
Chapter 5. Taking recommenders to production
- Analyzing data from a real dating site
- Designing and refining a recommender engine solution
- Deploying a web-based recommender service in production
So far, this book has toured the recommender algorithms and variants that Apache Mahout provides, and discussed how to evaluate the accuracy and performance of a recommender. The next step is to apply all of this to a real data set to create an effective recommender engine from scratch based on data. You’ll create one based on data taken from a dating site, and then you’ll turn it into a deployable, production-ready web service.
There’s no one standard approach to building a recommender for given data and a given problem domain. The data must at least represent associations between users and items—where users and items might be many things. Adapting the input to recommender algorithms is usually quite a problem-specific process. How you discover the best recommender engine to apply to the input data is likewise specific to each context. It inevitably involves hands-on exploration, experimentation, and evaluation on real problem data.
This chapter presents one end-to-end example that suggests the process you might follow to develop a recommender system using Mahout for your data set. You’ll try an approach, collect data, evaluate the results, and repeat many times. Many approaches won’t go anywhere, but that’s good information as well. This brute force approach is appropriate, because it’s relatively painless to evaluate an approach in Mahout, and because here, as in other problem domains, it’s not at all clear what the right approach is from just looking at the data.
5.1. Analyzing example data from a dating site
This example will use a new data set, derived from the Czech dating site Líbímseti (http://libimseti.cz/). Users of this site are able to rate other users’ profiles on a scale of 1 to 10. A 1 means NELÍBÍ, or dislike, and a 10 means LÍBÍ, or like. The presentation of profiles on the site suggests that users of such a site are expressing some assessment of the profiled user’s appeal, attractiveness, and dateability. A great deal of this data has been anonymized, made available for research, and published by Vaclav Petricek (http://www.occamslab.com/petricek/data/).[1] You’ll need to download a copy of the complete data from this site, at http://www.occamslab.com/petricek/data/libimseticomplete.zip, to use in this chapter’s examples.[2]
1 See also Lukas Brozovsky and Vaclav Petricek, “Recommender System for Online Dating Service,” http://www.occamslab.com/petricek/papers/dating/brozovsky07recommender.pdf
2 Neither the site nor the publisher of the data endorse or are connected with this book.
With 17,359,346 ratings in the data set, this is almost twice as big as our previous GroupLens data set. It contains users’ explicit ratings for items, where items are other people’s user profiles. That means a recommender system built on this data will be recommending people to people. This is a reminder to think broadly about recommenders, which aren’t limited to recommending objects like books and DVDs.
The first step in creating a recommender is analyzing what data you have to work with, and beginning to form ideas about which recommender algorithm might be suitable to use with it. The 257 MB ratings.dat file in the archive you downloaded is a simple comma-delimited file containing user ID, profile ID, and rating. Each line represents one user’s rating of one other user’s profile. The data is purposely obfuscated, so the user IDs aren’t real user IDs from the site. Profiles are user profiles, so this data represents users’ ratings of other users. One might suppose that user IDs and profile IDs are comparable here, that user ID 1 and profile ID 1 are the same user, but this doesn’t appear to be the case, likely for reasons of anonymity.
There are 135,359 unique users in the data, who together rated 168,791 unique user profiles. Because the number of users and items are about the same, neither user-based nor item-based recommendation is obviously more efficient. If there had been a great deal more profiles than users, an item-based recommender would have been slower. Slope-one can be applied here, even though its memory requirements scale up quickly with the number of items; its memory requirements can be capped.
The data set has been preprocessed in a way: no users who produced less than 20 ratings are included. In addition, users who seem to have rated every profile with the same value are excluded, presumably because it may be spam or an unserious attempt at rating. The data that’s given comes from users who bothered to make a number of ratings; presumably, their input is useful, and not noisy, compared to the ratings of less-engaged users.
This input is already formatted for use with Mahout’s FileDataModel. The user and profile IDs are numeric, and the file is already comma-delimited with fields in the required order: user ID, item ID, preference value.
The data set provides another interesting set of data: the gender of the user for many of the profiles in the data set. The gender isn’t given for all profiles; in gender.dat, several lines end in U which means unknown. The gender of the users isn’t given in the data set—just gender of the profiles—but that means we know something more about each item. When being recommended, male profiles are more like each other than they are like female profiles, and vice versa. If most or all of a user’s ratings are for male profiles, it stands to reason that the user will rate male profiles as far more desirable dates than female. This information could be the basis for an item-item similarity metric.
