
Of all the components available in Microsoft SharePoint Server 2010, Enterprise Search has the highest profile and the greatest impact on users. Searching has become a normal part of everyday life. Users utilize Web-based search engines like Bing and Google for both personal and professional needs. Concepts such as keyword searching, advanced searching, and search links are familiar to everyone. In fact, Enterprise Search has become a primary entry point into Microsoft SharePoint—the first place someone goes when trying to find information. If the search engine returns strong results, then users will be satisfied with SharePoint. On the other hand, poor search results can lead to negative opinions of SharePoint overall. Because Enterprise Search plays such a significant role in the success of SharePoint Server 2010, it is important to deploy, configure, and customize it correctly.
Contributing to the complexity of Enterprise Search is the fact that Microsoft includes five different search offerings under the SharePoint 2010 umbrella. The offerings include Microsoft SharePoint Foundation 2010 Search, Microsoft Search Server Express, Microsoft Search Server 2010, Microsoft SharePoint Server 2010, and FAST Search Server 2010 for SharePoint. Each of these offerings is intended for use in different situations, provides different levels of functionality, and has different licensing requirements.
SharePoint Foundation 2010 Search is the search engine that ships with SharePoint Foundation. This search engine works only on a single site collection at a time and cannot index external data sources. This engine is intended for team or departmental installations of SharePoint that do not require Enterprise Search.
Search Server Express is an Enterprise Search product that is freely downloadable. This engine can index external sources and supports search federation. It is intended for organizations that want an Enterprise Search capability but do not require significant scalability.
Search Server 2010 is an Enterprise Search engine that can scale across multiple servers and tens of millions of items. This product is the upgraded version of Search Server Express. It is intended for organizations that need a scalable search engine but are not using SharePoint Server 2010.
SharePoint Server 2010 includes all the capabilities of Search Server 2010, along with the integration of people search, taxonomy, and social networking. This is the Enterprise Search engine that is built into SharePoint Server, and it is the one that most readers will be using. Therefore, this chapter will focus on the overall search architecture and customizations that can be created by developers using SharePoint Server 2010.
FAST Search Server 2010 for SharePoint is the most powerful of all the search offerings. FAST provides scalability beyond any of the other offerings and supports additional customizations and configurations. While a discussion of FAST is beyond the scope of this book, many of the customizations presented in this chapter will also work with the FAST engine.
Traditionally, search engines have been used to return results for a specific user request as a list ranked by relevance. The results might provide some basic information, such as the title of a document or the date of a Web page along with a description, but users typically have had to follow links to see if the item was of interest. More recently, however, this paradigm is being replaced with the concept of a search-based application. A search-based application is a custom application that is written around a search engine.
The value of a search-based application is that it presents search results in an appropriate form and allows the user to operate on the results directly. A good example of a search-based application is the Bing video search. Figure 15-1 shows the results of searching for the term “SharePoint.” You can see that the search results are returned as videos that may be played directly from the page, thus making it significantly easier to locate items of interest.
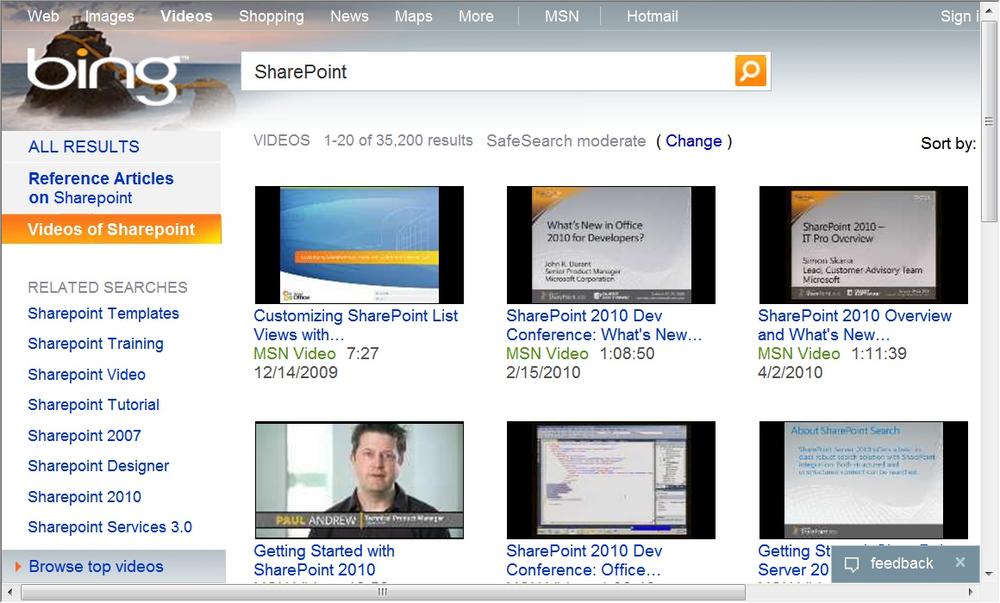
Although the default search results page in SharePoint still displays items in a simple list, you will find that the customization opportunities tend to support the creation of search-based applications. These customizations include the ability to influence the search results’ sort and ranking, change the way search results appear on the page, and create completely custom solutions against the search object model.
The concept of search-based applications is important to keep in mind as you work through this chapter. Instead of simply returning items from a search, give consideration to how the results appear and what operations can be performed. Then think about how the customizations presented in this chapter come into play.
As a quick example of a search-based application in SharePoint, consider the management of tasks for users. Task lists can be created in any site within SharePoint, so it is often the case that someone is assigned tasks in multiple sites. In many cases, users might not even know they have been assigned a particular task. Setting alerts on all the lists is unmanageable because the notifications become a form of internal spam. Thus, users are sometimes left unable to effectively manage their tasks.
In the past, developers have often created “rollups” to solve this problem. Rollup solutions go out to all sites looking for tasks and then display them in a single master list to the user. The problem with this, however, is that it can be very CPU-intensive if done incorrectly. A search-based solution is a better idea.
Instead of a single master list of tasks, imagine that a user goes to a specialized Search Center that runs a query to return all the task items for the current user sorted by due date. In addition, the user can see the key information for each task, such as title, due date, and priority. The user could also operate on the task directly in the search results by changing its status or editing the description. This is a search-based solution that is truly useful to a user. Keep this idea in mind as you learn more about SharePoint Server search.
