on the object as one. In global methods in general, occluded parts disturb recognition. [153] circumvents this problem by computing the color features from small object regions instead of the entire object. Further, to avoid sensitivity on object occlusion and cluttering, simple and effective illumination-independent color ratios have been proposed by [53, 121, 60]. These color constant models are based on the ratio of surface albedos rather than on recovering the actual surface albedo itself. However, these color models assume that the variation in spectral power distribution of the illumination can be modeled by the coefficient rule or von Kries model, where the change in the illumination color is approximated by a 3 ×× 3 diagonal matrix among the sensor bands and is equal to the multiplication of each RGB-color band by an independent scalar factor. The diagonal model of illumination change holds exactly in the case of narrow-band sensors. Although standard video cameras are not equipped with narrow-band filters, spectral sharpening could be applied [46] to achieve this to a large extent.
The color ratios proposed by [121] are given by ![]() and those proposed by [53] are defined by
and those proposed by [53] are defined by ![]() , expressing color ratios between two neighboring image locations, for C ∊ {R, G, B}, where
, expressing color ratios between two neighboring image locations, for C ∊ {R, G, B}, where ![]() and
and ![]() denote the image locations of the two neighboring pixels.
denote the image locations of the two neighboring pixels.
The color ratios of [60] are given by ![]() , expressing the color ratio between two neighboring image locations, for C1, C2 ∊ {R, G, B}, where
, expressing the color ratio between two neighboring image locations, for C1, C2 ∊ {R, G, B}, where ![]() and
and ![]() denote the image locations of the two neighboring pixels. All these color ratios are device-dependent, not perceptually uniform, and they become unstable when intensity is near zero. Further, N and F are dependent on the object geometry. M has no viewing and lighting dependencies. In [55], a thorough overview is given on color models for the purpose of image retrieval. Figure 8.5 shows the taxonomy of color models with respect to their characteristics. For more information, refer to [55].
denote the image locations of the two neighboring pixels. All these color ratios are device-dependent, not perceptually uniform, and they become unstable when intensity is near zero. Further, N and F are dependent on the object geometry. M has no viewing and lighting dependencies. In [55], a thorough overview is given on color models for the purpose of image retrieval. Figure 8.5 shows the taxonomy of color models with respect to their characteristics. For more information, refer to [55].
Figure 8.5. Overview of the dependencies differentiated for the various color systems. + denotes that the condition is satisfied; − denotes that the condition is not satisfied.

Rather than invariant descriptions, another approach to cope with the inequalities in observation due to surface reflection is to search for clusters in a color histogram of the image. In the RGB histogram, clusters of pixels reflected off an object form elongated streaks. Hence, in [126], a nonpara-metric cluster algorithm in RGB space is used to identify which pixels in the image originate from one uniformly colored object.
8.3.2. Shape
Under the name local shape, we collect all properties that capture conspicuous geometric details in the image. We prefer the name local shape over other characterizations, such as differential geometrical properties, to denote the result rather than the method.
Local shape characteristics derived from directional color derivatives are used in [117] to derive perceptually conspicuous details in highly textured patches of diverse materials. A wide, rather unstructured variety of image detectors can be found in [159].
In [61], a scheme is proposed to automatically detect and classify the physical nature of edges in images using reflectance information. To achieve this, a framework is given to compute edges by automatic gradient thresholding. Then, a taxonomy is given on edge types based upon the sensitivity of edges with respect to different imaging variables. A parameter-free edge classifier is provided, labeling color transitions into one of the following types: shadow-geometry edges, highlight edges, or material edges. In Figure 8.6.a, six frames are shown from a standard video often used as a test sequence in the literature. It shows a person against a textured background playing Ping-Pong. The size of the image is 260 x 135. The images are of low quality. The frames are clearly contaminated by shadows, shading, and interreflections. Note that each individual object-part (i.e., T-shirt, wall, and table) is painted homogeneously with a distinct color. Further, the wall is highly textured. The results of the proposed reflectance based edge classifier are shown in Figure 8.6. For more details, see [61].
Figure 8.6. Frames from a video showing a person against a textured background playing Ping-Pong. From left to right column: original color frame; classified edges; material edges; shadow and geometry edges.

Combining shape and color both in invariant fashion is a powerful combination, as described by [58], where the colors inside and outside affine curvature maximums in color edges are stored to identify objects.
Scale space theory was devised as the complete and unique primary step in preattentive vision, capturing all conspicuous information [178]. It provides the theoretical basis for the detection of conspicuous details on any scale. In [109], a series of Gabor filters of different directions and scale are used to enhance image properties [136]. Conspicuous shape geometric invariants are presented in [135]. A method employing local shape and intensity information for viewpoint and occlusion invariant object retrieval is given in [143]. The method relies on voting among a complete family of differential geometric invariants. Also, [170] searches for differential affine-invariant descriptors. From surface reflection, in [5], the local sign of the Gaussian curvature is computed while making no assumptions on the albedo or the model of diffuse reflectance.
