
10.4. Vision-Based Interfaces
Vision supports a wide range of human tasks, including recognition, navigation, balance, reading, and communication. In the context of perceptual interfaces, the primary task of computer vision is to detect and recognize meaningful visual cues to communication—that is, to "watch the users" and report on their locations, expressions, gestures, and so on. While vision is one of possibly several sources of information about the interaction to be combined multimodally in a perceptual interface, in this section we focus solely on the vision modality. Using computer vision to sense and perceive the user in an HCI context is often called vision-based interaction, or vision-based interfaces (VBI).
In order to accurately model human interaction, it is necessary to take every observable behavior into account [69, 68]. The analysis of human movement and gesture coordinated with speech conversations has a long history in areas such as sociology, communication, and therapy (e.g., Scheflen and Birdwhistell's Context Analysis [115]). These analyses, however, are often quite subjective and ill-suited for computational analysis. VBI aims to produce precise and real-time analysis that will be useful in a wide range of applications, from communication to games to automatic annotation of human-human interaction.
There is a range of human activity that has occupied VBI research over the past decade; Figure 10.5 shows some of these from the camera's view-point. Key aspects of VBI include the detection and recognition of the following elements:
- -
Presence and location:
Is someone there? How many people? Where are they (in 2D or 3D)? (face detection, body detection, head and body tracking)
- -
Identity:
Who are they? (face recognition, gait recognition)
- -
Expression:
Is a person smiling, frowning, laughing, speaking, ... ? (facial feature tracking, expression modeling and analysis)
- -
Focus of attention:
Where is a person looking? (head/face tracking, eye gaze tracking)
- -
Body posture and movement:
What is the overall pose and motion of the person? (body modeling and tracking)
- -
Gesture:
What are the semantically meaningful movements of the head, hands, body? (gesture recognition, hand tracking)
- -
Activity:
What is the person doing? (analysis of body movement)
Figure 10.5. Some common visual cues for VBI. (a) User presence and identity. (b) Facial expression. (c) A simple gesture. (d) A pointing gesture and focus of attention.

Surveillance and VBI are related areas with different emphases. Surveillance problems typically require less precise information and are intended not for direct interaction but to record general activity or to flag unusual activity. VBI demands more fine-grained analysis, where subtle facial expressions or hand gestures can be very important.
These computer vision problems of tracking, modeling, and analyzing human activities are quite difficult. In addition to the difficulties posed in typical computer vision problems by noise, changes in lighting and pose, and the general ill-posed nature of the problems, VBI problems add particular difficulties because the objects to be modeled, tracked, and recognized are people rather than simple, rigid, unchanging widgets. People change hairstyles, get sunburned, grow facial hair, wear baggy clothing, and in general make life difficult for computer vision algorithms. Robustness in the face of the variety of human appearances is a major issue in VBI research.
The main problem that computer vision faces is an overload of information. The human visual system effortlessly filters out unimportant visual information, attending to relevant details like fast-moving objects, even if they are in the periphery of the visible hemisphere. But this is a very complex computational task. At the low level in human vision, a great deal of preprocessing is done in the retina in order to decrease the bandwidth requirements of the nervous channel into the visual cortex. At the high level, humans leverage a priori knowledge of the world in ways that are not well understood computationally. For example, a computer does not simply know that objects under direct sunlight cast sharp shadows. The difficult question is how to extract only relevant observations from the visual information so that vision algorithms can concentrate on a manageable amount of work. Researchers frequently circumvent this problem by making simplifying assumptions about the environment, which makes it possible to develop working systems and investigate the suitability of computer vision as a user interface modality.
In recent years, there has been increased interest in developing practical vision-based interaction methods. The technology is readily available, inexpensive, and fast enough for most real-time interaction tasks. CPU speed has continually increased following Moore's law, allowing increasingly complex vision algorithms to run at frame rate (30 frames per second, fps). Figure 10.6 shows a history of available clock cycles per pixel of a VGA-sized video stream with a top-of-the-line CPU for the PC market over the last 35 years. Higher processing speeds, as well as the recent boom in digital imaging in the consumer market, could have far-reaching implications for VBI. It is becoming more and more feasible to process large, high-resolution images in near real-time, potentially opening the door for numerous new applications and vision algorithms.
Figure 10.6. CPU processing power over the last 35 years. Each + data point denotes the release of the fastest CPU for the PC market from one of the major manufacturers. Multiple data points per year are shown if one manufacturer released multiple CPUs that year or competing manufacturers' CPUs were released that year. The available clock cycles per pixel per frame of a video stream with 30 full frames per second of size 640 × 480 pixels determine the y-value. The "o" data points describe the cost in U.S. dollars per MHz CPU speed.

Fast, high-resolution digital image acquisition devices and fast processing power are only as effective as the link between them. The PC market has recently seen a revolution in connector standards. Interface speeds to peripheral devices used to be orders of magnitude lower than the connection speed between the motherboard and internal devices. This was largely due to the parallel (32 bits or more) connector structure for internal boards and serial links to external devices. The introduction of Firewire (also called 1394 and i-Link) in 1995 and more recently USB 2.0 pushed interface speeds for peripheral devices into the same league as internal interfaces. While other high-speed interfaces for external devices exist (e.g., ChannelLink), they have not made inroads to the consumer market.
Using computer vision in HCI can enable interaction that is difficult or impossible to achieve with other interface modalities. As a picture is worth a thousand words to a person, a video stream may be worth a thousand words of explanation to a computer. In some situations, visual interaction is very important to human-human interaction—hence, people fly thousands of miles to meet face to face. Adding visual interaction to computer interfaces, if done well, may help to produce a similarly compelling user experience.
Entirely unobtrusive interfaces are possible with computer vision because no special devices must be worn or carried by the user (although special, easily tracked objects may be useful in some contexts). No infrastructure or sensors need to be placed in the interaction space because cameras can cover a large physical range. In particular, no wires or active transmitters are required by the user. A camera operates extremely quietly, allowing input to a computer without disturbing the environment. Also, modern cameras can be very lightweight and compact, well suited for mobile applications. Even in environments unsuitable for moving or exposed parts, cameras can be utilized since a camera can be completely encapsulated in its housing with a transparent window.
The cost of cameras and their supporting hardware and software has dropped dramatically in recent years, making it feasible to expect a large installed based in the near future. Software for image and video processing (e.g., for movie and DVD editing) has entered the consumer market and is frequently preinstalled, bundled with a computer's operating system.
The versatility of a camera makes it reasonable and compelling to use as an interface device. A camera may be used for several different purposes, sometimes simultaneously. For example, a single camera, affixed to a person's head or body, may function as a user interface device by observing the wearer's hands [73]; it can videotape important conversations or other visual memories at the user's request [58]; it can store and recall the faces of conversation partners and associate their names [112]; it can be used to track the user's head orientation [140, 2]; it can guide a museum visitor by identifying and explaining paintings [111].
As a particular example of VBI, hand gesture recognition offers many promising approaches for interaction. Hands can operate without obstructing high-level activities of the brain, such as sentence-forming, thus being a good tool for interface tasks while the user is thinking. Generating speech, on the other hand, is said to take up general-purpose brain resources, impeding the thought process [66]. Hands are very dextrous physical tools, and their capabilities have been quite successfully employed in the HCI context in conjunction with devices such as the keyboard and mouse. Human motor skills are, in many cases, easily trained to execute new tasks with high precision and incredible speeds. With the aid of computer vision, we have the chance to go beyond the range of activities that simple physical devices can capture and instead to let hands gesture with all their capabilities. The goal is to leverage the full range of both static hand postures and dynamic gestures in order to communicate (purposefully or otherwise) and perhaps to command and control. Data gloves accomplish some of this goal, yet they have an unnatural feel and are cumbersome to the user.