The search architecture for Microsoft SharePoint Server 2010 is complex. It includes components for crawling and indexing content, administration, and search query execution. Figure 15-2 shows a block diagram of the search architecture.

In the center of the search architecture is the Search Service Application (SSA). The SSA is one of the many shared services available in SharePoint Server. This means that you may create and share instances of the SSA across farms just like any other service application. From the Central Administration website, you may access the SSA by selecting Manage Service Applications. From the list of service applications, you may select the SSA, set its properties, designate administrators, and enter the administration pages. Figure 15-3 shows the SSA in the list of service applications.

Within the SSA are three databases: the Search Service database, the Managed Properties database, and the Crawl database. The Search Service database maintains configuration data for the SSA. The Managed Properties database contains the definitions for Managed Properties that are defined and mapped to crawled properties. The Crawl database contains configuration information related to content sources to be crawled. The SSA also maintains the index file that is built during the crawl and provides support for Federated Search connectors. Each of these components supports search administration, which is accessed by clicking the Manage button for the SSA.
The indexing process is responsible for building the index file. The index file contains properties from content sources, along with access control information that ensures search results display only content for which the user has rights. The process of building the index file involves crawling the designated content sources.
A content source is a repository that you want to search. Content sources can be SharePoint sites, websites, external file systems, Exchange Server public folders, Business Connectivity Services (BCS) External Systems, or other custom repositories. The Index Engine gains access to these repositories through .NET Assembly Connectors and access to the contents of individual items through IFilters.
Chapter 13, presented the fundamentals of .NET Assembly Connectors, which are used by BCS to connect with External Systems. The indexing process uses these same components to connect with content sources. In previous versions of SharePoint, Protocol Handlers were the primary means of connecting with content sources, but they were difficult to create in managed code. In SharePoint 2010, Protocol Handlers are still supported, but .NET Assembly Connectors should be created whenever a custom repository is used as a content source.
Just as in previous versions of SharePoint, IFilters are used to allow the indexing process to access the contents of an item. For example, IFilters allow the indexing process to access the body of Microsoft Office documents so that a full-text search can be performed. While SharePoint 2010 ships with IFilters for Office documents, you may need to install additional IFilters for other types, such as Portable Document Format (PDF) documents. Generally, IFilters are available from the appropriate manufacturer, such as Adobe, and require a simple installation on the server where the indexing process runs.
Once the index file is created, it may be used to support query execution. Query execution begins when a user navigates to the Search Center and enters a query. The query in the Search Center may take the form of a simple keyword or an advanced search with multiple values against multiple Managed Properties.
When the user issues a search, the query is sent to the search engine. Within the search engine, the query processor accepts the query and also retrieves any required information from the Managed Properties database. Information from the Managed Properties database is required any time a query is issued against a specific Managed Property, such as Title. The combination of the user query and Managed Property information is then sent to the query server, which executes the query and returns the results. The results are returned as Extensible Markup Language (XML) to the Search Center where they are formatted using Extensible Stylesheet Language for Transformations (XSLT).
Along with performing a query on its own index, SharePoint can send the query out to other federated search locations. Federated search locations are connections to other search services that independently run the query and return the results separately to the Search Center for display. Communication with federated locations is based on the Open Search protocol, so any search service that supports Open Search can be used as a federated location.
The primary way in which users interact with the search engine is through a set of search Web Parts that ship with SharePoint. These search Web Parts may be used independently, but they are most often used as part of an Enterprise Search site created through a site template. The Enterprise Search template contains Web Parts for issuing queries and returning results. Table 15-1 lists the Web Parts and their purposes.
Table 15-1. Search Web Parts
Web Part | Description |
|---|---|
Allows users to create detailed searches against Managed Properties | |
Displays results from a federated search location | |
Presents facets that can be used to refine a people search | |
Allows users to search for people using a keyword | |
Displays the primary result set from a people search | |
Presents facets that can be used to refine a search | |
Presents queries related to the user’s query | |
Displays links for Really Simple Syndication (RSS), alerts, and Windows Explorer | |
Presents best-bets results | |
Allows users to enter keyword query searches | |
Displays the primary result set from a query | |
Presents statistics such as the time taken to execute the query | |
Provides a summary display of the executed query | |
Displays top results from a federated location |
Each of the Web Parts listed in Table 15-1 is configurable in various ways that are useful when creating search solutions. Furthermore, you can inherit from many of the Web Parts to create your own custom versions. You’ll learn more about customizing these Web Parts later in the chapter.
SharePoint Server 2010 contains two object models to support search. One object model is an administration application programming interface (API) that can be used to perform administrative operations on the SSA. The other is a search object model that can be used to create custom search solutions that execute keyword query and full-text query searches. Object models are covered in the section entitled Working with Keyword Query Syntax later in the chapter.
When users execute queries, they expect to have the most relevant items appear near the top when the results are displayed. The ranking engine is responsible for assigning a ranking score to each returned item based upon a number of factors defined in a ranking model. The ranking model contains the rules that will be applied to the search results and determine ranking. SharePoint Server 2010 ships with several ranking models that are applied when you search different contexts, such as documents or people. You can list all the ranking models available in your environment with the following Windows PowerShell command.
Get-SPEnterpriseSearchServiceApplication | Get-SPEnterpriseSearchRankingModel | Format-List
When you list the ranking models, you will notice that one of them is designated as the default model. This is the model that is used in SharePoint searches out of the box. You’ll also notice that there are several models to support people search and social networking.
The parameters used by the ranking model can be either query-independent or query-dependent. Query-independent parameters are computed at crawl time because they are static and will not change regardless of the query that is run. Query-dependent parameters are computed when the search is executed because they are affected by the search that the user runs. This distinction is important because a ranking model will not be able to gain access to query-independent information if the query is formed in such a way that it fails to access the static information. This can happen when a user forms a query strictly against a Managed Property. In this case, the Managed Property database is accessed, and there is no need for a full search of the index. So for efficiency, the static data is skipped. However, this can give strange results if the ranking model is highly dependent on query-independent factors.
One of the main query-independent parameters that you can affect is the proximity of an item to an authoritative page. An authoritative page is a way of specifying which pages in SharePoint are the most important. Authoritative pages are designated through the search administration interface in Central Administration. When designating authoritative pages, you may specify a page as being either most authoritative, second-level authoritative, third-level authoritative, or non-authoritative. The ranking of an item within search results will be higher based on its click distance from an authoritative page, with different multipliers being used for the various levels. Non-authoritative pages will be pushed to the bottom of the search results.