This isn’t a perfect assumption. Without becoming sidetracked on sensitive issues of sexuality, note that some users of the site may enjoy rating profiles of a gender they aren’t interested in dating, for fun. Some users may also legitimately have some romantic interest in both genders. In fact, the very first two ratings in ratings.dat are from one user, and yet appear to be for profiles of different genders.
It’s important to account for gender in a dating site recommender engine like this; it would be bad to recommend a female to a user interested only in males—this would surely be viewed as a bad recommendation, and, to some, offensive. This restriction is important, but it doesn’t fit neatly into the standard recommender algorithms we’ve seen in Mahout. Later sections in this chapter will examine how to inject this information as both a filter and a similarity metric.
5.2. Finding an effective recommender
To create a recommender engine for the Líbímseti data, you need to pick a recommender implementation from Mahout. The recommender ought to be both fast and produce good recommendations. Of those two, it’s better to focus on producing good recommendations first, and then look to performance. After all, what’s the use in producing bad answers quickly?
It’s impossible to deduce the right implementation from looking at the data; some empirical testing is needed. Armed with the recommender evaluation framework from chapter 2, the next step is to collect some information on how well various implementations perform on this data set.
5.2.1. User-based recommenders
User-based recommenders are a natural first stop. Several different similarity metrics and neighborhood definitions are available in Mahout. To get some sense of what works and what doesn’t, you can try many combinations. The result of some such experimenting in our test environment is summarized in tables 5.1 and 5.2, and figures 5.1 and 5.2.
Table 5.1. Average absolute difference in estimated and actual preferences when evaluating a user-based recommender using one of several similarity metrics, and using a nearest-n user neighborhood
|
Similarity |
n = 1 |
n = 2 |
n = 4 |
n = 8 |
n = 16 |
n = 32 |
n = 64 |
n = 128 |
|---|---|---|---|---|---|---|---|---|
| Euclidean | 1.17 | 1.12 | 1.23 | 1.25 | 1.25 | 1.33 | 1.48 | 1.43 |
| Pearson | 1.30 | 1.19 | 1.27 | 1.30 | 1.26 | 1.35 | 1.38 | 1.47 |
| Log-likelihood | 1.33 | 1.38 | 1.33 | 1.35 | 1.33 | 1.29 | 1.33 | 1.49 |
| Tanimoto | 1.32 | 1.33 | 1.43 | 1.32 | 1.30 | 1.39 | 1.37 | 1.41 |
Table 5.2. Average absolute difference in estimated and actual preferences when evaluating a user-based recommender using one of several similarity metrics, and using a threshold-based user neighborhood. Some values are “not a number,” or undefined, and are denoted by Java’s NaN symbol.
|
Similarity |
t = 0.95 |
t = 0.9 |
t = 0.85 |
t = 0.8 |
t = 0.75 |
t = 0.7 |
|---|---|---|---|---|---|---|
| Euclidean | 1.33 | 1.37 | 1.39 | 1.43 | 1.41 | 1.47 |
| Pearson | 1.47 | 1.4 | 1.42 | 1.4 | 1.38 | 1.37 |
| Log-likelihood | 1.37 | 1.46 | 1.56 | 1.52 | 1.51 | 1.43 |
| Tanimoto | NaN | NaN | NaN | NaN | NaN | NaN |
Figure 5.1. Visualization of values in table 5.1

Figure 5.2. Visualization of values in table 5.2

These scores aren’t bad. These recommenders are estimating user preferences to within 1.12 to 1.56 points on a scale of 1 to 10, on average.
There are some trends here, even though some individual evaluation results vary from that trend. It looks like the Euclidean distance similarity metric may be a little better than Pearson, though their results are quite similar. It also appears that using a small neighborhood is better than a large one; the best evaluations occur when using a neighborhood of two people! Maybe users’ preferences are truly quite personal, and incorporating too many others in the computation doesn’t help.
What explains the NaN (not a number) result for the Tanimoto coefficient–based similarity metric? It’s listed here to highlight a subtle point about this methodology. Although all similarity metrics return a value between −1 and 1 and return higher values to indicate greater similarity, it’s not true that any given value means the same thing for each similarity metric. This is generally true, and not an artifact of how Mahout works. For example, 0.5 from a Pearson correlation-based metric indicates moderate similarity. A value of 0.5 for the Tanimoto coefficient indicates significant similarity between two users: of all items known to either of them, half are known to both.