10.4.1. Terminology
This subsection reviews the essential terminology relevant to VBI. Current VBI tasks focus on modeling (and detecting, tracking, recognizing, etc.) one or more body parts. These parts could be a face, a hand, a facial feature such as an eye, or an entire body. We will interchangeably call this the object of focus, the feature of attention, or simply the "body part."
Determining the presence (or absence) of an object of focus is the problem of detection and has so far primarily been applied to people detection [43] and face detection [155, 49]. Strictly speaking, the output is binary ("person present" versus "no person present"), but typically the location of the object is also reported. Object localization is sometimes used to describe the special case that the presence of an object is assumed and its location is to be determined at a particular point in time. Registration refers to the problem of aligning an object model to the observation data, often both object position and orientation (or pose). Object tracking locates objects and reports their changing pose over time [43].
Although tracking can be considered as a repeated frame-by-frame detection or localization of a feature or object, it usually implies more than discontinuous processing. Various methods improve tracking by explicitly taking temporal continuity into account and using prediction to limit the space of possible solutions and speed up the processing. One general approach uses filters to model the object's temporal progression. This can be as simple as linear smoothing, which essentially models the object's inertia. A Kalman filter [63] assumes a Gaussian distribution of the motion process and can thus also model nonconstant movements. The frequently used extended Kalman filter (EKF) relieves the necessity of linearity. Particle filtering methods (or sequential Monte Carlo methods [34], and frequently called condensation [55] in the vision community) make no assumptions about the characteristics of underlying probability distributions but instead sample the probability and build an implicit representation. They can therefore deal with non-Gaussian processes and also with multimodal densities (caused by multiple, statistically independent sources) such as arise from object tracking in front of cluttered backgrounds. In addition to the filtering approach, different algorithms can be used for initialization (detection) and subsequent tracking. For example, some approaches detect faces with a learning-based approach [139] and then track with a shape- and color-based head tracker [8].
Recognition (or identification) involves comparing an input image to a set of models in a database. A recognition scheme usually determines confidence scores or probabilities that define how closely the image data fits each model. Detection is sometimes called recognition, which makes sense if there are very different classes of objects (faces, cars, and books) and one of them (faces) must be recognized. A special case of recognition is verification or authentication, which judges whether the input data belongs to one particular identity with very high confidence. An important application of verification is in biometrics, which has been applied to faces, fingerprints, and gait characteristics [17].
A posture is a static configuration of the human body—for example, sitting and thinking or holding a coffee cup or pen. Gestures are dynamic motions of the body or body parts and can be considered as temporally consecutive sequences of postures. Hand and arm gestures in particular are covered extensively in the social sciences literature, especially in conversational and behavioral psychology [36, 69, 86, 87, 108]. As a result, the term gesture often refers to the semantic interpretation associated with a particular movement of the body (e.g., happiness associated with a smile). We limit our attention in this chapter to a mostly syntactic view of gesture and gesture recognition, leaving the difficult problem of semantic interpretation and context [26, 86] to others.
Facial gestures are more commonly called facial expressions. Detecting and tracking facial features are typically the first steps of facial expression analysis, although holistic appearance-based approaches may also be feasible. Subsequent steps try to recognize known expressions (e.g., via FAGS action units [37]) and to infer some meaning from them, such as the emotional state of the human [6, 9].
The parameter set for a rigid body consists of its location (x, y, z) in 3D space and its orientation (rx, ry, rz) with respect to a fixed coordinate frame. Deformable objects such as human faces require many parameters for an accurate description of their form, as do articulated objects such as human bodies. An object's appearance describes its color and brightness properties at every point on its surface. Appearance is caused by texture, surface structure, lighting, and view direction. Since these attributes are view-dependent, it only makes sense to talk about appearance from a given viewpoint.
The view sphere is an imaginary sphere around the object or scene of interest. Every surface point of the sphere defines a different view of the object. When taking perspective into account, the object's appearance changes even for different distances, despite a constant viewing angle. Vision techniques that can detect, track, or recognize an object regardless of the viewing angle are called view-independent; those that require a certain range of viewing angles for good performance, for example, frontal views for face tracking, are called view-dependent.
10.4.2. Elements of VBI
VBI techniques apply computer vision to specific body parts and objects of interest. Depending on the application and environmental factors, it may be most useful to search for or track the body as a whole, individual limbs, a single hand, or an artifact such as a colored stick held by the user. VBI techniques for different body parts and features can complement and aid each other in a number of ways.
Coarse-to-fine hierarchy: Here, in a sequence of trackers targeted to successively more detailed objects, each stage benefits from the results of the previous stage by drastically reducing the search space. For example, whole-body detection limits the search space for face detection. After the face is detected in a scene, the search for particular facial features such as eyes can be limited to small areas within the face. After the eyes are identified, one might estimate the eye gaze direction [129].
Fine-to-coarse hierarchy: This approach works in the opposite way. From a large number of cues of potential locations of small features, the most likely location of a larger object that contains these features is deduced. For example, feature-based face recognition methods use this approach. They first try to identify prominent features such as eyes, nose, and lips in the image. This may yield many false positives, but knowledge about the features' relative locations allows the face to be detected. Bodies are usually attached to heads at the same location: thus, given the position of a face, the search for limbs, hands, and so on, becomes much more constrained and therefore simpler [91].
Assistance through more knowledge: The more elements in a scene that are modeled, the easier it is to deal with their interactions. For example, if a head tracking interface also tracks the hands in the image, although it does not need their locations directly, it can account for occlusions of the head by the hands (e.g., [146]). The event is within its modeled realm, whereas otherwise occlusions would constitute an unanticipated event, diminishing the robustness of the head tracker.
Face tracking in particular is often considered a good anchor point for other objects [135, 24], since faces can be fairly reliably detected based on skin color or frontal view appearance.
Person-level, whole body, and limb tracking
VBI at the person level has probably produced the most commercial applications to date. Basic motion sensing is a perfect example how effective VBI can be in a constrained setting: the scene is entirely stationary, so that frame-to-frame differencing is able to detect moving objects. Another successful application is in traffic surveillance and control. A number of manufacturers offer systems that automate or augment the push button for pedestrian crossings. The effectiveness of this technology was demonstrated in a study [137] that compared the number of people crossing an intersection during the "Don't Walk" signal with and without infrastructure that detected people in the waiting area on the curb or in the crossing. The study found that in all cases these systems can significantly decrease the number of dangerous encounters between people and cars.
Motion capture has frequently been used in the film industry to animate characters with technology from companies such as Adtech, eMotion, Motion Analysis, and Vicon Motion Systems. In optical motion capture, many infrared-reflecting markers are placed on an artist's or actor's body. Typically, more than five cameras observe the acting space from different angles, so at least two cameras can see each point at any time. This allows for precise reconstruction of the motion trajectories of the markers in 3D and eventually the exact motions of the human body. This information is used to drive animated models and can result in much more natural motions than those generated automatically. Other common applications of motion capture technology include medical analysis and sports training (e.g., to analyze golf swings or tennis serves).