In previous versions of SharePoint, authoritative pages were the primary way to influence the relevancy of items in search. SharePoint Server 2010, however, supports the concept of a custom ranking model. A custom ranking model allows you to specify query-independent and query-dependent factors that should be used when ranking search results. This gives you a powerful way to influence the display of results within your search-based applications.
Before proceeding to discuss the creation of custom ranking models, it is important to consider the difference between ranking results and sorting results. As discussed previously, ranking results should involve both query-independent and query-dependent factors that influence the order in which results are displayed. Sorting, on the other hand, is always completely static. For example, ranking documents by searching the body for keywords is dynamic and depends on the keyword. Sorting the same documents by creation date will not change no matter what keywords are used in the search. The point is that you should never use a custom ranking model when what you want is a fixed sort.
A custom ranking model is best used in situations where the default ranking model is not returning documents of interest close enough to the top and the introduction of an authoritative page does not solve the problem. This means that you will likely create few custom ranking models, but they can be very useful when necessary. Fixed sorts, on the other hand, can be accomplished using the query object model.
In SharePoint 2010, not all the internal ranking model capabilities are available to your custom ranking models, but there is enough power to have a significant impact on the search results. Custom ranking models are created as XML files that specify the query-independent and query-dependent factors to use when ranking search results. Example 15-1 shows a sample custom ranking model that gives extra weight to the title of an item and Microsoft Word documents. Such a model might be used if an organization’s most important documents are typically in Word format, and the title of the document contains key information.
Example 15-1. A sample custom ranking model
<?xml version='1.0'?>
<rankingModel
name='NewRankingModel'
id='11111111-65CD-4a1b-9A63-F7ECB4B6BB5E'
description = 'Sample ranking model'
xmlns='http://schemas.microsoft.com/office/2009/rankingModel'>
<queryDependentFeatures>
<queryDependentFeature
name='Body' pid='1' weight='10.0000000000'
lengthNormalization='2.8898552470'/>
<queryDependentFeature
name='Title' pid='2' weight='100.0000000000'
lengthNormalization='0.9574077587'/>
<queryDependentFeature
name='Author' pid='3' weight='0.1000000000'
lengthNormalization='1.0131509886'/>
<queryDependentFeature
name='AnchorText' pid='10' weight='0.1000000000'
lengthNormalization='2.6713762088' />
<queryDependentFeature
name='DisplayName' pid='56' weight='0.1000000000'
lengthNormalization='0.9713508040'/>
<queryDependentFeature
name='ExtractedTitle' pid='302' weight='0.1000000000'
lengthNormalization='1.0095022768'/>
<queryDependentFeature
name='QueryLogClickedText' pid='100' weight='0.1000000000'
lengthNormalization='1.6000001537'/>
</queryDependentFeatures>
<queryIndependentFeatures>
<queryIndependentFeature
name='DistanceFromAuthority' pid='96' default='5' weight='0.1000000000'>
<transformInvRational k='0.1359244473'/>
</queryIndependentFeature>
<queryIndependentFeature
name='URLdepth' pid='303' default='3' weight='0.1000000000'>
<transformLinear max='1000'/>
</queryIndependentFeature>
<queryIndependentFeature
name='DocumentPopularity' pid='306' default='0' weight='0.1000000000'>
<transformRational k='1.2170868558'/>
</queryIndependentFeature>
<queryIndependentFeature
name='DocumentUnpopularity' pid='307' default='0' weight='0.1000000000'>
<transformRational k='0.7333557072'/>
</queryIndependentFeature>
<categoryFeature name='FileType' pid='98' default='0'>
<category name='Html' value='0' weight='0.1000000000'/>
<category name='Doc' value='1' weight='100.0000000000'/>
<category name='Ppt' value='2' weight='0.1000000000'/>
<category name='Xls' value='3' weight='0.1000000000'/>
<category name='Xml' value='4' weight='0.1000000000'/>
<category name='Txt' value='5' weight='0.0000000000'/>
<category name='ListItems' value='6' weight='0.1000000000'/>
<category name='Message' value='7' weight='0.1000000000'/>
</categoryFeature>
<languageFeature name='Language' pid='5' default='1' weight='10.0000000000'/>
</queryIndependentFeatures>
</rankingModel>Custom ranking models begin with the rankingModel element. The only required attribute for this element is the id attribute, which is a globally unique identifier (GUID) that identifies the model. The other attributes are optional and are used largely for readability. In addition, the namespace must be called http://schemas.microsoft.com/office/2009/rankingModel. The child elements of the rankingModel are a set of queryDependentFeatures and queryIndependentFeatures, which specify the factors that will be used for dynamic and static ranking, respectively.
The queryDependentFeature element has name, pid, weight, and lengthNormalization attributes. The queryIndependentFeature element has name, pid, default, and weight attributes. The name attribute is optional and is used primarily for readability. The pid is the property identifier for the Managed Property that is being referenced. The weight is a relative attribute that determines the effect that the factor will have on the ranking. The lengthNormalization attribute is a number used to account for differences in the lengths of various properties. The default attribute is the value to be used when an actual value cannot be determined.
The categoryFeature and languageFeature elements are children of the queryIndependentFeature. The categoryFeature element allows you to specify a set of possible values for a Managed Property and give different weights to each one. The languageFeature element gives extra weight to an item if it is in the default language. Finally, the transformRational, transformInvRational, and transformLinear elements associate additional functions with the model that transform the weighting values.
Managed Property identifiers are critical to the creation of custom ranking models because both the queryDependentFeatures and the queryIndependentFeatures can use Managed Properties. When creating custom ranking models, you can choose which Managed Properties you want to include in the model, whether their effect is static or dynamic, and the weight of their impact. To do this, however, you must know the identifier for the Managed Property. You can use the following Windows PowerShell script to list all the Managed Properties and their identifiers.