Even though thresholds of 0.7 to 0.95 were reasonable values to test for the other metrics, these are quite high for a Tanimoto coefficient–based similarity metric. In each case, the bar was set so high that no user neighborhood was established in any test case! Here, it might have been more useful to test thresholds from, say, 0.4 on down. In fact, with a threshold of 0.3, the best evaluation score approaches 1.2.
Similarly, although there’s an apparent best value for n in the nearest-n user neighborhood data, there isn’t quite the same best value in the threshold-based user neighborhood results. For example, the Euclidean distance–based similarity metric seems to be producing better results as the threshold increases. Perhaps the most valuable users to include in the neighborhood have a Euclidean-based similarity of over 0.95. What happens at 0.99? Or 0.999? The evaluation result goes down to about 1.35; not bad, but not apparently the best recommender.
You can continue looking for even better configurations. For our purposes here, though, we take the current best solution in Mahout to be
- User-based recommender
- Euclidean distance similarity metric
- Nearest-2 neighborhood
5.2.2. Item-based recommenders
Item-based recommenders involve just one choice: an item similarity metric. Trying each similarity metric is a straightforward way to see what works best. Table 5.3 summarizes the outcomes.
Table 5.3. Average absolute differences in estimated and actual preferences, when evaluating an item-based recommender using several different similarity metrics
|
Similarity |
Score |
|---|---|
| Euclidean | 2.36 |
| Pearson | 2.32 |
| Log-likelihood | 2.38 |
| Tanimoto | 2.40 |
Scores are notably worse here; the average error, or difference between estimated and actual preference values, has roughly doubled to over 2. For this data, the item-based approach isn’t as effective, for some reason. Why? Before, the algorithm computed similarities between users in a user-based approach, based on how users rated other users’ profiles. Now, it’s computing the similarity between user profiles based on how other users rated that profile. Maybe this isn’t as meaningful—maybe ratings say more about the rater than the rated profile.
Whatever the explanation, it seems clear from these results that item-based recommendation isn’t the best choice here.
5.2.3. Slope-one recommender
Recall that the slope-one recommender constructs a diff for most item-item pairs in the data model. With 168,791 items (profiles) here, this means storing potentially 28 billion diffs—far too much to fit in memory. Storing these diffs in a database is possible, but it’ll greatly slow performance.
Fortunately, there is another option, which is to ask the framework to limit the number of diffs stored to perhaps ten million, as shown in listing 5.1. The framework will attempt to choose the most useful diffs to keep. Most useful here means those diffs between a pair of items that turn up most often together in the list of items associated with a user. For example, if items A and B appear in the preferences of hundreds of users, the average diff in their preference values is likely significant, and useful. If A and B only appear together in the preferences of one user, it’s more like a fluke than a piece of data worth storing.
Listing 5.1. Limiting memory consumed by MemoryDiffStorage
DiffStorage diffStorage = new MemoryDiffStorage(
model, Weighting.WEIGHTED, 10000000L);
return new SlopeOneRecommender(
model, Weighting.WEIGHTED, Weighting.WEIGHTED, diffStorage);
From examining the Mahout log output, this approach keeps memory consumption to about 1.5 GB. You’ll also notice again how fast slope-one is; on the workstation we used for testing, the average recommendation times were under 10 milliseconds, compared to 200 milliseconds or so for other algorithms.
The evaluation result is about 1.41. This isn’t a bad result, but not quite as good as observed with the user-based recommenders. It’s likely not worth pursuing slope-one for this particular data set.
5.2.4. Evaluating precision and recall
The preceding examples experimented with a Tanimoto coefficient–based similarity metric and a log-likelihood–based metric, neither of which use preference values. But they didn’t evaluate recommenders that completely ignore rating values. Such recommenders can’t be evaluated in the same way—there are no estimated preference values to compare against real values because there are no preference values at all.