Detecting and tracking people passively using computer vision, without the use of markers, has been applied to motion detection and other surveillance tasks. In combination with artificial intelligence, it is also possible to detect unusual behavior, for example in the context of parking lot activity analysis [47]. Some digital cameras installed in classrooms and auditoriums follow a manually selected person or head through pan-tilt-zoom image adjustments. Object-based image encoding such as defined in the MPEG-4 standard is an important application of body tracking technologies.
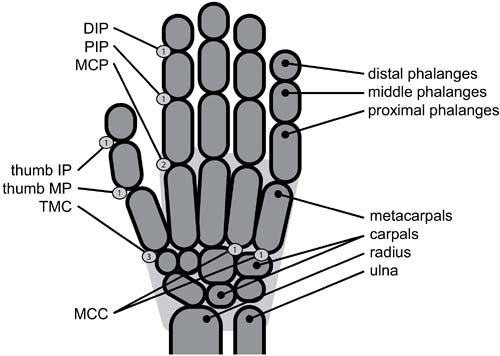
The difficulties of body tracking arise from the many degrees of freedom (DOF) of the human body. Adults have 206 bones, which are connected by over 230 joints. Ball and socket joints such as in the shoulder and hip have three DOFs: They can abduct and adduct, flex and extend, and rotate around the limb's longitudinal axis. Hinge joints have one DOF and are found in the elbow and between the phalanges of hands and feet. Pivot joints also allow for one DOF; they allow the head as well as radius and ulna to rotate. The joint type in the knee is called a condylar joint. It has two DOF because it allows for flexion and extension and for a small amount of rotation. Ellipsoid joints also have two DOF, one for flexion and extension, the other for abduction and adduction (e.g., the wrist's main joint and the metacarpophalangeal joint, depicted in Figure 10.8). The thumb's joint is a unique type, called a saddle joint; in addition to the two DOF of ellipsoid joints, it also permits a limited amount of rotation. The joints between the human vertebrae each allow limited three-DOF motion, and all together they are responsible for the trunk's flexibility.
Figure 10.8. The structure of the hand. The joints and their degrees of freedom: distal interphalangeal joints (DIP, 1 DOF), proximal interphalangeal joints (PIP, 1 DOF), metacarpophalangeal joints (MCP, 2 DOF), metacarpocarpal joints (MCC, 1 DOF for pinky and ring fingers), thumb's interphalangeal joint (IP, 1 DOF), thumb's metacarpophalangeal joint (MP, 1 DOF), and thumb's trapeziometacarpal joint (TMC, 3 DOF).
Recovering the DOF for all these joints is an impossible feat for today's vision technology. Body models for computer vision purposes must therefore abstract from this complexity. They can be classified by their dimensionality and by the amount of knowledge versus learning needed to construct them.
The frequently used 3D kinematic models have between 20 and 30 DOF. Figure 10.7 shows an example in which the two single-DOF elbow and radioulnar joints have been combined into a 2-DOF joint at the elbow. In fact, the rotational DOF of the shoulder joint is often transferred to the elbow joint. This is because the humerus shows little evidence of its rotation, while the flexed lower arm indicates this much better. Similarly, the rotational DOF of the radioulnar joint can be attributed to the wrist. This transfer makes a hierarchical model parameter estimation easier.
Figure 10.7. The "sausage link man" shows the structure of a 3D body model. The links can have cylindrical shape, but especially the trunk is more accurately modeled with a shape with noncircular cross-section.

Most of the vision-based efforts to date have concentrated on detecting and tracking people while walking, dancing, or performing other tasks in a mostly upright posture. Pedestrian detection, for example, has seen methods employed that had previously shown success in face detection, such as wavelets [99] and a combination of depth information and a learning method [162].
Two systems with comprehensive functionality, Pfinder [145] and W4 [48], both show well how computer vision must be tailored to the task and properties of the particular environment. First, they rely on a static camera mounting, which gives the opportunity to model the background and achieve fast and reliable segmentation of moving foreground objects. Second, they make assumptions of the body posture; namely, they expect a mostly upright person. This can be easily distinguished from other moving objects such as cars or windblown objects. Third, heuristics about the silhouettes enable classification of a few typical postures or actions such as carrying an object, making use of the fact that only a small number of scenarios are likely for a person entering the field of view.
Hands
Hands are our most dextrous body parts, and they are heavily used in both manipulation and communication. Estimation of the hands' configuration is extremely difficult due to the high DOF and the difficulties of occlusion. Even obtrusive data gloves[6] cannot acquire the hand state perfectly. Compared with worn sensors, computer vision methods are at a disadvantage. With a monocular view source, it is impossible to know the full state of the hand unambiguously for all hand configurations, as several joints and finger parts may be hidden from the camera's view. Applications in VBI have to keep these limitations in mind and focus on obtaining information that is relevant to gestural communication, which may not require full hand pose information.
[6] Data gloves are gloves with sensors embedded in them that can read out the fingers' flexion and abduction. Their locations and orientations in 3D space are often tracked with supplemental means such as electromagnetic trackers.
Generic hand detection is a largely unsolved problem for unconstrained settings. Systems often use color segmentation, motion flow, and background subtraction techniques, and especially a combination of these, to locate and track hands in images. In a second step and in settings where the hand is the prominent object in view, a shape recognition or appearance-based method is often applied for hand posture classification.
Anatomically, the hand is a connection of 18 elements: the five fingers with three elements each, the thumb-proximal part of the palm, and the two parts of the palm that extend from the pinky and ring fingers to the wrist (see Figure 10.8). The 17 joints that connect the elements have 1, 2, or 3 DOFs. There are a total of 23 DOFs, but for simplicity, the joints inside the palm are frequently ignored, as is the rotational DOF of the trapeziometacarpal joint, leaving 20 DOF. Each hand configuration is a point in this 20-dimensional configuration space. In addition, the hand reference frame has 6 DOF (location and orientation). See Braffort et al. [12] for an exemplary anthropomorphic hand model.
It is clearly difficult to automatically match a hand model to a point in such a high-dimensional space for posture recognition purposes. Lin et al. [80] suggest limiting the search to the interesting subspace of natural hand configurations and motions, and they define three types of constraints. Type I constraints limit the extent of the space by considering only anatomically possible joint angles for each joint (see also earlier work by Lee and Kunii [77]). Type II constraints reduce the dimensionality by assuming direct correlation between DIP and PIP flexion. Type III constraints limit the extent of the space again by eliminating generally impossible configurations and unlikely transitions between configurations. With a 7D space, they cover 95% of configurations observed in their experiments.
An introduction to the state of the art in hand modeling and recognition can be found in a survey by Wu and Huang [152]. One of the early papers that described whole hand tracking and posture classification as real-time input was written by Fukumoto et al. [42]. They moved a cursor around on a projection screen by making a pointing hand posture and moving the hand within a space observed from two cameras. Two different postures can be distinguished (thumb up and down) with various interpretations to control a VCR and to draw. The paper also deals with the problem of estimating the pointing direction. Cutler and Turk [23] use a rule-based system for gesture recognition in which image features are extracted by optical flow. The location and trajectory of the hand(s) constitutes the input to various simple interfaces such as controlling musical instruments. Mysliwiec [94, 107] tracks the hands by detecting the hands anew in every frame based on a skin color model. Then, a simple, hand-specific heuristic is used to classify the posture and find the index fingertip. Freeman and Roth [41] use histograms of edge orientations in hand images to distinguish different gestures. Moghaddam and Pentland [90] apply a density estimation to the PCA-transformed edge images and obtain a scale-invariant shape similarity measure. GREFIT [98] uses fingertip locations in 2D images to deduce possible 3D configurations of view-dependent hand images with an underlying anatomical hand model with Type I constraints. Zhu et al. [163] combine color segmentation with frame differencing to find handlike objects, using higher-level dynamic models together with shape similarity based on image moments to distinguish gestures. They observed that it was easier and more reliable to classify gestures based on their motion trajectory than on finger configurations.