Get-SPEnterpriseSearchServiceApplication | Get-SPEnterpriseSearchMetadataManagedProperty
SharePoint Server comes with many Managed Properties already defined, but when you are creating search-based applications, you will quite often need to create your own Managed Properties. Managed Properties are created through the search administration interface in the Central Administration site. Essentially, Managed Properties are properties that refer to one or more crawled properties. Managed Properties allow you to group together several different crawled properties that might refer to the same thing and represent them as a single Managed Property. For example, the Managed Property Title refers to the crawled properties Mail:5, People:PreferredName, Basic:displaytitle, and ows_Title. This grouping not only makes it easier to work with several crawled properties at once, it also provides a more readable name.
When creating a custom ranking model, you must set the weights that will be used for each one of the Managed Properties. The weights you apply can be any value, and they are relative to all the other weights in the ranking model. You can also set default values for queryIndependentFeatures if an item does not have the specified Managed Property.
All this means that you can disregard certain properties by setting them to zero or greatly enhance them with a large number relative to the other weighting values. It is important to remember, however, that using very large or very small numbers can overwhelm your model and essentially turn it into a sorting algorithm instead of a ranking model.
Of all the pieces in the custom ranking model, perhaps none is as mysterious as the lengthNormalization attribute. Length normalization is the process of accounting for the length of a string when keywords are found in it. This is necessary because longer strings have a better chance of containing a keyword, but that does not necessarily mean they are more relevant. While the lengthNormalization attribute is required, it can be difficult to know what value to use. As a general guide, examine Example 15-1 earlier in this chapter and you will see that long strings like Body have a number greater than 1, while shorter strings like Title have a value less than 1.
Transforms apply functions to queryIndependentFeatures. These functions use an additional factor as an input to the transformation function. A complete description of the effects of each transformation is beyond the scope of this chapter. Generally, these transforms will not be necessary for simple ranking models.
Once you have created a custom ranking model, you can use it with SharePoint Server. The process of using the custom ranking model involves several steps. First, you must enable any associated Managed Properties for use with the model. Second, you must install the ranking model. Third, you must reference the new model in either a custom solution or existing Web Part. Creating custom solutions is covered later in the chapter. For now, this section will focus on using the custom ranking model with existing search Web Parts.
When you create a custom ranking model, you will quite often be creating new Managed Properties for use in the weighting strategy. Previously, you saw how to get the identifier for a Managed Property so that it could be referenced in the ranking model. However, Managed Properties are not enabled for use as query-independent parameters by default. You must allow it explicitly. So if your model uses a Managed Property as a query-independent feature, you must set the EnabledForQueryIndependentRank property to True. You can set the property using the following Windows PowerShell code, substituting the name of the specific Managed Property for PropertyName in this example.
$p = Get-SPEnterpriseSearchServiceApplication |
Get-SPEnterpriseSearchMetadataManagedProperty -Identity {PropertyName}
$p.EnabledForQueryIndependentRank = $true
$p.UpdateThe next step is to install the custom ranking model. Installing the custom ranking model is accomplished using the Windows PowerShell cmdlet New-SPEnterpriseSearchRankingModel. This cmdlet takes as a parameter the complete ranking model as a string. Therefore, you have to crunch your ranking model into a single piece of text by removing all the line breaks and white space so it can be passed as a parameter. Once this is done, the following Windows PowerShell script will install the new ranking model.
Get-SPEnterpriseSearchServiceApplication |
New-SPEnterpriseSearchRankingModel -RankingModelXML {Crunched Ranking Model}The final step in the process is to reference the custom ranking model in the Search Core Results Web Part. The Search Core Results Web Part displays the primary result set from a search and uses the default ranking model out of the box. However, it has a DefaultRankingModelID property that may be changed to reference the Id of any custom ranking model, such as the required id attribute shown earlier in Example 15-1.
To change the DefaultRankingModelID property, you must navigate to a search results page and place that page in edit mode. Once in edit mode, the Search Core Results Web Part may be exported as an XML file. After exporting the Web Part, you can open it in an editor and search for the DefaultRankingModelID property, which will be empty. When the property is empty, the default ranking model is used. Simply change this value by hand and save it. You may then return to the search page and import the new file as an instance of the Search Core Results Web Part. Deleting the original Web Part from the page completes the process. Now when you search, the new ranking model will be used. The following code shows how the property appears in XML after editing.
<property name="DefaultRankingModelID" type="string"> 0D4CB5B6-2FA3-4D7F-AF79-EF0DE64F242C </property>
The Enterprise Search Center site template is available from the Create dialog for creating new Search Centers. Search Centers are publishing sites that have a Pages library, a Site Pages library, and a Site Assets library. While Search Centers support one-click page creation, most of the time you will add content to the site using one of the four page layouts associated with the Pages library and described in Table 15-2.
Table 15-2. Search Center Page Layouts
The Search Center uses a significantly different interface than any of the other site templates in SharePoint. This is because the Search Center is based on an interface that uses a single tab for each search scope. The page layouts are all designed to support the tab interface, and the site template uses the minimal.master master page to remove the Quick Launch and the Ribbon. Figure 15-4 shows a typical Search Center.
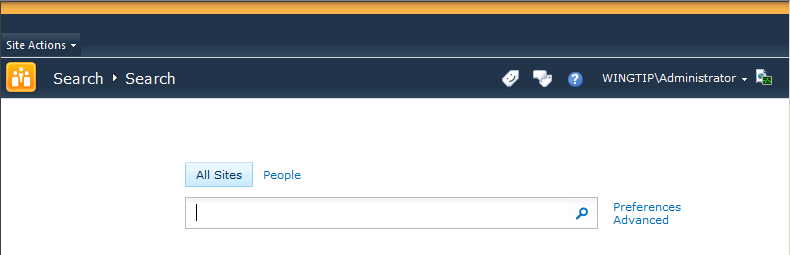
By default, the Search Center has an All Sites tab and a People tab, which correspond to search scopes. What’s interesting—but also potentially confusing—about the Search Center template is that it actually has two sets of tabs. One set is used to render initial tabs before a search is executed, and the other is used to render tabs that appear in the search results. However, both sets of tabs are given the same name to make it appear as though only a single set of tabs exists. The Tabs In Search Pages list contains the first set of tabs, and the Tabs In Search Results list contains the second set of tabs. When you create search-based applications, you will quite often deploy them as new tabs within the Search Center based on custom search scopes. This means that adding a new tab is a multistep process involving the creating of a search scope, page layouts, and tabs.