It’s possible to examine the precision and recall of such recommenders against the current best solution (user-based recommender with a Euclidean distance metric and a nearest-2 neighborhood) by using a RecommenderIRStatsEvaluator. This evaluator reveals that precision and recall at 10 (that is, precision and recall as judged by looking at the first 10 recommendations) are about 3.6 and 5 percent, respectively. This seems low: the recommender rarely recommends the users’ own top-rated profiles when those top-rated profiles are removed. In this context, that’s not obviously a bad thing. It’s conceivable that a user might see plenty of perfect 10s on such a dating site and perhaps has only ever encountered and rated some of them. It could be that the recommender is suggesting even more desirable profiles than the user has seen! Certainly, this is what the recommender is communicating, that the users’ top-rated profiles aren’t usually the ones they would like most, were they to actually review every profile in existence.
The other explanation, of course, is that the recommender isn’t functioning well. But this recommender is fairly good at estimating preference values, usually estimating ratings within about 1 point on a 10-point scale. So the explanation in the previous paragraph could be valid.
An interesting thing happens when the rating data is ignored by using Mahout’s GenericBooleanPrefDataModel, GenericBooleanPrefUserBasedRecommender, and an appropriate similarity metric like LogLikelihoodSimilarity. Precision and recall increase to over 22 percent in this case. Similar results are seen with TanimotoCoefficientSimilarity. These results seem better on the surface; what they say is that this sort of recommender engine is better at recommending those profiles that the user might already have encountered. If there were reason to believe users had, in fact, reviewed a large proportion of all profiles, their actual top ratings would be a strong indicator of what the right answers are. This isn’t likely to be the case on a dating site with hundreds of thousands of profiles.
In other contexts, a high precision and recall figure may be important. Here, it doesn’t seem to be as important. For our purposes, we move forward with the previous user-based recommender, with Euclidean distance similarity and a nearest-2 neighborhood, instead of opting to switch to one of these other recommenders.
5.2.5. Evaluating Performance
It’s important to look at the runtime performance of our chosen recommender. Because it’ll be queried in real time, it would do little good to produce a recommender that needs minutes to compute a recommendation!
The LoadEvaluator class can be used, as before, to assess the time required per recommendation. We ran this recommender on the data set with these flags -server -d64 -Xmx2048m -XX:+UseParallelGC -XX:+UseParallelOldGC and we found an average recommendation time of 218 milliseconds on our test machine. The application consumes only about a gigabyte of heap at runtime. Whether or not these values are acceptable or not will depend on application requirements and available hardware. These figures seem reasonable for many applications.
So far we’ve just applied standard Mahout recommenders to the data set at hand. We’ve had to do no customization. But creating the best recommender system for a particular data set or site inevitably requires taking advantage of all the information you can. This, in turn, requires some degree of customization and specialization of standard implementations, like those in Mahout, to make use of the particular attributes of the problem at hand. In the next section, we look at extending the existing Mahout implementations in small ways to take advantage of particular properties of the dating data, in order to increase the quality of our recommendations.
5.3. Injecting domain-specific information
So far the recommender hasn’t taken advantage of any domain-specific knowledge. It hasn’t taken advantage of the fact that the ratings are, specifically, people rating other people. It has used the user-profile rating data as if it were anything at all—ratings for books or cars or fruit. But it’s often possible to incorporate additional information in the data to improve recommendations.
In the following subsections, we look at ways to incorporate one important piece of information in this data set that has so far been unused: gender. We create a custom ItemSimilarity metric based on gender, and we also look at how to avoid recommending users of an inappropriate gender.
5.3.1. Employing a custom item similarity metric
Because the gender of many profiles is given, you could create a simple similarity metric for pairs of profiles based only on gender. Profiles are items, so this would be an ItemSimilarity in the framework.
For example, call two male or two female profiles very similar and assign them a similarity of 1.0. Say the similarity between a male and female profile is –1.0. Finally, assign a 0.0 to profile pairs where the gender of one or both is unknown.
This idea is simple, perhaps overly simplistic. It would be fast, but it would discard all rating-related information from the metric computation. For the sake of experimentation, let’s try it out with an item-based recommender, as follows.