View independence is a significant problem for hand gesture interfaces. Wu and Huang [151] compared a number of classifiers for their suitability to view-independent hand posture classification.
The above approaches operate in the visible light spectrum and do not use any auxiliary aids such as marked gloves. Segmenting the hand from the background is much simplified by using infrared (IR) light. Since the skin reflects near-IR light well, active IR sources placed in proximity to the camera in combination with an IR pass filter on the lens make it easy to locate hands that are within range of the light source. Dorfmüller-Ulhaas and Schmalstieg [32] use special equipment: users must wear gloves with IR-reflecting markers, the scene is illuminated with IR light sources, and a pair of cameras is used for stereo vision. The system's accuracy and robustness are quite high even with cluttered backgrounds. It can deliver the accuracy necessary to grab and move virtual checkerboard figures.
Hand and arm gestures in 4D
The temporal progression of hand gestures, especially those that accompany speech, are generally composable into three stages: pre-stroke, stroke, and post-stroke [86]. The pre-stroke prepares the movement of the hand. The hand waits in this ready state until the speech arrives at the point in time when the stroke is to be delivered. The stroke is often characterized by a peak in the hand's velocity and distance from the body. The hand is retracted during the post-stroke, but this phase is frequently omitted or strongly influenced by the gesture that follows (similar to coarticulation issues in speech processing).
Automatic sign language recognition has long attracted vision researchers. It offers enhancement of communication capabilities for the speech-impaired and deaf, promising improved social opportunities and integration. For example, the signer could wear a head-mounted camera and hand a device to his or her conversation partner that displays the recognized and translated text. Alternatively, a text-to-speech module could be used to output the sign language interpretation. Sign languages exist for several dozen spoken languages, such as American English (ASL), British English, French, German, and Japanese. The semantic meanings of language components differ, but most of them share common syntactic concepts. The signs are combinations of hand motions and finger gestures, frequently augmented with mouth movements according to the spoken language. Hand motions are distinguished by the spatial motion pattern, the motion speed, and in particular by which body parts the signer touches at the beginning, during, or at the end of a sign. The finger configuration during the slower parts of the hand movements is significant for the meaning of the gesture. Usually, uncommon words can be spelled out as a concatenation of letter symbols and then be assigned to a context-dependent symbol for more efficient signing. Trained persons achieve speeds that equal that of conversational speech.
Most computer vision methods applicable to the task of sign language recognition have extracted feature vectors composed of hand location and contour. These feature vectors have their temporal evolution and variability in common with feature vectors stemming from audio data; thus, tools applied to the speech recognition domain may be suited to recognizing the visual counterpart of speech as well. An early system for ASL recognition [127] fed such a feature vector into a hidden Markov model (HMM) and achieved high recognition rates for a small vocabulary of mostly unambiguous signs from a constrained context. However, expansion into a wider semantic domain is difficult; the richness of syntactic signs is a big hurdle for a universal sign language recognition system. The mathematical methods that perform well for speech recognition need adaptation to the specifics of spatial data with temporal variability. What is more, vision-based recognition must achieve precision in two complementary domains: very fast tracking of the position of the hand in 3D space and exact estimation of the configuration of the fingers of the hand. To combine these requirements in one system is a major challenge. The theoretical capabilities of sign language recognition— assuming the computer vision methods are fast and precise enough—can be evaluated with glove-based methods in which research has a longer history (e.g., [93, 79]).
Wu and Huang [150] present a review of recognition methods for dynamic gestures up to 1999. Overall, vision-based hand gesture recognition has not yet advanced to a stage where it can be successfully deployed for user interfaces in consumer-grade applications. The big challenges are robustness, user independence, and some measure of view independence.
Head and Face
Head and face detection and tracking contributes an essential component to VBIs. Heads and faces can safely be presumed to be present and visible for almost all kinds of human tasks. Heads are rarely occluded entirely, and they convey a good deal of information about the human, such as identity and focus of attention. In addition, this is an attractive area of research in computer vision because the appearance variability of heads and faces is limited yet complex enough to touch on many fundamental problems of computer vision. Methods that perform well on head or face detection or tracking may also perform well on other objects. This area of VBI has therefore received the most attention, and its maturity can be observed by the existence of standard evaluation methods (test databases), the availability of software tools, and commercial developments and products. This progress raises the question of whether at least parts of the problem are solved to a degree that computers can satisfactorily perform these tasks.
Applications of the technology include face detection followed by face recognition for biometrics—for example, to spot criminals at airports or to verify access to restricted areas. The same technology can be useful for personalized user interfaces—for example, to recall stored car seat positions, car stereo volume, and car phone speed-dial lists depending on the driver. Head pose estimation and gaze direction have applications for video conferencing. A common problem occurs when watching the video of one's interlocutor on a screen while the camera is next to the monitor. This causes an apparent offset of gaze direction, which can be disturbing if eye contact is expected. Computer vision can be used to correct for this problem [44, 156]. Head tracking has been used for automatically following and focusing on a speaker with fixed-mounted pan/tilt/zoom cameras. Future applications could utilize face recognition to aid human memory, and attempts are already being made to use face detection and tracking for low bandwidth, object-based image coding. Face tracking is usually a prerequisite for efficient and accurate locating of facial features and expression analysis.
Face tracking methods can be characterized along two dimensions: whether they track a planar face or a 3D face and whether they assume a rigid or a deformable face model. The usual tradeoffs apply: a model with more DOFs is harder to register with the image, but it can be more robust. For example, it may explicitly handle rotations out of the image plane. Planar methods can deal with only limited shape and appearance variation caused by out-of-plane rotations, for instance, by applying learning methods. Fixed shape and appearance models such as polygons [130], ellipses [8], cylinders [74], and ellipsoids [84], are efficient for coarse head tracking, especially when combined with other image features such as color [8]. Models that can describe shape and/or appearance variations have the potential to yield more precise results and handle varying lighting conditions and even sideways views. Examples for 2D models are Snakes [147], Eigenfaces [134, 103], active shape models [21] and active appearance models (AAM) [20, 154], Gabor and other wavelets [75, 104, 160, 38], and methods based on independent component analysis (ICA). Three-dimensional model examples are 3D AAM [33], point-distribution models [45, 78], and meshes [27, 157].
The major difficulties for face detection arise from in-plane (tilted head, upside down) and out-of-plane (frontal view, side view) rotations of the head, facial expressions (see below), facial hair, glasses, and, as with all computer vision methods, lighting variation and cluttered backgrounds. There are several good surveys of head and face VBI,[7] including face detection [155, 49], face recognition [153, 46], and face tracking [54].