Creating a search scope is accomplished through the Search Service Application. Within the SSA, you will find a Scopes link, where you may define a new search scope based on Web address, property, or content source. Once defined in the SSA, you can make the scope available to a site collection. This process starts in the Site Collection by browsing to Site Settings, Site Collection Administration, and Search Settings, and then enabling custom scopes, which requires you to enter the Uniform Resource Locator (URL) of the new Search Center. After that, you can go to Site Settings, Site Collection Administration, and Search Scopes, and then decide whether to use the new scope in the Scopes drop-down list.
Once the scope is defined and available, you may go to the Search Center to define search and search results pages. The best way to add the required pages is simply to select View All Site Content from the Site Actions menu in the Search Center. From the All Site Content page, click the Pages library link. Within the Pages library, click the Documents tab and finally the New Document button on the Ribbon, which will present the Create page.
On the Create page, you will see the four different page layouts available for the Search Center. For a typical search-based application, you will create a Search Box page and a Search Results page. The exact names of the pages don’t matter as long as you keep track of them. Typically, however, these pages are named ScopeSearch.aspx and ScopeResults.aspx, with “Scope” replaced in the page name with the actual name of the scope.
Once the pages are created, you can create the associated tabs. Again, the best way to do this is on the All Site Content page. In the Tabs In Search list, create a new tab using the same name as the scope and associate the search page. In the Tabs In Search Results list, create a new tab using the same name as the scope and associate the results page. At this point, you should be able to see the new tab in the Search Center. Creating the tabs and pages is not enough, however, to duplicate the functionality of the other tabs in the Search Center. To have the new scope fully implemented, changes must be made to several Web Parts.
First, a change must be made to the Search box Web Part on both the search and results page. This can be done by simply putting the appropriate page in edit mode and selecting to edit the Search Box Web Part. Under the Miscellaneous category, locate the Target Search Results Page URL and change it to be the name of the results page created earlier. In addition, a change must be made to the Search Core Results Web Part on the results page. In this Web Part, under the Location Properties category, you must enter the name of the scope in the Scope property. After these changes are complete, publish both the search and results pages. The new scope is now available to the Search Center.
The Search Core Results Web Part is central to all search-based applications. You have already seen that altering the DefaultRankingModelID or the Scope property can have a significant impact on the displayed search results. You can also customize which columns to display in the search results and the format of the display. Finally, you can create a custom Web Part that inherits directly from the Search Core Results Web Part to gain access to the query pipeline.
The columns that appear in the search results are specified by the Fetched Properties property, located under the Display Properties category of the Web Part. This property contains an XML chunk that defines which properties should appear in the search results. Example 15-2 shows the default XML contained in the Fetched Properties property.
Example 15-2. The Fetched Properties property
<root xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Columns>
<Column Name="WorkId"/>
<Column Name="Rank"/>
<Column Name="Title"/>
<Column Name="Author"/>
<Column Name="Size"/>
<Column Name="Path"/>
<Column Name="Description"/>
<Column Name="Write"/>
<Column Name="SiteName"/>
<Column Name="CollapsingStatus"/>
<Column Name="HitHighlightedSummary"/>
<Column Name="HitHighlightedProperties"/>
<Column Name="ContentClass"/>
<Column Name="IsDocument"/>
<Column Name="PictureThumbnailURL"/>
<Column Name="ServerRedirectedURL"/>
</Columns>
</root>You can customize the Fetched Properties XML to return different columns. Simply add or remove Column elements from the XML. Note that the column Name must refer to an existing Managed Property. In addition, adding the column to the Fetched Properties XML will not actually cause the column to be displayed in the search results. For this to happen, you must also modify the XSLT used to render the search results.
Search results are returned to the Search Core Results Web Part as XML. This XML is transformed into the display seen in the Search Center by applying the XSLT contained under the Display Properties of the Search Core Results Web Part properties. While you have complete access to this XSLT and can customize it significantly, SharePoint provides no graphical environment for understanding how changes to the XSLT will affect the display of the search results. Fortunately, we can use a combination of SharePoint Designer (SPD) and Microsoft Visual Studio to create and analyze the XSLT.
To begin modifying the XSLT, you must first get a copy of the raw XML sent to the Search Core Results Web Part prior to transformation. The simplest way to do this is to replace the XSLT with a null transformation. Doing so will cause the search results to appear as XML. Be sure that you have created all required Metadata Properties and updated the Fetched Columns before generating the raw XML. Example 15-3 shows the null-transformation XSLT to use.
Example 15-3. Generating raw XML in the search results
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:output method="xml" version="1.0" encoding="utf-8" indent="yes"/>
<xsl:template match="/">
<xmp>
<xsl:copy-of select="*"/>
</xmp>
</xsl:template>
</xsl:stylesheet>After you have a copy of the raw XML generated by the search, you can use it as a basis for creating the desired XSLT. The simplest way to create XSLT is by using SPD. This is because the Data View Web Part accepts an XML file as a data source and will generate XSLT as you use SPD to customize the display.
Start by opening SPD to any site. You will not be keeping any of the pages you create for this exercise, so the exact location of the pages is irrelevant. Once inside SPD, click on the Data Sources object, and then select to add a new XML File Connection from the New group on the Ribbon. Add the raw XML file that you generated from the search results.
Next, add a Web Part page to the site and place it in edit mode. From the edit menu, insert a Data View Web Part based on the raw XML file. Once the Data View Web Part is on the page, you can use the Add/Remove Columns dialog to decide what columns to display. In addition, you can go directly to the source view to make edits to the generated XSLT, which is contained between the XSL tags in the document. Once you have the search results appearing as you want them, simply copy the XSLT out of SPD and into the Search Core Results Web Part.
When users enter a search query, it is passed to the Search Core Results Web Part for execution. Within the Search Core Results Web Part, the QueryManager coordinates the execution of the query and returns the results as XML. This XML is then transformed using the provided XSLT, and the Search Core Results Web Part renders the search results in the Search Center.
In previous versions of SharePoint, the search Web Parts were sealed so that developers had no access to QueryManager. In SharePoint Server 2010, however, developers can inherit from search Web Parts and thus gain access to the query pipeline. This means that developers can manipulate the query before it is executed and manipulate the results after the query is run.
To gain access to the query pipeline, developers inherit from the Search Core Results Web Part. In Visual Studio 2010, a reference must be set to the Microsoft.Office.Server.Search.dll assembly. The Search Core Results Web Part is contained within the Microsoft.Office.Server.Search.WebControls namespace, and the QueryManager object is contained within the Microsoft.Office.Server.Search.Query namespace.