8.3.3. Texture
In computer vision, texture is considered all that is left after color and local shape have been considered, or it is given in terms of structure and randomness. Many common textures are composed of small textons, usually too large in number to be perceived as isolated objects. The elements can be placed more or less regularly or randomly. They can be almost identical or subject to large variations in their appearance and pose. In the context of image retrieval, research is mostly directed toward statistical or generative methods for the characterization of patches.
Basic texture properties include the Markovian analysis dating back to Haralick in 1973 and generalized versions thereof [95, 64]. In retrieval, the property is computed in a sliding mask for localization [102, 66].
Another important texture analysis technique uses multiscale, autoregressive MRSAR-models, which consider texture as the outcome of a deterministic dynamic system subject to state and observation noise [168, 110]. Other models exploit statistical regularities in the texture field [9].
Wavelets [33] have received wide attention. They have often been considered for their locality and their compression efficiency. Many wavelet transforms are generated by groups of dilations or dilations and rotations that have been said to have some semantic correspondent. The lowest levels of the wavelet transforms [33, 22] have been applied to texture representation [96, 156], sometimes in conjunction with Markovian analysis [21]. Other transforms have also been explored, most notably fractals [41]. A solid comparative study on texture classification from mostly transform-based properties can be found in [133].
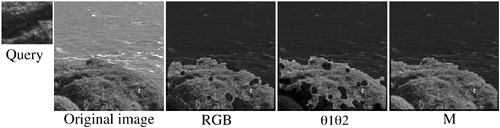
When the goal is to retrieve images containing objects having irregular texture organization, the spatial organization of these texture primitives is, in worst case, random. It has been demonstrated that for irregular texture, the comparison of gradient distributions achieves satisfactory accuracy [122, 130], as opposed to fractal or wavelet features. Therefore, most of the work on texture image retrieval is stochastic in nature [12, 124, 190]. However, these methods rely on gray-value information, which is very sensitive to the imaging conditions. In [56], the aim is to achieve content-based image retrieval of textured objects in natural scenes under varying illumination and viewing conditions. To achieve this, image retrieval is based on matching feature distributions derived from color-invariant gradients. To cope with object cluttering, region-based texture segmentation is applied on the target images prior to the actual image retrieval process. In Figure 8.7, results are shown of color-invariant texture segmentation for image retrieval. From the results, we can observe that RGB and normalized color θ1θ2 is highly sensitive to a change in illumination color. Only M is insensitive to a change in illumination color. For more information, refer to [56].
Figure 8.7. From left to right: query texture under different illumination; target image; segmentation result based on RGB; segmentation result based on variant of rgb; segmentation result based on color ratio gradient M.
Texture search proved also to be useful in satellite images [100] and images of documents [31]. Textures also served as a support feature for segmentation-based recognition [106], but the texture properties discussed so far offer little semantic referent. They are therefore illsuited for retrieval applications in which the user wants to use verbal descriptions of the image. Therefore, in retrieval research, in [104] the Wold features of periodicity, directionality, and randomness are used, which agree reasonably well with linguistic descriptions of textures, as implemented in [127].
8.3.4. Discussion
First of all, image processing in content-based retrieval should primarily be engaged in enhancing the image information of the query, not in describing the content of the image in its entirety.
To enhance the image information, retrieval has set the spotlights on color, as color has a high discriminatory power among objects in a scene, much higher than gray levels. The purpose of most image color processing is to reduce the influence of the accidental conditions of the scene and sensing (i.e., the sensory gap). Progress has been made in tailored color space representation for well-described classes of variant conditions. Also, the application of geometrical description derived from scale space theory will reveal viewpoint-and scene-independent salient point sets, thus opening the way to similarity of images on a few most informative regions or points.
In this chapter, we have made a separation between color, local geometry, and texture. At this point, it is safe to conclude that the division is an artificial labeling. For example, wavelets say something about the local shape as well as the texture, and so may scale space and local filter strategies. For the purposes of content-based retrieval, an integrated view on color, texture, and local geometry is urgently needed, as only an integrated view on local properties can provide the means to distinguish among hundreds of thousands of different images. A recent advancement in that direction is the fusion of illumination and scale invariant color and texture information into a consistent set of localized properties [74]. Also, in [16], homogeneous regions are represented as collections of ellipsoids of uniform color or texture, but invariant texture properties deserve more attention [167, 177]. Further research is needed in the design of complete sets of image properties with well-described variant conditions that they are capable of handling.