Facial expression analysis, eye tracking
Facial expressions are an often overlooked aspect of human-human communication. However, they make a rich contribution to our everyday life. Not only can they signal emotions and reactions to specific conversation topics, but on a more subtle level, they also regularly mark the end of a contextual piece of information and help in turn-taking during a conversation. In many situations, facial gestures reveal information about a person's true feelings, while other bodily signals can be artificially distorted more easily. Specific facial actions, such as mouth movements and eye gaze direction changes, have significant implications. Facial expressions serve as interface medium between the mental states of the participants in a conversation.
Eye tracking has long been an important facility for psychological experiments on visual attention. The quality of results of automatic systems that used to be possible only with expensive hardware and obtrusive head-mounted devices is now becoming feasible with off-the-shelf computers and cameras, without the need for head-mounted structures.[8] Application deployment in novel environments such as cars is now becoming feasible.
[8] See, for example, the Arrington Research, Inc. ViewPoint EyeTracker remote camera system (http://www.tobii.se).
Face-driven animation has begun to make an impact in the movie industry, just as motion capture products did a few years earlier. Some systems still require facial markers, but others operate without markers. The generated data is accurate enough to animate a virtual character's face with ease and with a degree of smoothness and naturalness that is difficult to achieve (and quite labor-intensive) with conventional, scripted animation techniques.
Facial expressions in general are an important class of human motion that behavioral psychology has studied for many decades. Much of the computer vision research on facial expression analysis has made use of the Facial Action Coding System (FACS) [37] (see Figure 10.9), a fine-grained classification of facial expressions. It describes on the order of 50 individual action units (AU) such as raising the upper lip, stretching the lips, or parting the lips, most of which are oriented on a particular facial muscle and its movements. Some AUs are combinations of two muscles' movements, and some muscles have more than one AU associated with them if contracting different parts of the muscle results in very different facial expressions. Expressions such as a smile are composed of one or more AU. AU thus do not carry semantic meaning; they only describe physical deformations of skin and facial tissues. FACS was originally developed so that human observers could succinctly describe facial expressions for use in behavioral psychology. While many degrees of freedom allow for precise distinction of even the most subtle facial notions— even distinction between natural and purposefully forced smiles is said to be possible—the high expressiveness also poses additional challenges over less fine-grained classifications, such as the semantics-oriented classification into facial expressions caused by emotions (for example, happiness and anger).
Figure 10.9. Some of the action units of the FACS [37].

For eye tracking, a coarse-to-fine approach is often employed. Robust and accurate performance usually necessitates brief user training and constant lighting conditions. Under these conditions, the eye gaze direction can be accurately estimated despite moderate head translations and rotations.
According to a survey by Donato et al. [31], most approaches to automatic analysis of facial expression are based on either optical flow, global appearance, or local features. The authors reimplemented some of the most promising methods and compared their performance on one data set. Optical flow methods (such as [85]) were used early on to analyze the short-term, dynamical evolution of the face. Naturally, these require an image sequence of the course of a facial expression and do not apply to static images due to the lack of motion information. These methods were found to perform significantly better when the image is not smoothed in a preprocessing step. This leads to the conclusion that small image artifacts are important when it comes to tracking and/or recognizing facial gestures. Another hint that high spatial frequencies contribute positively stems from comparing the performance of Gabor wavelets. Using only high frequencies had a less detrimental effect than using only low frequencies, compared to the baseline of unrestricted Gabor filters.
Approaches using Gabor filters and ICA, two methods based on spatially constrained filters, outperformed other methods such as those using PCA or local feature analysis [102] in the investigation by Donato et al. [31]. The authors conclude that local feature extraction and matching is very important to good performance. This alone is insufficient, however, as the comparison between global and local PCA-based methods showed. Good performance with less precise feature estimation can be achieved with other methods (e.g., [161].
Global methods that do not attempt to separate the individual contributors to visual appearances seem to be ill-suited to model multimodal distributions. Refinement of mathematical methods for computer vision tasks, such as ICA, appears to be promising in order to achieve high accuracy in a variety of appearance-based applications such as detection, tracking, and recognition. Optical flow and methods that do not attempt to extract FACS action units are currently better suited to the real-time demands of VBI.
Handheld objects
Vision-based interfaces that detect and track objects other than human body parts—that is, handheld objects used in interaction—have a high potential for successful commercial development in the transition period from traditional to perceptual interfaces. Tracking such objects can be achieved more reliably than tracking high DOF body parts, and they may be easier to use than freeform gestures. Handheld artifacts can be used in much the same way as one's hands, for example to make pointing gestures, to perform rhythmic commands, or to signal the spatial information content of sign languages. Possible useful objects include passive wands [143], objects with active transmitters such as LEDs,[9] and specially colored objects—in fact, anything that is easily trackable with computer vision methods. An alternative approach to having fixed-mounted cameras and tracking moving objects is to embed the camera in the moving object and recognize stationary objects in the environment or egomotion to enable user interaction. Since detecting arbitrary objects is very hard, fiducials can make this reverse approach practical [72].
[9] Head trackers can utilize this technology to achieve high accuracy and short latencies. One commercial product is the Precision Position Tracker, available at http://www.worldviz.com.
10.4.3. Computer vision methods for VBI
In order for a computer vision method to be suitable for VBI, its performance must meet certain requirements with respect to speed, precision, accuracy, and robustness. A system is said to experience real-time behavior if no delay is apparent between an event (occurrence) and its effect. Precision concerns the repeatability of observations for identical events. This is particularly important for recognition tasks and biometrics: only if the VBI consistently delivers the same result for a given view can this information be used to identify people or scenes. Accuracy describes the deviation of an observation from ground truth. Ground truth must be defined in a suitable format. This format can, for example, be in the image domain, in feature space, or it can be described by models such as a physical model of a human body. It is often impossible to acquire ground-truth data, especially if no straightforward translation from observation to the ground-truth domain is known. In that case, gauging the accuracy of a VBI method may be quite difficult.
Robustness, on the other hand, is easier to determine by exposing the VBI to different environmental conditions, including different lighting (fluorescent and incandescent lighting and sunlight), different users, cluttered backgrounds, occlusions (by other objects or self-occlusion), and nontrivial motion. Generally, the robustness of a vision technique is inversely proportional to the amount of information that must be extracted from the scene.
With currently available hardware, only a very specific set of fairly fast computer vision techniques can be used for truly interactive VBI. One of the most important steps is to identify constraints on the problem (regarding the environment or the user) in order to make simplifying assumptions for the computer vision algorithms. These constraints can be described by various means. Prior probabilities are a simple way to take advantage of likely properties of the object in question, both in image space and in feature space. When these properties vary significantly, but the variance is not random, PCA, neural networks, and other learning methods frequently do a good job in extracting these patterns from training data. Higher-level models can also be employed to limit the search space in the image or feature domain to physically or semantically possible areas.
Frequently, interface-quality performance can be achieved with multimodal or multicue approaches. For example, combining the results from a stereo-based method with those from optical flow may overcome the restrictions of either method used in isolation. Depending on the desired tradeoff between false positives and false negatives, early or late integration (see Figure 10.3) lends itself to this task. Application- and interface-oriented systems must also address issues such as calibration or adaptation to a particular user, possibly at runtime, and reinitialization after loss of tracking. Systems tend to become very complex and fragile if many hierarchical stages rely on each other. Alternatively, flat approaches (those that extract high-level information straight from the image domain) do not have to deal with scheduling many components, feedback loops from higher levels to lower levels, and performance estimation at each of the levels. Robustness in computer vision systems can be improved by devising systems that do not make irrevocable decisions in the lower layers but instead model uncertainties explicitly. This requires modeling of the relevant processes at all stages, from template matching to physical object descriptions and dynamics.