Listing 5.2. A gender-based item similarity metric
public class GenderItemSimilarity implements ItemSimilarity {
private final FastIDSet men;
private final FastIDSet women;
public GenderItemSimilarity(FastIDSet men, FastIDSet women) {
this.men = men;
this.women = women;
}
public double itemSimilarity(long profileID1, long profileID2) {
Boolean profile1IsMan = isMan(profileID1);
if (profile1IsMan == null) {
return 0.0;
}
Boolean profile2IsMan = isMan(profileID2);
if (profile2IsMan == null) {
return 0.0;
}
return profile1IsMan == profile2IsMan ? 1.0 : -1.0;
}
public double[] itemSimilarities(long itemID1, long[] itemID2s) {
double[] result = new double[itemID2s.length];
for (int i = 0; i < itemID2s.length; i++) {
result[i] = itemSimilarity(itemID1, itemID2s[i]);
}
return result;
}
...
private Boolean isMan(long profileID) {
if (men.contains(profileID)) {
return Boolean.TRUE;
}
if (women.contains(profileID)) {
return Boolean.FALSE;
}
return null;
}
public void refresh(Collection<Refreshable> alreadyRefreshed) {
// do nothing
}
}
This ItemSimilarity metric can be paired with a standard GenericItemBasedRecommender, as before, and we can evaluate the recommender’s accuracy. The concept is interesting, but the result here isn’t better than with other metrics: 2.35. If more information were available, such as the interests and hobbies expressed on each profile, it could form the basis of a more meaningful similarity metric that might yield better results.
This example, however, illustrates the main advantage of item-based recommenders: it provides a means to incorporate information about items themselves, which is commonly available in recommender problems. From the evaluation results, you also perhaps noticed how this kind of recommender is fast when based on such an easy-to-compute similarity metric; on our test machine, recommendations were produced in about 15 milliseconds on average.
5.3.2. Recommending based on content
If you blinked, you might have missed it—that was an example of content-based recommendation in the last section. It had a notion of item similarity that wasn’t based on user preferences, but that was based on attributes of the item itself. As we’ve said before, Mahout doesn’t provide content-based recommendation implementations, but it does provide expansion points and APIs that let you write code to deploy it within the framework.
It’s a powerful addition to pure collaborative filtering approaches, which are based only on user preferences. You can usefully inject your knowledge about items (here, people) to augment the user preference data you have, and hopefully produce better recommendations.
Unfortunately the previous item similarity metric is specific to the problem domain at hand. This metric doesn’t help with recommendations in other domains: recommending food, or movies, or travel destinations. That’s why it’s not part of the framework. But it’s a feasible and powerful approach any time you have domain-specific knowledge, beyond user preferences, about how items are related.
5.3.3. Modifying recommendations with IDRescorer
You may have observed an optional, final argument to the Recommender.recommend() method of type IDRescorer; instead of calling recommend(long userID, int howMany), you can call recommend(long userID, int howMany, IDRescorer rescorer). Implementations of this interface show up in several parts of the Mahout recommender-related APIs. Implementations can transform values used in the recommender engine to other values based on some logic, or they can exclude an entity from consideration in some process. For example, an IDRescorer can be used to arbitrarily modify a Recommender’s estimated preference value for an item. It can also remove an item from consideration entirely.
Suppose you were recommending books to a user on an e-commerce site. The user is currently browsing mystery novels, so when recommending books to that user at that moment, you might wish to boost estimated preference values for all mystery novels. You may also wish to ensure that no out-of-stock books are recommended. An IDRescorer can help you do this. The following listing shows an IDRescorer implementation that encapsulates this logic in terms of some made-up implementation classes, like Genre, from this fictitious bookseller.
Listing 5.3. Example IDRescorer that omits out-of-stock books and boosts a genre

The rescore() method boosts the estimated preference value for mystery novels. The isFiltered() method demonstrates the other use of IDRescorer: it ensures that no out-of-stock books are considered for recommendation.
This was merely an example and isn’t relevant to our dating site. Let’s apply this idea with the extra data available: gender.
5.3.4. Incorporating gender in an IDRescorer
An IDRescorer can filter out items, or user profiles, for users whose gender may not be of romantic interest. An implementation might work by first guessing the user’s preferred gender, by examining the gender of profiles rated so far. Then it could filter out profiles of the opposite gender, as seen in the next listing.