Access to the QueryManager object is obtained by overriding the GetXPathNavigator method. The QueryManager object gives direct access to the submitted query through the UserQuery property. Any manipulation of the query text occurs before the query is executed. This gives you the opportunity to implement search customizations that were not possible in earlier versions of SharePoint. For example, Example 15-4 shows a complete Web Part that manipulates the submitted query by adding an AssignedTo qualifier to the current query. The effect of this change is that the search results will contain only items that are assigned to the current user. To use the custom Web Part, you would simply replace the Core Search Results Web Part on the search results page.
Example 15-4. Manipulating the query text in a custom Web Part
using System;
using System.ComponentModel;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.Web.UI.WebControls.WebParts;
using Microsoft.SharePoint;
using Microsoft.SharePoint.WebControls;
using Microsoft.Office.Server.Search.Query;
using Microsoft.Office.Server.Search.WebControls;
using System.Xml.XPath;
namespace CustomSearchParts.AssignedToMeResults {
public class AssignedToMeResults : CoreResultsWebPart {
protected override XPathNavigator GetXPathNavigator(string viewPath) {
// get reference to Query Manager
QueryManager queryManager =
SharedQueryManager.GetInstance(this.Page).QueryManager;
// Modify User Query
queryManager.UserQuery +=
" AssignedTo:" + SPContext.Current.Web.CurrentUser.LoginName +
" AssignedTo:" + SPContext.Current.Web.CurrentUser.Name;
return base.GetXPathNavigator(viewPath);
}
}
}In addition to gaining access to the QueryManager, developers can access the federated search locations associated with the SSA. Accessing the collection of federated locations opens up additional search customizations through the Location object. For example, Example 15-5 shows a complete Web Part that exposes a RankingModelId property. Earlier in the chapter, the DefaultRankingModelId property was altered by exporting and importing the Search Core Results Web Part. By creating a custom Web Part, you can expose the property directly in the Web Part.
Example 15-5. Modifying properties on federated search locations
using System; using System.ComponentModel; using System.Web.UI; using System.Web.UI.WebControls; using System.Web.UI.WebControls.WebParts; using Microsoft.SharePoint; using Microsoft.SharePoint.WebControls; using Microsoft.Office.Server.Search.Query; using Microsoft.Office.Server.Search.WebControls; using System.Xml.XPath; namespace CustomSearchParts.RankingModelIdResults { public class RankingModelIdResults : CoreResultsWebPart { //Use default ranking model to start private string rankingModelId = "8f6fd0bc-06f9-43cf-bbab-08c377e083f4"; [ Personalizable(PersonalizationScope.Shared), WebBrowsable(true), WebDescription("The ID of the Ranking Model to use"), WebDisplayName("Ranking Model ID"), Category("Configuration") ] public string RankingModelID { get { return rankingModelId; } set { rankingModelId = value; } } protected override XPathNavigator GetXPathNavigator(string viewPath) { try { QueryManager queryManager = SharedQueryManager.GetInstance(this.Page).QueryManager; foreach (LocationList locList in queryManager) { foreach (Location loc in locList) try { loc.RankingModelID = RankingModelID; } catch { } } } catch { } return base.GetXPathNavigator(viewPath); } } }
While users are generally familiar with typing a keyword into the search box to initiate a search, they are not often familiar with the special keyword query syntax supported by SharePoint. Keyword query syntax allows users to enter keywords, phrases, and Managed Property names to create sophisticated searches. In addition, keyword query syntax supports operations and wildcards.
The simplest form of keyword query is to enter a single term, without spaces or punctuation (for example, Training). This form will cause SharePoint to search both the index and the Metadata Properties, returning all matching results. A more sophisticated search would involve multiple keywords, but these must be enclosed in quotations (for example, “Training Materials”).
Required and excluded terms may be added to the query using plus (+) and minus (-) signs. For example, the following query returns results for the term “business” except when it is used in the phrase “Business Connectivity Services” or “Business Intelligence.”
business - "Business Connectivity Services" -"Business Intelligence"
Operators may also be used with keywords. This includes Boolean operators, wildcards, and arithmetic. Boolean operations are done using the AND and OR operators. Wildcards are supported via an asterisk (*). The following examples show a query with a Boolean operator.
"Business Connectivity Services" OR "Business Intelligence"
Managed Properties may also be used as filters for keyword queries. This allows you to create queries that use the full power of the keyword query syntax against specific fields. Table 15-3 shows several keyword queries along with an explanation.
Table 15-3. Keyword Query Samples
Query | Description |
|---|---|
| Returns people whose last name starts with A |
| Returns items whose average rating is greater than zero |
| Returns documents that are related to training |
| Returns items authored by Scot Hillier |
| Returns items containing both “Client” and “Server” |
Along with using keyword query syntax in Search Center, developers may also create custom search Web Parts based on keyword queries. The KeywordQuery class contains the functionality necessary to issue keyword queries programmatically. The KeywordQuery class contains several properties for preparing the query and an Execute method to run the query. The query results are returned as a ResultTableCollection, which contains a collection of IDataReader objects. Example 15-6 shows the basic code for using the class.
Example 15-6. Using the KeywordQuery class
SearchServiceApplicationProxy proxy =
(SearchServiceApplicationProxy)SearchServiceApplicationProxy.GetProxy(
SPServiceContext.GetContext(SPContext.Current.Site));
KeywordQuery keywordQuery = new KeywordQuery(proxy);
keywordQuery.ResultsProvider = SearchProvider.Default;
keywordQuery.ResultTypes = ResultType.RelevantResults;
keywordQuery.EnableStemming = false;
keywordQuery.TrimDuplicates = true;
keywordQuery.QueryText = query;
ResultTableCollection results = keywordQuery.Execute;
ResultTable result = results[ResultType.RelevantResults];
DataTable table = new DataTable;
table.Load(result, LoadOption.OverwriteChanges);
myGrid.DataSource = table;
myGrid.DataBind;To use the KeywordQuery class, you must create an instance that references the SSA proxy. Once the class is created, then you can set the QueryText property with keyword query syntax. Additional properties, such as TrimDuplicates and EnableStemming, allow finer control over the query. When the results are returned, you may process them manually or bind them directly to a control.