All computer vision methods need to specify two things. First, they need to specify the mathematical or algorithmic tool used to achieve the result. This can be PCA, HMM, a neural network, and so on. Second, the domain to which this tool is applied must be made explicit. Sometimes this will be the raw image space with grayscale or color pixel information, and sometimes this will be a feature space that was extracted from the image by other tools in a preprocessing stage. One example would be using wavelets to find particular regions of a face. The feature vector, composed of the image-coordinate locations of these regions, is embedded in the domain of all possible region locations. This can serve as the input to an HMM-based facial expression analysis.
Edge- and shape-based methods
Shape properties of objects can be used in three different ways. Fixed shape models, such as an ellipse for head detection or rectangles for body limb tracking, minimize the summative energy function from probe points along the shape. At each probe, the energy is lower for sharper edges (in the intensity or color image). The shape parameters (size, ellipse foci, rectangular size ratio) are adjusted with efficient, iterative algorithms until a local minimum is reached. On the other end of the spectrum are edge methods that yield unconstrained shapes. Snakes [67] operate by connecting local edges to global paths. From these sets, paths are selected as candidates for recognition that resemble a desired shape as much as possible. In between these extremes lie the popular statistical shape models, such as the active shape model (ASM) [21]. Statistical shape models learn typical deformations from a set of training shapes. This information is used in the recognition phase to register the shape to deformable objects. Geometric moments can be computed over entire images or alternatively over select points such as a contour.
These methods require sufficient contrast between the foreground object and the background, which may be unknown and cluttered. Gradients in color space [119] can alleviate some of the problems. Even with perfect segmentation, nonconvex objects are not well suited for recognition with shape-based methods, since the contour of a concave object can translate into a landscape with many, deep local minima in which gradient descent methods get stuck. Only near-perfect initialization allows the iterations to descend into the global minimum.
Color-based methods
Compelling results have been achieved merely by using skin color properties, for example, to estimate gaze direction [116] or for interface-quality hand gesture recognition [71]. This is because the appearance of skin color varies mostly in intensity while the chrominance remains fairly consistent [114]. According to Zarit et al. [159], color spaces that separate intensity from chrominance (such as the HSV color space) are better suited to skin segmentation when simple threshold-based segmentation approaches are used. However, some of these results are based on a few images only, while more recent work examined a huge number of images and found an excellent classification performance with a histogram-based method in RGB color space as well [61]. It seems that simple threshold methods or other linear filters achieve better results in HSV space, while more complex methods, particularly learning-based, nonlinear models, do well in any color space. Jones et al. [61] also state that Gaussian mixture models are inferior to histogram-based approaches, which makes sense given the multimodality of random image scenes and the fixed amount of Gaussians available to model this. The CAMShift algorithm (continuously adaptive mean shift) [11, 19] is a fast method to dynamically parameterize a thresholding segmentation that can deal with a certain amount of lighting and background changes. Together with other image features such as motion, patches, or blobs of uniform color, this makes for a fast and easy way to segment skin-colored objects from backgrounds.
Infrared Light: One "color" is particularly well suited to segment human body parts from most backgrounds, and that is energy from the IR portion of the EM spectrum. All objects constantly emit heat as a function of their temperature in form of infrared radiation, which are electromagnetic waves in the spectrum from about 700 nm (visible red light) to about 1 mm (microwaves). The human body emits the strongest signal at about 10 μm, which is called long wave IR or thermal infrared. Not many common background objects emit strongly at this frequency in modest climates; therefore, it is easy to segment body parts given a camera that operates in this spectrum. Unfortunately, this requires very sensitive sensors that often need active cooling to reduce noise. While the technology is improving rapidly in this field, the currently easier path is to actively illuminate the body part with short-wave IR. The body reflects it just like visible light, so the illuminated body part appears much brighter than background scenery to a camera that filters out all other light. This is easily done for short-wave IR because most digital imaging sensors are sensitive this part of the spectrum. In fact, consumer digital cameras require a filter that limits the sensitivity to the visible spectrum to avoid unwanted effects. Several groups have used IR in VBI-related projects (e.g., [113, 32, 133]).
Color information can be used on its own for body part localization, or it can create attention areas to direct other methods, or it can serve as a validation and "second opinion" about the results from other methods (multicue approach). Statistical color as well as location information is thus often used in the context of Bayesian probabilities.
Motion flow and flow fields
Motion flow is usually computed by matching a region from one frame to a region of the same size in the following frame. The motion vector for the region center is defined as the best match in terms of some distance measure (e.g., least-squares difference of the intensity values). Note that this approach is parameterized by both the size of the region ("feature") as well as the size of the search neighborhood. Other approaches use pyramids for faster, hierarchical flow computation; this is especially more efficient for large between-frame motions. The most widely used feature tracking method is the KLT tracker. The tracker and the selection of good features to track (usually corners or other areas with high image gradients) are described by Shi and Tomasi [120]. KLT trackers have limitations due to the constancy assumption (no change in appearance from frame to frame), match window size (aperture problem), and search window size (speed of moving object, computational effort).
A flow field describes the apparent movement of entire scene components in the image plane over time. Within these fields, motion blobs are defined as pixel areas of (mostly) uniform motion—that is, motion with similar speed and direction. Especially in VBI setups with static camera positions, motion blobs can be very helpful for object detection and tracking. Regions in the image that are likely locations for a moving body part direct other computer vision methods and the VBI in general to these "attention areas."
The computational effort for tracking image features between frames increases dramatically with lower frame rates, since the search window size has to scale according to the tracked object's estimated maximal velocity. Since motion flow computation can be implemented as a local image operation that does not require a complex algorithm or extrinsic state information (only the previous image patch and a few parameters), it is suited for on-chip computation. Comprehensive reviews of optical flow methods can be found in Barron et al. [5] and Mitiche and Bouthemy [89].
Texture- and appearance-based methods
Information in the image domain plays an important role in every object recognition or tracking method. This information is extracted to form image features: higher-level descriptions of what was observed. The degree of abstraction of the features and the scale of what they describe (small, local image artifacts or large, global impressions) have a big impact on the method's characteristics. Features built from local image information such as steep gray-level gradients are more sensitive to noise; they need a good spatial initialization and frequently a large collection of those features is required. Once these features are found, they need to be brought into context with each other, often involving an iterative and computationally expensive method with multiple, interdependent, and thus more fragile, stages.
If instead the features are composed of many more pixels, cover a larger region in the image, and abstract to more complex visuals, the methods are usually better able to deal with clutter and might flatten the hierarchy of processing levels (since they already contain much more information than smaller-scale features). The benefits do not come without a price—in this case, increased computational requirements.
Appearance-based methods attempt to identify the patterns that an object frequently produces in images. The simplest approach to comparing one appearance to another is to use metrics such as least-squared difference on a pixel-by-pixel basis (i.e., the lowest-level feature vector). This is not very efficient and is too slow for object localization or tracking. The key is to encode as much information as possible in as small as possible a feature vector—to maximize the entropy.