Listing 5.4. Gender-based rescoring implementation

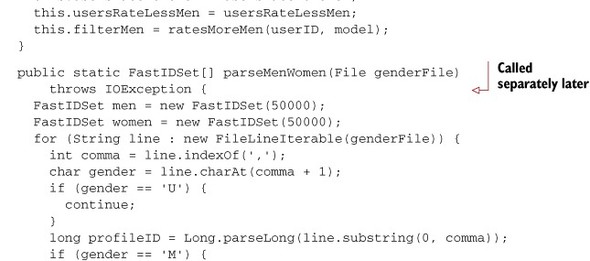
A few things are happening in this code example. The parseMenWomen() method will parse gender.dat and create two sets of profile IDs—those that are known to be men and those known to be women. This is parsed separately from any particular instance of GenderRescorer, because these sets will be reused many times. The ratesMoreMen() method will be used to determine and remember whether a user seems to rate more male or female profiles. These results are cached in two additional sets.
Instances of this GenderRescorer will then simply filter out men, or women, as appropriate, by returning NaN from rescore(), or true from isFiltered().
This ought to have some small but helpful effect on the quality of the recommendations. Presumably, women who rate male profiles are already being recommended male profiles, because they’ll be most similar to other women who rate male profiles. This mechanism will ensure this by filtering female profiles from the results. It’ll cause the recommender to not even attempt to estimate these women’s preference for female profiles because such an estimate is quite a guess, and likely wrong. Of course, the effect of this IDRescorer is limited by the quality of data available: the gender of only about half of the profiles is known.
5.3.5. Packaging a custom recommender
It will be useful for our purposes to wrap up the current recommender engine, plus the new IDRescorer, into one implementation. This will allow us, in section 5.5, to deploy one self-contained recommender engine.
The following listing shows a recommender implementation that contains the previous user-based recommender engine.
Listing 5.5. Complete recommender implementation for Líbímseti


This is a tidy, self-contained packaging of the recommender engine. If you evaluate it, the result is about 1.18; this is virtually unchanged, and it’s good to have this mechanism in place to avoid some seriously undesirable recommendations. Running time has increased to 500 milliseconds or so—the rescoring has added significant overhead. For our purposes here, this tradeoff is acceptable, and LibimsetiRecommender is the final implementation for this dating site.
5.4. Recommending to anonymous users
Another common issue you’ll soon run into when creating a real production-ready recommender is what to do with users that aren’t registered users yet. What can be done, for instance, for the new user browsing products in an e-commerce website?
This anonymous user has no browsing or purchase history, let alone an ID, as far as the site is concerned. The problem of making recommendations to such users, starting from no data, is called the cold start problem. It’s nevertheless valuable to be able to recommend products to such a user.
One extreme approach is to not bother personalizing the recommendations. That is, when presented with a new user, present a general predefined list of products to recommend. It’s simple, and usually better than nothing, but not an option we explore. Mahout is in the business of personalizing recommendations.
At the other extreme end of the spectrum, a site could promote such anonymous users to real users on their first visit, and assign an ID and track their activity based on a web session. This also works, though it potentially explodes the number of users, many of whom, by definition, may never return and for whom little information exists. This is also not an option we explore.
Instead, we examine two compromise approaches between these extremes: creating temporary users and treating all anonymous users as if they were one user.
5.4.1. Temporary users with PlusAnonymousUserDataModel
The recommender framework offers a simple way to temporarily add an anonymous user’s information into the DataModel: by using the PlusAnonymousUserDataModel class. This approach treats anonymous users like real users, but only for as long as it takes to make recommendations. They’re never added to or known to the real underlying DataModel. PlusAnonymousUserDataModel is a wrapper around any existing DataModel and is simply a drop-in replacement
The PlusAnonymousUserDataModel class has a spot for one temporary user, and it can hold preferences for one such user at a time. As such, a Recommender based on this class must only operate on one anonymous user at a time.
The next listing presents LibimsetiWithAnonymousRecommender, which extends the previous LibimsetiRecommender with a method that can recommend to an anonymous user. It takes preferences as input rather than a user ID, of course.
Listing 5.6. Anonymous user recommendation for Líbímseti


This implementation otherwise works like any other recommender and can be used to recommend to real users as well.
5.4.2. Aggregating anonymous users
It’s also possible to treat all anonymous users as if they were one user. This simplifies things. Rather than tracking potential users separately and storing their browsing histories individually, you could think of all such users as one big tire-kicking user. This depends upon the assumption that all such users behave similarly.