Along with keyword queries, you may also create solutions that use Enterprise SQL Search Query syntax. Enterprise SQL Search Query syntax is a full query language that gives you significant control over the executed query. The following code shows a query that returns the documents that were added to the SharePoint portal within the past week.
SELECT url, title, author FROM Scope WHERE "scope" = 'All Sites' AND isDocument=1 AND write >DATEADD(Day,-7,GetGMTDate)
You can see that the Enterprise SQL Search Query syntax is straightforward. The SELECT part is used to designate the columns to return from the query. The FROM part always contains the Scope statement, refined by the WHERE part, which specifies the exact scope to search. The WHERE part also contains the filters to apply. The WHERE part supports arithmetic operators, Boolean operators, and more specific full-text predicates, such as FREETEXT and CONTAINS. FREETEXT matches the meanings of phrases against fields, while CONTAINS does a straight match against the text in a field.
The FullTextSqlQuery class is used to create and issue queries based on the Enterprise SQL Search Query syntax. Using the FullTextQuery class is similar to using the KeywordQuery class. The query is set in the QueryText property, and additional properties are available to refine the search. Like the KeywordQuery class, the FullTextQuery class returns results as a ResultTableCollection. Example 15-7 shows the code to use the FullTextQuery class.
Example 15-7. Using the FullTextSqlQuery class
SearchServiceApplicationProxy proxy = (SearchServiceApplicationProxy)SearchServiceApplicationProxy.GetProxy( SPServiceContext.GetContext(SPContext.Current.Site)); FullTextSqlQuery queryObject = new FullTextSqlQuery(proxy); queryObject.ResultsProvider = SearchProvider.Default; queryObject.ResultTypes = ResultType.RelevantResults; queryObject.EnableStemming = true; queryObject.TrimDuplicates = true; queryObject.QueryText = queryString; ResultTableCollection results = queryObject.Execute;
As mentioned earlier in the chapter, .NET Assembly Connectors replace Protocol Handlers as the mechanism that the indexing engine uses to access various repositories. You can create a .NET Assembly Connector to index any external system, including databases, proprietary document managements systems, and custom applications. So long as you have access to an API for the external system, you can create a .NET Assembly Connector to support indexing and searching that system. Because .NET Assembly Connector fundamentals were covered in Chapter 13, this chapter will focus only on the requirements for enabling search.
Whenever any External Content Type (ECT) is created in BCS, there is an XML model that gets created behind the scenes. This model defines the external system, entities, relationships, methods, and user access rights for the ECT. The same is true when a .NET Assembly Connector is created. The primary difference is that the external system is defined as an association between a .NET assembly and the ECT.
When you use SPD to create ECTs, the model is generated for you so that you never have to deal with XML directly. When you use Visual Studio 2010 to create a .NET Assembly Connector, you also have design tools that hide the XML, but you often have to edit the XML model manually to get the exact capabilities you need. In Visual Studio, the XML model is contained in a file with a .bdcm extension. When this file is opened, it appears in three windows. First, a design surface is available for creating entities. Second, a detail section is available for method definitions. Third, the BDC Explorer is available for browsing the model. Figure 15-5 shows the three windows of information for the model described in Chapter 13. This model used a .NET Assembly Connector to connect with product information.
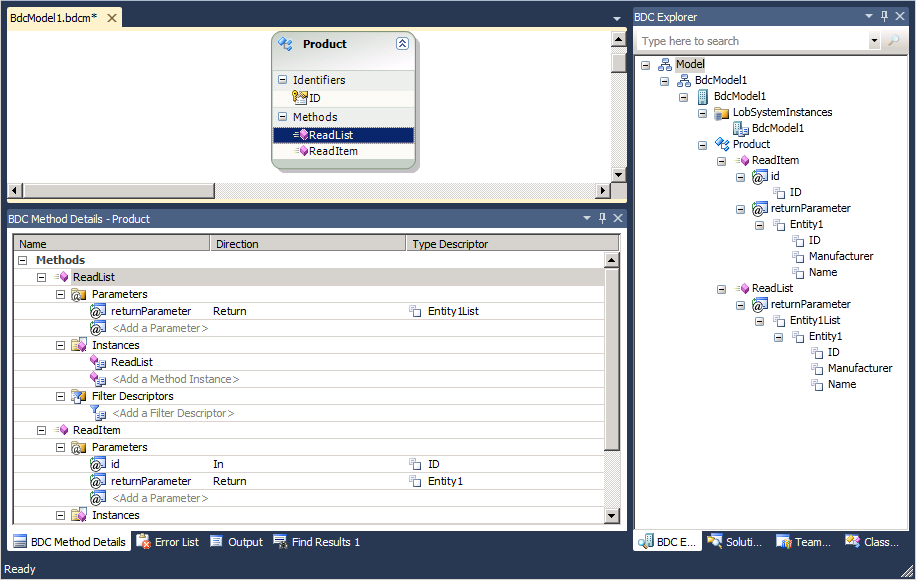
You may view the XML for the model directly by right-clicking the .bdcm file in the Solution Explorer and selecting Open With from the context menu. When the Open With dialog appears, select to open the file with the XML Editor. If you study the XML model alongside the BDC Explorer, you will begin to see that the BDC Explorer contains a node for each key element in the model. This concept is important because you typically will be adding information to model elements when you prepare a .NET Assembly Connector to support search.
To search-enable an existing model, you must make two changes. The first change is to designate which method to call during the indexing process. The second change allows the model to appear as a content source in search. Both changes are simple edits to the XML.
Chapter 13 discussed BCS operations in detail. In particular, Finder methods were defined as methods that return many records from an external system. Essentially, a Finder method defines a view of an external system. When search crawls an external system, it needs to know which of the available Finder methods represents the entire population of records to index. This finder method is known as the RootFinder method.
In your .NET Assembly Connector, you designate the RootFinder by first selecting the method instance in the Method Details pane. When you select it, the Properties window in Visual Studio 2010 will show details for the method. From this window, you can open the Custom Properties collection. In the Property Editor window, you can enter the RootFinder designation with a Type of System.String and a Value of x. Figure 15-6 shows the modifications being made to the sample from Chapter 13.

After setting RootFinder, you can open the model XML in Visual Studio and see how the new information was added to the model. The following code shows the resulting XML.