One of the most influential procedures uses a set of training images and the Karhunen-Loeve transform [65, 81]. This transformation is an orthogonal basis rotation of the training space that maximizes sample variance along the new basis vectors. It is frequently known in the computer vision literature as PCA [59] and is directly related to singular value decomposition (SVD). In the well-known eigenfaces approach, Turk and Pentland [134] applied this method to perform face detection and recognition, extending the work by Kirby and Sirovich for image representation and compression [70]. AAMs [20] encode shape and appearance information in one model, built in a two-step process with PCA. Active blobs [118] are similar to AAM. In these approaches, the observed object appearance steers object tracking by guiding initialization for subsequent frames, similar to the concept of the Kalman filter. During training, a parameterization is learned that correlates observation-estimation error with translational offsets.
A Gabor wavelet is a sine wave enveloped by a Gaussian, modeled after the function of the human visual cortical cell [106, 60, 29, 25]. Wavelets are well suited to encode both spatial and frequency information in a compact, parameterized representation. This alleviates problems of FFT approaches where all local spatial information is lost. Feris et al. [117] showed good face tracking performance with a hierarchical wavelet network, a collection of collections of wavelets. Each feature is represented by a set of wavelets, enabling tracking in the manner of KLT trackers, but comparatively more robust to lighting and deformation changes.
Another approach to learn and then test for common appearances of objects is to use neural networks; however, in some cases their performance (in terms of speed and accuracy) has been surpassed by other methods. One extremely fast detection procedure proposed by Viola and Jones [139] has attracted much attention. In this work, very simple features based on intensity comparisons between rectangular image areas are combined by Adaboosting into a number of strong classifiers. These classifiers are arranged in sequence and achieve excellent detection rates on face images with a low false-positive rate. The primary advantage of their method lies in the constant-time computation of features that have true spatial extent as opposed to other techniques that require time proportional to the area of the extent. This allows for very high-speed detection of complex patterns at different scales. However, the method is rotation-dependent.
A more complete review of appearance-based methods for detection and recognition of patterns (faces) can be found in Yang et al.'s survey on face detection [155].
Background modeling
Background modeling is often used in VBI to account for (or subtract away) the nonessential elements of a scene. There are essentially two techniques: segmentation by thresholding and dynamic background modeling.
Thresholding requires that the foreground object has some unique property that distinguishes it from all or most background pixels. For example, this property can be foreground brightness, so that pixels with values above a particular grayscale intensity threshold are classified as foreground, and values below as belonging to the background. Color restrictions on the background are also an effective means for simple object segmentation. There, it is assumed that the foreground object's color does not appear very frequently or in large blobs in the background scene. Of course, artificial coloring of the foreground object avoids problems induced by wildly varying or unknown object colors—for example, using a colored glove for hand detection and tracking.
Dynamic background modeling requires a static camera position. The values of each pixel are modeled over time with the expectation to find a pattern of values that this pixel assumes. The values may be described by a single contiguous range, or it may be multimodal (two or more contiguous ranges). If the value suddenly escapes these boundaries that the model describes as typical, the pixel is considered part of a foreground object that temporarily occludes the background. Foreground objects that are stationary for a long time will usually be integrated into the background model over time and segmentation will be lost. The mathematics to describe the background often use statistical models with one or more Gaussians [48].
Temporal filtering and modeling
Temporal filtering typically involves methods that go beyond motion flow to track on the object or feature level rather than at the pixel or pattern level. For example, hand and arm gesture recognition (see subsection "Hand and arm gestures in 4D" on page 486) requires temporal filtering.
Once the visual information has been extracted and a feature vector has been built, general physics-based motion models are often used. For example, Kalman filtering in combination with a skeletal model can deal with resolving simple occlusion ambiguities [146]. Other readily available mathematical tools can be applied to the extracted feature vectors, independently of the preceding computer vision computation. Kalman filtering takes advantage of smooth movements of the object of interest. At every frame, the filter predicts the object's location based on the previous motion history. The image matching is initialized with this prediction, and once the object is found, the Kalman parameters are adjusted according to the prediction error.
One of the limitations of Kalman filtering is the underlying assumption of a Gaussian probability. If this is not the case, and the probability function is essentially multimodal, as is the case for scenes with cluttered backgrounds, Kalman filtering cannot cope with the non-Gaussian observations. The particle filtering or factored sampling method, often called condensation (conditional density propagation) tracking, has no implicit assumption of a particular probability function but rather represents it with a set of sample points of the function. Thus, irregular functions with multiple "peaks"—corresponding to multiple hypotheses for object states—can be handled without violating the method's assumptions. Factored sampling methods [55] have been applied with great success to tracking of fast-moving, fixed-shape objects in very complex scenes [76, 28, 14]. Various models, one for each typical motion pattern, can improve tracking, as shown by Isard and Blake [56]. Partitioned sampling reduces the computational complexity of particle filters [82]. The modeled domain is usually a feature vector, combined from shape-describing elements (such as the coefficients of B-splines) and temporal elements (such as the object velocities).
Dynamic gesture recognition (i.e., recognition and semantic interpretation of continuous gestures and body motions) is an essential part of perceptual interfaces. Temporal filters exploit motion information only to improve tracking, while the following methods aim at detecting meaningful actions such as waving a hand for goodbye.
Discrete approaches can perform well at detecting spatio-temporal patterns [51]. Most methods in use, however, are borrowed from the more evolved field of speech recognition due to the similarity of the domains: multidimensional, temporal, and noisy data. Hidden Markov Models (HMMs) [15, 158] are frequently employed to dissect and recognize gestures due to their suitability to processing temporal data. However, the learning methods of traditional HMMs cannot model some structural properties of moving limbs very well.[10] Brand [13] uses another learning procedure to train HMMs that overcomes these problems. This allows for estimation of 3D model configurations from a series of 2D silhouettes and achieves excellent results. The advantage of this approach is that no knowledge has to be hardcoded but instead everything is learned from training data. This has its drawbacks when it comes to recognizing previously unseen motion.
[10] Brand [13] states that the traditional learning methods are not well suited to model state transitions, since they do not improve much on the initial guess about connectivity. Estimating the structure of a manifold with these methods thus is extremely suboptimal in its results.
Higher-level models
To model a human body or its parts very precisely, as is required for computer graphics applications, at least two models are necessary. One component describes the kinematic structure of the skeleton, the bone connections and the joint characteristics. Even complex objects such as the entire human body or the hand can thus—with reasonable accuracy—be thought of as a kinematic chain of rigid objects. The second component describes the properties of the flesh around the bones, either as a surface model or as a volumetric model. Very complex models that even describe the behavior of skin are commonplace in the animation industry. Additional models are frequently used to achieve even greater rendering accuracy, such as models of cloth or hair.
Computer vision can benefit from these models to a certain degree. A structural, anatomical, 3D model of the human body has advantages over a 2D model because it has explicit knowledge of the limbs and the fact that they can occlude each other from a particular view [110]. Given a kinematic model of the human body (e.g., [77]), the task to estimate the limb locations becomes easier compared to the case when the knowledge of interdependency constraints is lacking. Since the locations and orientations of the individual rigid objects (limbs, phalanges) are constrained by their neighboring chain links, the effort to find them in the image decreases dramatically.
It is important for VBI applications to exploit known characteristics of the object of interest as much as possible. A kinematic model does exactly that, as do statistical models that capture the variation in appearance from a given viewpoint or the variation of shape (2D) or form (3D). Often, the model itself is ad hoc; that is, it is manually crafted by a human based on prior knowledge of the object. The model's parameter range is frequently learned from training data.