At any time, this technique can produce recommendations for the anonymous user, and it’s fast. In fact, because the result is the same for all anonymous users, the set of recommendations can be stored and recomputed periodically instead of upon every request. In a sense, this variation nearly reduces to not personalizing recommendations at all, and to presenting anonymous users with a fixed set of recommendations.
5.5. Creating a web-enabled recommender
Creating a recommender that runs in your IDE is fine, but chances are you’re interested in deploying this recommender in a real production application.
You may wish to deploy a recommender that you’ve designed and tested in Java and Mahout as a standalone component of your application architecture, rather than embed it inside your application’s Java code. It’s common for services to be exposed over the web, via simple HTTP or web service protocols like SOAP. In this scenario, a recommender is deployed as a web-accessible service, or as an independent component in a web container, or even as its own server process. This adds complexity, but it allows other applications written in other languages, or running on other machines, to access the service.
Fortunately, Mahout makes it simple to bundle your recommender implementation into a deployable WAR (web archive) file. Such a component can be readily deployed into any Java servlet container, such as Tomcat (http://tomcat.apache.org/) or Resin (http://www.caucho.com/resin/). The WAR file, illustrated in figure 5.3, wraps up your Recommender implementation and exposes it via a simple servlet-based HTTP service, RecommenderServlet, and as an Apache Axis-powered web service using SOAP over HTTP, RecommenderService.
Figure 5.3. Automated WAR packaging of a recommender and deployment in a servlet container

5.5.1. Packaging a WAR file
The compiled code, plus data file, will need to be packaged into a JAR file before they can be deployed. Chances are you’ve already compiled this code with your IDE. Change to the book’s examples directory and copy the data set’s ratings.dat and gender.dat files into the src/main/resources directory, and then make a JAR file with this command:
mvn package
That will put the result into the target/mia-0.1.jar file.
Then change to the Mahout distribution and the taste-web/module directory, and copy target/mia-0.1.jar from the book’s examples into the lib/subdirectory. Also, edit recommender.properties to name your recommender as the one that will be deployed. If you’re using the same Java package name as the sample code does, the right value is mia.recommender.ch05.LibimsetiRecommender.
Now execute mvn package again. You should find a .war file in the target/subdirectory named mahout-taste-webapp-0.5.war (the version number may be higher if, by the time you read this, Mahout has published further releases). This file is suitable for immediate deployment in a servlet container like Tomcat. In fact, it can be dropped into Tomcat’s webapps/directory without further modification to produce a working web-based instance of your recommender.
Note
The name of the .war file will become part of the URL used to access the services; you may wish to rename it to something shorter like mahout.war.
5.5.2. Testing deployment
Alternatively, you can easily test this same web application containing your recommender without bothering to set up Tomcat by using Maven’s built-in Jetty plugin. Jetty (http://www.mortbay.org/jetty/) is an embeddable servlet container, which serves a function similar to that of Tomcat or Resin.
Before firing up a test deployment, you’ll need to ensure that your local Mahout installation has been compiled and made available to Maven. Execute mvn install from the top-level Mahout directory and take a coffee break, because this will cause Maven to download other dependencies, compile, and run tests, all of which takes 10 minutes or so. This only needs to be done once.
Having packaged the WAR file as discussed in the previous section, execute export MAVEN_OPTS=-Xmx2048m to ensure that Maven and Jetty have plenty of heap space available. Then, from the taste-web/directory, execute mvn jetty:run-war. This will start up the web-enabled recommender services on port 8080 on your local machine. Startup could take some time, because Mahout will load and analyze data files.
In your web browser, navigate to the URL: http://localhost:8080/RecommenderServlet?userID=3 to retrieve recommendations for user ID 3. This is precisely how an external application could access recommendations from your recommender engine, by issuing an HTTP GET request for this URL and parsing the simple text result: recommendations, one estimated preference value and item ID per line, with the best preference first (as shown in the next listing).
Listing 5.7. Output of a GET to RecommenderServlet
10.0 205930 10.0 156148 8.0 162783 7.5 208304 7.5 143604 7.0 210831 7.0 173483 4.5 163100
To explore the more formal SOAP-based web service API that’s available, access http://localhost:8080/RecommenderService.jws?wsdl to see the WSDL (Web Services Definition Language) file that defines the input and output of this web service. It exposes a simplified version of the Recommender API. This web services description file can be consumed by most web service clients to automatically understand and provide access to the API.