<MethodInstances>
<MethodInstance Type="Finder"
ReturnParameterName="returnParameter"
Default="true" Name="ReadList"
DefaultDisplayName="Entity1 List">
<Properties>
<Property Name="RootFinder" Type="System.String">x</Property>
</Properties>
</MethodInstance>
</MethodInstances>Once RootFinder is defined, you must make a change to allow the .NET Assembly Connector to appear as a content source in search. This is accomplished by applying the ShowInSearchUI property to the model. This property is applied by selecting the LobSystemInstance for your project under the LobSystemInstances folder in the model explorer. You may then create the property, again setting its value to x, using the same technique as for RootFinder. Figure 15-7 shows the modifications.

After applying the ShowInSearchUI property to the model, it is a good idea to examine the XML and verify the change. The following code shows the modified model for the sample in Chapter 14.
<LobSystemInstances>
<LobSystemInstance Name="BdcModel1" >
<Properties>
<Property Name="ShowInSearchUI" Type="System.String">x</Property>
</Properties>
</LobSystemInstance>
</LobSystemInstances>Once you have completed the two modifications, the model is search-enabled. You may deploy the feature and immediately select it as a search content source. It is worth noting that when you create models using SPD, the RootFinder and ShowInSearchUI properties are added automatically.
While search-enabling a BCS model is fairly simple, this process provides no security checking against search queries. This means that when a search is run against the external system, all matching results will be returned regardless of whether the current user is supposed to see them. In most production applications, you will want to implement an access control list (ACL) that specifies rights for the records returned when searching with a .NET Assembly Connector. This is accomplished by adding a special method to the model called a BinarySecurityDescriptorAccessor method.
The process to implement security begins by adding a new method to the model. In Visual Studio, you can right-click the entity in the design surface and select Add New Method from the context menu. You can then give it a name such as ReadSecurityDescriptor. Once created, the method will appear in the Method Details pane.
Now in the Method Details pane, you must create a new method instance beneath the new method. Once the new method instance is created, you can change its Type in the Properties window to BinarySecurityDescriptorAccessor.
The new method instance will require input and output parameters. Typically, the input parameters are the identifier for an item and the user name of the current user. The output parameter must be a byte array that holds the security descriptor. The following code shows the XML for the new method.
<Method Name="ReadSecurityDescriptor">
<Parameters>
<Parameter Name="id" Direction="In">
<TypeDescriptor Name="ID" TypeName="System.String" IdentifierName="ID" />
</Parameter>
<Parameter Name="acl" Direction="Return">
<TypeDescriptor Name="SecurityDescriptor"
TypeName="System.Byte[]" IsCollection="true" >
<TypeDescriptors>
<TypeDescriptor Name="SecurityDescriptorByte" TypeName="System.Byte"/>
</TypeDescriptors>
</TypeDescriptor>
</Parameter>
</Parameters>
<MethodInstances>
<MethodInstance Name="ReadSecurityDescriptorInstance"
Type="BinarySecurityDescriptorAccessor" ReturnParameterName="acl"/>
</MethodInstances>
</Method>When you create the new method definition, Visual Studio will automatically generate a method stub in code that accepts the input parameters and returns a byte array. Your job is to write code for this method that creates an ACL for the item.
When the BinarySecurityDescriptorAccessor method is called during the indexing process, username will be the account performing the search crawl. This is fine because this account will simply be designated as the owner account for the ACL. In the method, you may add other permissions for users based on whatever criteria you need. For example, the code in Example 15-8 grants access to all users.
Example 15-8. Creating a security ACL
public static byte[] ReadSecurityDescriptor(string id, string username) {
try {
//Grant everyone access
NTAccount workerAcc = new NTAccount(
username.Split('')[0], username.Split('')[1]);
SecurityIdentifier workerSid =
(SecurityIdentifier)workerAcc.Translate(typeof(SecurityIdentifier));
SecurityIdentifier everyone =
new SecurityIdentifier(WellKnownSidType.WorldSid, null);
CommonSecurityDescriptor csd = new CommonSecurityDescriptor(
false, false, ControlFlags.None, workerSid, null, null, null);
csd.SetDiscretionaryAclProtection(true, false);
csd.DiscretionaryAcl.AddAccess(
AccessControlType.Allow, everyone, unchecked((int)0xffffffffL),
InheritanceFlags.None, PropagationFlags.None);
byte[] secDes = new byte[csd.BinaryLength];
csd.GetBinaryForm(secDes, 0);
return secDes;
}
catch (Exception x) {
PortalLog.LogString("Product Model (ReadSecurityDescriptor): {0}", x.Message);
return null;
}
}After creating the BinarySecurityDescriptorAccessor method, a property must be added to the Product entity to hold the ACL. In the sample, this property is named SecurityDescriptor. The model must then be updated to relate the BinarySecurityDescriptorAccessor method to the SecurityDescriptor property. The following code shows how to relate the entity and the method instance.
<MethodInstances>
<MethodInstance Name="ReadSecurityDescriptorInstance"
Type="BinarySecurityDescriptorAccessor"
ReturnParameterName="acl">
<Properties>
<Property Name="WindowsSecurityDescriptorField" Type="System.String">
SecurityDescriptor
</Property>
</Properties>
</MethodInstance>
<MethodInstances>When your .NET Assembly Connector is complete, you should be able to select it as a content source and initiate a full crawl. When you crawl the solution for the first time, it’s a good idea to attach Visual Studio to the crawl process (mssdmn.exe) and watch how the crawl progresses. Set breakpoints in the Finder, SpecificFinder, and BinarySecurityDescriptorAccessor methods. Also, be sure that you have granted access in the BCS service to the account that will perform the crawling.
When the crawl is initiated, you should see the Finder method called first. You’ll then see the SpecificFinder called for each individual item returned from the Finder method. Along the way, the security descriptor should be built for each item. After the crawl completes, check the crawl log for errors. Now you can run a search against the crawled data. SharePoint should use the security descriptors that you constructed to limit access to items as appropriate.
This chapter focused on all the components necessary to create search-based applications in SharePoint 2010. When designing your solutions, you should give consideration to creating solutions that use search, either through keyword queries, full-text queries, or .NET Assembly Connectors, and present results to users so that they can be understood and acted upon. Keep in mind that search-based solutions include much more than just running queries and displaying results.