Higher-level models describe properties of the tracked objects that are not immediately visible in the image domain. Therefore, a translation between image features and model parameters needs to occur. A frequently used technique is analysis by synthesis in which the model parameters are estimated by an iterative process. An initial configuration of the model is back-projected into the image domain. The difference between projection and observation then drives adjustment of the parameters, following another back-projection into the image domain and so forth until the error is sufficiently small (e.g., see Kameda et al. [64] and Ström et al. [130]). These methods lack the capability to deal with singularities that arise from ambiguous views [92]. When using more complex models that allow methods from projective geometry to be used to generate the synthesis, self-occlusion is modeled again and thus it can be dealt with. Stenger et al. [128] use a recently proposed modification of the Kalman filter, the "unscented Kalman filter" [62], to align the model with the observations. Despite speed and accuracy advantages over more traditional approaches, the main drawbacks of all Kalman-based filters is that they assume a unimodal distribution. This assumption is most likely violated by complex, articulated objects such as the human body or the hand.
Particle filtering methods for model adjustment are probably better suited for more general applications because they allow for any kind of underlying distribution, even multimodal distributions. Currently, their runtime requirements are not immediately suitable for real-time operation, but more efficient modifications of the original algorithm are available.
Real-time systems, frame rate, latency, processing pipelines
Most user interfaces require real-time responses from the computer: for feedback to the user, to execute commands immediately, or both. But what exactly does real-time mean for a computer vision application?
There is no universal definition for real-time in computer terms. However, a system that responds to user input is said to operate in real time if the user of the system perceives no delay between action command and action. Hence, real time pertains to a system's ability to respond to an event without noticeable delay. The opposite would be a delayed response, a response after a noticeable processing time. Mouse input, for example, is usually processed in real time; that is, a mouse motion is immediately visible as a mouse pointer movement on the screen. Research has shown that delays as low as 50ms are noticeable for visual output [142, 83]. However, people are able to notice audible delays of just a few milliseconds, since this ability is essential to sound-source localization.
The terms frame rate and latency are well suited to describe a computer vision system's performance. The (minimum, maximum, average) frame rate determines how many events can be processed per time unit. About five frames per second is the minimum for a typical interactive system. The system latency, on the other hand, describes the time between the event occurrence and the availability of the processed information. As mentioned above, about 50ms is tolerable for a system's performance to be perceived as real time.
To illustrate the difference between frame rate and latency, imagine a pipeline of four processors, as shown in Figure 10.10. The first one grabs a frame from the camera and performs histogram normalization. The normalized image frame is input to the second processor, which segments the image into regions based on motion flow and color information, and then outputs the frame to the third processor. This processor applies an AAM for face recognition. The recognized face is input to the last processor, which performs a saliency test and then uses the information to drive various applications. Altogether, this process takes 20ms + 40ms + 50ms + 20ms = 130ms per frame. This is the latency: input is available after 130ms as output. The frame rate is determined by the pipeline's bottleneck, the third processor. A processed frame is available at the system output every 50ms, that is, the frame rate is maximal 20fps.

If the input occurs at a rate higher than 20fps, there are two options for pipelined systems:
The first option is to process every frame. A 10-second input sequence with 30fps, for example, has 300 frames. Thus, it requires 300f/20fps = 15s to process them all. The first frame is available 130ms after its arrival, so the last frame is available as output 5s 130ms after its input. It also means that there must be sufficient buffer space to hold the images; in our example, for 5s * 30fps = 150 frames. It is obvious that a longer input sequence increases the latency of the last frame and the buffer requirements. This model is therefore not suitable to real-time processing.
With the second option, frames are dropped somewhere in the system. In our pipeline example, a 30fps input stream is converted into at most a 20fps output stream. Valid frames (those that are not dropped) are processed and available in at most a constant time. This model is suitable to real-time processing.
Dropping frames, however, brings about other problems. There are two cases: First, there is no buffer available anywhere in the system, not even for partial frames. This is shown on the left-hand side in Figure 10.11. In our example, the first processor has no problems keeping up with the input pace, but the second processor will still be working on the first frame when it receives the second frame 33.3ms after arrival of the first. The second frame needs to be dropped. Then the second processor would idle for 2 * 33.3ms − 40ms = 26.7ms. Similar examples can be constructed for the subsequent pipeline stages.
Figure 10.11. An example of pipelined processing of frames, with and without buffering inside the pipeline. Buffering is indicated with arrows. The example on the right uses feedback from stage 3 to avoid unnecessary processing and increased latency.

Second, frames can be buffered at each pipeline stage output or input. This is shown in the center drawing of Figure 10.11. It assumes no extra communication between the pipeline stages. Each subsequent stage requests a frame as soon as it completed processing one frame, and the preceding stage keeps the latest processed frame around in a buffer until it can replace it with the next processed frame. In the example, the second frame would be buffered for 6.7ms at the transition to the second processor, the third frame for 2 * 40ms − 2 * 33.3ms = 13.3ms, the fourth for 3 * 40ms − 3 * 33.3ms = 20ms, and so on. The highest latency after the second stage would be for every fifth frame, which is buffered for a total of 5 * 40ms − 5 * 33.3ms = 33.3ms before processing. Then, in fact, the next processed frame (frame number 7) is finished being processed already and is sent to stage 3 instead of the buffered frame, which is dropped. These latencies can accumulate throughout the pipeline. The frame rate is maximal (20fps) in this example, but some of the frames' latencies have increased dramatically.
The most efficient method in terms of system latency and buffer usage facilitates pipeline feedback from the later stages to the system input, as shown on the right in Figure 10.11. The feedback is used to adjust every stages' behavior in order to maximize utilization of the most time-critical stage in the pipeline. Alternatively to the scenario shown, it is also possible to buffer frames only buffered before the first stage and feed them into the system with a speed that the pipeline's bottleneck stage can keep up with. This is not shown, but it completely avoids the need for in-pipeline buffering. Note that even in this efficient scenario with pipeline feedback, the increased frame rates in comparison to the leftmost case are bought with an increase in average latency.
Examples of architectures that implement component communication and performance optimizing scheduling are the Quality-Control Management in the DirectShow subsystem of Microsoft's DirectX technology and the Modular Flow Scheduling Middleware [40].
10.4.4. VBI summary
Vision-based interfaces have numerous applications; the potential of VBI has only begun to be explored. But computational power is getting to a stage where it can handle the vast amounts of data of live video streams. Progress has been made in many relevant areas of computer vision; many methods have been demonstrated that begin to provide HCI quality translation of body actions into computer commands. While a large amount of work is still required to improve the robustness of these methods, especially in modeling and tracking highly articulated objects, the community has begun to take steps toward standardizing interfaces of popular methods and providing toolkits for increasingly higher level tasks. These are important steps in bringing the benefits of VBI to a wider audience.
The number of consumer-grade commercial applications of computer vision has significantly increased in recent years, and this trend will continue, driven by ongoing hardware progress. To advance the state of the art of VBI—at the intersection of the disciplines of computer vision and HCI—it is vital to establish evaluation criteria, such as benchmarks for the quality and speed of the underlying methods and the resulting interfaces. Evaluation databases must be made accessible for all components of VBI (such as those already available for faces), both for static images and increasingly dynamic data for real-time video processing.