If you’re interested in trying the service directly in a browser, access http://localhost:8080/RecommenderService.jws?method=recommend&useID=1&howMany=10 to see the SOAP-based reply from the service. It’s the same set of results, just presented as a SOAP response (see figure 5.4).
Figure 5.4. Browser rendering of the SOAP response from RecommenderService

Normally, at this point, you would be sanity-checking the results. Put yourself in your users’ shoes—do the recommendations make sense? Here, it’s not possible to know who the users are or what the profiles are like, so there’s no intuitive interpretation of the results. This wouldn’t be true when developing your own recommender engine, where a look at the actual recommendations would likely give insight into problems or opportunities for refinement. This would lead to more cycles of experimentation and modification to make the results match the most appropriate answers for your problem domain.
5.6. Updating and monitoring the recommender
Now you have a live web-based recommender service running, but it’s not a static, fixed system that’s run and then forgotten. It’s a dynamic server, ingesting new information and returning answers in real time, and like any production system, it’s natural to think about how the service will be updated and monitored.
Of course, the data on which recommendations are based changes constantly in a real recommender engine system. Standard DataModel implementations will automatically use the most recent data available from your underlying data source, so, at a high level, there’s nothing special that needs to be done to cause the recommender engine to incorporate new data. For example, if you had based your recommender engine on data in a database, by using a JDBCDataModel, then just by updating the underlying database table with new data, the recommender engine would begin using that data.
But for performance, many components cache information and intermediate computations. These caches update eventually, but this means that new data doesn’t immediately affect recommendations. It’s possible to force all caches to clear by calling Recommender.refresh(), and this can be done by invoking the refresh method on the SOAP-based interface that’s exposed by the web application harness. If needed, this can be invoked by other parts of your enterprise architecture.
File-based preference data, accessed via a FileDataModel, deserves some special mention. The file can be updated or overwritten in order to deploy updated information; FileDataModel will shortly thereafter notice the update and reload the file.
Reloading the data file can be slow and memory-intensive, as both the old and new model will be in memory at the same time. Now is a good time to recall update files, introduced in chapter 3. Instead of replacing or updating the main data file, it’s more efficient to add update files representing recent updates. The update files are like diffs, and when placed in the same directory as the main data file and named appropriately, they’ll be detected and applied quickly to the in-memory representation of the preference data.
For example, an application might, each hour, locate all preference data created, deleted, or changed in the last 60 or more minutes, create an update file, and copy it alongside the main data file. Recall also that, for efficiency, all of these files can be compressed.
Monitoring the health of this recommender service is straightforward, even if support for monitoring is outside the scope of Mahout itself. Any monitoring tool that can check the health of a web-based service, accessed via HTTP, can easily check that the recommender service is live by accessing the service URL and verifying that a valid answer is returned. Such tools can and should also monitor the time it takes to answer these requests and create an alert if performance suddenly degrades. Normally, the time it takes to compute a recommendation is quite consistent and shouldn’t vary greatly.
5.7. Summary
In this chapter, we took an in-depth look at a real, large data set made available from the Czech dating site Líbímseti. It provides 17 million ratings of over a hundred thousand profiles from over a hundred thousand users. We set out to create a recommender for this site that could recommend profiles, or people, to its users.
We tried most of the recommender approaches seen so far with this data set and used evaluation techniques to choose an implementation that seemed to produce the best recommendations: a user-based recommender using a Euclidean distance-based similarity metric and a nearest-2 neighborhood definition.
From there, we explored mixing in additional information from the data set: the gender of the users, which is featured in many of the profiles. We tried creating an item similarity metric based on this data. We met the IDRescorer interface, a practical tool that can be used to modify results in ways specific to a problem domain. We achieved a small improvement by using an IDRescorer to take account of gender and exclude recommendations from the gender that doesn’t apparently interest the user.
Having tested performance and found it acceptable (about 500 ms per recommendation), we constructed a deployable version of the recommender engine and automatically created a web-enabled application around it using Mahout. We briefly examined how to deploy and access this component via HTTP and SOAP.
Finally, we reviewed how to update, at runtime, the recommender’s underlying data.
This concludes our journey from data to production-ready recommender service. This implementation can comfortably digest the data set of 17 million ratings on one machine and produce recommendations in real time. But what happens when the data outgrows one machine? In the next chapter, we examine how to handle a much larger data set with Hadoop.